
どんな市場でも優位性を得る方法(第3回):VISA消費指数

はじめに
ビッグデータの時代、現代の投資家が利用できる代替データの情報源はほぼ無限にあります。各データセットは、市場リターンを予測する際に、より高い精度レベルをもたらす可能性を秘めています。しかし、この約束を果たすデータセットはほとんどありません。この連載では、代替データの広大な領域を探求するお手伝いをし、これらのデータセットを分析に含めるべきかどうかについて、十分な情報に基づいた意思決定をおこなうための支援をします。一方、これらのデータセットが満足のいく結果をもたらさない場合は、読者の時間を節約するお手伝いができます。
その根拠は、MetaTrader 5端末では直接利用できない代替データセットを考慮することで、市場相場だけに依存するカジュアルな市場参加者と比較して、比較的高い精度で価格水準を予測する変数を発見できる可能性があるということです。
取引戦略の概要
VISAはアメリカの多国籍決済サービス会社です。同社は1958年に設立され、今日では世界最大級の取引処理ネットワークを運営しています。VISAは、先進国のほぼすべての市場に浸透しているため、評判の高い代替データの供給源として有利な立場にあります。さらに、セントルイス連邦準備銀行もマクロ経済データの一部をVISAから収集しています。
今回は、VISA支出モメンタム指数(SMI: Spending Momentum Index)を分析します。この指数は、消費者の消費行動を示すマクロ経済指標です。このデータは、VISAが独自のネットワークとVISAブランドのデビットカードやクレジットカードを使って集計しています。データはすべて非個人化されており、ほとんどが米国で収集されたものです。VISAがさまざまな市場のデータを集計し続ければ、この指数はやがて世界の消費者行動のベンチマークとなるかもしれません。
VISA SMIデータセットの取得には、セントルイス連邦準備銀行が提供するAPIサービスを利用します。米連邦準備制度理事会経済データベース(FRED)のAPIを使えば、世界中から収集された数十万のさまざまな経済時系列データにアクセスできます。
方法論の概要
SMIデータはVISAが毎月発表しているもので、本稿執筆時点では200行に満たないものです。そのため、過剰適合に強く、複雑な関係を捉えるのに十分な柔軟性を持つモデリング技術が必要となります。これはニューラルネットワークにとって理想的な仕事かもしれません。
VISAデータセットである通常の始値、高値、安値、終値のセットと3つの追加入力が与えられたEURUSDの変化を分類するために、ディープニューラルネットワークの5つのパラメータを最適化しました。最適化したモデルは、検証で71%の精度を達成することができ、デフォルトのモデルを凌駕しました。ただし、この精度は月次データによるものであることを念頭に置いてください。
ディープニューラルネットワークを最適化するために、ランダムサーチアルゴリズムの1000回の反復を採用し、訓練データに過剰適合することなくモデルの訓練に成功しました。これらの結果は印象的に聞こえるかもしれませんが、観察された関係が信頼できるものであると自信を持って断言することはできません。私たちの特徴量選択アルゴリズムは、ノンパラメトリックな方法で最も重要な特徴量を選択する際、3つのVISAデータセットすべてを破棄しました。さらに、3つのVISAデータセットの相互情報スコアはいずれも比較的低く、これはデータセットが独立しているか、モデルにとって意味のある形で関係を明らかにできていないことを示しているのかもしれません。
データ抽出
必要なデータを取得するには、まずFREDのWebサイトでアカウントを作成する必要があります。アカウントを作成したら、私たちの議論に従って、FRED APIキーを使ってセントルイス連邦準備制度理事会(FRB)が保有する経済時系列データにアクセスできます。EURUSD相場に関する市場データは、MetaTrader 5 Python APIを使用して端末から直接取得されます。
始めるには、まず必要なライブラリをロードします。
#Import the libraries we need import pandas as pd import seaborn as sns import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
ここでFRED APIキーを設定し、必要なデータを取得します。
#Let's setup our FredAPI
fred = Fred(api_key="ENTER YOUR API KEY")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
予測期間を定義します。
#Define how far ahead we want to forecast look_ahead = 10
データを可視化する
3つのデータセットを可視化してみましょう。
visa_discretionary.plot(title="VISA Spending Momentum Index: Discretionary") 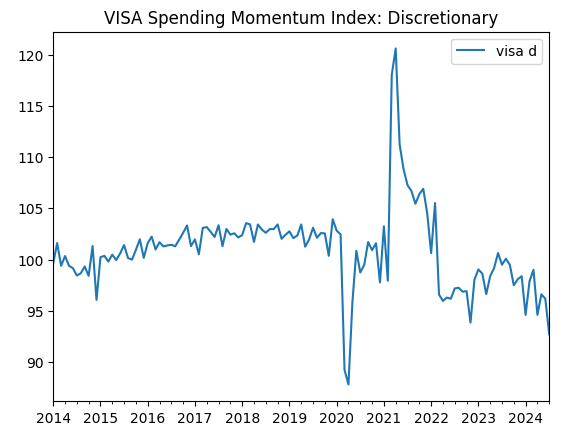
図1:最初のVISAデータセット
では、2つ目のデータセットを可視化してみましょう。
visa_headline.plot(title="VISA Spending Momentum Index: Headline") 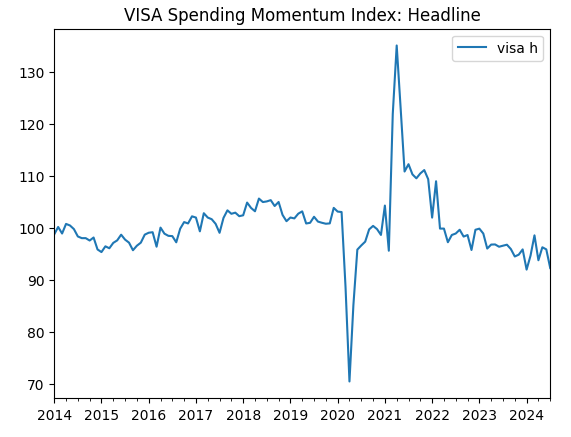
図2:第2のVISAデータセット
そして最後に、3つ目のVISAデータセットです。
visa_non_discretionary.plot(title="VISA Spending Momentum Index: Non-Discretionary") 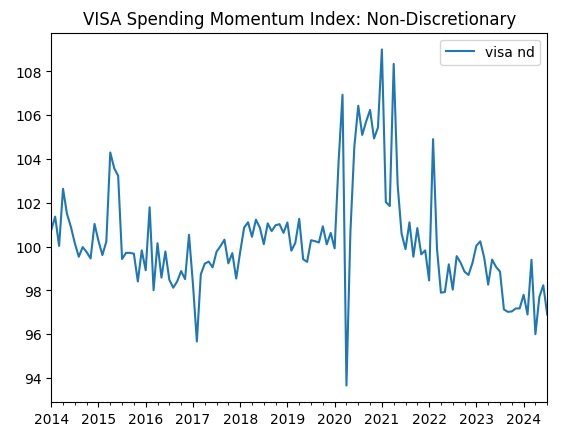
図3:第3のVISAデータセット
最初の2つのデータセットはほとんど同じに見えるが、さらに後述するように、これらのデータセットの相関レベルは0.89であり、同じ情報が含まれている可能性があります。これは、片方を捨ててもう片方を残すことを示唆しています。しかし、それが必要かどうかは、特徴量選択アルゴリズムに判断させます。
