有关MQL5数据分析和统计的文章


来自专业程序员的提示(第三部分):日志。 连接到 Seq 日志收集和分析系统
Logger 类的实现能够统一和结构化打印到智能系统栏的日志消息。 连接到 Seq 日志收集和分析系统。 在线监视日志消息。



MQL5.community 中的名人?
MQL5.com 网站能够记住你的一切!你有多少帖子受热捧,您的文章有多受欢迎,您的程序在代码库中被下载了多少次 – 这仅仅是 MQL5.com 记住的一小部分。您的成就可以在个人资料中找到,但是整体情况呢?在本文中,我将显示所有 MQL5.community 会员成就的概貌。

数据科学和机器学习(第 27 部分):MetaTrader 5 中训练卷积神经网络(CNN)交易机器人 — 值得吗?
卷积神经网络(CNN)以其在检测图像和视频形态方面的出色能力而闻名,其应用涵盖众多领域。在本文中,我们探讨了 CNN 在金融市场中识别有价值形态,并为 MetaTrader 5 交易机器人生成有效交易信号的潜力。我们来发现这种深度机器学习技术如何能撬动更聪明的交易决策。

从头开始开发智能交易系统(第 16 部分):访问 web 上的数据(II)
掌握如何从网络向智能交易系统输入数据并非那么轻而易举。 如果不了解 MetaTrader 5 提供的所有可能性,就很难做到这一点。
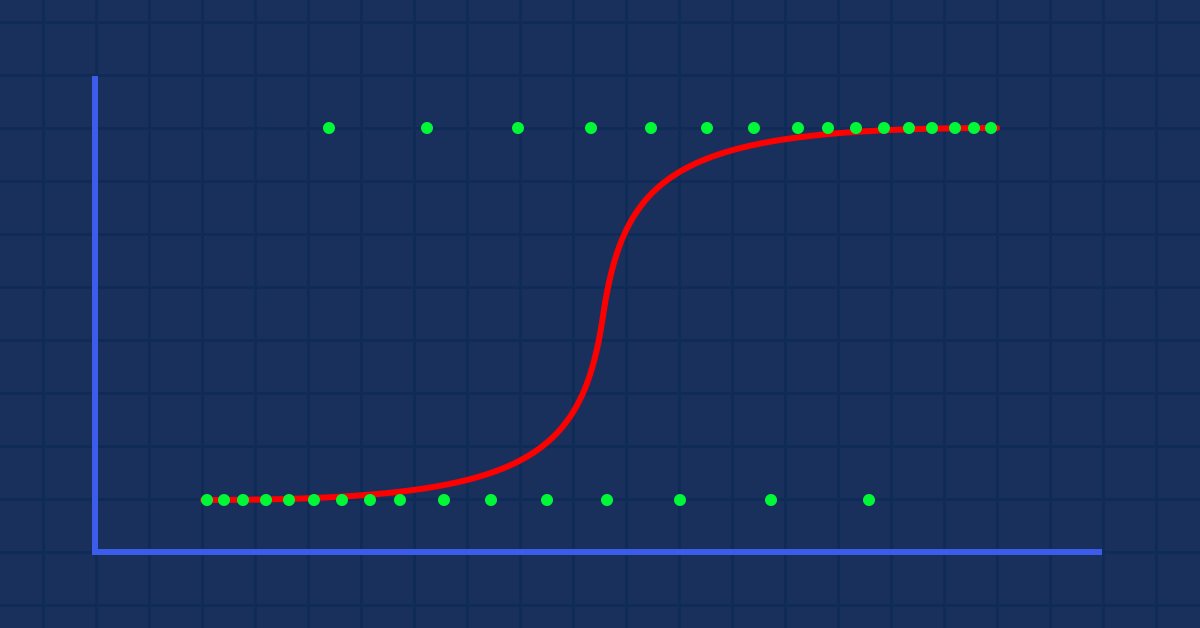
数据科学与机器学习(第 02 部分):逻辑回归
数据分类对于算法交易者和程序员来说是至关重要的。 在本文中,我们将重点关注一种分类逻辑算法,它有帮于我们识别“确定或否定”、“上行或下行”、“做多或做空”。
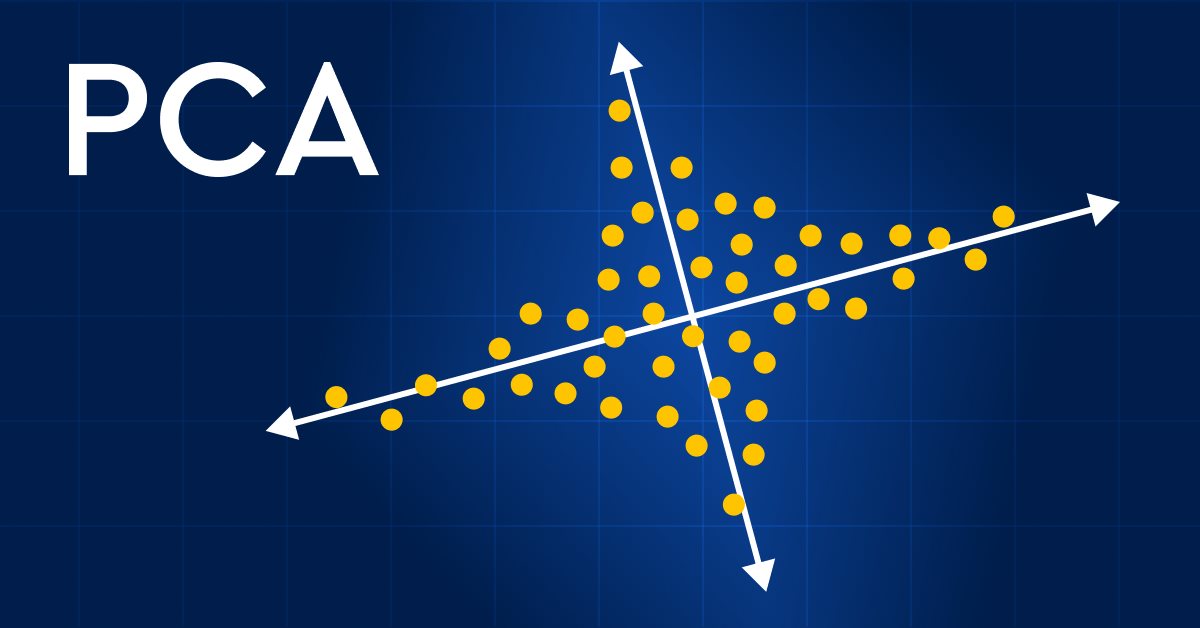
数据科学和机器学习(第 13 部分):配合主成分分析(PCA)改善您的金融市场分析
运用主成分分析(PCA)彻底革新您的金融市场分析! 发现这种强大的技术如何解锁数据中隐藏的形态,揭示潜在的市场趋势,并优化您的投资策略。 在本文中,我们将探讨 PCA 如何为分析复杂的金融数据提供新的视角,揭示传统方法会错过的见解。 发掘 PCA 应用于金融市场数据如何为您带来竞争优势,并帮助您保持领先地位。

通过配对交易中的均值回归进行统计套利:用数学战胜市场
本文描述了投资组合层面的统计套利基础知识。其目标是帮助没有深厚数学知识的读者理解统计套利的原则,并提出一个概念性的起点框架。文章包含一个可运行的智能交易系统(EA)、一些关于其一年回测的笔记,以及用于复现实验的相应回测配置设置(.ini 文件)。

掌握ONNX:MQL5交易者的游戏规则改变者
深入ONNX的世界,这是一种用于交换机器学习模型的强大的开放标准格式。了解利用ONNX如何彻底改变MQL5中的算法交易,使交易员能够无缝集成尖端的人工智能模型,并将其策略提升到新的高度。揭开跨平台兼容性的秘密,学习如何在您的MQL5交易活动中释放ONNX的全部潜力。通过这篇掌握ONNX的全面指南提升您的交易游戏

神经网络变得轻松(第十五部分):利用 MQL5 进行数据聚类
我们继续研究聚类方法。 在本文中,我们将创建一个新的 CKmeans 类来实现最常见的聚类方法之一:k-均值。 在测试期间,该模型成功地识别了大约 500 种形态。

DoEasy 函数库中的时间序列(第五十四部分):抽象基准指标类的衍生
本文研究基于基准抽象指标衍生对象类的创建。 这些对象所提供功能,可访问创建的指标 EA,收集和获取各种指标和价格数据的数值统计信息。 同样,创建指标对象集合,从中可以访问程序中创建的每个指标的属性和数据。
DoEasy 函数库中的时间序列(第六十部分):品种即时报价数据的序列列表
在本文中,我将创建存储单一品种即时报价数据的列表,并在 EA 中检查其创建状态,以及检索所需数据。 每个所用品种各自的即时报价数据列表将来会构成即时报价数据集合。


时间序列挖掘的数据标签(第1部分):通过EA操作图制作具有趋势标记的数据集
本系列文章介绍了几种时间序列标记方法,这些方法可以创建符合大多数人工智能模型的数据,而根据需要进行有针对性的数据标记可以使训练后的人工智能模型更符合预期设计,提高我们模型的准确性,甚至帮助模型实现质的飞跃!

DoEasy 函数库中的时间序列(第五十部分):多周期、多品种带位移的标准指标
在文章里,我们将改进函数库的方法,以便正确显示多品种、多周期的标准指标,即那些在当前品种图表上显示曲线,并可在设置中指定位移的指标。 同样,我们按照标准指标的操纵方法进行排序,并在最终的指标程序里将多余的代码移至函数库区域。

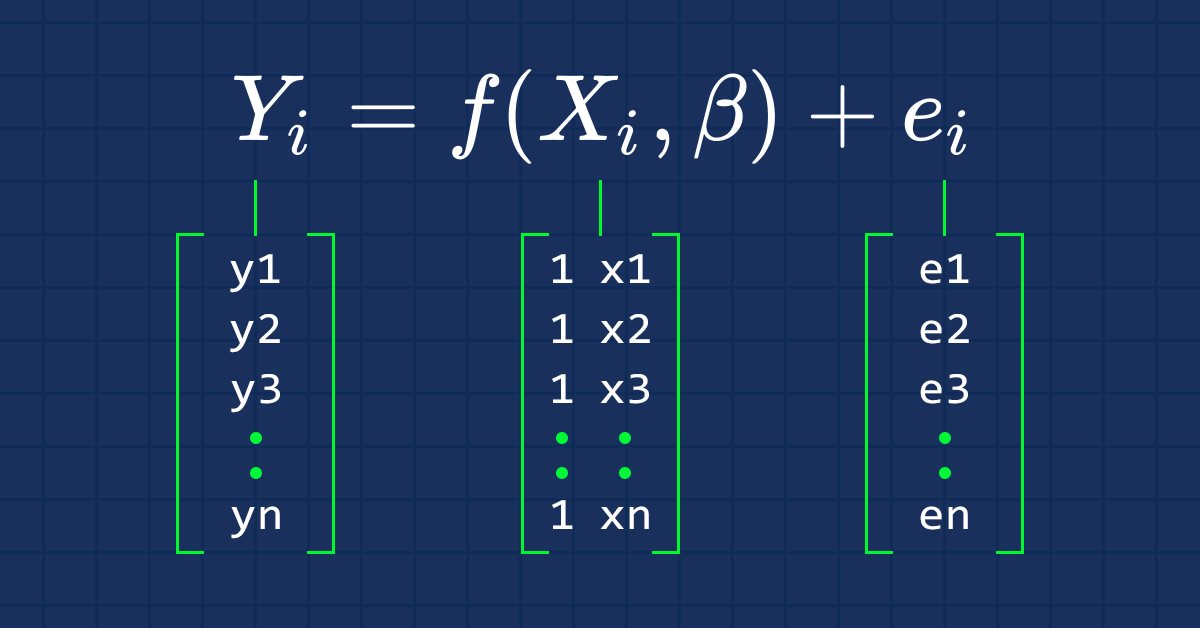
数据科学与机器学习(第 03 部分):矩阵回归
这一次,我们的模型是由矩阵构建的,它更具灵活性,同时它允许我们构建更强大的模型,不仅可以处理五个独立变量,但凡我们保持在计算机的计算极限之内,它还可以处理更多变量,这篇文章肯定会是一篇阅读起来很有趣的文章。

神经网络变得轻松(第三十九部分):Go-Explore,一种不同的探索方式
我们继续在强化学习模型中研究环境。 在本文中,我们将见识到另一种算法 — Go-Explore,它允许您在模型训练阶段有效地探索环境。

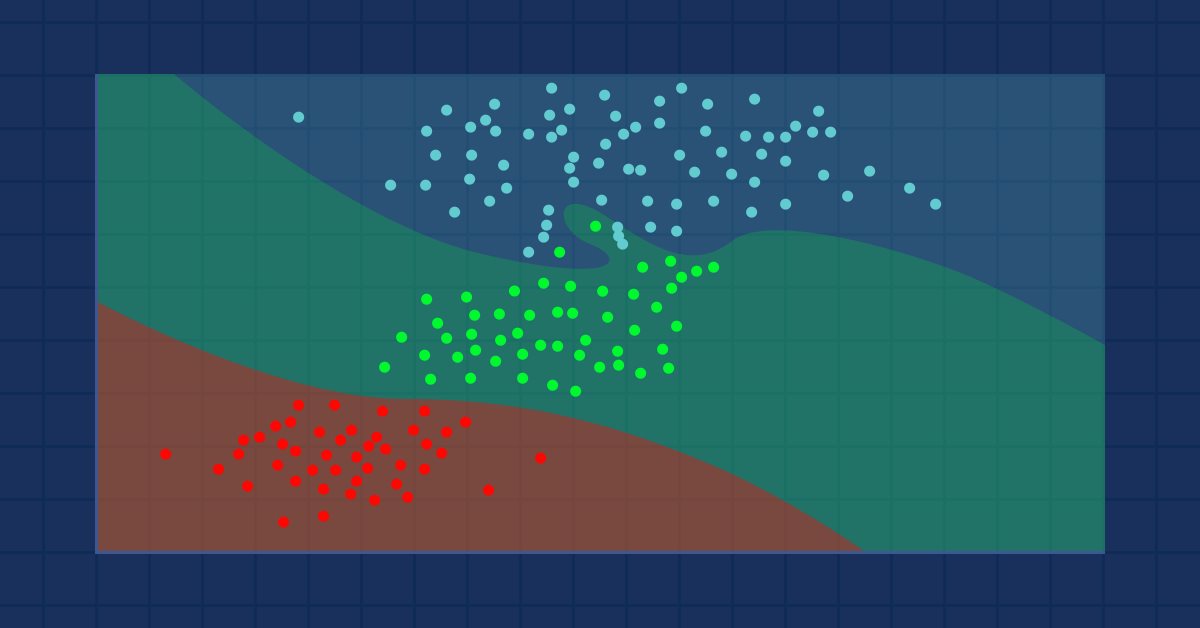
数据科学与机器学习(第 09 部分):K-最近邻算法(KNN)
这是一种惰性算法,它不是基于训练数据集学习,而是以存储数据集替代,并在给定新样本时立即采取行动。 尽管它很简单,但它能用于各种实际应用。
用于预测波动性的计量经济学工具:GARCH模型
文章描述了条件异方差非线性模型(GARCH)的特性。在GARCH模型的基础上,构建了iGARCH指标来预测未来一步的波动性。该模型参数的估计使用了ALGLIB数值分析库。
DoEasy 函数库中的时间序列(第四十四部分):指标缓冲区对象类集合
本文介绍如何创建指标缓冲区对象类的集合。 我计划测试为指标创建和操控任意数量缓冲区的能力(在 MQL 指标中可以创建的最大缓冲区数量为 512)。


使用凯利准则与蒙特卡洛模拟的投资组合风险模型
几十年来,交易员们一直使用凯利准则公式来确定投资或赌注的最优资本配置比例,其目标是在最大化长期增长的同时,最小化破产风险。然而,对于个人交易者而言,盲目地依据单次回测的结果来遵循凯利准则往往是危险的,因为在实盘交易中,交易优势会随着时间的推移而减弱,并且过往业绩并不能保证未来的结果。在本文中,我将提出一种在 MetaTrader 5 平台中,为一个或多个智能交易系统进行风险分配的现实方法,该方法将融合来自 Python 的蒙特卡洛模拟结果。


神经网络变得轻松(第十八部分):关联规则
作为本系列文章的延续,我们来研究无监督学习方法中的另一类问题:挖掘关联规则。 这种问题类型首先用于零售业,即超市等,来分析市场篮子。 在本文中,我们将讨论这些算法在交易中的适用性。

MQL5 中的范畴论 (第 7 部分):多域、相对域和索引域
范畴论是数学的一个多样化和不断扩展的分支,直到最近才在 MQL5 社区中得到一些报道。 这些系列文章旨在探索和验证一些概念和公理,其总体目标是建立一个开放的函数库,提供洞察力,同时也希望进一步在交易者的策略开发中运用这个非凡的领域。

利用 MQL5 实现 Janus 因子
加里·安德森(Gary Anderson)基于他称之为Janus因子的理论,开发了一套市场分析方法。 该理论描述了一套可揭示趋势和评估市场风险的指标。 在本文中,我们将利用 mql5 实现这些工具。

数据科学和机器学习(第 18 部分):掌握市场复杂性博弈,截断型 SVD 对比 NMF
截断型奇异值分解(SVD)和非负矩阵分解(NMF)都是降维技术。它们在制定数据驱动的交易策略方面都发挥着重要作用。探索降维的艺术,揭示洞察和优化定量分析,以明智的方式航行在错综复杂的金融市场。
数据科学与机器学习(第 07 部分):多项式回归
与线性回归不同,多项式回归是一种很灵活的模型,旨在更好地执行线性回归模型无法处理的任务,我们来找出如何在 MQL5 中制作多项式模型,并据其做出积极东西。
以 MQL5 实现 ARIMA 训练算法
在本文中,我们将实现一种算法,该算法应用了 Box 和 Jenkins 的自回归集成移动平均模型,并采用了函数最小化的 Powells 方法。 Box 和 Jenkins 表示,大多数时间序列可以由两个框架中之一个或两个来建模。

混沌博弈优化(CGO)
本文提出了一种新型元启发式算法——混沌博弈优化算法(CGO),该算法在处理高维问题时展现出独特的保持高效率的能力。与大多数优化算法不同,CGO在问题规模扩大时不仅不会降低性能,有时甚至还会提升性能,这便是其关键特性。

“MQL5 应用商店” 2013 年一季度业绩
自创立以来,销售自动交易与技术指标的“MQL5 应用商店”已经吸引来了 250 多位开发者,他们发布了 580 款产品。对于那些已通过销售自己的产品获得丰厚利润的“MQL5 应用商店”卖家来讲,2013 年第一季度是相当成功的。

时间序列挖掘的数据标签(第2部分):使用Python制作带有趋势标记的数据集
本系列文章介绍了几种时间序列标记方法,这些方法可以创建符合大多数人工智能模型的数据,而根据需要进行有针对性的数据标记可以使训练后的人工智能模型更符合预期设计,提高我们模型的准确性,甚至帮助模型实现质的飞跃!

群体优化算法:粒子群(PSO)
在本文中,我将研究流行的粒子群优化(PSO)算法。 之前,我们曾讨论过优化算法的重要特征,如收敛性、收敛率、稳定性、可伸缩性,并开发了一个测试台,并研究了最简单的 RNG 算法。
改编版 MQL5 网格对冲 EA(第 III 部分):优化简单对冲策略(I)
在第三部分中,我们重新审视了早前开发的简单对冲和简单网格智能系统(EA)。我们的重点转移到通过数学分析和蛮力方式完善简单对冲 EA,旨在实现最优策略用法。本文深入探讨了该策略的数学优化,为在日后文章中探索未来基于编码的优化奠定了基础。
