
Aprendizaje automático y Data Science (Parte 14): Aplicación de los mapas de Kohonen a los mercados

Introducción
Los mapas de Kohonen, mapas autoorganizados o Self Organizing Feature Maps (SOFM) son una técnica de aprendizaje automático no supervisado que se utiliza para crear un espacio de baja dimensionalidad (generalmente bidimensional) para representar un conjunto de datos multidimensional preservando la estructura topológica de los datos. Por ejemplo, tenemos un conjunto de datos de p variables medidas en n observaciones: se pueden representar como grupos de observaciones con los mismos valores de variables. Estos clústeres se pueden representar luego como un mapa 2D, en este caso, además, las observaciones en los clústeres cercanos tendrán valores más similares que aquellos en los distantes. Esto puede facilitar la visualización y el análisis de los datos multidimensionales.
Los mapas de Kohonen fueron desarrollados por el matemático finlandés Teuvo Kohonen en la década de los 80 del siglo pasado.
Información general
El mapa de Kohonen consiste en una cuadrícula de neuronas conectadas a las neuronas vecinas. Durante el entrenamiento, las entradas se presentan a la red y cada neurona calcula su similitud con las entradas. La neurona con la mayor similitud es la ganadora y sus pesos se ajustarán para que coincidan mejor con la entrada.

Con el tiempo, las neuronas vecinas también ajustarán sus pesos para volverse más similares a la neurona ganadora, lo cual da como resultado un ordenamiento topológico de las neuronas en el mapa. Gracias a los mapas de Kohonen, este proceso de autoorganización hace posible representar relaciones complejas entre las entradas en un espacio de dimensiones más pequeñas. Esta característica resulta muy valiosa al visualizar y clusterizar datos.
Algoritmo de entrenamiento
El objetivo del algoritmo de mapa autoorganizado es hacer que diferentes partes de la red respondan de la misma forma a ciertos patrones de entrada. Esto se debe en parte a cómo se procesa la información visual, auditiva y de otro tipo en ciertas partes del cerebro humano.
Veamos cómo funciona este algoritmo en cuanto a los cálculos matemáticos y el código MQL5.
Pasos del algoritmo
El desarrollo del algoritmo consta de cuatro pasos principales:
Paso 1 — inicialización de los pesos ![]() . Podemos utilizar valores aleatorios. Este paso también inicializa otros parámetros como la tasa de aprendizaje y el número de clústeres.
. Podemos utilizar valores aleatorios. Este paso también inicializa otros parámetros como la tasa de aprendizaje y el número de clústeres.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); }
Los parámetros se inicializan en el constructor de la clase de mapas de Kohonen.
Los mapas de Kohonen son una técnica de análisis intelectual de datos. En esta etapa, necesitaremos obtener dichos datos. De ello se encarga save_clusters=true, aquí obtenemos los clústeres que los mapas de Kohonen han recopilado para nosotros.
El paso 2 es el cálculo de la distancia euclidiana entre cada entrada y los pesos correspondientes.
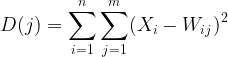
Donde:
![]() = Vector de entrada
= Vector de entrada
![]() = Vector de coeficientes de peso
= Vector de coeficientes de peso
double CKohonenMaps:: Euclidean_distance(const vector &v1, const vector &v2) { double dist = 0; if(v1.Size() != v2.Size()) Print(__FUNCTION__, " v1 and v2 not matching in size"); else { double c = 0; for(ulong i=0; i<v1.Size(); i++) c += MathPow(v1[i] - v2[i], 2); dist = MathSqrt(c); } return(dist); }
Para poner a prueba la fórmula, necesitaremos un conjunto de datos simple. Lo usaremos al escribir el código y realizar las pruebas.
matrix Matrix = { {1.2, 2.3}, {0.7, 1.8}, {3.6, 4.8}, {2.8, 3.9}, {5.2, 6.7}, {4.8, 5.6} }; maps = new CKohonenMaps(Matrix); //Giving our kohonen maps class data
A continuación, se llamará al constructor y se generarán los coeficientes de peso; en la salida obtendremos:
CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) w Matrix CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [[0.005340739158299509,0.01220740379039888] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [0.5453352458265939,0.9172643208105716]] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) Matrix CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [0.7,1.8] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [3.6,4.8] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [2.8,3.9] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [4.8,5.6]]
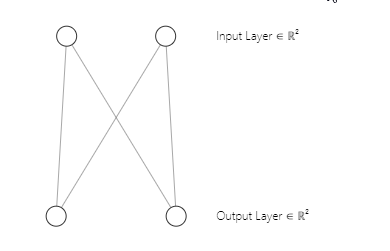
Quizá haya notado que la arquitectura de nuestra red neuronal es [2 entradas y 2 salidas]. Precisamente por eso terminamos con una matriz de pesos de 2x2. La matriz se generará teniendo en cuenta [2 columnas de la matriz de entrada n y 2 clústeres seleccionados m]. Línea de código de la primera parte:
w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE);Entonces, este será el aspecto de la arquitectura de nuestra red neuronal de mapas de Kohonen:
Paso 3 — búsqueda del ganador con el índice i para el que D(j) tenga el valor mínimo. En pocas palabras, hallaremos un clúster de unidades. Y aquí llegamos al importante tema del aprendizaje competitivo en los mapas de Kohonen.
Aprendizaje competitivo
Un mapa autoorganizado es un tipo de red neuronal artificial que, a diferencia de otros tipos de redes neuronales artificiales que aprenden de los errores (como la propagación inversa del descenso de gradiente), utilizan el aprendizaje competitivo.
En el aprendizaje competitivo, las neuronas en el mapa de Kohonen compiten entre sí para convertirse en la "ganadora". Para ello, la neurona deberá ser la más semejante a la entrada.
Durante la fase de entrenamiento, cada punto de los datos de entrada se representará en un mapa de Kohonen. Luego se calculará la similitud entre los datos de entrada y el vector de peso de cada neurona. La neurona cuyo vector sea más similar a los datos de entrada se determinará como ganadora o "unidad de mejor coincidencia" (best matching unit, BMU).
La BMU se elegirá según la distancia euclidiana más pequeña entre los datos de entrada y el vector de peso de la neurona. La neurona ganadora actualizará a continuación su vector de peso para parecerse más a la entrada. La fórmula de actualización del peso utilizada es la regla de aprendizaje de Kohonen, que desplaza el vector de peso de la neurona ganadora y sus neuronas vecinas más cerca de la entrada.
Cómo se ve el paso 3 en el código. Ocupa varias líneas de código.
vector D(m); //Euclidean distance btn clusters | Remember m is the number of clusters selected for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif
Recuerde que la neurona que produce la clase con la distancia euclidiana más pequeña es el clúster ganador.
A través del aprendizaje competitivo, el mapa de Kohonen aprende a crear una representación topológica de los datos de entrada en un espacio de dimensiones más pequeñas al tiempo que mantiene las relaciones entre los datos de entrada.
Paso 4 — actualización de los pesos.
Para actualizar los pesos, utilizaremos la siguiente fórmula.
![]()
Donde:
![]() — nuevo vector de escala
— nuevo vector de escala
![]() — antiguo vector de escala
— antiguo vector de escala
![]() — tasa de aprendizaje
— tasa de aprendizaje
![]() — vector de entrada
— vector de entrada
En el código, esta fórmula se verá así:
//--- weights update ulong min = D.ArgMin(); //winning cluster vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min);
A diferencia de otros tipos de redes neuronales artificiales que utilizan todos los pesos para una capa en particular, los mapas de Kohonen tienen en cuenta los pesos para un clúster concreto y los usan para encontrar solo ese clúster.
Bien, ya hemos terminado con los pasos y finalizado nuestro algoritmo. Veamos ahora cómo funciona todo.
