
Redes Neurais de Maneira Fácil (Parte 12): Dropout

Conteúdo
- Introdução
- 1. Dropout: Um Método para Aumentar a Convergência da Rede Neural
- 2. Implementação
- 2.1. Criando uma Nova Classe para o Nosso Modelo
- 2.2. Propagação direta
- 2.3. Retropropagação
-
2.4. Métodos de armazenamento e carregamento dos dados
- 2.5. Alterações nas Classes Base da Rede Neural
- 3. Teste
- Conclusão
- Referências
- Programas utilizados no artigo
Introdução
Desde o início desta série de artigos, nós já fizemos um grande progresso no estudo de vários modelos de redes neurais. Mas o processo de aprendizagem sempre foi realizado sem a nossa participação. Ao mesmo tempo, há sempre o desejo de ajudar de alguma forma a rede neural a melhorar os resultados do treinamento, o que também pode ser referido como a convergência da rede neural. Neste artigo, nós consideraremos um desses métodos, intitulado de Dropout.
1. Dropout: Um Método para Aumentar a Convergência da Rede Neural
Ao treinar uma rede neural, um grande número de características é alimentado em cada neurônio e é difícil avaliar o impacto de cada característica separada. Como resultado, os erros de alguns neurônios são atenuados pelos valores corretos de outros neurônios, enquanto esses erros são acumulados na saída da rede neural. Isso faz com que o treinamento pare em um determinado mínimo local com um erro bastante grande. Esse efeito é conhecido como co-adaptação de detectores de características, em que a influência de cada recurso se ajusta ao ambiente. Seria melhor ter o efeito oposto, quando o ambiente é decomposto em características separadas e é possível avaliar a influência de cada característica separadamente.
Em 2012, um grupo de cientistas da universidade de Toronto propôs excluir aleatoriamente alguns dos neurônios do processo de aprendizado como uma solução para o complexo problema de co-adaptação [12] Uma diminuição no número de recursos no treinamento aumenta a importância de cada característica, e uma mudança constante na composição quantitativa e qualitativa dos recursos reduz o risco de sua co-adaptação. Este método é denominado Dropout. Às vezes, a aplicação desse método é comparada as árvores de decisão: eliminando alguns dos neurônios, nós obtemos uma nova rede neural com seus próprios pesos a cada iteração de treinamento. De acordo com as regras combinatórias, tais redes apresentam uma variabilidade bastante elevada.
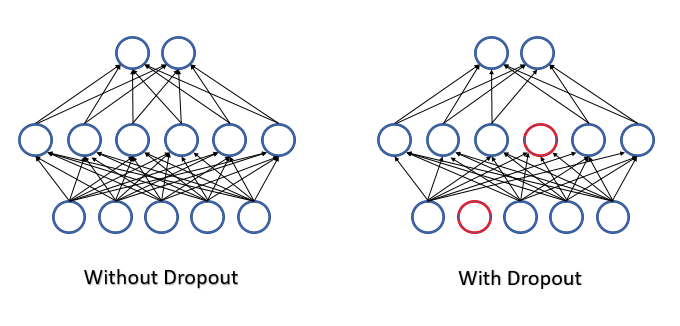
Todas as características e neurônios são avaliados durante a operação da rede neural e assim, nós obtemos a avaliação mais precisa e independente do estado atual do ambiente analisado.
Os autores mencionam em seu artigo (12) a possibilidade de utilizar o método para aumentar a qualidade dos modelos pré-treinados.
Do ponto de vista da matemática, nós podemos descrever esse processo como a eliminação de cada neurônio individual do processo com uma determinada probabilidade p. Em outras palavras, o neurônio participará do processo de aprendizagem da rede neural com probabilidade de q=1-p.
A lista de neurônios, que serão excluídos, é determinada por um gerador de números pseudoaleatórios com distribuição normal. Esta abordagem permite alcançar uma exclusão uniforme máxima possível de neurônios. Nós geraremos na prática um vetor com tamanho igual à sequência de entrada. O valor igual a "1" no vetor será usado para a característica a ser usado no treinamento, e "0" será usado para os elementos a serem excluídos.
No entanto, a exclusão das características analisadas, sem dúvida, leva a uma diminuição na quantidade na entrada da função de ativação do neurônio. Para compensar esse efeito, nós vamos multiplicar o valor de cada característica pelo coeficiente 1/q. Este coeficiente aumentará os valores porque a probabilidade q estará sempre no intervalo entre 0 e 1.
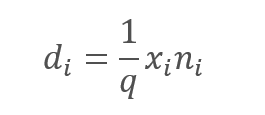 ,
,
onde:
d — elementos do vetor de resultado do Dropout,
q — a probabilidade de usar o neurônio no processo de treinamento,
x — elementos do vetor de mascaramento,
n — elementos da sequência de entrada.
Na passagem da retropropagação durante o processo de aprendizagem, o gradiente do erro é multiplicado pela derivada da função acima. Como você pode ver, no caso do Dropout, o passe da retropropagação será semelhante ao passe da propagação direta usando o vetor de mascaramento do passe de propagação direta.
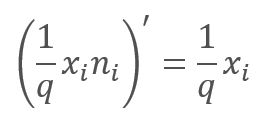
Durante a operação da rede neural, o vetor de mascaramento é preenchido com o valor "1", que permite que os valores sejam transmitidos suavemente em ambas as direções.
Na prática, o coeficiente 1/q é constante ao longo de todo o treinamento, portanto, nós podemos calcular facilmente esse coeficiente uma única vez e escrevê-lo em vez de "1" no tensor de mascaramento. Assim, nós podemos excluir as operações de recalcular o coeficiente e multiplicá-lo por "1" da máscara em cada iteração de treinamento.
2. Implementação
Agora que nós consideramos os aspectos teóricos, vamos passar a considerar as variantes para implementar esse método em nossa biblioteca. A primeira coisa que nós encontramos é a implementação de dois algoritmos diferentes. Um deles é necessário para o processo de treinamento e o segundo será utilizado para produção. Assim, nós precisamos indicar explicitamente ao neurônio de acordo com qual algoritmo ele deve funcionar em cada caso individual. Para este efeito, nós iremos apresentar a flag bTrain no nível do neurônio base. O valor da flag será definido como true para o treinamento e false para o teste.
class CNeuronBaseOCL : public CObject { protected: bool bTrain; ///< Training Mode Flag
Os métodos auxiliares a seguir controlarão os valores das flags.
virtual void TrainMode(bool flag) { bTrain=flag; }///< Set Training Mode Flag virtual bool TrainMode(void) { return bTrain; }///< Get Training Mode Flag
A flag é implementada no nível do neurônio base intencionalmente. Isso permite o uso de código relacionado ao dropout em um desenvolvimento posterior.
2.1. Criando uma nova classe para o nosso modelo
Para implementar o algoritmo Dropout, vamos criar a nova classe CNeuronDropoutOCL, que incluiremos em nosso modelo como uma camada separada. A nova classe herdará diretamente da classe de neurônios base CNeuronBaseOCL. Declaramos as variáveis no bloco protegido:
- OutProbability — a probabilidade especificada de eliminar o neurônio.
- OutNumber — o número de neurônios a serem eliminados.
- dInitValue — o valor para inicializar o vetor de mascaramento; na parte teórica do artigo este coeficiente foi especificado como 1/q.
Além disso, declaramos dois indicadores para as classes:
- DropOutMultiplier — vetor de dropout.
- PrevLayer — um ponteiro para o objeto da camada anterior; ele será usado durante o teste e a aplicação prática.
class CNeuronDropoutOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL *PrevLayer; double OutProbability; double OutNumber; CBufferDouble *DropOutMultiplier; double dInitValue; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///<\brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previous layer. virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.@param NeuronOCL Pointer to previous layer. //--- int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); } ///< Generates a random neuron position to turn off public: CNeuronDropoutOCL(void); ~CNeuronDropoutOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons,double out_prob, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer #param[in] out_prob Probability of neurons shutdown @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. //--- virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); } ///< Get index of output buffer @return Index virtual int getGradientIndex(void) { return (bTrain ? Gradient.GetIndex() : PrevLayer.getGradientIndex()); } ///< Get index of gradient buffer @return Index //--- virtual int getOutputVal(double &values[]) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return (bTrain ? Gradient.GetData(values) : PrevLayer.getGradient(values)); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual CBufferDouble *getOutput(void) { return (bTrain ? Output : PrevLayer.getOutput()); } ///< Get pointer of output buffer @return Pointer to object virtual CBufferDouble *getGradient(void) { return (bTrain ? Gradient : PrevLayer.getGradient()); } ///< Get pointer of gradient buffer @return Pointer to object //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronDropoutOCL; }///< Identificator of class.@return Type of class };
A lista de métodos da classe deve ser familiar para você, pois todos eles substituem os métodos da classe pai. A única exclusão é o método RND que é usado para gerar os números pseudoaleatórios a partir da distribuição uniforme. O algoritmo deste método foi descrito no artigo 13. Para garantir a máxima aleatoriedade possível dos valores em todos os objetos de nossa rede neural, o gerador de sequência pseudo-aleatória é implementado como uma substituição de macro usando as variáveis globais.
#define xor128 rnd_t=(rnd_x^(rnd_x<<11)); \ rnd_x=rnd_y; \ rnd_y=rnd_z; \ rnd_z=rnd_w; \ rnd_w=(rnd_w^(rnd_w>>19))^(rnd_t^(rnd_t>>8)) uint rnd_x=MathRand(), rnd_y=MathRand(), rnd_z=MathRand(), rnd_w=MathRand(), rnd_t=0;
O algoritmo proposto gera uma sequência de inteiros no intervalo [0, UINT_MAX = 4294967295]. Portanto, no método do gerador de sequência pseudoaleatória, após a execução da macro, o valor resultante é normalizado para o tamanho da sequência.
c c?}AAa/int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); }
Se você leu os artigos anteriores desta série, deve ter notado que nas versões anteriores nós não substituímos os métodos para trabalhar com os buffers de dados da classe de outros objetos. Estes métodos são usados para a troca de dados entre as camadas da rede neural quando os neurônios fazem acesso aos dados da camada anterior ou seguinte.
Esta solução foi escolhida em um esforço para otimizar a operação da rede neural durante a aplicação prática. Não se esqueça de que a camada Dropout é usada apenas para o treinamento da rede neural. Este algoritmo é desabilitado durante o teste e outras aplicações. Ao substituir os métodos de acesso do buffer de dados, nós habilitamos o pulo da camada Dropout. Todos os métodos substituídos seguem o mesmo princípio. Em vez de copiar os dados, nós implementamos a substituição dos buffers da camada Dropout pelos buffers da camada anterior. Assim, durante a operação posterior, a velocidade de uma rede neural com uma camada Dropout é comparável à velocidade de uma rede semelhante sem um Dropout, enquanto nós obtemos todas as vantagens da eliminação dos neurônios no estágio de treinamento.
virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); }
Encontre o código inteiro de todos os métodos de classe em anexo no artigo.
2.2. Propagação direta
Tradicionalmente, vamos implementar uma passagem da propagação direta no método feedForward. No início do método, verificamos a validade do ponteiro recebido para a camada anterior da rede neural e do ponteiro para o objeto OpenCL. Depois disso, salvamos a função de ativação usada na camada anterior e o ponteiro para o objeto da camada anterior. Para o modo de operação prática da rede neural, a passagem da propagação direta da camada Dropout termina aqui. Uma tentativa posterior de acessar esta camada da próxima camada irá ativar o mecanismo descrito acima para substituir os buffers de dados.
bool CNeuronDropoutOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- activation=(ENUM_ACTIVATION)NeuronOCL.Activation(); PrevLayer=NeuronOCL; if(!bTrain) return true;
As iterações subsequentes são relevantes apenas para o modo de treinamento da rede neural. Primeiro, geramos um vetor de mascaramento, no qual definiremos os neurônios a serem eliminados nesta etapa. Escrevemos a máscara no buffer DropOutMultiplier, verificamos a disponibilidade do objeto criado anteriormente e criamos um novo se necessário. Inicializamos o buffer com os valores iniciais. Para reduzir os cálculos, vamos inicializar o buffer com um fator crescente 1/q.
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(NeuronOCL.Neurons(),dInitValue)) return false; for(int i=0;i<OutNumber;i++) { uint p=RND(); double val=DropOutMultiplier.At(p); if(val==0 || val==DBL_MAX) { i--; continue; } if(!DropOutMultiplier.Update(RND(),0)) return false; }
Após a inicialização do buffer, organizamos um loop com o número de repetições igual ao número de neurônios a serem eliminados. Os elementos do buffer selecionados aleatoriamente serão substituídos por valores iguais a zero. Para evitar o risco de escrever "0" duas vezes em uma célula, nós implementamos uma verificação adicional dentro do loop.
Após gerar a máscara, criamos um buffer diretamente na memória da GPU e transferimos os dados.
if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
Agora, nós precisamos multiplicar dois vetores elemento a elemento. O resultado desta operação será a saída da camada Dropout. A operação de multiplicação dos vetores será implementada em uma GPU usando OpenCL. A maneira mais eficiente de multiplicar os elementos é utilizando as operações vetoriais. Eu usei a variável do tipo double4 no kernel OpenCL, ou seja, um vetor de 4 elementos. Portanto, o número de threads iniciadas será 4 vezes menor que o número de elementos no vetor.
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0);
Em seguida, indicamos os buffers de dados e as variáveis iniciais e iniciamos o kernel para execução.
if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; }
O resultado da operação realizada no kernel é obtido ao final do método. Aqui, o buffer de mascaramento é excluído da memória da GPU.
if(!Output.BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
Depois de concluir as operações, saímos do método com um retorno igual a true.
A descrição do método da propagação direta estaria incompleta sem considerar as operações no lado da GPU. Aqui está o código do kernel.
__kernel void Dropout (__global double *inputs, ///<[in] Input matrix __global double *map, ///<[in] Dropout map matrix __global double *out, ///<[out] Output matrix int dimension ///< Dimension of matrix )
O kernel recebe os ponteiros como parâmetros para dois tensores de entrada com o dado inicial e o tensor resultante, bem como o tamanho dos vetores.
No código do kernel, determinamos os elementos a serem multiplicados de acordo com o número da thread. Após isso o código é dividido em duas ramificações. A primeira branch é a principal: usamos as operações do vetor para multiplicar os quatro elementos consecutivos e escrever os dados recebidos para os elementos correspondentes do buffer de resultados.
{
const int i=get_global_id(0)*4;
if(i+3<dimension)
{
double4 k=(double4)(inputs[i],inputs[i+1],inputs[i+2],inputs[i+3])*(double4)(map[i],map[i+1],map[i+2],map[i+3]);
out[i]=k.s0;
out[i+1]=k.s1;
out[i+2]=k.s2;
out[i+3]=k.s3;
}
else
for(int k=i;k<min(dimension,i+4);k++)
out[i+k]=(inputs[i+k]*map[i+k]);
}
A segunda ramificação é ativada somente quando o número de elementos nos tensores não é multiplicado por 4, e os elementos restantes são multiplicados no loop. Esse loop não terá mais do que 3 iterações e, portanto, não será crítico em termos de tempo.
O código completo de todas as classes e seus métodos está disponível no anexo.
2.3. Retropropagação
A passagem da retropropagação em todos os neurônios considerados anteriormente foi dividido em 2 métodos:
- calcInputGradients — propaga o gradiente de erro para a camada anterior.
- updateInputWeights — atualiza os pesos da camada neural.
No caso de Dropout, nós não temos o tensor de peso. No entanto, para manter a estrutura geral dos objetos, nós iremos sobrescrever o método updateInputWeights - mas neste caso ele sempre retornará true.
virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.
Considere a implementação do método calcInputGradients. Este método recebe nos parâmetros um ponteiro para a camada anterior. No início do método, verificamos a validade do ponteiro recebido e de um ponteiro para o objeto OpenCL. Então, como na passagem da propagação direta, dividimos o algoritmo para os processos de treinamento e de operação. No modo de teste ou operação, nós saímos do método, pois devido à substituição do buffer de dados, a próxima camada neural gravou o gradiente diretamente no buffer da camada anterior, evitando iterações desnecessárias na camada Dropout.
bool CNeuronDropoutOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- if(!bTrain) return true;
No modo de treinamento, o gradiente será propagado de forma diferente. O algoritmo abaixo será relevante apenas para o processo de treinamento da rede neural. Como no método da propagação direta, verificamos a validade do ponteiro para o buffer de mascaramento DropOutMultiplier. No entanto, ao contrário da passagem da propagação direta, um erro de validação não leva à criação de um novo buffer - neste caso, nós sairemos do método com o valor igual a false. Isso ocorre porque o passe de retropropagação usa a máscara gerada pelo passe da propagação direta. Essa abordagem garante a comparabilidade dos dados e a distribuição correta do gradiente de erro entre os neurônios.
