
取引におけるニューラルネットワーク:独立したチャネルへのグローバル情報の注入(InjectTST)

はじめに
近年、マルチモーダル時系列予測のためのTransformerベースのアーキテクチャが広く普及し、時系列分析で最も好まれるモデルの1つになりつつあります。ますます多くのモデルが独立したチャネルアプローチを採用しており、モデルは他のチャネルと相互作用することなく、各チャネルシーケンスを個別に処理します。
チャネルの独立性には、主に2つの利点があります。
- ノイズ抑制:独立したモデルは、他のチャネルからのノイズの影響を受けずに、個々のチャネルの予測に集中できます。
- 分布ドリフトの緩和:チャネルの独立性は、時系列における分布ドリフトの問題に対処するのに役立ちます。
逆に、チャネルを混合すると、これらの課題に対処する効果が低くなる傾向があり、モデルのパフォーマンスが低下する可能性があります。ただし、チャネルミキシングには独自の利点があります。
- 高い情報容量:チャネルミキシングモデルはチャネル間の依存関係を捉えるのに優れており、将来の値予測するためのより多くの情報を提供できる可能性があります。
- チャネルの特異性:チャネルミキシングモデル内で複数のチャネルを最適化すると、モデルは各チャネルの独特の特性を最大限に活用できるようになります。
さらに、独立チャネルアプローチでは、統合モデルを通じて個々のチャネルを分析するため、モデルはチャネルを区別できず、主に複数のチャネル間で共有されるパターンに焦点が当てられます。これにより、チャネルの特異性が失われ、マルチモーダル時系列予測に悪影響を与える可能性があります。
したがって、チャネルの独立性と混合の両方の利点を組み合わせた効果的なモデルを開発し、両方のアプローチ(ノイズ低減、分布ドリフトの緩和、高い情報容量、チャネルの特異性)を活用できるようにすることが、マルチモーダル時系列予測のパフォーマンスをさらに向上させる鍵となります。
しかし、そのようなモデルを構築することは複雑な課題を伴います。まず、独立チャネルモデルは、本質的にチャネル依存関係と矛盾します。各チャネルの統合モデルを微調整することでチャネルの特殊性に対処できますが、それには多大な訓練コストがかかります。第二に、既存のノイズ低減方法と分布ドリフトのソリューションでは、チャネルミキシングフレームワークを独立したチャネルモデルと同じくらい堅牢にすることはできません。
これらの課題に対する潜在的な解決策の1つが、論文「InjectTST:A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting」では、マルチモーダル時系列の個々のチャネルにグローバル情報を注入する方法(InjectTST)を紹介しています。この方法の著者は、マルチモーダル時系列を予測するためにチャネル間の依存関係を明示的にモデル化することを回避します。代わりに、チャネル独立構造を基盤として維持しながら、各チャネルにグローバル情報(チャネルミキシング)を選択的に注入します。これにより、暗黙的なチャネルミキシングが可能になります。
個々のチャネルは、ノイズを回避しながら、高い情報容量とノイズ抑制を維持しながら、有用なグローバル情報を選択的に受信できます。チャネルの独立性が基本構造として維持されるため、配信ドリフトも軽減されます。
さらに、著者は、チャネルの特異性の問題に対処するために、InjectTSTにチャネル識別子を組み込んでいます。
1.InjectTSTアルゴリズム
特定の期間Tの予測Yを生成するために、L時間ステップを含むマルチモーダル時系列Xの履歴値を分析します。各時間ステップは、次元Mのベクトルとして表されます。
チャネルの独立性と混合の両方の利点を活用してこのタスクを解決するために、複雑なマルチレベルInjectTSTアルゴリズムが採用されています。
アルゴリズムの最初のステップでは、入力データを独立したチャネルハイウェイに分割します。その後、学習可能な位置エンコーディングを使用した線形投影が適用されます。
独立したチャネルプラットフォームは、共有モデルを使用して各チャネルを処理します。その結果、モデルはチャネルを区別することができず、主にチャネルの共通パターンを学習し、チャネルの特異性が欠如します。これを解決するために、InjectTSTの著者は学習可能なテンソルであるチャネル識別子を導入しました。
パッチの線形投影に続いて、位置エンコーディングとチャネル識別子の両方を持つテンソルが追加されます。
これらの準備されたデータは、高レベルの表現のためにTransformerエンコーダーに送られます。
この場合、Transformerエンコーダーは独立したチャネルハイウェイで動作し、個々のチャネルのトークンのみが分析され、チャネル間での情報交換はおこなわれないことに注意することが重要です。
チャネル識別子は各チャネルの特徴を表し、モデルがそれらを区別し、それぞれに固有の表現を取得できるようにします。
同時に、独立したチャネルハイウェイと並行して、チャネルミキシングルートは元のシーケンスXをグローバルミキシングモジュールに渡してグローバル情報を取得します。InjectTSTの主な目的は、各チャネルにグローバル情報を注入することであり、グローバル情報の取得は重要なタスクになります。この方法の著者は、CaT(ChannelasToken)とPaT(PatchasToken)と呼ばれる2種類のグローバルミキシングモジュールを提案しています。
CaTモジュールは各チャネルをトークンに直接投影します。つまり、チャネル内のすべての値に線形投影が適用されます。
PaTグローバルミキシングモジュールは、パッチを入力として処理します。最初に、分析されたマルチモーダルシーケンスのそれぞれの時間ステップに関連するパッチがグループ化されます。次に、グループ化されたパッチに線形投影が適用され、主にパッチレベルで情報がマージされます。次に位置エンコーディングが追加され、データはTransformerエンコーダーに渡され、パッチ全体とグローバル情報間の情報がさらに統合されます。
著者が実施した実験では、PaTの方が安定しているのに対し、特定の特殊なデータセットではCaTの方がパフォーマンスが優れていることが示されています。
InjectTSTメソッドの主な課題は、モデルの信頼性への影響を最小限に抑えながら、各チャネルにグローバル情報を注入する必要があることです。バニラTransformerでは、クロスアテンションにより、ターゲットシーケンスは関連性に基づいて別のソースからのコンテキスト情報に選択的に焦点を合わせることができます。クロスアテンションアーキテクチャに関するこの理解は、マルチモーダル時系列からグローバル情報を注入するためにも適用できます。したがって、チャネル間で混合されたグローバル情報はコンテキストとして扱うことができます。著者は、各チャネルにグローバル情報を注入するためにクロスアテンションを使用しています。
著者がコンテキスト注意モジュールにオプションの残差接続を導入していることは注目に値します。通常、残差接続によりモデルがわずかに不安定になる可能性がありますが、特定の特殊なデータセットではパフォーマンスが大幅に向上する可能性があります。
一般に、グローバル情報はKeyとValueとしてコンテキストアテンションモジュールに導入され、チャネル固有の情報はQueryとして提示されます。
クロスアテンションの後、データはグローバル情報で強化されます。予測値を生成するためにリニアヘッドが追加されます。
InjectTSTの著者は、3段階の訓練プロセスを提案しています。事前訓練段階では、元の時系列がランダムにマスクされ、マスクされた部分を予測することが目標となります。微調整段階では、事前訓練済みのInjectTSTヘッドが予測ヘッドに置き換えられ、予測ヘッドが微調整され、ネットワークの残りの部分は固定されます。最後に、微調整段階では、InjectTSTネットワーク全体が微調整されます。
この手法のオリジナルの視覚化を以下に示します。
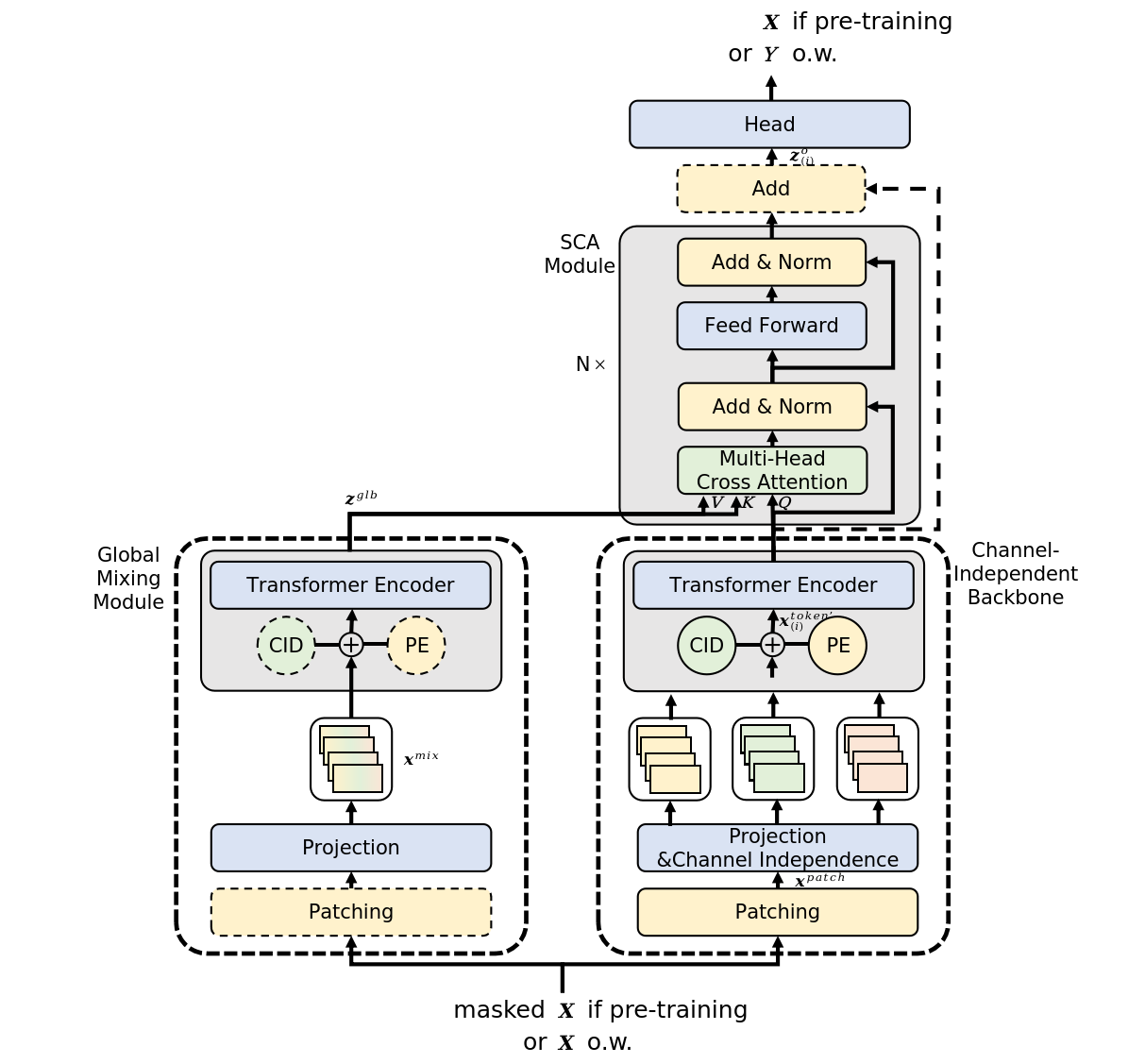
2.MQL5での実装
InjectTST法の理論的側面を確認した後、MQL5を使用して提案されたアプローチの解釈の実際的な実装に進みます。
この記事で提供されている実装が唯一の正しい実装ではないことに注意することが重要です。さらに、提案された実装は、元の論文で提示された資料に対する私の個人的な理解を反映したものであり、提案されたアプローチに対する著者のビジョンとは異なる場合があります。得られた結果についても同様です。
提案されたアプローチの実装作業を開始する際には、独立チャネルパラダイムを使用して、以前にいくつかのTransformerベースのモデルを検討したことを強調することが重要です。これらのモデルでは、独立したチャネルに対して予測が実行され、Transformerブロックを使用してチャネル間の依存関係が調査されました。これは、CaTグローバルミキシングモジュールアプローチに似ています。
ただし、この方法の作成者は、独立したチャネルハイウェイでTransformerアーキテクチャを採用し、この段階ではチャネル間の情報の流れを回避します。理論的には、データを個別のユニタリシーケンスで処理することでこのアルゴリズムを実装できます。ただし、このアプローチは広範囲にわたるため、マルチモーダル入力データで分析される変数の数に応じて順次操作の数が増加します。
私たちの仕事では、できるだけ多くの操作を並列スレッドで実行することを目指しています。したがって、この実装では、個々のチャネルを個別に分析できる新しい層を作成します。
2.1 独立チャネル解析ブロック
独立したチャネル分析の機能は、別の多層マルチヘッドアテンションブロックCNeuronMLMHAttentionOCLから基本関数を継承するクラスCNeuronMVMHAttentionMLKVに実装されています。以下に新しいクラスの構造を示します。
class CNeuronMVMHAttentionMLKV : public CNeuronMLMHAttentionOCL { protected: uint iLayersToOneKV; ///< Number of inner layers to 1 KV uint iHeadsKV; ///< Number of heads KV uint iVariables; ///< Number of variables CCollection KV_Tensors; ///< The collection of tensors of Keys and Values CCollection K_Tensors; ///< The collection of tensors of Keys CCollection K_Weights; ///< The collection of Matrix of K weights to previous layer CCollection V_Tensors; ///< The collection of tensors of Values CCollection V_Weights; ///< The collection of Matrix of V weights to previous layer CBufferFloat Temp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, CBufferFloat *scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMVMHAttentionMLKV(void) {}; ~CNeuronMVMHAttentionMLKV(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMVMHAttentionMLKV; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
このクラスでは3つの変数を追加します。
- iLayersToOneKV:1つのKey-Valueテンソルの層数
- iHeadsKV:Key-Valueテンソル内のアテンションヘッドの数
- iVariables:マルチモーダル時系列内の単変量シーケンスの数
さらに、5つのデータバッファコレクションを追加します。その目的については、実装を進めていく中で学習します。すべての内部オブジェクトは静的に宣言されるため、クラスのコンストラクタとデストラクタを「空」のままにすることができます。すべての内部変数とオブジェクトの初期化はInitメソッドで実行されます。
bool CNeuronMVMHAttentionMLKV::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
このメソッドのパラメータでは、初期化されたクラスのアーキテクチャを一意に識別できる主要な定数を受け取ることが期待されます。これらには次のものが含まれます。
- window:1つの単変量時系列のシーケンスの1つの要素を表すベクトルのサイズ
- window_key:単変量時系列のシーケンスの1つの要素のKeyエンティティの内部表現のベクトルのサイズ
- heads:Queryエンティティのアテンションヘッドの数
- heads_kv:連結されたKey-Valueテンソル内のアテンションヘッドの数
- unit_count:分析対象のシーケンスのサイズ
- layers:ブロック内のネストされた層の数
- layers_to_one_kv:1つのKey-Valueテンソルで動作するネストされた層の数
- variables:多峰性時系列内の単変量シーケンスの数
メソッド本体では、まず親クラスの同じメソッドを呼び出し、受け取ったパラメータを制御し、継承したオブジェクトを初期化します。さらに、このメソッドは、呼び出し元から受信したデータの必要最小限の制御をすでに実装しています。
親クラスメソッドが正常に実行された後、受信したパラメータを内部変数に保存します。
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1); iVariables = variables;
ここでは、ネストされたオブジェクトのアーキテクチャを決定する主な定数を定義します。
uint num_q = iWindowKey * iHeads * iUnits * iVariables; //Size of Q tensor uint num_kv = iWindowKey * iHeadsKV * iUnits * iVariables; //Size of KV tensor uint q_weights = (iWindow * iHeads + 1) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = (iWindow * iHeadsKV + 1) * iWindowKey; //Size of weights' matrix of K/V tenzor uint scores = iUnits * iUnits * iHeads * iVariables; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits * iVariables; //Size of multi-heads self-attention uint out = iWindow * iUnits * iVariables; //Size of out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 weights' matrix uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
ここで、このクラス内での実装のために提案しているアプローチについて簡単に説明することが重要です。まず第一に、OpenCLプログラムを変更せずに新しいクラスを構築するという決定が下されました。言い換えれば、新しい要件にもかかわらず、既存のカーネルを使用してクラスを完全に構築しています。
これを実現するには、まずKeyエンティティとValueエンティティの生成を分離します。念のためお伝えすると、以前は畳み込み層を1回通過して生成され、シーケンス要素ごとに順番にバッファに書き込まれていました。このアプローチは、グローバルな注意を構築するときに受け入れられます。ただし、プロセスを個別のチャネル内で整理すると、個々のチャネルのKey/Valueの交互のシーケンスが取得されます。これは、後続の分析には理想的ではなく、以前に作成されたアルゴリズムにも適合しません。したがって、これらのエンティティを個別に生成し、それらを1つのテンソルに連結します。
エンティティの生成を2つの段階に分割していることは注目に値します。その段階の数は、分析される変数またはアテンションヘッドの数とは無関係です。
2番目のポイントは、InjectTSTメソッドの作成者がすべてのチャネルに対して単一のTransformerエンコーダーを使用していることです。同様に、すべてのチャネルに対して単一の重み行列セットを使用します。その結果、チャネル数に関係なく、重み行列のサイズは一定のままになります。
これで準備作業は完了です。次は、ネストされた層の数と同じ回数の反復でループを構成します。
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
ループ本体では、ネストされたループを構成して、中間操作の結果と対応するエラー勾配のバッファを作成します。
for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
ここではまずQueryテンソルバッファを作成します。作成アルゴリズムはすべてのバッファに対して同一です。まず、バッファオブジェクトの新しいインスタンスを作成します。指定されたサイズでゼロ値で初期化します。次に、OpenCLコンテキストにバッファのコピーを作成し、対応するコレクションにバッファへのポインタを追加します。各ステップで操作を制御することを忘れないでください。
複数のネストされた層での分析に1つのKey-Valueテンソルを使用する予定なので、指定された頻度で対応するバッファを作成します。
//--- Initilize KV tensor if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Tensors.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(2 * num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; }
この段階では3つのバッファを作成することに注意してください。Key、Value、および連結されたKey-Value。
次のステップは、アテンション係数のバッファを作成することです。
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
これに続いて、マルチヘッドアテンションの結果のバッファが続きます。
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
そして、マルチヘッドアテンションとFeedForwardブロックの圧縮バッファがあります。
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
中間結果バッファとその勾配を初期化した後、重み行列の初期化に進みます。初期化のアルゴリズムはデータバッファの作成に似ていますが、行列にはランダムな値が入力される点が異なります。
最初に生成される行列は、Queryエンティティの重み行列です。
//--- Initialize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < q_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
KeyおよびValueエンティティの重み行列の作成頻度は、対応するエンティティのバッファの作成頻度と同様です。
//--- Initialize K weights if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; for(uint w = 0; w < kv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; }
アテンションヘッドの圧縮行列を追加しましょう。
//--- Initialize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
そして、FeedForwardブロック。
//--- Initialize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
その後、重み係数レベルでモーメントバッファを追加する別のネストされたループを作成します。作成されるバッファの数は、パラメータの更新方法によって異なります。
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? q_weights : iWindowKey * iHeads), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false; if(i % iLayersToOneKV == 0) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!K_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? kv_weights : iWindowKey * iHeadsKV), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!V_Weights.Add(temp)) return false; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_1 : 4 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_2 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
初期化メソッドの最後に、一時データを保存するためのバッファを追加し、実行された操作の論理結果を呼び出し元プログラムに返します。
if(!Temp.BufferInit(MathMax(2 * num_kv, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- return true; }
オブジェクトを初期化した後、フォワードパスアルゴリズムの構成に進みます。ここで、以前に作成されたカーネルの使用について少し説明しておきます。特に、クロスアテンションブロックMH2AttentionOutのフィードフォワードパスカーネルについては、それを実行キューに配置するアルゴリズムがAttentionOutメソッドに実装されています。カーネルを実行キューに配置するアルゴリズムは変更されていません。しかし、私たちの仕事は、このアルゴリズムを使用して独立したチャネルの分析を実装することです。
まず、カーネルが個々のアテンションヘッドでどのように動作するかを見てみましょう。別々のストリームで独立して処理します。まさにこれが私たちに必要なことだと私は思います。つまり、個々のチャネルは同じアテンションヘッドであるとします。
bool CNeuronMVMHAttentionMLKV::AttentionOut(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *scores, CBufferFloat *out) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits/*K units*/, iHeads * iVariables}; uint local_work_size[3] = {1, iUnits, 1};
それ以外の場合、メソッドのアルゴリズムは同じままです。必要なパラメータをカーネルに渡しましょう。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, scores.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Key-Valueテンソルヘッドの数を調整します。
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_heads_kv, (int)(iHeadsKV * iVariables))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
次に、カーネルを実行キューに入れます。
if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_mask, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
これでメソッドは終了です。しかし、これはフィードフォワードパスアルゴリズムの一部にすぎません。完全なアルゴリズムをfeedForwardメソッドで構築します。
bool CNeuronMVMHAttentionMLKV::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
パラメータでは、メソッドは、アルゴリズムの初期データを含む、前のニューラル層のオブジェクトへのポインタを受け取ります。初期データとして、3次元テンソル(シーケンスの長さ*単変量シーケンスの数*1つの要素の分析ウィンドウのサイズ)を受け取ることを期待します。
メソッドの本体では、受信したポインタの関連性をチェックし、モジュールのネストされた層を反復するサイクルを構成します。
CBufferFloat *kv = NULL; for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4));
ここではまず、必要なポインタを格納するソースデータバッファへのローカルポインタを宣言します。その後、解析した層に対応するQueryエンティティバッファをコレクションから抽出し、元のデータに基づいて生成されたデータをそこに書き込みます。
CBufferFloat *q = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
次のステップでは、新しいKey-Valueテンソルを生成する必要があるかどうかを確認します。必要に応じて、まず関連するコレクション内のオフセットを決定します。
if((i % iLayersToOneKV) == 0) { uint i_kv = i / iLayersToOneKV;
そして、必要なバッファへのポインタを抽出します。
kv = KV_Tensors.At(i_kv * 2); CBufferFloat *k = K_Tensors.At(i_kv * 2); CBufferFloat *v = V_Tensors.At(i_kv * 2);
その後、KeyとValueのエンティティを順番に生成します。
if(IsStopped() || !ConvolutionForward(K_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, k, iWindow, iWindowKey * iHeadsKV, None)) return false; if(IsStopped() || !ConvolutionForward(V_Weights.At(i_kv * (optimization == SGD ? 2 : 3)), inputs, v, iWindow, iWindowKey * iHeadsKV, None)) return false;
そして、得られたテンソルを最初の次元(シーケンスの要素)に沿って連結します。
if(IsStopped() || !Concat(k, v, kv, iWindowKey * iHeadsKV * iVariables, iWindowKey * iHeadsKV * iVariables, iUnits)) return false; }
このバージョンのデータ編成では、5次元データテンソルとして表すことができるデータバッファが取得されることに注意してください。Units * [Key, Value] * Variable * HeadsKV * Window_Key.Queryエンティティテンソルには同等のディメンションがありますが、[Key、Value]の代わりに[Query]があります。VariableとHeadsの次元を1つの次元「Variable*Heads」に集約することで、通常のMulti-HeadsSelf-Attentionに匹敵するテンソル次元が得られます。
ここで、OpenCLコンテキスト側では1次元データバッファを操作することを思い出す必要があります。データを多次元テンソルに分割することは、データのシーケンスを理解するための宣言的な作業にすぎません。一般に、バッファ内のデータの順序は最後の次元から最初の次元へと続きます。
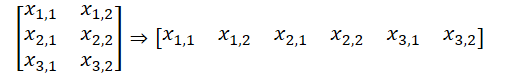
これにより、独立したチャネルを分析するために、以前に作成したOpenCLプログラムのカーネルを使用できるようになります。コレクションから必要なデータバッファへのポインタを取得し、Multi-HeadsSelf-Attentionアルゴリズムを実行します。上記で必要な方法を調整しました。
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
次に、マルチヘッドアテンションの結果を[Units * Variable] * Heads * Window_Keyのテンソルに精神的に再フォーマットし、データを元のデータの次元に投影します。
//--- Attention out calculation temp = FF_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9)), out, temp, iWindowKey * iHeads, iWindow, None)) return false; //--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
その後、得られた結果を元のデータと合計し、得られた値を正規化します。
次に、同じスタイルでFeedForwardブロック操作を実行し、ループの次の反復に進みます。
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), temp, out, 4 * iWindow, iWindow, activation)) return false; //--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- return true; }
ブロック内のすべてのネストされた層の操作が正常に完了したら、メソッドの実行を終了し、操作の完了ステータスを示す論理結果を呼び出し元プログラムに返します。
通常、フィードフォワードパスメソッドを実装した後、バックプロパゲーションアルゴリズムの開発に進みます。本日は、添付の資料に記載されている提案された実装を独自に分析していただきたいと思います。バックプロパゲーション法を実装するプロセスでは、フィードフォワードパスで前述したものと同じアプローチを利用しました。バックプロパゲーション操作は、順方向パスアルゴリズムに厳密に従いますが、逆の順序で実行されることに注意することが重要です。
さらに、添付ファイルにはCNeuronMVCrossAttentionMLKVクラスの実装が含まれています。このクラスのアルゴリズムはCNeuronMVMHAttentionMLKVクラスのアルゴリズムとほぼ同じですが、重要なクロスアテンションメカニズムが追加されています。
また、実装されたクラスCNeuronMVMHAttentionMLKVとCNeuronMVCrossAttentionMLKVは、理論的な側面については先ほど説明した、より大きなInjectTSTアルゴリズム内の構成要素として機能することも思い出していただきたいと思います。私たちの作業の次のステップは、完全なInjectTSTアルゴリズムを実装する新しいクラスを開発することです。
2.2 InjectTSTの実装
完全なInjectTSTアルゴリズムをCNeuronInjectTSTクラス内に構築します。このアルゴリズムは、完全に接続されたニューラル層の親クラスであるCNeuronBaseOCLからコア機能を継承します。以下に新しいクラスの構造を示します。
class CNeuronInjectTST : public CNeuronBaseOCL { protected: CNeuronPatching cPatching; CNeuronLearnabledPE cCIPosition; CNeuronLearnabledPE cCMPosition; CNeuronMVMHAttentionMLKV cChanelIndependentAttention; CNeuronMLMHAttentionMLKV cChanelMixAttention; CNeuronMVCrossAttentionMLKV cGlobalInjectionAttention; CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronInjectTST(void) {}; ~CNeuronInjectTST(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronInjectTST; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CBufferFloat *getWeights(void) override; };
このクラスには非常に多くの内部オブジェクトがありますが、変数は1つもありません。これは、このクラスが、主な機能が内部オブジェクトによって構築されるアルゴリズムの「大規模ノードアセンブリ」を実装しているという事実によるものです。また、ブロックアーキテクチャを定義するすべての定数は、クラス初期化メソッドでのみ使用され、ネストされたオブジェクト内に格納されます。アルゴリズムを実装する過程で、これらの機能について理解できるようになります。
クラスのすべての内部オブジェクトは静的に宣言されているため、クラスのコンストラクタとデストラクタを空のままにすることができます。また、ネストされたオブジェクトと継承されたオブジェクトすべての初期化は、Initメソッドで実行されます。
bool CNeuronInjectTST::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false; SetActivationFunction(None);
いつものように、このメソッドのパラメータでは、作成されたオブジェクトのアーキテクチャを決定する主要な定数を受け取ります。メソッドの本体では、受信したパラメータと継承したオブジェクトの初期化に関する基本的な制御がすでに実装されている親クラスの同じ名前のメソッドをすぐに呼び出します。
次に、InjectTSTアルゴリズムのフォワードパスシーケンスで内部オブジェクトを初期化します。上で紹介した方法の著者による視覚化では、取得された初期データが2つの情報フロー(独立したチャネルのブロックとグローバルミキシング)で使用されていることが簡単にわかります。どちらのブロックでも、まずソースデータがセグメント化されます。私の実装では、セグメンテーションプロセスを重複して実行するのではなく、情報フローが分岐する前に1回実行することにしました。
if(!cPatching.Init(0, 0, OpenCL, window, window, window, units_count, variables, optimization, iBatch)) return false; cPatching.SetActivationFunction(None);
この実装では、セグメントサイズ、セグメントウィンドウステップ、セグメント埋め込みサイズという等しいパラメータを使用していることに注意してください。したがって、セグメンテーションの前後のソースデータバッファのサイズは変わりませんでした。ただし、バッファ内のデータの順序は変更されています。2次元L*Vのデータテンソルは、3次元L/p*V*pに再フォーマットされました。ここで、Lは初期データのマルチモーダルシーケンスの長さ、Vは分析される変数の数、pはセグメントサイズです。
独立チャネルトランクのブロック内のセグメントトークンに、この方法の作成者は、位置コーディングとチャネル識別という2つの訓練可能なテンソルを追加します。2つの数値の合計は数値なので、私の実装では、入力テンソル内の個々の要素の位置ラベルを学習する単一の学習可能な位置エンコーディング層を使用することにしました。
if(!cCIPosition.Init(0, 1, OpenCL, window * units_count * variables, optimization, iBatch)) return false; cCIPosition.SetActivationFunction(None);
グローバルミキシングブロックでは、アルゴリズムによって位置コーディングも提供されます。2番目の情報フローハイウェイに対しても同様の層を初期化します。
if(!cCMPosition.Init(0, 2, OpenCL, window * units_count * variables, optimization, iBatch)) return false; cCMPosition.SetActivationFunction(None);
上で説明した独立チャネルCNeuronMVMHAttentionMLKVアテンションブロックを使用して、独立チャネルバックボーンを構築します。
if(!cChanelIndependentAttention.Init(0, 3, OpenCL, window, window_key, heads, heads_kv, units_count, layers, layers_to_one_kv, variables, optimization, iBatch)) return false; cChanelIndependentAttention.SetActivationFunction(None);
グローバルミキシングブロックを整理するために、以前に作成したアテンションブロックCNeuronMLMHAttentionMLKVを使用します。
if(!cChanelMixAttention.Init(0, 4, OpenCL, window * variables, window_key, heads, heads_kv, units_count, layers, layers_to_one_kv, optimization, iBatch)) return false; cChanelMixAttention.SetActivationFunction(None);
この場合、1つの要素の分析されたベクトルのウィンドウサイズは、セグメントサイズと分析された変数の数の積に等しく、これはチャネル混合パラダイムに対応することに注意してください。
独立したチャネルへのグローバル情報の注入は、クロスアテンションブロック内で実行されます。
if(!cGlobalInjectionAttention.Init(0, 5, OpenCL, window, window_key, heads, window * variables, heads_kv, units_count, units_count, layers, layers_to_one_kv, variables, 1, optimization, iBatch)) return false; cGlobalInjectionAttention.SetActivationFunction(None);
この場合、混合チャネルを扱っているため、コンテキスト内の単位行の数を1に設定することに注意してください。
初期化メソッドの最後に、データバッファのスワップを実行します。これにより、クラスのバッファと内部オブジェクト間の不要なコピーを回避できます。
if(!SetOutput(cGlobalInjectionAttention.getOutput(), true) || !SetGradient(cGlobalInjectionAttention.getGradient(), true) ) return false;
中間データを格納するための補助バッファを初期化し、操作の論理結果を呼び出し元プログラムに返します。
if(!cTemp.BufferInit(cPatching.Neurons(), 0) || !cTemp.BufferCreate(OpenCL) ) return false; //--- return true; }
クラスオブジェクトを初期化した後、クラスのフィードフォワードパスアルゴリズムの構築に進みます。初期化メソッドを実装するプロセスにおけるアルゴリズムの主な段階についてはすでに説明しました。そして、それらをfeedForwardメソッドで記述するだけです。
bool CNeuronInjectTST::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPatching.FeedForward(NeuronOCL)) return false;
メソッドパラメータでは、前の層のオブジェクトへのポインタを受け取り、元のデータを渡します。受信したポインタを、同じ名前のネストされたデータセグメンテーション層のメソッドにすぐに渡します。
この段階では、必要な制御がセグメンテーション層メソッドで実装されており、再チェックは不要であるため、取得したポインタの関連性はチェックしないことに注意してください。
次のステップは、セグメント化されたデータに位置エンコーディングを追加することです。
if(!cCIPosition.FeedForward(cPatching.AsObject()) || !cCMPosition.FeedForward(cPatching.AsObject()) ) return false;
その後、まずデータを独立したチャネルのブロックに渡します。
if(!cChanelIndependentAttention.FeedForward(cCIPosition.AsObject())) return false;
そして、グローバルミキシングブロックを通過します。
if(!cChanelMixAttention.FeedForward(cCMPosition.AsObject())) return false;
実行順序にかかわらず、これらは2つの独立した情報ストリームであることに注意してください。コンテキストアテンションブロックでのみ、独立したチャネルへのグローバルデータの注入が実行されます。
if(!cGlobalInjectionAttention.FeedForward(cCIPosition.AsObject(), cCMPosition.getOutput())) return false; //--- return true; }
意思決定プロセスをCNeuronInjectTSTクラス外に移動しました。
ご覧のとおり、フィードフォワードパスメソッドは非常に簡潔で読みやすいことがわかりました。言い換えれば、アルゴリズムの大規模ノード実装から予想されるとおりです。バックワードパスメソッドも同様の方法で構築されます。コードは添付ファイルにあります。このクラスとそのすべてのメソッドの完全なコードは添付ファイルに記載されています。添付ファイルには、記事で使用されているすべてのプログラムの完全なコードも含まれています。
2.3 学習可能なモデルのアーキテクチャ
上記では、MQL5を使用してInjectTSTメソッドの基本アルゴリズムを実装しました。これで、提案されたアプローチを独自のモデルに実装できます。私たちが検討している方法は、時系列を予測するために提案されました。そして、私たちは、これまでに検討されてきた時系列予測のいくつかの方法と同様に、提案されたアプローチを環境状態エンコーダーモデルに実装しようとします。ご存知のとおり、このモデルのアーキテクチャの説明はCreateEncoderDescriptionsメソッドで提示されます。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
このメソッドのパラメータでは、モデルアーキテクチャを記録するための動的配列オブジェクトへのポインタを受け取ります。メソッドの本体では、受信したポインタの関連性をすぐに確認し、必要に応じて新しい動的配列オブジェクトを作成します。次に、作成するモデルのアーキテクチャの説明を始めます。
1つ目は、元のデータを記録するために使用される基本的な全結合層です。
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
いつものように、生の入力データをモデルに入力する予定です。そして、バッチデータ正規化層で一次処理がおこなわれ、異なる分布からの情報が比較可能な形式に変換されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次は、グローバルインジェクションを備えた独立したチャネルの新しい層です。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronInjectTST; descr.window = PatchSize; //Patch window descr.window_out = 8; //Window Key
セグメントサイズを指定するには、PatchSize定数を追加します。分析された履歴の深さとセグメントのサイズに基づいて、シーケンスのサイズを計算します。
prev_count = descr.count = (HistoryBars + descr.window - 1) / descr.window; //Units
Query、Key、Valueエンティティのアテンションヘッドの数、およびユニタリシーケンスの数も配列に書き込みます。
{
int temp[] =
{
4, //Heads
2, //Heads KV
BarDescr //Variables
};
ArrayCopy(descr.heads, temp);
}
すべての内部ブロックには4つの折り畳まれた層が含まれます。
descr.layers = 4; //Layers
そして、1つのKey-Valueテンソルは2つのネストされた層に関連します。
descr.step = 2; //Layers to 1 KV descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、後続の値を予測するためのヘッドを追加する必要があります。InjectTSTブロックの出力では、次元L/p*V*pのテンソルが得られることを覚えています。独立したチャネル内のデータの予測を行うには、まずデータを転置する必要があります。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = PatchSize * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、2層MLPを使用して独立したチャネルを予測します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = PatchSize * BarDescr; descr.window = prev_count; descr.window_out = NForecast; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = PatchSize * NForecast; descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
そうすることで、データの次元がVariables*Forecastにまで削減されます。これで、予測値を元のデータ表現に戻すことができます。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
正規化中に元のデータから削除された統計指標を追加します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
さらに、FreDF法のアプローチを使用して、単変量系列の予測値を周波数領域で調整します。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
以前の作品のActorモデルとCriticモデルのアーキテクチャを使用します。したがって、ここではそれらの詳細な説明には立ち入りません。
さらに、新しいエンコーダーアーキテクチャでは、口座ステータスを決定するためにソースデータ層も結果も変更しませんでした。これにより、環境と対話したりモデルを訓練したりするために、以前に作成したすべてのプログラムを変更せずに使用できるようになります。したがって、以前に収集した訓練サンプルをモデルの初期訓練に使用できます。
この記事の作成に使用したすべてのプログラムと同様に、すべてのクラスとそのメソッドの完全なコードは添付ファイルにあります。
3.テスト
上記では、MQL5を使用してInjectTSTメソッドを実装し、環境状態エンコーダーモデルでのその応用を示しました。次に、実際の履歴データに対するモデルの有効性の評価に進みます。
前回と同様に、まず、指定された予測期間における将来の価格変動を予測するために、環境状態エンコーダーモデルを訓練します。この実験では、訓練データセットは、H1時間枠のEURUSD商品の2023年からの履歴データで構成されています。
環境状態エンコーダーは、エージェントの行動の影響を受けない過去の価格データのみを分析します。したがって、満足のいく結果が得られるか、予測誤差が安定するまでモデルを訓練します。
以下は、予測された価格変動の軌跡と実際の価格変動の軌跡を比較した視覚化です。
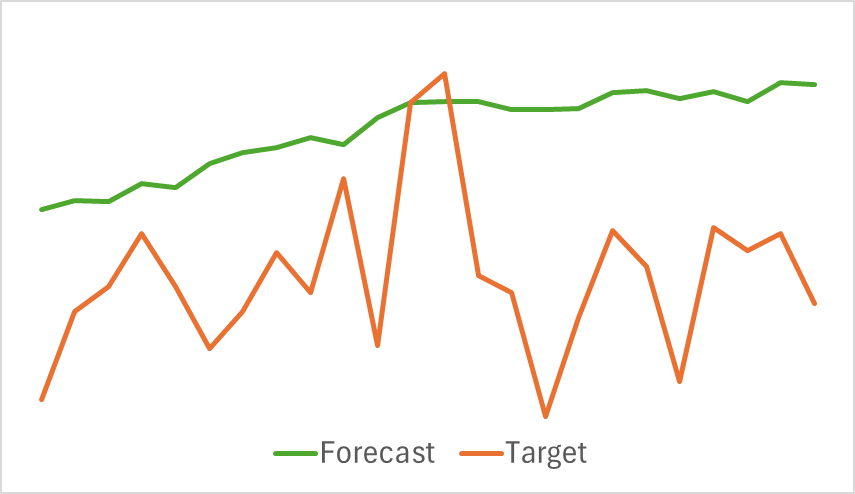
グラフに示されているように、予測された軌道は上方にシフトし、顕著な変動は少なくなっています。ただし、全体的なトレンドの方向は目標軌道と一致しています。これは、これまでに検討したモデルと比較すると最も正確な予測ではないかもしれませんが、このエンコーダーがActorによる収益性の高い戦略の開発に役立つかどうかを評価するために、訓練の第2フェーズに進みます。
ActorモデルとCriticモデルの訓練は反復的に実行されます。最初に、既存の訓練データセットを使用して、モデル訓練を数エポック実行します。次に、環境とのやり取り中に、Actorの現在の方策に基づく行動から得られた報酬に基づいてデータセットを更新します。これにより、現在のActor方策分布からの実際の行動報酬で訓練セットを強化できます。実際の報酬値で訓練データセットを強化することで、Criticの報酬関数をより適切に最適化し、Actorの行動をより正確に評価できるようになります。これにより、現在の方策の有効性を向上させるための調整が可能になります。望ましい結果が得られるまで反復が続けられます。
訓練されたActorの方策の有効性を評価するために、MetaTrader 5ストラテジーテスター内で環境相互作用アドバイザーのテスト実行を実行します。他のすべてのパラメータを変更せずに、2024年1月からの履歴データに対してテストが実行されます。テスト実行の結果を以下に示します。
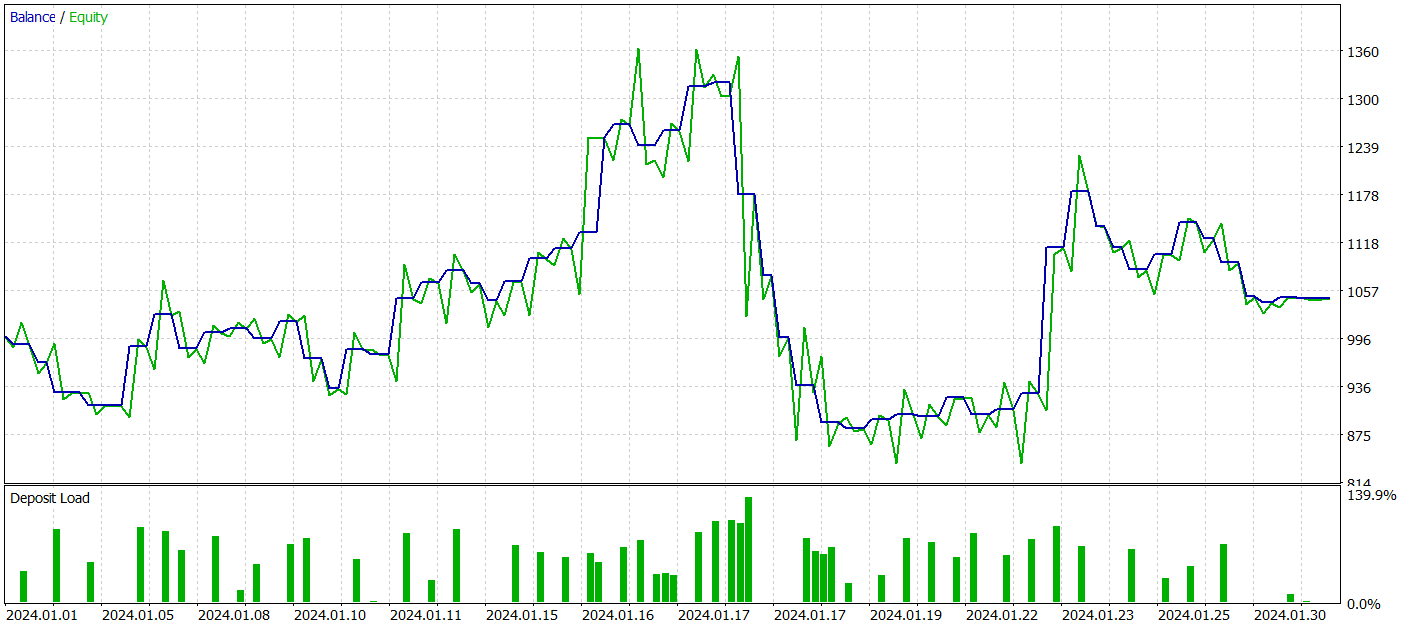
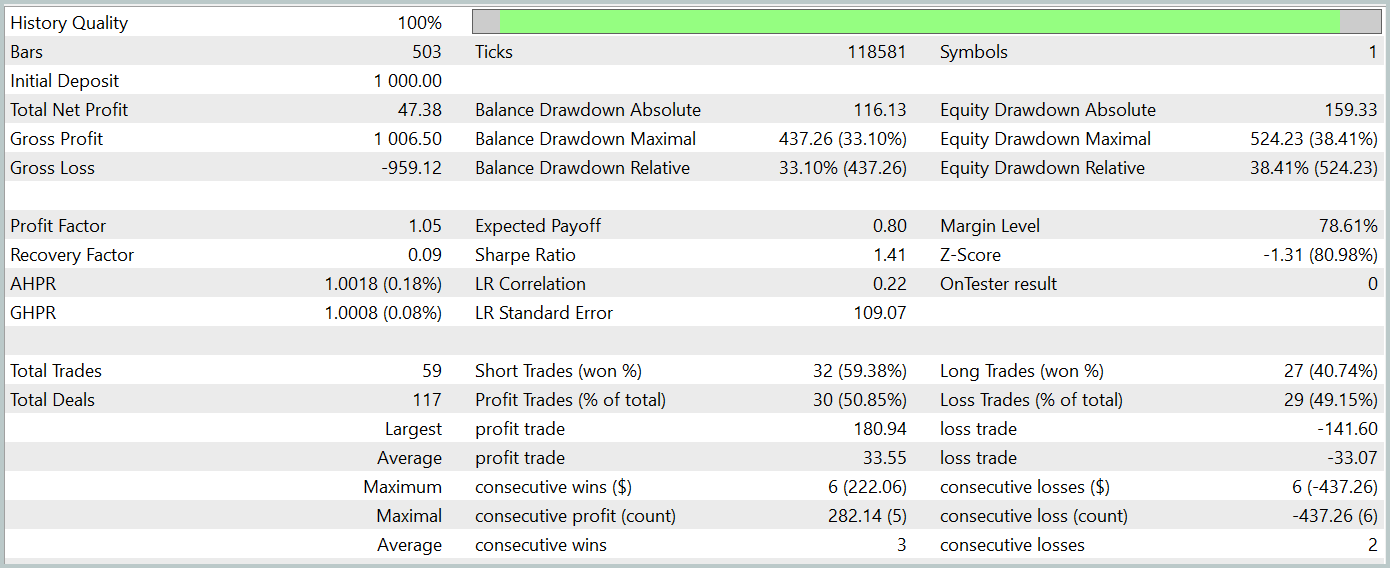
テスト期間中、モデルはわずかな利益を達成しました。合計59件の取引が実行され、30件が利益で終了しました。最大および平均の利益取引は、それぞれの損失取引を上回りました。その結果、利益率は1.05になりました。しかし、バランス曲線には明確な上昇傾向が見られず、テスト中に33%を超えるドローダウンが記録されました。
結論
本記事では、独立したデータチャネルにグローバル情報を注入することで長期予測を強化する新しい時系列予測手法InjectTSTについて紹介しました。
実践セクションでは、提案手法をMQL5で実装し、環境状態エンコーダーモデルに統合しました。重要な作業がおこなわれたものの、期待された結果は得られませんでした。
モデルの性能が低かった原因を特定するには、徹底的な分析が必要です。ただし、環境状態予測モデルの訓練に直接的なアプローチを取ったことが、その一因である可能性があります。InjectTSTの開発者は当初、より良い結果を得るために3段階の訓練プロセスが必要になる可能性を示唆していました。
参照文献
- InjectTST:A Transformer Method of Injecting Global Information into Independent Channels for Long Time Series Forecasting
- 本連載の他の記事
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15498
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索