
Python, ONNX y MetaTrader 5: Creamos un modelo RandomForest con preprocesamiento de datos RobustScaler y PolynomialFeatures

¿Qué tipo de base vamos a utilizar? ¿Qué es un bosque aleatorio?
La historia del desarrollo del método Random Forest se remonta en el tiempo y se vincula con el trabajo de varios científicos destacados en el campo del aprendizaje automático y la estadística. No obstante, para comprender mejor los principios y la aplicación de este método, debemos imaginarlo como un enorme grupo de "personas" (árboles de decisión) que se reúnen y trabajan en colaboración.
El método del bosque aleatorio hunde sus raíces en los árboles de decisión. Los árboles de decisión son una representación gráfica de un algoritmo de decisión, en la que cada nodo representa una prueba sobre una de los características y cada rama representa el resultado de esa prueba, mientras que las hojas del árbol representan el resultado previsto. Los árboles de decisión se desarrollaron a mediados del siglo XX y se han convertido en herramientas populares para la clasificación y la regresión.
El siguiente gran paso fue el concepto de bagging, propuesto por Leo Breiman en 1996. El bagging consiste en crear múltiples submuestras (muestras bootstrap) a partir del conjunto de datos de entrenamiento y entrenar modelos individuales en cada una de ellas. A continuación, los resultados de los modelos se promedian o combinan para obtener previsiones más sólidas y precisas. Este método redujo la varianza de los modelos y mejoró su capacidad generalizadora.
El método de los bosques aleatorios fue propuesto por Leo Breiman y Adele Cutler a principios de la primera década de 2000. Se basa en la idea de combinar múltiples árboles de decisión utilizando bagging y aleatoriedad adicional. Cada árbol se construye partiendo de una submuestra aleatoria de datos de entrenamiento, y al construir cada nodo del árbol se selecciona un conjunto aleatorio de características. Esto hace que cada árbol resulte único y reduce la correlación entre árboles, lo cual mejora la capacidad generalizadora.
El bosque aleatorio se convirtió rápidamente en uno de los métodos más populares en el aprendizaje automático debido a su alto rendimiento y su capacidad para trabajar tanto con tareas de clasificación como de regresión. En clasificación se usa para decidir si los objetos pertenecen a clases diferentes, mientras que en la regresión se usa para predecir valores numéricos.
Hoy en día, el bosque aleatorio se usa ampliamente en diversos campos, como las finanzas, la medicina, el análisis de datos y muchos otros, debido a su robustez y capacidad para procesar tareas complejas de aprendizaje automático.
El bosque aleatorio, o RandomForest, es una potente herramienta en el arsenal del aprendizaje automático. Para entender mejor cómo funciona, lo visualizaremos como un enorme grupo de personas que se reúnen y toman decisiones colectivas. No obstante, en lugar de personas reales, cada persona de este grupo supone un clasificador o predictor independiente de la situación actual. Dentro de este grupo, las personas son árboles de decisión, cada uno capaz de tomar decisiones basadas en determinadas características. Cuando un bosque aleatorio toma una decisión, usa el principio democrático y la votación: cada árbol expresa su opinión y se toma una decisión basada en múltiples votos.
El bosque aleatorio se ha usado ampliamente en multitud de campos, y su flexibilidad lo hace adecuado tanto para tareas de clasificación como de regresión. En una tarea de clasificación, el modelo decide a cuál de las clases predefinidas asignar el estado actual. Por ejemplo, en el mercado financiero, esto podría significar la decisión de comprar (clase 1) o vender (clase 0) un activo en función de múltiples características.
Sin embargo, en este artículo profundizaremos en el problema de la regresión. La regresión en el aprendizaje automático supone un intento de predecir los valores numéricos futuros de una serie temporal usando como base sus valores pasados. En lugar de la clasificación, en la que asignamos objetos a clases específicas, en la regresión intentamos predecir números concretos. Puede tratarse, por ejemplo, de predecir los precios de las acciones en el mercado financiero, predecir la temperatura o cualquier otra variable numérica.
Creamos un modelo básico de RF
Para crear un modelo básico de bosque aleatorio, usaremos la biblioteca sklearn (scikit-learn) en Python. A continuación le mostramos una simple plantilla de código para entrenar un modelo de regresión de un bosque aleatorio. Antes de poder ejecutar este código, deberemos instalar las bibliotecas necesarias para sklearn, MetaTrader 5, utilizando la herramienta de instalación de paquetes en Python.
pip install onnx
pip install skl2onnx
pip install MetaTrader5
Lo siguiente en el plan será importar las bibliotecas y configurar los parámetros. Importaremos las bibliotecas necesarias como pandas para la manipulación de datos, gdown para la carga de datos desde Google Drive, y bibliotecas para el procesamiento de datos y la creación de modelos de bosque aleatorio. También especificaremos el número de pasos temporales (n_pasos) en la secuencia de datos, que se determinará en función de los requisitos específicos:
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Set the number of time steps according to requirements n_steps = 100
El siguiente paso será descargar y procesar los datos. En esta parte del código cargaremos los datos de cotizaciones de MetaTrader 5 y los procesaremos. Luego fijaremos el índice temporal y seleccionaremos solo los precios de cierre (trabajaremos precisamente con ellos):
Aquí está la parte del código responsable de dividir nuestros datos en conjuntos de entrenamiento y de prueba, y de marcar las etiquetas para entrenar el modelo. Después dividiremos los datos en conjuntos de entrenamiento y de prueba. A continuación, crearemos las etiquetas para la regresión, lo cual significa que cada etiqueta representará un valor de precio futuro real. La función labelling_relabelling_regression se usará para crear datos etiquetados.mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Set the number of time steps according to your requirements n_steps = 100 # Process data data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Work only with close prices
# Define train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Function for creating and assigning labels for regression (changes made for regression, not classification) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['close'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Apply the labelling_relabeling_regression function to raw data to get labeled data train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
A continuación, crearemos conjuntos de datos de entrenamiento, a partir de secuencias específicas. Lo importante es que el modelo toma como características todos los precios de cierre de nuestra secuencia. El tamaño de la secuencia será el mismo que el de los datos introducidos en el modelo ONNX. En esta fase no se realizará ninguna normalización: se llevará a cabo en el proceso de entrenamiento, como parte de la operación del modelo.
# Create datasets of features and target variables for testing
x_test = np.array([test_data_labeled['close'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))])
y_test = test_data_labeled['future_price'].iloc[n_steps:].values
# After creating x_train and x_test, define n_features as follows:
n_features = x_train.shape[1]
# Now use n_features to determine the ONNX input data type
initial_type = [('float_input', FloatTensorType([None, n_features]))]
A continuación, escribiremos un pipeline para el preprocesamiento de datos
Nuestro siguiente paso será crear un modelo, el modelo de bosque aleatorio, y será importante hacer el modelo en forma de pipeline.
Un pipeline en la biblioteca scikit-learn (sklearn) es una forma de crear una cadena coherente de transformaciones y modelos para el análisis de datos y el aprendizaje automático. Un pipeline permite combinar varios pasos de procesamiento y modelado de datos en un único objeto que puede utilizarse para realizar operaciones con los datos de forma cómoda y coherente.
En nuestro ejemplo de código, crearemos el siguiente pipeline:
# Create a pipeline with MinMaxScaler, RobustScaler, PolynomialFeatures and RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Train the pipeline
pipeline.fit(x_train, y_train)
# Make predictions
predictions = pipeline.predict(x_test)
# Evaluate model using R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}')
Un pipeline es una secuencia de pasos de procesamiento de datos y modelización combinados en una única cadena. En este código, el pipeline se creará utilizando la librería scikit-learn (sklearn) e incluirá los siguientes pasos:
-
MinMaxScaler: Este paso escala los datos, llevándolos a un rango de 0 a 1. Esto resulta útil para garantizar que todas las características tengan la misma escala.
-
RobustScaler: RobustScaler también realiza el escalado de datos, pero es más robusto frente a valores atípicos en los datos. Usa la mediana y el rango intercuartílico para el escalado.
-
PolynomialFeatures: En este paso, se aplicará una transformación polinómica a las características. Esto añadirá características polinómicas que pueden ayudar al modelo a considerar las dependencias no lineales de los datos.
-
RandomForestRegressor: Este paso definirá un modelo de bosque aleatorio con un conjunto de hiperparámetros:
- n_estimators (Número de árboles del bosque): Supongamos que tenemos un grupo de "expertos", cada uno especializado en predecir precios en el mercado financiero. El número de árboles del bosque aleatorio (n_estimators) determinará cuántos de estos "expertos" habrá en su grupo. Cuantos más árboles haya, más opiniones y predicciones diversas se considerarán en la toma de decisiones del modelo.
- max_depth (Profundidad máxima de cada árbol): Este parámetro limitará la profundidad con la que cada "experto" (árbol) puede "bucear" en el análisis de los datos. Si establecemos una profundidad máxima en 20, por ejemplo, entonces cada árbol tomará decisiones teniendo en cuenta no más de 20 características.
- min_samples_split (Número mínimo de muestras para dividir un nodo del árbol): Este parámetro indicará cuántas muestras (observaciones) debe haber en un nodo del árbol para que éste continúe su división en nodos más pequeños. Por ejemplo, si establecemos el número mínimo de muestras a dividir en 5 000, el árbol solo dividirá los nodos si el nodo tiene más de 5 000 observaciones.
- min_samples_leaf (Número mínimo de muestras en un nodo de hoja del árbol): Este parámetro determinará cuántas muestras debe haber en un nodo de hoja del árbol para que ese nodo se convierta en "hoja" y no se divida más. Por ejemplo, si establecemos el número mínimo de muestras en un nodo de hoja en 5 000, entonces cada hoja del árbol contendrá al menos 5 000 observaciones.
- random_state (Establece el estado inicial para la generación aleatoria, garantizando resultados reproducibles): Este parámetro se utilizará para controlar los procesos aleatorios dentro del modelo. Si establecemos un valor fijo (por ejemplo, 1), los resultados serán los mismos cada vez que ejecutemos el modelo. Esto será útil para la reproducibilidad de los resultados.
- verbose (Permite la muestra de información sobre el proceso de entrenamiento del modelo): Cuando entrenamos un modelo, puede resultar útil ver información sobre el proceso. El parámetro verbose permitirá controlar el nivel de detalle de esta información. Cuanto mayor sea el valor (por ejemplo, 2), más información se deducirá en el proceso de aprendizaje.
Tras crear el pipeline, utilizaremos el método de ajuste para entrenarlo con los datos de entrenamiento. A continuación, utilizaremos el método de predicción para realizar predicciones sobre los datos de prueba. Por último, evaluaremos la calidad del modelo usando la métrica R2, que mide el ajuste del modelo a los datos.
El pipeline se entrenará y luego se evaluará utilizando la métrica R2. Luego usaremos la normalización, eliminando los valores atípicos de los datos y creando características polinómicas. Estos son los métodos más sencillos de preprocesamiento de datos. En futuros artículos, veremos cómo crear nuestra propia función de preprocesamiento usando el Function Transformer.
Utilizaremos la exportación de modelos en ONNX y escribiremos la función de exportación
Después de entrenar el pipeline, lo guardaremos en formato joblib, que guardaremos en formato ONNX usando la biblioteca skl2onnx.
# Save the pipeline
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Convert pipeline to ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Connect Google Drive (if you work in Colab and this is necessary)
from google.colab import drive
drive.mount('/content/drive')
# Specify the path to Google Drive where you want to move the model
drive_path = '/content/drive/My Drive/' # Make sure the path is correct
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Move ONNX model to Google Drive
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('The rf_pipeline model is saved in the ONNX format on Google Drive:', rf_pipeline_onnx_drive_path)
Este es el aspecto que tendrá el proceso de entrenamiento de un modelo y el almacenamiento del modelo en ONNX. Esta será la imagen que veremos cuando termine el entrenamiento:
El modelo se guardará en el directorio básico de Google Drive, en formato ONNX. ONNX puede considerarse una especie de "disquete" para los modelos de aprendizaje automático. Este formato permite guardar y convertir los modelos entrenados para usarlos en diversas aplicaciones. Es similar a cuando guardamos archivos en una memoria USB y luego podemos leerlos en otros dispositivos. En nuestro caso, el modelo ONNX se usará en el entorno MetaTrader 5 para pronosticar los precios en los mercados financieros. El propio "disquete" ONNX podrá desde fuera, por ejemplo, en MetaTrader 5, que es lo que vamos a hacer ahora.
Comprobamos el modelo en el simulador de MetaTrader 5
El modelo ONNX se ha guardado en Google Drive, lo descargaremos desde allí. Después de guardar el modelo ONNX en Google Drive, lo descargamos desde allí. Para utilizar este modelo en MetaTrader 5, crearemos un asesor que leerá y aplicará este modelo para tomar decisiones comerciales. En el código del asesor presentado, estableceremos los parámetros comerciales, tales como el tamaño del lote y el uso de órdenes stop, así como los niveles de Take Profit y Stop Loss. Aquí tenemos el código para el asesor que "leerá" nuestro modelo ONNX:
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Function for closing all positions void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Expert Advisor initialization int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("The model should work with EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Error setting the input shape OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Process the tick function void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Check position closing conditions void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to predict prices void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
Me gustaría enfatizar que se trata de la dimensionalidad de los datos de entrada:
const long input_shape[] = {1,100};
Deberá coincidir con la dimensionalidad en nuestro modelo Python:
# Set the number of time steps to your requirements n_steps = 100
A continuación, procederemos a probar el modelo en el entorno MetaTrader 5. Utilizaremos las predicciones del modelo para determinar la dirección de los movimientos de precios en el mercado. Si el modelo predice que el precio subirá, nos estaremos preparando para abrir una posición larga (comprar), y viceversa, si el modelo predice que el precio bajará, nos estaremos preparando para abrir una posición corta (vender). Probaremos el modelo con un take profit de 1000, y un stop loss de 500:
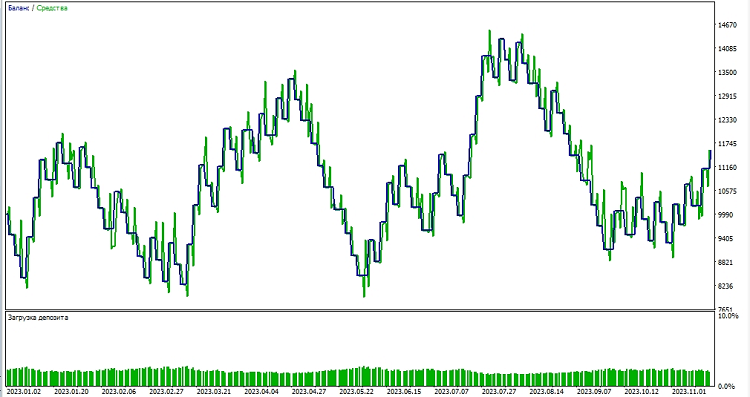
Conclusión
Bien, hoy hemos abarcado la creación y el entrenamiento de un modelo de bosque aleatorio en Python, el preprocesamiento de datos directamente en el modelo, y su exportación al estándar ONNX, así como la posterior apertura y el uso del modelo en MetaTrader 5.
ONNX es un excelente sistema de importación y exportación de modelos, versátil y sencillo. Guardar un modelo en ONNX resulta en realidad mucho más fácil de lo que parece, y el preprocesamiento de datos también es muy sencillo.
Obviamente, nuestro modelo de solo 20 árboles de decisión es muy simple, y el modelo de bosque aleatorio en sí ya es una solución bastante antigua, un modelo del siglo pasado. En el futuro, crearemos modelos más sofisticados y avanzados, y usaremos un preprocesamiento de datos más complejo. Por otra parte, nos gustaría mencionar la posibilidad de crear un conjunto de modelos a la vez como un pipeline de sklearn, junto con el preprocesamiento. Esto ampliará sustancialmente nuestras capacidades, incluso para tareas de clasificación.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13725
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Sólo el bosque fue elegido como un ejemplo sencillo)Busting en el próximo artículo, estoy retocando un poco ahora)
Bueno)
Sería interesante profundizar en el tema de los transportadores y su conversión a ONNX con posterior uso en metatrader. Por ejemplo, ¿es posible añadir transformaciones personalizadas al transportador y se abrirá en Metatrader el modelo ONNX obtenido de dicho transportador? Imho, el tema es digno de varios artículos.
Sería interesante profundizar en el tema de los transportadores y su conversión a ONNX con posterior uso en metatrader. Por ejemplo, ¿es posible añadir transformaciones personalizadas al transportador y se abrirá en Metatrader el modelo ONNX obtenido de dicho transportador? Imho, el tema es digno de varios artículos.