
Algoritmos de optimización de la población: Algoritmo del mono (Monkey algorithm, MA)

Contenido:
1. Introducción
2. Descripción del algoritmo
3. Resultados de las pruebas
1. Introducción
El Algoritmo del Mono (MA) supone un algoritmo de búsqueda metaheurístico. En este artículo, describiremos los componentes básicos del algoritmo, presentando soluciones para el proceso de ascenso (movimiento ascendente), el proceso de salto local y el proceso de salto global. Este algoritmo fue desarrollado por R. Zhao y W. Tang en 2007. El algoritmo simula el comportamiento de los monos al desplazarse y saltar por las montañas en busca de comida. Se supone que los monos asumen que cuanto más alta sea la montaña, más comida habrá en la cima.
El terreno explorado por los monos representa el paisaje de la función de aptitud, por lo que la solución del problema se corresponderá con la montaña más alta (consideramos el problema de maximización global). Desde su posición actual, cada uno de los monos irá ascendiendo hasta alcanzar la cima de la montaña. El proceso de escalada está diseñado para mejorar paulatinamente el valor de la función objetivo. A continuación, el mono realizará una serie de saltos locales en una dirección aleatoria con la esperanza de hallar una montaña más alta, y se repetirá el movimiento ascendente. Tras realizar un cierto número de subidas y saltos locales, el mono creerá haber explorado suficientemente el paisaje en las proximidades de su posición inicial.
Para explorar una nueva zona del espacio de búsqueda, el mono realizará un largo salto global. Las acciones anteriores se repetirán un número determinado de veces en los parámetros del algoritmo. Se declarará que la solución al problema será el pico más alto encontrado por la población de monos dada. Sin embargo, la IA invertirá un tiempo computacional considerable en buscar soluciones óptimas locales mientras se va adquiriendo altitud. El proceso de salto global puede acelerar la tasa de convergencia del algoritmo; el propósito de este proceso consistirá en forzar a los monos a encontrar nuevas oportunidades de búsqueda para evitar quedar atrapados en una búsqueda local. El algoritmo presenta ventajas como una estructura sencilla, una fiabilidad relativamente alta y una buena búsqueda de las soluciones óptimas locales.
El MA es un nuevo tipo de algoritmo evolutivo que puede resolver muchos problemas de optimización complejos caracterizados por la no linealidad, la no diferenciabilidad y la alta dimensionalidad. La diferencia con otros algoritmos es que el tiempo empleado por el MA se dedica principalmente a usar el proceso de toma de altitud para encontrar soluciones óptimas locales. En la siguiente sección, describiremos los principales componentes del algoritmo, las soluciones presentadas, la inicialización, el proceso de toma de altitud, el proceso de observación y el salto.
2. Descripción del algoritmo
Para entender fácilmente el algoritmo del mono, lo más fácil es comenzar por el pseudocódigo.
Pseudocódigo del algoritmo MA:
1. Distribuimos los monos aleatoriamente por el espacio de búsqueda.
2. Medimos la altitud de la posición del mono.
3. Realizamos saltos locales un número fijo de veces.
4. Si el nuevo tope es más alto que el obtenido en el paso 3, entonces realizamos saltos locales desde esta ubicación.
5. Si se agota el límite de saltos locales y no se encontramos un nuevo tope, realizamos un salto global.
6. Después del punto 5, repetimos el punto 3
7. Repetimos desde el paso 2 hasta que se cumpla el criterio de parada.
Bien, vamos a desglosar cada punto del pseudocódigo con más detalle.
1. Al principio de la optimización, el espacio de búsqueda resulta desconocido para los monos. Los animales se sitúan aleatoriamente en terrenos desconocidos, ya que la posición de la comida tiene las mismas probabilidades de encontrarse en cualquier parte.
2. El proceso de medición de la altitud de los monos es una tarea de función de aptitud.
3. Al realizar saltos locales, existe un límite en el número de saltos indicado en los parámetros del algoritmo. Esto significa que el mono intentará mejorar su posición actual dando pequeños saltos locales en la zona donde encuentre comida. Si la nueva fuente de alimento encontrada es mejor, pasaremos al paso 4.
4. Se ha localizado una nueva fuente de alimento, por lo que el contador local de saltos se reinicia. La búsqueda de una nueva fuente de alimento se realizará ahora desde este lugar.