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) return false; //--- if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
Após uma validação bem-sucedida do objeto DropOutMultiplier, criamos um buffer na memória da GPU e preenchemos ele com os dados.
Agora nós precisamos multiplicar dois vetores elemento a elemento. Isso não é familiar para você? A mesma frase exata é dada acima, na descrição do passo de da propagação direta. Sim, de fato. Na parte teórica, nós vimos que a derivada da função matemática do Dropout é igual ao coeficiente crescente. Portanto, durante a passagem da retropropagação, nós também multiplicaremos o gradiente da próxima camada pelo coeficiente crescente escrito no buffer de mascaramento DropOutMultiplier. Assim, a classe CNeuronDropoutOCL é um caso único quando o mesmo kernel será usado para a propagação direta e a retropropagação, mas os dados de entrada diferentes serão alimentados nesses casos: para uma passagem da propagação direta, são os dados de saída dos neurônios, e para o caso da retropropagação é o gradiente do erro.
Assim, nós especificamos os buffers de dados e chamamos a execução do kernel. O código é semelhante ao código da propagação direta e, portanto, não requer explicações adicionais.
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0); if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,Gradient.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; } if(!NeuronOCL.getGradient().BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
O código completo de todas as classes e seus métodos está disponível no anexo.
2.4. Métodos de armazenamento e carregamento dos dados
Vamos dar uma olhada nos métodos que salvam e carregam o objeto da camada neural Dropout. Não há necessidade de salvar o objeto do buffer de máscara, uma vez que uma nova máscara é gerada em cada ciclo de treinamento. Apenas uma variável foi adicionada no método de inicialização da classe CNeuronDropoutOCL: a probabilidade de excluir um neurônio, que deve ser salvo.
No método Save, nós vamos chamar o método relevante da classe pai. Após a conclusão bem-sucedida, nós salvamos a probabilidade dada da eliminação de neurônios.
bool CNeuronDropoutOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(FileWriteDouble(file_handle,OutProbability)<=0) return false; //--- return true; }
No método Load, nós vamos ler os dados do disco e restaurar todos os elementos da classe. Portanto, o algoritmo desse método é um pouco mais complicado do que o do método Save.
Por analogia com o método de salvamento de classe, vamos chamar o mesmo método que o nome do método da classe pai. Após sua conclusão, calculamos a probabilidade de eliminação do neurônio. Isso conclui o método de salvamento, mas nós precisamos restaurar os elementos ausentes. Com base na probabilidade da eliminação dos neurônios, vamos contar o número de neurônios a serem excluídos e o valor do coeficiente crescente, que também serve como valor para inicializar o vetor de mascaramento.
bool CNeuronDropoutOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; //--- OutProbability=FileReadDouble(file_handle); OutNumber=(int)(Neurons()*OutProbability); dInitValue=1/(1-OutProbability); if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(Neurons()+1,dInitValue)) return false; //--- return true; }
Agora, após o cálculo, nós podemos restaurar o vetor de mascaramento. Verificamos a validade do ponteiro para o objeto do buffer de dados em DropOutMultiplier e criamos um novo objeto, se for necessário. Em seguida, inicializamos o buffer de mascaramento com os valores iniciais.
2.5. Alterações nas Classes Base da Rede Neural
Novamente, essa nova classe deve ser adicionada corretamente à operação da biblioteca. Vamos começar com a declaração de substituições de macro para trabalhar com o novo kernel. Além disso, nós precisamos definir a constante de identificação para a nova classe.
#define def_k_Dropout 23 ///< Index of the kernel for Dropout process (#Dropout) #define def_k_dout_input 0 ///< Inputs Tensor #define def_k_dout_map 1 ///< Map Tensor #define def_k_dout_out 2 ///< Out Tensor #define def_k_dout_dimension 3 ///< Dimension of Inputs #define defNeuronDropoutOCL 0x7890 ///<Dropout neuron OpenCL \details Identified class #CNeuronDropoutOCL
Então, no método de descrição da camada neural, vamos adicionar uma nova variável para registrar a probabilidade de dropout do neurônio.
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) double probability; ///< Probability of neurons shutdown, only Dropout used };
No método de criação do método da rede neural CNet::CNet, no bloco de criação e inicialização da camada, vamos adicionar o código para inicializar uma nova camada (destacado no código abaixo).
for(int i=0; i<total; i++) { prev=desc; desc=Description.At(i); if((i+1)<total) { next=Description.At(i+1); if(CheckPointer(next)==POINTER_INVALID) return; } else next=NULL; int outputs=(next==NULL || (next.type!=defNeuron && next.type!=defNeuronBaseOCL) ? 0 : next.count); temp=new CLayer(outputs); int neurons=(desc.count+(desc.type==defNeuron || desc.type==defNeuronBaseOCL ? 1 : 0)); if(CheckPointer(opencl)!=POINTER_INVALID) { CNeuronBaseOCL *neuron_ocl=NULL; CNeuronConvOCL *neuron_conv_ocl=NULL; CNeuronAttentionOCL *neuron_attention_ocl=NULL; CNeuronMLMHAttentionOCL *neuron_mlattention_ocl=NULL; CNeuronDropoutOCL *dropout=NULL; switch(desc.type) { case defNeuron: case defNeuronBaseOCL: neuron_ocl=new CNeuronBaseOCL(); if(CheckPointer(neuron_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_ocl.Init(outputs,0,opencl,desc.count,desc.optimization)) { delete neuron_ocl; delete temp; return; } neuron_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_ocl)) { delete neuron_ocl; delete temp; return; } neuron_ocl=NULL; break; //--- case defNeuronConvOCL: neuron_conv_ocl=new CNeuronConvOCL(); if(CheckPointer(neuron_conv_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_conv_ocl.Init(outputs,0,opencl,desc.window,desc.step,desc.window_out,desc.count,desc.optimization)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_conv_ocl)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl=NULL; break; //--- case defNeuronAttentionOCL: neuron_attention_ocl=new CNeuronAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMHAttentionOCL: neuron_attention_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break; //--- case defNeuronDropoutOCL: dropout=new CNeuronDropoutOCL(); if(CheckPointer(dropout)==POINTER_INVALID) { delete temp; return; } if(!dropout.Init(outputs,0,opencl,desc.count,desc.probability,desc.optimization)) { delete dropout; delete temp; return; } if(!temp.Add(dropout)) { delete dropout; delete temp; return; } dropout=NULL; break; //--- default: return; break; } }
Não se esqueça de declarar um novo kernel no mesmo método.
opencl.SetKernelsCount(24); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut"); opencl.KernelCreate(def_k_Dropout,"Dropout");
A mesma nova declaração do kernel deve ser adicionada ao método de leitura da rede neural pré-treinada do disco - CNet::Load.
Com relação ao processo de carregamento de uma rede neural pré-treinada, nós também precisamos ajustar o método CLayer::CreateElement criando um elemento da camada da rede neural ao adicionar o código relevante para a criação do elemento Dropout. As alterações são destacadas abaixo.
bool CLayer::CreateElement(int index) { if(index>=m_data_max) return false; //--- bool result=false; CNeuronBase *temp=NULL; CNeuronProof *temp_p=NULL; CNeuronBaseOCL *temp_ocl=NULL; CNeuronConvOCL *temp_con_ocl=NULL; CNeuronAttentionOCL *temp_at_ocl=NULL; CNeuronMLMHAttentionOCL *temp_mlat_ocl=NULL; CNeuronDropoutOCL *temp_drop_ocl=NULL; if(iFileHandle<=0) { temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID || !temp.Init(iOutputs,index,SGD)) return false; result=true; } else { int type=FileReadInteger(iFileHandle); switch(type) { case defNeuron: temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID) result=false; result=temp.Init(iOutputs,index,ADAM); break; case defNeuronProof: temp_p=new CNeuronProof(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronConv: temp_p=new CNeuronConv(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronLSTM: temp_p=new CNeuronLSTM(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronBaseOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_ocl=new CNeuronBaseOCL(); if(CheckPointer(temp_ocl)==POINTER_INVALID) result=false; if(temp_ocl.Init(iOutputs,index,OpenCL,1,ADAM)) { m_data[index]=temp_ocl; return true; } break; case defNeuronConvOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_con_ocl=new CNeuronConvOCL(); if(CheckPointer(temp_con_ocl)==POINTER_INVALID) result=false; if(temp_con_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,ADAM)) { m_data[index]=temp_con_ocl; return true; } break; case defNeuronAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMLMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_mlat_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(temp_mlat_ocl)==POINTER_INVALID) result=false; if(temp_mlat_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,0,ADAM)) { m_data[index]=temp_mlat_ocl; return true; } break; case defNeuronDropoutOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_drop_ocl=new CNeuronDropoutOCL(); if(CheckPointer(temp_drop_ocl)==POINTER_INVALID) result=false; if(temp_drop_ocl.Init(iOutputs,index,OpenCL,1,0.1,ADAM)) { m_data[index]=temp_drop_ocl; return true; } break; default: result=false; break; } } if(result) m_data[index]=temp; //--- return (result); }
A nova classe deve ser adicionada aos métodos de despacho da classe base CNeuronBaseOCL.
Passe da propagação direta CNeuronBaseOCL::FeedForward.
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; }
Método de propagação do gradiente do erro CNeuronBaseOCL::calcHiddenGradients.
bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; CNeuronDropoutOCL *dropout=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; case defNeuronDropoutOCL: dropout=TargetObject; temp=GetPointer(this); return dropout.calcInputGradients(temp); break; } //--- return false; }
E, surpreendentemente, aqui está o método de atualização do peso CNeuronBaseOCL::UpdateInputWeights.
bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
Mesmo que as alterações acima possam parecer menores ou insignificantes, a ausência de pelo menos uma delas leva a uma operação incorreta de toda a rede neural.
O código completo de todas as classes e seus métodos está disponível no anexo.
3. Teste
Para preservar a sucessão e herança, nós usaremos um Expert Advisor do artigo 11, ao qual 4 camadas de exclusão foram adicionadas:
- 1 após os dados iniciais,
- 1 após o código de incorporação,
- 1 após o bloqueio de atenção,
- 1 após a primeira camada totalmente conectada.
A estrutura da rede neural é descrita no código a seguir.
//--- 0 CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 1 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 2 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=24; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 3 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 4 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMLMHAttentionOCL; desc.window=24; desc.window_out=4; desc.step=8; //heads desc.layers=5; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 5 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 6 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 7 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 8 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 9 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM;
O Expert Advisor foi testado em EURUSD com o intervalo de tempo H1, os dados históricos das últimas 20 velas são alimentados na rede neural. O teste de todas as arquiteturas nos conjuntos de dados semelhantes permite a minimização da influência de fatores externos, bem como a avaliação do desempenho de várias arquiteturas em condições semelhantes.
Ao comparar dois gráficos da aprendizagem da rede neural, com e sem Dropout, nós podemos ver que as primeiras 30 épocas das linhas de erro da rede neural foram quase paralelas, enquanto a rede neural sem Dropout mostrou resultados ligeiramente melhores. Mas após a 33ª época, há uma diminuição neste parâmetro mostrado pelo Expert Advisor usando Dropout. Após a 35ª era, o Dropout apresenta o melhor resultado, há tendência de diminuição do erro. O Expert Advisor sem Dropout continua a manter o erro no mesmo nível.
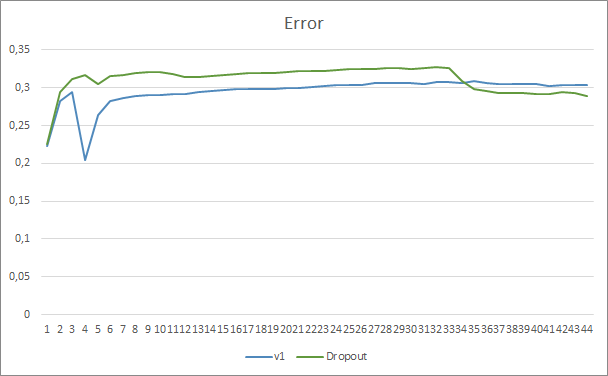
O gráfico do padrão perdido também mostra que o Expert Advisor que utiliza a tecnologia Dropout tem um desempenho melhor. Este gráfico fornece ainda mais detalhes. O Expert Advisor que usa Dropout mostra imediatamente uma tendência de diminuição das lacunas. Ao contrário, o Expert Advisor sem Dropout aumenta gradualmente as áreas de padrões perdidos.
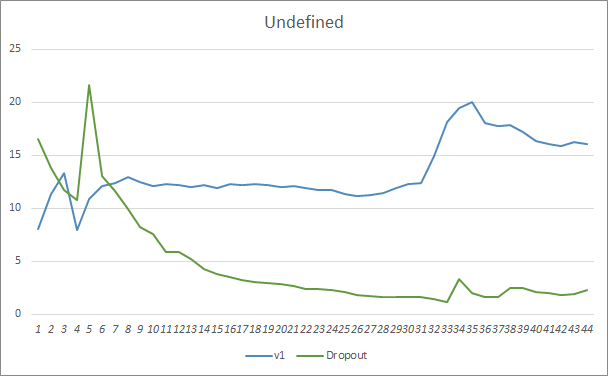
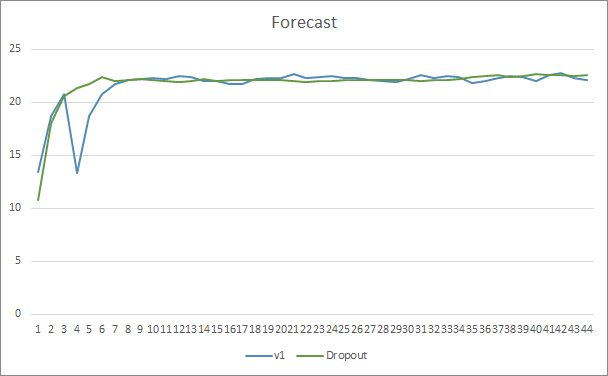
Os gráficos de predição de ambos os Expert Advisors são bem próximos. Após 44 épocas de treinamento, a AE com abandono só é melhor em 0,5%.
Conclusão
Neste artigo, nós começamos a considerar os métodos para aumentar a convergência das redes neurais e nos familiarizamos com um desses métodos, o Dropout. O método foi adicionado a um de nossos Expert Advisors anteriores. A eficiência deste método foi demonstrada nos testes do EA. Obviamente, o uso desse método pode aumentar os custos de treinamento da rede neural. Mas esses custos são cobertos pelo aumento da eficiência do resultado final.
Eu convido a todos a experimentar este método e avaliar sua eficácia.
Referências
- Redes neurais de maneira fácil
- Redes neurais de maneira fácil (Parte 2): Treinamento e teste da rede
- Redes Neurais de Maneira Fácil (Parte 3): Redes Convolucionais
- Redes Neurais de Maneira Fácil (Parte 4): Redes Recorrentes
- Redes Neurais de Maneira Fácil (Parte 5): Cálculos em Paralelo com o OpenCL
- Redes neurais de Maneira Fácil (Parte 6): Experimentos com a taxa de aprendizado da rede neural
- Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
- Redes Neurais de Maneira Fácil (Parte 8): Mecanismos de Atenção
- Redes Neurais de Maneira Fácil (Parte 9): Documentação do trabalho
- Redes neurais de maneira fácil (Parte 10): Atenção Multi-Cabeça
- Redes Neurais de Maneira Fácil (Parte 11): Uma visão sobre a GPT
- Improving neural networks by preventing co-adaptation of feature detectors
- Estimativas estatísticas
…
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a arquitetura GTP, com 5 camadas de atenção |
| 2 | Fractal_OCL_AttentionMLMH_d.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando a arquitetura GTP, com 5 camadas de atenção + Dropout |
| 3 | NeuroNet.mqh | Biblioteca de classe | Uma biblioteca de classes para a criação de uma rede neural |
| 4 | NeuroNet.cl | Código Base | Biblioteca do código do programa OpenCL |
| 5 | NN.chm | Ajuda HTML | Um arquivo CHM compilado de Ajuda da Biblioteca. |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/9112
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Aprendizado de máquina em sistemas de negociação baseados em grade e martingale. Deveríamos apostar nele?
Aprendizado de máquina em sistemas de negociação baseados em grade e martingale. Deveríamos apostar nele?
 Força bruta para encontrar padrões (Parte IV): funcionalidade mínima
Força bruta para encontrar padrões (Parte IV): funcionalidade mínima
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Presumo que nada funcione sem o OCL? Que pena, não sou um jogador e a placa é antiga....