
神经网络变得轻松(第三十九部分):Go-Explore,一种不同的探索方式

概述
我们继续强化学习中的环境探索主题。 在本系列的前几篇文章中,我们已经见识了经由融汇模型中的好奇心和分歧来探索环境的算法。 这两种方式都利用内在奖励来激励代理者在探索新领域的类似状况时采取不同的行动。 但问题在于,随着环境得到更好的探索,内在奖励会减少。 在奖励越发稀少的复杂情况下,或者当代理者可能在获得奖励的途中受到惩罚时,这种方式可能不是很奏效。 在这篇文章中,我提议来熟悉一种稍微不同的环境研究方法 — Go-Explore 算法。
1. Go-Explore 算法
Go-Explore 是一种强化学习算法,旨在为具有较大动作和状态空间的复杂问题找到最优解。 该算法由 Adrien Ecoffet 开发,并在文章 Go-Explore:一条艰难探索难题的新途径 中进行了阐述。
他使用进化算法和机器学习技术来有效地为复杂和棘手的问题找到最优解。
该算法首先探索大量随机路径,称为 “基础探索”。 然后,使用进化算法,它存储找到的最佳解,并将它们组合起来,以便创建新的路径。 然后将这些新路径与以前的最佳解进行比较,如果它们更好,则保存它们。 重复此过程,直到找到最优解。
Go-Explore 还使用一种称为“记录器”的技术来保存找到的最佳,并重用它们来创建新路径。 这令该算法能够找到更佳解,而非简单地继续探索随机路径。
Go-Explore 的主要优势之一是它能够在其它强化学习算法可能失败的复杂和棘手的问题中找到最优解。 它还能够在奖励稀缺下有效学习,这对其它算法来说可能是一个挑战。
总体而言,Go-Explore 是解决强化学习问题的强大工具,可以有效地应用于各个领域,包括机器人、电脑游戏、和普遍的人工智能。
Go-Explore 的主要思想是记忆并回归至更有前途的状态。 这是奖励数量有限时有效操作的基础。 这个思路是如此灵活和广泛,以至于可以经由多种途径实现。
与大多数强化学习算法不同,Go-Explore 并不专注于直接解决目标问题,而是专注于在状态空间中寻找可以导致达成目标状态的相关状态和动作。 为了达成这一点,该算法有两个主要阶段:搜索和重用。
第一阶段是遍历状态空间中的所有状态,并将访问的每个状态记录在状态“映射”当中。 此后,该算法开始研究每个所访问状态的细节,并收集有关可能导致其它有趣状态的操作信息。
第二阶段是重用以前学习的状态和操作,寻找新的解。 该算法存储最成功的轨迹,并用它们来生成新的状态,从而产生更成功的解。
Go-Explore 算法的操作如下:
- 收集样本存档:代理者启动游戏,记录每个成就,并将其保存在存档之中。 替代存储状态本身,存档包含导致达成特定状态的操作描述。
- 迭代探索:在每次迭代中,代理者从存档中随机选择一个状态,并从该状态重玩游戏。 它保存它设法实现的任何新状态,并将它们添加到存档当中,并附上导致这些状态的操作描述。
- 基于样本的学习:经过迭代探索后,算法运用某种强化学习算法从其收集到的有你根本中学习。
- 重复:该算法重复迭代探索和基于样本的学习,直到达到所需的性能等级。
Go-Explore 算法的目标是最大限度地减少实现高性能所需的游戏重玩次数。 它允许代理者使用样本数据库探索大型状态空间,从而加快学习过程,并获得更佳的性能。
Go-Explore 是一种强大而高效的算法,在解决复杂的强化学习问题方面表现优异。
2. 利用 MQL5 实现
在我们的实现中,与之前研究的所有算法不同,我们不会将整个算法组合在一个程序里。 Go-Explore 算法的阶段是如此不同,以至于为每个阶段创建一个单独的程序会更有效。
2.1. 第一阶段:探索
首先,我们创建一个程序来实现第一阶段的算法,即探索环境,并收集样本存档。 在开始实现之前,我们需要检测正在构建算法的基础。
当开始研究环境时,我们需要尽可能充分地探索它的所有状态。 在这个阶段,我们没有设定寻找最优策略的目标。 虽然看起来也许很奇怪,但我们不会在此刻用到神经网络,因为我们不是在寻找策略或优化策略。 这将是第二阶段的任务。 在这个阶段,我们简单地让若干个代理者执行随机操作,并记录每个代理者将访问的所有系统状态。
但以这种方式,我们得到了一堆随机的不相关状态。 那有关环境探索呢? 如果每个代理者只从每种状态执行一个动作,而不学习其它动作的积极和消极方面,这有什么帮助? 这就是为什么我们需要算法的第二步。 随机或采用一些预定义的政策,我们从存档中选择状态。 重复所有步骤,直到达到此状态。 然后我们再次随机检测代理者的行动,直至到达正在探索的剧集的结尾。 我们还要把新状态添加到样本存档之中。
算法的这两个步骤构成了第一阶段 — 探索。
请注意还有一点。 为了有效研究,我们需要用到若干位代理者。 在此,为了让多位独立的代理者并行运营,我们将利用策略测试器的多线程优化器。 基于每次验算的结果,代理者会将其累积的状态存档传送到一个单一中心进行归纳。
明确了算法的要点后,我们可以继续实现它。 我们的工作始自创建一个记录状态和达成该状态路径的结构。 在此,我们遇到了第一个限制:为了传递每次迭代的结果,策略测试器允许您使用任何类型的数组。 但它不应包含使用字符串值和动态数组的复杂结构。 这意味着我们不能使用动态数组来描述系统的路径和状态。 我们需要立即判定它们的维度。 为了在程序组织中提供灵活性,我们将主要值输出到常量。 在这些常量中,我们将判定所分析历史的深度(以柱线(HistoryBars)为单位)和路径缓冲区的大小(Buffer_Size)。 您可以用自己的值来适配您的特定问题。
#define HistoryBars 20 #define Buffer_Size 600 #define FileName "GoExploer"
此外,我们将立即指明记录样本的存档文件名。