5. Los saltos locales pueden impedir que el mono descubra mejor una nueva fuente de alimento; el mono llega a la conclusión de que la zona actual del espacio ha sido totalmente explorada y de que ha llegado el momento de buscar una nueva ubicación, pero más alejada. Llegados a este punto, surge la cuestión de qué camino tomar a continuación. La idea que subyace al algoritmo es usar el centro de las coordenadas de todos los monos, posibilitando algún tipo de comunicación. Los monos de la manada se comunicarán entre sí gritando fuerte y, como poseen un buen oído tridimensional, serán capaces de determinar la posición exacta de sus congéneres. Al mismo tiempo, conociendo la posición de sus congéneres (los congéneres no estarán en zonas donde no haya comida), podrá calcular aproximadamente la posición óptima de la nueva fuente de alimento, de ahí la necesidad de saltar en esa dirección.
En el algoritmo original de los autores, el mono realiza un salto global por una línea que pasa por el centro de las coordenadas de todos los monos y la posición actual del animal. La dirección del salto puede ser hacia el centro de las coordenadas o bien en dirección opuesta al centro. Como han confirmado mis experimentos con el algoritmo, saltar en dirección opuesta al centro derrota la propia lógica de localización de alimento con las coordenadas aproximadas de todos los monos: de hecho, existe un 50% de probabilidades de alejarse del óptimo global.
La práctica ha demostrado que resulta más rentable saltar sobre el centro de las coordenadas que no saltar o hacerlo en sentido contrario. La concentración de todos los monos en un solo punto no tiene lugar, aunque, a primera vista, dicha lógica debería conducir a ello. En la práctica, los monos, una vez agotado su límite de saltos locales, saltarán más allá del centro, sucediendo con ello la rotación de la posición de todos los monos de la población. Si imaginamos un antropoide cumpliendo este algoritmo, veremos una manada de animales saltando a través del centro geométrico de la misma de vez en cuando, con la propia manada moviéndose en grupos hacia una fuente de alimento más rica: este efecto de "movimiento de manada" resulta claramente visible en la animación del algoritmo (el algoritmo original no tiene tal efecto y muestra peores resultados).
6. Una vez realizado el salto global, el mono comenzará a precisar la posición de la fuente de alimento en la nueva ubicación. El proceso continuará hasta que se cumpla el criterio de parada.
La idea completa del algoritmo puede caber fácilmente en el esquema de una sola figura. El movimiento del mono se indica usando los círculos con números de la figura 1. Cada dígito representa una nueva posición del mono. Los círculos amarillos pequeños muestran los intentos fallidos de los saltos locales. El número 6 indica una posición en la que se ha agotado el límite de salto local y no se ha localizado una nueva posición mejor. Los círculos sin números simbolizan la ubicación de los otros miembros de la manada. El centro geométrico de las coordenadas de la manada se indica con la ayuda de un pequeño círculo con las coordenadas (x,y).

Figura 1. Representación esquemática de los movimientos del mono en manada.
Vamos a examinar el código del MA.
Podemos describir cómodamente un mono en una manada usando la estructura S_Monkey. La estructura contiene el array c [] con las coordenadas actuales, el array cB [] con las coordenadas del mejor alimento (partiendo precisamente de la posición con estas coordenadas se producen los saltos locales), h y hB, el valor de la altitud del punto actual y el valor del punto más alto respectivamente. lCNT es un contador de saltos locales, que limita el número de intentos de mejorar la posición.
//—————————————————————————————————————————————————————————————————————————————— struct S_Monkey { double c []; //coordinates double cB []; //best coordinates double h; //height of the mountain double hB; //best height of the mountain int lCNT; //local search counter }; //——————————————————————————————————————————————————————————————————————————————
La clase del algoritmo del mono C_AO_MA no se distingue de los algoritmos discutidos anteriormente. Una manada de monos se representa en la clase como un array de estructuras m []. Las declaraciones en la clase de métodos y miembros son pequeñas en cuanto al tamaño de código, porque el algoritmo es conciso, no existe clasificación como en muchos otros algoritmos de optimización. Necesitaremos arrays para especificar el máximo, el mínimo y el paso de los parámetros a optimizar, así como las variables constantes para transmitir los parámetros externos del algoritmo. Vamos a describir los métodos en los que se encapsula la lógica básica del MA.
//—————————————————————————————————————————————————————————————————————————————— class C_AO_MA { //---------------------------------------------------------------------------- public: S_Monkey m []; //monkeys public: double rangeMax []; //maximum search range public: double rangeMin []; //minimum search range public: double rangeStep []; //step search public: double cB []; //best coordinates public: double hB; //best height of the mountain public: void Init (const int coordNumberP, //coordinates number const int monkeysNumberP, //monkeys number const double bCoefficientP, //local search coefficient const double vCoefficientP, //jump coefficient const int jumpsNumberP); //jumps number public: void Moving (); public: void Revision (); //---------------------------------------------------------------------------- private: int coordNumber; //coordinates number private: int monkeysNumber; //monkeys number private: double b []; //local search coefficient private: double v []; //jump coefficient private: double bCoefficient; //local search coefficient private: double vCoefficient; //jump coefficient private: double jumpsNumber; //jumps number private: double cc []; //coordinate center private: bool revision; private: double SeInDiSp (double In, double InMin, double InMax, double Step); private: double RNDfromCI (double min, double max); private: double Scale (double In, double InMIN, double InMAX, double OutMIN, double OutMAX, bool revers); }; //——————————————————————————————————————————————————————————————————————————————
El método abierto Init () sirve para inicializar el algoritmo. Aquí estableceremos el tamaño de los arrays. El índice de calidad de la mejor zona de monos encontrada se inicializará con el menor número double posible, y lo mismo se hará con las variables correspondientes del array de la estructura MA.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_MA::Init (const int coordNumberP, //coordinates number const int monkeysNumberP, //monkeys number const double bCoefficientP, //local search coefficient const double vCoefficientP, //jump coefficient const int jumpsNumberP) //jumps number { MathSrand ((int)GetMicrosecondCount ()); // reset of the generator hB = -DBL_MAX; revision = false; coordNumber = coordNumberP; monkeysNumber = monkeysNumberP; bCoefficient = bCoefficientP; vCoefficient = vCoefficientP; jumpsNumber = jumpsNumberP; ArrayResize (rangeMax, coordNumber); ArrayResize (rangeMin, coordNumber); ArrayResize (rangeStep, coordNumber); ArrayResize (b, coordNumber); ArrayResize (v, coordNumber); ArrayResize (cc, coordNumber); ArrayResize (m, monkeysNumber); for (int i = 0; i < monkeysNumber; i++) { ArrayResize (m [i].c, coordNumber); ArrayResize (m [i].cB, coordNumber); m [i].h = -DBL_MAX; m [i].hB = -DBL_MAX; m [i].lCNT = 0; } ArrayResize (cB, coordNumber); } //——————————————————————————————————————————————————————————————————————————————
El primer método que es obligatorio ejecutar en cada iteración es el método abierto Moving (), que implementa la lógica de salto de los monos. En la primera iteración, cuando la bandera revision es false, hay que inicializar los agentes con valores aleatorios en el rango de coordenadas del espacio de estudio, lo cual equivale a ubicar aleatoriamente a los monos en el hábitat de la manada. Para reducir las operaciones repetitivas, como el cálculo de los coeficientes de los saltos globales y locales, guardaremos los valores de las coordenadas correspondientes (cada coordenada puede tener una dimensionalidad diferente) en los arrays v [] y b []. Asimismo, pondremos a cero el contador local de saltos de cada mono.
//---------------------------------------------------------------------------- if (!revision) { hB = -DBL_MAX; for (int monk = 0; monk < monkeysNumber; monk++) { for (int c = 0; c < coordNumber; c++) { m [monk].c [c] = RNDfromCI (rangeMin [c], rangeMax [c]); m [monk].c [c] = SeInDiSp (m [monk].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); m [monk].h = -DBL_MAX; m [monk].hB = -DBL_MAX; m [monk].lCNT = 0; } } for (int c = 0; c < coordNumber; c++) { v [c] = (rangeMax [c] - rangeMin [c]) * vCoefficient; b [c] = (rangeMax [c] - rangeMin [c]) * bCoefficient; } revision = true; }
Para calcular el centro de las coordenadas de todos los monos, utilizaremos el array cc [], cuya dimensionalidad se corresponde con el número de coordenadas. El cálculo consistirá en sumar las coordenadas de los monos y dividir la suma resultante por el tamaño de la población. El centro de coordenadas será, por lo tanto, la media aritmética de las coordenadas.
//calculate the coordinate center of the monkeys---------------------------- for (int c = 0; c < coordNumber; c++) { cc [c] = 0.0; for (int monk = 0; monk < monkeysNumber; monk++) { cc [c] += m [monk].cB [c]; } cc [c] /= monkeysNumber; }
Según el pseudocódigo, si no se ha agotado el límite de salto local, el mono saltará desde su ubicación en todas las direcciones por igual. El radio del círculo de los saltos locales se regirá por el factor de salto local, que se recalculará según la dimensionalidad del array de coordenadas b [].
//local jump-------------------------------------------------------------- if (m [monk].lCNT < jumpsNumber) //local jump { for (int c = 0; c < coordNumber; c++) { m [monk].c [c] = RNDfromCI (m [monk].cB [c] - b [c], m [monk].cB [c] + b [c]); m [monk].c [c] = SeInDiSp (m [monk].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } }
Vamos a pasar a una parte muy importante de la lógica del MA: el rendimiento del algoritmo dependerá en mayor medida de la implementación de los saltos globales; diferentes autores han abordado esta cuestión desde ángulos distintos, ofreciendo todo tipo de soluciones. Los saltos locales, según los estudios, tienen poco efecto en la convergencia del algoritmo; precisamente los saltos globales determinan la capacidad del algoritmo para "saltar" fuera de los extremos locales. Mis experimentos con saltos globales solo han revelado un enfoque viable que mejore los resultados para este algoritmo en particular.
Antes hemos hablado de la conveniencia de saltar hacia el centro de las coordenadas, resultando mejor además si el punto final se encuentra tras el centro, y no entre el centro y las coordenadas actuales. Este enfoque consiste en aplicar la fórmula del vuelo de Levy, que describimos detalladamente en el artículo sobre el algoritmo de optimización de cuco (COA).

Figura 2. Gráficos de la función de vuelo de Levy según el grado en la fórmula.
La coordenada del mono se calculará usando la siguiente fórmula:
m [monk].c [c] = cc [c] + v [c] * pow (r2, -2.0);
donde:
cc [c] — coordenada del centro de las coordenadas,
v [c] — coeficiente del radio de salto convertido a la dimensionalidad del espacio de búsqueda,
r2 — número comprendido entre 1 y 20.
Aplicando el vuelo Levy a esta operación, conseguiremos una mayor probabilidad de que el salto del mono termine en las proximidades del centro de las coordenadas y una menor probabilidad de que se encuentre lejos del centro. De esta forma, lograremos un equilibrio entre la exploración y la explotación de la búsqueda, detectando nuevas fuentes de alimento. Si la coordenada se encuentra fuera del límite inferior del rango válido, la coordenada se desplazará en la distancia correspondiente al límite superior del rango, y lo mismo ocurrirá si está fuera del límite superior. Tras finalizar los cálculos de coordenadas, comprobaremos si el valor resultante se corresponde con los límites y los pasos de la investigación.
//global jump------------------------------------------------------------- for (int c = 0; c < coordNumber; c++) { r1 = RNDfromCI (0.0, 1.0); r1 = r1 > 0.5 ? 1.0 : -1.0; r2 = RNDfromCI (1.0, 20.0); m [monk].c [c] = cc [c] + v [c] * pow (r2, -2.0); if (m [monk].c [c] < rangeMin [c]) m [monk].c [c] = rangeMax [c] - (rangeMin [c] - m [monk].c [c]); if (m [monk].c [c] > rangeMax [c]) m [monk].c [c] = rangeMin [c] + (m [monk].c [c] - rangeMax [c]); m [monk].c [c] = SeInDiSp (m [monk].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); }
Después de los saltos locales/globales, aumentaremos el contador de saltos en uno.
m [monk].lCNT++;
El segundo método público se llama en cada iteración tras calcularse la función de aptitud Revision(). Este método actualizará la solución global si se encuentra una mejor. La lógica para procesar los resultados tras los saltos locales y globales es diferente: con los saltos locales, resulta necesario comprobar si la posición actual ha mejorado y actualizarla (las siguientes iteraciones se realizarán desde esta nueva ubicación), mientras que con los saltos globales no existe comprobación alguna de las mejoras, los nuevos saltos se realizarán desde esta ubicación en cualquier caso.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_MA::Revision () { for (int monk = 0; monk < monkeysNumber; monk++) { if (m [monk].h > hB) { hB = m [monk].h; ArrayCopy (cB, m [monk].c, 0, 0, WHOLE_ARRAY); } if (m [monk].lCNT <= jumpsNumber) //local jump { if (m [monk].h > m [monk].hB) { m [monk].hB = m [monk].h; ArrayCopy (m [monk].cB, m [monk].c, 0, 0, WHOLE_ARRAY); m [monk].lCNT = 0; } } else //global jump { m [monk].hB = m [monk].h; ArrayCopy (m [monk].cB, m [monk].c, 0, 0, WHOLE_ARRAY); m [monk].lCNT = 0; } } } //——————————————————————————————————————————————————————————————————————————————
Al final de la descripción del código, podemos observar similitudes en los planteamientos de este algoritmo con un grupo de algoritmos de inteligencia de enjambre, como el enjambre de partículas (PSO) y otros, con una lógica de estrategia de búsqueda similar.
3. Resultados de las pruebas
Impresión del rendimiento del algoritmo del mono en el banco de pruebas:
2023.02.22 19:36:21.841 Test_AO_MA (EURUSD,M1) C_AO_MA:50;0.01;0.9;50
2023.02.22 19:36:21.841 Test_AO_MA (EURUSD,M1) =============================
2023.02.22 19:36:26.877 Test_AO_MA (EURUSD,M1) 5 Rastrigin's; Func runs 10000 result: 64.89788419898215
2023.02.22 19:36:26.878 Test_AO_MA (EURUSD,M1) Score: 0.80412
2023.02.22 19:36:36.734 Test_AO_MA (EURUSD,M1) 25 Rastrigin's; Func runs 10000 result: 55.57339368461394
2023.02.22 19:36:36.734 Test_AO_MA (EURUSD,M1) Score: 0.68859
2023.02.22 19:37:34.865 Test_AO_MA (EURUSD,M1) 500 Rastrigin's; Func runs 10000 result: 41.41612351844293
2023.02.22 19:37:34.865 Test_AO_MA (EURUSD,M1) Score: 0.51317
2023.02.22 19:37:34.865 Test_AO_MA (EURUSD,M1) =============================
2023.02.22 19:37:39.165 Test_AO_MA (EURUSD,M1) 5 Forest's; Func runs 10000 result: 0.4307085210424681
2023.02.22 19:37:39.165 Test_AO_MA (EURUSD,M1) Score: 0.24363
2023.02.22 19:37:49.599 Test_AO_MA (EURUSD,M1) 25 Forest's; Func runs 10000 result: 0.19875891413613866
2023.02.22 19:37:49.599 Test_AO_MA (EURUSD,M1) Score: 0.11243
2023.02.22 19:38:47.793 Test_AO_MA (EURUSD,M1) 500 Forest's; Func runs 10000 result: 0.06286212143582881
2023.02.22 19:38:47.793 Test_AO_MA (EURUSD,M1) Score: 0.03556
2023.02.22 19:38:47.793 Test_AO_MA (EURUSD,M1) =============================
2023.02.22 19:38:53.947 Test_AO_MA (EURUSD,M1) 5 Megacity's; Func runs 10000 result: 2.8
2023.02.22 19:38:53.947 Test_AO_MA (EURUSD,M1) Score: 0.23333
2023.02.22 19:39:03.336 Test_AO_MA (EURUSD,M1) 25 Megacity's; Func runs 10000 result: 0.96
2023.02.22 19:39:03.336 Test_AO_MA (EURUSD,M1) Score: 0.08000
2023.02.22 19:40:02.068 Test_AO_MA (EURUSD,M1) 500 Megacity's; Func runs 10000 result: 0.34120000000000006
2023.02.22 19:40:02.068 Test_AO_MA (EURUSD,M1) Score: 0.02843
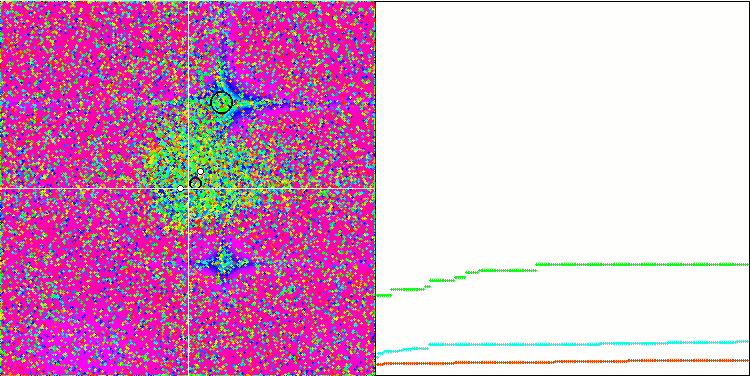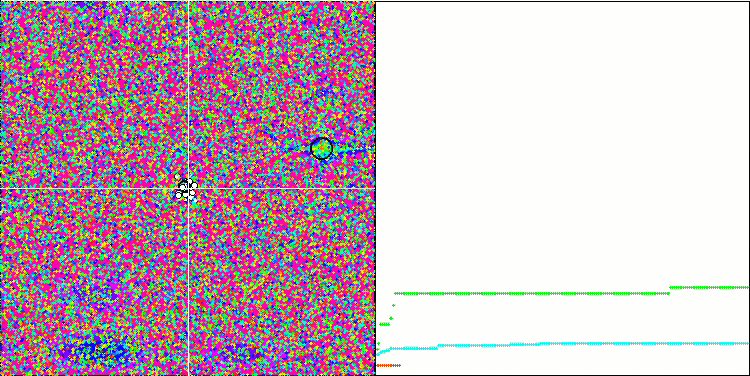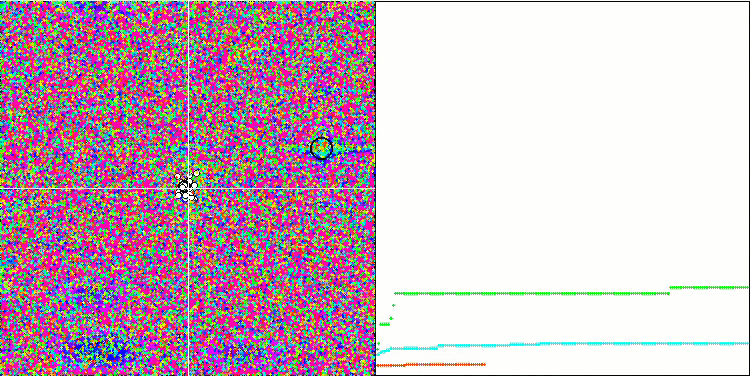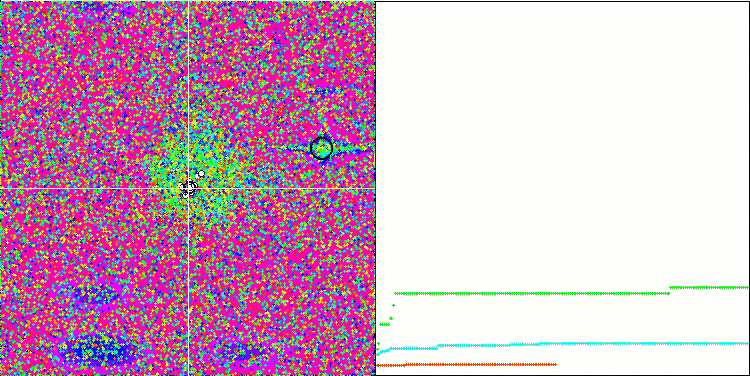
Prestando atención a la visualización del algoritmo sobre las funciones de prueba, podemos destacar que no existen patrones en el comportamiento; es muy similar al algoritmo RND. Existe una ligera concentración de agentes en los extremos locales, lo cual indica que el algoritmo está intentando precisar la solución, pero no se aprecian atascos evidentes.

MA en la función de prueba Rastrigin.

MA en la función de prueba Forest.
MA en la función de prueba Megacity.
Vamos a analizar los resultados de las pruebas. El algoritmo de MA se sitúa al final de la tabla, entre GSA y FSS. Querríamos señalar una cosa: como las pruebas de los algoritmos se basan en un principio del análisis comparativo en el que las puntuaciones son valores relativos entre la mejor y la peor, la aparición de un algoritmo con resultados sobresalientes en una prueba cualquiera y fallidos en otras, a veces provocará cambios en el rendimiento de los demás participantes en la prueba.
Pero los resultados de la IA han sido tales que no han provocado el recálculo de las puntuaciones de ninguno de los demás integrantes de la tabla. La IA no tiene un solo resultado en las pruebas que resulte el peor, aunque haya algoritmos con cero resultados relativos en la tabla, pero que tienen una calificación más alta (ejemplo: el GSA). Por lo tanto, podemos sacar algunas conclusiones: aunque el algoritmo se comporta de forma bastante modesta y la capacidad de búsqueda no es tan buena como nos gustaría, sí que muestra resultados estables, lo cual es una cualidad positiva para los algoritmos de optimización.
| AO | Description | Rastrigin | Rastrigin final | Forest | Forest final | Megacity (discrete) | Megacity final | Final result | ||||||
| 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | ||||||
| HS | harmony search | 1,00000 | 1,00000 | 0,57048 | 2,57048 | 1,00000 | 0,98931 | 0,57917 | 2,56848 | 1,00000 | 1,00000 | 1,00000 | 3,00000 | 100,000 |
| ACOm | ant colony optimization M | 0,34724 | 0,18876 | 0,20182 | 0,73782 | 0,85966 | 1,00000 | 1,00000 | 2,85966 | 1,00000 | 0,88484 | 0,13497 | 2,01981 | 68,094 |
| IWO | invasive weed optimization | 0,96140 | 0,70405 | 0,35295 | 2,01840 | 0,68718 | 0,46349 | 0,41071 | 1,56138 | 0,75912 | 0,39732 | 0,80145 | 1,95789 | 67,087 |
| COAm | cuckoo optimization algorithm M | 0,92701 | 0,49111 | 0,30792 | 1,72604 | 0,55451 | 0,34034 | 0,21362 | 1,10847 | 0,67153 | 0,30326 | 0,41127 | 1,38606 | 50,422 |
| FAm | firefly algorithm M | 0,60020 | 0,35662 | 0,20290 | 1,15972 | 0,47632 | 0,42299 | 0,64360 | 1,54291 | 0,21167 | 0,25143 | 0,84884 | 1,31194 | 47,816 |
| BA | bat algorithm | 0,40658 | 0,66918 | 1,00000 | 2,07576 | 0,15275 | 0,17477 | 0,33595 | 0,66347 | 0,15329 | 0,06334 | 0,41821 | 0,63484 | 39,711 |
| ABC | artificial bee colony | 0,78424 | 0,34335 | 0,24656 | 1,37415 | 0,50591 | 0,21455 | 0,17249 | 0,89295 | 0,47444 | 0,23609 | 0,33526 | 1,04579 | 38,937 |
| BFO | bacterial foraging optimization | 0,67422 | 0,32496 | 0,13988 | 1,13906 | 0,35462 | 0,26623 | 0,26695 | 0,88780 | 0,42336 | 0,30519 | 0,45578 | 1,18433 | 37,651 |
| GSA | gravitational search algorithm | 0,70396 | 0,47456 | 0,00000 | 1,17852 | 0,26854 | 0,36416 | 0,42921 | 1,06191 | 0,51095 | 0,32436 | 0,00000 | 0,83531 | 35,937 |
| MA | monkey algorithm | 0,33300 | 0,35107 | 0,17340 | 0,85747 | 0,03684 | 0,07891 | 0,11546 | 0,23121 | 0,05838 | 0,00383 | 0,25809 | 0,32030 | 14,848 |
| FSS | fish school search | 0,46965 | 0,26591 | 0,13383 | 0,86939 | 0,06711 | 0,05013 | 0,08423 | 0,20147 | 0,00000 | 0,00959 | 0,19942 | 0,20901 | 13,215 |
| PSO | particle swarm optimisation | 0,20515 | 0,08606 | 0,08448 | 0,37569 | 0,13192 | 0,10486 | 0,28099 | 0,51777 | 0,08028 | 0,21100 | 0,04711 | 0,33839 | 10,208 |
| RND | random | 0,16881 | 0,10226 | 0,09495 | 0,36602 | 0,07413 | 0,04810 | 0,06094 | 0,18317 | 0,00000 | 0,00000 | 0,11850 | 0,11850 | 5,469 |
| GWO | grey wolf optimizer | 0,00000 | 0,00000 | 0,02672 | 0,02672 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,18977 | 0,03645 | 0,06156 | 0,28778 | 1,000 |
Conclusiones
El algoritmo clásico de IA consiste básicamente en usar el proceso de marcación de la altitud para encontrar soluciones óptimas locales. El paso del conjunto de altitud desempeña un papel decisivo en la precisión de la aproximación de la solución local. Cuanto menor sea el paso de altitud para los saltos locales, mayor será la precisión de la solución, pero se necesitarán más iteraciones para encontrar el óptimo global. Para acortar el tiempo de cálculo usando la reducción del número de iteraciones, muchos investigadores recomiendan usar otros métodos de optimización como ABC, COA, IWO en las etapas iniciales de la optimización, y luego utilizar MA para precisar la solución global. No estoy de acuerdo con este enfoque: sería más apropiado utilizar directamente los algoritmos mencionados en lugar de MA, aunque el potencial de desarrollo de MA está presente y supone en sí una razón para seguir experimentando y estudiando.
El algoritmo del mono es un algoritmo de población que hunde sus raíces en la naturaleza. Al igual que muchos otros algoritmos metaheurísticos, este algoritmo pertenece a los algoritmos evolutivos y es capaz de resolver una serie de problemas de optimización, incluyendo la no linealidad, la no diferenciabilidad y el espacio de búsqueda de alta dimensión con alta tasa de convergencia. Otra ventaja del algoritmo del mono es que se rige por un número reducido de parámetros, lo cual facilita bastante su aplicación. A pesar de la estabilidad de los resultados, la baja tasa de convergencia no permite recomendar el algoritmo del mono para problemas de alta complejidad computacional, pues requiere un número significativo de iteraciones: hay muchos otros algoritmos que hacen el mismo trabajo en menos tiempo (número de iteraciones).
Me gustaría añadir en conclusión que, a pesar de nuestros numerosos experimentos, la versión clásica del algoritmo no pudo superar la tercera línea inferior de la tabla de valoración: se atascaba en extremos locales, funcionaba extremadamente mal en funciones discretas, resumiendo, no tenía muchas ganas de escribir sobre ella, así que realizamos varios intentos de mejorar el algoritmo. Uno de estos intentos logró cierta mejora en la convergencia y aumentó la estabilidad de los resultados utilizando desplazamientos de probabilidad en los saltos globales y también revisando el principio de los mayores saltos globales. Muchos investigadores del MA señalan la necesidad de modernizar el algoritmo, por lo que existen un gran número de modificaciones del algoritmo del mono. En ningún momento nos marcamos la meta de examinar todo tipo de modificaciones de la IA, porque el algoritmo en sí no es excepcional, sino más bien una variación sobre el tema del enjambre de partículas (PSO). El resultado de estos experimentos es la versión final del algoritmo que presentamos en este artículo, sin el marcado m adicional (modificado).
Histograma de los resultados de la prueba del algoritmo en la figura 3.

Figura 3. Histograma con los resultados finales de los algoritmos de prueba.
Ventajas y desventajas del algoritmo del mono (MA):
1. Es fácil de aplicar.
2. Tiene buena escalabilidad a pesar de la baja tasa de convergencia.
3. Muestra buen rendimiento en funciones discretas.
4. Tiene un número reducido de parámetros externos.
Desventajas:
1. Posee una baja tasa de convergencia.
2. Requiere un gran número de iteraciones de búsqueda.
3. Muestra una baja eficiencia global.
Para cada artículo, adjuntamos un archivo que contiene las versiones actualizadas actuales de los códigos del algoritmo para todos los artículos anteriores. El artículo representa la experiencia acumulada y la opinión personal del autor; las conclusiones y juicios se basan en los experimentos realizados.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12212
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso