
Машинное обучение и Data Science (Часть 26): Решающая битва в прогнозирование временных рядов — LSTM против GRU

Содержание
- Что такое нейронная сеть долгой кратковременной памяти LSTM?
- Математика в основе сетей LSTM
- Что такое нейронная сеть с управляемым рекуррентным блоком (GRU)?
- Математика в основе сетей GRU
- Построение родительского класса для сетей LSTM и GRU
- Дочерние классы нейронных сетей LSTM и GRU
- Обучение моделей
- Проверка важности признаков в моделях
- Классификаторы LSTM и GRU в тестере стратегий
- Различия между моделями нейронных сетей LSTM и GRU
- Заключение
Что такое нейронная сеть долгой кратковременной памяти LSTM?
Долгая кратковременная память (LSTM) — это тип рекуррентной нейронной сети, разработанный для решения задач последовательностей. Этот тип отлично подходит для сбора и использования долгосрочных зависимостей в данных. В отличие от простых рекуррентных нейронных сетей RNN, о которых мы говорили в предыдущей статье в этой серии (обязательно к прочтению), которые не могут уловить долгосрочные зависимости в данных,
сети LSTM были представлены для исправления кратковременной памяти, которая преобладает в простых RNN.
Недостатки простых рекуррентных нейросетей
Простые рекуррентные нейронные сети RNN предназначены для обработки последовательных данных с помощью внутреннего скрытого состояния (памяти) для сбора информации о предыдущих входах в последовательности. Несмотря на их концептуальную простоту и первоначальный успех в моделировании последовательных данных, они имеют ряд ограничений.
Одной из важных проблем является проблема исчезающего градиента. В процессе обратного распространения градиенты используются для обновления весов сети. В простых рекуррентных нейросетях эти градиенты могут уменьшаться экспоненциально по мере их распространения в обратном направлении во времени, особенно для длинных последовательностей. Это приводит к неспособности сети изучать долгосрочные зависимости, поскольку градиенты становятся слишком малыми для эффективного обновления весов. Это затрудняет понимание простыми RNN закономерностей, охватывающих множество временных шагов.
Еще одна проблема — это проблема взрыва градиента, что является противоположностью проблемы исчезающего градиента. В этом случае градиенты растут экспоненциально в процессе обратного распространения. Это может привести к численной нестабильности и значительно усложнить процесс обучения. Хотя градиентный взрыв встречается реже, чем исчезающие градиенты, он может приводить к чрезвычайно большим обновлениям весов сети, что фактически приведет к сбою процесса обучения.
Простые рекуррентные нейронные сети также трудно обучать из-за их восприимчивости как к исчезающим, так и к взрывным градиентам. Это может сделать процесс обучения неэффективным и медленным. Обучение простых RNN может быть более затратным с точки зрения вычислений и может потребовать тщательной настройки гиперпараметров.
Кроме того, простые RNN не способны обрабатывать сложные временные зависимости в данных. Из-за ограниченного объема памяти им часто трудно понять и уловить сложные последовательные закономерности.
Для задач, требующих понимания долгосрочных зависимостей в данных, простые RNN могут не покрыть весь необходимый контекст, что приведет к неоптимальным результатам.
Математика в основе сетей LSTM
Чтобы понять суть LSTM, давайте начнем с рассмотрения ячейки LSTM.

01: Врата забвения
Задается следующим уравнением:
![]()
Сигмовидная функция ![]() принимает в качестве входных данных предыдущее скрытое состояние
принимает в качестве входных данных предыдущее скрытое состояние ![]() и текущие входные данные
и текущие входные данные ![]() . Результат
. Результат ![]() — это значение от 0 до 1, указывающее, сколько каждого компонента в
— это значение от 0 до 1, указывающее, сколько каждого компонента в ![]() (предыдущее состояние ячейки) нужно сохранить.
(предыдущее состояние ячейки) нужно сохранить.
![]() - вес врат забвения
- вес врат забвения
![]() - сдвиг врат забвения
- сдвиг врат забвения
Врата забывания определяют, какую информацию из предыдущего состояния ячейки следует перенести далее. Выводится значение от 0 до 1 для каждого числа в состоянии ячейки ![]() , где 0 означает полное забвение, а 1 — сохранение целиком.
