プライスアクション分析ツールキットの開発(第35回):予測モデルの学習とデプロイ

はじめに
前回の記事では、MQL5スクリプトからPythonに履歴データをストリーミングし、ディスクに保存する信頼性の高いパイプラインを構築しました。この時点ではデータ取得レイヤーまでにとどめ、ローソク足データを取得、シリアライズ、再読み込みできることを確認しましたが、モデルの学習には進みませんでした。
今回の記事では前回中断したところから再開します。データの保存にとどまらず、以下のことをおこないます。
- 取得したデータを使った予測モデルの学習
- 銘柄ごとのモデルのパッケージ化とキャッシュ
- MQL5のエキスパートアドバイザー(EA)がリアルタイムでクエリできる、軽量なREST APIとしてのデプロイ
これを実現するために、Pythonの機械学習エコシステムの強みとMetaTrader 5の実行速度を組み合わせます。EAは市場とのやり取りを担当し、Pythonサービスが特徴量生成、モデル推論、および必要に応じた定期的な再学習を担当します。
この文脈での「学習可能なモデル」とは、データから内部パラメータを最適化できるアルゴリズムを指します。scikit-learnを使った古典的な手法(勾配ブースティングやサポートベクターマシンなど)は、表形式データに適しています。一方、TensorFlowやPyTorchなどの深層学習フレームワークは、より複雑なアーキテクチャの構築に対応します。Pythonは豊富なライブラリ、明快な構文、活発なコミュニティを備えているため、このパイプラインの段階に最適な言語です。
以下の表は、完成したシステムにおける各コンポーネントの役割をまとめたものです。
| コンポーネント | ワークフローにおける役割 |
|---|---|
| MQL5 EA | ライブバーや口座状態を取得し、特徴量のリクエストを送信。APIから返された売買シグナルを実行。 |
| Python取り込みスクリプト | MetaTrader 5からの履歴データを受け取り、クリーニングして保存(Parquet形式)。 |
| 特徴量エンジニアリングモジュール | 生のOHLCデータをテクニカルおよび統計的特徴量に変換。 |
| 学習モジュール | 銘柄ごとのモデルを訓練または更新し、joblibでシリアライズ。 |
| Flask RESTサービス | /predictや/upload_historyなどを提供し、メモリ内モデルキャッシュを管理してミリ秒単位の応答を実現。 |
この記事は次のように構成されています。
それでは、さっそく始めましょう。
データ取得パイプラインの要約
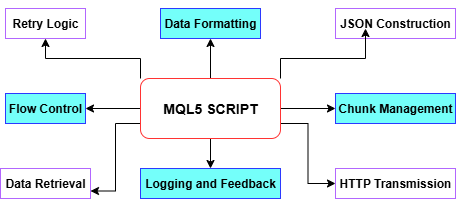
前回の記事で解説したとおり、履歴データ取り込みスクリプトはMetaTrader 5からPythonへのワークフロー全体を効率化しています。まず、CopyRatesを使用して必要な履歴バーを取得し、タイムスタンプ、高値、安値、終値を配列に変換します。その後、それぞれのデータ部分をBuildJSONによってJSON形式のペイロードにまとめます。MetaTrader5のWebRequestにおけるサイズ制限を超えないように、スクリプトはデータを自動的に扱いやすいチャンクに分け、必要に応じて半分のサイズまで縮小し、あらかじめ定義された最小サイズに達するまで調整します。各チャンクはPostChunkを通じてPython側のエンドポイントへ送信され、再試行ロジックやタイムアウト制御も備えています。実行の過程では、すべてのステップやエラーを[エキスパート]タブに記録し、失敗時には安全に終了、全データのアップロード完了時には正常終了を報告します。こうした設計により、スパイク検出パイプラインの堅固な基盤が築かれます。
以下の図を見ながら、MQL5スクリプト内の各関数について詳しく見ていきましょう。
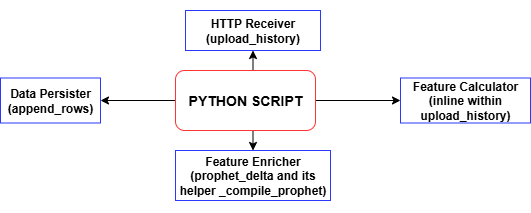
MQL5スクリプトが履歴バーのチャンクをPOSTするたびに、Python側のupload_historyハンドラはすべてのテクニカル指標とラベルを計算し、append_rowsを呼び出してそれらのレコードをtraining_set.csvに書き込みます。ファイルやヘッダーが存在しない場合は自動的に生成され、POSTのたびにタイムスタンプ付きの完全なデータセットが構築されていきます。このようにしてアップロードを繰り返すことで、モデル学習にそのまま使用できる整ったデータセットが形成されます。このtraining_set.csvこそが、次の段階でスパイク検出モデルを学習させるための主要なデータセットとなります。
MQL5とPythonでの実装
本記事では、単純なスクリプトの使用から一歩進め、完全なEAを開発し、継続的なモニタリングとPythonバックエンドとのリアルタイム通信を実現します。これは、単体のスクリプトでは効率的に処理できない部分です。MetaTrader5上で動作するSpike Detector EAはクライアント-サーバ構成で設計されており、EAがクライアントとして機能し、PythonのFlaskサーバがバックエンドとして動作します。EAは新しいローソク足の形成を常時監視します。定義された時間間隔ごとに、設定された本数の履歴ローソク足(OHLCVデータとタイムスタンプ)を収集し、それをJSON形式にシリアライズしてHTTPのPOSTリクエストを介してPythonサーバへ送信します。
Pythonバックエンドは、通常は機械学習モデルまたはルールベースのロジックを含んでおり、受信した市場データを分析してシグナル(BUY、SELL、CLOSE、WAIT)を返します。EAはこのレスポンスを受け取ると、ユーザー設定に基づいてシグナルを解釈し、チャート上に矢印を描画したり、新規ポジションを開いたり、既存のポジションをクローズしたりといった動作をおこないます。このフィードバックループにより、MetaTraderは外部の分析的インテリジェンスをリアルタイムで活用できるようになり、MetaTrader 5の実行エンジンとPythonの処理能力を効果的に組み合わせることができます。
MQL5での実装
スクリプトのメタデータとStrictモード
MQL5ファイルの冒頭では、#property copyright、#property link、#property versionといったメタデータプロパティを宣言し、著作権情報やバージョン情報をコンパイル済みEA内に直接埋め込みます。#property strictを有効にすると、最も厳格なコンパイル時チェックが適用され、構文エラーや型エラーを早期に検出できるようになり、コードがベストプラクティスに準拠していることを保証します。
#property copyright "Copyright 2025, MetaQuotes Ltd." #property link "https://www.mql5.com/ja/users/lynnchris" #property version "1.0" #property strict
取引ライブラリの読み込み
<Trade\Trade.mqh>をインクルードし、CTradeオブジェクトをインスタンス化することで、MetaTraderのネイティブな取引管理APIにアクセスできるようになります。この組み込みライブラリは、成行注文、逆指値注文、ポジションのクローズなど、取引に必要な各種操作をおこなうメソッドを提供しており、サーバーからのシグナルに応じて取引をプログラム的にオープン、変更、クローズすることができます。
#include <Trade\Trade.mqh> static CTrade trade;
入力パラメータの定義
RESTエンドポイントのURL(InpServerURL)や送信するバーの本数(InpBufferBars)から、チャート描画オプションや取引実行フラグに至るまで、すべてのユーザー設定可能な項目はinput文であらかじめ宣言されます。各パラメータにはその目的を説明するインラインコメントが付けられており、EA自体が自己ドキュメント化されます。これにより、トレーダーはコードを変更することなく、MetaTrader5のGUI上で動作を直接微調整することができます。
// REST endpoint & polling input string InpServerURL = "http://127.0.0.1:5000/analyze"; input int InpBufferBars = 200; input int MinSecsBetweenReq = 10; // Visual & trading options input color ColorBuy = clrLime; input color ColorSell = clrRed; input bool DrawSLTPLines = true; input bool EnableTrading = true; input double FixedLots = 0.10; // Debug & retry controls input int MaxRetry = 3; input bool DebugPrintJSON = true; input bool DebugPrintReply = true;
グローバル状態変数
lastBarTimeやlastReqTimeなど、リクエストの制御用のグローバル変数、HTTP再試行ロジック用のretryCount、および価格を正確にフォーマットするための_digitsとtickSizeなど、いくつかのグローバル変数を維持します。さらに、objPrefixという文字列を現在のチャートIDで初期化して使用し、EAが作成するすべてのチャートオブジェクト(矢印やライン)に名前空間を付与します。これにより、後からオブジェクトを正確に識別して削除できるようになります。
datetime lastBarTime = 0; datetime lastReqTime = 0; int retryCount = 0; int _digits; double tickSize; string objPrefix;
OnInitでの初期化
EAが起動すると、OnInit()が一度だけ実行され、入力値の検証(例:少なくとも2本のバーが要求されていることの確認)、銘柄プロパティ(SYMBOL_DIGITSやSYMBOL_POINT)のキャッシュ、および一意のオブジェクトプレフィックスの生成をおこないます。起動メッセージでは、POSTされるバーの本数とターゲットサーバーのURLがログに記録され、EAがポーリングサイクルを開始する準備が整ったことが確認されます。
int OnInit() { if(InpBufferBars < 2) return INIT_FAILED; _digits = (int)SymbolInfoInteger(_Symbol, SYMBOL_DIGITS); tickSize = SymbolInfoDouble(_Symbol, SYMBOL_POINT); objPrefix = StringFormat("SpikeEA_%I64d_", ChartID()); PrintFormat("[SpikeEA] Initialized: posting %d bars → %s", InpBufferBars, InpServerURL); return INIT_SUCCEEDED; }
OnDeinitでのクリーンアップ
EAが削除されたりシャットダウンされたりすると、OnDeinit()が実行され、チャート上のすべてのオブジェクトを逆順に走査し、名前がobjPrefixで始まるオブジェクトを削除します。これにより、EAの非アクティブ化後に不要な矢印やSL/TPラインがチャート上に残ることがなくなり、作業スペースをきれいに保つことができます。
void OnDeinit(const int reason) { for(int i = ObjectsTotal(0) - 1; i >= 0; --i) { string name = ObjectName(0, i); if(StringFind(name, objPrefix) == 0) ObjectDelete(0, name); } }
OnTickにおけるポーリングとペイロード構築
各ティックごとに、EAは新しいバーが形成されたかどうかを確認(PollOnNewBarOnlyが有効な場合)、前回のリクエストから最小間隔(MinSecsBetweenReq)が経過していることを確認します。その後、CopyRatesを使用して最後のInpBufferBars本のバーを取得し、時系列順に整列させ、BuildJSON()を呼び出して終値とタイムスタンプをJSONペイロードにシリアライズします。デバッグが有効な場合は、送信前に生のJSONがエキスパートログに出力されます。
void OnTick() { datetime barTime = iTime(_Symbol, _Period, 0); if(barTime == lastBarTime) return; lastBarTime = barTime; if(TimeCurrent() - lastReqTime < MinSecsBetweenReq) return; MqlRates rates[]; if(CopyRates(_Symbol, _Period, 0, InpBufferBars, rates) != InpBufferBars) return; ArraySetAsSeries(rates, true); string payload = BuildJSON(rates); if(DebugPrintJSON) PrintFormat("[SpikeEA] >>> %s", payload); SServerMsg msg; if(CallServer(payload, msg)) ActOnSignal(msg); lastReqTime = TimeCurrent(); }
BuildJSONでのJSON構築
ヘルパー関数BuildJSON()は、MqlRatesの配列を受け取り、銘柄名、終値の配列(正しい小数桁数でフォーマット済み)、および対応するUNIX形式のタイムスタンプ配列を含むコンパクトなJSON文字列を構築します。銘柄名に含まれる特殊文字に対応するために文字列エスケープが適用され、正しいJSON出力が保証されます。
string BuildJSON(const MqlRates &r[]) { string j = StringFormat("{\"symbol\":\"%s\",\"prices\":[", _Symbol); for(int i = 0; i < InpBufferBars; i++) j += DoubleToString(r[i].close, _digits) + (i+1<InpBufferBars?",":""); j += "],\"timestamps\":["; for(int i = 0; i < InpBufferBars; i++) j += IntegerToString(r[i].time) + (i+1<InpBufferBars?",":""); j += "]}"; return j; }
CallServerでのサーバー通信
CallServer()はJSON文字列をuchar[]バッファに変換し、その後WebRequest()を使用してInpServerURLにHTTPのPOSTを実行します。タイムアウトや200以外のステータスコードに対しては、MaxRetryまでの再試行ロジックが適用され、リクエストが失敗した場合はエラーが出力されます。成功した場合は、生のテキスト応答を取得し(オプションでログに記録)、その後ParseJSONLite()に渡して解釈します。
bool CallServer(const string &payload, SServerMsg &out) { uchar body[]; int len = StringToCharArray(payload, body, 0, WHOLE_ARRAY, CP_UTF8); ArrayResize(body, len); string hdr = "Content-Type: application/json\r\n"; uchar reply[]; string resp_hdr; int status = WebRequest("POST", InpServerURL, hdr, InpTimeoutMs, body, reply, resp_hdr); if(status <= 0) { PrintFormat("WebRequest error %d (retry %d/%d)", GetLastError(), retryCount+1, MaxRetry); ResetLastError(); if(++retryCount >= MaxRetry) retryCount = 0; return false; } retryCount = 0; string resp = CharArrayToString(reply); if(DebugPrintReply) PrintFormat("[SpikeEA] <<< HTTP %d – %s", status, resp); if(status != 200) return false; return ParseJSONLite(resp, out); }
ParseJSONLiteでの軽量JSON解析
ParseJSONLite()はフル機能のJSONライブラリを使用する代わりに、単純な文字列検索(StringFind)を用いて、「"signal":"BUY"」のようなキーワードや、「"conf":」、「"sl":」、「"tp":」といった数値キーを検出します。
bool ParseJSONLite(const string &txt, SServerMsg &o) { o.code = SIG_WAIT; o.conf = o.sl = o.tp = 0.0; if(StringFind(txt, "\"signal\":\"BUY\"") >= 0) o.code = SIG_BUY; if(StringFind(txt, "\"signal\":\"SELL\"") >= 0) o.code = SIG_SELL; if(StringFind(txt, "\"signal\":\"CLOSE\"") >= 0) o.code = SIG_CLOSE; // extract numeric values ParseJSONDouble(txt, "\"conf\":", o.conf); ParseJSONDouble(txt, "\"sl\":", o.sl); ParseJSONDouble(txt, "\"tp\":", o.tp); return true; }これらの部分文字列を抽出してSServerMsg構造体に変換し、EAのシグナルコード、信頼度値、ストップロス、テイクプロフィットレベルを設定します。
void ParseJSONDouble(const string &txt, const string &key, double &out) { int p = StringFind(txt, key); if(p >= 0) out = StringToDouble(StringSubstr(txt, p + StringLen(key))); }
ActOnSignalでのシグナル処理
新しいシグナルが到着すると、ActOnSignal()はまずobjPrefixに一致する以前の矢印やラインをすべてクリアします。次に、現在のBid値に新しい矢印を描画します。シグナルの種類に応じてアイコンコード、色、サイズを選択します。そして、もし有効になっていれば、水平のSLとTPラインおよびラベルも追加します。最後に、ライブ取引がオンになっている場合は、取引オブジェクトを使用してシグナルに従ってポジションを開閉します(Buy()、Sell()、PositionClose())。
void ActOnSignal(const SServerMsg &m) { static ESignal last = SIG_WAIT; if(m.code == SIG_WAIT || m.code == last) return; last = m.code; // remove old objects for(int i=ObjectsTotal(0)-1;i>=0;--i) if(StringFind(ObjectName(0,i),objPrefix)==0) ObjectDelete(0,ObjectName(0,i)); // draw arrow int arrow = (m.code==SIG_BUY ? 233 : m.code==SIG_SELL ? 234 : 158); color clr = (m.code==SIG_BUY ? ColorBuy : m.code==SIG_SELL ? ColorSell : ColorClose); string id = objPrefix + "Arr_" + TimeToString(TimeCurrent(),TIME_SECONDS); double y = SymbolInfoDouble(_Symbol, SYMBOL_BID); if(ObjectCreate(0,id,OBJ_ARROW,0,TimeCurrent(),y)) { ObjectSetInteger(0,id,OBJPROP_ARROWCODE,arrow); ObjectSetInteger(0,id,OBJPROP_COLOR,clr); ObjectSetInteger(0,id,OBJPROP_WIDTH,ArrowSize); PlaySound("alert.wav"); } // draw SL/TP lines if(DrawSLTPLines && m.sl>0) ObjectCreate(0,objPrefix+"SL_"+id,OBJ_HLINE,0,0,m.sl); if(DrawSLTPLines && m.tp>0) ObjectCreate(0,objPrefix+"TP_"+id,OBJ_HLINE,0,0,m.tp); // execute trade if(EnableTrading) { bool hasPos = PositionSelect(_Symbol); if(m.code==SIG_BUY && !hasPos) trade.Buy(FixedLots,_Symbol,0,m.sl,m.tp); if(m.code==SIG_SELL && !hasPos) trade.Sell(FixedLots,_Symbol,0,m.sl,m.tp); if(m.code==SIG_CLOSE&& hasPos) trade.PositionClose(_Symbol,SlippagePoints); } }
コンパイルとデプロイ
最終的に、EAコードをMetaEditorに貼り付け、Expertsフォルダに保存してF7キーを押します。「0 errors, 0 warnings」と表示されたことを確認したら、MetaTrader 5に戻り、ナビゲータで自分のEAを見つけ、チャートにドラッグします。ポップアップダイアログで入力パラメータを設定すると、[エキスパート]タブと[操作ログ]タブにJSON POST、解析されたシグナル、描画されたオブジェクト、および取引実行のリアルタイムログが表示されます。
Pythonでの実装
ファイルヘッダーと要件
engine.pyの冒頭には、Unixシバング(#!/usr/bin/env python3)と、バックエンドの機能を要約したコメントブロックを記述します。具体的には、ベクトル化された履歴の取り込み、CSVの正規化、Prophetのキャッシュ、学習、バックテスト、CLIモードなどです。また、必要な依存ライブラリをすべてインストールするpipコマンドも併記します。このヘッダーにより、スクリプトが何をするのか一目でわかるだけでなく、開発者がシステムをそのまま実行するために必要なライブラリの一覧も正確に確認できます。
#!/usr/bin/env python3 # engine.py – Boom/Crash/Vol-75 ML back-end # • vectorised /upload_history # • /upload_spike_csv # • Prophet cache (1h) # • robust CSV writer # • train() drops bad rows # • SL/TP with ATR or fallback # • backtest defaults to 30 days # • CLI: collect · history · train · backtest · serve · info # # REQS: pip install numpy pandas ta prophet cmdstanpy pykalman \ # scikit-learn flask MetaTrader5 joblib pytz
ユーザー構成可能な設定
ヘッダーの直後に、ターミナルのログイン情報(TERM_PATH、LOGIN、PASSWORD、SERVER)や、システムが処理するSYMBOLS配列の定数を定義します。また、ラベル付けの先読み制御(LOOKAHEAD、THRESH_LABEL)、ポーリング間隔(STEP_SECONDS)、取引開閉の閾値(THR_BC_OPEN、THR_O_OPEN、THR_O_CLOSE)、ATRベースのストップロス/テイクプロフィット倍率(ATR_PERIOD、SL_MULT、TP_MULT、ATR_FALLBACK_P)などのパラメータも設定します。これらの値を集中管理することで、ユーザーはコードのロジックに深く触れることなく、戦略のリスクパラメータ、データウィンドウ、シンボルリストを素早く調整できます。
TERM_PATH = r"" LOGIN = 123456 PASSWORD = "passwd" SERVER = "DemoServer" SYMBOLS = [ "Boom 900 Index", "Crash 1000 Index", "Volatility 75 (1s) Index" ] LOOKAHEAD = 10 # minutes THRESH_LABEL = 0.0015 # 0.15 % STEP_SECONDS = 60 # live collect interval ATR_PERIOD = 14 SL_MULT = 1.0 TP_MULT = 2.0 ATR_FALLBACK_P = 0.002
ファイルパスとCSVヘッダー
次に、ファイルシステム用の定数を設定します。BASE_DIRは解析のルートフォルダ、CSV_FILEは集約された学習データセット、MODEL_DIRはシンボルごとのモデルアーティファクト、GLOBAL_PKLは全体用モデルを指します。また、CSV_HEADERとして固定の列リストを定義し、書き込まれるすべての行が同じ12フィールドを持つようにします。このセクションにより、データの保存場所を標準化し、CSVの一貫性を確保することで、下流の学習や解析をスムーズにおこなえるようにしています。
BASE_DIR = r"C:\Analysis EA" CSV_FILE = rf"{BASE_DIR}\training_set.csv" MODEL_DIR = rf"{BASE_DIR}\models" GLOBAL_PKL = rf"{MODEL_DIR}\_global.pkl" CSV_HEADER = [ "timestamp","symbol","price","spike_mag","macd","rsi", "atr","slope","env_low","env_up","delta","label" ]
インポートとログ設定
まず、標準ライブラリ(os、sys、time、threadingなど)、データサイエンス用パッケージ(numpy、pandas、ta、joblib)、Prophetおよびカルマンフィルタモジュール、API用のFlask、MetaTrader 5 Pythonラッパーをインポートします。警告は見やすさのために抑制し、ログはタイムスタンプ、ログレベル、メッセージを人間が読みやすい形式で出力するよう設定します。最後に、モデルディレクトリの存在を確認し、作業ディレクトリをBASE_DIRに変更することで、すべての相対ファイル操作が既知の場所でおこなわれるようにしています。
import os,sys,time,logging,warnings,argparse,threading,io import datetime as dt from pathlib import Path import numpy as np, pandas as pd, ta, joblib, pytz from flask import Flask, request, jsonify, abort from prophet import Prophet from pykalman import KalmanFilter import MetaTrader5 as mt5 warnings.filterwarnings("ignore") logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)-7s %(message)s", datefmt="%H:%M:%S") Path(MODEL_DIR).mkdir(parents=True, exist_ok=True) os.chdir(BASE_DIR)
MetaTrader 5初期化ヘルパー
init_mt5()関数は、MetaTrader 5への接続を安全に初期化します。まずデフォルト呼び出しを試み、必要に応じてログイン情報を使用します。接続に失敗した場合は、エラーメッセージを表示して安全に終了します。ensure_symbol(sym)は、mt5.symbol_selectをラップしており、データ要求の前に各銘柄が有効になっていることを保証します。また、(_mt5_lock)というスレッドロックにより、MetaTrader 5へのマルチスレッド呼び出しを保護し、サーバーがバックグラウンドタスクを生成する際のスレッド安全性を維持します。
_mt5_lock = threading.Lock() def init_mt5(): if mt5.initialize(): return if not mt5.initialize(path=TERM_PATH, login=LOGIN, password=PASSWORD, server=SERVER): sys.exit(f"MT5 init failed {mt5.last_error()}") def ensure_symbol(sym): return mt5.symbol_select(sym, True)
Prophetキャッシュと予測デルタ
Prophetモデルをリクエストごとに再コンパイルしないよう、シンボルをキーとしてNone(コンパイル保留)または(model, timestamp)タプルを保持するスレッドセーフな辞書_PROPを管理します。_compile_prophet(df, sym)は、過去データに基づいて新しいProphetモデルを学習し、学習時刻を記録します。prophet_delta(prices, times, sym)はキャッシュを確認し、存在しないか古くなっている場合(1時間以上経過)、バックグラウンドでコンパイルを開始します。既に利用可能な場合は、1秒先の予測をおこない、予測デルタを返します。この設計により、予測処理が迅速におこなわれ、受信リクエストの処理をブロックしないようになっています。
_PROP_LOCK = threading.Lock()
_PROP = {} # sym -> (model, timestamp) or None
def _compile_prophet(df, sym):
mdl = Prophet(daily_seasonality=False, weekly_seasonality=False)
mdl.fit(df)
with _PROP_LOCK:
_PROP[sym] = (mdl, time.time())
def prophet_delta(prices, times, sym):
if len(prices) < 20: return 0.0
with _PROP_LOCK:
entry = _PROP.get(sym)
if entry is None:
_PROP[sym] = None
df = pd.DataFrame({"ds": pd.to_datetime(times, unit='s'),
"y": prices})
threading.Thread(target=_compile_prophet, args=(df, sym), daemon=True).start()
return 0.0
mdl, ts = entry
if time.time() - ts > 3600:
with _PROP_LOCK: _PROP[sym] = None
return 0.0
fut = mdl.make_future_dataframe(periods=1, freq='s')
return float(mdl.predict(fut).iloc[-1]["yhat"] - prices[-1])
特徴量ヘルパー関数
z_spike、macd_div、rsi_val、combo_spikeなどの小さな関数群を定義し、標準スコアのスパイク、MACDのダイバージェンス、RSI、そして複合的な「スパイクスコア」など、個別のテクニカルシグナルを計算します。各ヘルパー関数は計算前に十分な履歴データがあるかを確認し、データが不足している場合はデフォルト値を返します。これらの計算を分離することで、メインのデータ取り込みロジックをシンプルに保ち、各インジケーターのユニットテストも容易になります。
def z_spike(prices, win=20): if len(prices) < win: return False, 0.0 r = np.diff(prices[-win:]) z = (r[-1] - r.mean())/(r.std()+1e-6) return abs(z) > 2.5, float(z) def macd_div(prices): if len(prices) < 35: return 0.0 return float(ta.trend.macd_diff(pd.Series(prices)).iloc[-1]) def rsi_val(prices, l=14): if len(prices) < l+1: return 50.0 return float(ta.momentum.rsi(pd.Series(prices), l).iloc[-1]) def combo_spike(prices): _, z = z_spike(prices) m = macd_div(prices) v = prices[-1] - prices[-4] if len(prices) >= 4 else 0.0 s = abs(z) + abs(m) + abs(v)/(np.std(prices[-20:])+1e-6) return s > 3.0, s
CSV追記ヘルパーとgen_row
append_rows(rows)は、12要素のリストを受け取り、training_set.csvに書き込みます。最初の書き込み時にはヘッダー付きでファイルを作成し、それ以降は追記します。gen_row(i, closes, times, sym, highs=None, lows=None)は、1行分の学習データを生成します。価格履歴のインデックスiまでのデータをもとに特徴量を計算し(high/low配列が提供されていればATRやエンベロープバンドも含む)、prophet_deltaで予測を取得し、将来の価格変動に基づいて「BUY/SELL/WAIT」のラベルを割り当てます。行生成をデータ取り込みから分離することで、gen_rowはライブデータ取り込みでも過去データ取り込みでも再利用可能です。
def append_rows(rows): if not rows: return pd.DataFrame(rows, columns=CSV_HEADER)\ .to_csv(CSV_FILE, mode="a", index=False, header=not Path(CSV_FILE).exists()) def gen_row(i, closes, times, sym, highs=None, lows=None): if i < LOOKAHEAD or i+LOOKAHEAD >= len(closes): return None seq = closes[:i] _, mag = combo_spike(seq) atr = ta.volatility.average_true_range(pd.Series(highs[:i+1]), pd.Series(lows[:i+1]), pd.Series(seq)).iloc[-1] if highs else 0.0 row = [ times[i], sym, closes[i], mag, macd_div(seq), rsi_val(seq), atr, 0.0, 0.0, 0.0, prophet_delta(seq, times[:i], sym) ] ch = (closes[i+LOOKAHEAD] - closes[i]) / closes[i] row.append("BUY" if ch > THRESH_LABEL else "SELL" if ch < -THRESH_LABEL else "WAIT") return row
収集ループ(ライブデータ)
collect_loop()では、まずCSVファイルの存在を確認します。その後、無限ループに入り、各銘柄についてmt5.copy_rates_from_posで最新のLOOKAHEAD+1本のバーを取得し、タイムスタンプで重複をスキップした上でgen_rowを呼び出し、新しいラベル付き観測値を生成して追記します。STEP_SECONDSのスリープにより、制御されたポーリング間隔が維持されます。このライブデータループは、ユーザーが中断するまで、新しい観測値で学習セットを継続的に拡張していきます。
def collect_loop(): if not Path(CSV_FILE).exists(): append_rows([]) last = {} print("Collecting… CTRL-C to stop") init_mt5() while True: for sym in SYMBOLS: if not ensure_symbol(sym): continue bars = mt5.copy_rates_from_pos(sym, mt5.TIMEFRAME_M1, 0, LOOKAHEAD+1) if bars is None or len(bars) < LOOKAHEAD+1: continue if last.get(sym) == bars[-1]['time']: continue last[sym] = bars[-1]['time'] closes = bars['close'].tolist() times = bars['time'].tolist() row = gen_row(len(closes)-LOOKAHEAD-1, closes, times, sym) if row: append_rows([row]) time.sleep(STEP_SECONDS)
履歴データの取り込み(MetaTrader 5およびファイル)
history_from_mt5(sym, start, end)およびhistory_from_file(sym, path)は、MetaTrader 5に保存された履歴データやローカルファイルからCSVをバックフィルすることを可能にします。両関数とも、タイムスタンプ付きバーを順に処理し、gen_rowを呼び出して特徴量とラベルを生成し、行をバッチ(例:一度に5,000行)でまとめてappend_rowsで追記します。history_cli(args)ラッパーは、コマンドライン引数(--days、--from、--to、--file)を解析し、指定したシンボルや日付範囲に対してデータセット全体の取り込みを自動化します。
def history_from_mt5(sym, start, end): init_mt5() r = mt5.copy_rates_range(sym, mt5.TIMEFRAME_M1, start.replace(tzinfo=UTC), end.replace(tzinfo=UTC)) if r is None or len(r)==0: return closes, times = r['close'].tolist(), r['time'].tolist() highs, lows = r['high'].tolist(), r['low'].tolist() rows = [gen_row(i, closes, times, sym, highs, lows) for i in range(len(closes)-LOOKAHEAD) if gen_row(i, closes, times, sym, highs, lows)] append_rows([rw for rw in rows if rw]) print(sym, "imported", len(rows), "rows")
モデルの学習
train_models()はtraining_set.csvを読み込み、特徴量列を数値型に変換します(不正な行は削除されます)。その後、各銘柄のデータサブセットを順に処理し、少なくとも400行が存在する場合は、scikit‑learnのパイプライン(標準化 + 勾配ブースティング)を構築し、ラベル付きデータに対して学習させ、モデルを.pklファイルとして保存します。また、全銘柄を対象としたグローバルモデルも訓練、保存します。その結果、すぐに利用可能な分類器のディレクトリが作成されます。
def build_pipe(X, y): pipe = Pipeline([ ("sc", StandardScaler()), ("gb", GradientBoostingClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, random_state=42)) ]) return pipe.fit(X, y) def train_models(): df = pd.read_csv(CSV_FILE) df = df.dropna(subset=FEATURES) for sym in SYMBOLS: d = df[df.symbol == sym] if len(d) < 400: continue model = build_pipe(d[FEATURES], d.label.map({"WAIT":0,"BUY":1,"SELL":2})) joblib.dump(model, Path(MODEL_DIR)/f"{sym.replace(' ','_')}.pkl") global_model = build_pipe(df[FEATURES], df.label.map({"WAIT":0,"BUY":1,"SELL":2})) joblib.dump(global_model, GLOBAL_PKL)
Flaskサーバーエンドポイント
Flaskアプリを起動し、主に3つのルートを用意します。
/upload_history:JSON形式のバーのチャンクを解析し、gen_rowと同じ特徴量を計算して各行にラベルを付け、append_rowsを呼び出します。
/upload_spike_csv:生のEAログ(CSVテキストまたはJSON配列)を受け取り、12列形式に変換して追記します。
/analyze:load_model()で適切なモデルを読み込み、投稿された価格とタイムスタンプからライブ特徴量を計算し、クラス確率を予測します。その後、オープン/クローズ閾値を適用し、シグナル、信頼度、SL/TP、ポジションの強さを含むJSONオブジェクトを返します。
app = Flask(__name__) app.config["MAX_CONTENT_LENGTH"] = 32*1024*1024 @app.route("/upload_history", methods=["POST"]) def upload_history(): j = request.get_json(force=True) close, ts = np.array(j["close"]), np.array(j["time"],dtype=int) high = np.array(j.get("high", close)) low = np.array(j.get("low", close)) df = pd.DataFrame({"timestamp": ts, "price": close}) # compute features as in gen_row… append_rows(df.assign(symbol=j["symbol"]).values.tolist()) return jsonify(status="ok", rows_written=len(df)) @app.route("/upload_spike_csv", methods=["POST"]) def upload_spike_csv(): j = request.get_json(force=True) df_ea = pd.read_csv(io.StringIO(j.get("csv","")), sep=",") # map EA columns → CSV_HEADER append_rows(mapped_rows) return jsonify(status="ok", rows_written=len(mapped_rows)) @app.route("/analyze", methods=["POST"]) def api_analyze(): j = request.get_json(force=True) mdl = load_model(j["symbol"]) feats = [...] # compute from j["prices"], j["timestamps"] proba = mdl.predict_proba([feats])[0] signal = decide_open(proba[1], proba[2], j["symbol"]) # build sl, tp, manage _trades… return jsonify(signal=signal, sl=sl, tp=tp, strength=max(proba))
これらのエンドポイントは、MQL5 EAのデータ取り込み、バックフィル、リアルタイム意思決定を支えています。
バックテストおよび情報ユーティリティ
backtest_one(sym, df)は、オフラインの特徴量ヘルパーとモデル推論ロジックを再利用し、過去のDataFrame df上で取引をシミュレートします。ストップロス、テイクプロフィット、または早期クローズ条件が満たされた際に損益を記録します。backtest_cli(args)は、すべての銘柄にわたる結果を集計し、損益のサマリーを出力します。info()関数は、CSVの行数、ラベル分布、各モデルの特徴量数を報告するだけで、データの健康状態を手早く確認するのに便利です。
def backtest_one(sym, df): mdl = load_model(sym) for i in range(len(df)): feats = [...] # offline feature calcs pr = mdl.predict_proba([feats])[0] # open/close logic identical to /analyze return trades def info(): df = pd.read_csv(CSV_FILE) print("Rows:", len(df), "Labels:", df.label.value_counts()) for pkl in Path(MODEL_DIR).glob("*.pkl"): mdl = joblib.load(pkl) print(pkl.name, "features", mdl.named_steps["sc"].n_features_in_)
コマンドラインインターフェース
最後に、「if __name__ == "__main__"」ブロックでは、argparseを用いたCLIを定義しており、6つのサブコマンド(collect、history、train、backtest、serve、info)がそれぞれ対応する関数を呼び出します。このパターンにより、たとえば「python engine.py history --days 180」で過去6か月分のデータをバックフィルしたり、「python engine.py serve」でEA向けのライブAPIを起動したりと、1つの統合されたスクリプトで操作できます。
if __name__ == "__main__": parser = argparse.ArgumentParser() subs = parser.add_subparsers(dest="mode", required=True) subs.add_parser("collect") subs.add_parser("history") subs.add_parser("train") subs.add_parser("backtest") subs.add_parser("serve") subs.add_parser("info") args = parser.parse_args() if args.mode == "collect": init_mt5(); collect_loop() elif args.mode == "history": history_cli(args) elif args.mode == "train": train_models() elif args.mode == "backtest": backtest_cli(args) elif args.mode == "serve": init_mt5(); app.run("0.0.0.0", 5000, threaded=True) elif args.mode == "info": info()
Pythonでのモデル学習
MQL5の履歴取り込みルーチンやPython受信機を通じてCSVに十分な過去データが蓄積されたら、次のステップはモデルの学習です。まず、MQL5およびPythonスクリプトで定義したすべての銘柄のデータが取り込まれていることを確認します。データ取り込みが完了したら、以下の作業をおこないます。- 機械学習モデルの学習
- 過去期間におけるバックテストでの性能確認
- 学習済みモデルのライブ推論へのデプロイ
このステップでは、銘柄ごと(および1つのグローバルモデル)に勾配ブースティング分類器を学習させ、ルックアヘッド期間後の価格がBUY、SELL、WAITのどちらに該当するかを予測します。勾配ブースティングは、逐次的に決定木のアンサンブルを構築し、新しい木が前の木の誤差を修正していく手法です。これにより、ノイズの多い金融データに対しても頑健で、特徴量セット全体にわたる非線形パターンを捉えることができます。学習前には、特徴量を正規化するためにStandardScalerを用いてscikit‑learnのパイプラインでラップします。
# 3) TRAIN MODELS def build_pipe(X, y): """ Construct and fit a pipeline: StandardScaler → GradientBoostingClassifier. """ pipe = Pipeline([ ("sc", StandardScaler()), ("gb", GradientBoostingClassifier( n_estimators=400, # number of boosting rounds learning_rate=0.05, # shrinkage factor per tree max_depth=3, # depth of each tree random_state=42 # reproducibility )) ]) pipe.fit(X, y) return pipe def train_models(): """ Load the CSV, clean it, train per-symbol and global Gradient Boosting models, and save to disk. """ if not Path(CSV_FILE).exists(): sys.exit("No training_set.csv") # Read and sanitize df = pd.read_csv(CSV_FILE) if "symbol" not in df.columns: sys.exit("CSV missing 'symbol' column") # Ensure numeric features for col in FEATURES: df[col] = pd.to_numeric(df[col], errors="coerce") bad = df[FEATURES].isna().any(axis=1).sum() if bad: print(f"Discarding {bad} malformed rows") df = df.dropna(subset=FEATURES) # Train a Gradient Boosting model for each symbol for sym in SYMBOLS: d = df[df.symbol == sym] if len(d) < 400: print("Skip", sym, "(few rows)") continue model = build_pipe( d[FEATURES], d.label.map({"WAIT": 0, "BUY": 1, "SELL": 2}) ) joblib.dump(model, Path(MODEL_DIR) / f"{sym.replace(' ', '_')}.pkl") print("model", sym, "saved") # Train and save a global Gradient Boosting model global_model = build_pipe( df[FEATURES], df.label.map({"WAIT": 0, "BUY": 1, "SELL": 2}) ) joblib.dump(global_model, GLOBAL_PKL) print("global model saved")学習を実行するには、以下のコマンドを使用します。
python engine.py train学習ルーチンを実行した後、コンソールには次のような出力が表示されました。
C:\Users\hp\Pictures\Saved Pictures\Analysis EA>python engine.py train Discarding 1152650 malformed rows model Boom 900 Index saved model Boom 1000 Index saved model Boom 500 Index saved model Crash 500 Index saved model Boom 300 Index saved .................................... .................................... All models saved
学習が完了し、すべてのモデルが保存されたら次のステップに進む準備が整います。データ量によっては、保存に時間がかかる場合があります。学習済みモデルを過去データでバックテストすることもできますし、そのままデプロイに進むことも可能です。私の場合は、直接モデルのデプロイに進みました。この手順については次のセクションで説明します。
モデルのデプロイとリアルタイム推論
学習プロセスを終了するには、Ctrl+Cを押します。その後、リアルタイム推論サーバーを起動するには以下のコマンドを使用します。python engine.py serve
このコマンドにより、学習済みモデルがデプロイされ、ライブの取引シグナルの提供が開始されます。
MetaTrader 5では、学習済みモデルに対応する各銘柄にEAをアタッチします。次に、MetaTrader 5の[ツール] → [オプション] → [エキスパートアドバイザ]で[WebRequestを許可するURLリスト]にチェックを入れて、サーバーのアドレスを追加します。
HTTPステータスコード200は「OK」を意味します。つまり、リクエストが受信され、理解され、正常に処理されたことを示します。
ライブサーバーテスト中、各EAインスタンスはPythonバックエンドに正常に到達(HTTP 200)し、50ミリ秒未満で取引推奨を返しました。ログは以下の通りです。
Crash 1000 Index (M1)
At 00:31:59.717, the model reported a BUY probability of 0% and a SELL probability of 2.6%, yielding a combined confidence (strength) of just 3%.Since neither threshold was crossed, the EA correctly chose WAIT signal.
Boom 1000 Index (M1)
Just 37 ms later (at 00:31:59.754), this symbol’s model gave a BUY probability of 99.4% and SELL of 0%.That high confidence immediately triggered an OPEN BUY signal.
これらのログにより、デプロイメントパイプラインがエンドツーエンドで正常に機能していることが確認できます。
2025.07.30 00:31:59.717 Spike DETECTOR (Crash 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.0,"Psell":0.026,"scale_in":null ,"side":"NONE","signal":"WAIT","strength":0.03 2025.07.30 00:31:59.754 Spike DETECTOR (Boom 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.994,"Psell":0.0,"scale_in":null ,"side":"BUY","signal":"OPEN" , "strength":0.99
以前のテスト実行でも同様で、EAがエントリーシグナルを出すことがあります。これらの「OPEN」指示はMetaTrader 5のログに表示されますが、チャート上には矢印が描画されない場合があります。視覚的なマーカーが表示されるかどうかは、シグナルの強さに依存します。
MetaTrader 5ログ
2025.07.25 19:55:01.445 Spike DETECTOR (Boom 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.999,"Psell":0.0,"scale_in":null ,"side":"BUY","signal":"OPEN","strength":1.0
MetaTrader 5チャート
結論
MQL5とPythonを組み合わせることで、非常に強力かつ柔軟な取引フレームワークを構築しました。MQL5側では、EAがスパイク、MACDのダイバージェンス、RSI、ATR、カルマンフィルタ処理された傾き、Prophetデルタなどをシームレスに取得し、それらの指標を直接Pythonにストリームします。一方、Python側では、単一のengine.pyスクリプト(collect、history、train、backtest、serveコマンド対応)が、モデル学習とライブ配信の重い処理を担います。今回の構成では、MQL5 EAが必要なすべての特徴量データを提供してくれるため、実際に実行したのは以下のコマンドだけです。
python engine.py train python engine.py serve
collectやhistoryはスキップしました。EAがすでに完全なデータセットを維持し、提供してくれていたからです。
その結果、Serveを実行してわずか数瞬で、勾配ブースティングモデルはMetaTrader 5にリアルタイムのBUY/SELL/WAITシグナルを返します。1バーあたり50ミリ秒未満で返され、EAの注文ロジックで即座に処理可能です。MQL5ウェブサイトの豊富なドキュメントやコミュニティ例から学び始めた方でも、新しい特徴量生成器やアルゴリズムを組み込みたい経験豊富なクオンツの方でも、このエンドツーエンドのパイプラインは銘柄や戦略を問わずスケール可能です。
最後に、MQL5コミュニティとmql5.comで提供されている膨大なコードサンプルやフォーラムの知見に感謝します。これらのリソースのおかげで、統合が非常にスムーズにおこなえました。ぜひ皆さんも、ハイパーパラメータの調整、新しい指標の追加、あるいはPythonサーバーのコンテナ化などに挑戦してみてください。そして最も重要なのは、学んだことをコミュニティと共有し、データ駆動型アルゴリズム取引をみんなでさらに進化させていくことです。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/18985
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索