
Торговля по алгоритму: ИИ и его путь к золотым вершинам
Введение
Эволюция понимания возможностей методов машинного обучения в торговле привела к созданию разных алгоритмов, которые одинаково хорошо справляются с одной и той же задачей, но принципиально отличаются. В этой статье снова будет рассмотрена однонаправленная трендовая торговая система на примере золота, но с использованием алгоритма кластеризации.
- В прошлой статье были описаны два алгоритма причинно-следственного вывода для создания похожей трендовой стратегии для золота.
- В статье про кластеризацию временных рядов были рассмотрены разные способы кластеризация в задачах трейдинга.
- Создание стратегии возврата к среднему, с использованием алгоритма кластеризации, было представлено публике ранее.
- Разработка трендовой торговой системы на базе кластеризации также подсветила возможности такого подхода.
Рассматривая этот важный подход к анализу и прогнозированию временных рядов с разных ракурсов, можно определить его преимущества и недостатки по сравнению с другими способами создания торговых систем, основанных исключительно на анализе и прогнозировании финансовых временных рядов. В некоторых случаях данные алгоритмы становятся достаточно эффективными и превосходят классические подходы как по скорости создания, так и и по качеству торговых систем на выходе.
В этой статье мы сконцентрируем свое внимание на однонаправленной торговле, когда алгоритм будет открывать сделки только на покупку или продажу. В качестве базовых алгоритмов будут использованы алгоритмы CatBoost и K-Means. CatBoost является базовой моделью, которая выполняет функции бинарного классификатора для классификации сделок. K-Means же используется для определения режимов рынка на этапе препроцессинга.
Подготовка к работе и импорт модулей
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX import time
В коде используются только надежные и проверенные общедоступные пакеты, такие как:
- Pandas — отвечает за работу с таблицами данных (датафреймами)
- Scikit-learn — содержит разнообразные функции для препроцессинга и машинного обучения, в том числе алгоритмы кластеризации
- CatBoost — мощный алгоритм градиентного бустинга от компании Яндекс
Импортированы созданные мной отдельные модули:
- labeling_lib — содержит функции семплеров для разметки сделок
- tester_lib — в нем расположены тестеры стратегий на основе машинного обучения
- export_lib — модуль для экспорта обученных моделей в терминал Meta Trader 5 в ONNX-формате
Получение данных и создание признаков
def get_prices() -> pd.DataFrame:
p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+')
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed')
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
return pFixed.dropna() В коде реализована загрузка котировок из файла, для удобства получения данных из разных источников. Используются только цены закрытия. На основе этих данных создаются признаки.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1
Признаки разделены на две группы:
- Основные признаки для обучения базовой модели, которая предсказывает направление торговли.
- Дополнительные мета-признаки для кластеризации. Они используются для разделения исходных данных на кластеры (рыночные режимы).
В данном примере в качестве признаков используется волатильность (стандартные отклонения цен в скользящих окнах заданного периода). Но мы протестируем и другие признаки, например скользящие средние и скосы распределений.
Кластеризация рыночных режимов
def clustering(dataset, n_clusters: int) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ return data
Функция получает датафрейм с ценами и признаками и использует дополнительные мета-признаки для кластеризации на заданное количество кластеров (обычно 10). Для кластеризации используется алгоритм K-Means. После этого, каждой строке датафрейма назначается метка кластера, которая соответствует этому наблюдению. И возвращается датафрейм с дополнительным столбцом "clusters".
Функция для обучения классификаторов
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=500, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=300, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model_one_direction([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
Для обучения используются две модели. Первая обучается на основных признаках и метках, а вторая обучается на мета-признаках и мета-метках. Если для первой модели метками являются направления сделок, для второй модели метками служат номера кластеров. 1 — в случае, если данные соответствуют необходимому кластеру, и 0 — если данные соответствуют всем остальным кластерам.
Перед обучением данные разделяются на тренировочные и валидационные в пропорции 70/30, для того, чтобы алгоритм CatBoost меньше переобучался. Он использует валидационные данные для раннего останова, когда ошибка на них перестает падать в процессе обучения. Затем выбирается лучшая модель, которая имеет наименьшую ошибку предсказания на валидационных данных.
После тренировки моделей, они передаются в функцию тестирования, чтобы оценить кривую баланса посредством R^2. Это необходимо для последующей сортировки моделей и выбора лучшей.
Функция тестирования моделей
def test_model_one_direction( result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): pr_tst = get_features(get_prices()) X = pr_tst[pr_tst.columns[1:]] X_meta = X.copy() X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X_meta)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(pr_tst, stop, take, forward, backward, markup, direction, plt)
Функция принимает две обученные модели (основную и мета-модель), а также остальные параметры, необходимые для тестирования в кастомном тестере стратегий. Затем, снова создается датафрейм с ценами и признаками, которые передаются в эти модели для предсказаний. Полученные предсказания записываются в колонки "labels" и "meta_labels" этого датафрейма.
В самом конце вызывается функция кастомного тестера, который расположен в подключаемом модуле tester_lib.py, который проводит тестирование моделей на истории и возвращает оценку R^2.
Функция разметки сделок
Модуль labeling_lib.py содержит семплер, предназначенный для разметки сделок только в выбранном направлении:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Основной обучающий цикл
# LEARNING LOOP dataset = get_features(get_prices()) // получение цен и признаков models = [] // создание пустого списка моделей for i in range(1): // цикл задает сколько попыток обучения нужно выполнить start_time = time.time() data = clustering(dataset, n_clusters=hyper_params['n_clusters']) // добавление номеров кластеров к данным sorted_clusters = data['clusters'].unique() // определение уникальных кластеров sorted_clusters.sort() // сортировка кластеров по возрастанию for clust in sorted_clusters: // цикл по всем кластерам clustered_data = data[data['clusters'] == clust].copy() // выбор данных для одного гластера if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) // проверка на достаточность обучающих примеров continue clustered_data = get_labels_one_direction(clustered_data, // разметка сделок для выбранного кластера markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1)// удаление цен закрытия и номеров кластеров meta_data = data.copy() // создание данных для мета-модели meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) // размтка текущего кластера как "1" models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) // обучение моделей и добавление их в список end_time = time.time() print("Время выполнения: ", end_time - start_time)
В обучающем цикле последовательно используются все функции, описанные ранее:
- Из файла загружаются котировки в датафрейм и создаются признаки
- Создается пустой список, который будет хранить обученные модели
- Задается количество итераций (попыток) обучения на одних и тех же данных, чтобы исключить случайные флюктуации моделей
- Происходит кластеризация мета-признаков и добавляется колонка "clusters" к данным
- В цикле, для каждого кластера, выбираются данные, которые принадлежат только ему
- Данные для каждого кластера размечаются, то есть создаются метки классов для основной модели
- Создается дополнительный датасет для мета-модели, которая учится определять заданный кластер ото всех остальных
- Оба датасета передаются в обучающую функцию, которая выполняет обучение двух классификаторов
- Обученные модели добавляются в список
Процесс обучения и тестирования моделей
Гиперпараметры (общие настройки) алгоритма вынесены в словарь:
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 10,
} Обучение будет происходить на периоде с 2020 по 2024 годы, а тестовый период — с начала 2024 года по сей день.
Очень важно правильно задать следующие параметры:
- markup - 0.2 — это средний спред по символу XAUUSD. Если вы зададите слишком маленький или слишком большой спред, то результаты тестирования могут оказаться нереалистичным. Плюс, сюда же закладываются дополнительные потери, связанные с проскальзываниями и комиссиями, если они имеются.
- stop loss — размер стопа в пунктах символа.
- take profit — размер тэйка в пунктах. Стоит учитывать, что сделки закрываются как по сигналам модели, так и при достижении стоп-лосс или тэйк-профит.
- periods — список со значениями периодов для основных признаков. В общем случае хватает десяти периодов, начиная с пяти и с шагом 30.
- periods meta — список со значениями периодов для мета-признаков. Для определения рыночных режимов большое количество признаков не требуется. Обычно это один признак, например стандартное отклонение за 5 последних баров.
- direction — будем использовать только "buy", потому что на золоте восходящий тренд.
- n_clusters — количество режимов (кластеров) для кластеризации. Обычно я использую 10.
Обучение на стандартных отклонениях
Сначала будем использовать только стандартные отклонения в качестве признаков, поэтому функция создания признаков будет выглядеть так:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Запустим один цикл обучения, в процессе которого получим следующую информацию:
Iteration: 0, Cluster: 0 R2: 0.989543793954197 Iteration: 0, Cluster: 1 R2: 0.9697821077241253 too few samples: 19 too few samples: 238 Iteration: 0, Cluster: 4 R2: 0.9852770333065658 Iteration: 0, Cluster: 5 R2: 0.7723040599270985 too few samples: 87 Iteration: 0, Cluster: 7 R2: 0.9970885055361235 Iteration: 0, Cluster: 8 R2: 0.9524980839809385 too few samples: 446 Время выполнения: 2.140070915222168
Произошла попытка обучения десяти моделей для десяти рыночных режимов. Не все режимы оказались полезными, потому что некоторые из них содержали слишком мало обучающих примеров (сделок). Они не прошли фильтр на минимальное количество сделок, поэтому не использовались для обучения.
Лучший рыночный режим (кластер) под номером 7 показал R^2 0.99. Это хороший кандидат на лучшую модель для торговли. Время выполнения всего обучающего цикла составило всего 2 секунды, что очень быстро.
После сортировки моделей, протестируем лучшую:
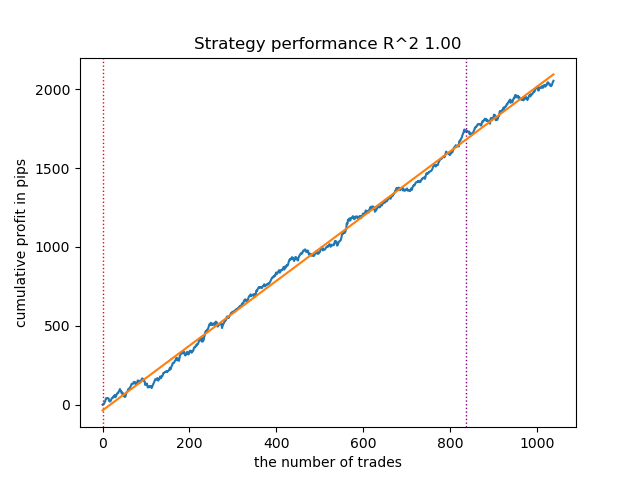
Рис 1. Тестирование лучшей модели после сортировки
Следующая за ней модель тоже оказалась достаточно хорошей и имеет большое количество сделок:
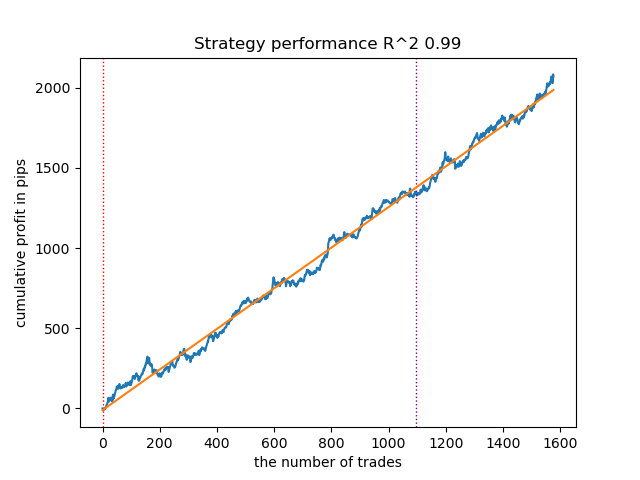
Рис 2. Тестирование второй модели в рейтинге
Поскольку обучение и тестирование моделей происходит очень быстро, можно перезапускать цикл много раз, получая максимально качественные модели. Например, после следующего перезапуска и сортировки, получился такой вариант:
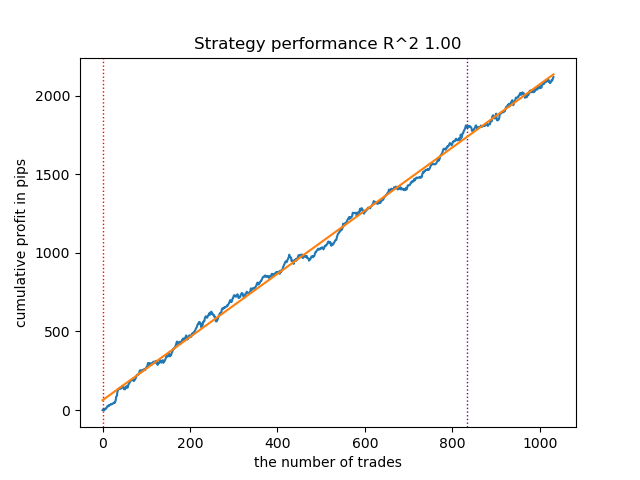
Рис 3. Тестирование лучшей модели после повторного цикла обучения
Обучение на скользящих средних и стандартных отклонениях
Давайте изменим наши признаки и посмотрим, как покажут себя модели.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).mean() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
В качестве основных признаков будут использоваться простые скользящие средние, а в качестве мета-признаков - стандартные отклонения.
Запустим цикл обучения и посмотрим на лучшие модели:
Iteration: 0, Cluster: 0 R2: 0.9312180471969619 Iteration: 0, Cluster: 1 R2: 0.9839766532391275 too few samples: 101 Iteration: 0, Cluster: 3 R2: 0.9643925934007344 too few samples: 299 Iteration: 0, Cluster: 5 R2: 0.9960009821184868 too few samples: 19 Iteration: 0, Cluster: 7 R2: 0.9557947960449501 Iteration: 0, Cluster: 8 R2: 0.9747160963596306 Iteration: 0, Cluster: 9 R2: 0.5526910449937035 Время выполнения: 2.8627688884735107
Так выглядит в тестере лучшая модель:
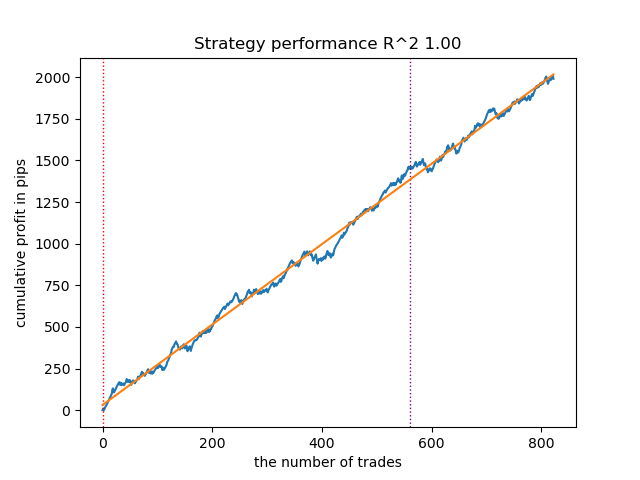
Рис 4. Тестирование лучшей модели на скользящих средних
Вторая по качеству модель тоже демонстрирует неплохой результат:
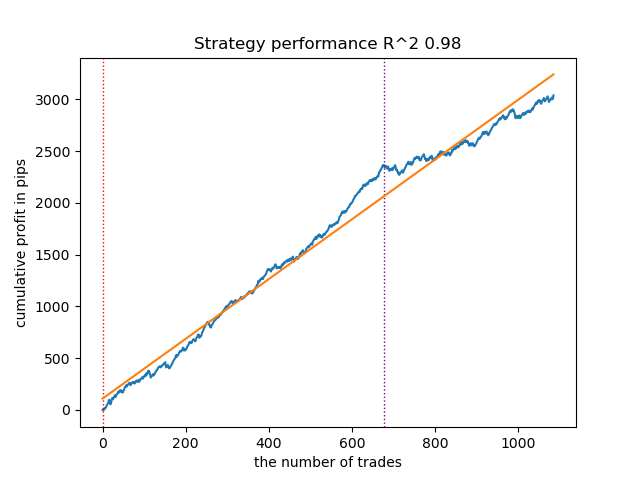
Рис 5. Тестирование второй модели на скользящих средних
Перезапустив цикл обучения еще несколько раз, я получил более аккуратный график баланса:
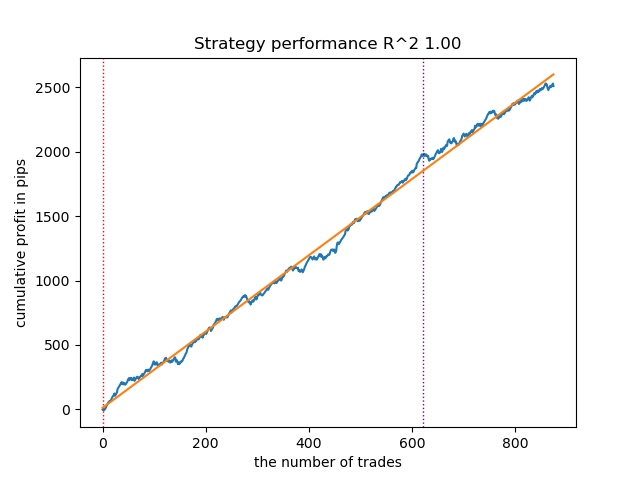
Рис 6. Тестирование лучшей модели после повторного цикла обучения
Здесь я не экспериментировал с количеством признаков (списком их периодов), поэтому, в действительности, можно получать большое разнообразие таких моделей. Представленные скриншоты просто демонстрируют некоторые варианты.
Борьба с переобучением
Часто бывает, что чрезмерная сложность модели оказывает негативный эффект на ее обобщающие способности. Даже с учетом валидационного участка и раннего останова. В этом случае можно попытаться уменьшить количество признаков и/или снизить сложность модели. Под сложностью модели в алгоритме CatBoost подразумевается количество итераций или последовательно построенных деревьев принятия решений. В функции fit_final_models() попробуйте изменить следующие значения:
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False)
Снизьте количество итераций до 100 и значение раннего останова до 15. Это позволит построить менее сложную модель.
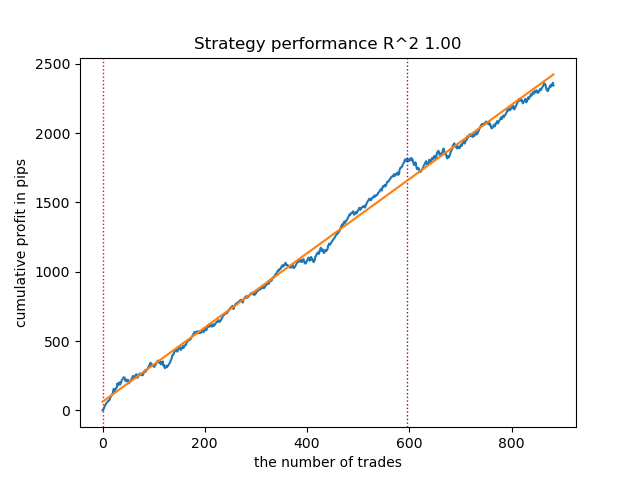
Рис 7. Тестирование менее "сложной" модели
Экспорт моделей в терминал Meta Trader 5
Функция export_model_to_ONNX() из модуля export_lib() содержит следующие строки:
# get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathMean(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathSkewness(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n'
Выделенные строки отвечают за расчет признаков в MQL5 коде. В том случае, если вы изменяете признаки в Python скрипте в функции get_features(), как это было описано выше, вам необходимо изменить их расчет в этом коде, либо вы можете сделать это в уже экспортированном .mqh файле.
Например, в экспортированном файле XAUUSD_H1 ONNX include 0.mqh нужно исправить следующие строки:
#include <Math\Stat\Math.mqh> #resource "catmodel XAUUSD_H1 0.onnx" as uchar ExtModel_XAUUSD_H1_0[] #resource "catmodel_m XAUUSD_H1 0.onnx" as uchar ExtModel2_XAUUSD_H1_0[] int PeriodsXAUUSD_H1_0[10] = {5,35,65,95,125,155,185,215,245,275}; int Periods_mXAUUSD_H1_0[1] = {5}; void fill_araysXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(PeriodsXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,PeriodsXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); // ret[0] = MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); } void fill_arays_mXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods_mXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods_mXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Теперь расчет признаков соответствует расчету функции get_features(), в которой использовались только стандартные отклонения. Если использовались скользящие средние, то следует заменить на MathMean().
После компиляции, можно протестировать бота уже в терминале Meta Trader 5.
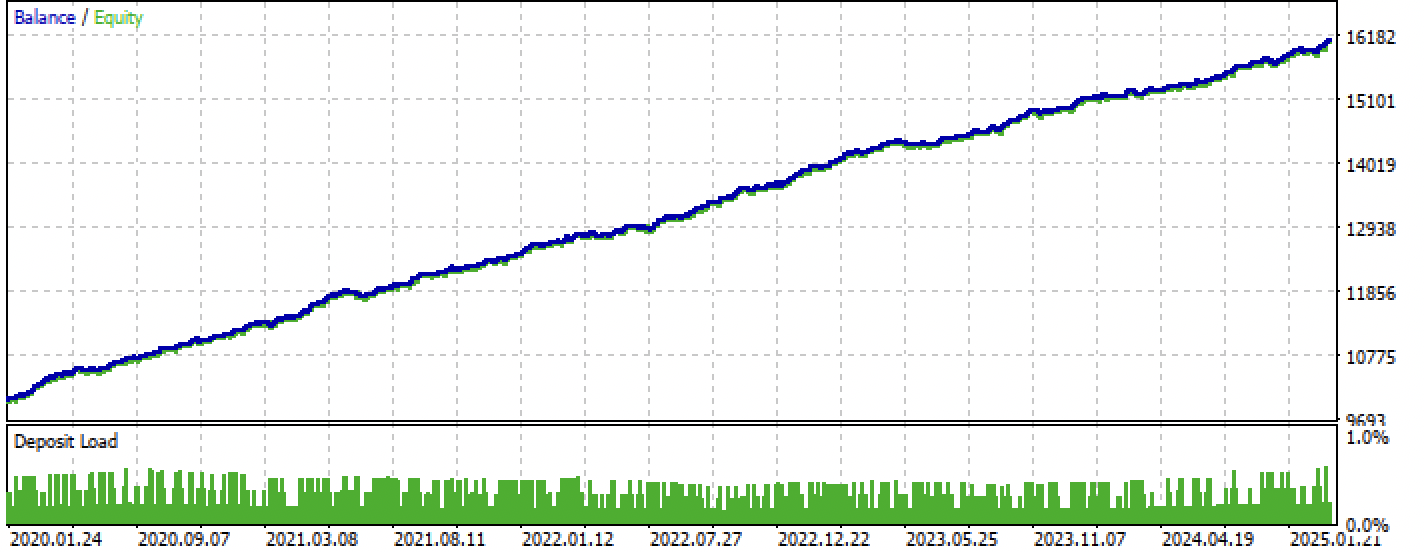
Рис 8. Тестирование на интервале обучение + форвард
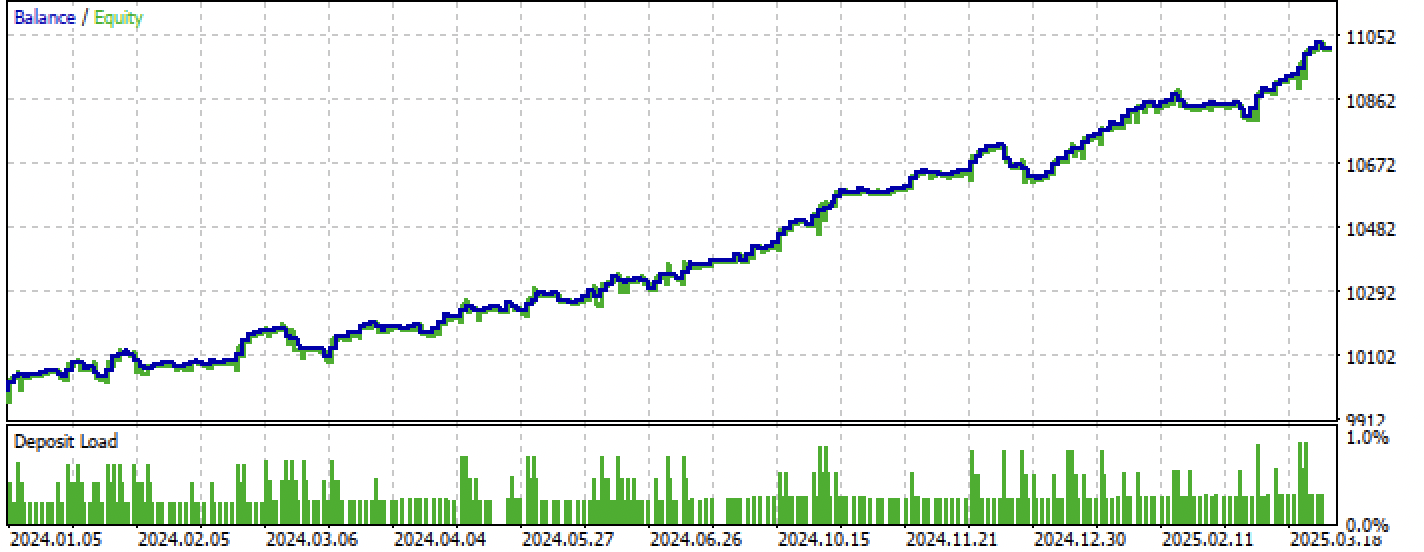
Рис 9. Тестирование только на форвард периоде
Заключение
В данной статье продемонстрирован еще один способ создания однонаправленных трендовых стратегий, но уже на основе кластеризации. Основным отличием данного подхода является его интуитивность и высокая скорость обучения. Качество получаемых моделей сопоставимо с тем, что было в предыдущей статье.
Архив Python files.zip содержит следующие файлы для разработки в среде Python:
| Имя файла | Описание |
|---|---|
| one direction clusters.py | Основной скрипт для обучения моделей |
| labeling_lib.py | Обновленный модуль с разметчиками сделок |
| tester_lib.py | Обновленный кастомный тестер стратегий, основанных на машинном обучении |
| export_lib.py | Модуль для экспорта моделей в терминал |
| XAUUSD_H1.csv | Файл с котировками, экспортированный из терминала MetaTrader 5 |
Архив MQL5 files.zip cодержит файлы для терминала MetaTrader 5:
| Имя файла | Описание |
|---|---|
| one direction clusters.ex5 | Скомпилированный бот из данной статьи |
| one direction clusters.mq5 | Исходник бота из статьи |
| папка Include//Trend following | Расположены модели ONNX и заголовочный файл для подключения к боту |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Так у вас же R2 это модифицированный показатель, эффективность которого основывается на профите в пипсах. А как же просадка и другие показатели эффективности? Если мы получим модель которая на обучении выдает более 90% и на тесте не менее 85%, то и ваш показатель выдаст внушительные цифры. Я вот сколько ни гонял тестер на MT5 ни разу не получил профита на истории. Депозит сливается. Это при том, что ваш тестер на питоне выдает 0.97-0.98
Не понял какое отношение это имеет к CV.
Все эти стратегии имеют низкую доказательную способность, потому что основаны только на истории нестационарных котировок. Но можно ловить тренды.Так а где здесь ИИ? Вы катбуст повысили до этого уровня? Или это обычный маркетинговый трюк для завлечения аудитории?
В нескольких последних публикациях разных авторов заметил эту странную особенность.
А кроме катбуста нет достойных моделей?
Так а где здесь ИИ? Вы катбуст повысили до этого уровня? Или это обычный маркетинговый трюк для завлечения аудитории?
В нескольких последних публикациях разных авторов заметил эту странную особенность.
А кроме катбуста нет достойных моделей?
Кликбейт (популярная аббревиатура). Не являюсь вообще сторонником этого термина.
Люди привыкли называть МО как "ИИ". Плюс ТС представляет собой комплекс разных МО алгоритмов, например кластеризации и классификации.