
ニューラルネットワークが簡単に(第12回): ドロップアウト

内容
- はじめに
- 1. ドロップアウト: ニューラルネットワークの収束を高める方法
- 2. 実装
- 2.1. モデルでの新しいクラスの作成
- 2.2. フィードフォワード
- 2.3. フィードバックワード
- 2.4. データの保存メソッドと読み込みメソッド
- 2.5. ニューラルネットワーク基本クラスの変更
- 3. 検証
- 終わりに
- 参照文献
- 記事で使用されたプログラム
はじめに
この連載の開始以来、さまざまなニューラルネットワークモデルの研究ではすでに大きな進歩を遂げていますが、学習プロセスは常に私たちの参加なしに実行されました。同時に、ニューラルネットワークが訓練結果を何らかの形で改善したいという願望は常にあります。これは、ニューラルネットワークの収束とも呼ばれます。本稿では、そのような手法の1つである「ドロップアウト」について考察します。
1. ドロップアウト: ニューラルネットワークの収束を高める方法
ニューラルネットワークを訓練する場合、多数の機能が各ニューロンに供給され、それぞれの個別の特徴の影響を評価することは困難です。その結果、一部のニューロンのエラーは他のニューロンの正しい値によって平滑化されますが、これらのエラーはニューラルネットワークの出力に蓄積されます。これにより、かなり大きなエラーによって訓練が特定の極小値で停止します。この効果は、特徴検出器の共適応と呼ばれ、各特徴の影響が環境に適応します。環境が個別の特徴に分解され、各特徴の影響を個別に評価できる場合は、逆の効果がある方がよいでしょう。
2012年、トロント大学の科学者グループは、複雑な共適応問題の解決策として、ニューロンの一部を学習プロセスからランダムに除外することを提案しました[第12部]。訓練中の特徴の数が減少すると、各特徴の重要性が増し、特徴の量的および質的構成が絶えず変化することで、それらの共適応のリスクが減少します。この手法はドロップアウトと呼ばれます。この手法の適用はよく決定木と比較されます。ニューロンの一部を削除することにより、訓練の反復ごとに独自の重みを持つ新しいニューラルネットワークを取得します。組み合わせ論の規則によれば、そのようなネットワークの変動性は非常に高くなります。
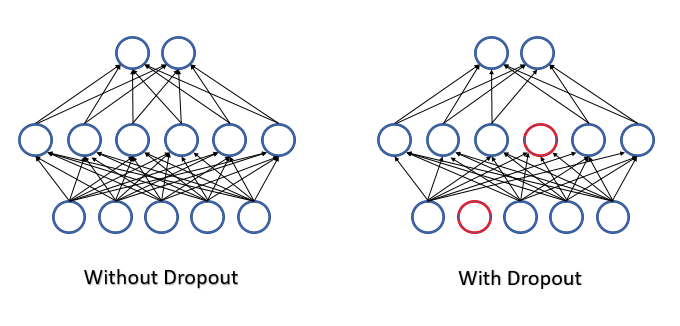
すべての機能とニューロンはニューラルネットワーク操作中に評価されるため、分析された環境の現在の状態について最も正確で独立した評価が得られます。
複数の著者は、記事(第12部)内で、事前に訓練されたモデルの品質を向上させるためにこの手法を使用する可能性について言及しています。
数学の観点からは、このプロセスは、特定の確率pでプロセスから個々のニューロンをドロップアウトすることとして説明できます。言い換えると、ニューロンはq=1-pの確率でニューラルネットワークの学習プロセスに参加します。
除外されるニューロンのリストは、正規分布の疑似乱数生成器によって決定されます。このアプローチにより、ニューロンを可能な限り均一に排除することができます。実際には、入力シーケンスに等しいサイズのベクトルを生成します。ベクトル内の1は、訓練で使用される特徴に使用され、"0"は除外する要素に使用されます。
ただし、分析された特徴を除外すると、間違いなくニューロンの活性化関数の入力での量が減少します。この影響を補正するために、各特徴の値に1/q係数を乗算します。確率qは常に0から1の範囲にあるため、この係数によって値が増加します。
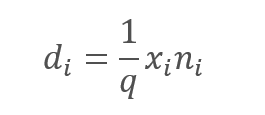 ,
,
ここで
d - ドロップアウト結果ベクトルの要素
q — 訓練プロセスでニューロンを使用する確率
x — マスキングベクトルの要素
n — 入力シーケンスの要素
学習プロセス中のフィードバックパスでは、エラー勾配に上記の関数の導関数が乗算されます。ご覧のとおり、ドロップアウトの場合、フィードバックワードパスは、フィードフォワードパスからのマスキングベクトルを使用したフィードフォワードパスと同様になります。
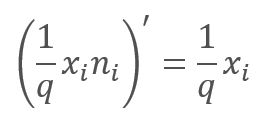
ニューラルネットワークの動作中、マスキングベクトルは1で埋められます。これにより、値を両方向にスムーズに渡すことができます。
実際には、係数1/qは訓練全体を通じて一定であるため、この係数を一度計算して、「1」の代わりにマスキングテンソルに書き込むことができます。したがって、各訓練の反復で係数を再計算してそれをマスクの「1」で乗算する操作を除外できます。
2. 実装
理論的な側面を検討したので、ライブラリにこの手法を実装するためのバリエーションの検討に移りましょう。最初に遭遇するのは、2つの異なるアルゴリズムの実装です。そのうちの1つは訓練プロセスに必要であり、もう1つは本番環境に使用されます。したがって、個々のケースでどのアルゴリズムが機能するかに従って、ニューロンに明示的に示す必要があります。この目的のために、ベースニューロンのレベルでbTrainフラグを導入します。フラグ値は、訓練の場合はtrueに設定され、テストの場合はfalseに設定されます。
class CNeuronBaseOCL : public CObject { protected: bool bTrain; ///< Training Mode Flag
次のヘルパーメソッドでフラグ値を制御します。
virtual void TrainMode(bool flag) { bTrain=flag; }///< Set Training Mode Flag virtual bool TrainMode(void) { return bTrain; }///< Get Training Mode Flag
フラグは、ベースニューロンのレベルで意図的に実装されます。これにより、今後の開発でドロップアウト関連のコードを使用できるようになります。
