Aproximación por fuerza bruta a la búsqueda de patrones (Parte VI): Optimización cíclica

Contenido
- Introducción
- Complejo
- El nuevo algoritmo de optimización
- El criterio de optimización más importante
- Búsqueda automática de configuraciones comerciales.
- Conclusión
- Enlaces
Introducción
Basándonos en un breve recorrido por el artículo anterior, podemos afirmar que esta es solo una descripción superficial de todas las funciones que introdujimos en nuestro algoritmo. Estas se refieren no solo a la automatización completa de la creación de asesores, sino también a funciones tan importantes como la automatización completa del proceso de optimización y selección de resultados con su posterior uso para el comercio automático, o la creación de asesores más progresivos que mostraremos un poco más tarde.
Gracias a la simbiosis de terminales comerciales, asesores universales y el propio algoritmo, si disponemos de capacidades informáticas, podemos deshacernos por completo del desarrollo manual o, en el peor de los casos, reducir en un orden de magnitud la complejidad de las posibles mejoras. En este artículo comenzaremos a describir los aspectos más importantes de estas innovaciones.
Complejo
A nuestro juicio, el factor más importante en la creación y las posteriores modificaciones de este tipo de soluciones a lo largo del tiempo es la comprensión de la posibilidad de garantizar la máxima automatización de las acciones rutinarias. Las acciones rutinarias, en este caso, incluyen todo el trabajo humano no esencial:
- La generación de ideas.
- La creación de la teoría.
- La escritura del código según la teoría.
- La corrección del código.
- El proceso constante de reoptimización de asesores.
- El proceso de selección constante de asesores.
- El mantenimiento de asesores.
- El trabajo con terminales.
- Los experimentos y la práctica.
- Otros trabajos.
Como puede ver, el alcance de toda esta rutina es bastante amplio. Lo tratamos precisamente como una rutina, porque todas estas cosas, como hemos podido comprobar, están absolutamente automatizadas. Hemos ofrecido una lista general. No importa en absoluto quién sea usted: un tráder algorítmico, un programador o ambos. No importa en absoluto si sabe programar o no, incluso si no sabe, en cualquier caso encontrará al menos la mitad de esta lista. Ahora no nos referimos a los casos en los que compramos un asesor en el mercado, lo ponemos en el gráfico y nos tranquilizamos tras presionar un botón. Esto, por supuesto, sucede, pero muy raras veces.
Entendiendo todo esto, primero hemos tenido que automatizar lo que había en la superficie. Ya hemos descrito conceptualmente toda esta optimización en un artículo anterior. Sin embargo, al hacer algo como esto, comenzamos a comprender cómo mejorar todo, basándonos en la funcionalidad ya implementada. En nuestro caso, las ideas principales a este respecto han sido las siguientes:
- La mejora del mecanismo de optimización.
- La creación de un mecanismo para fusionar asesores (fusionar bots).
- La correcta arquitectura de las rutas de interacción de todos los componentes.
Aquí todo está muy condensado, ahora lo describiremos con más detalle. Cuando hablamos de «mejorar la optimización», nos referimos a un conjunto de varios factores a la vez. Todo esto se ha pensado dentro del paradigma elegido para construir todo el sistema:
- Aceleración de la optimización eliminando ticks.
- Aceleración de la optimización eliminando el control de la curva de beneficio entre los puntos de decisión comercial.
- Mejora de la calidad de la optimización introduciendo nuestros propios criterios de optimización.
- Maximización de la eficiencia del periodo forward.
En diferentes rincones del portal aún siguen candentes los debates sobre la necesidad de la optimización y sus posibilidades. Antes, yo tenía una actitud bastante categórica respecto a este tema, en gran parte debido a la influencia de ciertas personas que habitan los foros y el portal en general. Ahora bien, esta opinión no me preocupa en absoluto, y puedo afirmar que todo depende de si sabemos usar la optimización correctamente, de para qué la usamos y cómo la realizamos. Si se usa correctamente, esta acción dará el resultado deseado. En general, resulta que esta acción resulta de gran utilidad.
A muchos usuarios no les gusta la optimización, existen dos razones objetivas para ello:
- Falta de comprensión de los conceptos básicos (qué hacer, por qué hacerlo y cómo hacerlo, cómo seleccionar los resultados y todo lo relacionado con ello, incluida la falta de experiencia).
- Imperfección de los algoritmos de optimización.
De hecho, ambos factores se refuerzan mutuamente. Siendo justos, diremos que el optimizador MetaTrader 5 está estructuralmente ejecutado de manera impecable, pero desde el punto de vista de los criterios de optimización y los posibles filtros, el campo aún no está explorado del todo. Hasta ahora, toda esta funcionalidad se encuentra al nivel de un arenero para niños. Pocos piensan en cómo lograr periodos forward positivos y, lo más importante, en cómo controlar este proceso. He estado pensando en esto durante mucho tiempo y se podría decir que una buena mitad de mi material trata sobre dicho tema.
El nuevo algoritmo de optimización
Además de los criterios de evaluación básicos conocidos de cualquier backtest, para una selección más eficiente de los resultados y la posterior aplicación de la configuración, podemos encontrar algunas características combinadas que pueden ayudar a multiplicar el valor de cualquier algoritmo. La ventaja de estas características reside en que pueden acelerar el proceso de búsqueda de entornos de trabajo. Para hacer esto, hemos creado algo así como un informe de prueba de las estrategias, algo semejante a MetaTrader:
figura 1

Con esta herramienta podemos elegir la opción que nos guste con un simple clic. Al hacer clic, se generará una configuración que podremos tomar inmediatamente y desplazar a la carpeta correspondiente en el terminal, para que los asesores universales puedan leerla y comenzar a operar con ella. Asimismo, si lo deseamos, podemos clicar en el botón para generar un asesor, y este se creará en caso de que necesitemos un asesor independiente con la configuración incorporada. También tenemos un gráfico de la curva de beneficios, que se redibuja cuando seleccionamos la siguiente opción de la tabla.
Vamos a averiguar qué se cuenta en esta tabla. Los elementos principales para el cálculo de estas características serán los siguientes datos:
- Points: beneficio de todo el backtest en "_Point" del instrumento correspondiente.
- Orders: número de órdenes completamente abiertas y cerradas (se suceden en estricto orden, según la regla “solo puede haber una orden abierta”).
- Drawdown: reducción del balance.
A partir de estos valores se calcularán las siguientes características comerciales:
- Math Waiting: esperanza matemática en puntos.
- P Factor: análogo del factor de beneficio normalizado al rango [-1... 0 ... 1] (mi criterio).
- Martingale: indicador de aplicabilidad del martingale (mi criterio).
- MPM Complex: indicador compuesto de los tres anteriores (mi criterio).
Veamos ahora cómo se calculan los criterios presentados:
fórmula 1

Como podemos ver, todos los criterios que hemos creado son muy simples y, lo más importante, fáciles de entender. Como el aumento en cada uno de los criterios indica que el resultado del backtest es mejor desde el punto de vista del análisis en el marco de la teoría de la probabilidad, podremos multiplicar estos criterios, como hemos hecho en el criterio "MPM complejo". La métrica común clasificará los resultados de manera más efectiva según su importancia y, con optimizaciones masivas, nos permitirá conservar más opciones de alta calidad y eliminar más opciones de baja calidad, respectivamente.
Querríamos destacar aparte que en estos cálculos todo se da en puntos, lo cual tiene un efecto positivo en el proceso de optimización. Para los cálculos se usan magnitudes primarias estrictamente positivas, que siempre se calculan al principio y, usando estas como base, se calcula todo lo demás. A nuestro juicio, merece la pena enumerar las magnitudes primarias que no se encuentran en la tabla:
- Point Plus: suma de los beneficios de cada orden rentable o cero en puntos
- Point Minus: suma de los módulos de las pérdidas de cada orden no rentable en puntos
- Drawdown: reducción del balance (según un cálculo propio)
Lo más interesante aquí es cómo se calcula la reducción. En nuestro caso, hablamos de la reducción relativa máxima del balance. Teniendo en cuenta que nuestro algoritmo de prueba se niega a controlar la curva de fondos, no podemos calcular otros tipos de reducciones. No obstante, creo que ha resultado útil mostrar cómo calculamos esta reducción:
figura 2

Se define de forma muy simple:
- Calculamos el punto de partida del backtest (el inicio de la cuenta de la primera reducción).
- Si el comercio comienza con ganancias, entonces desplazaremos este punto hacia arriba siguiendo el crecimiento del balance, hasta que aparezca el primer signo negativo (que marca el inicio del cálculo de la reducción).
- Luego esperaremos hasta que el balance alcance el nivel del punto de referencia, después de lo cual fijaremos este punto como un nuevo punto de referencia.
- Después regresaremos a la última sección de la búsqueda de reducción y encontraremos el punto más bajo en ella (la magnitud de la reducción en esta sección se calcula precisamente a partir de este punto).
- Repetiremos todo el proceso para toda la curva de backtest o trading.
También debemos señalar que el último ciclo siempre quedará inconcluso. Sin embargo, también se considerará su reducción, a pesar de que existe la posibilidad de que aumente si las pruebas continúan en el futuro. Pero este no es un matiz especialmente importante en este caso.
El criterio de optimización más importante
Por otra parte, queremos hablar del filtro más importante. De hecho, este criterio es el más importante a la hora de seleccionar los resultados de optimización. Este criterio no se incluye en la funcionalidad del optimizador MetaTrader 5, y podemos afirmar que no debería ser así. No obstante, siendo consciente de que nadie atenderá a esa observación, queremos ofrecer material teórico para que todos puedan reproducir este algoritmo en su propio código. De hecho, este criterio es multifuncional para cualquier tipo de operación y funciona para absolutamente cualquier curva de beneficio, incluidas las apuestas deportivas, las criptomonedas y cualquier otra cosa que pueda venirnos a la cabeza. El criterio es el siguiente:
fórmula 2

Veamos qué hay dentro de esta fórmula:
- N es el número de posiciones comerciales completamente abiertas y cerradas a lo largo de toda la sección del backtest o la negociación.
- B(i) — valor de la línea de balance después de la posición cerrada correspondiente “i”.
- L(i) — línea recta trazada desde el cero hasta el último punto del balance (balance final).
La peculiaridad del cálculo de este indicador reside en que para calcularlo deberemos realizar dos backtests. El primer backtest calculará el balance final, y solo después podremos calcular el indicador correspondiente, almacenando el valor de cada punto de balance para que no sea necesario realizar cálculos innecesarios. Sin embargo, de una forma u otra, este cálculo se puede llamar un backtest repetido. Esta fórmula se puede usar en simuladores personalizados que pueden integrarse en nuestros asesores (aquellos que saben por qué).
Debemos señalar que este indicador en su conjunto puede modificarse para una mayor comprensión. Por ejemplo, de esta forma:
fórmula 3

Desde el punto de vista de la percepción y la comprensión, la presente fórmula resulta más pesada. Pero si consideramos un plano puramente aplicado, entonces ese criterio resultará conveniente porque cuanto más alto sea, más se parecerá nuestra curva de balance a una línea recta. Hemos tocado temas similares en artículos anteriores, pero no hemos explicado el significado detrás de ellos. Entonces, intuitivamente, creo que mucha gente entiende el qué y porqué, pero no todo el mundo. Para entenderlo, veamos primero la figura siguiente:
figura 3

Esta figura muestra una línea de balance y dos curvas, una de las cuales (en rojo) se relaciona con nuestra fórmula , mientras que la segunda se relaciona con el siguiente criterio modificado (fórmula 11). Lo mostraremos más adelante, pero ahora deberemos centrarnos en la fórmula cuyo significado estamos revelando.
Si imaginamos nuestro backtest como un simple array de puntos con balances, entonces podremos representarlo como una muestra estadística y aplicarle fórmulas de teoría de probabilidad. Consideraremos que la línea recta es el modelo que queremos alcanzar, mientras que la curva de beneficio en sí será el flujo de datos real al que queremos llegar.
Debemos comprender que el factor de linealidad indica la fiabilidad de todo el conjunto de criterios comerciales disponibles, y a su vez, una mayor fiabilidad de los datos puede indicar un posible periodo forward más largo y mejor (comercio rentable en el futuro). Estrictamente hablando, de inicio deberíamos haber comenzado a considerar estas cosas tendiendo en cuenta variables aleatorias, pero tal presentación, a nuestro juicio, no debería hacerlas obligatoriamente más fáciles de entender.
Vamos a crear un análogo alternativo de nuestro factor de linealidad, considerando posibles valores atípicos aleatorios. Para ello necesitaremos introducir una variable aleatoria que nos resulte cómoda, así como su media para el posterior cálculo de la varianza:
fórmula 4

Para entender esto, cabe aclarar que tendremos “N” posiciones completamente abiertas y cerradas que se suceden estrictamente una tras otra. Esto significa que tendremos “N+1” puntos que conectan estos segmentos de la línea de balance. El punto cero de todas las líneas será común, por lo que sus datos distorsionarán los resultados hacia la mejora, al igual que el último punto. Por consiguiente, los descartaremos de los cálculos y nos quedarán puntos "N-1" sobre los cuales realizaremos los cálculos.
La selección de la expresión para convertir los arrays de valores de dos líneas en una ha resultado muy interesante. Preste atención a la siguiente fracción:
fórmula 5

Lo importante aquí es que en todos los casos dividiremos todo por el balance final. Por ello, reduciremos todo a un valor relativo, lo cual garantizará la equivalencia de las características calculadas para todas las estrategias probadas, sin excepción. No es casualidad que la misma fracción esté presente en el primer y simple criterio del factor de linealidad, ya que se basa en la misma consideración. Vamos a completar la construcción de nuestro criterio alternativo. Para ello, podemos usar un concepto tan conocido como la dispersión:
fórmula 6

La dispersión no supone más que la media aritmética de la desviación al cuadrado de la media de toda la muestra. Allí hemos sustituido directamente nuestras variables aleatorias, cuyas expresiones definimos anteriormente. Una curva ideal tiene una desviación media de cero y, como consecuencia de ello, la varianza de una muestra determinada también será cero. Usando estos datos como base, podemos adivinar con facilidad que esta varianza, debido a su estructura -la variable aleatoria utilizada o la muestra (como se desee)-, puede usarse como un factor de linealidad alternativo. Además, ambos criterios se pueden usar en conjunto para restringir de forma más efectiva los parámetros de la muestra, aunque, siendo honestos, solo usamos el primer criterio.
Bueno, para ser justos, vamos a ver un criterio similar, más cómodo, igualmente basado en el nuevo factor de linealidad que hemos definido:
fórmula 7
![]()
Como podemos ver, resulta idéntico al criterio análogo, basado en el primero (fórmula 2). No obstante, estos dos criterios quedan lejos del límite de lo que se puede pensar. Un hecho evidente que habla a favor de esta consideración es que este criterio está demasiado idealizado y resulta más adecuado para modelos ideales; será extremadamente difícil ajustar tal o cual asesor a una correspondencia más o menos significativa. A nuestro juicio, merece la pena enumerar los factores negativos que se harán evidentes algún tiempo después de aplicar estas fórmulas:
- La reducción crítica en el número de operaciones (reducirá la fiabilidad de los resultados)
- El descarte del número máximo de escenarios efectivos (dependiendo de la estrategia, la curva no siempre tenderá a una línea recta)
Estas deficiencias son de esencial importancia, ya que el objetivo no consiste en descartar buenas estrategias, sino, por el contrario, en encontrar nuevos y mejores criterios que estén libres de estas deficiencias. Estas desventajas pueden neutralizarse total o parcialmente introduciendo varias líneas preferidas a la vez, cada una de las cuales puede considerarse un modelo aceptable o preferido. Para comprender el nuevo criterio mejorado, libre de estas deficiencias, bastará con comprender el reemplazo correspondiente:
fórmula 8

Luego podremos calcular el factor de correspondencia para cada curva de la lista:
fórmula 9

Y de manera similar, también podremos calcular un criterio alternativo que considere los valores atípicos aleatorios, también para cada una de las curvas:
fórmula 10

Entonces necesitaremos calcular lo siguiente:
fórmula 11

Aquí presentamos un criterio llamado factor de familia de curvas. De hecho, con esta acción encontraremos simultáneamente la curva más semejante a nuestra curva comercial e inmediatamente hallaremos el factor que le corresponde. La curva con el factor de correspondencia mínimo será la más próxima a la situación real. Tomaremos su valor como el valor del criterio modificado y, por supuesto, el cálculo se podrá realizar de dos formas, dependiendo de cuál de las dos variaciones nos guste más.
Todo esto está genial, pero aquí, como muchos habrán notado, existen matices en cuanto a la selección de dicha familia de curvas. Para describir correctamente una familia así, podremos seguir varias consideraciones; les dejo aquí mis reflexiones al respecto:
- Ninguna curva deberá tener puntos de flexión (cada punto intermedio posterior deberá ser estrictamente más alto que el anterior).
- La curva deberá ser cóncava (la pendiente de la curva podrá o bien ser constante o bien aumentar).
- La concavidad de la curva deberá ser regulable (por ejemplo, la magnitud de desviación deberá ajustarse utilizando algún valor o porcentaje relativo).
- El modelo de curva deberá ser simple (será mejor basar el modelo en modelos gráficos inicialmente simples y comprensibles).
Aparte quiero decir que esta es solo la variación inicial de esta familia de curvas con la que hemos comenzado, pero podemos crear otras más extensas y considerando todas las configuraciones deseadas, lo cual puede salvarnos por completo de perder calidad en los ajustes. En el futuro abordaremos este problema, pero por ahora solo tocaremos la estrategia original de la familia de curvas cóncavas. He logrado crear una familia así con bastante facilidad, utilizando mis conocimientos de matemáticas. Permítanme mostrarles directamente el aspecto final de esta familia de curvas:
figura 4

Al construir una familia de este tipo, hemos utilizado la abstracción de una varilla elástica apoyada sobre soportes verticales. El grado de desviación de dicha varilla dependerá del punto de aplicación de la fuerza y de su magnitud. Está claro que esto solo se parecerá un poco a una situación similar, pero bastará para desarrollar algún tipo de modelo visualmente similar. En esta situación, claro está, primero tendremos que determinar la coordenada del extremo, que deberá coincidir con uno de los puntos en el gráfico de prueba posterior, y allí el eje x estará representado por los índices comerciales, partiendo desde cero. Lo calculamos así:
fórmula 12

Aquí hay dos casos: para "N" par e impar. Si "N" resulta ser par, entonces resultará imposible simplemente dividirlo entre dos, ya que el índice deberá ser un número entero. Por cierto, hemos representado exactamente este caso en la última imagen. Allí, el punto de aplicación de la fuerza se encuentra un poco más cerca del principio. Obviamente, podemos hacer lo contrario, un poco más cerca del final, pero esto resultará significativo solo con un pequeño número de transacciones, como lo describimos en la figura. A medida que aumente el número de operaciones, todo esto no desempeñará ningún papel importante para los algoritmos de optimización.
Tras establecer el valor de flexión "P" en porcentaje y el balance final del backtest "B", habiendo determinado previamente la coordenada del extremo, podremos comenzar a calcular secuencialmente los componentes adicionales para construir expresiones para cada una de las familias de curvas aceptadas. A continuación necesitaremos la inclinación de la línea recta que conecta el principio y el final del backtest:
fórmula 13

Otra característica de estas curvas es el hecho de que la tangente a cada ángulo de inclinación de las curvas en los puntos con la abscisa "N0" es idéntico a "K". Al construir las fórmulas, requerimos esta condición a la tarea. Esto se puede ver gráficamente en la última figura (figura 4), y allí también hay algunas fórmulas e identidades. Continuemos. Ahora necesitaremos calcular el siguiente valor:
fórmula 14

Aquí debemos señalar que “P” se establece de forma distinta para cada curva de la familia. Estrictamente hablando, éstas son fórmulas para construir una curva de una familia. Estos cálculos deberán repetirse para cada curva de la familia. Entonces necesitaremos calcular otro coeficiente importante:
fórmula 15
![]()
No resulta necesario profundizar en el significado de estas estructuras. Estas solo se crean para simplificar el proceso de construcción de las curvas. Nos queda por calcular el último coeficiente auxiliar:
fórmula 16

Ahora, a partir de los datos conseguidos, podremos obtener una expresión matemática para calcular los puntos de la curva construida. No obstante, primero deberemos aclarar que la curva no se describe mediante una única fórmula. A la izquierda del punto "N0" funciona una fórmula y a la derecha, otra. Para que resulte más fácil de entender, podemos hacer lo siguiente:
fórmula 17
![]()
Ahora podemos ver las fórmulas finales:
fórmula 18

Además, esto se puede reescribir así:
fórmula 19

Estrictamente hablando, esta función deberá usarse como una función discreta y auxiliar. Sin embargo, permitirá calcular valores en “i” fraccionaria. Lo cual, por supuesto, resulta poco probable que tenga beneficios útiles para nosotros en el contexto del problema que estamos considerando.
Como estamos mostrando este tipo de matemáticas, estoy obligado a dar ejemplos de la implementación del algoritmo. En mi opinión, todo el mundo estará interesado en obtener un código ya preparado que sea más fácil de adaptar a sus sistemas. Empezaremos por definir las principales variables y métodos que simplificarán el cálculo de las magnitudes necesarias:
//+------------------------------------------------------------------+ //| Number of lines in the balance model | //+------------------------------------------------------------------+ #define Lines 11 //+------------------------------------------------------------------+ //| Initializing variables | //+------------------------------------------------------------------+ double MaxPercent = 10.0; double BalanceMidK[,Lines]; double Deviations[Lines]; int Segments; double K; //+------------------------------------------------------------------+ //| Method for initializing required variables and arrays | //| Parameters: number of segments and initial balance | //+------------------------------------------------------------------+ void InitLines(int SegmentsInput, double BalanceInput) { Segments = SegmentsInput; K = BalanceInput / Segments; ArrayResize(BalanceMidK,Segments+1); ZeroStartBalances(); ZeroDeviations(); BuildBalances(); } //+------------------------------------------------------------------+ //| Resetting variables for incrementing balances | //+------------------------------------------------------------------+ void ZeroStartBalances() { for (int i = 0; i < Lines; i++ ) { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = 0.0; } } } //+------------------------------------------------------------------+ //| Reset deviations | //+------------------------------------------------------------------+ void ZeroDeviations() { for (int i = 0; i < Lines; i++) { Deviations[i] = -1.0; } }
El código está diseñado para ser reutilizable. Después del siguiente cálculo, podremos calcular el indicador para una curva de balance diferente llamando primero al método "InitLines". En este se debe ofrecer el balance final del backtest y el número de operaciones, después de lo cual podremos comenzar a construir nuestras curvas basadas en estos datos:
//+------------------------------------------------------------------+ //| Constructing all balances | //+------------------------------------------------------------------+ void BuildBalances() { int N0 = MathFloor(Segments / 2.0) - Segments / 2.0 == 0 ? Segments / 2 : (int)MathFloor(Segments / 2.0);//calculate first required N0 for (int i = 0; i < Lines; i++) { if (i==0)//very first and straight line { for (int j = 0; j <= Segments; j++) { BalanceMidK[j,i] = K*j; } } else//build curved lines { double ThisP = i * (MaxPercent / 10.0);//calculate current line curvature percentage double KDelta = ( (ThisP /100.0) * K * Segments) / (MathPow(N0,2)/2.0 );//calculation first auxiliary ratio double Psi0 = -KDelta * N0;//calculation second auxiliary ratio double KDelta1 = ((ThisP / 100.0) * K * Segments) / (MathPow(Segments-N0, 2) / 2.0);//calculate last auxiliary ratio //this completes the calculation of auxiliary ratios for a specific line, it is time to construct it for (int j = 0; j <= N0; j++)//construct the first half of the curve { BalanceMidK[j,i] = (K + Psi0 + (KDelta * j) / 2.0) * j; } for (int j = N0; j <= Segments; j++)//construct the second half of the curve { BalanceMidK[j,i] = BalanceMidK[i, N0] + (K + (KDelta1 * (j-N0)) / 2.0) * (j-N0); } } } }
Tenga en cuenta que "Lines" determina cuántas curvas habrá en nuestra familia. La concavidad aumentará gradualmente desde cero (recta) y así sucesivamente hasta "MaxPercent", exactamente como hemos mostrado en la figura correspondiente. Luego podremos calcular la desviación para cada una de las curvas y seleccionar la mínima:
//+------------------------------------------------------------------+ //| Calculation of the minimum deviation from all lines | //| Parameters: initial balance passed via link | //| Return: minimum deviation | //+------------------------------------------------------------------+ double CalculateMinDeviation(double &OriginalBalance[]) { //define maximum relative deviation for each curve for (int i = 0; i < Lines; i++) { for (int j = 0; j <= Segments; j++) { double CurrentDeviation = OriginalBalance[Segments] ? MathAbs(OriginalBalance[j] - BalanceMidK[j, i]) / OriginalBalance[Segments] : -1.0; if (CurrentDeviation > Deviations[i]) { Deviations[i] = CurrentDeviation; } } } //determine curve with minimum deviation and deviation itself double MinDeviation=0.0; for (int i = 0; i < Lines; i++) { if ( Deviations[i] != -1.0 && MinDeviation == 0.0) { MinDeviation = Deviations[i]; } else if (Deviations[i] != -1.0 && Deviations[i] < MinDeviation) { MinDeviation = Deviations[i]; } } return MinDeviation; }
Así es como debes usarlo:
- Definición del array de balance original "OriginalBalance".
- En base a esto, determinaremos su longitud “SegmentsInput” y el balance final “BalanceInput” y llamaremos al método “InitLines”.
- Después construiremos las curvas llamando al método "BuildBalances".
- Como las curvas están trazadas, podemos considerar nuestro criterio mejorado para la familia de curvas "CalculateMinDeviation".
Esto completará el cálculo del criterio. Creo que el modo de cálculo del "Curve Family Factor" es algo que todos descubrirán muy fácilmente. No es necesario presentar esto aquí.
Búsqueda automática de configuraciones comerciales.
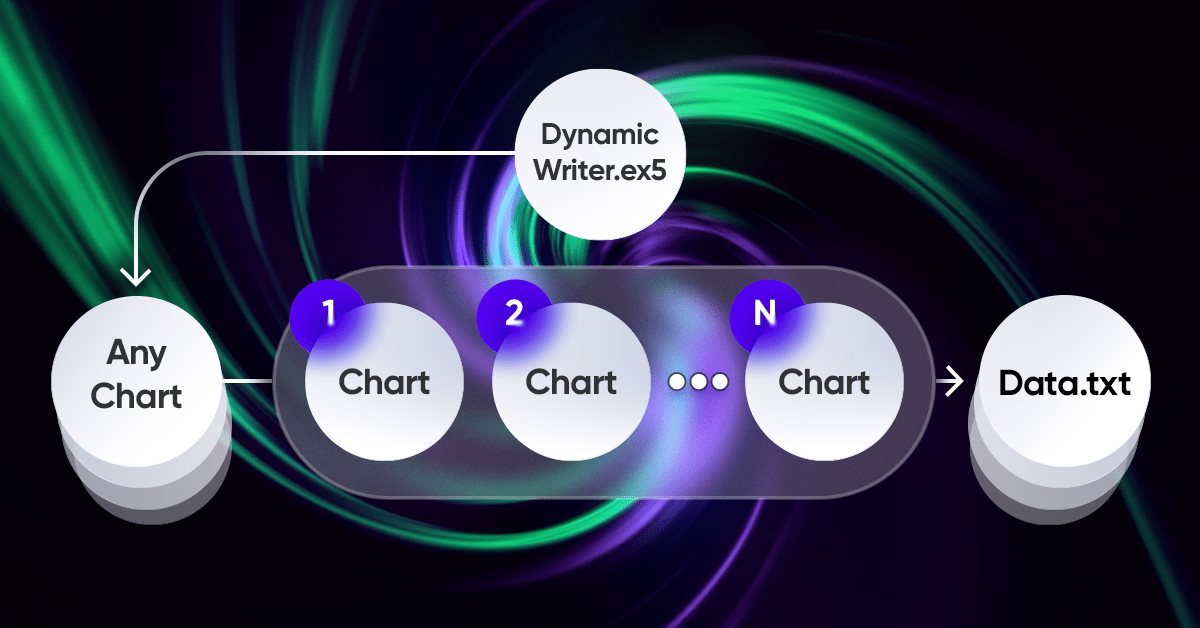
El elemento más importante de toda la idea es el sistema de interacción entre el terminal y el programa. De hecho, supone un optimizador por ciclos con criterios de optimización avanzados, el más importante de los cuales hemos abarcado en la sección anterior. Para que todo el sistema funcione, primero necesitaremos una fuente de cotizaciones, que será uno de los terminales MetaTrader 5. Como ya hemos mostrado en el artículo anterior, las cotizaciones se escriben en un archivo en un formato que nos resulte cómodo. Esto se logra mediante un asesor, que a primera vista funciona de forma bastante extraña:
. 
A nuestro juicio, supone una experiencia bastante interesante y útil usar nuestro esquema único para el funcionamiento de los asesores. Aquí tenemos solo una demostración de los problemas que necesitábamos resolver, pero todo esto también puede usarse para los asesores comerciales:

