Статьи об анализе данных и статистике в MQL5
Статьи на темы математических моделей и законов вероятности заинтересуют многих трейдеров. Ведь математика положена в основу технических индикаторов, а знание статистики необходимо для анализа результатов торговли и разработки стратегий.
Читайте о нечеткой логике, цифровых фильтрах, рыночном профиле, картах Кохонена, нейронном газе и многих других инструментах, которые могут использованы для торговли.
Новая статья

Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь

Разработка робота на Python и MQL5 (Часть 2): Выбор модели, создание и обучение, кастомный тестер Python
Продолжаем цикл статей по созданию торгового робота на Python и MQL5. Сегодня решим задачу выбора и обучения модели, ее тестирования, внедрения кросс-валидации, поиска по сетке, а также задачу ансамблирования моделей.
Машинное обучение и Data Science. Нейросети (Часть 02): архитектура нейронных сетей с прямой связью
В предыдущей статье мы начали изучать нейросети с прямой связью, однако остались неразобранными некоторые моменты. Один из них — проектирование архитектуры. Поэтому в этой статье мы рассмотрим, как спроектировать гибкую нейронную сеть с учетом входных данных, количества скрытых слоев и узлов для каждой сети.
Машинное обучение и Data Science (Часть 13): Анализируем финансовый рынок с помощью метода главных компонент (PCA)
Попробуем качественно улучшить анализ финансовых рынков с помощью метода главных компонент (Principal Component Analysis, PCA). Узнаем, как этот метод может помочь выявлять скрытые закономерности в данных, определять скрытые рыночные тенденции и оптимизировать инвестиционные стратегии. В этой статье мы посмотрим, как метод PCA дает новую перспективу для анализа сложных финансовых данных, помогая увидеть идеи, которые мы упустили при использовании традиционных подходов. Дает ли применение метода PCA на данных финансовых рынков конкурентное преимущество и поможет ли быть на шаг впереди?

Обучение многослойного персептрона с помощью алгоритма Левенберга-Марквардта
В статье представлена реализация алгоритма Левенберга-Марквардта для обучения нейронных сетей прямого распространения. Проведен сравнительный анализ результативности с алгоритмами из библиотеки scikit-learn Python. Предварительно обсуждаются более простые методы обучения такие как градиентный спуск, градиентный спуск с импульсом и стохастический градиентный спуск.
Нейросети — это просто (Часть 25): Практикум Transfer Learning
В последних двух статьях мы создали инструмент, позволяющий создавать и редактировать модели нейронных сетей. И теперь пришло время оценить потенциальные возможности использования технологии Transfer Learning на практических примерах.

Работа с ценами в библиотеке DoEasy (Часть 59): Объект для хранения данных одного тика
С данной статьи приступим к созданию функционала библиотеки для работы с ценовыми данными. Сегодня создадим класс объекта, который будет хранить в себе все данные цен, пришедшие с очередным тиком.

Скрытые марковские модели в торговых системах на машинном обучении
Скрытые марковские модели (СММ) представляют собой мощный класс вероятностных моделей, предназначенных для анализа последовательных данных, где наблюдаемые события зависят от некоторой последовательности ненаблюдаемых (скрытых) состояний, которые формируют марковский процесс. Основные предположения СММ включают марковское свойство для скрытых состояний, означающее, что вероятность перехода в следующее состояние зависит только от текущего состояния, и независимость наблюдений при условии знания текущего скрытого состояния.

Реализация расширенного теста Дики-Фуллера в MQL5
В статье показаны реализация расширенного теста Дики-Фуллера и его применение для проведения коинтеграционных тестов с использованием метода Энгла-Грейнджера.
Эконометрические инструменты для прогнозирования волатильности: Модель GARCH
В статье дается описание свойств нелинейной модели условной гетероскедастичности(GARCH). На ее основе построен индикатор iGARCH для прогнозирования волатильности на один шаг вперед. Для оценки параметров модели используется библиотека численного анализа ALGLIB.

Модифицированный советник Grid-Hedge в MQL5 (Часть I): Создание простого хеджирующего советника
Мы будем создавать простой хеджирующий советник в качестве основы для нашего более продвинутого советника Grid-Hedge, который будет представлять собой смесь классической сетки и классических стратегий хеджирования. К концу этой статьи вы узнаете, как создать простую стратегию хеджирования, а также что говорят люди о прибыльности этой стратегии.
Работа с таймсериями в библиотеке DoEasy (Часть 57): Объект данных буфера индикатора
В статье разработаем объект, который будет содержать в себе все данные одного буфера одного индикатора. Такие объекты потребуются для хранения серийных данных буферов индикаторов, и с помощью которых возможно будет сортировать и сравнивать данные буферов любых индикаторов и других схожих данных между собой.

Движение цены: Математические модели и технический анализ
Прогнозирование движений валютных пар является важным фактором успеха в трейдинге. Данная статья посвящена исследованию различных моделей движения цены, анализу их преимуществ и недостатков, а также практическому применению в торговых стратегиях. Мы рассмотрим подходы, позволяющие выявлять скрытые закономерности и повышать точность прогнозов.

Торговля спредами на рынке форекс с использованием фактора сезонности
В статье рассматриваются возможности формирования и предоставления отчетных данных по использованию фактора сезонности при торговле спредами на рынке форекс.

Алгоритм кодового замка (Сode Lock Algorithm, CLA)
В этой статье мы переосмыслим кодовые замки, превращая их из механизмов защиты в инструменты для решения сложных задач оптимизации. Откройте для себя мир кодовых замков, не как простых устройств безопасности, но как вдохновения для нового подхода к оптимизации. Мы создадим целую популяцию "замков", где каждый замок представляет собой уникальное решение задачи. Затем мы разработаем алгоритм, который будет "вскрывать" эти замки и находить оптимальные решения в самых разных областях, от машинного обучения до разработки торговых систем.
Прочие классы в библиотеке DoEasy (Часть 70): Расширение функционала и автообновление коллекции объектов-чартов
В статье расширим функционал объектов-чартов, организуем навигацию по графикам, создание скриншотов, сохранение и применение шаблонов к графикам. Также сделаем автоматическое обновление коллекции объектов-чартов, их окон и индикаторов в них.
Работа с ценами в библиотеке DoEasy (Часть 63): Стакан цен, класс абстрактной заявки стакана цен
В статье начнём разработку функционала для работы со стаканом цен. Создадим класс объекта абстрактной заявки стакана цен и его наследников.

Модифицированный советник Grid-Hedge в MQL5 (Часть II): Создание простого сеточного советника
В статье рассматривается классическая сеточная стратегия, подробно описана ее автоматизация с помощью советника на MQL5 и проанализированы первоначальные результаты тестирования на истории. Также подчеркивается необходимость в долгом удержании позиций и рассматривается возможность оптимизации ключевых параметров (таких как расстояние, тейк-профит и размеры лотов) в будущих частях. Целью этой серии статей является повышение эффективности торговой стратегии и ее адаптируемости к различным рыночным условиям.
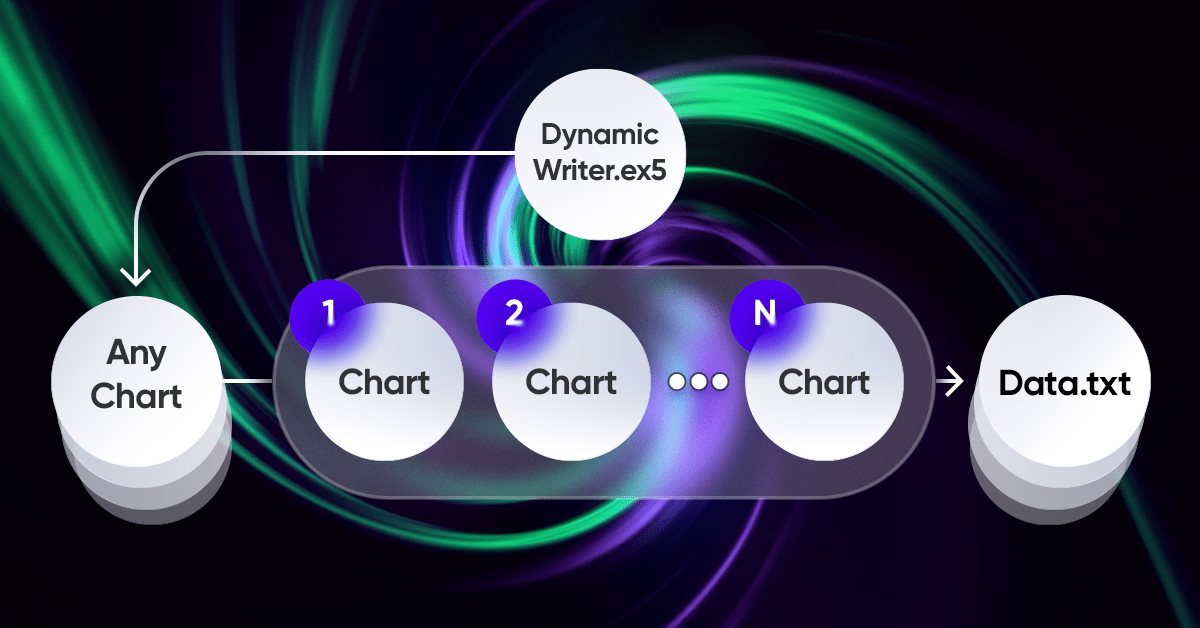
Брутфорс-подход к поиску закономерностей (Часть VI): Циклическая оптимизация
В этой статье я покажу первую часть доработок, которые позволили мне не только замкнуть всю цепочку автоматизации для торговли в MetaTrader 4 и 5, но и сделать что-то гораздо интереснее. Отныне данное решение позволяет мне полностью автоматизировать как процесс создания советников, так и процесс оптимизации, а также минимизировать трудозатраты на поиск эффективных торговых конфигураций.

Работа с матрицами, расширение функционала Стандартной библиотеки матриц и векторов
Матрица служит основой алгоритмов машинного обучения и компьютеров в целом из-за ее способности эффективно обрабатывать большие математические операции. В Стандартной библиотеке есть все, что нужно, но мы можем расширить ее, добавив несколько функций в файл utils.
Работа с таймсериями в библиотеке DoEasy (Часть 48): Мультипериодные мультисимвольные индикаторы на одном буфере в подокне
В статье рассмотрим пример создания мультисимвольных мультипериодных стандартных индикаторов, использующих для своих построений один индикаторный буфер, и работающих в подокне графика. Подготовим классы библиотеки для работы со стандартными индикаторами, работающими в основном окне программы, или имеющими более одного буфера для вывода своих данных.
Понимание и эффективное использование тестера стратегий MQL5
MQL5-разработчикам крайне необходимо освоить важные и ценные инструменты. Одним из таких инструментов является тестер стратегий. Статья представляет собой практическое руководство по использованию тестера стратегий MQL5.

Популяционные алгоритмы оптимизации: Алгоритм растущих деревьев (Saplings Sowing and Growing up — SSG)
Алгоритм растущих деревьев (Saplings Sowing and Growing up, SSG) вдохновлен одним из самых жизнестойких организмов на планете, который является замечательным образцом выживания в самых различных условиях.
Популяционные алгоритмы оптимизации: Бинарный генетический алгоритм (Binary Genetic Algorithm, BGA). Часть II
В этой статье мы рассмотрим бинарный генетический алгоритм (BGA), который моделирует естественные процессы, происходящие в генетическом материале у живых существ в природе.

Количественный анализ на MQL5: реализуем перспективный алгоритм
Разбираем вопрос, что такое количественный анализ, как его применяют крупные игроки, создадим один из алгоритмов количественного анализа на языке MQL5.

Популяционные алгоритмы оптимизации: Алгоритмы эволюционных стратегий (Evolution Strategies, (μ,λ)-ES и (μ+λ)-ES)
В этой статье будет рассмотрена группа алгоритмов оптимизации, известных как "Эволюционные стратегии" (Evolution Strategies или ES). Они являются одними из самых первых популяционных алгоритмов, использующих принципы эволюции для поиска оптимальных решений. Будут представлены изменения, внесенные в классические варианты ES, а также пересмотрена тестовая функция и методика стенда для алгоритмов.

Машинное обучение и Data Science (Часть 04): Предсказание биржевого краха
В этой статье я попытаюсь использовать нашу логистическую модель, чтобы спрогнозировать крах фондового рынка на основе главнейших акций для экономики США: NETFLIX и APPLE. Мы проанализируем эти акции, будем использовать информацию о предыдущих падениях рынка 2019 и 2020 годов. Посмотрим, как наша модель будет работать в нынешних мрачных условиях.

Нейросети — это просто (Часть 16): Практическое использование кластеризации
В предыдущей статье мы построили класс для кластеризации данных. В этой статье я хочу с вами поделиться вариантами возможного использования полученных результатов для решения практических задач трейдинга.

Критерий однородности Смирнова как индикатор нестационарности временного ряда
В статье рассматривается один из самых известных непараметрических критериев однородности — критерий Смирнова. Анализируются как модельные данные, так и реальные котировки. Приводится пример построения индикатора нестационарности (iSmirnovDistance).
Работа с ценами в библиотеке DoEasy (Часть 62): Реалтайм-обновление тиковых серий, подготовка к работе со стаканом цен
В статье сделаем реалтайм-обновление коллекции тиковых данных и подготовим класс объекта-символа для работы со стаканом цен, работу над которым начнём со следующей статьи.

Алгоритм докупки: симуляция мультивалютной торговли
В данной статье мы создадим математическую модель для симуляции мультивалютного ценообразования и завершим исследование принципа диверсификации в рамках поиска механизмов увеличения эффективности торговли, которое я начал в предыдущей статье с теоретических выкладок.

Парный трейдинг: Алготорговля с автооптимизацией на разнице Z-оценки
В этой статье разберем, что такое парный трейдинг и как происходит торговля на корреляциях. Также создадим советник для автоматизации парного трейдинга и добавим возможность автоматической оптимизации такого торгового алгоритма на исторических данных. Кроме того, в рамках проекта узнаем, как рассчитывать расхождения двух пар с помощью z-оценки.

Популяционные алгоритмы оптимизации: Алгоритм боидов, или алгоритм стайного поведения (Boids Algorithm, Boids)
В данной статье мы проводим исследование алгоритма Boids, в основе которого лежат уникальные примеры стайного поведения животных. Алгоритм Boids, в свою очередь, послужил основой для создания целого класса алгоритмов, объединенных под названием "Роевый интеллект".

Машинное обучение и Data Science (Часть 21): Сравниваем алгоритмы оптимизации в нейронных сетях
В этой статье мы заглянем в самую глубь нейронных сетей и поговорим об используемых в них алгоритмах оптимизации. В частности обсудим ключевые методы, которые позволяют раскрыть потенциал нейронных сетей и повысить точность и эффективность моделей.

Машинное обучение и Data Science (Часть 25): Прогнозирование временных рядов на форексе с помощью рекуррентных нейросетей (RNN)
Рекуррентные нейронные сети (RNN) ценятся за способность использовать прошлую информацию для прогнозирования будущих событий. Такие прогностические возможности с успехом применяются в различных областях. В этой статье мы применим модели RNN для прогнозирования трендов на рынке Форекс. Посмотрим, смогут ли они повысить точность прогнозирования в трейдинге.

Машинное обучение и Data Science (Часть 15): SVM — полезный инструмент в арсенале трейдера
В этой статье мы разберем, какую роль метод опорных векторов (Support Vector Machines, SVM) играет в формировании будущего трейдинга. Статью можно рассматривать как подробное руководством, которое рассказывает, как с помощью SVM улучшить торговые стратегии, оптимизировать процесс принятия решений и открыть новые возможности на финансовых рынках. Вы погрузитесь в мир SVM через реальные приложения, пошаговые инструкции и экспертные оценки. Возможно, этот незаменимый инструмент поможет разобраться в сложностях современной торговли. В любом случае SVM станет очень полезным инструментом в арсенале каждого трейдера.

Роль качества генератора случайных чисел в эффективности алгоритмов оптимизации
В этой статье мы рассмотрим генератор случайных чисел Mersenne Twister и сравним со стандартным в MQL5. Узнаем влияние качества случайных чисел генераторов на результаты алгоритмов оптимизации.

Машинное обучение и Data Science (Часть 24): Прогнозирование временных рядов на форексе с помощью обычных ИИ-моделей
На валютном рынке сложно предсказать будущие тренды, не имея представления о прошлом. Очень немногие модели машинного обучения способны делать прогнозы на будущее, учитывая прошлые значения. В этой статье мы посмотрим, как можно использовать классические (не временные ряды) модели искусственного интеллекта, чтобы понять рынок.

Машинное обучение и Data Science (Часть 17): Растут ли деньги на деревьях? Случайные леса в форекс-трейдинге
Эта статья познакомит вас с секретами алгоритмической алхимии, познакомит с искусством и точностью особенностей финансовых ландшафтов. Вы узнаете, как случайные леса преобразуют данные в прогнозы и помогают ориентироваться в сложностях финансовых рынков. Мы постараемся определить роль случайных лесов в отношении финансовых данных и проверить, смогут ли они помочь увеличить прибыль.

Своп-арбитраж на Форекс: Собираем синтетический портфель и создаем стабильный своп-поток
Хотите узнать, как извлекать выгоду из разницы в процентных ставках? В статье мы посмотрим, как использовать своп-арбитраж на Форексе, чтобы каждую ночь получать стабильный доход, создавая портфель, устойчивый к рыночным колебаниям.

Индикатор прогноза волатильности при помощи Python
Прогнозируем будущую экстремальную волатильность при помощи бинарной классификации. Создаем индикатор прогноза экстремальной волатильности с использованием машинного обучения.