数据将以 Cell 结构格式记录。 我们在结构中创建两个数组:一个整数型数组,用于写入状态实现路径 — 动作;第二个是实数型数组,用于记录所实现状态的描述 — 状态。 由于我们必须使用静态数据数组,我们将引入 total_actions 变量来指示由代理者所创建路径的大小。 此外,我们将添加一个实数型变量值,来记录状态权重值。 它作为后续探索的优先状态选择。
//+------------------------------------------------------------------+ //| Cell | //+------------------------------------------------------------------+ struct Cell { int actions[Buffer_Size]; float state[HistoryBars * 12 + 9]; int total_actions; float value; //--- Cell(void); //--- bool Save(int file_handle); bool Load(int file_handle); };
我们在结构的构造函数中初始化所创建的变量和数组。 创建结构时,我们用数值 “-1” 填充路径数组。 我们还用零值填充状态数组和变量。
Cell::Cell(void) { ArrayInitialize(actions, -1); ArrayInitialize(state, 0); value = 0; total_actions = 0; }
应该记住,我们会将收集到的状态保存到一个样本存档文件之中。 因此,我们需要创建操控文件的方法。 数据保存方法基于我们已经熟悉的算法。 我们不止一次用到为所创建类记录数据。
该方法接收记录数据的文件句柄作为参数。 我们需立即检查其值。 如果收到不正确的句柄,则终止该方法,并返回 “false” 结果。
成功通过管控模块后,我们会在文件中写入 “999” 来标识我们的结构。 此后,我们将保存变量和数组的数值。 为了确保以后能正确读取数组,在写入数组数据之前,我们需要指定数组维度。 为了节省磁盘空间,我们只保存实际的路径数据,而不是整个 “actions” 数组。 鉴于我们已经保存了 total_actions 变量值,我们就可跳过为此数组指定尺寸。 在保存 'state' 数组时,我们首先指定数组的尺寸,然后再保存其内容。 确保控制每个操作的过程。 成功保存所有数据后,我们完成该方法,并返回 “true” 结果。
bool Cell::Save(int file_handle) { if(file_handle <= 0) return false; if(FileWriteInteger(file_handle, 999) < INT_VALUE) return false; if(FileWriteFloat(file_handle, value) < sizeof(float)) return false; if(FileWriteInteger(file_handle, total_actions) < INT_VALUE) return false; for(int i = 0; i < total_actions; i++) if(FileWriteInteger(file_handle, actions[i]) < INT_VALUE) return false; int size = ArraySize(state); if(FileWriteInteger(file_handle, size) < INT_VALUE) return false; for(int i = 0; i < size; i++) if(FileWriteFloat(file_handle, state[i]) < sizeof(float)) return false; //--- return true; }
从文件中读取数据的 “Load” 方法构造类似。 它执行数据读取操作,同时严格维护其写入顺序。 该方法的完整代码可在文后的附件中找到。
在创建了描述系统状态的一个结构,及达成的方法之后,我们移步到创建一个智能系统来实现 Go-Explore 算法的第一阶段。 我们称该智能系统为 Faza1.mq5。 虽然我们会在不分析市场状况的情况下执行随机动作,但我们仍然会使用指标来描述系统的状态。 因此,我们将从以前的智能系统中转移它们的参数。 外部 “Start” 变量指示来自样本存档的状态。 我们稍后再说它。
input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input int Start = 100; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price bool TrainMode = true;
指定外部参数后,我们将创建全局变量。 在此,我们创建了 2 个描述系统状态的结构数组。 第一个(Base)记录当前验算的状态。 第二个(Total)记录完整的样本存档。
于此,我们还声明了执行交易操作和加载历史数据的对象。 它们与之前所用的完全相似。
对于当前算法,我们将创建以下内容:
- action_count — 动作计数器;
- actions — 记录时段期间执行的动作的数组;
- StartCell — 开始探索的状态描述结构;
- bar — 自启动智能系统以来的柱线计数器。
Cell Base[Buffer_Size]; Cell Total[]; CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- int action_count = 0; int actions[Buffer_Size]; Cell StartCell; int bar = -1;
在 OnInit 函数中,我们首先初始化指标和交易操作对象。 此功能与前面讨论过的 EA 完全相同。
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
然后,我们尝试加载样本存档,其可能先于 EA 操作就已创建完毕。 这两个选项此刻都是可以接受的。 如果我们设法加载样本存档,那么我们尝试从中读取拥有外部 “Start” 变量中指定索引的元素。 如果没有这样的元素,我们取一个随机元素,并将其复制到 “StartCell” 结构之中。 这是我们探索的起点。 如果没有加载样本数据库,那么我们就从头开始研究。
//--- if(LoadTotalBase()) { int total = ArraySize(Total); if(total > Start) StartCell = Total[Start]; else { total = (int)(((double)MathRand() / 32768.0) * (total - 1)); StartCell = Total[total]; } } //--- return(INIT_SUCCEEDED); }
我使用如此广泛的系统来创建一个探索起点,是为了能够在不更改 EA 代码的情况下组织各种场景。
完成所有操作后,我们终止 EA 初始化函数,返回结果 INIT_SUCCEEDED。
为了加载样本存档,我们用到了 LoadTotalBase 函数。 为了完成对初始化过程的描述,我们来研它的算法。 该函数没有参数。 代之,我们会用之前定义的文件名常量 FileName。
请注意,该文件在算法的第一、第二阶段都会用到。 这就是我们在状态描述结构文件中声明 FileName 常量的原因。
在函数的主体中,我们首先打开欲读取数据的文件,并根据句柄值检查操作结果。
当文件成功打开时,我们读取样本存档中的元素数量。 我们更改数组的尺寸,以便保存数据,并实现一个循环从文件中读取数据。 为了读取每个单独的结构,我们要调用之前创建的系统状态存储结构的 “Load” 方法。
在每次迭代中,我们控制操作过程。 退出函数之前,无论处于何种选项,请务必关闭之前打开的文件。
bool LoadTotalBase(void) { int handle = FileOpen(FileName + ".bd", FILE_READ | FILE_BIN | FILE_COMMON); if(handle < 0) return false; int total = FileReadInteger(handle); if(total <= 0) { FileClose(handle); return false; } if(ArrayResize(Total, total) < total) { FileClose(handle); return false; } for(int i = 0; i < total; i++) if(!Total[i].Load(handle)) { FileClose(handle); return false; } FileClose(handle); //--- return true; }
创建 EA 初始化算法后,我们移步到 OnTick 跳价处理方法。 当 EA 所在图表上产生新的跳价事件时,终端会调用该方法。 我们只需要处理新的烛条开盘事件。 为了实现这种控制,我们调用 IsNewBar 函数。 它完全是从以前的 EA 复制而来的,所以我们无需在此讨论它的算法。
void OnTick() { //--- if(!IsNewBar()) return;
接下来,我们增加 EA 开始的步数计数器,并将其值与探索开始前的步数进行比较。 如果我们还没有达到探索开始的状态,那么我们从通往目标状态的路径里取下一个动作,并执行它。 之后,我们等待新烛条的开盘。
bar++; if(bar < StartCell.total_actions) { switch(StartCell.actions[bar]) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; } return; }
在达到探索开始状态后,我们将之前的路径复制到当前代理者的动作数组之中。
if(bar == StartCell.total_actions) ArrayCopy(actions, StartCell.actions, 0, 0, StartCell.total_actions);
随后,我们更新指标的历史数据。
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
之后,我们创建一个系统状态当前描述的数组。 在此文件中,我们将记录指标和价格数值的历史数据,以及有关账户状态和持仓的信息。
float state[249]; MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- state[b * 12] = (float)Rates[b].close - open; state[b * 12 + 1] = (float)Rates[b].high - open; state[b * 12 + 2] = (float)Rates[b].low - open; state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; state[b * 12 + 4] = (float)sTime.hour; state[b * 12 + 5] = (float)sTime.day_of_week; state[b * 12 + 6] = (float)sTime.mon; state[b * 12 + 7] = rsi; state[b * 12 + 8] = cci; state[b * 12 + 9] = atr; state[b * 12 + 10] = macd; state[b * 12 + 