A continuación le mostramos el código completo del algoritmo a partir de este momento.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif }
Resultados
CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [2.122748018266242,1.822857430002081] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [1.434132188481296,1.100846180984197] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [5.569896531530945,5.257391342266398] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [4.36622216533946,4.000958814345993] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [8.053842751911217,7.646959164093921] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [6.966950064745546,6.499246789416081] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Epoch [1/100] | 0.000 Seconds Elapsed .... .... .... CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [0.7271897806071723,4.027137175049654] Winning cluster 0 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [0.08133608432880858,4.734224801594559] Winning cluster 0 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [4.18281664576938,0.5635073709012016] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [2.979092473547668,1.758946102746018] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [6.664860479474853,1.952054507391296] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [5.595867985957728,0.8907607121421737] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Epoch [100/100] | 0.000 Seconds Elapsed CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) New weights CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) [[0.75086979456201,4.028060179594681] CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) [1.737580668068743,5.173650598091957]]
Genial, todo funciona, nuestros mapas de Kohonen han logrado agrupar nuestra matriz primaria.
matrix Matrix = { {1.2, 2.3}, //Into cluster 0 {0.7, 1.8}, //Into cluster 0 {3.6, 4.8}, //Into cluster 1 {2.8, 3.9}, //Into cluster 1 {5.2, 6.7}, //Into cluster 1 {4.8, 5.6} //Into cluster 1 };
Todo ha salido como esperábamos. Sin embargo, presentar este resultado y visualizarlo en un gráfico no resulta tan fácil como parece. Tenemos dos clústeres, uno de ellos es una matriz de 2x2, mientras que el otro es una matriz de 4x2. Uno tiene 4 valores, y el otro, 8. Si recuerda, en el artículo "Clusterización con el método de k-medias en MQL5", tuvimos problemas para representar los clústeres debido a esta diferencia de tamaño.
Tensores en el aprendizaje automático
Un tensor supone una generalización de vectores y matrices dentro de una matriz multidimensional. Dicho de forma simple: un tensor es un array que contiene matrices y vectores en su interior. En python se ve así:
# create tensor from numpy import array T = array([ [[1,2,3], [4,5,6], [7,8,9]], [[11,12,13], [14,15,16], [17,18,19]], [[21,22,23], [24,25,26], [27,28,29]], ])
Los tensores son una estructura de datos fundamental usada por los marcos de trabajo para el aprendizaje automático como TensorFlow, PyTorch y Keras.
Los tensores se usan en algoritmos de aprendizaje automático para la multiplicación de matrices, la convolución, la combinación y otras operaciones. Los tensores también se utilizan para almacenar y gestionar los pesos y desplazamientos de las redes neuronales durante el entrenamiento y la inferencia. Como una estructura de datos importante en el aprendizaje automático, los tensores nos permiten realizar cálculos y representar datos complejos de forma eficiente.
En nuestro caso, hemos importado la biblioteca Tensors.mqh. Encontrará más detalles en mi GitHub wiki.
Asimismo, hemos añadido tensores para recopilar conjuntos de clústeres para cada tensor.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); Print("w Matrix\n",w_matrix,"\nMatrix\n",Matrix); vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); if (epoch == epochs-1) //last iteration cluster_tensor.TensorAppend(Matrix.Row(i), min); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); //Print("New w_Matrix\n ",w_matrix); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of the training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif //--- Print("\nclusters"); cluster_tensor.TensorPrint(); }
Resultados
CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) clusters CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [0.7,1.8]] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [[3.6,4.8] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [2.8,3.9] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [4.8,5.6]]
Ahora nuestros clústeres se almacenan en los tensores correspondientes. Ha llegado el momento de hacer algo útil con esto.
Extracción de clústeres
Vamos a extraer los clústeres y a guardarlos en archivos CSV.
matrix mat= {}; if (save_clusters) for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); //Obtain a matrix located at I index in a cluster tensor string header[]; ArrayResize(header, (int)mat.Cols()); for (int k=0; k<ArraySize(header); k++) header[k] = "col"+string(k); if (this.matrix_utils.WriteCsv("SOM\\Cluster"+string(i+1)+".csv",mat,header)) Print("Clusters CSV files saved under the directory Files\\SOM"); }
Los archivos se almacenarán en el directorio SOM dentro del directorio principal Files.
Ya hemos terminado de extraer los datos, pero una parte importante de los mapas de Kohonen es la visualización y la construcción de mapas. Las bibliotecas de Python y otros marcos de trabajo suelen usar mapas de calor. Para esto, usaremos un gráfico de curvas.
vector v; matrix plotmatrix(rows, m); for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); v = this.matrix_utils.MatrixToVector(mat); plotmatrix.Col(v, i); } this.plt.ScatterCurvePlotsMatrix("kom",plotmatrix,"Map","clusters","clusters");
Resultados
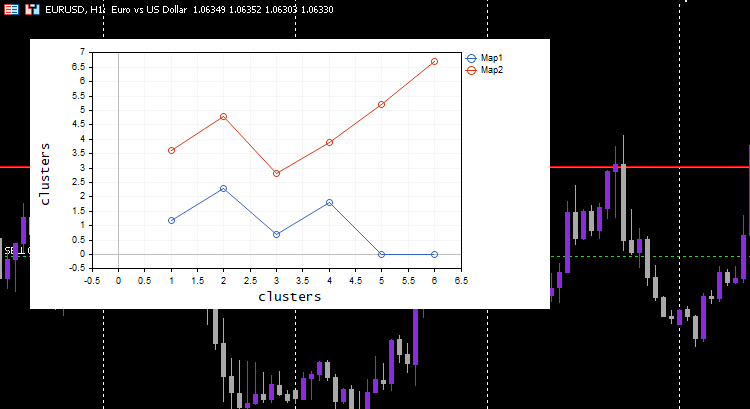
Todo funciona: el gráfico representa los datos perfectamente, como esperábamos. Ahora probaremos el algoritmo en algo útil.
Clusterización de los valores del indicador
Vamos a recopilar 100 barras para cinco medias móviles diferentes e intentar agruparlas usando los mapas de Kohonen. Todos los indicadores operarán con el mismo gráfico, marco temporal y precio de cálculo. Solo se diferenciarán los periodos de cálculo de la media móvil.
#include <MALE5\Neural Networks\kohonen maps.mqh> #include <MALE5\matrix_utils.mqh> CMatrixutils matrix_utils; CKohonenMaps *maps; input int bars = 100; int handles[5]; int period[5] = {10,20,30,50,100}; matrix Matrix(bars,5); //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- vector v; for (int i=0; i<5; i++) { handles[i] = iMA(Symbol(),PERIOD_CURRENT,period[i],0,MODE_LWMA,PRICE_CLOSE); matrix_utils.CopyBufferVector(handles[i],0,0,bars, v); Matrix.Col(v, i); //store indicators into a matrix } maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //--- return(INIT_SUCCEEDED); }
Hemos establecido una tasa de aprendizaje/alfa = 0.01 y una época = 1000. Ahora tenemos estos mapas de Kohonen.
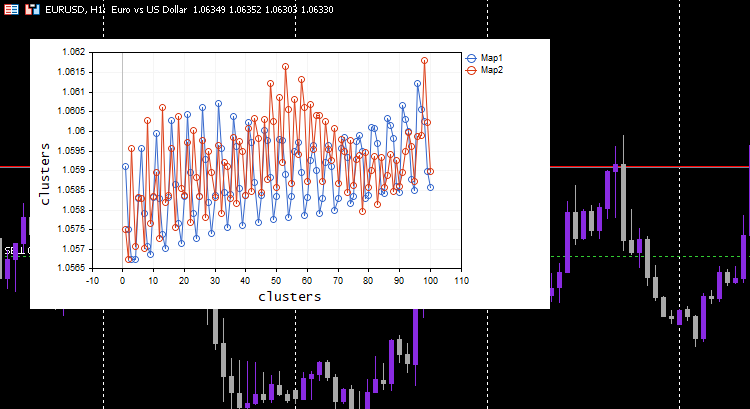
Parece extraño, así que he revisado los registros para entender el motivo. Esto es lo que vemos:
CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) clusters CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) [[1.059108363197969,1.057514381244092,1.056754472954214,1.056739184229631,1.058300613902105] CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) [1.059578181379783,1.057915286006,1.057066064352063,1.056875795994335,1.05831249905062] .... .... CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [1.063954363197777,1.061619428863266,1.061092386932678,1.060653270504107,1.059293304991227] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [1.065106545015954,1.062409714577555,1.061610946072463,1.06098919991587,1.059488318852614…] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) CMatrixutils::MatrixToVector Failed to turn the matrix to a vector rows 0 cols 0
El tensor del segundo grupo está vacío, es decir, el algoritmo no lo ha pronosticado en absoluto, mientras que todos los datos se han pronosticado como pertenecientes al grupo 0.
Normalice siempre las variables
Ya hemos mencionado esto un par de veces antes y lo repetimos: la normalización de los datos de entrada es esencial para todos los modelos de aprendizaje automático con los que trabajemos. Y nuevamente vemos lo importante que es esta normalización. Echemos un vistazo al resultado después de normalizar los datos.
Para la normalización, hemos usado la técnica Min-Max scaler
#include <MALE5\Neural Networks\kohonen maps.mqh> #include <MALE5\preprocessing.mqh> #include <MALE5\matrix_utils.mqh> CPreprocessing *pre_processing; CMatrixutils matrix_utils; CKohonenMaps *maps; input int bars = 100; int handles[5]; int period[5] = {10,20,30,50,100}; matrix Matrix(bars,5); //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- vector v; for (int i=0; i<5; i++) { handles[i] = iMA(Symbol(),PERIOD_CURRENT,period[i],0,MODE_LWMA,PRICE_CLOSE); matrix_utils.CopyBufferVector(handles[i],0,0,bars, v); Matrix.Col(v, i); } pre_processing = new CPreprocessing(Matrix, NORM_MIN_MAX_SCALER); maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //--- return(INIT_SUCCEEDED); }
Esta vez, en el gráfico han aparecido hermosos mapas de Kohonen.
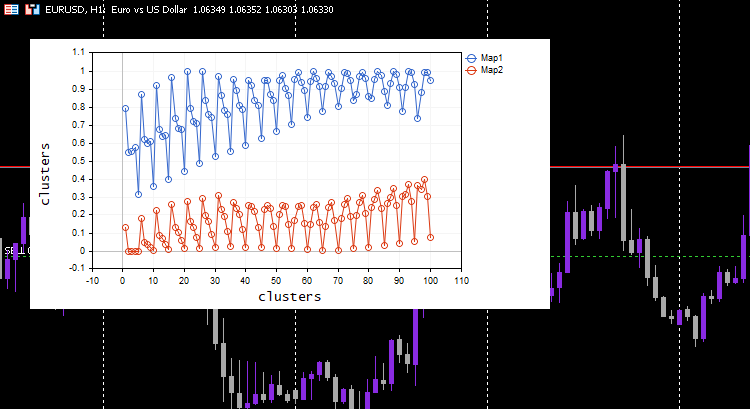
Sin embargo, la normalización de datos convierte los datos a valores más pequeños. Para aquellos que simplemente deseen agrupar sus datos para comprender patrones y utilizar los datos extraídos en otros programas, el proceso de normalización deberá integrarse en el núcleo del algoritmo. Los datos deberán normalizarse y desnormalizarse para que los clústeres resultantes tengan sus valores originales, porque los métodos de clusterización no cambian los datos, sino que solo los agrupan. Para la normalización y desnormalización, podemos usar esta clase de preprocesamiento.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100, norm_technique NORM_TECHNIQUE=NORM_MIN_MAX_SCALER) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; pre_processing = new CPreprocessing(Matrix, NORM_TECHNIQUE); cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); #ifdef DEBUG_MODE Print("w Matrix\n",w_matrix,"\nMatrix\n",Matrix); #endif vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); if (epoch == epochs-1) //last iteration cluster_tensor.TensorAppend(Matrix.Row(i), min); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of the training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif //--- matrix mat= {}; vector v; matrix plotmatrix(rows, m); for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); v = this.matrix_utils.MatrixToVector(mat); plotmatrix.Col(v, i); } this.plt.ScatterCurvePlotsMatrix("kom",plotmatrix,"Map","clusters","clusters"); //--- if (save_clusters) for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); pre_processing.ReverseNormalization(mat); cluster_tensor.TensorAdd(mat, i); string header[]; ArrayResize(header, (int)mat.Cols()); for (int k=0; k<ArraySize(header); k++) header[k] = "col"+string(k); if (this.matrix_utils.WriteCsv("SOM\\Cluster"+string(i+1)+".csv",mat,header)) Print("Clusters CSV files saved under the directory Files\\SOM"); } //--- Print("\nclusters"); cluster_tensor.TensorPrint(); }
Para mostrar cómo funciona esto, deberemos volver al conjunto de datos simple que teníamos al principio.
matrix Matrix = { {1.2, 2.3}, {0.7, 1.8}, {3.6, 4.8}, {2.8, 3.9}, {5.2, 6.7}, {4.8, 5.6} }; maps = new CKohonenMaps(Matrix,true,2,0.01,1000);
Resultados
CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) w Matrix CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [[0.005340739158299509,0.01220740379039888] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.5453352458265939,0.9172643208105716]] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Matrix CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [[0.1111111111111111,0.1020408163265306] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0,0] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.6444444444444445,0.6122448979591836] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.4666666666666666,0.4285714285714285] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [1,1] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.911111111111111,0.7755102040816325]] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [1/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [2/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [3/1000] | 0.000 Seconds Elapsed ... ... ... CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) Epoch [999/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) Epoch [1000/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) New weights CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) [[0.1937869656464888,0.8527427060068337] CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) [0.1779676215121214,0.7964618795904062]] CS 0 07:14:44.725 Self Organizing map (EURUSD,H1) Clusters CSV files saved under the directory Files\SOM CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) Clusters CSV files saved under the directory Files\SOM CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) clusters CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [0.7,1.8] CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [2.8,3.899999999999999]] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [[3.600000000000001,4.8] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [4.8,5.6]]
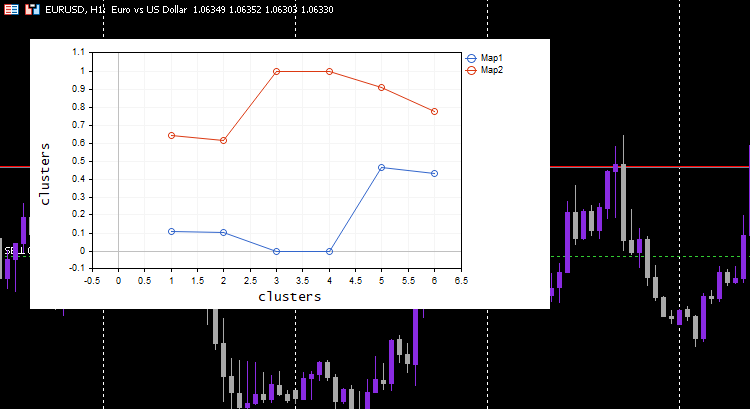
Funciona como por arte de magia. Aunque el modelo de aprendizaje automático usa datos normalizados, el modelo podrá clusterizar los datos y aún podrá producir datos no normalizados/originales. Tenga en cuenta que los clústeres representados eran datos normalizados. Esto es importante porque resulta difícil representar datos a diferentes escalas. Esta vez, el gráfico de clústeres con el conjunto de datos de prueba simple ha resultado mucho mejor:
Expansión del mapa de Kohonen
Aunque el propósito original de los mapas de Kohonen y otros métodos de análisis de datos no es el de realizar pronósticos, dado que tienen parámetros entrenados, es decir, pesos, podemos expandirlos y obtener clústeres de datos nuevos.
uint CKohonenMaps::KOMPredCluster(vector &v) { vector temp_v = v; pre_processing.Normalization(v); if (n != v.Size()) { Print("Can't predict the cluster | the input vector size is not the same as the trained matrix cols"); return(-1); } vector D(m); //Euclidean distance btn clusters for (ulong j=0; j<m; j++) D[j] = Euclidean_distance(v, w_matrix.Col(j)); v.Copy(temp_v); return((uint)D.ArgMin()); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CKohonenMaps::KOMPredCluster(matrix &matrix_) { vector v(n); if (n != matrix_.Cols()) { Print("Can't predict the cluster | the input matrix Cols is not the same size as the trained matrix cols"); return (v); } for (ulong i=0; i<matrix_.Rows(); i++) v[i] = KOMPredCluster(matrix_.Row(i)); return(v); }
Enviemos los nuevos datos a la entrada. Usted y yo sabemos qué clúster tienen [0.5, 1.5] y [5.5, 6]. Estos datos se refieren a los clústeres 0 y 1, respectivamente.
maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //Training matrix new_data = { {0.5,1.5}, {5.5, 6.0} }; Print("new data\n",new_data,"\nprediction clusters\n",maps.KOMPredCluster(new_data)); //using it for predictions
Resultados
CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) new data CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [[0.5,1.5] CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [5.5,6]] CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) prediction clusters CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [0,1]
¡Los mapas de Kohonen los han pronosticado correctamente!
Mapas de Kohonen en el simulador de estrategias

El algoritmo funciona muy bien. Entonces, hemos notado que predice el clúster 0 cuando el mercado está subiendo y viceversa con 1. No estoy seguro de si la conclusión es correcta, es posible que no haya analizado el comportamiento con suficiente profundidad, así que dejo esto a su discreción. De ser así, incluso podemos usar los mapas de Kohonen como indicador.
Ventajas de los mapas de Kohonen
Los mapas Kohonen tienen una serie de ventajas:
- Pueden captar relaciones no lineales entre los datos de entrada y el mapa de salida, lo cual significa que pueden manejar estructuras de datos y patrones complejos.
- Pueden encontrar patrones en datos no etiquetados. Es decir, se pueden usar cuando los datos marcados no son suficientes o es difícil obtenerlos.
- Al reducir la dimensionalidad de los datos de entrada, se reduce la complejidad computacional de las tareas posteriores, como la regresión y la clasificación.
- Se conserva la relación topológica entre los datos de entrada y el mapa de salida: las neuronas cercanas en el mapa se corresponden con áreas similares en el espacio de entrada, lo cual puede ayudar en la exploración y visualización de datos.
- Son resistentes al ruido y a los valores atípicos en los datos de entrada si el ruido es demasiado alto.
Desventajas de los mapas de Kohonen
- La calidad depende en gran medida de la inicialización del vector de pesos. Si la inicialización es mala, podemos terminar con una solución subóptima o quedarnos atrapados en un mínimo local.
- La calidad de los mapas también depende de la elección de los hiperparámetros (tasa de aprendizaje, número de neuronas, etc.) Configurar estos ajustes puede demandar mucho tiempo y requerir trabajo adicional.
- Necesita grandes recursos informáticos y memoria al trabajar con grandes conjuntos de datos. El tamaño de los mapas depende del número de puntos de los datos de entrada, y cuantos más datos, mayor será la cantidad de neuronas y más largo será el entrenamiento.
- Cuando se trata de redes neuronales, no existen criterios formales de convergencia para los mapas de autoaprendizaje, por lo que puede resultar difícil saber cuándo detener el entrenamiento.
Conclusión
Los mapas de Kohonen o mapas autoorganizados son un enfoque innovador para el comercio que puede ayudar a los tráders a orientarse en los mercados. Usando el aprendizaje no supervisado, los mapas de Kohonen pueden revelar patrones y estructuras en los datos del mercado, lo cual permite a los tráders tomar decisiones informadas. Como hemos visto en este artículo, los mapas de Kohonen pueden revelar relaciones no lineales en los datos y unir estos en grupos apropiados. Sin embargo, al trabajar con ellos, deberemos ser conscientes de sus posibles inconvenientes, como la sensibilidad a la inicialización, la falta de criterios formales de convergencia, etc. En general, los mapas de Kohonen pueden ser una valiosa adición al kit de herramientas de los tráders, pero como cualquier herramienta, deben usarse con cuidado y atención.
Buena suerte.
Sigue el desarrollo del tema en mi repositorio de GitHub https://github.com/MegaJoctan/MALE5.
| Archivo | Contenido y uso |
|---|---|
| Self Organizing map.mq5 | Archivo de asesor para probar el algoritmo discutido en este artículo |
| kohonen maps.mqh | Biblioteca que contiene el algoritmo del mapa de Kohonen |
| plots.mqh | Biblioteca que contiene las funciones necesarias para dibujar gráficos en un gráfico en MT5 |
| preprocessing.mqh | Funciones para normalizar y preprocesar datos de entrada |
| matrix_utils.mqh | Contiene funciones adicionales para realizar operaciones matriciales en MQL5 |
| Tensors.mqh | Biblioteca que contiene las clases necesarias para crear tensores. |
Artículos relacionados:
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/12261
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso