Artículos sobre análisis de datos y estadísticas en MQL5
Los artículos sobre los modelos matemáticos y leyes de probabilidades serán interesantes para muchos operadores. Es que las matemáticas han sido puestas como base de los indicadores, y el conocimiento de las estadísticas es necesario para el análisis de los resultados del trading y el desarrollo de las estrategias.
Lea sobre la lógica difusa, filtros digitales, perfil del mercado, mapas de Kohonen, gas neuronal y muchas otras herramientas que pueden ser utilizadas para el trading.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Redes neuronales: así de sencillo (Parte 21): Autocodificadores variacionales (VAE)
En el anterior artículo, vimos el algoritmo del autocodificador. Como cualquier otro algoritmo, tiene ventajas y desventajas. En la implementación original, el autocodificador se encarga de dividir los objetos de la muestra de entrenamiento tanto como sea posible. Y en este artículo, en cambio, hablaremos de cómo solucionar algunas de sus deficiencias.

Automatización de estrategias comerciales con la estrategia de tendencia Parabolic SAR en MQL5: Creación de un asesor experto eficaz
En este artículo, automatizaremos las estrategias comerciales con la estrategia Parabolic SAR en MQL5: Creación de un asesor experto eficaz. El EA realizará operaciones basadas en las tendencias identificadas por el indicador Parabolic SAR.

Representaciones en el dominio de la frecuencia de series temporales: El espectro de potencia
En este artículo, veremos métodos asociados con el análisis de series temporales en el dominio de la frecuencia. También prestaremos atención a los beneficios del estudio de las funciones espectrales de series temporales al construir modelos predictivos. Además, analizaremos algunas perspectivas prometedoras para el análisis de series temporales en el dominio de la frecuencia utilizando la transformada discreta de Fourier (DFT).

Biblioteca para el desarrollo rápido y sencillo de programas para MetaTrader (Parte VIII): Eventos de modificación de órdenes y posiciones
En artículos anteriores, comenzamos a crear una gran biblioteca multiplataforma, cuyo cometido es simplificar la escritura de programas para las plataformas MetaTrader 5 y MetaTrader 4. En el séptimo artículo, añadimos el seguimiento de los eventos de activación de órdenes StopLimit y preparamos la funcionalidad para monitorear el resto de eventos que tienen lugar con las órdenes y posiciones. En el presente artículo, vamos a crear una clase que monitoreará los eventos de modificación de las órdenes y posiciones de mercado.

Redes neuronales: así de sencillo (Parte 19): Reglas asociativas usando MQL5
Continuamos con el tema de la búsqueda de reglas asociativas. En el artículo anterior, vimos los aspectos teóricos de este tipo de problemas. En el presente artículo, mostraremos la implementación del método FP-Growth usando MQL5. Y también pondremos a prueba nuestra aplicación con datos reales.
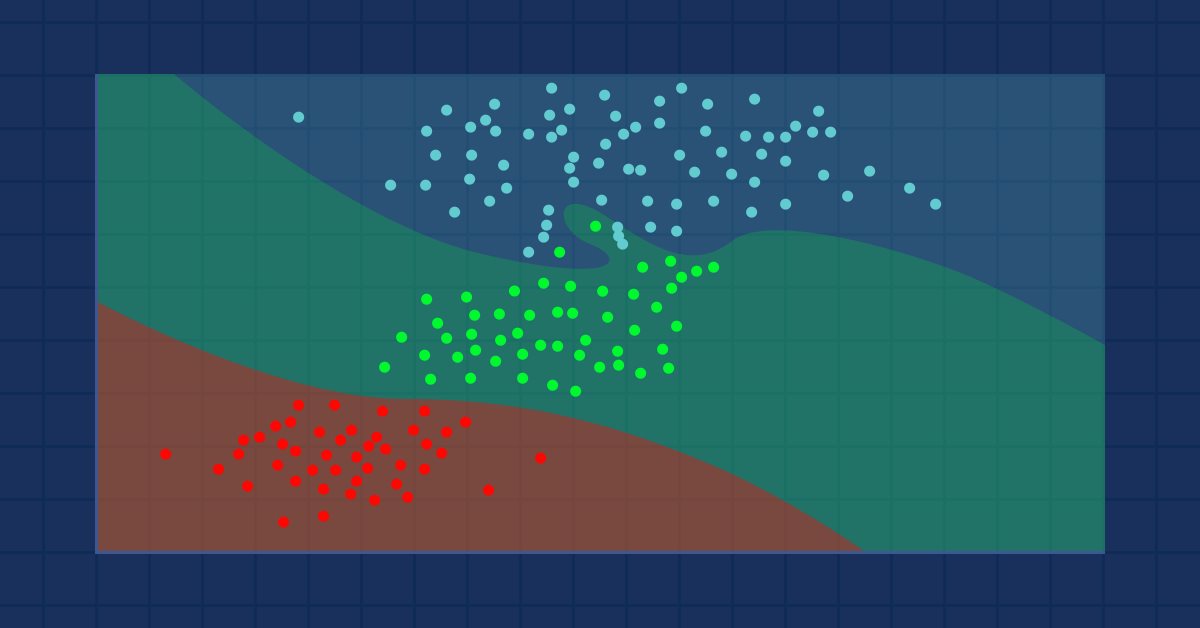
Aprendizaje automático y Data Science (Parte 9): Algoritmo de k vecinos más próximos (KNN)
Se trata de un algoritmo perezoso que no aprende a partir de una muestra de entrenamiento, sino que almacena todas las observaciones disponibles y clasifica los datos en cuanto recibe una nueva muestra. A pesar de su sencillez, este método se usa en muchas aplicaciones del mundo real.
Otras clases en la biblioteca DoEasy (Parte 66): Clases de Colección de Señales MQL5.com
En este artículo, crearemos una clase de colección de señales del Servicio de señales de MQL5.com con funciones para gestionar las señales suscritas, y también modificaremos la clase del objeto de instantánea de la profundidad de mercado para mostrar el volumen total de la profundidad de mercado de compra y venta.
Otras clases en la biblioteca DoEasy (Parte 72): Seguimiento y registro de parámetros de los objetos de gráfico en la colección
En el presente artículo, finalizaremos el trabajo con las clases de los objetos de gráfico y sus colecciones. Implementaremos el seguimiento automático del cambio de las propiedades de los gráficos y sus ventanas, y también el almacenamiento de los parámetros en las propiedades del objeto. Estas mejoras nos permitirán en el futuro crear una funcionalidad de eventos para la colección de gráficos al completo.

Sistema de arbitraje de alta frecuencia en Python con MetaTrader 5
Hoy vamos a crear un sistema de arbitraje legal a los ojos de los brókeres, que creará miles de precios sintéticos en el mercado Fórex, los analizará y negociará con éxito para obtener beneficios.

Aprendizaje automático y data science (Parte 04): Predicción de una caída bursátil
En este artículo, intentaremos usar nuestro modelo logístico para predecir una caída del mercado de valores según las principales acciones de la economía estadounidense: NETFLIX y APPLE. Analizaremos estas acciones, y también usaremos la información sobre las anteriores caídas del mercado en 2019 y 2020. Veamos cómo funcionará nuestro modelo en las poco favorables condiciones actuales.

Enfoque ideal sobre el desarrollo y el análisis de sistemas comerciales
En el presente artículo, trataremos de mostrar con qué criterio elegir un sistema o señal para invertir nuestro dinero, además de cuál es el mejor enfoque para desarrollar sistemas comerciales y por qué este tema es tan importante en el comercio en fórex.

Búsqueda de patrones arbitrarios de pares de divisas en Python con ayuda de MetaTrader 5
¿Existen patrones y regularidades recurrentes en el mercado de divisas? He decidido crear mi propio sistema de análisis de patrones usando Python y MetaTrader 5. Una simbiosis de matemáticas y programación para conquistar Fórex.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 01): Primeros experimentos (I)
¿Qué te parece crear un sistema para estudiar el mercado cuando está cerrado o simular situaciones de mercado? Aquí iniciaremos una nueva secuencia de artículos para tratar este tema.
Trabajando con las series temporales en la biblioteca DoEasy (Parte 45): Búferes de indicador de periodo múltiple
En el artículo, comenzaremos a mejorar los objetos de búfer de indicador y la clase de colección de búferes para trabajar en los modos de periodo y símbolo múltiples. Asimismo, analizaremos el funcionamiento de los objetos de búfer para obtener y mostrar los datos desde cualquier marco temporal en el gráfico actual del símbolo actual.
Gradient boosting en el aprendizaje de máquinas transductivo y activo
En este artículo, el lector podrá familiarizarse con los métodos de aprendizaje automático activo basados en datos reales, descubriendo además cuáles son sus ventajas y desventajas. Puede que estos métodos terminen por ocupar un lugar en su arsenal de modelos de aprendizaje automático. El término transducción fue introducido por Vladímir Naúmovich Vápnik, el inventor de la máquina de vectores de soporte (SVM).
Redes neuronales: así de sencillo (Parte 34): Función cuantílica totalmente parametrizada
Seguimos analizando algoritmos de aprendizaje Q distribuidos. En artículos anteriores hemos analizado los algoritmos de aprendizaje Q distribuido y cuantílico. En el primero, enseñamos las probabilidades de los rangos de valores dados. En el segundo, enseñamos los rangos con una probabilidad determinada. Tanto en el primer algoritmo como en el segundo, usamos el conocimiento a priori de una distribución y enseñamos la otra. En el presente artículo, veremos un algoritmo que permite al modelo aprender ambas distribuciones.
Características del Wizard MQL5 que debe conocer (Parte 5): Cadenas de Markov
Las cadenas de Markov son una poderosa herramienta matemática que se puede usar para modelar y predecir los datos de las series temporales en varios campos, incluido el financiero. En el modelado y la previsión de series temporales financieras, las cadenas de Markov se usan a menudo para modelar la evolución de los activos financieros a lo largo del tiempo, como los precios de las acciones o los tipos de cambio. Una de las principales ventajas de los modelos de cadenas de Markov es su simplicidad y sencillez de uso.

Algoritmos de optimización de la población: Algoritmo de gotas de agua inteligentes (Intelligent Water Drops, IWD)
El artículo analiza un interesante algoritmo, las gotas de agua inteligentes, IWD, presente en la naturaleza inanimada, que simula el proceso de formación del cauce de un río. Las ideas de este algoritmo han permitido mejorar significativamente el anterior líder de la clasificación, el SDS, y el nuevo líder (SDSm modificado); como de costumbre, se puede encontrar en el archivo del artículo.
Biblioteca para el desarrollo rápido y sencillo de programas para MetaTrader (Parte VI): Eventos en la cuenta con compensación
En anteriores artículos comenzamos a crear una gran biblioteca multiplataforma cuyo objetivo es simplificar la escritura de programas para las plataformas MetaTrader 5 y MetaTrader 4. En la quinta parte, hemos creado las clases de los eventos comerciales y la colección de eventos desde donde se envían los eventos a la objeto de la biblioteca Engine y al gráfico del programa de control. En esta parte de la descripción, vamos a añadir la posibilidad de trabajar con la biblioteca en las cuentas de tipo compensación.

El criterio de homogeneidad de Smirnov como indicador de la no estacionariedad de las series temporales
El artículo analiza uno de los criterios de homogeneidad no paramétricos más famosos: el criterio de Smirnov. Asimismo, se consideran tanto datos modelo como cotizaciones reales, y se ofrece un ejemplo de construcción de un indicador de no estacionariedad (iSmirnovDistance).

Redes neuronales: así de sencillo (Parte 16): Uso práctico de la clusterización
En el artículo anterior, creamos una clase para la clusterización de datos. En este artículo, queremos compartir con el lector diferentes opciones de uso de los resultados obtenidos para resolver problemas prácticos en el trading.
Trabajando con las series temporales en la biblioteca DoEasy (Parte 44): Las clases de colección de los objetos de búferes de indicador
En el artículo, analizaremos la creación de la clase de colección de los objetos de búferes de indicador y pondremos a prueba la posibilidad de crear cualquier número de búferes para los programas-indicadores, así como la posibilidad de trabajar con estos (el número máximo de búferes que se pueden crear en los indicadores MQL es de 512).
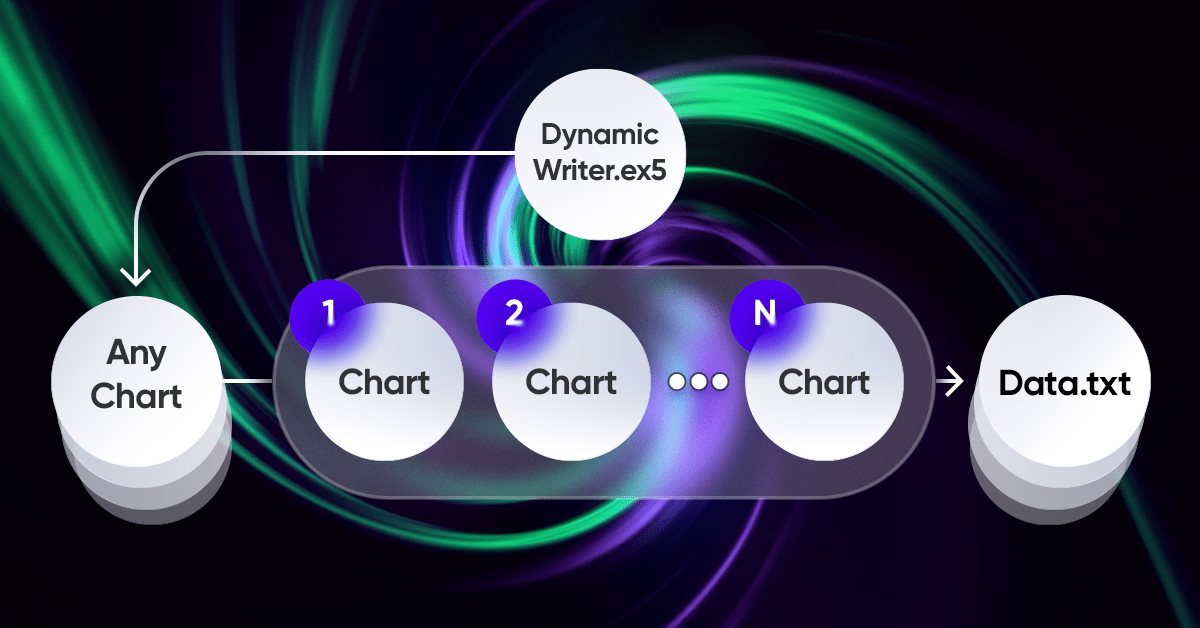
Aproximación por fuerza bruta a la búsqueda de patrones (Parte VI): Optimización cíclica
En este artículo mostraremos la primera parte de las mejoras que nos permitieron no solo cerrar toda la cadena de automatización para comerciar en MetaTrader 4 y 5, sino también hacer algo mucho más interesante. A partir de ahora, esta solución nos permitirá automatizar completamente tanto el proceso de creación de asesores como el proceso de optimización, así como minimizar el gasto de recursos a la hora de encontrar configuraciones comerciales efectivas.

Python, ONNX y MetaTrader 5: Creamos un modelo RandomForest con preprocesamiento de datos RobustScaler y PolynomialFeatures
En este artículo, crearemos un modelo de bosque aleatorio en Python, entrenaremos el modelo y lo guardaremos como un pipeline ONNX con preprocesamiento de datos. Además, usaremos el modelo en el terminal MetaTrader 5.

Aprendizaje automático y Data Science (Parte 30): La pareja ideal para predecir el mercado bursátil: redes neuronales convolucionales (CNN) y recurrentes (RNN)
En este artículo exploramos la integración dinámica de redes neuronales convolucionales (CNN) y redes neuronales recurrentes (RNN) en la predicción bursátil. Aprovechando la capacidad de las CNN para extraer patrones y la destreza de las RNN para manejar datos secuenciales. Veamos cómo esta potente combinación puede mejorar la precisión y la eficacia de los algoritmos de negociación.

Aprendizaje automático y Data Science (Parte 14): Aplicación de los mapas de Kohonen a los mercados
¿Quiere encontrar un nuevo enfoque comercial que lo ayude a orientarse en mercados complejos y en cambio constante? Eche un vistazo a los mapas de Kohonen, una forma innovadora de redes neuronales artificiales que puede ayudarle a descubrir patrones y tendencias ocultos en los datos del mercado. En este artículo, veremos cómo funcionan los mapas de Kohonen y cómo usarlos para desarrollar estrategias comerciales efectivas. Creo que este nuevo enfoque resultará de interés tanto a los tráders experimentados como para los principiantes.
Algoritmos de optimización de la población: Algoritmo genético binario (Binary Genetic Algorithm, BGA). Parte II
En este artículo, analizaremos el algoritmo genético binario (BGA), que modela los procesos naturales que ocurren en el material genético de los seres vivos en la naturaleza.

Redes neuronales: así de sencillo (Parte 18): Reglas asociativas
Como continuación de esta serie, hoy presentamos otro tipo de tarea relacionada con los métodos de aprendizaje no supervisado: la búsqueda de reglas asociativas. Este tipo de tarea se usó por primera vez en el comercio minorista para analizar las cestas de la compra. En este artículo, hablaremos de las posibilidades que ofrece el uso de dichos algoritmos en el trading.

Creación de un Panel de administración de operaciones en MQL5 (Parte I): Creación de una interfaz de mensajería
Este artículo analiza la creación de una interfaz de mensajería para MetaTrader 5, dirigida a los administradores de sistemas, para facilitar la comunicación con otros traders directamente dentro de la plataforma. Las integraciones recientes de plataformas sociales con MQL5 permiten una rápida transmisión de señales a través de diferentes canales. Imagina poder validar las señales enviadas con un solo clic: "SÍ" o "NO". Sigue leyendo para obtener más información.

Teoría de categorías en MQL5 (Parte 8): Monoides
El presente artículo continúa la serie sobre la implementación de la teoría de categorías en MQL5. Aquí presentamos los monoides como un dominio (conjunto) que distingue la teoría de categorías de otros métodos de clasificación de datos al incluir reglas y un elemento de identidad.

Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 2): Script de comentarios analíticos
En línea con nuestra visión de simplificar la acción del precio, nos complace presentar otra herramienta que puede mejorar significativamente su análisis de mercado y ayudarle a tomar decisiones bien informadas. Esta herramienta muestra indicadores técnicos clave, como los precios del día anterior, los niveles significativos de soporte y resistencia, y el volumen de operaciones, al tiempo que genera automáticamente señales visuales en el gráfico.

Metamodelos en el aprendizaje automático y el trading: Timing original de las órdenes comerciales
Metamodelos en el aprendizaje automático: Creación automática de sistemas comerciales sin apenas intervención humana: el Modelo decide por sí mismo cómo y cuándo comerciar.

Construya Asesores Expertos Auto-Optimizables con MQL5 y Python (Parte II): Ajuste de redes neuronales profundas
Los modelos de aprendizaje automático vienen con varios parámetros ajustables. En esta serie de artículos, exploraremos cómo personalizar sus modelos de IA para que se adapten a su mercado específico utilizando la biblioteca SciPy.

Aprendizaje automático y ciencia de datos (Parte 15): SVM, una herramienta útil en el arsenal de los tráders
En este artículo analizaremos el papel que desempeña el método de máquinas de vectores soporte (Support Vector Machines, SVM) en la configuración del futuro del comercio. El artículo puede considerarse una guía detallada sobre cómo utilizar SVM para mejorar las estrategias comerciales, optimizar la toma de decisiones y abrir nuevas oportunidades en los mercados financieros. Hoy nos sumergiremos en el mundo de la SVM a través de aplicaciones reales, instrucciones paso a paso y revisiones por pares. Quizá esta herramienta indispensable le ayude a entender las complejidades del comercio moderno. En cualquier caso, la SVM se convertirá en una herramienta muy útil en el arsenal de todo tráder.
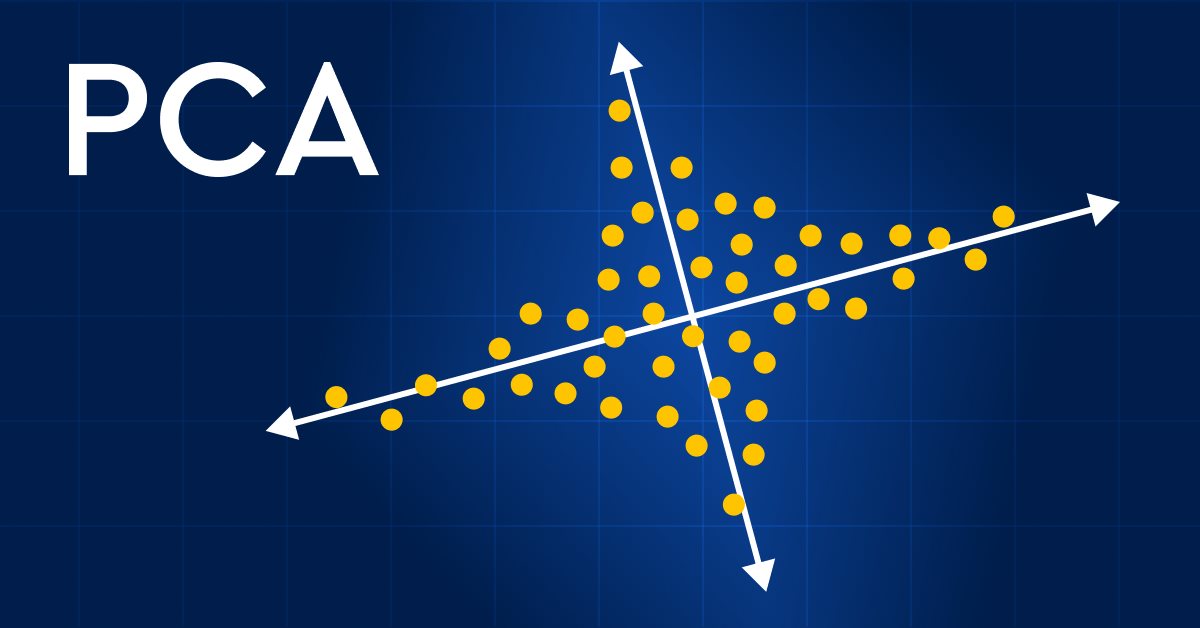
Aprendizaje automático y Data Science (Parte 13): Analizamos el mercado financiero usando el análisis de componentes principales (ACP)
Hoy intentaremos mejorar cualitativamente el análisis de los mercados financieros utilizando el Análisis de Componentes Principales (ACP). Asimismo, aprenderemos cómo este método puede ayudarnos a identificar patrones ocultos en los datos, detectar tendencias ocultas del mercado y optimizar las estrategias de inversión. En este artículo veremos cómo el método de ACP aporta una nueva perspectiva al análisis de datos financieros complejos, ayudándonos a ver ideas que hemos pasado por alto con los enfoques tradicionales. ¿La aplicación del método ACP en estos mercados financieros ofrece una ventaja competitiva y ayuda a ir un paso por delante?

Elaboración de previsiones económicas: el potencial de Python
¿Cómo utilizar los datos económicos del Banco Mundial para crear previsiones? ¿Qué ocurre si se combinan modelos de IA y economía?
Indicadores alternativos de riesgo y rentabilidad en MQL5
En este artículo, presentaremos una aplicación de varias medidas de rentabilidad y riesgo consideradas alternativas al ratio de Sharpe e investigaremos diferentes curvas de capital hipotéticas para analizar sus características.

Desarrollo de un sistema de repetición (Parte 32): Sistema de órdenes (I)
De todas las cosas desarrolladas hasta ahora, esta, como seguramente también notarás y con el tiempo estarás de acuerdo, es la más desafiante de todas. Lo que tenemos que hacer es algo simple: hacer que nuestro sistema simule lo que hace un servidor comercial en la práctica. Esto de tener que implementar una forma de simular exactamente lo que haría el servidor comercial parece simple. Al menos en palabras. Pero necesitamos hacer esto de manera que, para el usuario del sistema de repetición/simulación, todo suceda de la manera más invisible o transparente posible.

Algoritmos de optimización de la población: Algoritmo de salto de rana aleatorio (Shuffled Frog-Leaping, SFL)
El artículo presenta una descripción detallada del algoritmo de salto de rana aleatorio (SFL) y sus capacidades para resolver problemas de optimización. El algoritmo SFL se inspira en el comportamiento de las ranas en su entorno natural y ofrece un enfoque innovador para la optimización de características. El algoritmo SFL supone una herramienta eficaz y flexible que puede gestionar una gran variedad de tipos de datos y alcanzar soluciones óptimas.

Análisis cuantitativo en MQL5: implementamos un algoritmo prometedor
Hoy veremos qué es el análisis cuantitativo, cómo lo utilizan los grandes jugadores y crearemos uno de los algoritmos de análisis cuantitativo en MQL5.