
Metamodelos en el aprendizaje automático y el trading: Timing original de las órdenes comerciales
Introducción
Una característica distintiva de algunos sistemas comerciales es la negociación selectiva, es decir, que no están constantemente en el mercado. En su mayor parte, esto se debe a que, en determinados momentos, algunos patrones están presentes, mientras que en otros no están, o bien no están definidos.
En artículos anteriores, hemos examinado con detalle las distintas formas en que los modelos de aprendizaje automático pueden aplicarse a las tareas de clasificación de series temporales. Todos estos modelos se entrenaron "tal cual" con una muestra de entrenamiento y se compilaron en bots después de dicho entrenamiento. El proceso de etiquetado del conjunto de datos de entrenamiento y de selección del mejor modelo se ha automatizado al máximo, eliminando prácticamente el factor humano. A pesar de la elegancia de los enfoques propuestos, estos modelos tienen dos defectos que serían difíciles de corregir sin introducir funcionalidades adicionales.
Por eso, he propuesto ampliar el enfoque a los casos en los que el modelo puede:
- adaptarse a un conjunto de datos de entrenamiento seleccionando los mejores ejemplos para el entrenamiento
- filtrar las secciones de las series temporales que estén mal clasificadas y omitirlas en el proceso de aprendizaje y comercio
Esta generalización me ha hecho reconsiderar en parte mi enfoque sobre el aprendizaje, y resulta que el uso de un solo clasificador no cumple los nuevos requisitos, pues no puede ajustarse en el proceso de aprendizaje. Por consiguiente, le presento un nuevo trabajo con la funcionalidad modificada para los casos anteriores.
Aspectos teóricos del nuevo enfoque
Al principio de esta sección, querría hacer una pequeña observación. Como en el proceso de desarrollo de sistemas comerciales (incluido el aprendizaje automático) el investigador se enfrenta con la incertidumbre, no resulta posible formalizar de forma rigurosa lo que buscamos finalmente. Hablamos de unas dependencias más o menos estables en el espacio multidimensional, difíciles de interpretar en lenguaje humano o incluso matemático. Resulta difícil hacer un desglose detallado de lo que obtenemos de los sistemas altamente parametrizados y de autoaprendizaje. Estos algoritmos requieren cierto grado de confianza humana en ellos, y dicha confianza se basa en los resultados de los backtests, pero no aclaran la esencia misma o incluso la naturaleza del patrón encontrado.
Queremos escribir un algoritmo que sea capaz de analizar y corregir sus propios errores, mejorando sus resultados iterativamente. Para ello, proponemos al lector tomar un conjunto de dos clasificadores y entrenarlos secuencialmente como se sugiere en el esquema siguiente. A continuación, describiremos detalladamente la idea y la explicación del esquema.
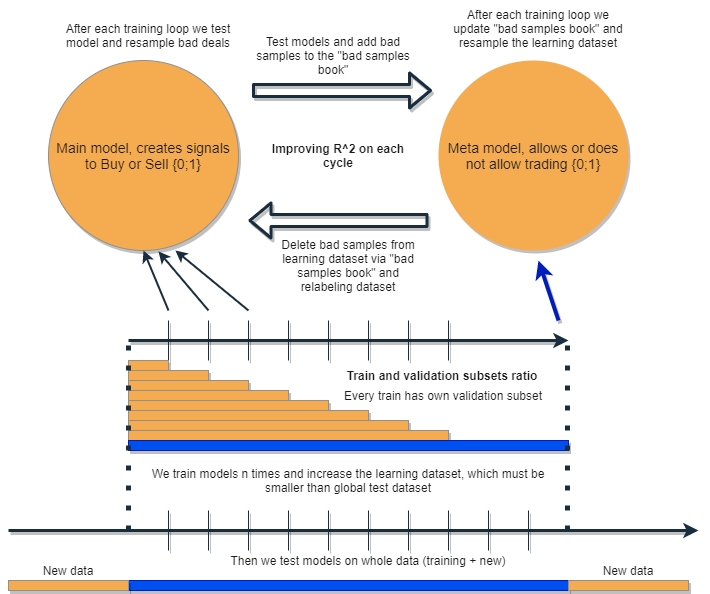
Cada uno de los clasificadores se entrena con su propio conjunto de datos, que tienen diferentes tamaños. La línea horizontal azul representa la profundidad teórica de la historia para el metamodelo, mientras que la naranja representa la profundidad para el modelo de básico. En otras palabras, la profundidad de la historia para el metamodelo es siempre mayor que para el modelo básico, y es igual al intervalo temporal estimado (de prueba) con el que se probará el conjunto de estos modelos.
El conjunto de modelos se reentrena varias veces; en este caso, el conjunto de datos de entrenamiento para el modelo básico puede aumentarse gradualmente (incrementando la longitud de las columnas naranjas con cada nueva iteración), pero su longitud no deberá superar la longitud de la azul. Después de cada iteración, todos los ejemplos que han sido clasificados como falsos (o nulos) por el metamodelo, se eliminarán de la muestra de entrenamiento del modelo básico. El metamodelo, a su vez, seguirá aprendiendo de todos los ejemplos.
La intuición detrás de este enfoque reside en que las operaciones no rentables son errores de clasificación del primer tipo para el modelo básico, en la terminología de la matriz de confusión. Es decir, son los casos que clasifica como falsos positivos. El metamodelo filtra dichos casos y da una puntuación de 1 para los verdaderos positivos y 0 para todo lo demás. Al filtrar el conjunto de datos a través del metamodelo para entrenar el modelo básico, aumentamos su precisión, es decir, el número de activaciones correctas de compra y venta. Al mismo tiempo, el metamodelo aumenta su Recall (completitud) al clasificar tantos resultados diferentes como sea posible.
Cuanto mayor resulte la precisión y la exhaustividad, más preciso será el modelo. Pero en situaciones reales, una mejora en un indicador provoca el deterioro del otro dentro del mismo clasificador, por lo que usar un paquete de dos clasificadores parece una idea interesante que redundará en la mejora en ambos indicadores.
Por su diseño, los dos modelos se entrenan con los mismos rasgos y, por tanto, muestran una interacción adicional. Debido a la mayor selección para el metamodelo (columna horizontal azul en comparación con las naranjas), este deja buenas situaciones comerciales, como si estuviera resolviendo los errores del modelo básico con los nuevos datos para él. Al interactuar entre sí, los modelos mejoran iterativamente a través del reetiquetado, y la puntuación R^2 en la muestra de validación aumenta constantemente. Pero un metamodelo puede ser entrenado con sus propias características como un filtro para el modelo básico; esta conexión no queda realmente dentro del alcance del enfoque propuesto, por lo que no la analizaremos en este artículo.
El modelo básico debería funcionar bien gracias al "apoyo" constante del metamodelo, pero el propio metamodelo también podría cometer errores. Por ejemplo, en la primera iteración se han clasificado los casos en los que no merece la pena comerciar. En la segunda iteración, tras reentrenar el modelo básico y ajustar los ejemplos para el metamodelo, los ejemplos malos pueden ser diferentes a los de la iteración anterior. Por ello, el metamodelo puede tender a reetiquetar constantemente los ejemplos, que serán diferentes de una iteración a otra. Es posible que este comportamiento nunca llegue a resultar óptimo. Para ponerle remedio, hemos creado el recuadro de "bad samples book", que se rellenará con ejemplos de todas las iteraciones anteriores. Para ser más exactos, registrará los valores de los rasgos en los puntos de tiempo etiquetados como malos para el comercio en todas las iteraciones anteriores del entrenamiento. Esto actualizará el conjunto de datos del metamodelo antes de cada reentrenamiento para que cualquier fallo de las iteraciones anteriores también quede etiquetado como malo (ceros).
El "bad samples book" también tiene la desventaja de que demasiadas iteraciones añadirán demasiados ceros (malas operaciones); el número de ejemplos se reducirá mucho para cada nueva iteración de aprendizaje. Por lo tanto, debemos encontrar un equilibrio entre el número de iteraciones y el número de ejemplos añadidos al libro de malos ejemplos. Parte de la situación puede resolverse promediando el número de malos ejemplos según el momento en que se produzcan y filtrando solo los más frecuentes. Esto garantizará que el conjunto de datos para el metamodelo no se degenere (habrá un equilibrio entre ceros y unos). No sería una mala ayuda usar el sobremuestreo si las clases resultan muy desequilibradas.
Tras varias iteraciones, este conjunto de modelos mostrará magníficos resultados con los datos de entrenamiento y validación. Además, el resultado mejorará de iteración en iteración. Tras el entrenamiento, el conjunto de modelos deberá probarse con datos completamente nuevos, que puedan situarse antes o después de la submuestra de entrenamiento. No hay ninguna teoría que diga inequívocamente qué parte de la historia debemos elegir para las pruebas de las series temporales financieras no estacionarias. No obstante, se supone que el rendimiento del enfoque propuesto mejora con los nuevos datos, y la práctica mostrará el resto.
Bien, entrenamos un modelo, corregimos sus errores usando los nuevos datos de otro modelo y repetimos este proceso varias veces. ¿Por qué debería esto mejorar la estabilidad de los clasificadores con los nuevos datos? No existe una respuesta clara a esta pregunta. Se supone que hay un patrón y, si lo hay, este será hallado, y después se filtrarán las situaciones sin patrón. Si el patrón es estable, el modelo también funcionará con los nuevos datos.
En teoría, este enfoque debería matar dos pájaros de un tiro:
- tener una alta expectativa de transacciones rentables
- conseguir un "timing" automático del sistema comercial, operando solo en determinados momentos de alta efectividad
En lo que respecta al timing del sistema comercial, hay otro punto interesante que debemos señalar. Ahora se reduce la dependencia de la elección de atributos (características) del modelo.
El planteamiento básico y el etiquetado supervisado implican una actitud escrupulosa respecto a la elección de los predictores y los objetivos, de hecho, este es el principal problema de este planteamiento. La preparación y el análisis de los datos son siempre lo primero, y la calidad de los modelos dependerá directamente de la profesionalidad del analista en ese campo concreto, concretamente en FÓREX.
El enfoque propuesto, en cambio, debería encontrar automáticamente eventos de tiempo, predictores y etiquetas interrelacionados, y también explotar los patrones encontrados de forma automática. La selección del predictores y el etiquetado de las operaciones son automáticos. Todavía deben cumplirse una serie de condiciones: por ejemplo, los signos deberán ser estacionarios y tener al menos una relación indirecta con el instrumento financiero. Pero en una situación en la que desconocemos los verdaderos patrones y no hay de dónde recopilar información, este enfoque parece justificado.
Por supuesto, este algoritmo funcionará al azar con los rasgos "basura", que no tienen ninguna relación causal con las transacciones. Sin embargo, esto es una cuestión de presencia/ausencia de relaciones causa/efecto en sí. La construcción de rasgos distintos a los incrementos (la diferencia entre la media móvil y el precio) no se trata deliberadamente en este artículo, ya que es un tema aparte (bastante voluminoso) que puede tratarse en otros materiales. Se supone que el enfoque analítico para la selección de rasgos informativos debería aumentar significativamente la solidez de este algoritmo con los nuevos datos.
Aplicación práctica del enfoque propuesto
En teoría, todo parece estupendo (como siempre); ahora vamos a comprobar qué efecto tiene realmente la combinación de los dos clasificadores. Para ello, debemos reescribir el código de nuevo.
Función de etiquetado automático de transacciones
Hemos realizado varios cambios: ahora es posible reetiquetar el modelo básico en función de las etiquetas del metamodelo:
def labelling_relabeling(dataset, min=15, max=15, relabeling=False) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if relabeling: m_labels = dataset['meta_labels'][i:rand+1].values if relabeling and 0.0 in m_labels: labels.append(2.0) else: if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index) return dataset
El código resaltado comprueba la bandera de reetiquetado, si es True y las métricas actuales con el horizonte de la transacción contienen ceros, entonces el metamodelo rechazará la transacción en esa zona. En consecuencia, dichas transacciones se etiquetarán como 2.0 y se eliminarán del conjunto de datos. De este modo, podremos eliminar iterativamente las muestras no deseadas de la muestra de entrenamiento para el modelo básico, reduciendo su error de aprendizaje.
Función de simulador personalizado
Ahora hemos ampliado la funcionalidad, haciendo posible probar dos modelos a la vez (el modelo básico y el metamodelo). Además, el simulador personalizado ahora sabe cómo reetiquetar el metamodelo para mejorarlo en la siguiente iteración.
def tester(dataset: pd.DataFrame, markup=0.0, use_meta=False, plot=False): last_deal = int(2) last_price = 0.0 report = [0.0] meta_labels = dataset['labels'].copy() for i in range(dataset.shape[0]): pred = dataset['labels'][i] meta_labels[i] = np.nan if use_meta: pred_meta = dataset['meta_labels'][i] # 1 = allow trades if last_deal == 2 and ((use_meta and pred_meta==1) or not use_meta): last_price = dataset['close'][i] last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 continue if last_deal == 1 and pred < 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (last_price - dataset['close'][i])) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l, meta_labels.fillna(method='backfill')
El simulador funciona de la siguiente manera.
Si la bandera del metamodelo se activa durante la prueba, se comprobará la condición referente a la existencia de su señal (uno). Si existe una señal, el modelo básico podrá abrir y cerrar operaciones, de lo contrario, no comerciará. El marcador amarillo indica cuándo se añadirán nuevas etiquetas al metamodelo en función del resultado de una transacción cerrada. Si el resultado es positivo, se añadirá uno, de lo contrario, la transacción se etiquetará como 0 (sin éxito).
Función de fuerza bruta
Los cambios más importantes los hemos realizado aquí. Los marcaré en el listado con diferentes colores y los describiré para que se entienda lo que sucede.
def brute_force(dataset, bad_samples_fraction=0.5): # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = dataset[dataset.columns[:-2]] X = X[X.index >= START_DATE] X = X[X.index <= STOP_DATE] X_meta = dataset[dataset.columns[:-2]] X_meta = X_meta[X_meta.index >= TSTART_DATE] X_meta = X_meta[X_meta.index <= STOP_DATE] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = dataset[dataset.columns[-2]] y = y[y.index >= START_DATE] y = y[y.index <= STOP_DATE] y_meta = dataset[dataset.columns[-1]] y_meta = y_meta[y_meta.index >= TSTART_DATE] y_meta = y_meta[y_meta.index <= STOP_DATE] # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True,) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # train\test split train_X, test_X, train_y, test_y = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) meta_model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # predict on new data (validation plus learning) pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] X.columns = [''] * len(X.columns) X_meta = X.copy() # predict the learned models (base and meta) p = model.predict_proba(X) p_meta = meta_model.predict_proba(X_meta) p2 = [x[0] < 0.5 for x in p] p2_meta = [x[0] < 0.5 for x in p_meta] pr2 = pr_tst.iloc[:len(p2)].copy() pr2['labels'] = p2 pr2['meta_labels'] = p2_meta pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) full_pr = pr2.copy() pr2 = pr2[pr2.index >= TSTART_DATE] pr2 = pr2[pr2.index <= STOP_DATE] # add bad samples of this iteratin (bad meta labels) global BAD_SAMPLES_BOOK BAD_SAMPLES_BOOK = BAD_SAMPLES_BOOK.append(pr2[pr2['meta_labels']==0.0].index) # test mdels and resample meta labels R2, meta_labels = tester(pr2, MARKUP, use_meta=True, plot=False) pr2['meta_labels'] = meta_labels # resample labels based on meta labels pr2 = labelling_relabeling(pr2, relabeling=True) pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) # mark bad labels from bad_samples_book if BAD_SAMPLES_BOOK.value_counts().max() > 1: to_mark = BAD_SAMPLES_BOOK.value_counts() mean = to_mark.mean() marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index pr2.loc[pr2.index.isin(marked_idx), 'meta_labels'] = 0.0 else: pr2.loc[pr2.index.isin(BAD_SAMPLES_BOOK), 'meta_labels'] = 0.0 R2, _ = tester(full_pr, MARKUP, use_meta=True, plot=False) return [R2, model, meta_model, pr2]
BAD_SAMPLES_BOOK y el resto del código etiquetado con el marcador correspondiente es responsable de implementar el libro de malos ejemplos. En cada nueva iteración del reentrenamiento de los dos modelos, el libro se repone con nuevos ejemplos de operaciones fallidas abiertas por los modelos anteriores después de su entrenamiento. La prueba se realiza con un simulador.
El último bloque asignado puede configurarse de forma flexible según la cantidad de ejemplos fallidos que deban marcarse como 0 en el siguiente reentrenamiento. Por defecto, se calcula la media de todos los duplicados para cada fecha presente en el libro.
marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index Esto se hace así para que no se borren todas las fechas fallidas, sino solo aquellas en las que el modelo ha fallado más veces durante todas las iteraciones de entrenamiento. Cuanto mayor sea el valor de bad_samples_fraction, menos fechas malas se eliminarán, y al contrario.
El color azul indica que la parte acortada del conjunto de datos que comienza a partir de la hora START_DATE, se usa para el modelo básico. Los datos anteriores no participarán en su aprendizaje, pero sí en el del metamodelo. También se destaca con este color que estamos entrenando precisamente dos modelos distintos. El modelo básico y el metamodelo.
La parte en la que se extraen las predicciones de ambos modelos se marca en color rosa. Con estas predicciones, se genera un nuevo conjunto de datos que se empuja hacia abajo en el código. Además, las etiquetas de los metamodelos malos son añadidas al libro de malos ejemplos.
A continuación, ambos modelos se prueban en el simulador personalizado, que además vuelve a marcar (corregir) las etiquetas del metamodelo para la siguiente iteración de entrenamiento. Usando el conjunto de datos corregido, se realiza un nuevo etiquetado para el modelo básico.
En la etapa final, el conjunto de datos se ajusta adicionalmente utilizando el libro de etiquetas malas y la función lo retorna para la siguiente iteración de entrenamiento.
A pesar de la abundancia de código Python, todo funciona rápidamente, gracias a la ausencia de ciclos anidados y optimización realizada. El entrenamiento de los clasificadores CatBoost lleva la mayor parte del tiempo. El tiempo de entrenamiento se incrementa conforme aumenta el número de rasgos y la longitud del conjunto de datos.
Proceso de reentrenamiento iterativo de los modelos
Ya hemos terminado de esbozar los detalles básicos del nuevo enfoque, ahora podemos pasar directamente al ciclo de entrenamiento del modelo. Le sugiero observar todo lo que sucede en cada etapa.
# make dataset
pr = get_prices()
pr = labelling_relabeling(pr, relabeling=False)
a, b = tester(pr, MARKUP, use_meta=False, plot=False)
pr['meta_labels'] = b
pr = pr.dropna()
pr = labelling_relabeling(pr, relabeling=True)
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
Las dos primeras líneas simplemente crean un conjunto de datos de entrenamiento, como ocurrió en los ejemplos mostrados en los artículos anteriores.
>>> pr = get_prices(START_DATE, STOP_DATE) >>> pr = labelling_relabeling(pr, relabeling=False) >>> pr close 0 1 2 3 4 5 6 labels time 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 -0.002396 -0.004554 -0.007759 -0.009549 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 -0.002664 -0.004900 -0.008039 -0.009938 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 -0.003494 -0.005663 -0.008761 -0.010778 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 -0.003380 -0.005485 -0.008559 -0.010684 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 -0.002873 -0.004894 -0.007929 -0.010144 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 23:00:00 1.19474 0.000154 0.002590 0.003375 0.003498 0.004095 0.004273 0.004888 0.0 2021-04-14 00:00:00 1.19492 0.000108 0.002337 0.003398 0.003565 0.004183 0.004410 0.005001 0.0 2021-04-14 01:00:00 1.19491 -0.000038 0.002023 0.003238 0.003433 0.004076 0.004353 0.004908 0.0 2021-04-14 02:00:00 1.19537 0.000278 0.002129 0.003534 0.003780 0.004422 0.004758 0.005286 0.0 2021-04-14 03:00:00 1.19543 0.000356 0.001783 0.003423 0.003700 0.004370 0.004765 0.005259 0.0 [5670 rows x 9 columns]
Ahora debemos añadir las etiquetas para el metamodelo. Recordemos que tester() retorna una puntuación R^2 y un marco con las operaciones etiquetadas. Así que ejecutaremos el simulador y añadiremos el frame resultante a los datos brutos.
>>> a, b = tester(pr, MARKUP, use_meta=False, plot=False) >>> pr['meta_labels'] = b >>> pr = pr.dropna() >>> pr close 0 1 2 ... 5 6 labels meta_labels time ... 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 ... -0.007759 -0.009549 1.0 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 ... -0.008039 -0.009938 1.0 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 ... -0.008761 -0.010778 1.0 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 ... -0.008559 -0.010684 1.0 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 ... -0.007929 -0.010144 1.0 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 18:00:00 1.19385 0.001442 0.003437 0.003198 ... 0.003637 0.004279 0.0 1.0 2021-04-13 19:00:00 1.19379 0.000546 0.003121 0.003015 ... 0.003522 0.004166 0.0 1.0 2021-04-13 20:00:00 1.19423 0.000622 0.003269 0.003349 ... 0.003904 0.004555 0.0 1.0 2021-04-13 21:00:00 1.19465 0.000820 0.003315 0.003640 ... 0.004267 0.004929 0.0 1.0 2021-04-13 22:00:00 1.19552 0.001112 0.003733 0.004311 ... 0.005092 0.005733 1.0 1.0 [5665 rows x 10 columns]
Los datos están ahora preparados para el entrenamiento. Además, podemos reetiquetar de nuevo las etiquetas principales ('labels') según las segundas etiquetas ('meta_labels'), es decir, eliminar del conjunto de datos todas las transacciones que hayan tenido pérdidas.
pr = labelling_relabeling(pr, relabeling=True) Con los datos totalmente completos, ahora podemos ver el funcionamiento del ciclo de aprendizaje de ambos modelos.
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
En primer lugar, debemos poner a cero el libro de operaciones malas, si es que queda algo en él del entrenamiento anterior. A continuación, establecemos el número necesario de iteraciones en el ciclo. En cada iteración, en la lista res[] se incrustarán las listas con los modelos guardados y todo lo que retorne brute_force(). Por ejemplo, podemos imprimir adicionalmente las métricas básicas del modelo en cada iteración.
El conjunto de datos convertido y retornado se escribe en la variable pr, y se usará para el entrenamiento en la siguiente iteración.
Podemos aumentar el periodo de entrenamiento del modelo básico, como se sugiere en la parte teórica. Esto se consigue cambiando la fecha de inicio del entrenamiento por un número determinado de días. Sin embargo, dicho periodo no deberá superar el tamaño del intervalo de validación TSTART_DATE sobre el que se entrena el metamodelo.
Una vez iniciado el entrenamiento, podremos ver más o menos la siguiente imagen:
Iteration: 0, R^2: 0.30121038659012245 Iteration: 1, R^2: 0.7400055934041012 Iteration: 2, R^2: 0.6221261327516192 Iteration: 3, R^2: 0.8892813889403367 Iteration: 4, R^2: 0.787251984980149 Iteration: 5, R^2: 0.794241109825588 Iteration: 6, R^2: 0.9167876214355855 Iteration: 7, R^2: 0.903399695678254 Iteration: 8, R^2: 0.8273236332747745 Iteration: 9, R^2: 0.8646088124681762 Iteration: 10, R^2: 0.8614746864767437 Iteration: 11, R^2: 0.7900599001415054 Iteration: 12, R^2: 0.8837049280116869 Iteration: 13, R^2: 0.784793801426211 Iteration: 14, R^2: 0.941340102099874 Iteration: 15, R^2: 0.8715065229034792 Iteration: 16, R^2: 0.8104990158946458 Iteration: 17, R^2: 0.8542444489379808 Iteration: 18, R^2: 0.8307365677342298 Iteration: 19, R^2: 0.9092509787525882
La primera pasada no suele ser muy buena; luego el modelo intenta mejorar con cada nueva pasada. A continuación, los modelos se clasifican en orden ascendente de R^2, y pueden ponerse a prueba con los nuevos datos. También podemos no usar la clasificación, y observar primero la evolución de los modelos en lugar de ello. Un rasgo característico de la evolución será la reducción del número de transacciones al poner a prueba los modelos.
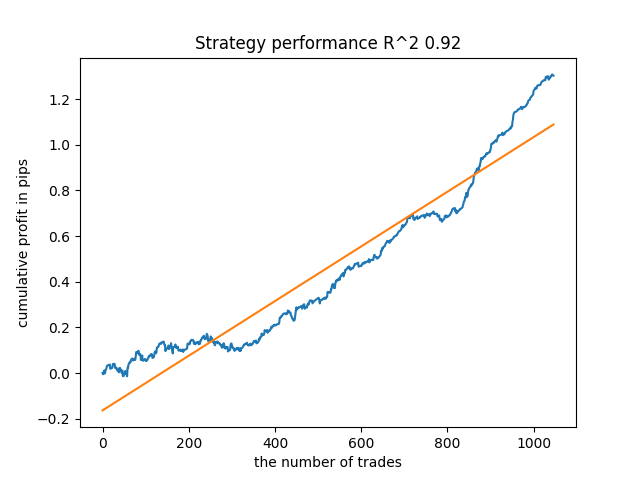
Por ejemplo, he probado el último modelo entrenado y he obtenido este resultado (todos los resultados se ofrecen con los nuevos datos):
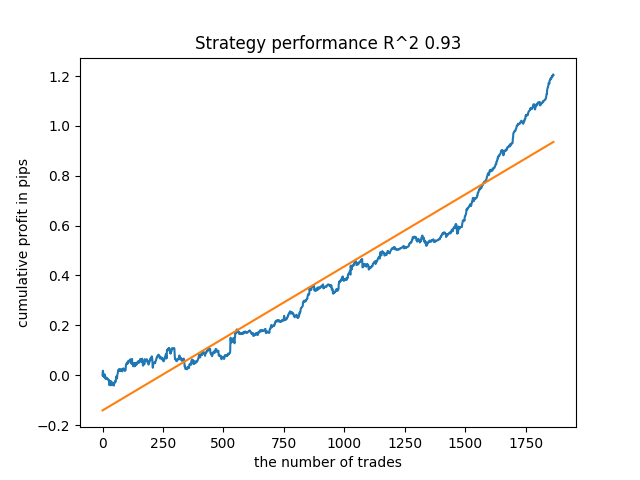
El quinto desde el final tendrá más transacciones, y así sucesivamente:
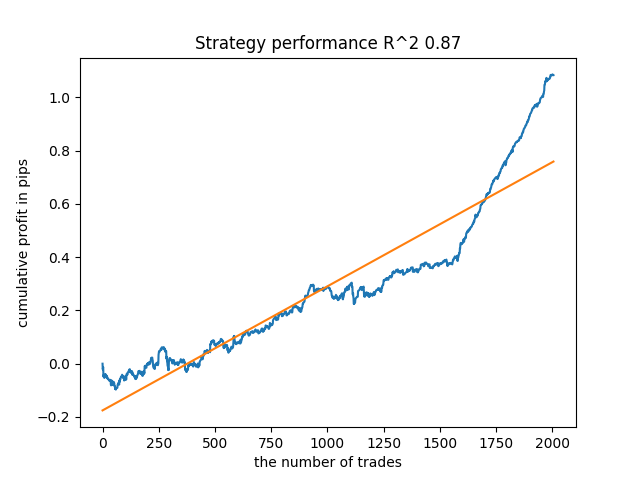
Dependiendo del número de iteraciones y del parámetro bad_samples_fraction, así como del tamaño de las muestras de entrenamiento y de prueba, podremos obtener modelos robustos con los nuevos datos. En general, la idea ha resultado viable, aunque bastante difícil de entender y aplicar. Más o menos la misma situación se ha producido con el parámetro use_GMM_resampling activado. El número de transacciones dependerá directamente del número de iteraciones, pero hay excepciones. He eliminado el remuestreo de la biblioteca, ya que requería demasiado tiempo de entrenamiento y no mejoraba demasiado los resultados con este enfoque.
Por ejemplo, me ha gustado el quinto resultado del final:
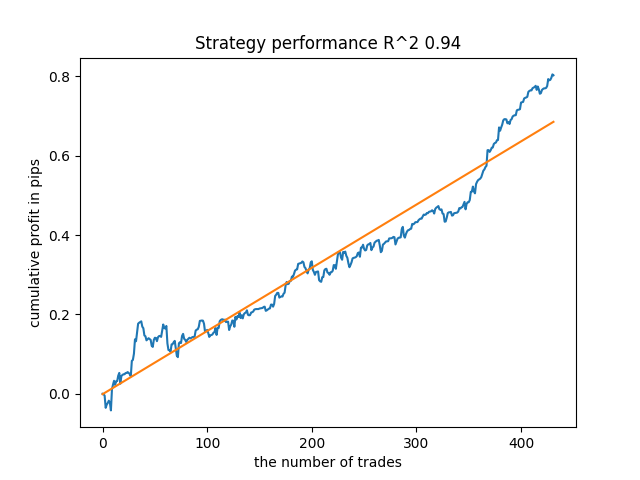
Pero el séptimo resultado ha sido preferible en cuanto al número de transacciones, que ha resultado dos veces superior. El beneficio acumulado en pips también ha aumentado:
Exportación de modelos a formato MQL5 y compilación de un asesor comercial
Ahora se mantendrán dos modelos: un modelo básico y un metamodelo. El modelo básico, como antes, controla las señales de compra y venta, mientras que el metamodelo prohíbe o permite el comercio en determinados momentos.
# add CatBosst base model code += 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n' # add CatBosst meta model code += 'double catboost_meta_model' + '(const double &features[]) { \n' code += ' ' with open('meta_catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
El código de los expertos comerciales se ha modificado ligeramente. Así, se llama a la función catboost_meta_model(), que genera la señal. Si es superior a 0,5, se permitirá el comercio.
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); double meta_sig = catboost_meta_model(features); // закрываем позиции по противоположному сигналу if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // открываем позиции и отложки по сигналам if(meta_sig > 0.5) if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); } } }
Adiciones
Para los usuarios de MAC y Linux, no está disponible la api del terminal para cargar las cotizaciones. Le sugiero utilizar otra función que acepte las cotizaciones cargadas desde el terminal MetaTrader 5 a un archivo. El archivo deberá guardarse en el directorio de trabajo.
def get_prices() -> pd.DataFrame:
p = pd.read_csv('EURUSDMT5.csv', delim_whitespace=True)
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], infer_datetime_format=True)
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
pFixed = pFixed.dropna()
pFixedC = pFixed.copy()
count = 0
for i in MA_PERIODS:
pFixed[str(count)] = pFixedC - pFixedC.rolling(i).mean()
count += 1
return pFixed.dropna()
Actualmente se usan tres fechas. Esto nos permite clasificar los modelos usando tanto los backtests como las pruebas forward. El inicio de la prueba forward se indica usando la variable global STOP_DATE, los datos posteriores a esta fecha no se utilizarán en el entrenamiento, pero sí en las pruebas. Por analogía, todo lo que sea anterior a TSTART_DATE será un backtest.
START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2017, 1, 1) STOP_DATE = datetime(2022, 1, 1)
No olvide que el modelo básico se entrena con los datos START_DATE - STOP_DATE, y el metamodelo se entrena con los datos TSTART_DATE - STOP_DATE. Todos los demás datos que quedan en el archivo solo intervienen en el backtest y la prueba forward.
Algunas pruebas más
He decidido probar el método de aprendizaje propuesto en algunos tipos de cambio cruzados, por ejemplo, GBPJPY H1. Para ello, he descargado del terminal las cotizaciones de 2010. El número de rasgos y los periodos de entrenamiento los he elegido así:
MA_PERIODS = [i for i in range(15, 500, 15)] MARKUP = 0.00002 START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2018, 1, 1) STOP_DATE = datetime(2022, 1, 1)
El modelo básico se entrena desde 2021 hasta principios de 2022, mientras que el metamodelo se entrena desde 2018 hasta 2022. Todos los demás datos se usan para las pruebas con datos nuevos, es decir, desde 2010 hasta el 2022.06.15.
Muestreo de transacciones con una duración aleatoria seleccionada en el intervalo 15-35.
def labelling_relabeling(dataset, min=15, max=35, relabeling=False):
Hemos elegido 25 iteraciones de entrenamiento. El multiplicador de malos ejemplos para el libro de ejemplos es igual a 0,5;
# iterative learning res = [] BAD_SAMPLES_BOOK = pd.DatetimeIndex([]) for i in range(25): res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.5)) print('Iteration: {}, R^2: {}'.format(i, res[-1][0])) pr = res[-1][3] # test best model res.sort() p = test_model(res[-1])
El proceso de entrenamiento ha dado estas puntuaciones R^2 en todo el conjunto de datos desde 2010:
Iteration: 0, R^2: 0.8364212812476872 Iteration: 1, R^2: 0.8265960950867208 Iteration: 2, R^2: 0.8710535097094494 Iteration: 3, R^2: 0.820894300254345 Iteration: 4, R^2: 0.7271704621597865 Iteration: 5, R^2: 0.8746302835797399 Iteration: 6, R^2: 0.7746283871087961 Iteration: 7, R^2: 0.870806543378866 Iteration: 8, R^2: 0.8651222653557956 Iteration: 9, R^2: 0.9452164577256995 Iteration: 10, R^2: 0.867541289963404 Iteration: 11, R^2: 0.9759544230548619 Iteration: 12, R^2: 0.9063804006221455 Iteration: 13, R^2: 0.9609701853129079 Iteration: 14, R^2: 0.9666262255426672 Iteration: 15, R^2: 0.7046628448822643 Iteration: 16, R^2: 0.7750941894554821 Iteration: 17, R^2: 0.9436968900331276 Iteration: 18, R^2: 0.8961403809578388 Iteration: 19, R^2: 0.9627553719743711 Iteration: 20, R^2: 0.9559809326980575 Iteration: 21, R^2: 0.9578579606050637 Iteration: 22, R^2: 0.8095556721129047 Iteration: 23, R^2: 0.654147043077418 Iteration: 24, R^2: 0.7538928969905255
A continuación, los modelos han sido clasificados según el R^2 máximo; aquí están los mejores, en orden descendente de puntuación.
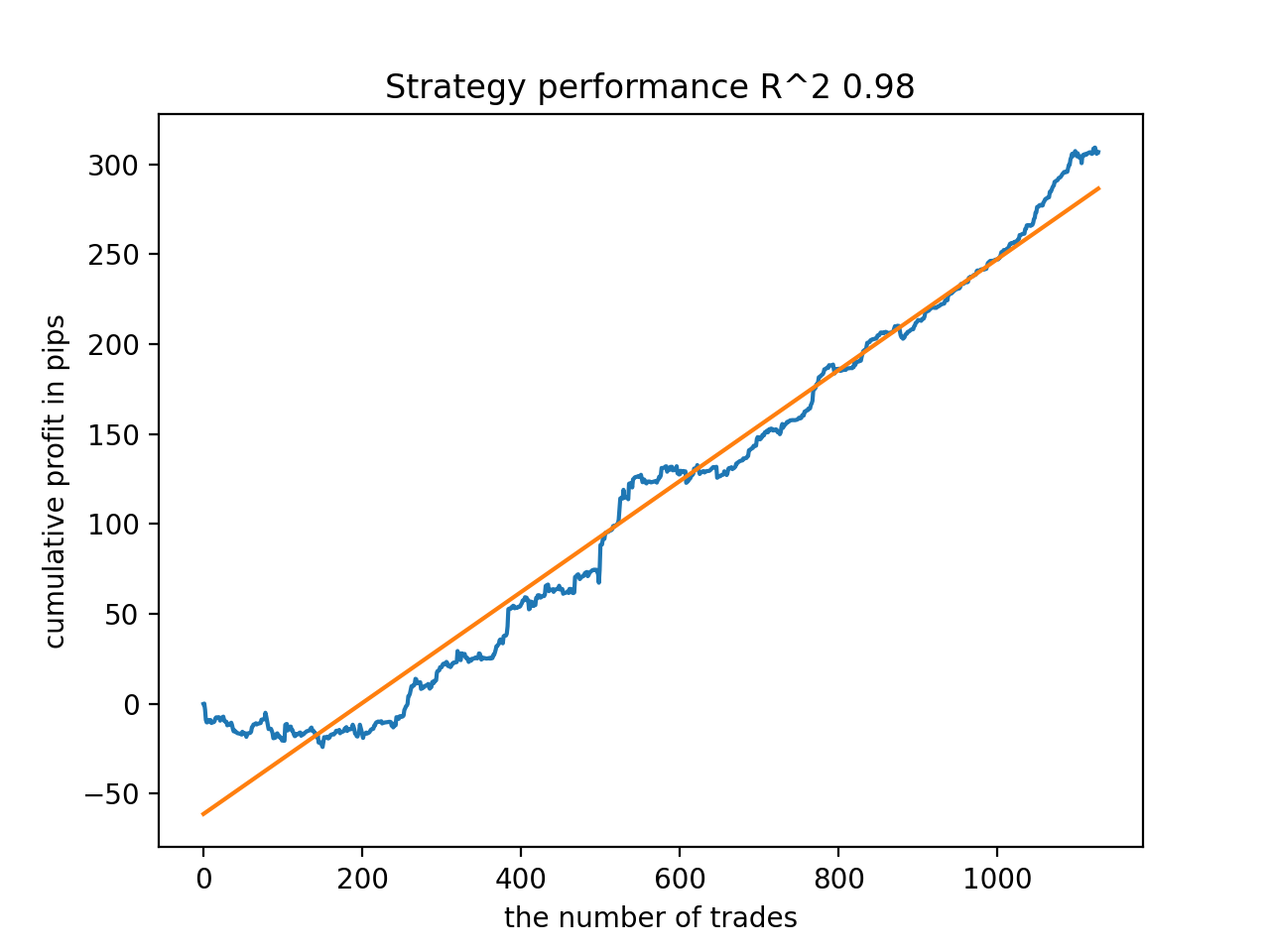
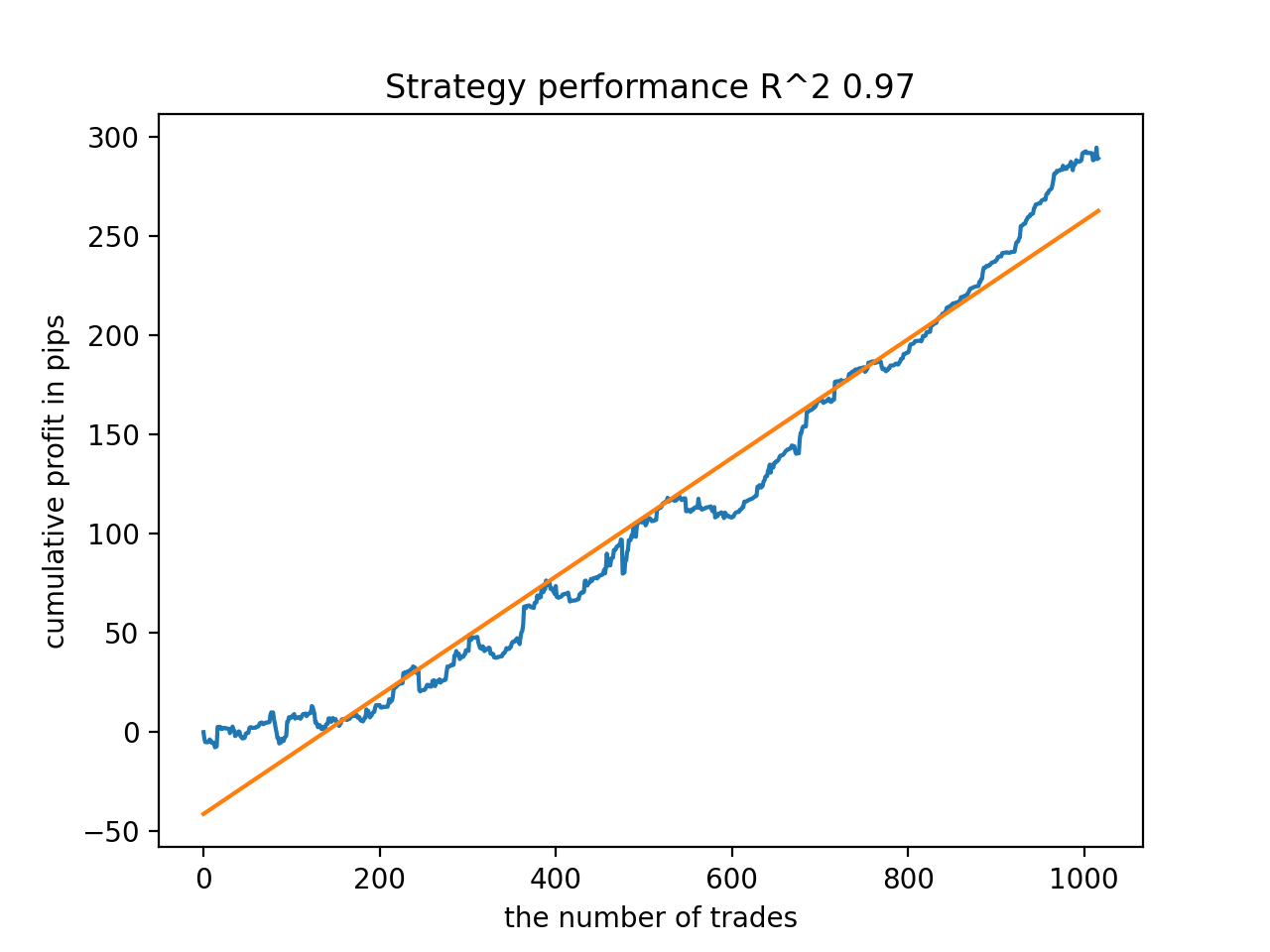
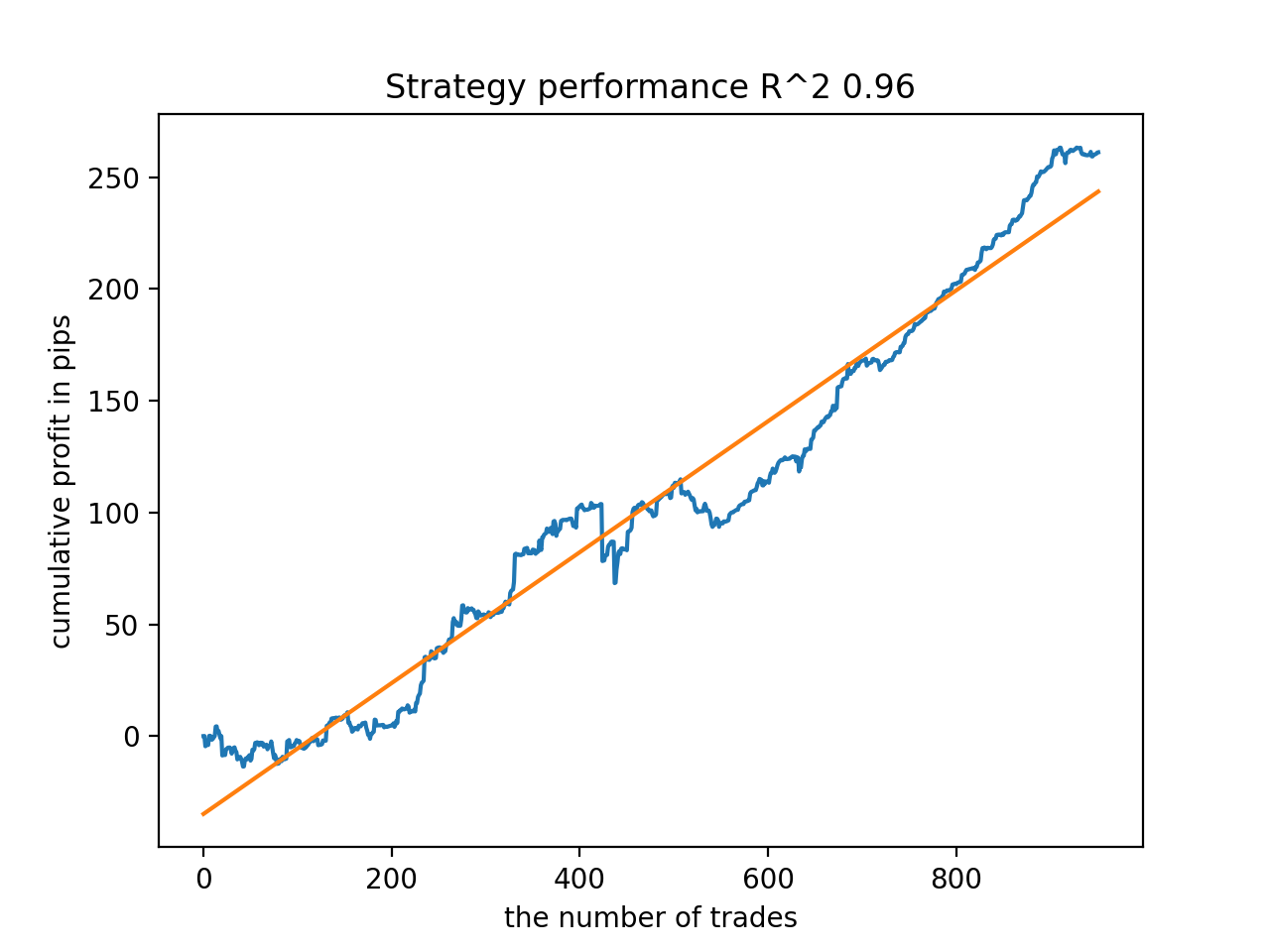
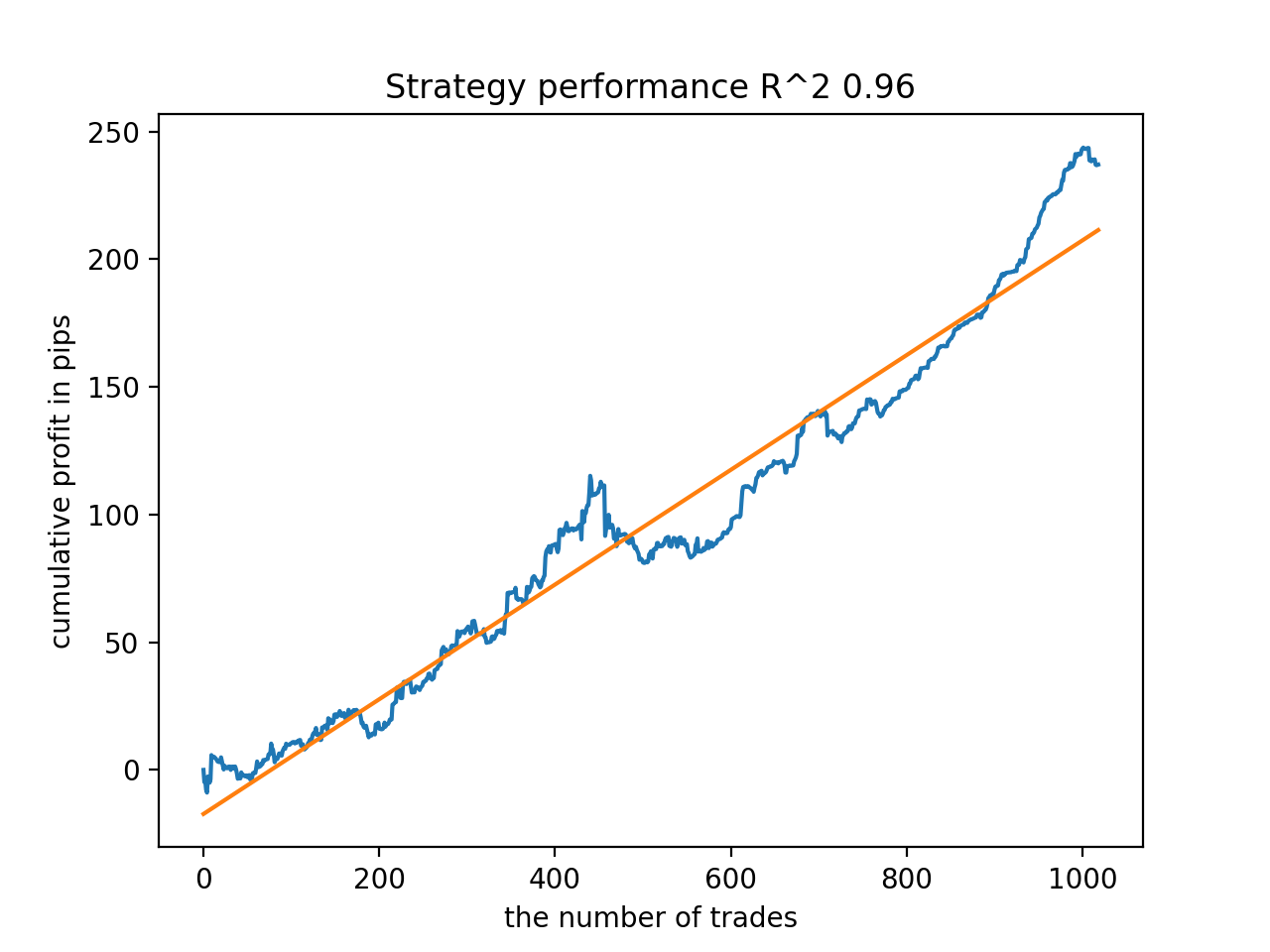
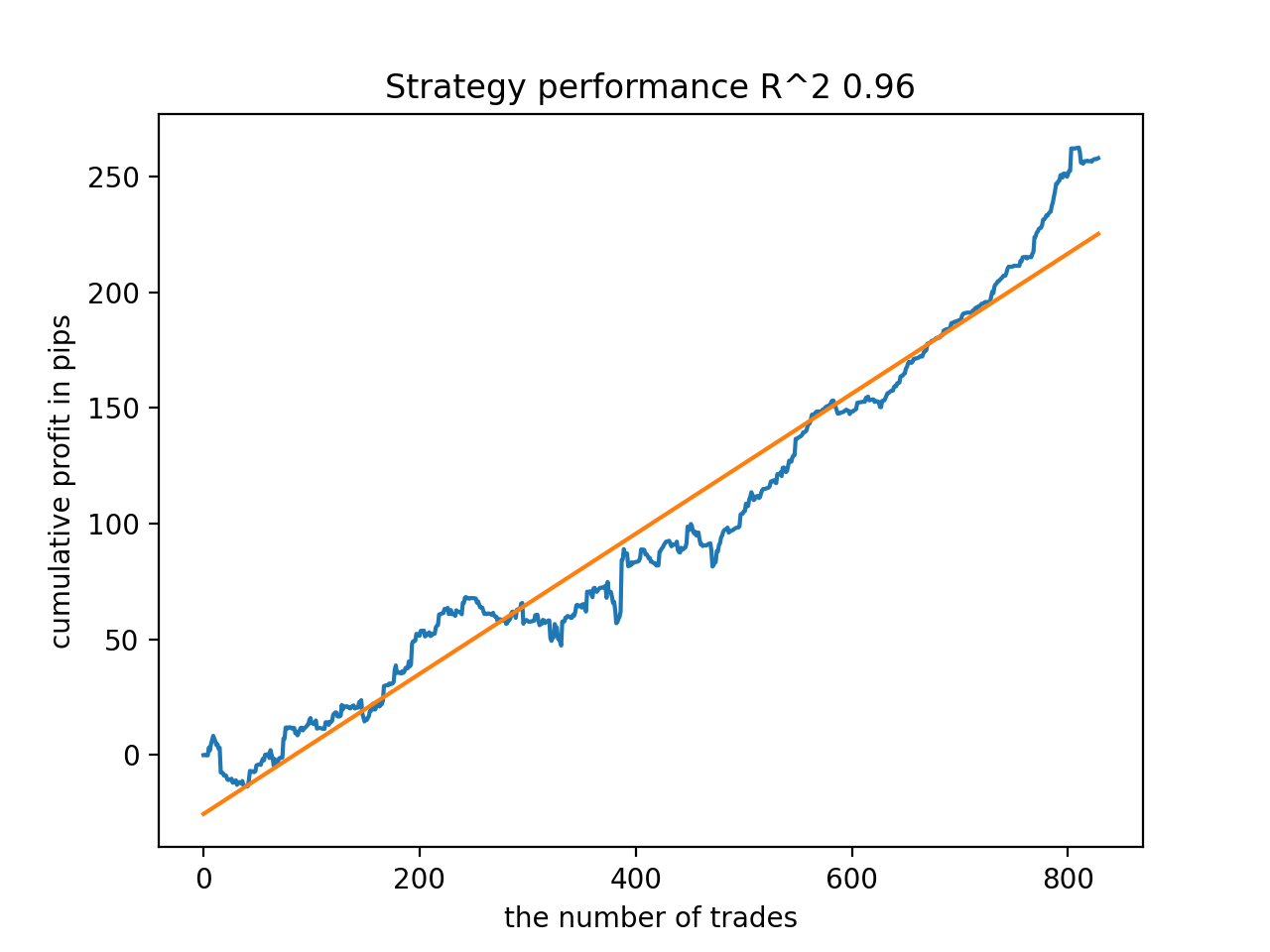
En general, todos los modelos son bastante estables durante el periodo que va desde 2010, aunque los gráficos no representan curvas perfectas.
Como paso final, vamos a exportar los modelos de interés a MetaTrader 5, para realizar pruebas adicionales, o bien para usarlos en el comercio. La función de exportación toma como entrada un modelo (en este caso es el mejor empezando desde el final) y un número de modelo para cambiar el nombre del archivo de forma que se puedan grabar varios modelos simultáneamente.
export_model_to_MQL_code(res[-1], str(1))
Compilamos el bot y lo ponemos a prueba en el simulador de estrategias de MetaTrader 5.
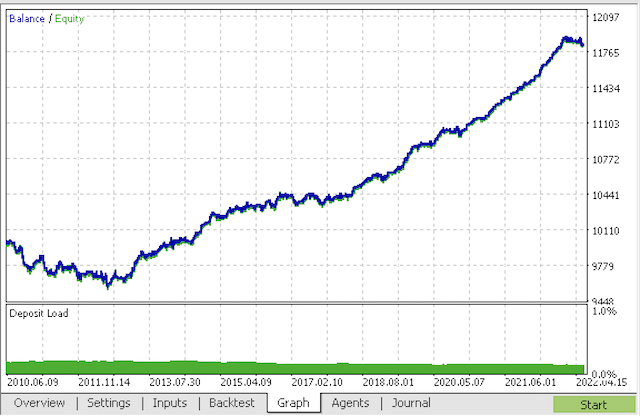
En el último paso, podemos trabajar con los modelos en el conocido terminal de MetaTrader 5.
Conclusión
En este artículo, hemos creado y mostrado probablemente el modelo de clasificación de series temporales más complejo y sofisticado que he tenido que implementar. Un punto interesante es la capacidad de descartar automáticamente los segmentos de historia difíciles de clasificar usando un metamodelo. Estos modelos a veces incluso superan a los modelos estacionales, que son entrenados para comerciar a una hora del día o un día de la semana concretos en los que hay ciclos estacionales pronunciados. En cambio, aquí el filtrado temporal es automático, sin intervención humana.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/9138
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
 Aprendiendo a diseñar un sistema de trading con Volumes
Aprendiendo a diseñar un sistema de trading con Volumes
 Aprendizaje automático y data science (Parte 05): Árboles de decisión usando como ejemplo las condiciones meteorológicas para jugar al tenis
Aprendizaje automático y data science (Parte 05): Árboles de decisión usando como ejemplo las condiciones meteorológicas para jugar al tenis
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Mi código funciona un poco más rápido que el código original :) Así que el entrenamiento es aún más rápido. Pero yo uso GPU.
Por favor, aclare si se trata de un error en el código
La expresión correcta parece ser
De lo contrario, la primera línea simplemente no tiene sentido, porque en la segunda línea se ejecuta de nuevo la condición de copia de datos, lo que lleva a copiar sin filtrar por el objetivo "1" del metamodelo.
Estoy aprendiendo y puedo estar equivocado con este python, por eso pregunto a .....
Sí, te has dado cuenta correctamente, tu código es correcto
También tengo una versión más rápida y un poco diferente, quería subirlo como un artículo mb.Sí, te has dado cuenta correctamente, tu código es correcto.
También tengo una versión más rápida y un poco diferente, quería subirlo como un artículo mb.Escribe, será interesante.
Lo mejor que pude conseguir en el entrenamiento.
Y esto es en una muestra separada
He añadido el proceso de inicialización a través de la formación.
Escribe, será interesante.
Lo mejor de la formación que pude conseguir
Y esto es en una muestra separada
He añadido el proceso de inicialización a través de la formación.
Ahí lo tienes, ya conoces python
.
No pretendo ser un experto, todo con un "diccionario".
Me interesaba encontrar algún efecto de este enfoque. Hasta ahora no me he dado cuenta de si hay alguno. En general, CatBoost se entrena sobre la muestra, sin ninguna "magia" - el equilibrio está abajo en la imagen. Por lo tanto, esperaba un resultado más expresivo.
Yo no pretendería ser versado - todo con un "diccionario".
Me interesaba encontrar algún efecto de este enfoque. Hasta ahora no me he dado cuenta si hay alguno. Así, CatBoost se entrena sobre la muestra, en general, sin ninguna "magia" - el balance está abajo en la imagen. Por eso esperaba un resultado más expresivo.