
掌握ONNX:MQL5交易者的游戏规则改变者

“以ONNX格式导出和导入人工智能模型的能力简化了开发过程,在将人工智能集成到不同的语言生态系统中时节省了时间和资源。”
概述
不可否认,我们正处于人工智能和机器学习的时代,每天都有一种新的基于人工智能的技术部署在金融、艺术和游戏、教育以及生活的更多方面。
对我们这些交易员来说,学习利用人工智能的力量可以让我们在市场上占据优势,让我们检测到肉眼看不到的模式和关系。
尽管人工智能看起来很酷很神奇,但在这些模型背后,有一些复杂的数学运算,如果你要从头开始实现这些机器学习模型,需要大量的工作、高度的准确性和专注力才能正确地计算和实现,而这要归功于开源。
如今,你甚至不需要是数学和编程天才就可以构建和实现人工智能模型。你需要对你想在项目中使用的某种编程语言或工具有一个基本的了解,在某些情况下,你甚至不用拥有电脑,这要归功于Google Colab等服务,你可以使用python免费编写、构建和运行人工智能模型的代码。
尽管使用Python和其他流行且成熟的编程语言实现机器学习模型很容易,但老实说,在MQL5中实现它并不容易。除非你想通过在MQL5中从头开始创建机器学习模型来重新发明轮子——这是我们在系列文章中所做的事情——否则我强烈建议使用ONNX将python中构建的人工智能模型集成到MQL5。ONNX现在在MQL5中得到支持,我很兴奋,我相信你也应该这样做。

什么是ONNX?
ONNX代表开放神经网络交换(Open Neural Network Exchange),是一种用于表示机器学习和深度学习模型的开源格式。它允许您将在一个深度学习框架中训练的模型转换为可在其他框架中使用的通用格式,从而更容易在不同平台和工具中使用模型。
这意味着您可以使用MQL5以外的任何支持机器学习的语言构建机器学习模型,然后将该模型转换为ONNX格式,然后可以在MQL5程序中使用该ONNX模型。
在这篇文章中,我将使用Python来构建机器学习,因为我很熟悉它,我被告知你也可以使用其他语言,我不确定。顺便说一句,整个ONNX文档似乎是基于Python的,我相信目前ONNX是为Python而设计的,这是有道理的,因为我认为除了Python之外,没有任何语言具有高级的基于AI的库和工具。
ONNX的基本概念:
在深入研究ONNX之前,您应该熟悉一些关键概念:
- ONNX模型:ONNX模型是机器学习模型的表现形式,它由一个计算图组成,其中节点表示运算(例如卷积、加法),边表示运算之间的数据流。
- Nodes:ONNX图中的节点(Node)表示应用于输入数据的操作或函数。这些节点可以是卷积、加法或自定义操作等操作。
- Tensors:张量(Tensor)是表示计算图中节点之间流动的数据的多维数组。它们可以是输入、输出或中间数据。
- Operators:运算符(Operators)是应用于ONNX中张量的函数。每个运算符表示一个特定的运算,如矩阵乘法或逐元素加法。
用Python构建模型并使用ONNX在MQL5中部署
要在Python中成功构建机器学习模型,请在MQL5中的EA、指标或脚本中部署该模型;它需要的不仅仅是模型的Python代码,下面是要遵循的关键步骤,这样你不仅可以得到ONNX模型,还可以得到一个可以给出你想要的准确预测的模型;
- 数据收集
- MQL5侧的数据规范化
- 用Python构建模型
- 在MQL5中获取已构建的ONNX模型
- 实时运行模型
01:数据收集
数据收集是MQL5程序中必须完成的第一件事,我认为最好在MQL5计划中收集所有数据,以与我们收集训练数据和实时交易或实时运行模型期间使用的数据的方式一致。请记住,数据收集可能会因您试图解决的问题的性质而异。在本文中,我们将试图解决回归问题。我们将使用OHLC(开盘价、最高价、最低价、收盘价)市场信息作为我们的主要数据集,其中开盘价(Open)、最高价(High)和最低价(Low)将用作自变量,而收盘价(Close)价格值将用作目标变量。
在 ONNX get data.mq5 文件内
matrixf GetTrainData(uint start, uint total) { matrixf return_matrix(total, 3); ulong last_col; OPEN.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_LOW, start, total); CLOSE.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); x_vars = "OPEN,HIGH,LOW"; return_matrix.Resize(total, 4); //if we are collecting the train data collect the target variable also last_col = return_matrix.Cols()-1; //Column located at the last index is the last column return_matrix.Col(CLOSE, last_col); //put the close price information in the last column of a matrix csv_name_ +=".targ=CLOSE"; csv_header = x_vars + ",CLOSE"; if (!WriteCsv("ONNX Datafolder\\"+csv_name_+".csv", return_matrix, csv_header)) Print("Failed to Write to a csv file"); else Print("Data saved to a csv file successfully"); return return_matrix; }
该函数的作用是收集自变量OHL和目标变量CLOSE。在有监督的机器学习中,需要指定目标变量并将其提供给模型,以便它能够在此基础上学习并理解目标变量和其他变量之间的模式,在我们的例子中,模型将试图了解这些指标读数是如何导致上涨或下跌的。
在部署模型时,我们需要以相同的方式收集数据,只是这次我们将在没有目标变量的情况下进行收集,因为这是我们希望经过训练的模型能够解决的问题。可以说是预测。
这就是为什么有一个名为GetLiveData的不同函数,用于加载新数据,以便在市场上进行流畅的预测。
在 ONNX mt5.mq5 文件中
matrixf GetLiveData(uint start, uint total) { matrixf return_matrix(total, 3); OPEN.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_LOW, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); return return_matrix; }
收集训练数据
matrixf dataset = GetTrainData(start_bar, total_bars); Print("Train data\n",dataset);
输出:
DK 0 23:10:54.837 ONNX get data (EURUSD,H1) Train data PR 0 23:10:54.837 ONNX get data (EURUSD,H1) [[1.4243405,1.4130603,1.4215617,1.11194] HF 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3976599,1.3894916,1.4053394,1.11189] RK 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.402994,1.3919021,1.397626,1.11123] PM 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3848507,1.3761013,1.3718294,1.11022] FF 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3597701,1.3447646,1.3545419,1.1097701] CH 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3461626,1.3522644,1.3433729,1.1106] NL 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3683074,1.3525325,1.3582669,1.10996]
获取实时数据
获取当前柱的OHL信息。
matrixf live_data = GetLiveData(0,1); Print("Live data\n",live_data);
输出:
MN 0 23:15:47.167 ONNX mt5 (EURUSD,H1) Live data KS 0 23:15:47.167 ONNX mt5 (EURUSD,H1) [[-0.21183228,-0.23540309,-0.20334835]]
error 2023.09.18 18:03:53.212 ONNX: invalid parameter size, expected 1044480 bytes instead of 32640
02:MQL5侧的数据规范化
对于机器学习模型将要使用的数据集,数据规范化是最关键的事情之一。
请记住,用于准备训练数据的规范化技术需要与用于准备测试和实时数据的技术相同。这意味着,如果所使用的技术是MinMaxScaler,则必须使用在准备训练数据时使用的min和max值来保持将由模型在其他地方处理的新数据的标准化。为了实现这种一致性,我们必须将每个规范化技术的变量保存到csv文件中:
数据规范化仅适用于自变量,无论您试图解决哪种问题,都不必规范化目标变量
我们将使用此处找到的预处理(Preprocessing)类 。
在 ONNX get data.mq5 脚本文件中
//--- Saving the normalization prameters switch(NORM) { case NORM_MEAN_NORM: //--- saving the mean norm_params.Assign(norm_x.mean_norm_scaler.mean); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv",norm_params,x_vars); //--- saving the min norm_params.Assign(norm_x.mean_norm_scaler.min); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.mean_norm_scaler.max); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.max.csv",norm_params,x_vars); break; case NORM_MIN_MAX_SCALER: //--- saving the min norm_params.Assign(norm_x.min_max_scaler.min); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.min_max_scaler.max); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.max.csv",norm_params,x_vars); break; case NORM_STANDARDIZATION: //--- saving the mean norm_params.Assign(norm_x.standardization_scaler.mean); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.mean.csv",norm_params,x_vars); //--- saving the std norm_params.Assign(norm_x.standardization_scaler.std); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.std.csv",norm_params,x_vars); break; }
输出:

当在csv文件中使用 Standardization Scaler 时,参数如下所示;
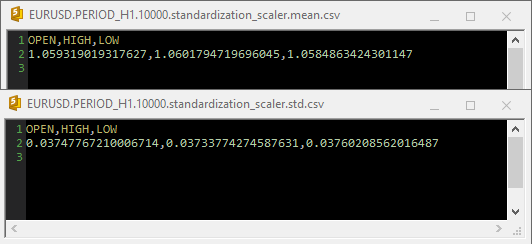
请注意,规范化也集成在GetData函数中,因为规范化非常重要,所以负责收集数据的两个函数返回的每个数据矩阵都必须是具有规范化价格值的矩阵。
在 ONNX get data.mq5 脚本文件中
matrixf GetTrainData(uint start, uint total) { matrixf return_matrix(total, 3); ulong last_col; OPEN.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_LOW, start, total); CLOSE.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); matrixf norm_params = {}; csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); x_vars = "OPEN,HIGH,LOW"; while (CheckPointer(norm_x) != POINTER_INVALID) delete (norm_x); norm_x = new CPreprocessing<vectorf, matrixf>(return_matrix, NORM); //--- Saving the normalization prameters switch(NORM) { case NORM_MEAN_NORM: //--- saving the mean norm_params.Assign(norm_x.mean_norm_scaler.mean); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv",norm_params,x_vars); //--- saving the min norm_params.Assign(norm_x.mean_norm_scaler.min); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.mean_norm_scaler.max); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.max.csv",norm_params,x_vars); break; case NORM_MIN_MAX_SCALER: //--- saving the min norm_params.Assign(norm_x.min_max_scaler.min); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.min_max_scaler.max); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.max.csv",norm_params,x_vars); break; case NORM_STANDARDIZATION: //--- saving the mean norm_params.Assign(norm_x.standardization_scaler.mean); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.mean.csv",norm_params,x_vars); //--- saving the std norm_params.Assign(norm_x.standardization_scaler.std); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.std.csv",norm_params,x_vars); break; } return_matrix.Resize(total, 4); //if we are collecting the train data collect the target variable also last_col = return_matrix.Cols()-1; //Column located at the last index is the last column return_matrix.Col(CLOSE, last_col); //put the close price information in the last column of a matrix csv_name_ +=".targ=CLOSE"; csv_header = x_vars + ",CLOSE"; if (!WriteCsv("ONNX Datafolder\\"+csv_name_+".csv", return_matrix, csv_header)) Print("Failed to Write to a csv file"); else Print("Data saved to a csv file successfully"); return return_matrix; }
最后,数据保存在CSV中,以便与Python代码共享。
03:用Python构建模型
我将建立一个多层感知器神经网络,但你可以建立任何你选择的模型。您不限于此特定类型的模型。如果你还没有在系统中安装Python,请先安装。之后,通过从Windows CMD运行以下命令安装virtualenv,不要与Powershell混淆
$ pip3 install virtualenv
在运行之后,
$ virtualenv venv
这将为您的Windows机器创建一个Python虚拟环境,我相信我们大多数人都在Windows上,对于Mac用户和Linux用户来说,这个过程可能有点不同。之后,通过运行以下命令启动一个虚拟环境
$ venv\Scripts\activate
之后,通过运行安装本教程中使用的所有依赖项
通过创建虚拟环境来隔离项目总是很重要的,以避免模块和Python版本之间的冲突,并使项目易于共享
导入和初始化MT5
import MetaTrader5 as mt5 if not mt5.initialize(): #This will open MT5 app in your pc print("initialize() failed, error code =",mt5.last_error()) quit() # program logic and ML code will be here mt5.shutdown() #This closes the program # Getting the data we stored in the Files path on Metaeditor data_path = terminal_info.data_path dataset_path = data_path + "\\MQL5\\Files\\ONNX Datafolder"
我们需要检查路径是否存在,如果它不存在,那意味着我们还没有收集到MT5方面的数据。
import os if not os.path.exists(dataset_path): print("Dataset folder doesn't exist | Be sure you are referring to the correct path and the data is collected from MT5 side of things") quit()
构建多层感知器神经网络(MLP)
我们将把一个MLP NN封装在一个类中,使我们的代码成为可读的部分;
01:类初始化
数据被收集并划分为训练和测试样本,同时重要变量被声明为可供整个类使用,
class NeuralNetworkClass(): def __init__(self, csv_name, target_column, batch_size=32): # Loading the dataset and storing to a variable Array self.data = pd.read_csv(dataset_path+"\\"+csv_name) if self.data.empty: print(f"No such dataset or Empty dataset csv = {csv_name}") quit() # quit the program print(self.data.head()) # Print 5 first rows of a given data self.target_column = target_column # spliting the data into training and testing samples X = self.data.drop(columns=self.target_column).to_numpy() # droping the targeted column, the rest is x variables Y = self.data[self.target_column].to_numpy() # We convert data arrays to numpy arrays compartible with sklearn and tensorflow self.train_x, self.test_x, self.train_y, self.test_y = train_test_split(X, Y, test_size=0.3, random_state=42) # splitting the data into training and testing samples print(f"train x shape {self.train_x.shape}\ntest x shape {self.test_x.shape}") self.input_size = self.train_x.shape[-1] # obtaining the number of columns in x variable as our inputs self.output_size = 1 # We are solving for a regression problem we need to have a single output neuron self.batch_size = batch_size self.model = None # Object to store the model self.plots_directory = "Plots" self.models_directory = "Models"
输出:

02:建立神经网络模型
我们的单层神经网络是由给定数量的神经元定义的。
def BuildNeuralNetwork(self, activation_function='relu', neurons = 10): # Create a Feedforward Neural Network model self.model = keras.Sequential([ keras.layers.Input(shape=(self.input_size,)), # Input layer keras.layers.Dense(units=neurons, activation=activation_function, activity_regularizer=l2(0.01), kernel_initializer="he_uniform"), # Hidden layer with an activation function keras.layers.Dense(units=self.output_size, activation='linear', activity_regularizer=l2(0.01), kernel_initializer="he_uniform") ]) # Print a summary of the model's architecture. self.model.summary()
输出:

03:训练和测试神经网络模型
def train_network(self, epochs=100, learning_rate=0.001, loss='mean_squared_error'): early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) # Early stoppage mechanism | stop training when there is no major change in loss in the last to epochs, defined by the variable patience adam = optimizers.Adam(learning_rate=learning_rate) # Adam optimizer >> https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/ # Compile the model: Specify the loss function, optimizer, and evaluation metrics. self.model.compile(loss=loss, optimizer=adam, metrics=['mae']) # One hot encode the validation and train target variables validation_y = self.test_y y = self.train_y history = self.model.fit(self.train_x, y, epochs=epochs, batch_size=self.batch_size, validation_data=(self.test_x, validation_y), callbacks=[early_stopping], verbose=2) if not os.path.exists(self.plots_directory): #create plots path if it doesn't exist for saving the train-test plots os.makedirs(self.plots_directory) # save the loss and validation loss plot plt.figure(figsize=(12, 6)) plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() title = 'Training and Validation Loss Curves' plt.title(title) plt.savefig(fname=f"{self.plots_directory}\\"+title) # use the trained model to make predictions on the trained data pred = self.model.predict(self.train_x) acc = metrics.r2_score(self.train_y, pred) # Plot actual & pred count = [i*0.1 for i in range(len(self.train_y))] title = f'MLP {self.target_column} - Train' # Saving the plot containing information about predictions and actual values plt.figure(figsize=(7, 5)) plt.plot(count, self.train_y, label = "Actual") plt.plot(count, pred, label = "forecast") plt.xlabel('Actuals') plt.ylabel('Preds') plt.title(title+f" | Train acc={acc}") plt.legend() plt.savefig(fname=f"{self.plots_directory}\\"+title) self.model.save(f"Models\\lstm-pat.{self.target_column}.h5") #saving the model in h5 format, this will help us to easily convert this model to onnx later def test_network(self): # Plot actual & pred count = [i*0.1 for i in range(len(self.test_y))] title = f'MLP {self.target_column} - Test' pred = self.model.predict(self.test_x) acc = metrics.r2_score(self.test_y, pred) # Saving the plot containing information about predictions and actual values plt.figure(figsize=(7, 5)) plt.plot(count, self.test_y, label = "Actual") plt.plot(count, pred, label = "forecast") plt.xlabel('Actuals') plt.ylabel('Preds') plt.title(title+f" | Train acc={acc}") plt.legend() plt.savefig(fname=f"{self.plots_directory}\\"+title) if not os.path.exists(self.plots_directory): #create plots path if it doesn't exist for saving the train-test plots os.makedirs(self.plots_directory) plt.savefig(fname=f"{self.plots_directory}\\"+title) return acc
输出:
Epoch 1/50 219/219 - 2s - loss: 1.2771 - mae: 0.3826 - val_loss: 0.1153 - val_mae: 0.0309 - 2s/epoch - 8ms/step Epoch 2/50 219/219 - 1s - loss: 0.0836 - mae: 0.0305 - val_loss: 0.0582 - val_mae: 0.0291 - 504ms/epoch - 2ms/step Epoch 3/50 219/219 - 1s - loss: 0.0433 - mae: 0.0283 - val_loss: 0.0323 - val_mae: 0.0284 - 515ms/epoch - 2ms/step Epoch 4/50 219/219 - 0s - loss: 0.0262 - mae: 0.0272 - val_loss: 0.0218 - val_mae: 0.0270 - 482ms/epoch - 2ms/step Epoch 5/50 ... ... Epoch 48/50 219/219 - 0s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0121 - 490ms/epoch - 2ms/step Epoch 49/50 219/219 - 0s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0109 - 486ms/epoch - 2ms/step Epoch 50/50 219/219 - 1s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0097 - 501ms/epoch - 2ms/step 219/219 [==============================] - 0s 2ms/step C:\Users\Omega Joctan\OneDrive\Documents\onnx article\ONNX python\venv\Lib\site-packages\keras\src\engine\training.py:3079: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`. saving_api.save_model( 94/94 [==============================] - 0s 2ms/step Test accuracy = 0.9336617822086006

神经网络模型在训练期间的准确率为93%,在测试期间的准确度约为95%,可能过拟合,但我们无论如何都会继续进行。
04:保存ONNX模型。
一旦训练成功完成,并且您对模型在训练和样本外验证中的性能感到满意,通常保存模型是一种很好的做法。我们需要在类中的train_network函数中添加ONNX运行时代码来保存模型。首先,我们需要安装两个库,onnx和tf2onnx
def train_network(self, epochs=100, learning_rate=0.001, loss='mean_squared_error'): # at the end of this function # .... self.model.save(f"Models\\MLP.REG.{self.target_column}.{self.data.shape[0]}.h5") #saving the model in h5 format, this will help us to easily convert this model to onnx later self.saveONNXModel() def saveONNXModel(self, folder="ONNX Models"): path = data_path + "\\MQL5\\Files\\" + folder if not os.path.exists(path): # create this path if it doesn't exist os.makedirs(path) onnx_model_name = f"MLP.REG.{self.target_column}.{self.data.shape[0]}.onnx" path += "\\" + onnx_model_name loaded_keras_model = load_model(f"Models\\MLP.REG.{self.target_column}.{self.data.shape[0]}.h5") onnx_model, _ = tf2onnx.convert.from_keras(loaded_keras_model, output_path=path) onnx.save(onnx_model, path ) print(f'Saved model to {path}')
输出:

您可能已经注意到,我选择将ONNX模型保存在 Files 父目录下,为什么是这个目录?这是因为将 ONNX 文件作为资源(如专家顾问或指示器)包含在我们的MQL5程序中更容易。
04:在MQL5中获取已构建的ONNX模型
#resource "\\Files\\ONNX Models\\MLP.REG.CLOSE.10000.onnx" as uchar RNNModel[]
这将导入ONNX模型并将其存储在RNNModel uchar数组中。
我们需要做的下一件事是将ONNX句柄定义为全局变量,并在OnInit函数内创建句柄。
在 ONNX mt5.mq5 EA 文件中
long mlp_onnxhandle; #include <MALE5\preprocessing.mqh> CPreprocessing<vectorf, matrixf> *norm_x; int inputs[], outputs[]; vectorf OPEN, HIGH, LOW; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!LoadNormParams()) //Load the normalization parameters we saved once { Print("Normalization parameters csv files couldn't be found \nEnsure you are collecting data and Normalizing them using [ONNX get data.ex5] Script \nTrain the Python model again if necessary"); return INIT_FAILED; } //--- ONNX SETTINGS mlp_onnxhandle = OnnxCreateFromBuffer(RNNModel, MQLInfoInteger(MQL_DEBUG) ? ONNX_DEBUG_LOGS : ONNX_DEFAULT); //creating onnx handle buffer | rUN DEGUG MODE during debug mode if (mlp_onnxhandle == INVALID_HANDLE) { Print("OnnxCreateFromBuffer Error = ",GetLastError()); return INIT_FAILED; } //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(mlp_onnxhandle); Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(mlp_onnxhandle,i); Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(mlp_onnxhandle,i,type_info)) { PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(mlp_onnxhandle); Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(mlp_onnxhandle,i); Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(mlp_onnxhandle,i,type_info)) { PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- if (MQLInfoInteger(MQL_DEBUG)) { Print("Inputs & Outputs"); ArrayPrint(inputs); ArrayPrint(outputs); } const long input_shape[] = {batch_size, 3}; if (!OnnxSetInputShape(mlp_onnxhandle, 0, input_shape)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); return INIT_FAILED; } const long output_shape[] = {batch_size, 1}; if (!OnnxSetOutputShape(mlp_onnxhandle, 0, output_shape)) //giving the onnx handle the output shape { printf("Failed to set the input shape Err=%d",GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
输出:
PR 0 18:57:10.265 ONNX mt5 (EURUSD,H1) ONNX: Creating and using per session threadpools since use_per_session_threads_ is true CN 0 18:57:10.265 ONNX mt5 (EURUSD,H1) ONNX: Dynamic block base set to 0 EE 0 18:57:10.266 ONNX mt5 (EURUSD,H1) ONNX: Initializing session. IM 0 18:57:10.266 ONNX mt5 (EURUSD,H1) ONNX: Adding default CPU execution provider. JN 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Use DeviceBasedPartition as default QK 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Saving initialized tensors. GR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Done saving initialized tensors RI 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Session successfully initialized. JF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) model has 1 input(s) QR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 input name is input_1 NF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) type ONNX_TYPE_TENSOR PM 0 18:57:10.269 ONNX mt5 (EURUSD,H1) data type ONNX_TYPE_TENSOR HI 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape [-1, 3] FS 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 input shape must be defined explicitly before model inference NE 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape of input data can be reduced to [3] if undefined dimension set to 1 GD 0 18:57:10.269 ONNX mt5 (EURUSD,H1) model has 1 output(s) GQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 output name is dense_1 LJ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) type ONNX_TYPE_TENSOR NQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) data type ONNX_TYPE_TENSOR LF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape [-1, 1] KQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 output shape must be defined explicitly before model inference CO 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape of output data can be reduced to [1] if undefined dimension set to 1 GR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) Inputs & Outputs IE 0 18:57:10.269 ONNX mt5 (EURUSD,H1) -1 3 CK 0 18:57:10.269 ONNX mt5 (EURUSD,H1) -1 1
获取实时数据
正如我之前所说,实时数据必须从市场上获得,并以收集训练数据时的规范化方式进行规范化。
在 ONNX mt5.mq5 EA 文件中
matrixf GetLiveData(uint start, uint total) { matrixf return_matrix(total, 3); OPEN.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_LOW, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); if (!norm_x.Normalization(return_matrix)) Print("Failed to Normalize"); return return_matrix; }
为了使norm_x类实例工作,它是在OnInit内的LoadNormParams()函数内声明的,该函数从相应的CSV文件加载保存的规范化参数。
在 ONNX mt5.mq5 EA 文件中
bool LoadNormParams() { vectorf min = {}, max ={}, mean={} , std = {}; csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); switch(NORM) { case NORM_MEAN_NORM: mean = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv"); //--- Loading the mean min = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.min.csv"); //--- Loading the min max = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.max.csv"); //--- Loading the max if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMean ",mean,"\nMin ",min,"\nMax ",max); norm_x = new CPreprocessing<vectorf,matrixf>(max, mean, min); if (mean.Sum()<=0 && min.Sum()<=0 && max.Sum() <=0) return false; break; case NORM_MIN_MAX_SCALER: min = ReadCsvVector(normparams_folder+csv_name_+".min_max_scaler.min.csv"); //--- Loading the min max = ReadCsvVector(normparams_folder+csv_name_+".min_max_scaler.max.csv"); //--- Loading the max if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMin ",min,"\nMax ",max); norm_x = new CPreprocessing<vectorf,matrixf>(max, min); if (min.Sum()<=0 && max.Sum() <=0) return false; break; case NORM_STANDARDIZATION: mean = ReadCsvVector(normparams_folder+csv_name_+".standardization_scaler.mean.csv"); //--- Loading the mean std = ReadCsvVector(normparams_folder+csv_name_+".standardization_scaler.std.csv"); //--- Loading the std if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMean ",mean,"\nStd ",std); norm_x = new CPreprocessing<vectorf,matrixf>(mean, std, NORM_STANDARDIZATION); if (mean.Sum()<=0 && std.Sum() <=0) return false; break; } return true; }
05:实时运行模型
要在OnTick函数中使用模型,只需调用OnnxRun函数,并将ONNX句柄、向量或矩阵的float值传递给它,即可用于输入和预测。
在 ONNX mt5.mq5 EA 文件中
void OnTick() { //--- matrixf input_data = GetLiveData(0,1); vectorf output_data(1); //It is very crucial to resize this vector or matrix if (!OnnxRun(mlp_onnxhandle, ONNX_NO_CONVERSION, input_data, output_data)) { Print("Failed to Get the Predictions Err=",GetLastError()); ExpertRemove(); return; } Comment("inputs_data\n",input_data,"\npredictions\n",output_data); }
需要调整输出数据矢量或float矩阵的大小,以避免出现代表ERR_ONNX_INVALID_PARAMETER的错误代码5805由于我在神经网络中只有一个输出,这就是为什么我调整了这个向量的大小,使其大小为1如果我使用矩阵,那么我应该将其调整为1行1列
输出:

太好了,一切都很好。我们现在正在使用MetaTrader5中使用Python制作和训练的神经网络模型,这个过程并没有那么困难,干杯
在MQL5中使用ONNX的优势
- 互操作性:ONNX提供了一种表示深度学习模型的通用格式。这种格式允许在一个深度学习框架(如TensorFlow、PyTorch或scikit learn)中训练的模型在MQL5中使用,而无需大量的模型重新实现。这可以节省大量时间,因为我们不再需要从头开始硬编码模型以使其在MQL5中工作
- 灵活性:ONNX支持广泛的深度学习模型类型,从传统的前馈神经网络到更复杂的模型,如递归神经网络(RNN)和卷积神经网络(CNNs)。这种灵活性使其适用于各种应用。
- 效率:ONNX型号可以进行优化,以便在不同的硬件和平台上进行高效部署。这意味着您可以在边缘设备、移动设备、云服务器甚至专用硬件加速器上部署模型。
- 社区支持:ONNX获得了大量的社区支持。主要的深度学习框架,如TensorFlow、PyTorch和scikit-learn,支持将模型导出为ONNX格式,而各种运行时引擎,如ONNX runtime,使ONNX模型的部署变得容易。
- 广泛的生态系统:ONNX集成到各种软件包中,并且有广泛的工具用于处理ONNX模型。您可以使用这些工具转换、优化和运行ONNX格式的模型。
- 跨平台兼容性:ONNX被设计为跨平台,这意味着以ONNX格式导出的模型可以在外部和硬件的不同操作系统上运行,而无需修改。
- 模型演进:ONNX支持模型版本控制和演进。您可以随着时间的推移改进和扩展您的模型,同时保持与以前版本的兼容性。
- 标准化:ONNX正在成为不同深度学习框架之间互操作性的事实标准,使社区更容易共享模型和工具。
最后的想法
ONNX在需要跨不同框架利用模型、在各种平台上部署模型或与可能使用不同深度学习工具的其他人合作的场景中尤其有价值。它简化了使用深度学习模型的过程,随着生态系统的不断发展,ONNX的优势变得更加显著。在本文中,我们看到了开始使用工作模型所需遵循的5个重要步骤。至少可以说,您可以扩展此代码以满足您的需求。此外,为了让程序在策略测试器上工作,需要在测试器内部读取规范化CSV文件,这是我在本文中没有涉及的。
顺致敬意
| 文件 | 用途 |
|---|---|
| neuralnet.py | 主python脚本文件,包含所有用python语言实现的神经网络 |
| ONNX mt5.mq5 | EA 交易,展示如何在交易情况下使用ONNX模型 |
| ONNX get data.mq5 | 用于收集和准备要与python脚本共享的数据的脚本 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/13394
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

@Omega J Msigwa 非常感谢你的这篇文章。由于最新版本的 MALE5 没有 CPreprocessing,能否请您更新一下教程文件?如果不可能,请问使用哪个版本的 MALE5 来运行本教程?
我不确定是否有该库的文档。
谢谢
有关本教程的任何内容,请使用本文所附的 cprecessi mg 代码。
我指的是这一行:
#include <MALE5\preprocessing.mqh> // 您指向使用没有 CPreprocessing 的 https://github.com/MegaJoctan/MALE5/blob/MQL5-ML/preprocessing.mqh
好的,明白了,如果是这样,请将该行改为:
#include <preprocessing.mqh>将预处理.mqh 保存在此 压缩文件 (文章附件)中的 include 文件夹下。
CPreprocessing 自 2.0.0 版(即本文使用的版本)起已被弃用。
或者,调用预处理文件中的每个缩放器,而不是 CPreprocessing。假设您使用的是 MALE5 版本 3.0.0
每个标量器类都提供
在数据矩阵 X 上拟合标量并执行变换。
使用拟合缩放器变换数据矩阵 X。
使用拟合标量对数据向量 X 进行变换。
如果对你有帮助,请告诉我。
要使 ONNX 与 MetaTrader 5 兼容,Python 模型是否必须简单,还是可以使用高度优化的复杂架构?
MetaTrader 5 适用于任何复杂程度的模型。