MetaTrader 5端末からのデータ取得
これから端末を初期化します。
#Initialize the terminal
mt5.initialize()
ここでタイムゾーンを指定します。
#Set timezone to UTC timezone = pytz.timezone("Etc/UTC")
datetimeオブジェクトを作成します。
#Create a 'datetime' object in UTC utc_from = datetime(2024,7,1,tzinfo=timezone)
MetaTrader 5からデータを取得し、pandasデータフレームにラップします。
#Fetch the data eurusd = pd.DataFrame(mt5.copy_rates_from("EURUSD",mt5.TIMEFRAME_MN1,utc_from,visa_headline.shape[0]))
データにラベルを付け、タイムスタンプをインデックスとして使います。
#Label the data eurusd["target"] = np.nan eurusd.loc[eurusd["close"] > eurusd["close"].shift(-look_ahead),"target"] = 0 eurusd.loc[eurusd["close"] < eurusd["close"].shift(-look_ahead),"target"] = 1 eurusd.dropna(inplace=True) eurusd.set_index("time",inplace=True)
では、両データセットが共有している日付を使って、両データセットを統合しましょう。
#Let's merge the datasets merged_data = eurusd.merge(visa_headline,right_index=True,left_index=True) merged_data = merged_data.merge(visa_discretionary,right_index=True,left_index=True) merged_data = merged_data.merge(visa_non_discretionary,right_index=True,left_index=True)
探索的データ分析
データを調べる準備はできています。散布図は、2つの変数の関係を可視化するのに役立ちます。各VISAデータセットを終値に対してプロットした散布図を見てみましょう。青い点は次の10本のローソク足で価格が下落した場合を、オレンジの点はその逆を表しています。
プロットの中央部ではノイズが多いが、極端なレベルではVISAデータセットは上下の動きを適度に分離しているように見えます。
#Let's create scatter plots sns.scatterplot(data=merged_data,y="close",x="visa h",hue="target").set(title="EURUSD Close Against VISA Momentum Index: Headline")
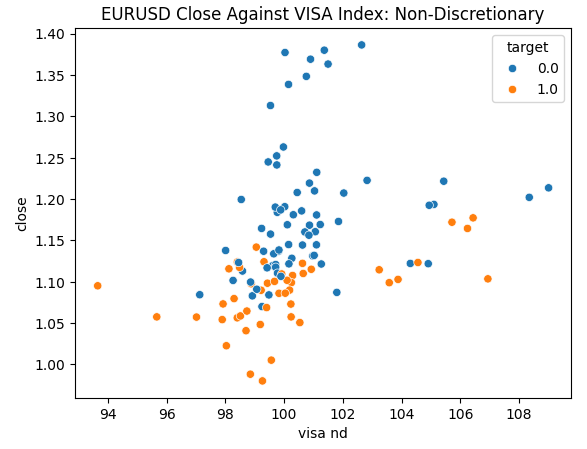
図4:EURUSD終値に対する無裁量VISAデータセットのプロット
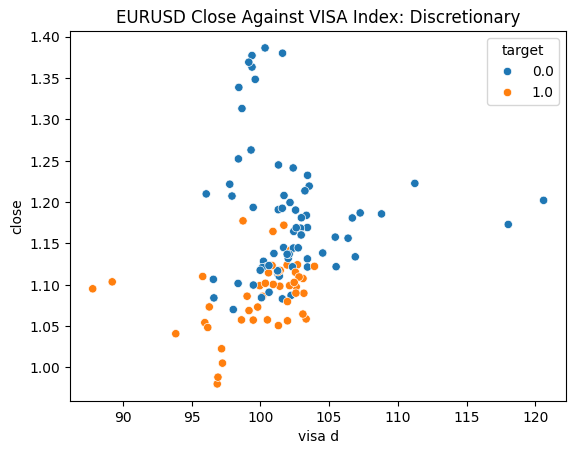
図5:EURUSD終値に対する裁量VISAデータセットのプロット
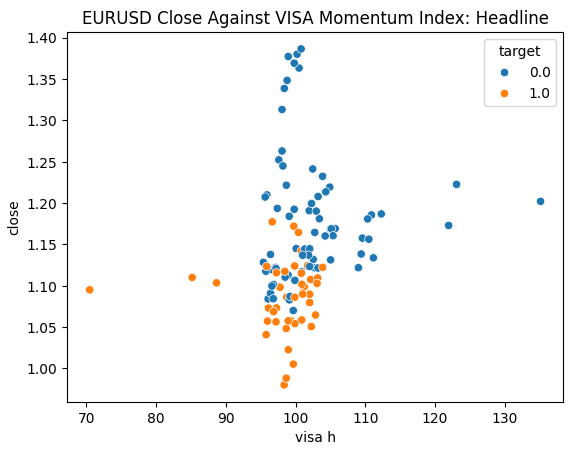
図6:EURUSD終値に対するヘッドラインVISAデータセットのプロット
VISAデータセットとEURUSD市場との相関レベルは中程度で、すべて正の値です。どの相関レベルも、私たちにとっては特に興味深いものではありません。しかし、正の値は2つの変数が共に上昇下降する傾向があることを示していることは注目に値します。これはマクロ経済学の理解に沿ったもので、アメリカの消費支出は為替レートにある程度の影響を与えます。消費者が一斉に消費しないことを選択した場合、彼らの行動は通貨流通総額を減らし、ドル高を引き起こす可能性があります。
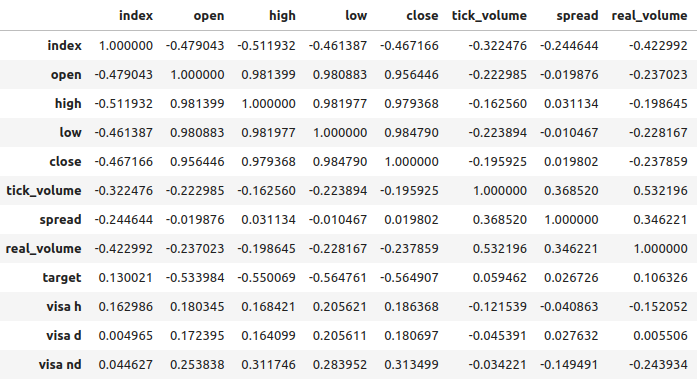
図7:データセットの相関分析
特徴量の選択
ターゲットと新しい特徴量の関係はどの程度重要なのでしょうか。新しい特徴量が特徴量選択アルゴリズムによって除去されるかどうかを観察してみましょう。私たちのアルゴリズムが新しい変数を選択しない場合、これは関係が信頼できないことを示している可能性があります。
前方選択アルゴリズムは、帰無モデルから始まり、一度に1つの特徴を追加し、そこから最良の単一変数モデルを選択し、次に2つ目の変数の探索を開始する、といった具合です。そして、その最高のモデルを私たちに返却します。私たちの研究では、アルゴリズムによって選択されたのは始値だけであり、これは関係が安定していない可能性を示しています。
必要なライブラリをインポートします。
#Let's see which features are the most important from mlxtend.feature_selection import SequentialFeatureSelector as SFS from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
前方選択オブジェクトを作成します。
#Create the forward selection object sfs = SFS( MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"]), k_features=(1,train_X.shape[1]), forward=False, scoring="accuracy", cv=5 ).fit(train_X,train_y)
結果をプロットしてみましょう。
fig1 = plot_sfs(sfs.get_metric_dict(),kind="std_dev") plt.title("Neural Network Backward Feature Selection") plt.grid()
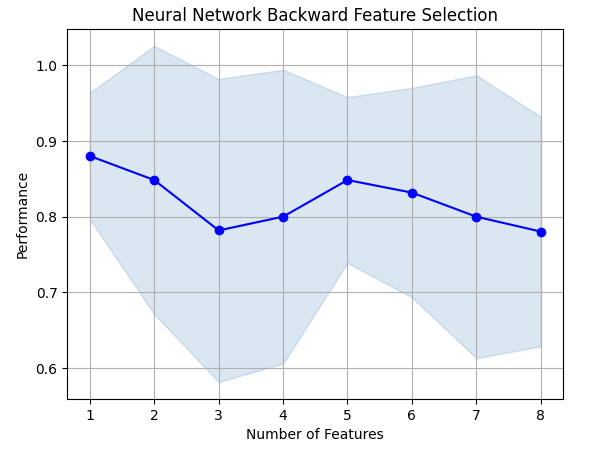
図8:モデルの特徴数の増加に伴うパフォーマンスの悪化
残念なことに、特徴を増やすにつれて精度は落ちていきました。これは単に関連性がそれほど強くないか、モデルが解釈できるような方法で関連性を明らかにしていないかのどちらかでしょう。そのため、1つの特徴を備えたモデルでも仕事をこなせる可能性があるようです。
私たちが確認した最高の特徴量。
sfs.k_feature_names_
ここで、相互情報量(MI)スコアを観察してみましょう。MIスコアは正の値であり、理論的には0から無限大までの範囲であるが、実際には2以上のMIスコアが観測されることは稀であり、1以上のMIスコアは良好です。
scikit-learnからMI分類器をインポートします。
#Mutual information
from sklearn.feature_selection import mutual_info_classif ヘッドラインデータセットのMIスコア。
#Mutual information from the headline visa dataset, print(f"VISA Headline dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa h']],train_y)[0]}")
一任データセットのMIスコア。
#Mutual information from the second visa dataset, print(f"VISA Discretionary dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa d']],train_y)[0]}")
このことは、VISAデータセットにさまざまな変換を施してみるべき説得力のある理由かもしれません。
パラメータチューニング
それでは、EURUSDを予測するためにディープニューラルネットワークをチューニングしてみましょう。その前に、データをスケーリングする必要があります。まず、結合したデータセットのインデックスをリセットします。
#Reset the index
merged_data.reset_index(inplace=True)
ターゲットと予測変数を定義します。
#Define the target target = "target" ohlc_predictors = ["open","high","low","close","tick_volume"] visa_predictors = ["visa d","visa h","visa nd"] all_predictors = ohlc_predictors + visa_predictors
では、データをスケーリングして変換してみましょう。データセットの各値から平均を引き、それぞれの列の標準偏差で割ります。この変換は外れ値に敏感であることは注目に値します。
#Let's scale the data scale_factors = pd.DataFrame(index=["mean","standard deviation"],columns=all_predictors) for i in np.arange(0,len(all_predictors)): #Store the mean and standard deviation for each column scale_factors.iloc[0,i] = merged_data.loc[:,all_predictors[i]].mean() scale_factors.iloc[1,i] = merged_data.loc[:,all_predictors[i]].std() merged_data.loc[:,all_predictors[i]] = ((merged_data.loc[:,all_predictors[i]] - scale_factors.iloc[0,i]) / scale_factors.iloc[1,i]) scale_factors
スケーリングされたデータを見てみましょう。
#Let's see the normalized data merged_data
標準ライブラリのインポート
#Lets try to train a deep neural network to uncover relationships in the data from sklearn.neural_network import MLPClassifier from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
訓練とテストの分割をおこないます。
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"],test_size=0.5,shuffle=False)
利用可能な入力に合わせてモデルを調整します。最初にチューニングしたいモデルを渡し、次に関心のあるモデルのパラメータを指定しなければならないことを思い出してください。その後、交差検証に使用するフォールド数を指定する必要があります。
tuner = RandomizedSearchCV(MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="accuracy", return_train_score=False )
チューナーの適合
tuner.fit(train_X,train_y)
訓練データで得られた結果を、良いものから悪いものの順に見てみましょう。
tuner_results = pd.DataFrame(tuner.cv_results_) params = ["param_activation","param_solver","param_alpha","param_learning_rate","param_learning_rate_init","mean_test_score"] tuner_results.loc[:,params].sort_values(by="mean_test_score",ascending=False)

図9:最適化の結果
訓練データでの最高精度は88%でした。なお、今回選択した最適化アルゴリズムは確率的なものであるため、このデモで得られた結果を再現するのは難しいかもしれません。
過剰適合のテスト
ここで、デフォルトモデルとカスタマイズモデルを比較して、訓練データに過剰適合しているかどうかを確認してみましょう。もし過剰適合していれば、検証セット上ではデフォルトモデルがカスタマイズモデルを上回り、そうでなければカスタマイズモデルの方が良い結果を出す。
2つのモデルを用意しましょう。
#Let's compare the default model and our customized model on the hold out set default_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
デフォルトモデルの精度を測定します。
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
accuracy_score(test_y,default_model.predict(test_X))
次に、カスタマイズされたモデルの精度です。
#The accuracy of the defualt model
customized_model.fit(train_X,train_y)
accuracy_score(test_y,customized_model.predict(test_X))
訓練データに過剰適合することなくモデルを訓練できたようです。また、訓練誤差は通常、テスト誤差よりも常に大きいことに注意。しかし、両者の差が大きすぎることはないはずです。訓練エラーは88%、テストエラーは74%で、これは妥当な結果です。訓練誤差とテスト誤差の間に大きなギャップがある場合は、過剰適合の可能性がある!
戦略の実施
まず、使用するグローバル変数を定義します。
#Let us now start building our trading strategy SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_MN1 DEVIATION = 1000 VOLUME = 0 LOT_MULTIPLE = 1
MetaTrader 5端末を初期化してみましょう。
#Get the system up
if not mt5.initialize():
print('Failed To Log in')
市場についてもっと詳しく知る必要があります。
#Let's fetch the trading volume
for index,symbol in enumerate(mt5.symbols_get()):
if symbol.name == SYMBOL:
print(f"{symbol.name} has minimum volume: {symbol.volume_min}")
VOLUME = symbol.volume_min * LOT_MULTIPLE
この関数は、現在の市場価格を取得します。
#A function to get current prices def get_prices(): start = datetime(2024,1,1) end = datetime.now() data = pd.DataFrame(mt5.copy_rates_range(SYMBOL,TIMEFRAME,start,end)) data['time'] = pd.to_datetime(data['time'],unit='s') data.set_index('time',inplace=True) return(data.iloc[-1,:])
FRED APIから最新の代替データを取得する関数も作ります。
#A function to get our alternative data def get_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] return(visa_d,visa_h,visa_n)
入力を正規化し、スケーリングする関数が必要です。
#A function to prepare the inputs for our model def get_model_inputs(): LAST_OHLC = get_prices() visa_d , visa_h , visa_n = get_alternative_data() return( np.array([[ ((LAST_OHLC['open'] - scale_factors.iloc[0,0]) / scale_factors.iloc[1,0]), ((LAST_OHLC['high'] - scale_factors.iloc[0,1]) / scale_factors.iloc[1,1]), ((LAST_OHLC['low'] - scale_factors.iloc[0,2]) / scale_factors.iloc[1,2]), ((LAST_OHLC['close'] - scale_factors.iloc[0,3]) / scale_factors.iloc[1,3]), ((LAST_OHLC['tick_volume'] - scale_factors.iloc[0,4]) / scale_factors.iloc[1,4]), ((visa_d - scale_factors.iloc[0,5]) / scale_factors.iloc[1,5]), ((visa_h - scale_factors.iloc[0,6]) / scale_factors.iloc[1,6]), ((visa_n - scale_factors.iloc[0,7]) / scale_factors.iloc[1,7]) ]]) )
手持ちのすべてのデータでモデルを訓練してみましょう。
#Let's train our model on all the data we have model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation="logistic",solver="lbfgs",alpha=0.00001,learning_rate="constant",learning_rate_init=0.00001) model.fit(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"])
この関数はモデルから予測を得ます。
#A function to get a prediction from our model def ai_forecast(): model_inputs = get_model_inputs() prediction = model.predict(model_inputs) return(prediction[0])
これでアルゴリズムの核心にたどり着きました。まず、ポジションの数を確認します。次に、モデルから予測を得ます。ポジションがない場合は、モデルの予測を使ってポジションを建てます。そうでなければ、ポジションが建っている場合、モデルの予測をエグジットシグナルとして使用します。
while True: #Get data on the current state of our terminal and our portfolio positions = mt5.positions_total() forecast = ai_forecast() BUY_STATE , SELL_STATE = False , False #Interpret the model's forecast if(forecast == 0.0): SELL_STATE = True BUY_STATE = False elif(forecast == 1.0): SELL_STATE = False BUY_STATE = True print(f"Our forecast is {forecast}") #If we have no open positions let's open them if(positions == 0): print(f"We have {positions} open trade(s)") if(SELL_STATE): print("Opening a sell position") mt5.Sell(SYMBOL,VOLUME) elif(BUY_STATE): print("Opening a buy position") mt5.Buy(SYMBOL,VOLUME) #If we have open positions let's manage them if(positions > 0): print(f"We have {positions} open trade(s)") for pos in mt5.positions_get(): if(pos.type == 1): if(BUY_STATE): print("Closing all sell positions") mt5.Close(SYMBOL) if(pos.type == 0): if(SELL_STATE): print("Closing all buy positions") mt5.Close(SYMBOL) #If we have finished all checks then we can wait for one day before checking our positions again time.sleep(24 * 60 * 60)
We have 0 open trade(s)
Opening a sell position
MQL5での実装
MQL5で戦略を実行するには、まずモデルをOpen Neural Network Exchange(ONNX)形式にエクスポートする必要があります。ONNXは、機械学習モデルをグラフとエッジの組み合わせで表現するためのプロトコルです。この標準化されたプロトコルにより、開発者は異なるプログラミング言語を使用して機械学習モデルを簡単に構築し、展開することができます。残念ながら、すべての機械学習モデルやフレームワークが現在のONNX APIで完全にサポートされているわけではありません。
手始めに、いくつかのライブラリをインポートしましょう。
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
そして、必要なデータにアクセスするために、FRED APIキーを入力する必要があります。
#Let's setup our FredAPI
fred = Fred(api_key="")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
データを取得した後、上で説明したのと同じ形式でスケーリングしました。同じ情報の繰り返しを避けるため、これらの手順は省略しました。唯一のわずかな違いは、バイナリターゲットだけでなく、実際の終値を予測するためにモデルを訓練していることです。
データをスケーリングした後、モデルのパラメータを調整してみましょう。
#A few more libraries we need from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error
モデルを最適化するための訓練セットと、過剰適合をテストするための検証セットを持つように、データを分割する必要があります。
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"close target"],test_size=0.5,shuffle=False)
次にハイパーパラメータのチューニングをおこないます。スコアリングメトリックを「neg mean squared error」に設定していることに注意してください。このスコアリング メトリックは、最も低い MSE を生成するモデルを最高のパフォーマンスのモデルとして識別します。
tuner = RandomizedSearchCV(MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,early_stopping=True), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="neg_mean_squared_error", return_train_score=False, n_jobs=-1 )
チューナーオブジェクトの適合
tuner.fit(train_X,train_y)
ここで過剰適合をテストしてみましょう。
#Let's compare the default model and our customized model on the hold out set default_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
以下は、デフォルトモデルの精度です。
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
保留中の検証セットでは、デフォルト モデルを上回るパフォーマンスを発揮できました。これは、過剰適合していないことを示す良い兆候です。
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
0.006138795093781729
ONNX形式にエクスポートする前に、カスタマイズしたモデルをすべてのデータに適合してみましょう。
#Fit the model on all the data we have
customized_model.fit(test_X,test_y)
ONNX変換ライブラリのインポート
#Convert to ONNX
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn
import netron
import onnx モデルの入力タイプと形状を定義します。
#Define the initial types initial_types = [("float_input",FloatTensorType([1,train_X.shape[1]]))]
メモリ内にモデルのONNX表現を作成します。
#Create the onnx representation onnx_model = convert_sklearn(customized_model,initial_types=initial_types,target_opset=12)
ONNX表現をハードドライブに保存します。
#Save the ONNX model onnx_model_name = "EURUSD VISA MN1 FLOAT.onnx" onnx.save(onnx_model,onnx_model_name)
ONNXモデルをNetronで確認します。
#View the ONNX model
netron.start(onnx_model_name) 
図10:ONNX形式のディープニューラルネットワーク

図11:ONNXモデルのメタデータ
EAの構築はほぼ完了しましたが、まずFREDからデータを取得し、それをプログラムに渡すバックグラウンドのPythonサービスを作成する必要があります。
まず、必要なライブラリをインポートします。
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred from datetime import datetime
FREDの認証情報を使ってログインします。
#Let's setup our FredAPI fred = Fred(api_key="")
データを取得してCSVに書き出す関数を定義します。
#A function to write out our alternative data to CSV def write_out_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] data = pd.DataFrame(np.array([visa_d,visa_h,visa_n]),columns=["Data"],index=["Discretionary","Headline","Non-Discretionary"]) data.to_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\fred_visa.csv")
1日に1回、新しいデータを確認してCSVファイルを更新するループを書きます。
while True: #Update the fred data for our MT5 EA write_out_alternative_data() #If we have finished all checks then we can wait for one day before checking for new data time.sleep(24 * 60 * 60)FREDの最新データにアクセスできるようになったので、EAを作り始めることができます。
We will first load our ONNX model as a resource into our application. //+------------------------------------------------------------------+ //| VISA EA.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resorces | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD VISA MN1 FLOAT.onnx" as const uchar onnx_buffer[];
ポジションを建て、管理するのに役立つ取引ライブラリをロードします。
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
ここまでで、アプリケーションはうまくまとまりつつあるので、アプリケーションのさまざまなブロックで使うグローバル変数を作ってみましょう。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[8],std_values[8]; float visa_data[3]; vector model_forecast = vector::Zeros(1); double trading_volume = 0.3; int state = 0;
ONNXモデルを使い始める前に、まずプログラムの最初に必要なリソースからONNXモデルを作成する必要があります。その後、モデルの入出力の形状を定義します。
//+------------------------------------------------------------------+ //| Load the ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- Try create the ONNX model from the buffer we have onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the model if(onnx_model == INVALID_HANDLE) { Comment("Failed to create the ONNX model. ",GetLastError()); return(false); } //--- Set the I/O shape ulong input_shape[] = {1,8}; ulong output_shape[] = {1,1}; //--- Validate the I/O shapes if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape. ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape. ",GetLastError()); return(false); } return(true); }
列の平均を引き、各列の標準偏差で割ることによってデータを標準化したことを思い出してください。これらの値をメモリに保存する必要があります。これらの値が変わることはないので、単純にプログラムにハードコードしました。
//+------------------------------------------------------------------+ //| Mean & Standard deviation values | //+------------------------------------------------------------------+ void load_scaling_values(void) { //--- Mean & standard deviation values for the EURUSD OHLCV mean_values[0] = 1.146552; std_values[0] = 0.08293; mean_values[1] = 1.165568; std_values[1] = 0.079657; mean_values[2] = 1.125744; std_values[2] = 0.083896; mean_values[3] = 1.143834; std_values[3] = 0.080655; mean_values[4] = 1883520.051282; std_values[4] = 826680.767222; //--- Mean & standard deviation values for the VISA datasets mean_values[5] = 101.271017; std_values[5] = 3.981438; mean_values[6] = 100.848506; std_values[6] = 6.565229; mean_values[7] = 100.477269; std_values[7] = 2.367663; }
作成したPythonのバックグラウンドサービスは、常に最新のデータを提供してくれるので、そのCSVを読み込んで配列に格納する関数を作ってみましょう。
//+-------------------------------------------------------------------+ //| Read in the VISA data | //+-------------------------------------------------------------------+ void read_visa_data(void) { //--- Read in the file string file_name = "fred_visa.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 10) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value); if(counter == 3) { Print("Discretionary data: ",value); visa_data[0] = (float) value; } if(counter == 5) { Print("Headline data: ",value); visa_data[1] = (float) value; } if(counter == 7) { Print("Non-Discretionary data: ",value); visa_data[2] = (float) value; } if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //--- Show the VISA data Print("VISA DATA: "); ArrayPrint(visa_data); //---Close the file FileClose(result); } }
最後に、モデルから予測を得るための関数を定義しなければなりません。まず、現在の入力をfloatベクトルに格納します。ONNXの初期型を作成するときに定義したように、このモデルにはfloat型の入力があるからです。
入力値をモデルに渡す前に、列の平均を引き、列の標準偏差で割ることによって、各入力値をスケーリングしなければならないことを思い出してください。
//+--------------------------------------------------------------+ //| Get a prediction from our model | //+--------------------------------------------------------------+ void model_predict(void) { //--- Fetch input data read_visa_data(); vectorf input_data = {(float)iOpen("EURUSD",PERIOD_MN1,0), (float)iHigh("EURUSD",PERIOD_MN1,0), (float)iLow("EURUSD",PERIOD_MN1,0), (float)iClose("EURUSD",PERIOD_MN1,0), (float)iTickVolume("EURUSD",PERIOD_MN1,0), (float)visa_data[0], (float)visa_data[1], (float)visa_data[2] }; //--- Scale the data for(int i =0; i < 8;i++) { input_data[i] = (float)((input_data[i] - mean_values[i])/std_values[i]); } //--- Show the input data Print("Input data: ",input_data); //--- Obtain a forecast OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT|ONNX_DEFAULT,input_data,model_forecast); } //+------------------------------------------------------------------+
では、初期化手順を定義しましょう。まずONNXモデルをロードし、次にVISAデータセットを読み込み、最後にスケーリング値をロードします。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!load_onnx_model()) { //--- We failed to load the ONNX model return(INIT_FAILED); } //--- Read the VISA data read_visa_data(); //--- Load scaling values load_scaling_values(); //--- We were successful return(INIT_SUCCEEDED); }
プログラムが使われなくなったときはいつでも、もう必要のないリソースを解放します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we don't need OnnxRelease(onnx_model); ExpertRemove(); }
新しい価格データが入手可能になると、まずモデルから予測を取得します。ポジションがない場合は、モデルによって生成されたエントリに従います。最後に、ポジションがある場合は、AIモデルを使って価格の反転の可能性を事前に察知します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Get a prediction from our model model_predict(); Comment("Model forecast: ",model_forecast[0]); //--- Check if we have any positions if(PositionsTotal() == 0) { //--- Note that we have no trades open state = 0; //--- Find an entry and take note if(model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Sell(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,"Gain an Edge VISA"); state = 1; } if(model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Buy(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,"Gain an Edge VISA"); state = 2; } } //--- If we have positions open, check for reversals if(PositionsTotal() > 0) { if(((state == 1) && (model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0))) || ((state == 2) && (model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)))) { Alert("Reversal detected, closing positions now"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

図12:VISA EA

図13:プログラムのサンプル出力

図14:アプリケーションの動作
結論
この記事では、取引戦略に役立つデータを選択する方法を紹介しました。これまで、代替データの潜在的な強さを測定する方法や、過剰適合せずに可能な限りパフォーマンスを引き出せるようにモデルを最適化する方法について説明してきました。調査すべきデータセットは何十万にも及ぶ可能性があり、私たちは最も有益な情報を特定するお手伝いをすることに全力を尽くしています。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15575
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ありがとう、ガム
素晴らしい記事だ!
いつもありがとう。いつもながらよく書けている。データセットからどのように視覚化し、スケーリングし、テストし、オーバーフィッティングをチェックし、データフィードを実装し、予測し、取引システムを実装するかについて、素晴らしいコメントのテンプレートです。 ファンタスティックに感謝します。