Aprendizaje automático y Data Science (Parte 13): Analizamos el mercado financiero usando el análisis de componentes principales (ACP)

El método de componentes principales es un método fundamental de análisis de datos y aprendizaje automático ampliamente usado en aplicaciones que van desde el tratamiento de imágenes y señales hasta las finanzas y las ciencias sociales.
Introducción
El método de componentes principales es un método de reducción de la dimensionalidad que a menudo se usa para reducir la dimensionalidad de grandes conjuntos de datos convirtiendo un conjunto de variables voluminoso en un conjunto más pequeño que sigue conteniendo la mayor parte de la información del conjunto grande.
Reducir el número de variables de una muestra suele tener como contrapartida una menor precisión, pero el truco para reducir la dimensionalidad consiste en sacrificar un poco de precisión para lograr una mayor simplificación. Usted y yo sabemos que un número reducido de variables en un conjunto de datos es más fácil de investigar y visualizar, y el propio análisis de datos resulta mucho más simple y rápido para los algoritmos de aprendizaje automático. Personalmente, no creo que elegir la sencillez a cambio de la precisión sea algo malo cuando se trata del ámbito del trading. Precisión no implica necesariamente beneficio.

La idea básica del método es simple: reducir el número de variables del conjunto de datos conservando toda la información posible. Veamos los pasos que componen el algoritmo del método de componentes principales.
Pasos del algoritmo del método APC
- Normalización de datos
- Cálculo de la matriz de covarianza
- Cálculo de vectores y valores propios
- Cálculo de las estimaciones del ACP y su normalización
- Obtención de componentes
Empezaremos por la normalización de datos.
1. Normalización de datos
El objetivo de la normalización consiste en situar todas las variables en la misma escala para poder compararlas y analizarlas sobre una base común. Al analizar datos, suele ocurrir que tratamos con variables con diferentes unidades o escalas de medida, lo cual puede dar lugar a resultados erróneos y conclusiones incorrectas. Por ejemplo, una media móvil tiene un rango de valores similar al del mercado, y el indicador RSI suele tener valores de 0 a 100. Las dos variables no pueden compararse al usarse juntas en cualquier modelo. Es decir, no pueden usarse ni combinarse en su forma pura para realizar comparaciones.
La normalización de los datos es la transformación de cada variable para que tenga un valor medio de cero y una desviación estándar igual a la unidad. Esto garantiza que cada variable tenga la misma escala y distribución, haciéndolas comparables. La normalización de los datos también puede ayudarnos a mejorar la precisión y estabilidad de los modelos de aprendizaje automático, especialmente cuando las variables tienen magnitudes o desviaciones diferentes.
Para demostrar este punto, utilizaremos datos sobre la tensión arterial. Suelo usar una cierta variedad de datos irrelevantes, solo para comprender mejor los conceptos básicos. Por ejemplo, como ahora, los datos relacionados con una persona, que resultan más fáciles de entender y depurar.
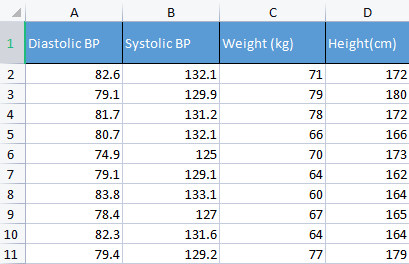
matrix Matrix = matrix_utiils.ReadCsv("bp data.csv"); pre_processing = new CPreprocessing(Matrix, NORM_STANDARDIZATION);
Antes y después:
CS 0 10:17:31.956 PCA Test (NAS100,H1) Non-Standardized data CS 0 10:17:31.956 PCA Test (NAS100,H1) [[82.59999999999999,132.1,71,172] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.09999999999999,129.9,79,180] CS 0 10:17:31.956 PCA Test (NAS100,H1) [81.7,131.2,78,172] CS 0 10:17:31.956 PCA Test (NAS100,H1) [80.7,132.1,66,166] CS 0 10:17:31.956 PCA Test (NAS100,H1) [74.90000000000001,125,70,173] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.09999999999999,129.1,64,162] CS 0 10:17:31.956 PCA Test (NAS100,H1) [83.8,133.1,60,164] CS 0 10:17:31.956 PCA Test (NAS100,H1) [78.40000000000001,127,67,165] CS 0 10:17:31.956 PCA Test (NAS100,H1) [82.3,131.6,64,164] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.40000000000001,129.2,77,179]] CS 0 10:17:31.956 PCA Test (NAS100,H1) Standardized data CS 0 10:17:31.956 PCA Test (NAS100,H1) [[0.979632638610581,0.8604038253411385,0.2240645398825688,0.3760399462363875] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4489982926965129,-0.0540350228475094,1.504433339211528,1.684004976623816] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.6122703991316175,0.4863152056275964,1.344387239295408,0.3760399462363875] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2040901330438764,0.8604038253411385,-0.5761659596980309,-0.6049338265541837] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-2.163355410265021,-2.090739730176784,0.06401843996644889,0.539535575034816] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4489982926965129,-0.3865582403706605,-0.8962581595302708,-1.258916341747898] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.469448957915872,1.276057847245071,-1.536442559194751,-0.9319250841510407] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.7347244789579271,-1.259431686368917,-0.416119859781911,-0.7684294553526122] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.8571785587842599,0.6525768143891719,-0.8962581595302708,-0.9319250841510407] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.326544212870186,-0.3449928381802696,1.184341139379288,1.520509347825387]]
En el contexto del método de los componentes principales, la normalización de los datos supone un paso importante, porque el método se basa en una matriz de covarianza que es sensible a las diferencias de escala y a las diferencias entre variables. Normalizar los datos antes de ejecutar el método nos garantiza que los componentes principales resultantes no estén dominados por variables de mayor magnitud o varianza, lo cual puede distorsionar el análisis y llevar a conclusiones erróneas.
2. Cálculo de la matriz de covarianza
Una matriz de covarianza es una matriz que contiene una medida de cuánto afecta una variable aleatoria a un cambio conjunto, y se utiliza para calcular la covarianza entre cada columna de la matriz de datos. Podemos definir la covarianza entre dos variables aleatorias reales X e Y distribuidas conjuntamente con segundos momentos finitos
![]()
No pasa nada si no entiende esta fórmula. Ya existe una función preparada en la biblioteca estándar del lenguaje MQL5.
matrix Cova = Matrix.Cov(false); Print("Covariances\n", Cova);
Resultados
CS 0 10:17:31.957 PCA Test (NAS100,H1) Covariances CS 0 10:17:31.957 PCA Test (NAS100,H1) [[1.111111111111111,1.05661579634328,-0.2881675653452953,-0.3314539233600543] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.05661579634328,1.111111111111111,-0.2164241126576326,-0.2333966556085017] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.2881675653452953,-0.2164241126576326,1.111111111111111,1.002480628180182] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.3314539233600543,-0.2333966556085017,1.002480628180182,1.111111111111111]]
Recordemos que la covarianza es una matriz cuadrada con valores en la diagonal iguales a 1. Al llamar a este método de matriz de covarianza, la entrada rowval debe establecerse en false.
matrix matrix::Cov( const bool rowvar=true // rows or cols vectors of observations );
así que necesitaremos que nuestra matriz cuadrada sea una matriz unitaria basada en las columnas que fijamos con esta función, y tenemos 4 columnas. En la salida tendríamos una matriz 4x4, de lo contrario sería una matriz 8x8.
3. Cálculo de vectores y valores propios
Los vectores propios son vectores especiales vinculados a una matriz cuadrada. Un vector propio de una matriz es un vector distinto a cero que, al multiplicarse por la matriz, da un número escalar múltiplo de sí mismo, llamado valor propio.
Formalmente, si A es una matriz cuadrada, entonces un vector v distinto a cero será un vector propio de A si existe un escalar λ llamado valor propio, de modo que Av = λv. Podrá leer más información aquí.
Como antes, no será necesario conocer y comprender la fórmula de cálculo: puede utilizar la función de la biblioteca estándar
if (!Cova.Eig(component_matrix, eigen_vectors)) Print("Failed to get the Component matrix matrix & Eigen vectors");
Si miramos el método Eig más de cerca
bool matrix::Eig( matrix& eigen_vectors, // matrix of eigenvectors vector& eigen_values // vector of eigenvalues );
Podremos observar que la primera matriz de entrada eigen_vectors retorna eigenvectores. Sin embargo, este vector propio también puede denominarse matriz de componentes. Así que guardaremos estos vectores propios en una matriz de componentes, dado que llamarlos vectores propios puede resultar confuso, pues según las normas de lenguaje MQL5 esto es en realidad una matriz.
Print("\nComponent matrix\n",component_matrix,"\nEigen Vectors\n",eigen_vectors);
Resultados
CS 0 10:17:31.957 PCA Test (NAS100,H1) Component matrix CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.5276049902734494,0.459884739531444,0.6993704635263588,-0.1449826035480651] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4959779194731578,0.5155907011803843,-0.679399121133044,0.1630612352922813] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4815459137666799,0.520677926282417,-0.1230090303369406,-0.6941734714553853] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4937128827246101,0.5015643052337933,0.184842006606018,0.6859404272536788]] CS 0 10:17:31.957 PCA Test (NAS100,H1) Eigen Vectors CS 0 10:17:31.957 PCA Test (NAS100,H1) [2.677561590453738,1.607960239905343,0.04775016337426833,0.1111724507110918]
5. Cálculo de las estimaciones del ACP
Obtener los resultados del método de componentes principales es muy sencillo y apenas requiere una línea de código.
pca_scores = Matrix.MatMul(component_matrix);
Para hallar las estimaciones del método, deberemos multiplicar la matriz normalizada por la matriz de componentes.
Resultados
CS 0 10:17:31.957 PCA Test (NAS100,H1) PCA SCORES CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537,0.1425145462368588,0.1006701620494091] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321,-0.1510888243020112,0.1670753033981925] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756,0.001937917070391801,-0.6847663538666366] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518,-0.4827665581567511,0.09571954869438426] CS 0 10:17:31.957 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386,-0.0006861487484489809,0.2983796568520111] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733,-0.1738415909335406,-0.2393186981373224] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769,0.1774740257067155,0.4223436077935874] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977,0.2509606394263523,-0.337079680008286] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656,0.09411419638842802,-0.03495245015036286] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609,0.1413817973120564,0.2119289033750197]]
Una vez obtenidas las estimaciones del método, tendremos que normalizarlas.
pre_processing = new CPreprocessing(pca_scores_standardized, NORM_STANDARDIZATION); Resultados
CS 0 10:17:31.957 PCA Test (NAS100,H1) PCA SCORES | STANDARDIZED CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.4187491401035159,0.9970295470975233,0.68746486754918,0.3182591681100855] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.172130620033975,1.15846730049564,-0.7288256625700642,0.528192723531639] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.1731572094549987,1.181160740523977,0.009348167869829477,-2.164823873278453] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.715386880184365,-0.05481045923432144,-2.328780161211247,0.3026082735855334] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.594713612332284,-1.470442808583469,-0.003309859736641006,0.9432989819176616] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4023014443028848,-1.250129598312728,-0.8385809690405054,-0.7565833632510734] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.68012890598631,0.05510361946569121,0.8561031894464458,1.335199254045385] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2786284867625921,-1.321151824538665,1.210589566461227,-1.06564543418136] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.074244269325531,-0.1690934905926844,0.4539901733759543,-0.1104988556867913] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.072180711318756,0.8738669736790375,0.6820006878558206,0.6699931252073736]]
6. Obtención de los componentes del método
Por último (pero no por ello menos importante), deberemos conseguir los componentes principales; de hecho, este es el objetivo principal de todos los pasos que hemos dado hasta ahora.
Para obtener los componentes, primero tendremos que calcular los coeficientes de las estimaciones del método no normalizado. Al fin y al cabo, ahora tenemos dos métodos de estimación: uno normalizado y otro no normalizado.
Los coeficientes de la puntuación de cada método suponen simplemente la varianza de cada columna en la columna de estimación.
pca_scores_coefficients.Resize(cols); vector v_row; for (ulong i=0; i<cols; i++) { v_row = pca_scores.Col(i); pca_scores_coefficients[i] = v_row.Var(); //variance of the pca scores }
Resultados
2023.02.25 10:17:31.957 PCA Test (NAS100,H1) SCORES COEFF [2.409805431408367,1.447164215914809,0.04297514703684173,0.1000552056399828]
Para extraer el componente, hay que considerar los siguientes criterios:
- Criterio del valor propio: este criterio consiste en elegir los componentes principales con los valores propios más elevados. La idea es que los mayores números de eigen se correspondan con los componentes principales que abarquen la mayor varianza de los datos.
- Criterio de proporción de la varianza: este criterio consiste en seleccionar los componentes principales que expliquen una determinada proporción de la varianza total de los datos. En esta biblioteca, estableceremos el valor por encima del 90%.
- Criterio de selección: este criterio consiste en analizar un gráfico que muestre los valores propios de cada componente principal en orden descendente. El punto en el que la curva empieza a aplanarse se usa como umbral para seleccionar los principales componentes que deben conservarse.
- Criterio de Kaiser: este criterio supone que solo se almacenan los componentes principales con valores propios superiores al valor medio de los coeficientes. En otras palabras, se trata del componente principal con coeficientes superiores a la unidad.
- Criterio de validación cruzada: este criterio consiste en evaluar el rendimiento del modelo en la muestra de validación y seleccionar los componentes principales que ofrecen la mejor precisión predictiva.
Esta biblioteca implementa los que considero los tres mejores y más eficientes criterios desde el punto de vista computacional. Se trata de la proporción de varianza, el gráfico de Kaiser y el gráfico de declive. Podrá elegir el adecuado de la lista:
enum criterion
{
CRITERION_VARIANCE,
CRITERION_KAISER,
CRITERION_SCREE_PLOT
};
A continuación le mostramos la función completa para extraer los componentes principales:
matrix Cpca::ExtractComponents(criterion CRITERION_) { vector vars = pca_scores_coefficients; vector vars_percents = (vars/(double)vars.Sum())*100.0; //--- for Kaiser double vars_mean = pca_scores_coefficients.Mean(); //--- for scree double x[], y[]; //--- matrix PCAS = {}; double sum=0; ulong max; vector v_cols = {}; switch(CRITERION_) { case CRITERION_VARIANCE: #ifdef DEBUG_MODE Print("vars percentages ",vars_percents); #endif for (int i=0, count=0; i<(int)cols; i++) { count++; max = vars_percents.ArgMax(); sum += vars_percents[max]; vars_percents[max] = 0; v_cols.Resize(count); v_cols[count-1] = (int)max; if (sum >= 90.0) break; } PCAS.Resize(rows, v_cols.Size()); for (ulong i=0; i<v_cols.Size(); i++) PCAS.Col(pca_scores.Col((ulong)v_cols[i]), i); break; case CRITERION_KAISER: #ifdef DEBUG_MODE Print("var ",vars," scores mean ",vars_mean); #endif vars = pca_scores_coefficients; for (ulong i=0, count=0; i<cols; i++) if (vars[i] > vars_mean) { count++; PCAS.Resize(rows, count); PCAS.Col(pca_scores.Col(i), count-1); } break; case CRITERION_SCREE_PLOT: v_cols.Resize(cols); for (ulong i=0; i<v_cols.Size(); i++) v_cols[i] = (int)i+1; vars = pca_scores_coefficients; SortAscending(vars); //Make sure they are in ascending first order ReverseOrder(vars); //Set them to descending order VectorToArray(v_cols, x); VectorToArray(vars, y); plt.ScatterCurvePlots("Scree plot",x,y,"variance","PCA","Variance"); //--- vars = pca_scores_coefficients; for (ulong i=0, count=0; i<cols; i++) if (vars[i] > vars_mean) { count++; PCAS.Resize(rows, count); PCAS.Col(pca_scores.Col(i), count-1); } break; } return (PCAS); }
El criterio de Kaiser se establece para seleccionar los componentes principales con coeficientes que expliquen más del 90% de todos los valores atípicos. Así que hemos tenido que convertir las desviaciones en porcentajes:
vector vars = pca_scores_coefficients; vector vars_percents = (vars/(double)vars.Sum())*100.0;
A continuación mostramos los resultados de cada método.
CRITERION KAISER:
CS 0 12:03:49.579 PCA Test (NAS100,H1) PCA'S CS 0 12:03:49.579 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518] CS 0 12:03:49.579 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609]]
CRITERION VARIANCE:
CS 0 12:03:49.579 PCA Test (NAS100,H1) PCA'S CS 0 12:03:49.579 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518] CS 0 12:03:49.579 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609]]
CRITERION SCREE PLOT:

Excelente, ahora tenemos los dos componentes principales. En términos sencillos, el conjunto de datos se reduce de 4 a 2 variables. Ahora, podremos utilizar estas variables en cualquier proyecto en el que estemos trabajando.
El método de componentes principales en MetaTrader
Ha llegado el momento de usar el método de los componentes principales para lo que todos estamos aquí: el ámbito del trading.
Para ello hemos tomado 10 osciladores. Como todos son osciladores, hemos decidido probarlos para demostrar que si tenemos 10 indicadores del mismo tipo, podemos utilizar el método de componentes principales para reducirlos y acabar con varias variables con las que sea fácil trabajar.
He ejecutado 10 indicadores en un gráfico: ATR, Bears Power, MACD, Chaikin Oscillator, Commodity Channel Index, De marker, índice de fuerza, Momentum, RSI y rango porcentual de Williams.
handles[0] = iATR(Symbol(),PERIOD_CURRENT, period); handles[1] = iBearsPower(Symbol(), PERIOD_CURRENT, period); handles[2] = iMACD(Symbol(),PERIOD_CURRENT,12, 26,9,PRICE_CLOSE); handles[3] = iChaikin(Symbol(), PERIOD_CURRENT,12,26,MODE_SMMA,VOLUME_TICK); handles[4] = iCCI(Symbol(),PERIOD_CURRENT,period, PRICE_CLOSE); handles[5] = iDeMarker(Symbol(),PERIOD_CURRENT,period); handles[6] = iForce(Symbol(),PERIOD_CURRENT,period,MODE_EMA,VOLUME_TICK); handles[7] = iMomentum(Symbol(),PERIOD_CURRENT,period, PRICE_CLOSE); handles[8] = iRSI(Symbol(),PERIOD_CURRENT,period,PRICE_CLOSE); handles[9] = iWPR(Symbol(),PERIOD_CURRENT,period); for (int i=0; i<10; i++) { matrix_utiils.CopyBufferVector(handles[i],0,0,bars,buff_v); ind_Matrix.Col(buff_v, i); //store each indicator in ind_matrix columns }
Hemos representado todos estos indicadores en un único gráfico. Este es el aspecto que tienen:

Entonces, ¿por qué todos parecen casi idénticos? Echemos un vistazo a su matriz de correlaciones:
Print("Oscillators Correlation Matrix\n",ind_Matrix.CorrCoef(false));
Resultados
CS 0 18:03:44.405 PCA Test (NAS100,H1) Oscillators Correlation Matrix CS 0 18:03:44.405 PCA Test (NAS100,H1) [[1,0.01772984879133655,-0.01650305145071043,0.03046861668248528,0.2933315924162302,0.09724971519249033,-0.054459564042778,-0.0441397473782667,0.2171969726706487,0.3071254662907512] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.01772984879133655,1,0.6291675928958272,0.2432064602541826,0.7433991440764224,0.7857575973967624,0.8482060554701495,0.8438879842180333,0.8287766948950483,0.7510097635884428] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.01650305145071043,0.6291675928958272,1,0.80889919514547,0.3583185473647767,0.79950773673123,0.4295059398014639,0.7482107564439531,0.8205910850439753,0.5941794310595322] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.03046861668248528,0.2432064602541826,0.80889919514547,1,0.03576792595345671,0.436675349452699,0.08175026884450357,0.3082792264724234,0.5314362133025707,0.2271361556104472] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.2933315924162302,0.7433991440764224,0.3583185473647767,0.03576792595345671,1,0.6368513319457978,0.701918992559641,0.6677393692960837,0.7952832674277922,0.8844891719743937] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.09724971519249033,0.7857575973967624,0.79950773673123,0.436675349452699,0.6368513319457978,1,0.6425071357003039,0.9239712092224102,0.8809179254503203,0.7999862160768584] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.054459564042778,0.8482060554701495,0.4295059398014639,0.08175026884450357,0.701918992559641,0.6425071357003039,1,0.7573281438252102,0.7142333470379938,0.6534102287503526] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.0441397473782667,0.8438879842180333,0.7482107564439531,0.3082792264724234,0.6677393692960837,0.9239712092224102,0.7573281438252102,1,0.8565660350098397,0.8221821793990941] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.2171969726706487,0.8287766948950483,0.8205910850439753,0.5314362133025707,0.7952832674277922,0.8809179254503203,0.7142333470379938,0.8565660350098397,1,0.8866871375902136] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.3071254662907512,0.7510097635884428,0.5941794310595322,0.2271361556104472,0.8844891719743937,0.7999862160768584,0.6534102287503526,0.8221821793990941,0.8866871375902136,1]]
Si observamos la matriz de correlaciones, solo unos pocos indicadores se correlacionan con otros, pero son una minoría, así que, después de todo, no son idénticos. Vamos a aplicar el método de componentes principales a esta matriz y veamos qué nos da.
pca = new Cpca(ind_Matrix); matrix pca_matrix = pca.ExtractComponents(ENUM_CRITERION);Hemos seleccionado el criterio de gráficos de declive:

Del gráfico se desprende claramente que solo se han seleccionado tres componentes principales cuyo aspecto se muestra a continuación:
CS 0 15:03:30.992 PCA Test (NAS100,H1) PCA'S CS 0 15:03:30.992 PCA Test (NAS100,H1) [[-2.297373513063062,0.8489493134565058,0.02832445955171548] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-2.370488225540198,0.9122356709081817,-0.1170316144060158] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-2.728297784013197,1.066014896296926,-0.2859442064697605] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-1.818906988827231,1.177846546204641,-0.748128826146959] ... ... CS 0 15:03:30.992 PCA Test (NAS100,H1) [-3.26602969252589,0.4816995789189212,-0.7408982990360158] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-3.810781495417407,0.4426824869307094,-0.5737277071364888…]
Solo quedan 3 de las 10 variables,
por eso es importante ser analista además de tráder. Muchas veces he visto tráders con muchos indicadores en el gráfico, y a veces incluso en asesores. Creo que esta forma de reducción de variables merece la pena para reducir los costes de cálculo. Por cierto, no se lo tome como un consejo comercial. Si lo que hace funciona y está satisfecho con ello, no tiene de qué preocuparse.
Vamos a representar estos componentes principales para ver cómo se ven en el mismo eje.
plt.ScatterCurvePlotsMatrix("pca's ",pca_matrix,"var","PCA");
Resultados

Ventajas del método de los componentes principales
- Reducción de la dimensionalidad: este método puede reducir eficazmente el número de variables de un conjunto de datos preservando la información más importante. Esto puede simplificar el análisis y la visualización de los datos, reducir la complejidad de los procesos computacionales y mejorar el rendimiento de los modelos.
- Compresión de datos: el método puede usarse para comprimir eficazmente grandes conjuntos de datos en un número menor de componentes principales, lo cual puede ahorrar espacio de almacenamiento y reducir el tiempo de transmisión de los datos.
- Eliminación de ruidos: el método puede eliminar el ruido o las variaciones aleatorias de los datos para centrarse en los patrones o tendencias más significativos. Como acaba de ver, los 10 osciladores tenían bastante ruido.
- Resultados interpretables: los componentes principales resultantes pueden interpretarse y visualizarse fácilmente, lo cual resulta útil para comprender la estructura de los datos.
- Normalización de los datos: el método normaliza los datos ajustándolos a la varianza unitaria para eliminar los efectos de las diferencias en las escalas de las variables y mejorar la precisión de los modelos.
Desventajas del método de componentes principales.
- Pérdida de datos: el método puede descartar demasiados componentes principales o dejar aquellos que no abarcan toda la diversidad de los datos.
- La interpretación de los resultados puede ser complicada porque resulta difícil entender cuáles son las variables, sobre todo cuando las variables originales están muy correlacionadas o cuando se obtienen muchos componentes principales.
- Sensibilidad a los valores atípicos: como ocurre con muchos métodos de ML, los valores atípicos pueden distorsionar el algoritmo y provocar resultados sesgados.
- Demanda muchos recursos informáticos. En un conjunto de datos voluminoso, el método de componentes principales puede provocar el mismo problema que intenta resolver.
- El método supone que los datos están relacionados linealmente y que los componentes principales no están correlacionados, lo cual de hecho no siempre es cierto. Y si no es así, los resultados no serán fiables.
Conclusiones finales
En conclusión, el método de los componentes principales (ACP) es un potente método que puede usarse para reducir la dimensionalidad de los datos conservando la información más importante. Identificando los principales componentes del conjunto de datos, podemos hacernos una idea de las principales estructuras del mercado. El método se usa ampliamente fuera del trading, por ejemplo en ingeniería y biología. Aunque es un método matemáticamente intensivo, sus ventajas hacen que merezca la pena tenerlo en cuenta. Con el enfoque y los datos adecuados, el método puede ayudarnos en la búsqueda de nuevos enfoques, y también a tomar decisiones comerciales informadas basadas en los datos.
Siga el desarrollo del tema en mi repositorio de GitHub https://github.com/MegaJoctan/MALE5
| Archivo | Descripción |
|---|---|
| matrix_utils.mqh | Contiene funciones matriciales adicionales |
| pca.mqh | Biblioteca principal del método de componentes principales |
| plots.mqh | Contiene una clase de ayuda para dibujar vectores |
| preprocessing.mqh | Biblioteca para preparar y escalar los datos para los algoritmos de ML |
| PCA Test.mqh | Asesor para probar el algoritmo y todo lo explicado en este artículo |
Artículos relacionados:
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/12229
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Preguntas: ¿Qué indicadores tienen una correlación inversa? ¿Puede variar este indicador en función del activo y de los parámetros? En este programa, ¿se pueden insertar otros indicadores en el manipulador para poder evaluarlos conjuntamente? ¡Vuestros artículos son geniales! ¡Muchas gracias!
Dudas: 1 - ¿Cuáles son los 3 indicadores? Están inversamente correlacionados entre sí. ¿Es correcto? 2 - ¿Se puede cambiar el programa para insertar más indicadores? Indicadores de tendencia como la media móvil y el indicador de volumen en el programa? 3 - ¿Este resultado de los 3 indicadores cambia para cada activo, marco de tiempo y parámetros respectivos?
gracias por leer mi artículo, hay un montón de ideas e indicadores para jugar con este programa. No puedo explorar todos ellos tbh yo sugeriría descargar el programa y jugar con él como creo que el artículo es muy claro. Nadie puede hacer el trabajo por usted especialmente para usted, especialmente de forma gratuita.