11] = sign; } //--- state[240] = (float)AccountInfoDouble(ACCOUNT_BALANCE); state[240 + 1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); state[240 + 2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); state[240 + 3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); state[240 + 4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } state[240 + 5] = (float)buy_value; state[240 + 6] = (float)sell_value; state[240 + 7] = (float)buy_profit; state[240 + 8] = (float)sell_profit;
之后,我们执行随机动作。
//--- int act = SampleAction(4); switch(act) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; }
我们将当前状态保存到当前代理者的已访问状态数组当中。
请注意,作为到当前状态的步数,我们指明至探索开始处的总状态步数,和已探索的随机步数。 我们在开始探索之前就已保存了状态,因其已经保存在我们的样本存档之中。 与此同时,我们需要存储通往每个状态的完整路径。
作为状态值,我们将指示账户净值变化的倒数。 我们将以此为指南,为探索优选状态。 优选的目的是查找通往损失最低的步骤。 这会潜在提升整体盈利。 此外,我们稍后可在 Go-Explore 算法的第二阶段训练策略时使用该值的倒数作为奖励。
//--- copy cell actions[action_count] = act; Base[action_count].total_actions = action_count+StartCell.total_actions; if(action_count > 0) { ArrayCopy(Base[action_count].actions, actions, 0, 0, Base[action_count].total_actions+1); Base[action_count - 1].value = Base[action_count - 1].state[241] - state[241]; } ArrayCopy(Base[action_count].state, state, 0, 0); //--- action_count++; }
在保存了有关当前状态的数据后,我们增加计步器,并继续等待下一根烛条。
我们已构建出一个代理者算法来探索环境。 现在,我们需要把从所有代理者收集数据的过程组织到单个样本存档之中。 为此,在测试完成后,每位代理者都必须将收集到的数据发送到归纳中心。 我们在 OnTester 方法中组织该功能。 策略测试器在每次验算完成后调用它。
我决定只保留盈利验算。 这将大大减少样本存档的尺寸,并加快学习过程。 如果您想以尽可能高的精度训练策略,并且您不受资源限制,则可以保存所有验算。 这将有助于您的策略更好地探索环境。
我们首先检查验算的盈利能力。 如有必要,我们调用 FrameAdd 函数发送数据。
//+------------------------------------------------------------------+ //| Tester function | //+------------------------------------------------------------------+ double OnTester() { //--- double ret = 0.0; //--- double profit = TesterStatistics(STAT_PROFIT); action_count--; if(profit > 0) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), action_count, profit, Base); //--- return(ret); }
请注意,在发送之前,我们会将步数减 1,因为我们尚不知道最后一个动作的结果。
为了把收集数据的过程组织到一个通用的样本存档中,我们将用到 3 个函数。 首先,在初始化优化过程时,我们加载样本存档(如果之前已创建)。 此操作在 OnTesterInit 函数中完成。
//+------------------------------------------------------------------+ //| TesterInit function | //+------------------------------------------------------------------+ void OnTesterInit() { //--- LoadTotalBase(); }
然后,我们在 OnTesterPass 函数中处理每次验算。 在此,我们实现了从所有可用帧中收集数据,并将它们添加到通用样本存档的数组当中。 FrameNext 函数读取下一帧。 如果数据加载成功,则返回 true。 但如果读取帧数据时出错,它将返回 false。 依据该属性,我们可以组织一个循环来读取数据,并将其添加到我们的通用数组当中。
//+------------------------------------------------------------------+ //| TesterPass function | //+------------------------------------------------------------------+ void OnTesterPass() { //--- ulong pass; string name; long id; double value; Cell array[]; while(FrameNext(pass, name, id, value, array)) { int total = ArraySize(Total); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue; if(ArrayResize(Total, total + (int)id, 10000) < 0) return; ArrayCopy(Total, array, total, 0, (int)id); } }
在优化过程结束时,将调用 OnTesterDeinit 函数。 在此,我们首先按状态描述的“值”对数据库进行降序排序。 这令我们将最大损失的元素移到数组的开头。
//+------------------------------------------------------------------+ //| TesterDeinit function | //+------------------------------------------------------------------+ void OnTesterDeinit() { //--- bool flag = false; int total = ArraySize(Total); printf("total %d", total); Cell temp; Print("Start sorting..."); do { flag = false; for(int i = 0; i < (total - 1); i++) if(Total[i].value < Total[i + 1].value) { temp = Total[i]; Total[i] = Total[i + 1]; Total[i + 1] = temp; flag = true; } } while(flag); Print("Saving..."); SaveTotalBase(); Print("Saved"); }
之后,我们调用 SaveTotalBase 方法将样本存档保存到文件中。 它的算法类似于上面讨论的 LoadTotalBase 方法。 附件中提供了所有函数的完整代码。
我们在第一阶段 EA 上的工作到此结束。 编译它,并转到策略测试器。 选择 Faza1.ex5 EA、一个品种、一个测试周期(在我们的例子中是训练)、带有所有选项的慢速优化。
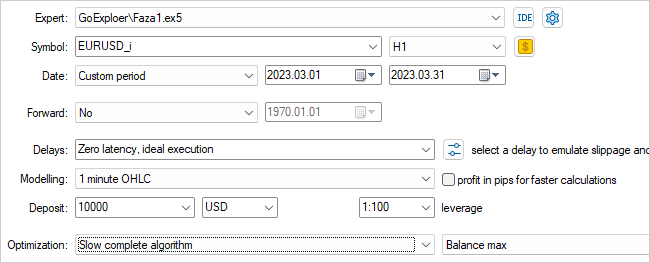
EA 将针对一个参数进行优化 – Start。 它用于检测正在运行的代理者的数量。 在初始阶段,我以少量代理者启动了 EA。 这为我们提供了创建初始样本存档的快速通道。
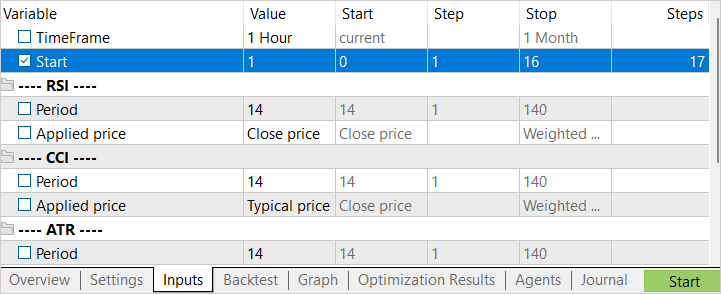
在完成第一阶段的优化后,我们增加了测试代理者的数量。 在此,下一次启动我们可有 2 种方式。 如果我们想尝试在最无盈利可能的状态下找到最佳动作,那么 Start 参数的优化间隔应该从 “0” 开始表示。 为了选择随机状态,我们特意为参数优化设置了一个较大的初始值,作为探索的起点。 该参数的最终优化值取决于要启动的代理者数量。 “步数” 列中的值对应于在优化(训练)过程中启动的代理者数量。
2.2. 第二阶段:依据样本训练策略
正当我们的第一款 EA 努力创建一个样本数据库之时,我们也转移到第二阶段 EA 的工作。
在我的实现中,我稍微偏离了本文作者提出的第 2 阶段的政策训练过程。 文章提出了使用模拟方法来训练策略。 这用到了一种改进的强化学习算法方法。 在单独的部分中,对代理者进行训练,以重复样本存档中成功策略的动作,然后再应用标准的强化学习方法。 在第一阶段,“教师” 部分展现出最大值。 代理者必须得到不差于 “教师” 的结果。 随着训练的进行,“教师” 间隔会递减。 代理者必须学习优化“教师”的策略。
在我的实现中,我把这个阶段又切分为 2 个阶段。 在第一阶段,我们以类似于监督学习过程的方式训练代理者。 不过,我们并未指定正确的动作。 取而代之,我们会调整预测奖励值。 在这个阶段,我们创建 Faza2.mq5 EA。
在 EA 代码中,我们添加了一个描述系统状态的元素,和一个完全参数化的 FQF 模型类。
//+------------------------------------------------------------------+ //| Includes | //+------------------------------------------------------------------+ #include "Cell.mqh" #include "..\RL\FQF.mqh" //+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 100000;
它有最少的外部参数。 我们只需指示模型训练迭代的次数。
在全局参数中,我们声明了一个模型类、一个状态描述对象、和一个奖励数组。 我们还需要声明一个数组来加载样本存档。
CNet StudyNet; //--- float dError; datetime dtStudied; bool bEventStudy; //--- CBufferFloat State1; CBufferFloat *Rewards; Cell Base[];
在 EA 初始化方法中,我们首先加载样本存档。 在这种情况下,这是关键点之一。 如果加载样本存档时出错,我们将没有源数据来训练模型。 因此,如果出现加载错误,我们会终止函数,并返回 INIT_FAILED 结果。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!LoadTotalBase()) return(INIT_FAILED); //--- if(!StudyNet.Load(FileName + ".nnw", dError, dError, dError, dtStudied, true)) { CArrayObj *model = new CArrayObj(); if(!CreateDescriptions(model)) { delete model; return INIT_FAILED; } if(!StudyNet.Create(model)) { delete model; return INIT_FAILED; } delete model; } if(!StudyNet.TrainMode(true)) return INIT_FAILED; //--- bEventStudy = EventChartCustom(ChartID(), 1, 0, 0, "Init"); //--- return(INIT_SUCCEEDED); }
加载样本存档后,我们初始化模型进行训练。 如往常一样,我们首先尝试加载一个预训练的模型。 如果模型因任何原因无法加载,我们将初始化一个具有随机权重的新创建模型。 模型描述在 CreateDescriptions 函数中指定。
模型初始化成功后,我们创建一个自定义事件来启动模型训练过程。 我们在监督学习中使用了相同的方法。
至此,我们完成了 EA 的初始化函数。
请注意,在此 EA 中,我们没有创建加载历史价格数据和指标的对象。 整个学习过程都是基于样本的。 样本存档存储系统状态的所有描述,包括有关账户和持仓的信息。
我们创建的自定义事件会在 OnChartEvent 函数中进行处理。 此处我们只检查预期事件的发生情况,并调用模型训练函数。
//+------------------------------------------------------------------+ //| ChartEvent function | //+------------------------------------------------------------------+ void OnChartEvent(const int id, const long &lparam, const double &dparam, const string &sparam) { //--- if(id == 1001) Train(); }
真实的模型训练过程是在 Train 函数中实现的。 该函数没有参数。 在函数的主体中,我们首先判定样本存档的尺寸,并将系统启动时的毫秒数保存在局部变量之中。 我们将用该值来定期通知用户模型训练过程的进度。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total = ArraySize(Base); uint ticks = GetTickCount();
经过一些准备工作后,我们组织了一个模型训练循环。 循环迭代次数对应于外部变量的值。 我们还将根据用户要求强制中断循环,并关闭程序。 这可以通过 IsStopped 函数完成。 如果用户关闭程序,则指定的函数将返回 true。
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int i = 0; int count = 0; int total_max = 0; i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 1)); State1.AssignArray(Base[i].state); if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; }
在循环体中,我们从存档中随机选择一个样本,并将状态复制到数据缓冲区。 然后我们执行模型的前馈验算。
if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return;
然后,我们从当前样本中提取所执行的动作,查找前馈结果,并更新所执行动作的奖励。
int action = Base[i].total_actions; if(action < 0) { iter--; continue; } action = Base[i].actions[action]; if(action < 0 || action > 3) action = 3; StudyNet.getResults(Rewards); if(!Rewards.Update(action, -Base[i].value)) return;
注意以下两个时刻。 如果样本中没有动作(选择初始状态),则我们递减迭代计数器,并选择一个新样本。 在更新奖励时,我们取带有相反符号的值。 还记得吗? 在保存状态时,我们做了一个正值来减少净值。 而这次是一个负值点。
更新奖励后,我们执行反向验算,并更新权重。
if(!StudyNet.backProp(GetPointer(Rewards))) return; if(GetTickCount() - ticks > 500) { Comment(StringFormat("%.2f%% -> Error %.8f", iter * 100.0 / (double)(Iterations), StudyNet.getRecentAverageError())); ticks = GetTickCount(); } }
在循环迭代结束时,我们检查是否需要为用户更新学习过程信息。 在此示例中,我们每 0.5 秒更新一次图表注释字段。
直至循环体中的操作完成,我们移到来自数据库中的新样本。
完成循环的所有迭代后,我们清除注释字段。 我们将信息输出到日志中,并着手关闭 EA。
Comment(""); //--- PrintFormat("%s -> %d -> %10.7f", __FUNCTION__, __LINE__, StudyNet.getRecentAverageError()); ExpertRemove(); //--- }
关闭 EA 时,我们在其逆初始化方法中删除用到的动态对象,并将训练好的模型保存到磁盘上。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!!Rewards) delete Rewards; //--- StudyNet.Save(FileName + ".nnw", 0, 0, 0, 0, true); }
第一阶段 EA 收集样本存档完毕后,我们只需要在图表上运行第二阶段 EA,模型训练过程就会开始。 请注意,与第一阶段 EA 不同,我们不会在策略测试器中运行第二阶段 EA,而是将其加载到真实图表上。 在 EA 参数中,我们指示学习过程循环的迭代次数,并监控该过程。
为了获得最优结果,可以重复第一阶段和第二阶段的迭代。 在这种情况下,可以先重复第一阶段 N 遍,然后重复第二阶段 M 遍。 或者,您可以多次重复第一阶段 + 第二阶段迭代的循环。
为了优调策略,我们用到第三个 EA GE-learning.mq5。 它实现了经典的强化学习算法。 我们现在不再详细讨论 EA 的所有功能。 其完整代码可在附件中找到。 我们只考虑跳价处理函数 OnTick。
与第一阶段 EA 一样,我们只处理新的烛条开盘事件。 如果没有,我们只需等待合适的时机,然后完成功能即可。
当新烛条开盘事件发生时,我们首先将最后状态、采取的动作、和净值变化保存到体验回放缓冲区之中。 我们将净值指标重写到一个全局变量,以便跟踪下一根烛条的变化。
void OnTick() { if(!IsNewBar()) return; //--- float current = (float)AccountInfoDouble(ACCOUNT_EQUITY); if(Equity >= 0 && State1.Total() == (HistoryBars * 12 + 9)) cReplay.AddState(GetPointer(State1), Action, (double)(current - Equity)); Equity = current;
然后,我们更新价格值和指标的历史记录。
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
形成系统当前状态的描述。 在此,您需要精心确保生成的系统状态描述与第一阶段 EA 中的类似过程完全对应。 因为操作和优调应该在基于训练样本数据相当的数据上进行。
State1.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[b].close - open) || !State1.Add((float)Rates[b].high - open) || !State1.Add((float)Rates[b].low - open) || !State1.Add((float)Rates[b].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } //--- if(!State1.Add((float)AccountInfoDouble(ACCOUNT_BALANCE)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_EQUITY)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_MARGIN_FREE)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL)) || !State1.Add((float)AccountInfoDouble(ACCOUNT_PROFIT))) return; //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); return; } } if(!State1.Add((float)buy_value) || !State1.Add((float)sell_value) || !State1.Add((float)buy_profit) || !State1.Add((float)sell_profit)) return;
之后,执行前馈验算。 根据前馈验算的结果,我们判定并执行对应动作。
if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return; Action = StudyNet.getAction(); switch(Action) { case 0: Trade.Buy(Symb.LotsMin(), Symb.Name()); break; case 1: Trade.Sell(Symb.LotsMin(), Symb.Name()); break; case 2: for(int i = PositionsTotal() - 1; i >= 0; i--) if(PositionGetSymbol(i) == Symb.Name()) Trade.PositionClose(PositionGetInteger(POSITION_IDENTIFIER)); break; }
请注意,在这种情况下,我们不使用任何探索政策。 我们严格遵循学习政策。
在跳价处理函数结束时,我们检查时间。 每天一次,于午夜,我们用体验重播缓冲区来更新代理者的策略。
MqlDateTime time; TimeCurrent(time); if(time.hour == 0) { int repl_action; double repl_reward; for(int i = 0; i < 10; i++) { if(cReplay.GetRendomState(pstate1, repl_action, repl_reward, pstate2)) return; if(!StudyNet.feedForward(pstate1, 12, true)) return; StudyNet.getResults(Rewards); if(!Rewards.Update(repl_action, (float)repl_reward)) return; if(!StudyNet.backProp(GetPointer(Rewards), DiscountFactor, pstate2, 12, true)) return; } } //--- }
所有 EA 的完整代码都可以在附件中找到。
3. 测试
所有三个 EA 都按照 Go-Explore 算法依次进行了测试:
- 在策略测试器的优化模式下连续多次启动第一阶段 EA,来创建样本存档。
- 第二阶段 EA 的策略迭代训练若干次。
- 采用强化学习算法在策略测试器中进行最终优调。
如同整个系列文章一样,所有测试都是依据 EURUSD 的历史数据进行的,时间帧 H1。 采用指标默认参数,无需进行任何调整。
测试产生了相当不错的结果,如下面的屏幕截图所示。


此处,我们看到一个相当均匀的余额增长图。 测试数据的盈利因子为 6.0,恢复因子为 3.34。 在 30 笔所执行交易中,有 22 笔盈利,占比 73.3%。 交易的平均盈利是平均亏损的 2 倍以上。 每笔交易的最大盈利是最大亏损的 3.5 倍。
请注意,EA 只执行买入交易,并平仓时没有大幅回撤。 缺少卖出交易的原因是需要进一步研究的主题。
测试结果是有前途的,但它们是在很短的时间段内获得的。 为了确认算法的结果,需要在更长的时间段内进行额外的实验。
结束语
在本文中,我们介绍了 Go-Explore 算法,这是一种解决复杂强化学习问题的新方式。 它的思路基于记忆和重新访问状态空间中有前途的状态,从而更快地达成期望的性能。 Go-Explore 与其它算法的主要区别在于,它专注于查找相关状态和动作,而不是直接解决目标问题。
我们按运行顺序构建了三个智能交易。 它们中的每一个都执行自己的算法功能,来达成政策学习的共同目标。 这里的政策是指交易策略。
该算法依据历史数据进行测试,并展示出最佳结果之一。 不过,结果是在策略测试器中的较短时间段内达成的。 因此,在真实账户上使用 EA 之前,需要在更长、更具代表性的时间段内进行更全面的测试和模型训练。
参考
- Go-Explore:解决艰难探索难题的新途径
- 神经网络变得轻松(第三十五部分):内在好奇心模块
- 神经网络变得轻松(第三十六部分):关系强化学习
- 神经网络变得轻松(第三十七部分):分散关注度
- 神经网络变得轻松(第三十八部分):凭借分歧进行自我监督探索
本文中用到的程序
| # | 发行 | 类型 | 说明 |
|---|---|---|---|
| 1 | Faza1.mq5 | 智能交易系统 | 第一阶段智能系统 |
| 2 | Faza2.mql5 | 智能交易系统 | 第二阶段智能系统 |
| 3 | GE-lerning.mq5 | 智能交易系统 | 政策微调后的智能系统 |
| 4 | Cell.mqh | 类库 | 系统状态结构的说明 |
| 5 | FQF.mqh | 类库 | 组织完全参数化模型工作的类库 |
| 6 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 7 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/12558
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

我遇到了这个错误。
2023.05.07 20:04:44.281 Core 01 pass 359 tested with error "critical runtime error 502 in OnTester function(array out of range, module Experts\GoExploer\Faza1.ex5, file Faza1.mq5, line 223, col 12)" in 0:00:00.202
//--- 复制单元格
actions[action_count] = act;
Base[action_count].total_actions = action_count+StartCell.total_actions;
如何解决?
如果误差持续增长,请尝试降低训练系数。
我遇到了这个错误。
2023.05.07 20:04:44.281 Core 01 pass 359 tested with error "critical runtime error 502 in OnTester function (array out of range, module Experts\GoExploer\Faza1.ex5, file Faza1.mq5, line 223, col 12)" in 0:00:00.202
//--- 复制单元格
actions[action_count] = act;
Base[action_count].total_actions = action_count+StartCell.total_actions;
如何解决?
学习时间是多久?
学习时间是多久?
上半年数据,从 2023 年 4 月 1 日至 2023 年 4 月 30 日