2.1. モデルでの新しいクラスの作成
ドロップアウトアルゴリズムを実装するために、新しいクラスCNeuronDropoutOCLを作成して、モデルに別の層として含めます。新しいクラスは、CNeuronBaseOCLベースニューロンクラスから直接継承します。protectedブロックで変数を宣言します。
- OutProbability — ニューロンドロップアウトの指定された確率。
- OutNumber — ドロップアウトされるニューロンの数
- dInitValue — マスキングベクトルを初期化するための値。本稿の理論的な部分では、この係数は1/qとして指定されていました。
また、クラスへの2つのポインタを宣言します。
- DropOutMultiplier — ドロップアウトベクトル
- PrevLayer — 前の層のオブジェクトへのポインタ(テストおよび実際の適用で使用)
class CNeuronDropoutOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL *PrevLayer; double OutProbability; double OutNumber; CBufferDouble *DropOutMultiplier; double dInitValue; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///<\brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previous layer. virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.@param NeuronOCL Pointer to previous layer. //--- int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); } ///< Generates a random neuron position to turn off public: CNeuronDropoutOCL(void); ~CNeuronDropoutOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons,double out_prob, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer #param[in] out_prob Probability of neurons shutdown @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. //--- virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); } ///< Get index of output buffer @return Index virtual int getGradientIndex(void) { return (bTrain ? Gradient.GetIndex() : PrevLayer.getGradientIndex()); } ///< Get index of gradient buffer @return Index //--- virtual int getOutputVal(double &values[]) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return (bTrain ? Gradient.GetData(values) : PrevLayer.getGradient(values)); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual CBufferDouble *getOutput(void) { return (bTrain ? Output : PrevLayer.getOutput()); } ///< Get pointer of output buffer @return Pointer to object virtual CBufferDouble *getGradient(void) { return (bTrain ? Gradient : PrevLayer.getGradient()); } ///< Get pointer of gradient buffer @return Pointer to object //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronDropoutOCL; }///< Identificator of class.@return Type of class };
クラスメソッドのリストはすべて親クラスのメソッドをオーバーライドするものであるため、お馴染みだと思います。唯一の除外は、一様分布から疑似乱数を生成するために使用されるRNDメソッドです。このメソッドのアルゴリズムは、第13部で説明されています。ニューラルネットワークのすべてのオブジェクトで可能な最大の値のランダム性を確保するために、疑似乱数シーケンス生成器は、グローバル変数を使用したマクロ置換として実装されます。
#define xor128 rnd_t=(rnd_x^(rnd_x<<11)); \ rnd_x=rnd_y; \ rnd_y=rnd_z; \ rnd_z=rnd_w; \ rnd_w=(rnd_w^(rnd_w>>19))^(rnd_t^(rnd_t>>8)) uint rnd_x=MathRand(), rnd_y=MathRand(), rnd_z=MathRand(), rnd_w=MathRand(), rnd_t=0;
提案されたアルゴリズムは、[0、UINT_MAX=4294967295]の範囲の整数のシーケンスを生成します。したがって、疑似乱数シーケンス生成器メソッドでは、マクロを実行した後、結果の値がシーケンスのサイズに正規化されます。
int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); }
連載の以前の記事を読んだことがある方は、以前のバージョンでは、他のオブジェクトのクラスデータバッファを操作するためのメソッドをオーバーライドしていなかったことにお気づきかもしれません。これらのメソッドは、ニューロンが前後の層のデータにアクセスするときに、ニューラルネットワークの層の間でデータを交換するために使用されます。
このソリューションは、実際の適用でニューラルネットワークの動作を最適化するために選択されました。ドロップアウト層はニューラルネットワークの訓練にのみ使用されます。このアルゴリズムは、テストおよび以降の適用では無効になります。データバッファアクセスメソッドをオーバーライドすることにより、ドロップアウト層をスキップできます。オーバーライドされたメソッドはすべて同じ原則に従います。データをコピーする代わりに、ドロップアウト層のバッファを前の層のバッファーに置き換えます。したがって、さらなる操作中は、ドロップアウト層を備えたニューラルネットワークの速度は、ドロップアウトを備えていない同様のネットワークの速度に匹敵しますが、訓練段階でニューロンドロップアウトのすべての利点が得られます。
virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); }
添付ファイルにはすべてのクラスメソッドのコードが全部あります。
2.2. フィードフォワード
従来通り、feedForwardメソッドにフィードフォワードパスを実装しましょう。メソッドの開始時に、受信したニューラルネットワークの前の層へのポインタとOpenCLオブジェクトへのポインタの有効性を確認します。その後、前の層で使用した活性化関数と前の層のオブジェクトへのポインタを保存します。ニューラルネットワークの実用モードの場合、ドロップアウト層のフィードフォワードパスはここで終了します。次の層からこの層にアクセスしようとすると、データバッファを置き換えるための上記のメカニズムがアクティブになります。
bool CNeuronDropoutOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- activation=(ENUM_ACTIVATION)NeuronOCL.Activation(); PrevLayer=NeuronOCL; if(!bTrain) return true;
後続の反復は、ニューラルネットワーク訓練モードにのみ関連します。まず、マスキングベクトルを生成します。このベクトルでは、このステップでドロップアウトするニューロンを定義します。DropOutMultiplierバッファにマスクを書き込み、以前に作成したオブジェクトの可用性を確認し、必要に応じて新しいオブジェクトを作成します。初期値でバッファを初期化します。計算を減らすために、増加係数1/qでバッファを初期化します。
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(NeuronOCL.Neurons(),dInitValue)) return false; for(int i=0;i<OutNumber;i++) { uint p=RND(); double val=DropOutMultiplier.At(p); if(val==0 || val==DBL_MAX) { i--; continue; } if(!DropOutMultiplier.Update(RND(),0)) return false; }
バッファの初期化後、ドロップアウトするニューロンの数に等しい繰り返し数でループを編成します。バッファのランダムに選択された要素はゼロ値に置き換えられます。1つのセルに「0」を2回書き込むリスクを回避するために、ループ内に追加のチェックを実装します。
マスクを生成した後、GPUメモリに直接バッファを作成し、データを転送します。
if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
次に、2つのベクトルを要素ごとに乗算します。この操作の結果は、ドロップアウト層の出力になります。ベクトル乗算演算は、OpenCLを使用してGPUに実装されます。要素を乗算する最も効率的な方法は、ベクトル演算を使用することです。OpenCLカーネルのdouble4型変数を使用(4つの要素のベクトル)したため、開始されるスレッドの数は、ベクトル内の要素の数の4分の1になります。
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0);
次に、初期データバッファと変数を指定し、実行のためにカーネルを起動します。
if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; }
カーネルで実行された操作の結果は、メソッドの最後に取得されます。ここで、マスキングバッファがGPUメモリから削除されます。
if(!Output.BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
操作が完了したら、メソッドをtrueで終了します。
フィードフォワードメソッドの説明はGPU側の操作なしでは不完全でしょう。これがカーネルコードです。
__kernel void Dropout (__global double *inputs, ///<[in] Input matrix __global double *map, ///<[in] Dropout map matrix __global double *out, ///<[out] Output matrix int dimension ///< Dimension of matrix )
カーネルは、初期データと結果テンソル、およびベクトルのサイズを含む2つの入力テンソルへのポインタをパラメータとして受け取ります。
カーネルコードで、スレッド番号に従って乗算する要素を決定します。その後、コードは2つのブランチに分かれます。最初のブランチがメインです。ベクトル演算を使用して、4つの連続する要素を乗算し、受信したデータを結果バッファの適切な要素に書き込みます。
{
const int i=get_global_id(0)*4;
if(i+3<dimension)
{
double4 k=(double4)(inputs[i],inputs[i+1],inputs[i+2],inputs[i+3])*(double4)(map[i],map[i+1],map[i+2],map[i+3]);
out[i]=k.s0;
out[i+1]=k.s1;
out[i+2]=k.s2;
out[i+3]=k.s3;
}
else
for(int k=i;k<min(dimension,i+4);k++)
out[i+k]=(inputs[i+k]*map[i+k]);
}
2番目のブランチは、テンソルの要素数が4の倍数でない場合にのみアクティブになり、残りの要素はループ内で乗算されます。このようなループの反復回数は3回以下であるため、タイムクリティカルではありません。
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
2.3. フィードバックワード
以前に検討されたすべてのニューロンのフィードバックパスは、次の2つのメソッドに分けられていました。
- calcInputGradients — エラー勾配を前の層に伝播
- updateInputWeights — ニューラルレイヤーの重みを更新
ドロップアウトの場合、重みテンソルはありません。ただし、オブジェクトの一般的な構造を維持するために、updateInputWeightsメソッドをオーバーライドしますが、この場合、常にtrueを返します。
virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.
calcInputGradientsメソッドの実装を検討してください。このメソッドは、パラメータとして前の層へのポインタを受け取ります。メソッドの開始時に、受信したポインタとOpenCLオブジェクトへのポインタの有効性を確認します。次に、フィードフォワードパスの場合と同様に、アルゴリズムを訓練プロセスと操作プロセスに分割します。テストモードまたは操作モードでは、ここでメソッドを終了します。これは、データバッファの置き換えにより、次のニューラルレイヤーが前の層のバッファに直接勾配を書き込み、ドロップアウト層での不要な反復を回避するためです。
bool CNeuronDropoutOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- if(!bTrain) return true;
訓練モードでは、グラデーションは別の方法で伝播されます。以下のアルゴリズムは、ニューラルネットワークの訓練プロセスにのみ関連します。フィードフォワードメソッドと同様に、マスキングバッファDropOutMultiplierへのポインタの有効性を確認します。ただし、フィードフォワードパスとは異なり、検証エラーによって新しいバッファが作成されることはありません。この場合、falseを指定してメソッドを終了します。これは、フィードバックパスがフォワードパスによって生成されたマスクを使用するためです。このアプローチにより、データの比較可能性とニューロン間のエラー勾配の正しい分布が保証されます。
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) return false; //--- if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
DropOutMultiplierオブジェクトの検証が成功したら、GPUメモリにバッファを作成し、データを入力します。
次に、2つのベクトルを要素ごとに乗算する必要があります。これはおなじみではありませんか?上記のフィードフォワードパスの説明では、まったく同じ文が示されています。はい、確かに。理論的な部分では、数学関数Dropoutの導関数が増加する係数に等しいことを確認しました。したがって、フィードバックパス中に、次の層からの勾配に、DropOutMultiplierマスキングバッファに書き込まれた増加係数を乗算します。CNeuronDropoutOCLクラスは、フィードフォワードとバックワードの両方に同じカーネルが使用されるというユニークなケースですが、これらのケースでは異なる入力データがフィードされます。フィードフォワードパスの場合はニューロンの出力データであり、 フィードバックの場合はエラー勾配です。
したがって、データバッファを指定し、カーネル実行を呼び出します。このコードはフィードフォワードコードに似ているため、追加の説明は必要ありません。
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0); if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,Gradient.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; } if(!NeuronOCL.getGradient().BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
2.4. データの保存メソッドと読み込みメソッド
ドロップアウトニューラルレイヤーオブジェクトを保存および読み込みするメソッドを見てみましょう。訓練サイクルごとに新しいマスクが生成されるため、マスクバッファオブジェクトを保存する必要はありません。CNeuronDropoutOCLクラスの初期化メソッドに追加された変数は1つだけです。それは、保存する必要があるニューロンを除外する確率です。
Saveメソッドでは、親クラスの関連するメソッドを呼び出します。正常に完了した後、ニューロンがドロップアウトする確率を保存します。
bool CNeuronDropoutOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(FileWriteDouble(file_handle,OutProbability)<=0) return false; //--- return true; }
Loadメソッドでは、ディスクからデータを読み取り、クラスのすべての要素を復元します。したがって、このメソッドアルゴリズムは、保存のアルゴリズムよりも少し複雑です。
クラス保存メソッドと同様に、親クラスのメソッド名と同じメソッドを呼び出します。完了後、ニューロンのドロップアウト確率を計算します。これで保存メソッドは完了ですが、不足している要素を復元する必要があります。ニューロンのドロップアウト確率に基づいて、除外するニューロンの数と、マスキングベクトルを初期化するための値としても機能する増加係数の値を数えましょう。
bool CNeuronDropoutOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; //--- OutProbability=FileReadDouble(file_handle); OutNumber=(int)(Neurons()*OutProbability); dInitValue=1/(1-OutProbability); if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(Neurons()+1,dInitValue)) return false; //--- return true; }
これで、計算後にマスキングベクトルを復元できます。DropOutMultiplierのデータバッファオブジェクトへのポインタが有効かどうかを確認し、必要に応じて新しいオブジェクトを作成します。次に、マスキングバッファを初期値で初期化します。
2.5. ニューラルネットワーク基本クラスの変更
繰り返しになりますが、この新しいクラスはライブラリ操作に正しく追加する必要があります。新しいカーネルを操作するためのマクロ置換の宣言から始めましょう。また、新しいクラスの識別定数を設定する必要があります。
#define def_k_Dropout 23 ///< Index of the kernel for Dropout process (#Dropout) #define def_k_dout_input 0 ///< Inputs Tensor #define def_k_dout_map 1 ///< Map Tensor #define def_k_dout_out 2 ///< Out Tensor #define def_k_dout_dimension 3 ///< Dimension of Inputs #define defNeuronDropoutOCL 0x7890 ///<Dropout neuron OpenCL \details Identified class #CNeuronDropoutOCL
次に、ニューラルレイヤーの記述方法で、ニューロンのドロップアウト確率を記録するための新しい変数を追加しましょう。
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) double probability; ///< Probability of neurons shutdown, only Dropout used };
ニューラルネットワークメソッド作成メソッドCNet::CNetの層作成および初期化ブロックで、新しい層を初期化するためのコードを追加します(以下のコードで強調表示)。
for(int i=0; i<total; i++) { prev=desc; desc=Description.At(i); if((i+1)<total) { next=Description.At(i+1); if(CheckPointer(next)==POINTER_INVALID) return; } else next=NULL; int outputs=(next==NULL || (next.type!=defNeuron && next.type!=defNeuronBaseOCL) ? 0 : next.count); temp=new CLayer(outputs); int neurons=(desc.count+(desc.type==defNeuron || desc.type==defNeuronBaseOCL ? 1 : 0)); if(CheckPointer(opencl)!=POINTER_INVALID) { CNeuronBaseOCL *neuron_ocl=NULL; CNeuronConvOCL *neuron_conv_ocl=NULL; CNeuronAttentionOCL *neuron_attention_ocl=NULL; CNeuronMLMHAttentionOCL *neuron_mlattention_ocl=NULL; CNeuronDropoutOCL *dropout=NULL; switch(desc.type) { case defNeuron: case defNeuronBaseOCL: neuron_ocl=new CNeuronBaseOCL(); if(CheckPointer(neuron_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_ocl.Init(outputs,0,opencl,desc.count,desc.optimization)) { delete neuron_ocl; delete temp; return; } neuron_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_ocl)) { delete neuron_ocl; delete temp; return; } neuron_ocl=NULL; break; //--- case defNeuronConvOCL: neuron_conv_ocl=new CNeuronConvOCL(); if(CheckPointer(neuron_conv_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_conv_ocl.Init(outputs,0,opencl,desc.window,desc.step,desc.window_out,desc.count,desc.optimization)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_conv_ocl)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl=NULL; break; //--- case defNeuronAttentionOCL: neuron_attention_ocl=new CNeuronAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMHAttentionOCL: neuron_attention_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break; //--- case defNeuronDropoutOCL: dropout=new CNeuronDropoutOCL(); if(CheckPointer(dropout)==POINTER_INVALID) { delete temp; return; } if(!dropout.Init(outputs,0,opencl,desc.count,desc.probability,desc.optimization)) { delete dropout; delete temp; return; } if(!temp.Add(dropout)) { delete dropout; delete temp; return; } dropout=NULL; break; //--- default: return; break; } }
同じメソッドで新しいカーネルを宣言することを忘れないでください。
opencl.SetKernelsCount(24); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut"); opencl.KernelCreate(def_k_Dropout,"Dropout");
同じ新しいカーネル宣言を、事前に訓練されたニューラルネットワークをディスクから読み取るメソッドに追加する必要があります - CNet::Load。
事前に訓練されたニューラルネットワークを読み込むプロセスに関しては、Dropout要素を作成するための関連コードを追加することにより、ニューラルネットワークレイヤーの要素を作成するCLayer::CreateElementメソッドも調整する必要があります。変更点は以下で強調表示されています。
bool CLayer::CreateElement(int index) { if(index>=m_data_max) return false; //--- bool result=false; CNeuronBase *temp=NULL; CNeuronProof *temp_p=NULL; CNeuronBaseOCL *temp_ocl=NULL; CNeuronConvOCL *temp_con_ocl=NULL; CNeuronAttentionOCL *temp_at_ocl=NULL; CNeuronMLMHAttentionOCL *temp_mlat_ocl=NULL; CNeuronDropoutOCL *temp_drop_ocl=NULL; if(iFileHandle<=0) { temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID || !temp.Init(iOutputs,index,SGD)) return false; result=true; } else { int type=FileReadInteger(iFileHandle); switch(type) { case defNeuron: temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID) result=false; result=temp.Init(iOutputs,index,ADAM); break; case defNeuronProof: temp_p=new CNeuronProof(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronConv: temp_p=new CNeuronConv(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronLSTM: temp_p=new CNeuronLSTM(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronBaseOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_ocl=new CNeuronBaseOCL(); if(CheckPointer(temp_ocl)==POINTER_INVALID) result=false; if(temp_ocl.Init(iOutputs,index,OpenCL,1,ADAM)) { m_data[index]=temp_ocl; return true; } break; case defNeuronConvOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_con_ocl=new CNeuronConvOCL(); if(CheckPointer(temp_con_ocl)==POINTER_INVALID) result=false; if(temp_con_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,ADAM)) { m_data[index]=temp_con_ocl; return true; } break; case defNeuronAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMLMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_mlat_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(temp_mlat_ocl)==POINTER_INVALID) result=false; if(temp_mlat_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,0,ADAM)) { m_data[index]=temp_mlat_ocl; return true; } break; case defNeuronDropoutOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_drop_ocl=new CNeuronDropoutOCL(); if(CheckPointer(temp_drop_ocl)==POINTER_INVALID) result=false; if(temp_drop_ocl.Init(iOutputs,index,OpenCL,1,0.1,ADAM)) { m_data[index]=temp_drop_ocl; return true; } break; default: result=false; break; } } if(result) m_data[index]=temp; //--- return (result); }
新しいクラスをCNeuronBaseOCL基本クラスのディスパッチャメソッドに追加します。
フィードフォワードパス(CNeuronBaseOCL::FeedForward)
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; }
エラー勾配伝播メソッド(CNeuronBaseOCL::calcHiddenGradients)
bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; CNeuronDropoutOCL *dropout=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; case defNeuronDropoutOCL: dropout=TargetObject; temp=GetPointer(this); return dropout.calcInputGradients(temp); break; } //--- return false; }
そして、驚くべきことに、以下は重み更新メソッドです(CNeuronBaseOCL::UpdateInputWeights)。
bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
上記の変更がマイナーで重要でないと思われる場合でも、少なくとも1つの変更がないと、ニューラルネットワーク全体が正しく動作しなくなります。
すべてのクラスとそのメソッドの完全なコードは、添付ファイルにあります。
3. テスト
継承と継承を維持するために、第11部のエキスパートアドバイザーを使用して、4つのドロップアウト層が追加されました。
- 初期データの後で1つ
- 埋め込みコードの後で1つ
- 注意ブロックの後で1つ
- 最初の完全接続層の後で1つ
ニューラルネットワークの構造は、以下のコードで説明されています。
//--- 0 CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 1 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 2 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=24; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 3 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 4 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMLMHAttentionOCL; desc.window=24; desc.window_out=4; desc.step=8; //heads desc.layers=5; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 5 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 6 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 7 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 8 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 9 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM;
エキスパートアドバイザーはH1時間枠でEURUSDでテストされ、最後の20本のローソク足の履歴データがニューラルネットワークに送られます。同様のデータセットですべてのアーキテクチャをテストすることで、外部要因の影響を最小限に抑え、同様の条件でのさまざまなアーキテクチャのパフォーマンスを評価できます。
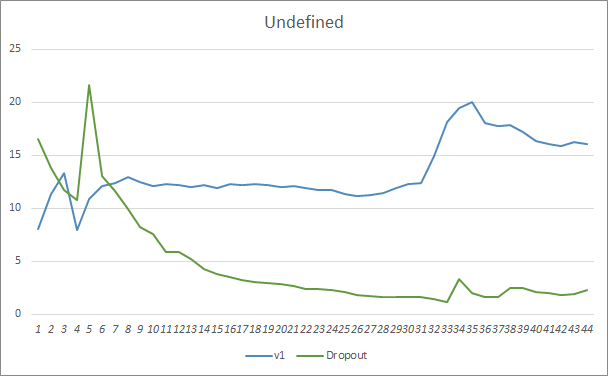
ドロップアウトがある場合とない場合の2つのニューラルネットワーク学習チャートを比較すると、ニューラルネットワークエラーラインの最初の30エポックはほぼ平行でしたが、ドロップアウトなしのニューラルネットワークはわずかに良い結果を示しました。しかし、33番目のエポックの後、ドロップアウトを使用したエキスパートアドバイザーによって示されるこのパラメーターが減少します。35回以降、ドロップアウトが最良の結果を示し、エラーが減少する傾向があります。ドロップアウトのないエキスパートアドバイザーのエラーは、同じレベルに保たれます。
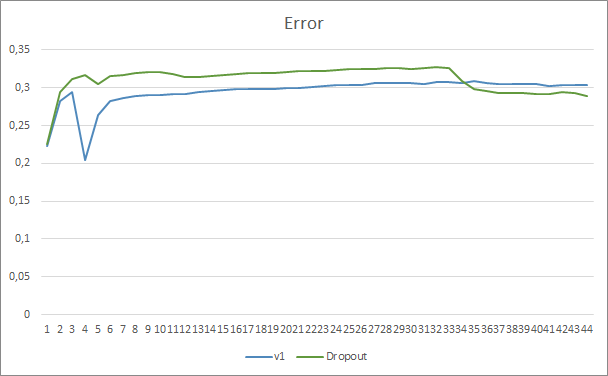
見逃されたパターンチャートは、ドロップアウトテクノロジを利用するエキスパートアドバイザーのパフォーマンスが優れていることも示しています。このチャートはさらに詳細を提供します。ドロップアウトを使用するエキスパートアドバイザーは、ギャップが減少する傾向をすぐに示します。それどころか、ドロップアウトのないエキスパートアドバイザーは、見逃したパターン領域が徐々に増えていきます。
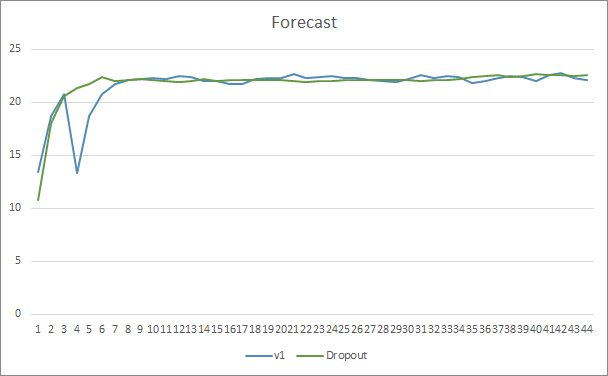
両方のエキスパートアドバイザーの予測ヒットチャートは非常に近いです。44エポックのトレーニングの後、ドロップアウトのあるEAは0.5%だけ良くなります。
終わりに
本稿では、ニューラルネットワークの収束を高める方法の検討を開始し、そのような方法の1つであるドロップアウトを詳しく説明しました。この手法は、以前のエキスパートアドバイザーの1つに追加されて、その効率がEAテストで示されました。もちろん、この手法を使用すると、ニューラルネットワークの訓練コストが増加する可能性がありますが、これらのコストは、最終結果の効率の向上によってカバーされます。
お試しになって、その効果を評価してください。
参照文献
- ニューラルネットワークが簡単に
- ニューラルネットワークが簡単に(第2回): ネットワークの訓練とテスト
- ニューラルネットワークが簡単に(第3回): コンボリューションネットワーク
- ニューラルネットワークが簡単に(第4回): リカレントネットワーク
- ニューラルネットワークが簡単に(第5回): OPENCLでのマルチスレッド計算
- ニューラルネットワークが簡単に(第6回): ニューラルネットワークの学習率を実験する
- ニューラルネットワークが簡単に(第7回): 適応的最適化法
- ニューラルネットワークが簡単に(第8回): アテンションメカニズム
- ニューラルネットワークが簡単に(第9部): 作業の文書化
- ニューラルネットワークが簡単に(第10回): Multi-Head Attention
- ニューラルネットワークが簡単に(第11部): GPTについて
- 特徴検出器の共適応を防ぐことによるニューラルネットワークの改善
- 統計的推定
…
記事で使用されたプログラム
| # | ファイル名 | 種類 | 説明 |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | エキスパートアドバイザー | GTPアーキテクチャを使用した分類ニューラルネットワーク(出力層に3つのニューロン)と5つのAttention層を備えたエキスパートアドバイザー |
| 2 | Fractal_OCL_AttentionMLMH_d.mq5 | エキスパートアドバイザー | GTPアーキテクチャを使用した分類ニューラルネットワーク(出力層に3つのニューロン)と5のAttention層とドロップアウトを備えたエキスパートアドバイザー |
| 3 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 4 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 5 | NN.chm | HTMLヘルプ | コンパイル済みのライブラリヘルプCHMファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/9112
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 ニューラルネットワークが簡単に(第13回): Batch Normalization
ニューラルネットワークが簡単に(第13回): Batch Normalization
 MVCデザインパターンとその可能なアプリケーション
MVCデザインパターンとその可能なアプリケーション
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
OCLなしでは何も動かないということですか?残念ですが、私はゲーマーではありませんし、カードも古いので...。