PythonとMQL5を使用した特徴量エンジニアリング(第4回):UMAP回帰によるローソク足パターン認識

ローソク足パターンは、当コミュニティにおける多くのアルゴリズムトレーダーが、さまざまな取引戦略やスタイルにおいて広く活用しています。しかしながら、私たちの理解は、これまでに発見されたローソク足パターンに限られており、実際には、まだ気づいていない有益なローソク足パターンが数多く存在している可能性があります。現代の市場には膨大な情報があるため、トレーダーが自分の取引市場で常に最も信頼性の高いローソク足パターンを使用できていると確信を持つことは、実際には非常に困難です。
この問題を緩和するために、私たちはコンピュータに、これまで認識していなかった新しいローソク足パターンを特定させることが可能となるアプローチを提案します。この枠組みは、子供のころに多くの人が遊んだあるゲームに部分的に似ています。このゲームには様々な名前がありますが、本質は同じです。プレイヤーは、ある名詞を使わずに、その名詞を形容詞だけで説明するよう求められます。たとえば、「バナナ」という単語が与えられた場合、リード役のプレイヤーは「黄色くて曲がっている」といった手がかりを使って友達にそれを当てさせます。これは読者にとって直感的に理解しやすいはずです。
この子供時代のゲームは、今日のデータセットが多くの次元を持つ傾向にあるために、これまで隠れていたローソク足パターンを発見するために、私たちがコンピュータに実行させようとしているタスクと論理的に同一です。ちょうど先ほど説明した「バナナを3語以内で説明する」ゲームと同様に、私たちはローソク足を表す10列の市場データをコンピュータに与え、それを8列以下(埋め込み)で元の市場データを表現するように求めます。これを次元削減と呼びます。
すでにご存知かもしれませんが、主成分分析(PCA)のように、よく知られている次元削減手法は数多く存在します。これらの手法は、変換されたデータの中で最も重要な側面にコンピュータの注目を向けさせるという点で有用です。本日は、UMAP (Uniform Manifold Approximation And Projection)と呼ばれる手法を使用します。これは比較的新しいアルゴリズムであり、読者の方にもすぐにご理解いただけると思いますが、市場データに含まれる非線形の関係性を新しい方法で明らかにするために活用できます。
私たちの目的は、現在のローソク足を詳細に記述できるように、元のデータセット内に慎重に列を設計・構築することです。こうすることで、UMAPアルゴリズムがデータを変換し、似たローソク足をグループ化し、それらをより少ない「言葉」(埋め込みベクトル)で表現することが可能になります。このプロセスによって、ローソク足を正確に記述するために必要な多くの次元のせいでこれまで見つけられなかったパターンを、コンピュータが認識できる可能性が出てきます。
UMAPアルゴリズムの有効性を検証するために、2つの同一の統計モデルを使ってEURGBPの日次為替リターンの予測をおこないました。1つ目のモデルは、元の形のままの市場データで学習をおこないました。この例では、元データはMetaTrader 5端末から直接取得された10次元の市場データです。UMAPアルゴリズムを使うことで、この元データをわずか3次元にまで変換することができました。そして、この3次元データで学習したモデルは、元の10次元データで学習したモデルよりも予測誤差が小さくなる結果を出しました。
最後に、UMAPアルゴリズムをMQL5上でゼロからネイティブに実装する方法については本稿では扱いません。このアルゴリズムは非常に高度で、数値的安定性と計算効率の両立を図る実装は容易ではないためです。もし読者の中に、解析幾何学や代数的位相幾何学の必要なスキルに自信がある方がいれば、MQL5上での独自実装に挑戦することも可能です。アルゴリズムの数学的仕様を正確に記載した原論文へのリンクはこちらです。
それ以外の方(私自身も含めます)には、アルゴリズムを一から実装する必要を回避する代わりに、関数近似のスキルを使ってUMAPの役割を代替する方法を今後紹介していきます。
なぜUMAPなのか
次元削減のための有用で広く知られた手法が数多く存在する中で、読者の中には自然と、なぜUMAPを学ぶ必要があるのか。そして、新しいライブラリを学ぶことが本当に必要なのかについて疑問を持つ方もいるかもしれません。UMAPの主な利点の1つは、データセットのサイズが大きくなっても、変換にかかる時間がほとんど変わらないという点です。さらに、UMAPアルゴリズムは、データの非線形な効果を抽出することに特化している一方で、元のデータの全体的な構造を可能な限り保持しようとします。言い換えれば、UMAPはデータを歪めたり、誤解を招くようなアーティファクト(人工的な構造)を作り出すことを極力避けるように設計されているということです。これは、ほとんどの次元削減アルゴリズムではあまり見られない特徴です。
UMAPアルゴリズムは比較的新しいもので、今回扱う実装はPythonとNumbaで構築されています。Numbaは、Pythonコードをマシンコードに変換するコンパイラです。このPythonとマシンコードの融合により、大規模なデータセットに対しても、高速かつ数値的に安定した計算性能を実現しています。今回取り上げるUMAPライブラリの実装は、リーランド・マキネス(Leland McInnes)らによって設計され、2018年に初めて公開されました。

図1: Leland McInnesはUMAPの研究論文の主要な著者の1人であり、Pythonライブラリのメンテナンスにも関わっている
ただし、読者には注意していただきたい点があります。本稿で取り上げるものとは異なるライブラリによるUMAPの実装を使う場合、ここで述べた特性が必ずしも保証されるわけではありません。同じアルゴリズムでも、実装が異なれば数値的な性質に違いが生じる可能性があるためです。
MQL5の始め方
まず最初のステップとして、現在のローソク足を記述する定量的なデータを取得します。ここでは、一定期間(この例では「ホライズン」と呼びます)における、始値(Open)、高値(High)、安値(Low)、終値(Close)の価格レベルの変化量を知りたいと考えています。これに加えて、始値から高値までの上昇率、始値から安値までの下落率、始値から終値までの変化率を追跡します。これらの成長(変化)計算は、MetaTrader 5端末で利用可能な4つの価格フィードそれぞれに対して繰り返し実行します。これによって、合計10列のデータが得られます(最初の2列である「Time」と「True Close」を除いた数です)。これらの10列は、同時線やハンマーなど、あらゆるローソク足パターンを効果的に表現することができます。ただし、注意すべき点として、今回の手法では、2本以上のローソク足によって構成されるパターンを識別することはできません。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 24 //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " UMAP Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Close","Open","High","Low","Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
Pythonでデータを分析する
私たちの目標は2つあります。
- 価格データをそのまま使用するのではなく、UMAP変換を用いる利点を示すこと
- 関数近似の技術を使ってUMAPアルゴリズムの動作を再現できるようにし、その効果をバックテスト可能にすること
まず、UMAPを使用することで得られる利点が明確に伝わるように、価格データをそのまま使う場合との比較を通して、UMAP変換の優位性を示します。UMAPの利点を確認した後、UMAPライブラリによって得られた変換結果(埋め込み)を使って、市場データに対するUMAPの埋め込みを推定するニューラルネットワークの学習をおこないます。
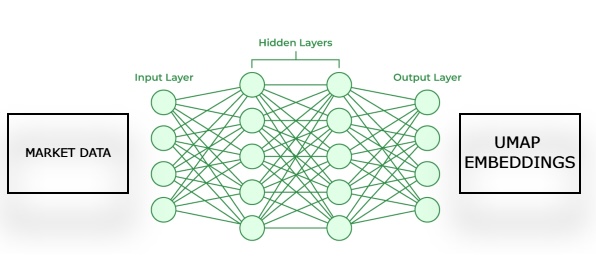
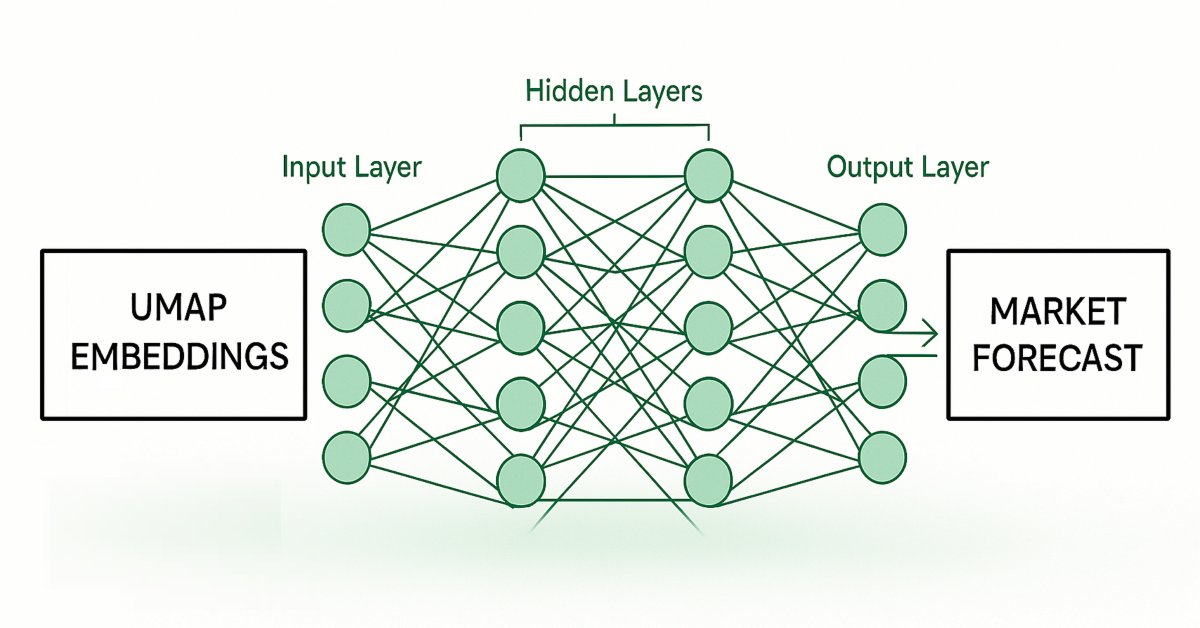
図2:与えられた市場データからUMAP埋め込みを推定するためのフレームワークの可視化
続いて、最初のモデルによって推定されたUMAP埋め込みを入力として、市場の将来の価格変動を予測する2番目のモデルを学習させます。私たちの目的は、これら2つの統計モデルが連鎖的に機能するように設計することです。つまり、第1モデルは与えられた市場データからUMAP埋め込みを推定し、第2モデルはその出力を受け取って、取引対象市場の将来リターンを予測するという流れです。このフレームワークは、UMAPアルゴリズムを一から実装する場合と比べて、はるかに高速でありながら、同等の効果を得られる可能性があることが分かるでしょう。
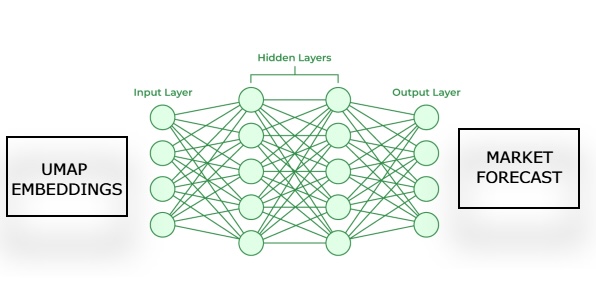
図3:推定されたUMAP埋め込みから市場予測を生成するためのフレームワークの視覚化
ここまでで、私たちの動機と今後取り組む方法論について説明したので、いよいよPythonで作業を始めましょう。まずは、必要なライブラリをインポートします。なお、読者の方が一緒に進めたい場合は、「pip install umap-learn」コマンドを入力してUMAPライブラリを事前にインストールしておく必要があります。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import umap import seaborn as sns
読者の方が準備できていて一緒に進める場合、次のステップは、MQL5スクリプトを使って生成した市場データを読み込むことになります。
HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1 data.dropna(inplace=True) data
市場データは正常に読み込まれましたが、Time列を確認すると、CSVファイルには直近の市場データも含まれていることがわかります。このままでは、過去のモデルでは知り得なかった将来の情報が混入してしまい、バックテストの結果が汚染されてしまう可能性があります。そのため、CSVファイルから直近5年間の市場データを削除したいと考えています。
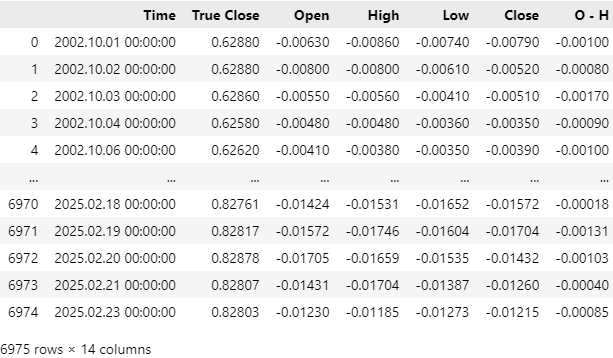
図4:MQL5スクリプトを使用して取得した過去の市場データ
それでは、CSVファイルから直近5年間の市場データを削除しましょう。ご覧のとおり、CSVファイル内の最終日付は現在、2019年10月16日になっています。ここからおこなうバックテストは2020年1月1日から開始されます。このように、トレーニング期間の終了とテスト期間の開始の間にギャップを設けることは、テストのロバスト性を確保するために重要です。
#Delete all the data that overlaps with our back test data = data.iloc[:(-(365 * 5) + (31 * 5)),:] data
図5:バックテストしたい期間と重複するデータはすべて削除する
それでは、今回の演習で作成した列の効果を可視化してみましょう。「H - L」列は、その日の最高値と最安値の差を表しており、これは実質的な1日の値動きの範囲を示しています。一方で、「O - C」列は、その日の始値と終値の差、つまり1日の純粋な価格変化を示しています。これら2つの列を使って散布図を作成することで、1日のレンジと純粋な価格変化との間に何らかの関係があるのかを探ろうとしています。しかしながら、残念なことに、この2つの間の関係性は複雑で非線形的に見えます。こうしたデータこそ、UMAPのような手法で分析するのに適している可能性があります。
sns.scatterplot(
data=data,
y='O - C',
x='H - L',
hue='Class'
)
plt.grid()
plt.title("Visualizing Our Custom Columns on EURUSD Market Data")
plt.axhline(0,color='black',linestyle='--')
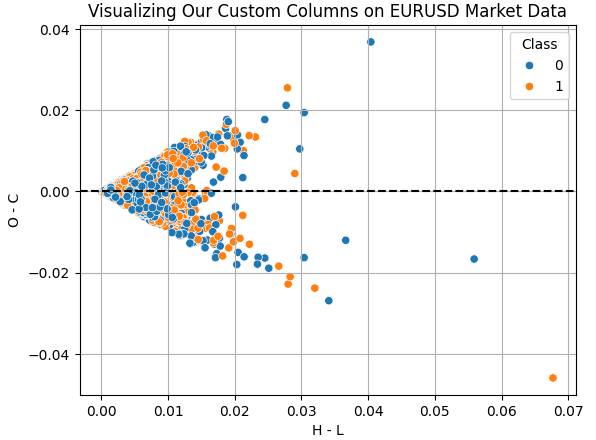
図6:取引範囲と当日の価格の純変動の関係の視覚化
UMAP変換の適用は、比較的簡単です。まずは、UMAPオブジェクトを作成します。その後、このオブジェクトをデータに適合させ、その結果として変換されたデータを取得します。UMAPオブジェクトは、デフォルトではデータを2次元(2列)に削減します。今後の説明では、希望する次元数をどのように指定するかも紹介していきます。元々は、MQL5スクリプトで取得した10列のデータでしたが、図7に示されているように、それが2次元にまで削減されました。
以下のコード例では、UMAPライブラリの一部のチューニングパラメータを読者に紹介しています。
- n_neighbors:このパラメータは、アルゴリズムに対して「どれだけの数のデータ点を同じ近傍内に維持するようにするか」を指示します。
- metric:2点間の「距離(類似度)」をどのように測るかにはさまざまな手法があり、それによって「同じ近傍かどうか」が判断されます。距離の測定方法(メトリック)を変えることで、投影されたデータの構造も大きく変化します。
reducer = umap.UMAP(n_neighbors=100,metric="euclidean") embedding = reducer.fit_transform(data.iloc[:,2:-2]) embedding = pd.DataFrame(embedding,columns=['X1','X2']) embedding['Class'] = data['Class'] sns.scatterplot( data=embedding, x='X1', y='X2', hue='Class' ) plt.grid() plt.title("Visualizing the effects of UMAP on our EURUSD Market Data")
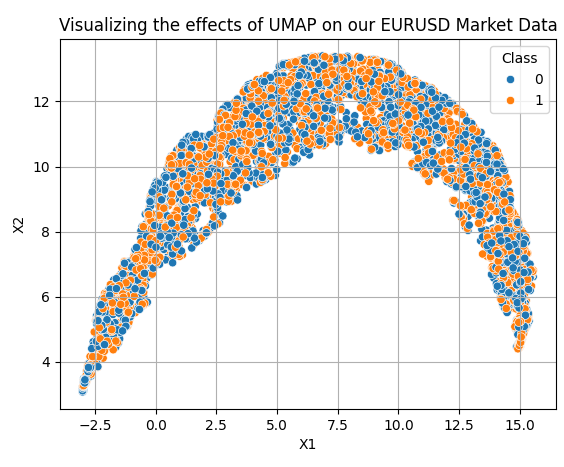
図7:UMAPアルゴリズムを適用した後の変換されたデータの視覚化
新しいデータ表現は完璧ではありません。しかし、オレンジ色の点が多く存在する領域と、青色の点が多く存在する領域が見られます。これは、統計モデルが2つのクラス(分類対象)を学習しやすくなる可能性を示しています。ただし、今回使用した2列は便宜的に選んだだけであり、読者に「簡単に始められる」という感覚を持ってもらうためのものでした。実際のところ、データを効果的に変換するために必要な次元数は分かっていません。そのため、次元数を1から9まで変化させながらラインサーチをおこないます。以下の関数では、希望する次元数を引数として指定すると、その次元数に変換されたデータを返すようになっています。
def return_transformed_data(n_components): HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data.dropna(inplace=True) data = data.iloc[:(-(365 * 5) + (31 * 5)),:] reducer = umap.UMAP(n_neighbors=100,metric="euclidean",n_components=n_components,n_jobs=-1) embedding = reducer.fit_transform(data.iloc[:,2:-1]) cols = [] for i in np.arange(n_components): s = 'X' + ' ' + str(i) cols.append(s) embedding = pd.DataFrame(embedding,columns=cols) return embedding.copy()
それではモデルを準備しましょう。
from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import TimeSeriesSplit,cross_val_score
適切な時系列交差検証のために時系列分割オブジェクトを定義します。
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) ここで、直線探索を実行して、元のデータを表すために必要な最適な次元数を調べてみましょう。
LEVELS = 8 res = pd.DataFrame(columns=['X'],index=np.arange(LEVELS)) for i in range(LEVELS): new_data = return_transformed_data(i+1) res.iloc[i,0] = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),new_data.iloc[:,0:],data['Target'],cv=tscv)))
最小インデックスと最小値を取得します。
res['X'] = pd.to_numeric(res['X'], errors='coerce') min_value = min(res.iloc[:,0]) min_index = res['X'].idxmin()
最良の結果は、元の10列のデータを3列に圧縮して表現したときに得られました。ここで読者の皆様に理解していただきたいのは、この3列を元の10列の中から選ばれた最良の3列と考えてはいけないということです。むしろ、元の10列の情報が変換されて3列にまとめられたものなのです。
plt.plot(res,color='black') plt.grid() plt.title('Finding The Optimal Number of U-MAP Components') plt.ylabel('RMSE Validation Error') plt.xlabel('Training Iteration') plt.scatter(min_index,min_value,color='red')
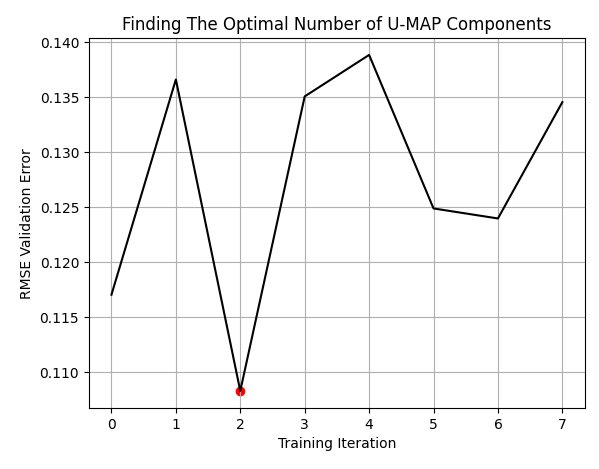
図8:元の10列の中から、最適な列数は3列となった
ここで、市場データを元の形式で使用する場合の誤差レベルを記録しましょう。
classic_error = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),data.iloc[:,2:-2],data['Target'],cv=tscv)))
それでは、UMAPで変換したデータを使用した場合の誤差と、変換を行わず元の市場データをそのまま使用した場合の誤差を比較してみましょう。ご覧の通り、UMAP変換によって誤差は大幅に低減され、元の価格データのままでは到達できなかった最適な領域に到達しています。
results = [min(res.iloc[:,0]),classic_error] sns.barplot(results,color='black') plt.axhline(results[0],color='red',linestyle='--') plt.ylabel('RMSE Validation Error') plt.xlabel('0: UMAP Transformed Data | 1: Original OHLC Data') plt.title("UMAP Transformations Are Helping Us Reduce Our Error Rates")
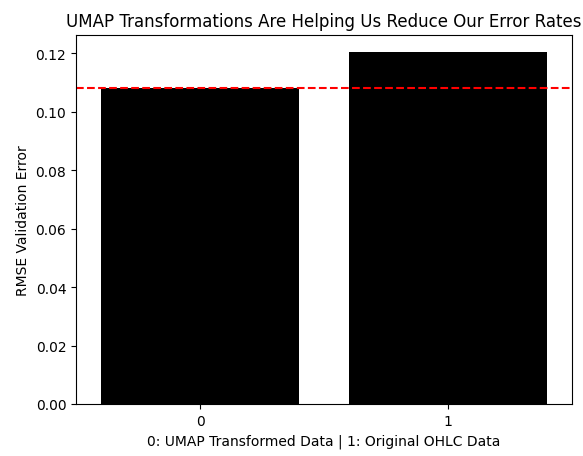
図9:UMAP変換により誤差が低減され、元のデータをそのまま使った場合よりも優れた結果を出している
UMAP変換を用いる動機が明確になったので、次に図2および図3で示したアーキテクチャの構築を始めましょう。まずは、元の市場データを効果的にUMAP埋め込みへ変換する方法を学習する際に、ニューラルネットワークが何回の訓練イテレーションを必要とするかを評価することから始めます。
from sklearn.neural_network import MLPRegressor
必要なデータを取得します。
new_data = return_transformed_data(3) モデルの誤差と許容される訓練エポック数の関係を観察するため、ラインサーチを実施します。
LEVELS = 18 NN_ERROR = pd.DataFrame(columns=['Error'],index=np.arange(LEVELS)) for i in range(LEVELS): model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=(2 ** i),solver='adam') NN_ERROR.iloc[i,0] = np.mean(np.abs(cross_val_score(model,new_data,data['Target'],cv=tscv)))
結果をプロットしてみましょう。最良の結果は、モデルに65,536回(つまり2の16乗)の訓練イテレーションを許可したときに得られました。
NN_ERROR['Error'] = pd.to_numeric(NN_ERROR['Error'], errors='coerce') min_idx = NN_ERROR.idxmin() min_value = NN_ERROR.min() plt.plot(NN_ERROR,color='black') plt.grid() plt.ylabel('5 Fold CV RMSE') plt.xlabel('Max Iterations As Powers of 2') plt.scatter(min_idx,min_value,color='red') plt.title('Minimizing The Error of Our Neural Network')
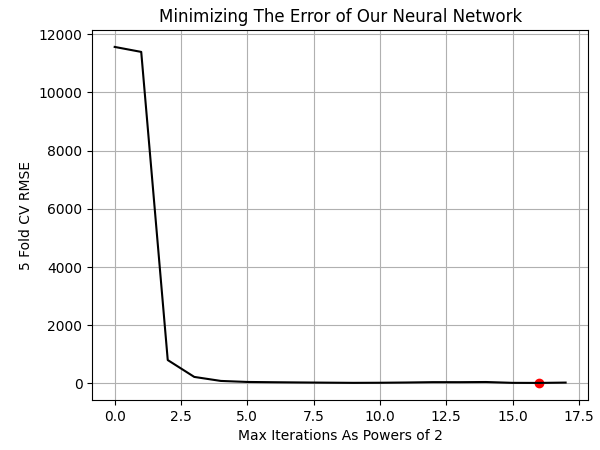
図10:UMAP埋め込みを学習するために必要なモデルの最適なトレーニング反復回数の可視化
次に、両方のモデルを適合させることができます。
#The first model will transform the given market data into its UMAP embeddings umap_transform_model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') umap_transform_model.fit(data.iloc[:,2:-2],new_data) #The second model will forecast the future EURGBP returns, given UMAP embeddings forecast_model = MLPRegressor(hidden_layer_sizes=(new_data.shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') forecast_model.fit(new_data,data['Target'])
モデルをONNX形式にエクスポートする準備をしましょう。
import onnx import netron from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
UMAP埋め込みの推定を担当するモデルは、独特の入力形状と出力形状を持っています。入力として10個のパラメータを受け取り、出力として3個のパラメータを返します。これをONNX APIのinitial_typesとfinal_typesを使って指定します。
umap_transform_shape = [("float_input",FloatTensorType([1,data.iloc[:,2:-2].shape[1]]))] umap_transform_output_shape = [("float_output",FloatTensorType([new_data.shape[1],1]))]
一方で、与えられたUMAP埋め込みから価格変動を予測するモデルは、シンプルな入力と出力の形状を持っています。このモデルは、最初のモデルの3つの出力を入力として受け取り、出力は1つだけ返します。
forecast_shape = [("float_input",FloatTensorType([1,new_data.shape[1]]))]
モデルの入出力の形状を定義します。ここで注意すべき点は、最初のモデルが複数出力であることを明示的に指定する必要があることです。その後、複数出力モデルの形状を設定します。
umap_model_proto = convert_sklearn(umap_transform_model,initial_types=umap_transform_shape,final_types=umap_transform_output_shape,target_opset=12) forecast_model_proto = convert_sklearn(forecast_model,initial_types=forecast_shape,target_opset=12)
モデルを保存します。
onnx.save(umap_model_proto,"EURGBP UMAP.onnx") onnx.save(forecast_model_proto,"EURGBP UMAP Forecast.onnx")
MQL5の始め方
これで、UMAP回帰の収益性を検証するためのMQL5コードの作成を開始できます。図5で示したように、2020年以降のすべてのデータを削除していることを思い出してください。したがって、今回行うバックテストは、これまで見たことのない実際の相場環境下での戦略のパフォーマンスを公平に評価するものとなります。それでは、ONNXモデルを読み込みましょう。
//+------------------------------------------------------------------+ //| UMAP Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ja/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP UMAP.onnx" as uchar umap_onnx_buffer[]; #resource "\\Files\\EURGBP UMAP Forecast.onnx" as uchar umap_forecast_onnx_buffer[];
さらに、いくつかのグローバル変数が必要です。戦略がアルゴリズムに基づいているため、それほど多くは必要ありません。
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ long umap_onnx_model,umap_forecast_onnx_model; vectorf umap_onnx_output(3),umap_forecast_onnx_output(1); double trade_sl;
テクニカル指標のハンドラとバッファを定義します。
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
取引ライブラリを読み込みます。
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
コードの設計を人間に読みやすく保つために、各イベントハンドラごとに関数を割り当てることにしました。これにより、プログラムの本体を最初から最後まで読みやすくなっています。もしユーザーが機能を追加したい場合は、同じ設計原則に従い、追加したい処理をメソッドとしてまとめ、本体から呼び出すことをお勧めします。こうすることで、何百行ものコードがすべて一つのイベントハンドラに詰め込まれている場合と比べて、はるかにメンテナンスしやすいコードベースを維持できます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- update(); } //+------------------------------------------------------------------+
release関数は、エキスパートアドバイザー(EA)が完全に停止する前に後片付けをおこないます。
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Free up system memory | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handler); IndicatorRelease(ma_o_handler); OnnxRelease(umap_onnx_model); OnnxRelease(umap_forecast_onnx_model); }
setup関数は、ONNXモデルやその他重要なシステム変数の初期化を担当します。初期化中に問題が発生した場合は、Boolean型でfalseを返します。それ以外の場合は、trueを返すようにします。ONNXモデルの入出力の形状はペアで管理されており、呼び出しも同様にペアになっています。
//+------------------------------------------------------------------+ //| Setup system variables | //+------------------------------------------------------------------+ bool setup(void) { umap_onnx_model = OnnxCreateFromBuffer(umap_onnx_buffer,ONNX_DATA_TYPE_FLOAT); umap_forecast_onnx_model = OnnxCreateFromBuffer(umap_forecast_onnx_buffer,ONNX_DATA_TYPE_FLOAT); ma_c_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_CLOSE); ma_o_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_OPEN); if(umap_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Transformer ONNX model"); return(false); } if(umap_forecast_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Forecast ONNX model"); return(false); } ulong umap_input_shape[] = { 1 , 10 }; ulong umap_forecast_input_shape[] = { 1 , 3 }; ulong umap_output_shape[] = { 3 , 1 }; ulong umap_forecast_output_shape[] = { 1 , 1 }; if(!OnnxSetInputShape(umap_onnx_model,0,umap_input_shape)) { Comment("Failed to specify ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetInputShape(umap_forecast_onnx_model,0,umap_forecast_input_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_onnx_model,0,umap_output_shape)) { Comment("Failed to specify ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_forecast_onnx_model,0,umap_forecast_output_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } trade_sl = 2e-2; return(true); }
Update関数は、インジケーターの値をバッファにコピーし、日次で定期的に取引処理を実行するのを助けます。
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_CURRENT,0); if(current_time != time_stamp) { time_stamp = current_time; CopyBuffer(ma_c_handler,0,0,1,ma_c); CopyBuffer(ma_o_handler,0,0,1,ma_o); if(PositionsTotal() == 0) { GetModelForecast(); FindSetup(); } } }
予測関数は、予測を連鎖的に実行するために必要です。最初の予測は、元の市場データに対するUMAP埋め込みの近似値を取得することです。2つ目の予測は、そのUMAP埋め込みの近似を入力として受け取り、EUR/GBP市場リターンを予測する、つまり私たちの取引シグナルを生成することです。
//+------------------------------------------------------------------+ //| Get a forecast from our models | //+------------------------------------------------------------------+ void GetModelForecast(void) { vectorf model_inputs = GetUmapModelInputs(); OnnxRun(umap_onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,umap_onnx_output); OnnxRun(umap_forecast_onnx_model,ONNX_DATA_TYPE_FLOAT,umap_onnx_output,umap_forecast_onnx_output); Print("Model Inputs: \n",model_inputs); Print("Umap Transformer Forecast: \n",umap_onnx_output); Print("EURUSD Return UMAP Forecast: \n",umap_forecast_onnx_output); }
予測を取得する前に、モデルへの入力を準備する必要があります。最初に、第1モデルの入力を整形し、その出力を第2モデルの入力として渡すことを忘れないでください。
//+------------------------------------------------------------------+ //| Get our model's input data | //+------------------------------------------------------------------+ vectorf GetUmapModelInputs(void) { vectorf umap_model_inputs(10); umap_model_inputs[0] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iOpen(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[1] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[2] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[3] = (float)(iClose(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[4] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[5] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[6] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[7] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[8] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[9] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); return(umap_model_inputs); } //+------------------------------------------------------------------+
図4と図5で、以下に示す図11の日時と重複する過去データをすべて削除したことを思い出してください。これにより、モデルが学習時に見ていない「アウトオブサンプル」データを扱う際にどのように振る舞うかを確認でき、戦略の真の収益性推定として機能します。

図11:UMAPアンサンブルモデルを評価するためのバックテスト期間
それでは、戦略をテストする条件を決定しましょう。最も信頼性の高い結果を得るために、EAを過酷な状況下でストレステストします。具体的には、バックテストにおいて注文実行から約定までにランダムな遅延を与えることでテストをおこないます。

図12:上記でシミュレーションした条件は、実際の取引シナリオを模倣したものである
ストラテジーテスターの操作ログを見ると、ONNXモデルへの入力と、UMAPモデルの連鎖によって有効な出力が生成されていることが確認できます。最初のモデルは、市場データから取得した10個の入力を正しく3個に削減し、その出力を用いて市場の予測をおこなっています。

図13:内部的にはすべてがうまく機能しているようである
資産曲線は、システムのパフォーマンスに対して好意的なフィードバックを示しているようです。これは、読者の皆さんもご承知のとおり、私たちがUMAPアルゴリズムおよびその埋め込みを単に近似したに過ぎないという状況を踏まえると、非常に心強い結果です。

図14:戦略は今のところ利益を上げているようである
戦略のパフォーマンスをより詳細に検証しましょう。本システムのシャープレシオは0.42、期待ペイオフは7.05と、いずれもポジティブな統計値です。また、利益の出た取引の割合は64%で、合計25回の取引をおこないました。

図15:UMAP回帰を用いた過去のパフォーマンスの詳細な分析
平均すると、各取引は1274時間、つまり約54日間ポジションを保有していました。これは、EAが市場のトレンドを捉えている可能性が高いことを示唆しています。

図16:取引期間の分布を視覚化する
バックテストを精査したところ、EAが確かに市場の持続的なトレンドを捉えていたことが分かりました。下のスクリーンショットでは、縦の白い線が1日を表しており、表示されている取引はすべてバックテスト中にUMAP Regression EAが実行したものです。最初のポジションは2020年4月にオープンし、翌5月にクローズされました。次の取引は5月末に始まり、9月初旬まで保持されました。
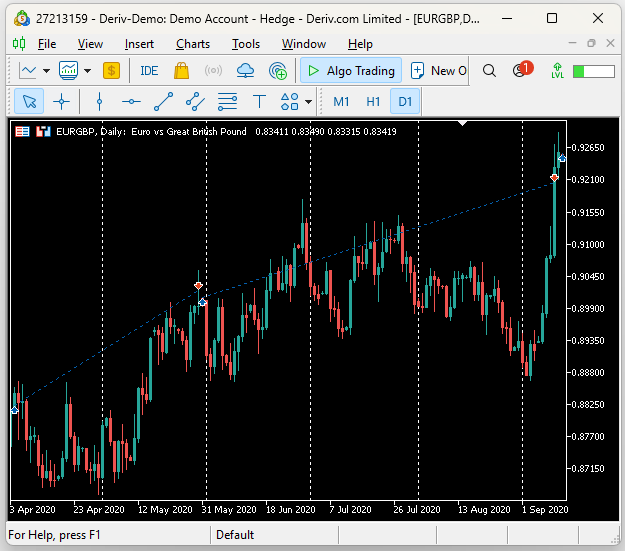
図17:EAによる取引の可視化
結論
本記事では、読者が次元削減技術を活用して、統計モデルにデータ中の主要な市場特徴を学習させる方法を紹介しました。UMAPアルゴリズムを用いることで、統計モデルの誤差率をUMAP変換を行わずに同一条件で学習させたモデルと比較して最大40%低減できることを示しました。最後に、ネイティブ実装が難しいアルゴリズムを安全に近似するための新しいフレームワークを学んだことで、どの市場で取引をおこなう場合でも競争優位性を得るための手段を提供できたと考えています。| ファイル名 | 説明 |
|---|---|
| EURGBP UMAP Forecast.onnx | 近似したUMAP埋め込みを入力として受け取り、将来のEUR/GBPリターンを予測するONNXファイル |
| EURGBP UMAP.onnx | 市場データを入力として受け取り、正しいUMAP埋め込みを近似する役割を果たすONNXファイル |
| UMAP Candlestick Recognition.ipynb | MetaTrader 5の市場データを分析し、ONNXファイルを作成するために使用したJupyter Notebook |
| UMAP Candlestick Recognition.mq5 | 詳細な市場データを取得するために作成したMQL5スクリプトファイル |
| UMAP Regression.mq5 | 2つのモデルアーキテクチャを使用してEURGBPを取引するために構築したEA |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/17631
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ありがとう、これは本当に面白いアプリケーションだ。NameError:名前'FloatTensorType'が定義されていない場合は、onnixxmltoolsをインストールまたはアップデートする必要があります。私のデータは、ここに示されているデータとは全く異なる結果となりました。
MT5用のEAが欲しいのですが、エクスネスブローカーを使用しています。