La peculiaridad de este esquema es que seleccionaremos cualquier gráfico según nuestro criterio. Este gráfico no se usará como herramienta comercial para evitar la duplicación de datos, sino que actuará únicamente como un manejador de ticks o un temporizador, mientras que el resto de los gráficos representará aquellos instrumentos-periodos para los que necesitamos generar las cotizaciones.
El proceso de registro de cotizaciones supone una selección aleatoria de cotizaciones usando un generador de números aleatorios. Podremos optimizar este proceso, si fuera necesario. El registro se producirá después de un cierto periodo de tiempo usando esta función básica:
//+------------------------------------------------------------------+ //| Function to write data if present | //| Write quotes to file | //+------------------------------------------------------------------+ void WriteDataIfPresent() { // Declare array to store quotes MqlRates rates[]; ArraySetAsSeries(rates, false); // Select a random chart from those we added to the workspace ChartData Chart = SelectAnyChart(); // If the file name string is not empty if (Chart.FileNameString != "") { // Copy quotes and calculate the real number of bars int copied = CopyRates(Chart.SymbolX, Chart.PeriodX, 1, int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))), rates); // Calculate ideal number of bars int ideal = int((YearsE*(365.0*(5.0/7.0)*24*60*60)) / double(PeriodSeconds(Chart.PeriodX))); // Calculate percentage of received data double Percent = 100.0 * copied / ideal; // If the received data is not very different from the desired data, // then we accept them and write them to a file if (Percent >= 95.0) { // Open file (create it if it does not exist, // otherwise, erase all the data it contained) OpenAndWriteStart(rates, Chart, CommonE); WriteAllBars(rates); // Write all data to file WriteEnd(rates); // Add to end CloseFile(); // Close and save data file } else { // If there are much fewer quotes than required for calculation Print("Not enough data"); } } }
La función "WriteDataIfPresent" escribe la información sobre las cotizaciones del gráfico seleccionado en un archivo si los datos copiados son al menos el 95% del número ideal de barras calculado según los parámetros especificados. Si los datos copiados son inferiores al 95%, la función mostrará el mensaje "Muy pocos datos". Si el archivo con el nombre establecido no existe, la función lo creará.
Para que este código funcione, deberemos describir adicionalmente lo siguiente:
//+------------------------------------------------------------------+ //| ChartData structure | //| Objective: Storing the necessary chart data | //+------------------------------------------------------------------+ struct ChartData { string FileNameString; string SymbolX; ENUM_TIMEFRAMES PeriodX; }; //+------------------------------------------------------------------+ //| Randomindex function | //| Objective: Get a random number with uniform distribution | //+------------------------------------------------------------------+ int Randomindex(int start, int end) { return start + int((double(MathRand())/32767.0)*double(end-start+1)); } //+------------------------------------------------------------------+ //| SelectAnyChart function | //| Objective: View all charts except current one and select one of | //| them to write quotes | //+------------------------------------------------------------------+ ChartData SelectAnyChart() { ChartData chosenChart; chosenChart.FileNameString = ""; int chartCount = 0; long currentChartId, previousChartId = ChartFirst(); // Calculate number of charts while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; if (currentChartId != ChartID()) { chartCount++; } } int randomChartIndex = Randomindex(0, chartCount - 1); chartCount = 0; currentChartId = ChartFirst(); previousChartId = currentChartId; // Select random chart while (currentChartId = ChartNext(previousChartId)) { if(currentChartId < 0) { break; } previousChartId = currentChartId; // Fill in selected chart data if (chartCount == randomChartIndex) { chosenChart.SymbolX = ChartSymbol(currentChartId); chosenChart.PeriodX = ChartPeriod(currentChartId); chosenChart.FileNameString = "DataHistory" + " " + chosenChart.SymbolX + " " + IntegerToString(CorrectPeriod(chosenChart.PeriodX)); } if (chartCount > randomChartIndex) { break; } if (currentChartId != ChartID()) { chartCount++; } } return chosenChart; }
Este código se usa para registrar y analizar datos históricos del mercado financiero (cotizaciones) para diferentes divisas a partir de varios gráficos que pueden estar abiertos en el terminal en ese momento.
- La estructura "ChartData" se usa para almacenar los datos sobre cada gráfico, incluido el nombre del archivo, el símbolo (par de divisas) y el periodo de tiempo (marco temporal).
- La función "Randomindex(start, end)" generará un número aleatorio entre "start" y "end". Esto se utilizará para seleccionar aleatoriamente uno de los gráficos disponibles.
- "SelectAnyChart()" iterará todos los gráficos abiertos y disponibles, excluyendo el actual, y luego seleccionará aleatoriamente uno de ellos para procesarlo.
El programa recogerá automáticamente las cotizaciones generadas y luego buscará de forma automática las configuraciones rentables. La automatización del proceso completo resulta bastante compleja, pero hemos intentado condensarla en una sola imagen:
figura 5

Existen tres estados de este algoritmo:
- Desactivado.
- Esperando cotizaciones.
- Activo.
Si el asesor para registrar cotizaciones aún no ha generado un solo archivo o hemos eliminado todas las cotizaciones de la carpeta especificada, el algoritmo simplemente esperará a que aparezcan y se detendrá por un momento. En cuanto a nuestro criterio mejorado, que implementamos para en estilo MQL5, también se ha implementado tanto para la fuerza bruta como para la optimización:
figura 6

El modo avanzado trabaja con el factor de familia de curvas, mientras que el algoritmo estándar usa solo el factor de linealidad. Las mejoras restantes son demasiado extensas para incluirlas en este artículo. En el próximo mostraremos nuestro nuevo algoritmo para «pegar» asesores, construido sobre la base de una plantilla universal multidivisa. La plantilla se cuelga en un gráfico, pero procesa todos los sistemas comerciales fusionados, sin necesidad de que cada asesor se inicie en su propio gráfico. Parte de su funcionalidad se ha migrado a este artículo.
Conclusión
Hoy hemos analizado con mayor detalle nuevas nuevas posibilidades e ideas en el campo de la automatización del proceso de desarrollo y optimización de los sistemas comerciales. Los principales logros son el desarrollo de un nuevo algoritmo de optimización, y la creación de un mecanismo de sincronización de los terminales y un optimizador automático, así como un importante criterio de optimización: el factor de curva y la familia de curvas. Esto nos permitirá reducir el tiempo de desarrollo y mejorar la calidad de los resultados obtenidos.
Una adición importante es también la familia de curvas cóncavas, que representan un modelo de balance más realista en el contexto de los periodos forward inversos. El cálculo del factor de correspondencia para cada curva nos permitirá seleccionar con mayor precisión la configuración óptima para el comercio automático.
Enlaces
- Aproximación por fuerza bruta a la búsqueda de patrones (Parte V): Una mirada desde el otro lado
- Aproximación por fuerza bruta a la búsqueda de patrones (Parte IV): Funcionalidad mínima
- Aproximación por fuerza bruta a la búsqueda de patrones (Parte III): Nuevos horizontes
- Aproximación por fuerza bruta a la búsqueda de patrones (Parte II): Inmersión
- Aproximación por fuerza bruta a la búsqueda de patrones
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/9305
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Tienes que
1) Desarrollar un sistema de simulaciones, intervalos de confianza y tomar la curva como resultado no de un cálculo de TS comercial como el que tienes, sino por ejemplo 50 simulaciones de TS en diferentes entornos, la media de estas 50 simulaciones tomarla como resultado de la función fitness, que debe ser maximizada/minimizada.
2) Durante la búsqueda de la mejor curva (a partir del punto 1 ) por el algoritmo de optimización, cada iteración debería correlacionarse para realizar múltiples pruebas.
¿Hay algún ejemplo en el que alguien haya utilizado este enfoque y lo haya llevado a un resultado práctico? Pregunta sin burla, realmente interesante.
¿Hay algún ejemplo de alguien que haya utilizado este enfoque y lo haya llevado a un resultado práctico? La pregunta es sin burla, realmente interesante.
Yo lo he hecho y lo estoy aplicando.
Sería interesante ver ejemplos concretos. Está claro que mucha gente se limita a aplicarlo (aunque con éxito) y se calla. Pero alguien debería tener descripciones detalladas de lo que hicieron, lo que consiguieron y cómo siguieron negociando.
Sería interesante ver ejemplos concretos. Está claro que mucha gente se limita a aplicar (aunque con éxito) y se calla. Pero alguien debería tener descripciones detalladas de lo que hicieron, lo que consiguieron y cómo siguieron negociando.
Ejemplos concretos se pueden ver en la ciencia, la medicina como escribí anteriormente....
Qué y cómo aplicar en el mercado se puede leer en esas publicaciones anteriores ...
Debido al analfabetismo total de los comerciantes y casi comerciantes, ejemplos de la aplicación de estos métodos en los mercados que no verá pronto en el dominio público....
Pero todos estos métodos han estado disponibles y abiertos durante muchos años en forma de proyectos de código abierto sobre la ciencia de datos en lenguajes normales....
En un lenguaje normal, todo esto se escribe en 15 líneas de código.
¿Y qué es la normalidad de los lenguajes de programación, cómo se define?
¿Sabes en qué lenguaje escribió el autor del artículo el código principal de su programa?
¿Cree que la presencia de bibliotecas específicas es un signo de normalidad del lenguaje?
Me gustaría ver discusiones sobre el material del artículo. El autor ha publicado una serie de fórmulas para evaluar el rendimiento de la estrategia, por lo que escribir específicamente acerca de sus deficiencias, razonablemente.
Si va a encajar allí o no se desconoce, porque la selección de reglas de la estrategia es desconocida. No se sabe lo que hay debajo del capó. Tal vez hay predictores seleccionados por algunos otros métodos.....
El autor no impone nada, sino que cuenta su visión y sus logros, lo que es bienvenido en este recurso e incluso alentado financieramente.