, где 0 означает полное забвение, а 1 — сохранение целиком.
02: Входные ворота
Задаются формулой:
![]()
Сигмовидная функция ![]() определяет, какие значения следует обновить. Эти врата (так же называют вентилем) управляют вводом новых данных в ячейку памяти.
определяет, какие значения следует обновить. Эти врата (так же называют вентилем) управляют вводом новых данных в ячейку памяти.
![]() - вес входных ворот.
- вес входных ворот.
![]() - сдвиг входных ворот.
- сдвиг входных ворот.
Врата решают, какие значения из входных данных ![]() использовать для обновления состояния ячейки. Они регулируют ввод новой информации в клетку.
использовать для обновления состояния ячейки. Они регулируют ввод новой информации в клетку.
03: Candidate Memory Cell
Задается следующим уравнением:
![]()
Функция tanh генерирует потенциально новую информацию, которую можно сохранить в состоянии ячейки.
![]() - вес кандидата на добавление в ячейку памяти.
- вес кандидата на добавление в ячейку памяти.
![]() - сдвиг кандидата на добавление в ячейку памяти.
- сдвиг кандидата на добавление в ячейку памяти.
Этот компонент генерирует новые значения-кандидаты, которые можно добавить к состоянию ячейки. Он использует функцию активации tanh, чтобы получить значения в диапазоне от -1 до 1.
04: Обновление состояния ячейки
Задается следующим уравнением:
![]()
Предыдущее состояние ячейки ![]() умножается на
умножается на ![]() (результат ворот забвения), чтобы отбросить неважную информацию. Затем
(результат ворот забвения), чтобы отбросить неважную информацию. Затем ![]() (выходной сигнал входного вентиля) умножается на
(выходной сигнал входного вентиля) умножается на ![]() (кандидат в статус ячейки), а результаты суммируются для формирования нового состояния ячейки
(кандидат в статус ячейки), а результаты суммируются для формирования нового состояния ячейки ![]() .
.
Состояние ячейки обновляется путем объединения старого состояния ячейки и значений-кандидатов. Выходной сигнал ворот забвения (забывающего вентиля) контролирует вклад предыдущего состояния ячейки, а выходной сигнал входного вентиля контролирует вклад новых значений-кандидатов.
05: Выходной вентиль
Задается следующим уравнением:
![]()
Сигмовидная функция определяет, какие части состояния ячейки следует выводить. Этот вентиль управляет выводом информации из ячейки памяти.
![]() - вес выходного слоя
- вес выходного слоя
![]() - сдвиг выходного слоя
- сдвиг выходного слоя
Этот вентиль определяет конечный выходной сигнал для текущего состояния ячейки. Он решает, какие части состояния ячейки нужно вывести на основе входных данных ![]() и предыдущего скрытого состояния
и предыдущего скрытого состояния ![]() .
.
06: Обновление скрытого состояния
Задается следующим уравнением:
![]()
Новое скрытое состояние ![]() получается путем умножения выходного вентиля
получается путем умножения выходного вентиля ![]() на тангенс обновленного состояния ячейки
на тангенс обновленного состояния ячейки ![]() .
.
Скрытое состояние обновляется на основе состояния ячейки и решения выходного вентиля. Используется как выход для текущего временного шага и как вход для следующего временного шага.
Что такое нейронная сеть с управляемым рекуррентным блоком (GRU)?
Gated Recurrent Unit (GRU) — это тип рекуррентной нейронной сети (RNN), которая в некоторых случаях имеет преимущества перед долгой кратковременной памятью (LSTM). GRU использует меньше памяти и работает быстрее, чем LSTM, однако сеть LSTM более точна при использовании наборов данных с более длинными последовательностями.
Сети LSTM и GRU были разработаны для исправления кратковременной памяти, которая преобладает в простых рекуррентных нейронных сетях. У обоих видов долговременная память активируется с помощью ворот в их клетках.
Несмотря на то, что во многих отношениях LSTM и GRU работают аналогично простым RNN, они решают проблему исчезающего градиента, от которой страдают простые рекуррентные нейронные сети.
Математика в основе сетей GRU
На изображении ниже показано, как выглядит ячейка сети GRU в разрезе.

01: Врата обновления
Задаются формулой:
![]()
Этот вентиль определяет, какая часть предыдущего скрытого состояния ![]() следует сохранить и какую часть кандидата на скрытое состояние
следует сохранить и какую часть кандидата на скрытое состояние ![]() нужно использовать для обновления скрытого состояния.
нужно использовать для обновления скрытого состояния.
Вентиль обновления контролирует, какую часть предыдущего скрытого состояния ![]() нужно перенести на следующий временной шаг. Он эффективно определяет баланс между сохранением старой информации и включением новой.
нужно перенести на следующий временной шаг. Он эффективно определяет баланс между сохранением старой информации и включением новой.
02: Врата сброса
Задаются формулой:
![]()
Сигмовидная функция ![]() в этом вентиле определяет части предыдущего скрытого состояния, которые следует сбросить перед объединением с текущим входом для создания кандидата в функцию активации.
в этом вентиле определяет части предыдущего скрытого состояния, которые следует сбросить перед объединением с текущим входом для создания кандидата в функцию активации.
03: Кандидат в функцию активации
Задаются формулой:
![]()
Кандидата в активацию вычисляется с использованием текущего входного сигнала ![]() и сброса скрытого состояния
и сброса скрытого состояния![]() .
.
Этот компонент генерирует новые потенциальные значения для скрытого состояния, которые могут быть включены на основе решения вентиля обновления.
04: Обновление скрытого состояния
Задаются формулой:
![]()
Выходной сигнала врат обновления ![]() определяет, какая часть потенциального скрытого состояния
определяет, какая часть потенциального скрытого состояния ![]() используется для формирования нового скрытого состояния
используется для формирования нового скрытого состояния ![]() .
.
Скрытое состояние обновляется путем объединения предыдущего скрытого состояния и потенциального скрытого состояния. Вентиль обновления ![]() контролирует эту комбинацию, чтобы соответствующая информация из прошлого сохраняется при включении новой информации.
контролирует эту комбинацию, чтобы соответствующая информация из прошлого сохраняется при включении новой информации.
Построение родительского класса для сетей LSTM и GRU
Поскольку LSTM и GRU во многом работают схожим образом и используют одни и те же параметры, удобно создать базовый(родительский) класс для функций, необходимых для построения, компиляции, оптимизации, проверки важности признаков и сохранения моделей. Этот класс затем будет наследоваться в классах-наследниках LSTM и GRU.
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx import optuna import shap from sklearn.metrics import accuracy_score class RNNClassifier(): def __init__(self, time_step, x_train, y_train, x_test, y_test): self.model = None self.time_step = time_step self.x_train = x_train self.y_train = y_train self.x_test = x_test self.y_test = y_test # a crucial function that all the subclasses must implement def build_compile_and_train(self, params, verbose=0): raise NotImplementedError("Subclasses should implement this method") # a function for saving the RNN model to onnx & the Standard scaler parameters def save_onnx_model(self, onnx_file_name): # optuna objective function to oprtimize def optimize_objective(self, trial): # optimize for 50 trials by default def optimize(self, n_trials=50): def _rnn_predict(self, data): def check_feature_importance(self, feature_names):
Оптимизация сетей LSTM и GRU с помощью Optuna
Как уже говорилось раньше, нейронные сети очень чувствительны к гиперпараметрам. Без правильной настройки и оптимизации параметров эффективность нейронных сетей будет под вопросом.
Python
def optimize_objective(self, trial): params = { "neurons": trial.suggest_int('neurons', 10, 100), "n_hidden_layers": trial.suggest_int('n_hidden_layers', 1, 5), "dropout_rate": trial.suggest_float('dropout_rate', 0.1, 0.5), "learning_rate": trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True), "hidden_activation_function": trial.suggest_categorical('hidden_activation_function', ['relu', 'tanh', 'sigmoid']), "loss_function": trial.suggest_categorical('loss_function', ['categorical_crossentropy', 'binary_crossentropy', 'mean_squared_error', 'mean_absolute_error']) } val_accuracy = self.build_compile_and_train(params, verbose=0) # we build a model with different parameters and train it, just to return a validation accuracy value return val_accuracy # optimize for 50 trials by default def optimize(self, n_trials=50): study = optuna.create_study(direction='maximize') # we want to find the model with the highest validation accuracy value study.optimize(self.optimize_objective, n_trials=n_trials) return study.best_params # returns the parameters that produced the best performing model
Метод optimize_objective определяет целевую функцию для оптимизации гиперпараметров с использованием фреймворка Optuna. Во время оптимизации ищется наилучший набора гиперпараметров, при котором работа модели будет наилучшей.
Метод Optimize использует фреймворк Optuna для оптимизации гиперпараметров путем многократного вызова метода optimize_objective.
Проверка важности признаков с помощью SHAP
Измерение того, насколько сильно признаки влияют на прогнозы модели, важно при обработке данных. Это может не только помочь выявить возможности для ключевых улучшений, но и лучше понимать конкретные наборы данных о моделях.
def check_feature_importance(self, feature_names): # Sample a subset of training data for SHAP explainer sampled_idx = np.random.choice(len(self.x_train), size=100, replace=False) explainer = shap.KernelExplainer(self._rnn_predict, self.x_train[sampled_idx].reshape(100, -1)) # Get SHAP values for the test set shap_values = explainer.shap_values(self.x_test[:100].reshape(100, -1), nsamples=100) # Update feature names for SHAP feature_names = [f'{feature}_t{t}' for t in range(self.time_step) for feature in feature_names] # Plot the SHAP values shap.summary_plot(shap_values, self.x_test[:100].reshape(100, -1), feature_names=feature_names, max_display=len(feature_names), show=False) # Adjust layout and set figure size plt.subplots_adjust(left=0.12, bottom=0.1, right=0.9, top=0.9) plt.gcf().set_size_inches(7.5, 14) plt.tight_layout() # Get the class name of the current instance class_name = self.__class__.__name__ # Create the file name using the class name file_name = f"{class_name.lower()}_feature_importance.png" plt.savefig(file_name) plt.show()
Сохранение классификаторов LSTM и GRU в форматах моделей ONNX
Созданные модели нужно сохранить в формате ONNX, который совместим с MQL5.
def save_onnx_model(self, onnx_file_name):
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, self.time_step, self.x_train.shape[2]), tf.float16, name="input"),)
self.model.output_names = ['outputs']
onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open(onnx_file_name, "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the mean and scale parameters to binary files
scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin")
scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
Классы-наследники нейронных сетей LSTM и GRU
Рекуррентные нейронные сети работают во многом схожим образом, даже их реализация с использованием библиотеки Keras использует аналогичный подход и параметры. Их основное отличие — тип модели, а все остальное не меняется.
LSTM-классификатор
Python
class LSTMClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(LSTM(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
GRU-классификатор
Python
class GRUClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(GRU(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
Как видно из классификаторов унаследованных классов, единственное отличие заключается в типе модели: и LSTM, и GRU используют схожий подход.
Обучение моделей
Для начала необходимо инициализировать экземпляры классов для обеих моделей. Начнем с модели LSTM.
lstm_clf = LSTMClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
Затем инициализируем модель GRU.
gru_clf = GRUClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
После оптимизируем обе модели по 20 проходам;
best_params = lstm_clf.optimize(n_trials=20)
best_params = gru_clf.optimize(n_trials=20) Модель классификатора LSTM на 19-м проходе оказалась лучшей.
[I 2024-07-01 11:14:40,588] Trial 19 finished with value: 0.5597269535064697 and parameters: {'neurons': 79, 'n_hidden_layers': 4, 'dropout_rate': 0.335909076638275, 'learning_rate': 3.0704319088493336e-05, 'hidden_activation_function': 'relu', 'loss_function': 'categorical_crossentropy'}. Best is trial 19 with value: 0.5597269535064697.
Между тем, модель классификатора GRU, полученная на проходе 3, показала точность приблизительно 55,97% по данным проверки и оказалась лучшей из всех моделей.
[I 2024-07-01 11:18:52,190] Trial 3 finished with value: 0.532423198223114 and parameters: {'neurons': 55, 'n_hidden_layers': 5, 'dropout_rate': 0.2729838602302831, 'learning_rate': 0.009626688728041802, 'hidden_activation_function': 'sigmoid', 'loss_function': 'mean_squared_error'}. Best is trial 3 with value: 0.532423198223114.
Точность на этих данных составила около 53,24%.
Проверка важности признаков в моделях
| LSTM-классификатор | GRU-классификатор |
|---|---|
feature_importance = lstm_clf.check_feature_importance(X.columns) Результат. 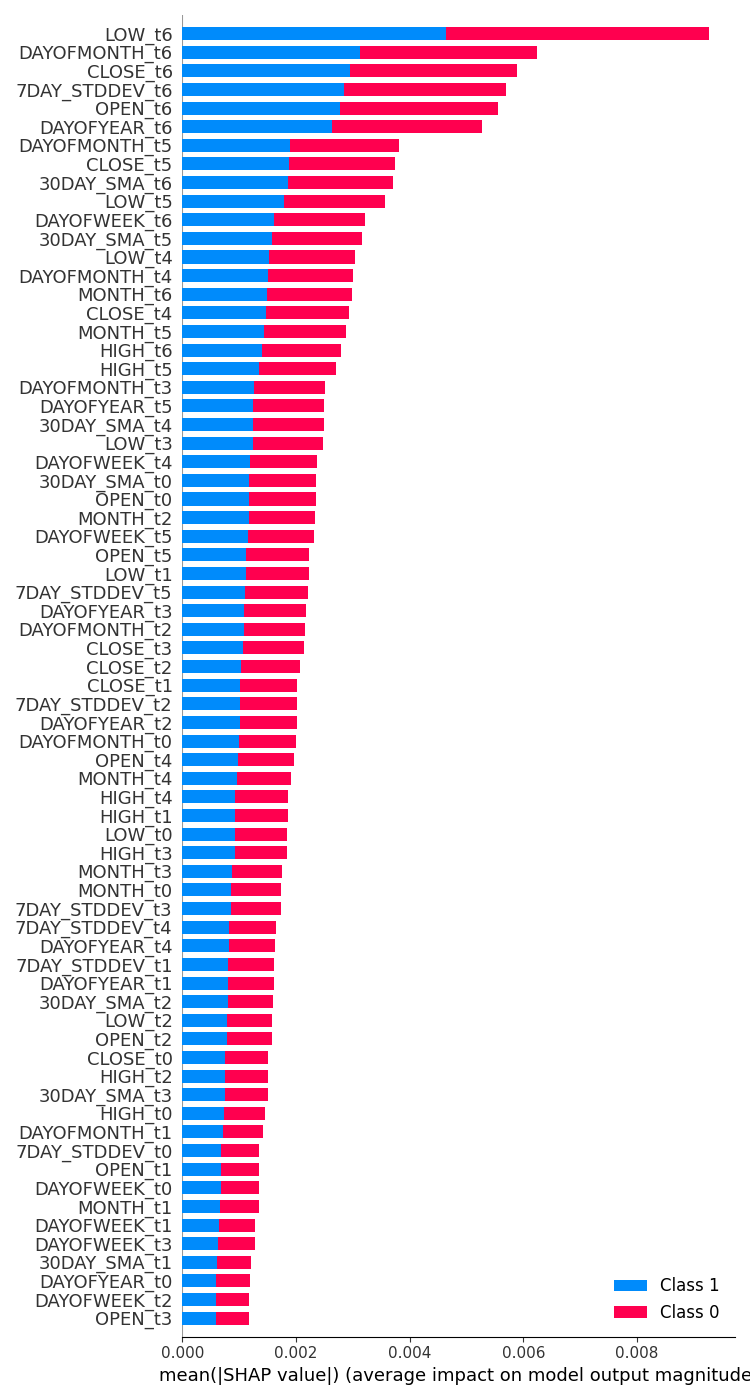 | feature_importance = gru_clf.check_feature_importance(X.columns) Результат.  |
Важность признаков классификатора LSTM чем-то похожа на результат, полученный с помощью простой модели RNN. Наименее важные переменные относятся к старым временным интервалам, тогда как наиболее важные признаки относятся к более близким временным интервалам.
Таким образом, переменные, которые вносят наибольший вклад в то, что происходит с текущим баром, — это информация о недавнем закрытом баре.
У классификатора GRU было иное мнение, которое, похоже, далеко от правды. Это могло произойти из-за того, что модель GRU имела более низкую точность.
по ее результатам, наиболее влиятельной переменной является день недели 7 дней назад. Такие признаки, как цены открытия, максимума, минимума и закрытия со значением временного шага 6, то есть самая последняя информация, оказались в середине, как будто они внесли средний вклад в конечный результат прогноза.
Классификаторы LSTM и GRU в тестере стратегий
После обучения мы сохранили модели классификаторов LSTM и GRU в формате ONNX.
LSTM | Python
lstm_clf.build_compile_and_train(best_params, verbose=1) # best_params = best parameters obtained after optimization lstm_clf.save_onnx_model("lstm.EURUSD.D1.onnx")
GRU | Python
gru_clf.build_compile_and_train(best_params, verbose=1) gru_clf.save_onnx_model("gru.EURUSD.D1.onnx") # best_params = best parameters obtained after optimization
Сохраняем файлы модели ONNX и масштабатора в папке MQL5\Files. Оттуда их можно использовать в составе советника.
| LSTM | GRU |
|---|---|
#resource "\\Files\\lstm.EURUSD.D1.onnx" as uchar onnx_model[]; //lstm model in onnx format #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\LSTM.mqh> CLSTM lstm; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique | #resource "\\Files\\gru.EURUSD.D1.onnx" as uchar onnx_model[]; //gru model in onnx format #resource "\\Files\\gru.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\gru.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\GRU.mqh> CGRU gru; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique |
Код остальных советников не меняется, мы его обсуждали ранее.
Мы используем те же настройки по умолчанию, которые мы использовали начиная с Части 24 этой серии статей, в которой мы начали изучать прогнозирование временных рядов.
Стоп-лосс: 500, тейк-профит: 700, проскальзывание: 50.
Опять же, поскольку данные были собраны с дневного таймфрейма, было бы неплохо протестировать их на более низком таймфрейме, чтобы избежать ошибок market closed, поскольку торговые сигналы проверяются при открытии нового бара. Можно установить тип моделирования по ценам открытия для более быстрого тестирования.

Результаты советника с LSTM


Результаты советника с GRU


О чем говорят результаты тестирования?
Несмотря на то, что модель на основе LSTM оказалась наименее точной (44,98%), она оказалась наиболее прибыльной, принеся чистую прибыль в размере 138 $. За ней следует советник на основе модели GRU, который хоть и совершил в прибыль только 45,25% сделок, общая чистая прибыль составила 120 $.
В этом случае LSTM — явный победитель с точки зрения прибыльности. Несмотря на то, что LSTM технически более продвинут, чем другие подобные сети RNN, на результат могут влиять множество факторов. Все рекуррентные модели хороши и могут превосходить другие в определенных ситуациях. Вы можете поэкспериментировать и с другими моделями, обсуждаемых в этой и предыдущей статьях, и сравнить результаты.
Различия между моделями нейронных сетей LSTM и GRU
Давайте сравним эти модели и посмотрим на их различия. Попробуем определить, когда их стоит использовать, а когда — нет. В таблице ниже показаны их различия.
| Параметр | LSTM | GRU |
|---|---|---|
Сложность архитектуры | LSTM имеют более сложную архитектуру с тремя вентилями (вход, выход, забывание) и состоянием ячейки, которые обеспечивают строгий контроль над тем, какая информация сохраняется или отбрасывается на каждом временном шаге. | У модели GRU архитектура более простая, всего с двумя воротами (сброс и обновление). Такая простая архитектура несомненно упрощает реализацию. |
Скорость обучения | Наличие дополнительных вентилей и состояния ячейки в LSTM означает, что придется выполнить больше процессов и оптимизировать больше параметров. Обучение будет более медленным. | Благодаря меньшему количеству ворот и более простой работе, такие сети обычно обучаются быстрее, чем LSTM. |
Эффективность | В сложных задачах, где учет долгосрочных зависимостей имеет решающее значение, LSTM-сети, как правило, работают немного лучше своих аналогов. | Сети GRU обычно обеспечивают сопоставимую с LSTM производительность для многих задач. |
Обработка долгосрочных зависимостей | LSTM-сети специально разработаны для сохранения долгосрочных зависимостей в данных благодаря состоянию ячеек и механизмам пропускания, которые контролируют поток информации во времени. | Хотя GRU также хорошо справляются с долгосрочными зависимостями, они могут быть не столь эффективны, как LSTM, при понимании более долгосрочных зависимостей из-за своей более простой структуры. |
| Память | Из-за сложной структуры и дополнительных параметров LSTM потребляют больше памяти, что может стать ограничением в средах с ограниченными ресурсами. | С другой стороны, сети GRU проще, имеют меньше параметров и используют меньше памяти. Это делает их более подходящими для приложений с ограниченными вычислительными ресурсами. |
Заключительные мысли
Нейронные сети LSTM (долгая кратковременная память) и GRU (управляемый рекуррентный блок) являются мощными инструментами для трейдеров, которые хотят использовать современные модели прогнозирования временных рядов. LSTM-сети имеют более сложную архитектуру, которая отлично подходит для понимания более долгих зависимостей в рыночных данных. При этом сети GRU являются более простой и эффективной альтернативой, которая часто может сравниться по производительности с LSTM-сетями при меньших вычислительных затратах.
Эти модели глубокого обучения для прогнозирования временных рядов (LSTM и GRU) широко и довольно успешно используются в различных областях помимо Форекс-трейдинга, например, прогнозирование погоды, моделирование потребления энергии, обнаружение аномалий и распознавание речи. Однако на постоянно меняющемся рынке Форекс сложно гарантировать стабильно высокие результаты.
Целью этой статьи было только в деталях разобрать эти модели и показать, как их можно развернуть в MQL5 для торговли. Изучайте сами и поиграйтесь с моделями и наборами данных, о которых мы говорили в этой статье. Делитесь результатами в комментариях.
С наилучшими пожеланиями.
За развитием этой модели машинного обучения и других из этой серии статей можно следить в моем репозиторий на GitHub.
Таблица вложений
| Название файла | Тип файла | Описание и использование |
|---|---|---|
| GRU EA.mq5 LSTM EA.mq5 | Советники | Советник на основе модели GRU. Советник на основе модели LSTM. |
| gru.EURUSD.D1.onnx lstm.EURUSD.D1.onnx | Файлы ONNX | Модель GRU в формате ONNX. Модель LSTM в формате ONNX. |
| lstm.EURUSD.D1.standard_scaler_mean.bin lstm.EURUSD.D1.standard_scaler_scale.bin | Бинарные файлы | Бинарные файлы для стандартного масштабатора, используемого для модели LSTM. |
| gru.EURUSD.D1.standard_scaler_mean.bin gru.EURUSD.D1.standard_scaler_scale.bin | Бинарные файлы | Бинарные файлы для стандартного масштабатора, используемого для модели GRU. |
| preprocessing.mqh | Включаемый файл | Библиотека стандартного масштабатора. |
| lstm-gru-for-forex-trading-tutorial.ipynb | Скрипт Python/Блокнот Jupyter | Содержит весь код Python, обсуждаемый в этой статье. |
- Illustrated Guide to LSTM's and GRU's: A step by step explanation
- Designing neural network based decoders for surface codes
- An Adaptive Anti-Noise Neural Network for Bearing Fault Diagnosis Under Noise and Varying Load Conditions
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15182
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Машинное обучение и Data Science (Часть 27): Сверточные нейросети (CNN) в торговых роботах для MetaTrader 5
Машинное обучение и Data Science (Часть 27): Сверточные нейросети (CNN) в торговых роботах для MetaTrader 5
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования