Artículos sobre análisis de datos y estadísticas en MQL5
Los artículos sobre los modelos matemáticos y leyes de probabilidades serán interesantes para muchos operadores. Es que las matemáticas han sido puestas como base de los indicadores, y el conocimiento de las estadísticas es necesario para el análisis de los resultados del trading y el desarrollo de las estrategias.
Lea sobre la lógica difusa, filtros digitales, perfil del mercado, mapas de Kohonen, gas neuronal y muchas otras herramientas que pueden ser utilizadas para el trading.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Modelos ocultos de Markov para la predicción de la volatilidad siguiendo tendencias
Los modelos ocultos de Markov (Hidden Markov Models, HMM) son potentes herramientas estadísticas que identifican los estados subyacentes del mercado mediante el análisis de los movimientos observables de los precios. En el ámbito bursátil, los HMM mejoran la predicción de la volatilidad y proporcionan información para las estrategias de seguimiento de tendencias mediante la modelización y la anticipación de los cambios en los regímenes de mercado. En este artículo, presentaremos el procedimiento completo para desarrollar una estrategia de seguimiento de tendencias que utiliza HMM para predecir la volatilidad como filtro.

Otras clases en la biblioteca DoEasy (Parte 70): Ampliación de la funcionalidad y actualización automática de la colección de objetos de gráfico
En este artículo, ampliaremos la funcionalidad de los objetos de gráfico, organizaremos la navegación por los gráficos, crearemos capturas de pantalla, y también guardaremos plantillas y las aplicaremos a los gráficos. Asimismo, implementaremos la actualización automática de la colección de objetos de gráfico, sus ventanas y los indicadores en ellas.

Marcado de datos en el análisis de series temporales (Parte 2): Creando conjuntos de datos con marcadores de tendencias utilizando Python
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.

Algoritmo de cerradura de código (Сode Lock Algorithm, CLA)
En este artículo repensaremos las cerraduras de código, transformándolas de mecanismos de protección en herramientas para resolver problemas complejos de optimización. Descubra el mundo de las cerraduras de código, no como simples dispositivos de seguridad, sino como inspiración para un nuevo enfoque de la optimización. Hoy crearemos toda una población de "cerraduras" en la que cada cerradura representará una solución única a un problema. A continuación, desarrollaremos un algoritmo que "forzará" estas cerraduras y hallará soluciones óptimas en ámbitos que van desde el aprendizaje automático hasta el desarrollo de sistemas comerciales.

Características del Wizard MQL5 que debe conocer (Parte 6): Transformada de Fourier
La transformada de Fourier, introducida por Joseph Fourier, es un medio para descomponer puntos de datos de ondas complejos en componentes de ondas simples. Esta característica puede resultar útil para los tráders, así que hablaremos de ella en este artículo.
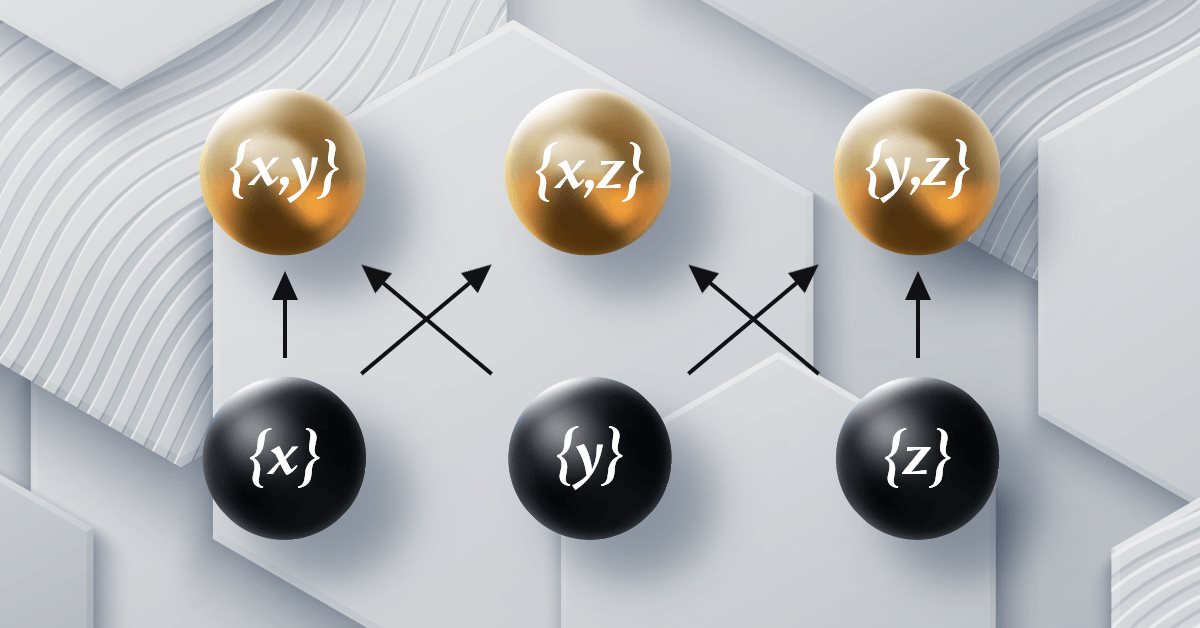
Teoría de categorías en MQL5 (Parte 12): Orden
El artículo forma parte de una serie sobre la implementación de grafos utilizando la teoría de categorías en MQL5 y está dedicado a la relación de orden (Order Theory). Hoy analizaremos dos tipos básicos de orden y exploraremos cómo los conceptos de relación de orden pueden respaldar conjuntos monoides en las decisiones comerciales.

Algoritmos de optimización de la población: Evolución de grupos sociales (Evolution of Social Groups, ESG)
En este artículo analizaremos el principio de construcción de algoritmos multipoblacionales y como ejemplo de este tipo de algoritmos consideraremos la evolución de grupos sociales (ESG), un nuevo algoritmo de autor. Así, analizaremos los conceptos básicos, los mecanismos de interacción con la población y las ventajas de este algoritmo, y revisaremos su rendimiento en problemas de optimización.

Aprendizaje automático y Data Science (Parte 37): Uso de patrones de velas japonesas e inteligencia artificial para superar al mercado
Los patrones de velas japonesas ayudan a los operadores a comprender la psicología del mercado e identificar tendencias en los mercados financieros, lo que permite tomar decisiones de inversión más informadas que pueden conducir a mejores resultados. En este artículo, exploraremos cómo utilizar los patrones de velas japonesas con modelos de IA para lograr un rendimiento óptimo en las operaciones comerciales.
Trabajando con las series temporales en la biblioteca DoEasy (Parte 53): Clase del indicador abstracto básico
En este artículo, vamos a analizar la creación de la clase del indicador abstracto que a continuación va a usarse como una clase básica para crear objetos de los indicadores estándar y personalizados de la biblioteca.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 17): Ticks y más ticks (I)
Aquí vamos a empezar a ver cómo implementar algo realmente interesante y curioso. Pero al mismo tiempo, es extremadamente complicado debido a algunas cuestiones que muchos confunden. Y lo peor que puede pasar es que algunos operadores que se autodenominan profesionales no tienen idea de la importancia de estos conceptos en el mercado de capitales. Sí, a pesar de que el enfoque aquí es la programación, comprender algunas cuestiones relacionadas con las operaciones en los mercados es de suma importancia para lo que vamos a empezar a implementar aquí.

El modelo de movimiento de precios y sus principales disposiciones (Parte 2): Ecuación de evolución del campo de probabilidad del precio y aparición del paseo aleatorio observado
En el presente artículo, hemos derivado una ecuación para la evolución del campo probabilístico de precio, hemos encontrado un criterio para acercarnos al salto de precio, y también hemos revelado la esencia de los valores de precio en los gráficos de cotización y el mecanismo para la aparición de un paseo aleatorio de dichos valores .

Redes neuronales: así de sencillo (Parte 39): Go-Explore: un enfoque diferente sobre la exploración
Continuamos con el tema de la exploración del entorno en los modelos de aprendizaje por refuerzo. En este artículo, analizaremos otro algoritmo: Go-Explore, que permite explorar eficazmente el entorno en la etapa de entrenamiento del modelo.
Análisis causal de series temporales mediante entropía de transferencia
En este artículo, analizamos cómo se puede aplicar la causalidad estadística para identificar variables predictivas. Exploraremos el vínculo entre causalidad y entropía de transferencia, además de presentar código MQL5 para detectar transferencias direccionales de información entre dos variables.

Redes neuronales: así de sencillo (Parte 41): Modelos jerárquicos
El presente artículo describe modelos de aprendizaje jerárquico que ofrecen un enfoque eficiente para resolver problemas complejos de aprendizaje automático. Los modelos jerárquicos constan de varios niveles; cada uno de ellos es responsable de diferentes aspectos del problema.

Redes neuronales: así de sencillo (Parte 38): Exploración auto-supervisada por desacuerdo (Self-Supervised Exploration via Disagreement)
Uno de los principales retos del aprendizaje por refuerzo es la exploración del entorno. Con anterioridad, hemos aprendido un método de exploración basado en la curiosidad interior. Hoy queremos examinar otro algoritmo: la exploración mediante el desacuerdo.

Trabajando con las series temporales en la biblioteca DoEasy (Parte 58): Series temporales de los datos de búferes de indicadores
En conclusión del tema de trabajo con series temporales, vamos a organizar el almacenamiento, la búsqueda y la ordenación de los datos que se guardan en los búferes de indicadores. En el futuro, eso nos permitirá realizar el análisis a base de los valores de los indicadores que se crean a base de la biblioteca en nuestros programas. El concepto general de todas las clases de colección de la biblioteca permite encontrar fácilmente los datos necesarios en la colección correspondiente, y por tanto, lo mismo también será posible en la clase que vamos a crear hoy.

Desarrollo de un sistema de repetición (Parte 30): Proyecto Expert Advisor — Clase C_Mouse (IV)
Aquí te mostraré una técnica que puede ayudarte mucho en varios momentos de tu vida como programador. En contra de lo que muchos dicen, lo limitado no es la plataforma, sino los conocimientos del individuo que lo dice. Lo que se explicará aquí es que con un poco de sentido común y creatividad, se puede hacer que la plataforma MetaTrader 5 sea mucho más interesante y versátil, sin tener que crear programas locos ni nada por el estilo puedes crear un código sencillo, pero seguro y fiable. Utiliza tu ingenio para domar el código con el fin de modificar algo que ya existe, sin eliminar ni añadir una sola línea al código original.

Creación de una estrategia de retorno a la media basada en el aprendizaje automático
Este artículo propone otro enfoque original para crear sistemas comerciales basados en el aprendizaje automático, usando la clusterización y el etiquetado de transacciones para estrategias de retorno a la media.

Desarrollo de un sistema de repetición (Parte 34): Sistema de órdenes (III)
En este artículo concluiremos la primera fase de la construcción. Aunque será algo relativamente rápido, explicaré detalles que quizás no se comentaron anteriormente. Pero aquí explicaré algunas cosas que mucha gente no entiende por qué son como son. Uno de estos casos es el del ratón. ¡¡¡¿Sabes por qué tienes que pulsar la tecla Shift o Ctrl en tu teclado?!!!
Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 12): Flujo externo (III) TrendMap
El flujo del mercado está determinado por las fuerzas entre alcistas y bajistas. Hay niveles específicos que el mercado respeta debido a las fuerzas que actúan sobre ellos. Los niveles de Fibonacci y VWAP son especialmente poderosos a la hora de influir en el comportamiento del mercado. Acompáñame en este artículo mientras exploramos una estrategia basada en los niveles VWAP y Fibonacci para la generación de señales.

Optimización de carteras en Python y MQL5
Este artículo explora técnicas avanzadas de optimización de cartera utilizando Python y MQL5 con MetaTrader 5. Demuestra cómo desarrollar algoritmos para el análisis de datos, la asignación de activos y la generación de señales comerciales, enfatizando la importancia de la toma de decisiones basada en datos en la gestión financiera moderna y la mitigación de riesgos.

Aprendizaje automático y Data Science (Parte 17): ¿Crece el dinero en los árboles? Bosques aleatorios en el mercado Fórex
Este artículo le presentará los secretos de la alquimia algorítmica, introduciéndole con precisión las particularidades de los paisajes financieros. Asimismo, aprenderá cómo los bosques aleatorios transforman los datos en predicciones y le servirán de ayuda al navegar por las complejidades de los mercados financieros. Intentaremos identificar el papel de los bosques aleatorios en los datos financieros y comprobaremos si pueden ayudar a aumentar los beneficios.
Algoritmo de optimización de reacciones químicas (CRO) (Parte I): Química de procesos en la optimización
En la primera parte de este artículo, nos sumergiremos en el mundo de las reacciones químicas y descubriremos un nuevo enfoque de la optimización. La optimización de reacciones químicas (Chemical Reaction Optimization, CRO) utiliza principios derivados de las leyes de la termodinámica para lograr resultados eficientes. Desvelaremos los secretos de la descomposición, la síntesis y otros procesos químicos que se convirtieron en la base de este innovador método.

Aprendizaje automático y Data Science (Parte 32): Mantener actualizados los modelos de IA, aprendizaje en línea
En el cambiante mundo del comercio, adaptarse a los cambios del mercado no es solo una opción, es una necesidad. Cada día surgen nuevos patrones y tendencias, lo que dificulta que incluso los modelos de aprendizaje automático más avanzados sigan siendo eficaces ante condiciones en constante evolución. En este artículo, exploraremos cómo mantener tus modelos relevantes y receptivos a los nuevos datos del mercado mediante el reentrenamiento automático.

Descifrando las estrategias de trading intradía de ruptura del rango de apertura
Las estrategias de ruptura del rango de apertura (Opening Range Breakout, ORB) se basan en la idea de que el rango de negociación inicial establecido poco después de la apertura del mercado refleja niveles de precios significativos en los que compradores y vendedores acuerdan el valor. Al identificar rupturas por encima o por debajo de un determinado rango, los operadores pueden aprovechar el impulso que suele producirse cuando la dirección del mercado se vuelve más clara. En este artículo, exploraremos tres estrategias ORB adaptadas del Grupo Concretum.

Algoritmo de evolución del caparazón de tortuga (Turtle Shell Evolution Algorithm, TSEA)
Hoy hablaremos sobre un algoritmo de optimización único inspirado en la evolución del caparazón de las tortugas. El algoritmo TSEA emula la formación gradual de los sectores de piel queratinizada que representan soluciones óptimas a un problema. Las mejores soluciones se vuelven más "duras" y se encuentran más cerca de la superficie exterior, mientras que las menos exitosas permanecen "blandas" y se hallan en el interior. El algoritmo utiliza la clusterización de soluciones según su calidad y distancia, lo cual permite conservar las opciones menos acertadas y aporta flexibilidad y adaptabilidad.

Simulación de mercado: Position View (I)
El contenido que veremos a partir de ahora es mucho más complicado en términos de teorías y conceptos. Intentaré dejar el contenido lo más simple posible. La parte referente a la programación en sí es incluso bastante simple y directa. Pero, si no comprendes toda la teoría que hay detrás, te quedarás completamente sin recursos para poder mejorar o incluso adaptar el sistema de repetición/simulador a algo diferente de lo que voy a mostrar. Mi intención no es que simplemente compiles y uses el código que estoy mostrando. Quiero que aprendas, entiendas y, si es posible, puedas crear algo todavía mejor.

Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 1): Proyector de gráficos
Este proyecto tiene como objetivo aprovechar el lenguaje MQL5 para desarrollar un conjunto integral de herramientas de análisis para MetaTrader 5. Estas herramientas, que van desde scripts e indicadores hasta modelos de IA y asesores expertos, automatizarán el proceso de análisis del mercado. En ocasiones, este desarrollo producirá herramientas capaces de realizar análisis avanzados sin intervención humana y pronosticar resultados para las plataformas adecuadas. Ninguna oportunidad jamás se perderá. Únase a mí mientras exploramos el proceso de creación de un conjunto sólido de herramientas personalizadas para el análisis de mercado. Comenzaremos desarrollando un programa MQL5 simple que he llamado "Proyector de gráficos" (Chart Projector).

Desarrollo de un sistema de repetición (Parte 38): Pavimentando el terreno (II)
Muchas personas que se hacen llamar programadores de MQL5 no tienen los conocimientos básicos que presentaré en este artículo. Muchos consideran que MQL5 es limitado; sin embargo, todo se debe a la falta de conocimientos. Así que no te avergüences de no saber. Avergüénzate, en cambio, de no preguntar. El simple hecho de obligar a MetaTrader 5 a no permitir que un indicador se duplique, en ningún caso nos da los medios para realizar una comunicación bidireccional entre el indicador y el Expert Advisor. Todavía estamos muy lejos de esto. No obstante, el hecho de que el indicador no se duplique en el gráfico nos da cierta tranquilidad.

Marcado de datos en el análisis de series temporales (Parte 1):Creamos un conjunto de datos con marcadores de tendencia utilizando el gráfico de un asesor
En esta serie de artículos, presentaremos varias técnicas de etiquetado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El etiquetado específico de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorar la precisión del modelo e incluso ayudarle a dar un salto cualitativo.

De novato a experto: Depuración colaborativa en MQL5
La resolución de problemas puede establecer una rutina concisa para dominar habilidades complejas, como la programación en MQL5. Este enfoque le permite concentrarse en la resolución de problemas al tiempo que desarrolla sus capacidades. Cuantos más problemas abordes, más conocimientos avanzados se transferirán a tu cerebro. Personalmente, creo que la depuración es la forma más efectiva de dominar la programación. Hoy repasaremos el proceso de limpieza de código y analizaremos las mejores técnicas para transformar un programa desordenado en uno limpio y funcional. Lea este artículo y descubra información valiosa.

Asesor de autoaprendizaje con red neuronal basada en matriz de estados
Asesor de autoaprendizaje con red neuronal basada en matriz de estados. Hoy combinaremos cadenas de Márkov con una red neuronal multicapa MLP, escrita en la biblioteca ALGLIB MQL5. ¿Cómo podemos combinar las cadenas de Márkov y las redes neuronales para realizar previsiones en Forex?

Creación de barras 3D basadas en el tiempo, el precio y el volumen
Qué son los gráficos de precios multidimensionales en 3D y cómo se crean. Cómo las barras 3D predicen las inversiones de precios, y cómo Python y MetaTrader 5 permiten construir estas barras volumétricas en tiempo real.

Métodos de optimización de la biblioteca ALGLIB (Parte I)
En este artículo nos familiarizaremos con los métodos de optimización de la biblioteca ALGLIB para MQL5. El artículo incluye ejemplos sencillos e ilustrativos de la aplicación de ALGLIB para resolver problemas de optimización, lo que hará que el proceso de dominio de los métodos resulte lo más accesible posible. Asimismo, analizaremos con detalle la conectividad de algoritmos como BLEIC, L-BFGS y NS y resolveremos un sencillo problema de prueba basado en ellos.
Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 3): Asesor Experto Analytics Master
Pasar de un simple script de trading a un Asesor Experto (EA) totalmente funcional puede mejorar significativamente su experiencia de trading. Imagina tener un sistema que supervisa automáticamente tus gráficos, realiza cálculos esenciales en segundo plano y proporciona actualizaciones periódicas cada dos horas. Este EA estaría equipado para analizar métricas clave que son cruciales para tomar decisiones comerciales informadas, lo que garantiza que usted tenga acceso a la información más actualizada para ajustar sus estrategias de manera eficaz.

El papel de la calidad del generador de números aleatorios en la eficiencia de los algoritmos de optimización
En este artículo, analizaremos el generador de números aleatorios Mersenne Twister y lo compararemos con el estándar en MQL5. También determinaremos la influencia de la calidad del generador de números aleatorios en los resultados de los algoritmos de optimización.

Algoritmo de viaje evolutivo en el tiempo — Time Evolution Travel Algorithm (TETA)
Se trata de un algoritmo propio. En este artículo, le presentaremos el Algoritmo de viaje evolutivo en el tiempo (TETA), inspirado en el concepto de universos paralelos y flujos temporales. La idea básica del algoritmo es que, si bien no es posible viajar en el tiempo en el sentido habitual, podemos elegir una secuencia de acontecimientos que generen realidades distintas.

Teoría de categorías en MQL5 (Parte 19): Inducción cuadrática de la naturalidad
Continuamos analizando las transformaciones naturales considerando la inducción cuadrática de la naturalidad. Pequeñas restricciones en la implementación de las capacidades multidivisa para los asesores ensamblados usando el wizard MQL5 significan que estamos demostrando nuestras capacidades en la clasificación de datos usando un script. Las principales áreas de aplicación son la clasificación de las variaciones de precios y, como consecuencia, su previsión.

Codificación ordinal para variables nominales
En este artículo, analizamos y demostramos cómo convertir predictores nominales en formatos numéricos adecuados para algoritmos de aprendizaje automático, utilizando tanto Python como MQL5.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 14): Nacimiento del SIMULADOR (IV)
En este artículo, continuaremos con la fase de desarrollo del simulador. Sin embargo, ahora veremos cómo crear efectivamente un movimiento del tipo "RANDOM WALK" (paseo aleatorio). Este tipo de movimiento es bastante intrigante, ya que sirve de base para todo lo que sucede en el mercado de capitales. Además, comenzarás a comprender algunos conceptos esenciales para quienes realizan análisis de mercado.