
取引におけるニューラルネットワーク:価格変動予測におけるマスクアテンションフリーアプローチ

はじめに
本稿では、引き続き点群処理手法を用いた研究を紹介します。前回の記事では、SPFormer法について解説しました。SPFormerの提案者は、Transformerアーキテクチャに基づく包括的なアルゴリズムを開発しました。Transformerデコーダの複数の層では、固定数のオブジェクトクエリを用いることで、大域的な特徴の反復処理と直接的なオブジェクト予測を実現しています。SPFormerでは、学習時に1対1の二部マッチング戦略を採用しており、重複排除のための後処理は不要です。さらに、最終層で生成されるオブジェクトマスクは、クロスアテンションのガイドとして機能します。
しかし、論文「Mask-Attention-Free Transformer for 3D Instance Segmentation」の著者は、現行のTransformerベースの手法が収束の遅さという課題を抱えていると指摘しています。ベースライン手法の分析により、この課題は初期マスクの品質の低さに起因している可能性があることが判明しました。具体的には、初期オブジェクトクエリと各点のマスク特徴との類似度をもとにマスクを生成する手法が、低品質の初期マスクを生み出し、それが学習の複雑化および収束の遅延につながっていると述べられています。
この問題に対処するため、著者らは新たなアルゴリズムであるMask-Attention-Free Transformer (MATF)を提案しました。MAFTでは従来のマスクアテンション設計を廃止し、代わりにクロスアテンションを誘導する補助的な中心回帰タスクを導入しています。中心回帰を実現するために、著者らは点群の位置情報を活用する一連のコンポーネントを開発しました。まず、各コンテンツクエリに対応する位置を表す学習可能な位置クエリを導入しています。これらの位置クエリは学習空間全体にわたって密に分布しており、各クエリが局所領域に集中できるよう制約が課されています。その結果、各クエリはシーン内のオブジェクトをより特徴的かつ効果的に捉えることができ、これにより学習の複雑さが軽減され、収束が加速されます。
さらに、MATFの著者らはクロスアテンションのためのコンテキスト相対位置エンコーディングも提案しています。従来の手法で使われていたアテンションマスクと比べて、これはより柔軟な設計となっており、アテンションの重みが固定されたマスクではなく、相対的な位置関係に基づいて調整されます。クエリ位置は反復的に更新されることで、より精度の高い表現が可能となります。
本論文で示された実験結果は、MATFがさまざまなデータセットにおいて優れた性能を発揮することを裏付けています。
1. MATFアルゴリズム
SPFormerアルゴリズムは、オブジェクトクエリによってインスタンス予測を直接生成する、完全なエンドツーエンドのパイプラインを表しています。Transformerデコーダを使用することで、一定数のオブジェクトクエリが解析された点群から大域的なオブジェクト情報を集約します。さらに、SPFormerはオブジェクトマスクを活用してクロスアテンションをガイドし、クエリがマスクされた特徴のみに注意を向けるようにします。しかし、学習の初期段階では、これらのマスクの品質が低く、それが後続層での性能を妨げ、全体的な学習の複雑さを増加させます。。
この問題に対処するために、MAFT法の著者らは、インスタンスセグメンテーションをガイドする補助的な中心回帰タスクを導入しています。まず、生の点群から大域的な位置𝒫が選択され、バックボーンネットワークを介して大域的なオブジェクト特徴ℱが抽出されます。これらはボクセルやスーパーポイントで構成される場合があります。コンテンツクエリ𝒬0cに加えて、MAFTの著者らは、正規化されたオブジェクト中心を表す固定数の位置クエリ𝒬0pを導入しています。𝒬0pはランダムに初期化され、𝒬0cはゼロ値から開始されます。主な目的は、位置クエリがクロスアテンション内で対応するコンテキストクエリをガイドできるようにし、その後、両方のクエリセットを反復的に洗練することで、オブジェクトの中心、クラス、およびマスクを予測することです。
オブジェクト中心回帰タスクを効果的に解決し、初期オブジェクトマスクの生成を改善するために、MAFTの著者らは点の位置情報を考慮に入れた一連のアーキテクチャコンポーネントを提案しています。
従来のアプローチとは異なり、位置クエリの追加セット𝒬0pが導入されています。点群における点の範囲はシーンによって大きく異なるため、初期位置クエリは正規化された形で学習可能なパラメータとして格納され、シグモイド活性化関数を通して出力されます。
特筆すべき点として、これらの初期位置クエリはターゲット空間全体に密に分布しており、それぞれのクエリは対応する局所領域からオブジェクトを集約します。この設計により、初期クエリがシーン内のオブジェクトを高い再現率で捉えることが可能になり、品質の低い初期インスタンスマスクによって引き起こされる記憶性の低下問題を緩和し、後続層での学習の複雑さを軽減します。
MAFTは、絶対的な位置エンコーディングに加えて、クロスアテンションメカニズムにおいてコンテキスト相対位置エンコーディングを採用しています。これを実現するために、位置クエリ𝒬tpと大域的な位置𝒫の間の相対位置𝐫がまず計算され、その後離散化されて整数の𝐫'に量子化されます。これらの離散相対位置は、位置エンコーディングテーブルから対応する値を取得するためのインデックスとして使用されます。
次に、相対位置エンコーディング𝐟posは、クロスアテンションモジュール内でQuery特徴量𝐟qまたはKey特徴量𝐟kと乗算され、その結果がクロスアテンションの重みに加算され、最後にSoftmax関数が適用されます。
相対位置エンコーディングは、従来のマスク付きアテンションと比べて柔軟性と誤差に対する堅牢性が高い点で注目に値します。本質的には、厳格なマスキングを適用するのではなく、アテンションの重みを柔軟に調整するソフトマスクとして機能します。さらに、意味的情報を統合し、局所コンテキストを選択的に捉えることができます。これは、相対位置と意味特徴との相互作用によって実現されます。
デコーダ層のコンテキストクエリは継続的に更新されるため、デコード全体を通して位置クエリを固定のままにするのは最適とは言えません。初期位置クエリが静的であることを踏まえ、後続層ではそれらを入力シーンに適応させることが有効です。そのために、著者らはコンテンツクエリに基づいて位置クエリを繰り返し改良します。具体的には、MLPを用いて更新されたコンテキストクエリト𝒬t+1cから中心オフセットΔptを予測し、これを前の位置クエリ𝒬tpに加算します。
上記の論文におけるMAFT法のオリジナルな可視化を以下に示します。

2.MQL5での実装
Mask-Attention-Free Transformer法の理論的側面について確認した後は、本稿の実用的な部分に移り、MQL5を使用して、提案するアプローチのビジョンを実装します。まず、OpenCLプログラムを拡張することから始めます。
2.1 OpenCLプログラムの拡張
まず、相対位置エンコーディングアルゴリズムの構築から始めます。一方で、このアルゴリズムは比較的単純です。必要なのは、2点間の距離を計算することだけです。さらに、著者らは各座標軸に沿った距離を個別に計算しています。他方で、MAFTの著者らは得られたオフセットを量子化し、その結果を用いて学習可能なパラメータテーブルにインデックスを付ける処理をおこなっています。私たちは、元の手法をわずかに最適化することを選びました。私たちの実装は、分析対象となるクエリの近傍に位置する点が最大の影響を与えるという仮定に基づいています。このロジックに従い、まずN次元空間内の2点間の距離Sを計算します。次に、以下の式を用いて位置バイアス係数kpbを算出します。

任意の2点間の距離が常に0以上であることは明白です。もし2点が一致する場合、係数は1となります。距離が大きくなるにつれて、相対位置エンコーディング係数は0に近づきます。
提案されたアルゴリズムの実装は、CalcPositionBiasカーネル内にて提供されています。カーネルのパラメータには、3つのグローバルデータバッファへのポインタが含まれており、そのうち2つは入力データ、残りの1つは結果の保存に用いられます。さらに、単一要素の特徴量ベクトルの次元数も指定します。
なお、2つのベクトル間の距離を正確に計算するためには、それらを同じ部分空間に射影する必要があることに注意してください。つまり、両方の入力テンソルに含まれる特徴量ベクトルは、同一の次元数でなければなりません。
__kernel void CalcPositionBias(__global const float *data1, __global const float *data2, __global float *result, const int dimension ) { const size_t idx1 = get_global_id(0); const size_t idx2 = get_global_id(1); const size_t total1 = get_global_size(0); const size_t total2 = get_global_size(1);
私たちは、カーネルを2次元のタスク空間で起動する予定です。各次元のタスク数は、元データの対応するテンソルの要素数と等しくなります。カーネルの本体では、すぐに現在のスレッドをタスク空間の両次元で特定します。
次のステップでは、データバッファへのオフセットを決定します。
const int shift1 = idx1 * dimension; const int shift2 = idx2 * dimension; const int shift_out = idx1 * total2 + idx2;
準備段階が完了したら、計算の実行に進みます。ここでは、まず、分析されたベクトル間の距離を計算するためのループを構成します。
float res = 0; for(int i = 0; i < dimension; i++) res = pow(data1[shift1 + i] - data2[shift2 + i], 2.0f); res = sqrt(res);
そして相対バイアス係数を計算します。
res = 1.0f / exp(res); if(isnan(res) || isinf(res)) res = 0; //--- result[shift_out] = res; }
次に、計算した値を結果バッファの対応する要素に書き込みます。
得られた係数はどれも負ではないことに注意してください。これは、入力シーケンス内のどの要素もマスクしないことを意味します。逆に、私たちの実装では、クエリに空間的に最も近い要素を強調します。
この段階で、相対的な位置バイアス係数を計算しました。次のステップは、それらをクロスアテンションメカニズムに統合することです。ただし、実装に進む前に、重要な詳細に注目していただきたいと思います。上に示したMAFT法の著者らによる可視化図をよくご覧ください。特にシーン表現情報の流れに注目してください。注目すべきは、シーン表現内での位置エンコーディングに対する著者のアプローチです。具体的には、位置エンコーディングはKeyエンティティにのみ適用されます。Valueエンティティには適用されていません。これは、アテンションの重みを位置情報を踏まえて計算しつつ、シーン要素の実際の特徴は歪めないための意図的な設計と思われます。そのため、KeyとValueのテンソルは別々に生成する必要があります。具体的には、まず生の入力からValueを生成し、次に元データに位置エンコーディングを加えてKeyを作成します。
なぜこの点を強調するのかというと、この設計方針によりKeyとValueは別テンソルとして扱わねばならず、これに対応した新たなアテンションカーネルを設計できるからです。この方法により、従来必要だったテンソルの連結処理も不要になります。
アテンションアルゴリズムの実装には、MHPosBiasAttentionOutというカーネルを用意しました。このカーネルは、多数のグローバルデータバッファを受け入れますが、その多くはこれまでの実装で馴染みのあるものです。さらに、相対位置バイアスインデックスpos_biasのバッファへのポインタも渡します。また、このカーネルは位置バイアスなしの標準的なアテンション計算もオプションでサポートし、use_pos_biasパラメータで切り替え可能です。
__kernel void MHPosBiasAttentionOut(__global const float *q, ///<[in] Matrix of Querys __global const float *k, ///<[in] Matrix of Keys __global const float *v, ///<[in] Matrix of Values __global float *score, ///<[out] Matrix of Scores __global const float *pos_bias, ///<[in] Position Bias __global float *out, ///<[out] Matrix of attention const int dimension, ///< Dimension of Key const int heads_kv, const int use_pos_bias ) { //--- const int q_id = get_global_id(0); const int k_id = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
これまでと同様に、このカーネルは三次元のタスク空間で実行する予定です。最初の二つの次元は、解析対象のシーケンス内の要素数を表し、三つ目の次元は使用するアテンションヘッドの数を示します。カーネルアルゴリズムは、まずこの三次元タスク空間における現在のスレッド位置を特定するところから始まります。
次に、必要な定数をすべて定義します。
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_kv = dimension * (heads_kv * k_id + h_kv); const int shift_s = kunits * (q_id * heads + h) + k_id; const int shift_pb = q_id * kunits + k_id; const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
そして次に、ローカルグループ内のスレッド間でデータをやり取りするためのローカルメモリ上のデータ配列を作成します。
__local float temp[LOCAL_ARRAY_SIZE];
これで準備作業の段階は完了し、いよいよ計算処理に入ります。計算プロセスは大部分が従来のアルゴリズムを踏襲していますが、必要に応じて相対位置バイアスを追加します。その使用の有無は、use_pos_biasパラメータの値によって制御されます。
まず、アテンション係数の指数値の合計を計算します。最初の段階では、ローカルグループ内の各スレッドが自分の担当部分を計算し、その結果をローカルデータ配列の対応する要素に保存します。
//--- sum of exp uint count = 0; if(k_id < ls) { temp[k_id] = 0; do { if(q_id >= (count * ls + k_id)) if((count * ls) < (kunits - k_id)) { float sum = 0; int sh_k = dimension * heads_kv * count * ls; for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * k[shift_kv + d + sh_k]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; temp[k_id] = temp[k_id] + sum + (use_pos_bias > 0 ? pos_bias[shift_pb + count * ls] : 0); } count++; } while((count * ls + k_id) < kunits); } barrier(CLK_LOCAL_MEM_FENCE);
計算する合計には位置バイアス係数の合計を含める必要があることに注意してください。
次に、ローカル配列の要素の値を合計します。
count = min(ls, (uint)kunits); //--- do { count = (count + 1) / 2; if(k_id < ls) temp[k_id] += (k_id < count && (k_id + count) < kunits ? temp[k_id + count] : 0); if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
合計を計算した後、位置バイアス係数を考慮して依存係数の正規化された値を決定し、保存します。
//--- score float sum = temp[0]; float sc = 0; if(q_id >= (count * ls + k_id)) if(sum != 0) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * k[shift_kv + d]; sc = (exp(sc / koef) + (use_pos_bias > 0 ? pos_bias[shift_pb] : 0)) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
得られたアテンション係数により、分析されたシーケンスの各要素に対するマルチヘッドアテンションの最終値を計算できます。
//--- out for(int d = 0; d < dimension; d++) { uint count = 0; if(k_id < ls) do { if((count * ls) < (kunits - k_id)) { int sh_v = 2 * dimension * heads_kv * count * ls; float sum = v[shift_kv + d + sh_v] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; temp[k_id] = (count > 0 ? temp[k_id] : 0) + sum; } count++; } while((count * ls + k_id) < kunits); barrier(CLK_LOCAL_MEM_FENCE); //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k_id < ls) temp[k_id] += (k_id < count && (k_id + count) < kunits ? temp[k_id + count] : 0); if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
次に、MHPosBiasAttentionInsideGradientsカーネル内にバックプロパゲーションアルゴリズムを実装します。まず再確認しておきたいのは、誤差勾配を加算演算を通じて伝播する際、通常は勾配が両方の被加数にそのまま伝播されるという点です。学習率が1よりも十分に小さい場合、このような誤差の「重複カウント」は実質的に問題とはなりません。もう一点重要なのは、相対位置バイアス係数の計算が、点の実際の空間的配置のみに基づいているということです。これはすなわち、モデルの学習可能なパラメータの影響を受けないということです。計算処理そのものには、学習されるパラメータが一切含まれていません。したがって、相対位置バイアス係数のテンソルに対して勾配を伝播するのは理にかなっていないため、このステップをバックプロパゲーションプロセスから除外します。
これらの考慮事項を踏まえ、アテンションブロックに対して古典的な勾配分布アプローチに到達しました。しかし、前述の通り、KeyとValueエンティティを別々のデータバッファに分離したため、新しいカーネルを開発しました。添付ファイルにあるMHPosBiasAttentionInsideGradientsのバックプロパゲーションカーネルの実装を確認してください。これで、OpenCLコンポーネントに関する作業は終了です。
2.2 MAFTクラスの作成
作業の次の段階では、Mask-Attention-Free Transformer (MAFT)手法に関して、提案者の意図を私たちなりに解釈し、それをカプセル化した新しいオブジェクトを作成します。そのために、CNeuronMAFTという新しいクラスを導入します。
MAFTアルゴリズムは、先に述べたSPFormerアーキテクチャを基盤としています。同様に、私たちの実装でもCNeuronSPFormerクラスによって築かれた基礎を活用します。ただし、今回必要となる変更の規模と範囲を考慮すると、そのクラスから継承するのは現実的ではありません。したがって、新しいオブジェクトは、基本となる全結合層クラスCNeuronBaseOCLを直接継承する形となります。新クラスの構造は以下のとおりです。
class CNeuronMAFT : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint iHeads; uint iSPWindow; uint iSPUnits; uint iSPHeads; uint iWindowKey; uint iLayers; uint iLayersSP; //--- CLayer cSuperPoints; CLayer cQuery; CLayer cQPosition; CLayer cQKey; CLayer cQValue; CLayer cMHSelfAttentionOut; CLayer cSelfAttentionOut; CLayer cSPKey; CLayer cSPValue; CArrayInt cScores; CArrayInt cPositionBias; CLayer cMHCrossAttentionOut; CLayer cCrossAttentionOut; CLayer cResidual; CLayer cFeedForward; CBufferFloat cTempSP; CBufferFloat cTempQ; CBufferFloat cTempCrossK; CBufferFloat cTempCrossV; //--- virtual bool CreateBuffers(void); virtual bool CalcPositionBias(CBufferFloat *pos_q, CBufferFloat *pos_k, const int pos_bias, const int units, const int units_kv, const int dimension); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int pos_bias, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const bool use_pos_bias); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *k, CNeuronBaseOCL *v, const int scores, CNeuronBaseOCL *out, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMAFT(void) {}; ~CNeuronMAFT(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMAFT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
提示された構造には、よく知られたオーバーライド可能な仮想メソッド群と、多数の内部オブジェクトが含まれていることが分かります。内部コンポーネントの中には、これまでに使用されたものと共通するものもあれば、完全に新規のものもあります。CNeuronMAFTクラスのメソッドを実装していく中で、それぞれの機能について順を追って理解していくことになります。
従来と同様に、すべての内部オブジェクトは静的に宣言されているため、クラスのコンストラクタおよびデストラクタは空のままにしておくことが可能です。継承されたコンポーネントと新たに宣言されたコンポーネントの初期化は、Initメソッド内でおこなわれます。
bool CNeuronMAFT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
このメソッドのパラメータには、作成されるオブジェクトのアーキテクチャを定義する重要な定数が含まれています。ここで注目すべき点は、これらのパラメータがCNeuronSPFormerクラスの対応するメソッドから完全に流用されていることです。これは、私たちが採用している継承ベースの設計方針と一致しています。ただし、メソッドの実際のロジックについては、大きな変更は加えられていません。
メソッド本体では、まず親クラスの同名メソッドを呼び出します。この呼び出しにより、受け取ったパラメータに対する基本的な処理がおこなわれ、継承されたオブジェクトの初期化が実施されます。その後、得られた定数を本クラスの内部変数として保存します。
iWindow = window; iUnits = units_count; iHeads = heads; iSPUnits = units_sp; iSPWindow = window_sp; iSPHeads = heads_sp; iWindowKey = window_key; iLayers = MathMax(layers, 1); iLayersSP = MathMax(layers_to_sp, 1);
次のステップは、オブジェクト用の学習可能なクエリおよびその位置エンコーディングを生成するためのオブジェクトを初期化することです。MAFT法の提案者は、クエリをゼロ値で初期化することを提案しています。私たちも同様の方法を採用することができます。そのために、クエリ生成用のパラメータをリセットします。
CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iWindow * iUnits, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; buf = base.getWeights(); if(!buf || !buf.BufferInit(buf.Total(), 0) || !buf.BufferWrite()) return false; if(!cQuery.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base || !base.Init(0, 1, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cQuery.Add(base)) return false;
また、ランダムな値で初期化された学習可能な位置エンコーディングも追加します。
CNeuronLearnabledPE *pe = new CNeuronLearnabledPE(); if(!pe || !pe.Init(0, 2, OpenCL, base.Neurons(), optimization, iBatch)) return false; if(!cQuery.Add(pe)) return false;
位置コーディングは、MAFTアルゴリズム全体を通じて独立した情報の流れとして扱われることを述べておく必要があります。したがって、これを別個のオブジェクトとして提供します。
if(!base || !base.Init(0, 3, OpenCL, pe.Neurons(), optimization, iBatch)) return false; if(!base.SetOutput(pe.getOutput())) return false; if(!cQPosition.Add(base)) return false;
次の段階は一次データ処理です。ここでは、SPFormer法で提案されたスーパーポイントアプローチを取り入れます。
//--- Init SuperPoints int layer_id = 4; for(int r = 0; r < 4; r++) { if(iSPUnits % 2 == 0) { iSPUnits /= 2; CResidualConv *residual = new CResidualConv(); if(!residual) return false; if(!residual.Init(0, layer_id, OpenCL, 2 * iSPWindow, iSPWindow, iSPUnits, optimization, iBatch)) return false; if(!cSuperPoints.Add(residual)) return false; } else { iSPUnits--; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, layer_id, OpenCL, 2 * iSPWindow, iSPWindow, iSPWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; } layer_id++; }
ここで注意すべき点は、提示された実装が異なる次元のテンソルをクロスアテンションに使用できるようになっていることです。しかし、相対位置オフセット係数の提案アルゴリズムではこれは許容されません。したがって、学習可能なクエリ空間に対してスーパーポイント射影層を追加します。
CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, layer_id, OpenCL, iSPWindow, iSPWindow, iWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; layer_id++;
次に、位置エンコーディングの層を追加します。
pe = new CNeuronLearnabledPE(); if(!pe || !pe.Init(0, layer_id, OpenCL, conv.Neurons(), optimization, iBatch)) return false; if(!cSuperPoints.Add(pe)) return false; layer_id++;
この時点で、MAFT法の提案者が示した元のアルゴリズムから若干逸脱していることに注意してください。彼らの研究では、元の座標に基づく点群のボクセル化を採用していました。これに対して、私たちは完全に学習可能な位置エンコーディングを用いることで、モデル自身が入力シーケンスの各要素の最適な位置を学習できるようにしています。
ソースデータの一次処理が完了した後、デコーダの内部層を順に処理するループを構成します。
//--- Inside layers for(uint l = 0; l < iLayers; l++) { //--- Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; layer_id++;
ここで注意すべき点は、MAFTの提案者は従来の構成である「自己アテンション->クロスアテンション->フィードフォワード」を採用していることです。しかし、SPFormer法の著者は、自己アテンションとクロスアテンションの順序を入れ替えています。
まず、Queryエンティティを生成し、その後にKeyとValueを追加します。
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQKey.Add(conv)) return false; layer_id++; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQValue.Add(conv)) return false; layer_id++;
この場合、学習可能なクエリの数は少数を想定しています。したがって、Key-Valueのヘッド数を減らさず、各内部層で新しいエンティティを生成します。
生成したエンティティは、位置バイアス係数を用いることなくマルチヘッドアテンションブロックに渡します。
//--- Multy-Heads Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch)) return false; if(!cMHSelfAttentionOut.Add(base)) return false; layer_id++;
マルチヘッドアテンションの結果をスケーリングする層を追加します。
//--- Self-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cSelfAttentionOut.Add(conv)) return false; layer_id++;
自己アテンションブロックの最後に、従来のTransformerアルゴリズムに従って、残差接続層を追加します。
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; layer_id++;
次に、クロスアテンションブロックのオブジェクトを構築します。Queryエンティティテンソルから始めます。
//--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; layer_id++;
次に、KeyとValueエンティティのテンソルを追加します。今回はユーザーの指示に従って、アテンションヘッドを減らして層を交互に配置します。
if(l % iLayersSP == 0) { //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPKey.Add(conv)) return false; layer_id++; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPValue.Add(conv)) return false; layer_id++; }
マルチヘッドアテンションからの結果の層を追加します。
//--- Multy-Heads Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch)) return false; if(!cMHCrossAttentionOut.Add(base)) return false; layer_id++;
その後、残差接続を追加することでスケールされます。
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cCrossAttentionOut.Add(conv)) return false; layer_id++; //--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; layer_id++;
デコーダはFeedForwardブロックによって完成し、これに残差接続も追加されます。
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; layer_id++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false; layer_id++; //--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient())) return false; if(!cResidual.Add(base)) return false; layer_id++;
後は、学習可能なクエリの位置エンコーディングのMLP修正を追加するだけです。
//--- Delta position conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindow, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(SIGMOID); if(!cQPosition.Add(conv)) return false; layer_id++; base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, conv.Neurons(), optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient())) return false; if(!cQPosition.Add(base)) return false; layer_id++; }
次に、ループの次の反復に進み、デコーダの新しい内部層のオブジェクトを作成します。
デコーダのすべての内部層のオブジェクトの初期化が正常に完了したら、誤差勾配バッファへのポインタを置き換え、呼び出し元プログラムに成功を示すブール値の結果を返します。
base = cResidual[iLayers * 3 - 1]; if(!SetGradient(base.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
補助データバッファの初期化は別のメソッドであるCreateBuffersに移されていることを付け加えておきます。このメソッドについては、ご自身で確認されることをおすすめします。
このクラスおよび全メソッドの完全な実装は添付ファイルにあります。
内部オブジェクトの初期化が完了した後、feedForwardメソッドでフィードフォワード処理のアルゴリズム構築に移ります。このメソッドのパラメータとして、ソースデータオブジェクトへのポインタを受け取ります。
bool CNeuronMAFT::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Superpoints CNeuronBaseOCL *superpoints = NeuronOCL; int total_sp = cSuperPoints.Total(); for(int i = 0; i < total_sp; i++) { if(!cSuperPoints[i] || !((CNeuronBaseOCL*)cSuperPoints[i]).FeedForward(superpoints)) return false; superpoints = cSuperPoints[i]; }
生成されたオブジェクトはすぐにスーパーポイント特徴量の生成に使用します。そのために、ネストされたモデルであるcSuperPointsを利用します。
このモデルの最終層は位置エンコーディング層です。
次に、位置エンコーディングを付加した学習可能なクエリを生成します。
//--- Query CNeuronBaseOCL *inputs = NULL; for(int i = 0; i < 2; i++) { inputs = cQuery[i + 1]; if(!inputs || !inputs.FeedForward(cQuery[i])) return false; }
次に、オブジェクトへのポインタを一時的に保存するためのローカル変数を作成します。
CNeuronBaseOCL *query = NULL, *key = NULL, *value = NULL, *base = NULL;
デコーダの内部層を通るループを構成します。
//--- Inside layers for(uint l = 0; l < iLayers; l++) { //--- Self-Atention query = cQuery[l * 2 + 3]; if(!query || !query.FeedForward(inputs)) return false; key = cQKey[l]; if(!key || !key.FeedForward(inputs)) return false; value = cQValue[l]; if(!value || !value.FeedForward(inputs)) return false;
ここではまず、位置エンコーディングを使用した学習可能なクエリに対する自己アテンションブロックの操作を整理します。これをおこなうには、まず必要なエンティティを生成し、それをマルチヘッドアテンションブロックに渡します。
if(!AttentionOut(query, key, value, cScores[l * 2], cMHSelfAttentionOut[l], -1, iUnits, iHeads, iUnits, iHeads, iWindowKey, false)) return false;
次に、得られた結果をスケーリングし、残差接続を追加します。
base = cSelfAttentionOut[l]; if(!base || !base.FeedForward(cMHSelfAttentionOut[l])) return false; value = cResidual[l * 3]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
別のスレッドとして、位置コーディングを追加します。
value = cQPosition[l * 2]; if(!value || !SumAndNormilize(inputs.getOutput(), value.getOutput(),inputs.getOutput(), iWindow, false, 0, 0, 0, 1)) return false;
その後、クロスアテンションブロックに進みます。しかし、まずは相対的な位置バイアスの係数を定義しましょう。
//--- Calc Position bias if(!CalcPositionBias(value.getOutput(), ((CNeuronLearnabledPE*)superpoints).GetPE(), cPositionBias[l], iUnits, iSPUnits, iWindow)) return false;
次に、位置エンコーディングを考慮して、位置クエリテンソルからQueryエンティティを生成します。
//--- Cross-Attention query = cQuery[l * 2 + 4]; if(!query || !query.FeedForward(inputs)) return false;
KeyおよびValueエンティティの操作には多くの細かい注意点があります。まず、新しいテンソルは必要な場合にのみ生成されます。
key = cSPKey[l / iLayersSP]; value = cSPValue[l / iLayersSP]; if(l % iLayersSP == 0) { if(!key || !key.FeedForward(superpoints)) return false; if(!value || !value.FeedForward(cSuperPoints[total_sp - 2])) return false; }
次に、位置エンコーディングを含む最後のcSuperPoints層のデータからKeyエンティティが生成されます。Valueを生成するには、位置エンコーディングを持たない最後から2番目の層を使用します。
位置バイアス係数を使用せずに、結果のエンティティをマルチヘッドアテンションブロックに渡します。
if(!AttentionOut(query, key, value, cScores[l * 2 + 1], cMHCrossAttentionOut[l], cPositionBias[l], iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey, true)) return false;
その後、取得したデータをスケーリングし、残差接続を追加します。
base = cCrossAttentionOut[l]; if(!base || !base.FeedForward(cMHCrossAttentionOut[l])) return false; value = cResidual[l * 3 + 1]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
デコーダの最後に、データをFeedForwardブロックに渡し、その後に残差接続を渡します。
//--- Feed Forward base = cFeedForward[l * 2]; if(!base || !base.FeedForward(inputs)) return false; base = cFeedForward[l * 2 + 1]; if(!base || !base.FeedForward(cFeedForward[l * 2])) return false; value = cResidual[l * 3 + 2]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
この段階で、1つのデコーダ層の操作は完了していますが、学習可能なクエリの位置エンコーディングデータをまだ調整する必要があります。これをおこなうには、受信したデータに基づいて位置偏差を生成し、それを既存の値に追加します。
//--- Delta Query position base = cQPosition[l * 2 + 1]; if(!base || !base.FeedForward(inputs)) return false; value = cQPosition[(l + 1) * 2]; query = cQPosition[l * 2]; if(!value || !SumAndNormilize(query.getOutput(), base.getOutput(), value.getOutput(), iWindow, false, 0,0,0,0.5f)) return false; }
次に、次のデコーダ内部層の処理へ進みます。
デコーダの全内部層の処理が正常に完了すると、強化されたクエリとその洗練された位置情報という形で結果を得られます。これら2つのテンソルを合算し、予測ヘッドへ渡します。
value = cQPosition[iLayers * 2]; if(!value || !SumAndNormilize(inputs.getOutput(), value.getOutput(), Output, iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
このメソッドは、初期化処理の成功・失敗を示すブール値を返します。
これでフィードフォワードパスの実装は完了です。次に、calcInputGradientsメソッドとupdateInputWeightsメソッドに実装されているバックプロパゲーションアルゴリズムの開発に進みます。前者は、最終出力への寄与度に応じて誤差勾配を全内部コンポーネントへ分配する役割を担い、後者はモデルパラメータの更新をおこないます。
ご存知の通り、勾配の分配はフィードフォワードパスの情報フローとは厳密に逆順で実行されます。これらのメソッドの実装については、ご自身で調べてみることをお勧めします。
このクラスおよび全メソッドの完全な実装は添付ファイルにあります。
また、本記事で使用しているモデルのアーキテクチャや、環境との訓練およびインタラクションに関わるすべてのプログラムは、以前の研究から全面的に流用したものです。実際、環境状態をエンコードする部分で加えた唯一の変更は、単一層の識別子を変更した点のみであるため、ここでは詳細な検討はおこないません。この記事の作成に使用したすべてのプログラムクラスの完全なコードも添付ファイルに含まれています。
3.テスト
本記事では、MAFT法に触れ、その提案手法をMQL5で実装しました。ここからは、実装結果の評価に移ります。モデルはMAFTフレームワークを用いて実際の過去データで学習をおこない、その後、学習済みのActor方策をテストします。
これまでと同様に、モデルの訓練にはEURUSDの実際の履歴データ(H1時間枠、2023年全期間)を使用します。すべてのインジケーターのパラメータはデフォルト値のままとしています。
モデルの訓練手順と関連ツールは、以前の記事から引き継がれました。
学習済みのActor方策は、MetaTrader 5 のストラテジーテスターで2024年1月の過去データを用いてテストしました。それ以外のパラメータは変更していません。以下にそのテスト結果を示します。
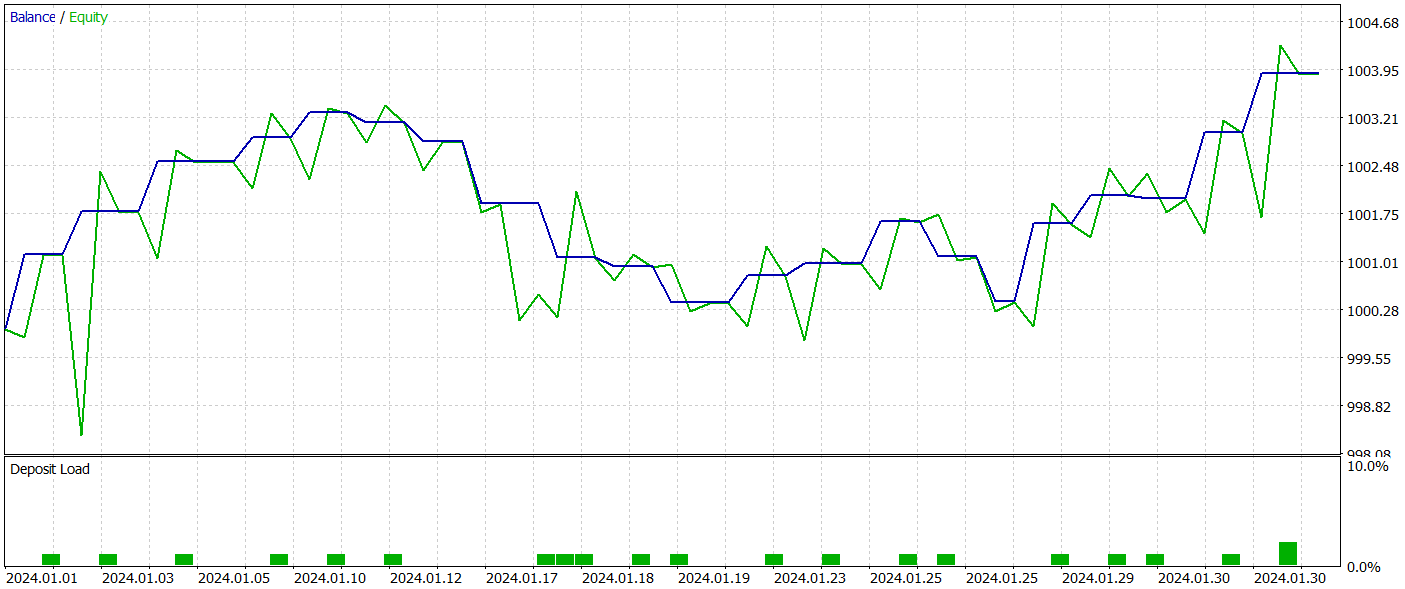
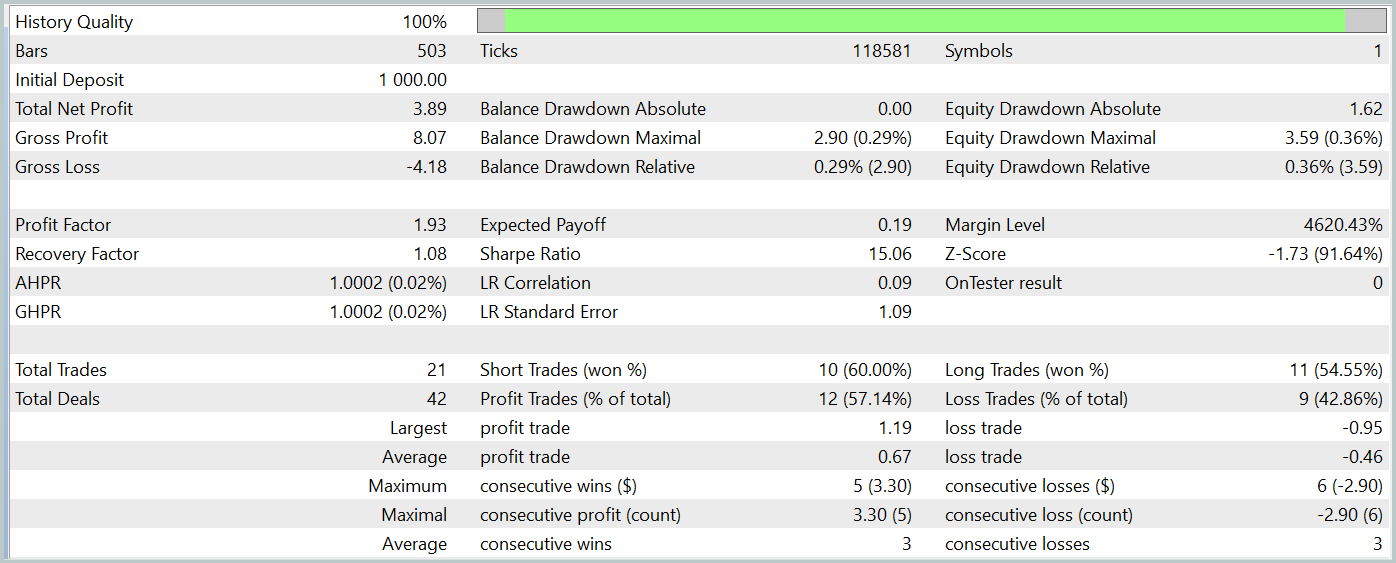
テスト期間中のバランスチャートは上昇傾向を示しており、明らかに好ましい結果です。しかし、モデルはテスト期間全体で21件の取引のみを実行し、そのうち12件が利益を上げました。残念ながら、この限られた取引回数では、長期にわたるモデルの有効性を決定的に評価することは困難です。
結論
本記事では、Mask-Attention-Free Transformer (MAFT)法とそのアルゴリズム取引への応用について解説しました。従来のTransformerアーキテクチャとは異なり、MAFTはデータマスキングの必要を排除し、シーケンス処理を高速化することで計算効率を大幅に向上させています。
テスト結果から、MAFTは予測精度を向上させるとともに、モデルの訓練時間を短縮できることが確認されました。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15973
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは、ドミトリー、
あなたのzipファイルは間違って作られているようです。 私はあなたのボックスにリストされたソースコードを見ることを期待したのですが、代わりにこれがzipに含まれていたものです。 リストされた各ディレクトリには、あなたの様々な記事で使用されたファイルが含まれているようです。 それぞれの説明を提供するか、より良い方法は、適切なように各ディレクトリに記事番号を追加することです。
ありがとうございました。
ケープコッダ
こんにちは、ドミトリー、
あなたのzipファイルは間違って作られているようです。 私はあなたのボックスにリストされたソースコードを見ることを期待したのですが、代わりにこれがzipに含まれていたものです。 リストされた各ディレクトリには、あなたの様々な記事で使用されたファイルが含まれているようです。 それぞれの説明を提供するか、より良い方法は、適切なように各ディレクトリに記事番号を追加することです。
ありがとうございました。
ケープコッダ
こんにちは、CapeCoddah、
zipファイルには全シリーズのファイルが入っています。OpenCLプログラムは "MQL5Experts\NeuroNet_DNG "に保存されています。全てのクラスが保存されたライブラリは、"MQL5Expertsそして、この記事を参照したモデルとエキスパートは、"MQL5Experts "ディレクトリにあります。
Regards,
Dmitriy.
こんにちは、CapeCoddah、
zipファイルには全シリーズのファイルが入っています。OpenCLプログラムは "MQL5Experts\NeuroNet_DNG.cl "に保存されています。全てのクラスが保存されたライブラリは、"MQL5Expertsそして、この記事で参照したモデルとエキスパートは、"MQL5Experts_MAFT "ディレクトリにあります。
Regards,
Dmitriy.
こんにちは、Dmitriy、
あなたの言っていることは理解できますが、誤解していると思います。 どのようにサブディレクトリ名を対応する記事と関連づければよいですか?
ありがとうございました。
ケープコッダ
こんにちは、ドミトリー、
迅速な回答をありがとうございます。 おっしゃっていることは理解できますが、誤解されているようです。 サブディレクトリ名と対応する記事を関連付けるにはどうすればよいのでしょうか。名前または記事番号で関連付け、そこから記事を検索することができます。
ありがとうございました。
ケープコッダ
フレームワークの名前で