
Aprendizado de máquina em sistemas de negociação baseados em grade e martingale. Deveríamos apostar nele?
Introdução
Já trabalhamos e pesquisamos várias abordagens para usar o aprendizado de máquina para encontrar padrões no mercado de moedas. Já temos uma ideia de como treinar modelos e implementá-los. Porém, existe inúmeras abordagens para negociação e quase todas podem ser aprimoradas com algoritmos modernos de aprendizado de máquina. Uma das mais populares é a grade e/ou martingale. Antes de escrever este artigo, fiz uma pequena análise exploratória para verificar a presença de informações na Internet sobre o tema. Para minha surpresa, essa abordagem, por algum motivo, não é afetada de forma alguma na rede global. Além disso, eu perguntei aos membros da comunidade sobre as perspectivas dessa solução, e a maioria respondeu que nem sabia como abordar este tema, mas a ideia em si é do seu interesse. Embora, ao que parece, não haja nada de complicado nisso.
Vamos realizar uma série de experimentos para nossa própria segurança, a fim de, em primeiro lugar, provar que isso não é tão difícil quanto pode parecer à primeira vista e, em segundo lugar, para descobrir se é aplicável e eficaz.
Marcação de trades
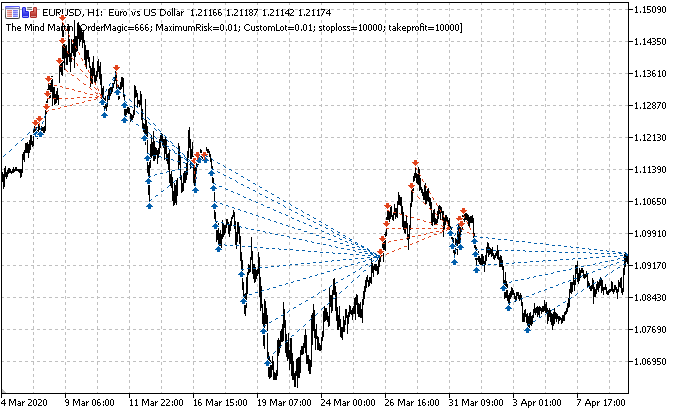
O objetivo principal é marcar corretamente os trades. Lembremos como fizemos isso para posições simples em artigos anteriores. Era definido um horizonte de negociação aleatório ou determinístico, por exemplo, 15 barras. Se o mercado subisse ao londo dessas 15 barras, o trade seria marcado para compra, ao contrário, para venda. Com uma grade de ordens, a lógica será semelhante, mas devemos levar em consideração o lucro/prejuízo total para um grupo de posições abertas. Isso pode ser ilustrado com um exemplo simples. O autor do artigo desenhou o melhor que pôde.
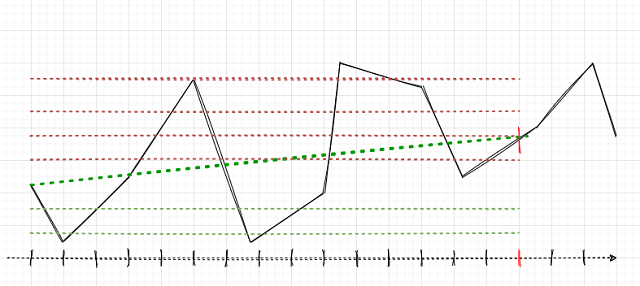
Suponhamos que o horizonte do trade seja de 15 (quinze) barras (marcadas com um traço vertical vermelho na escala de tempo convencional). Se uma única posição for usada, ela será marcada para compra (linha pontilhada traço verde oblíqua), uma vez que o mercado tem crescido de ponto a ponto. O mercado é uma curva quebrada preta, se alguém não entendeu.
Com essa margem de lucro, as flutuações do mercado intermediário não serão levadas em consideração. Se aplicarmos uma grade de ordens (linhas horizontais vermelhas e verdes), devemos calcular o lucro total para todas as ordens pendentes acionadas mais a ordem aberta no início (podemos abrir uma posição de uma vez e colocar a grade na mesma direção, mas podemos não abrir uma posição e nos limitar apenas com uma grade de ordens pendentes). Essa marcação continuará numa janela deslizante para toda a profundidade do histórico de aprendizado, e a tarefa do AM (aprendizado de máquina) é generalizar toda a variedade de situações e prever com eficiência novos dados (se possível).
Nesse caso, pode haver vários cenários para a escolha da direção da negociação e da marcação dos dados, a escolha de uma delas é uma tarefa filosófica e experimental ao mesmo tempo.
- Escolha com base no lucro total máximo. Se a grade para vender dá mais lucro, então é ela que será marcada.
- Escolha ponderada entre o número de ordens abertas e o lucro total. Se o lucro médio para cada ordem da grade aberta for maior do que para o lado oposto, esse lado é selecionado.
- Seleção com base no número máximo de ordens acionadas. Visto que queremos que o robô negocie exatamente com base na grade, é razoável escolher esta abordagem. Se o número de ordens acionadas for máxima e a posição total for lucrativa, esse lado é selecionado. O lado aqui se refere à direção da grade (venda ou compra).
Talvez, para começar, esses três critérios sejam suficientes. Eu gostaria de focar no primeiro, pois é o mais simples e voltado para o lucro máximo.
Marcação de trades no código
Vamos agora relembrar como ocorreu a marcação dos trades nos artigos anteriores.
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index).reset_index(drop=True) return dataset
Este código precisa ser generalizado para a grade normal e a grade com implementação de martingale. Uma característica marcante é que podemos explorar grades com diferentes números de ordens, com diferentes distâncias entre ordens, e até mesmo aplicar martingale (aumento do lote).
Para fazer isso, adicionamos variáveis globais que podem ser iteradas e otimizadas posteriormente.
GRID_SIZE = 10 GRID_DISTANCES = np.full(GRID_SIZE, 0.00200) GRID_COEFFICIENTS = np.linspace(1, 3, num= GRID_SIZE)
A variável GRID_SIZE contém o número de ordens em ambos os sentidos.
A variável GRID_DISTANCES define a distância entre as ordens. A distância pode ser escolhida fixa ou diferente para todas as ordens. Isso ajudará a aumentar a flexibilidade da estratégia de negociação.
A variável GRID_COEFFICIENTS contém multiplicadores de lote para cada ordem. Se os tornamos iguais, usaremos uma grade comum. Se diferentes, então usaremos martingale ou antimartingale, ou qualquer outro nome aplicável a uma grade com diferentes multiplicadores de lote.
Para aqueles que são novos na biblioteca numpy:
- np.full preenche uma matriz com um determinado número de valores idênticos
- np.linspace preenche uma matriz com o número especificado de valores distribuídos uniformemente entre dois números reais. No exemplo acima, GRID_COEFFICIENTS conteria o seguinte.
array([1. , 1.22222222, 1.44444444, 1.66666667, 1.88888889, 2.11111111, 2.33333333, 2.55555556, 2.77777778, 3. ])
Consequentemente, o multiplicador do primeiro lote será igual a um, ou seja, lote base especificado nas configurações da estratégia de negociação. E depois mais em ordem ascendente de 1 a 3 para o resto das ordens da grade. Para usar uma grade multiplicadora fixa para todas as ordens, chamamos np.full.
A contabilização de ordens acionadas e não acionados pode parecer um certo truque, portanto, devemos criar algum tipo de estrutura de dados. Decidi criar um dicionário para registro de ordens e posições para cada caso específico (amostra). Em vez disso, podemos usar um objeto Data Class, um objeto pandas Data Frame ou uma matriz estruturada numpy. A última solução, talvez, seja a mais rápida, mas aqui não é crítica.
A cada iteração de adição de uma amostra ao conjunto de treinamento, será criado um dicionário que armazena informações sobre a grade de ordens. Aqui, provavelmente, deve ser descriptografado. O dicionário grid_stats contém todas as informações necessárias sobre a grade de ordens atual, desde o momento de abertura até o momento de fechamento.
def add_labels(dataset, min, max, distances, coefficients): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) all_pr = dataset['close'][i:i + rand + 1] grid_stats = {'up_range': all_pr[0] - all_pr.min(), 'dwn_range': all_pr.max() - all_pr[0], 'up_state': 0, 'dwn_state': 0, 'up_orders': 0, 'dwn_orders': 0, 'up_profit': all_pr[-1] - all_pr[0] - MARKUP, 'dwn_profit': all_pr[0] - all_pr[-1] - MARKUP } for i in np.nditer(distances): if grid_stats['up_state'] + i <= grid_stats['up_range']: grid_stats['up_state'] += i grid_stats['up_orders'] += 1 grid_stats['up_profit'] += (all_pr[-1] - all_pr[0] + grid_stats['up_state']) \ * coefficients[int(grid_stats['up_orders']-1)] grid_stats['up_profit'] -= MARKUP * coefficients[int(grid_stats['up_orders']-1)] if grid_stats['dwn_state'] + i <= grid_stats['dwn_range']: grid_stats['dwn_state'] += i grid_stats['dwn_orders'] += 1 grid_stats['dwn_profit'] += (all_pr[0] - all_pr[-1] + grid_stats['dwn_state']) \ * coefficients[int(grid_stats['dwn_orders']-1)] grid_stats['dwn_profit'] -= MARKUP * coefficients[int(grid_stats['dwn_orders']-1)] if grid_stats['up_profit'] > grid_stats['dwn_profit'] and grid_stats['up_profit'] > 0: labels.append(0.0) continue elif grid_stats['dwn_profit'] > 0: labels.append(1.0) continue labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index).reset_index(drop=True) return dataset
A variável all_pr contém preços do atual para o futuro, é necessário calcular a própria grade. Para construir a grade, queremos saber as faixas de preço da primeira barra à última, elas estão contidas nas entradas do dicionário 'up_range' e 'dwn_range'. As variáveis 'up_profit' e 'dwn_profit' conterão o lucro final de implementação de grade de compra ou venda no segmento atual do histórico. Esses valores são inicializados com o lucro recebido por um trade, que foi inicialmente aberto a mercado. Em seguida, eles serão acrescentados aos trades que foram abertos na grade se ordens pendentes foram acionadas.
Agora precisamos percorrer num loop todos os GRID_DISTANCESe verificar se as ordens limite pendentes foram acionadas. Se a ordem estiver no intervalo up_range ou dwn_range, então foi acionado. Nesse caso, os contadores correspondentes são incrementados up_state e dwn_state, que armazenam o nível da última ordem ativada. Na próxima iteração, a distância para a nova ordem de grade é adicionada a esse nível e, se essa ordem estiver na faixa de preço, ela também será acionada.
Informações adicionais são registradas para todas as ordens ativadas. Por exemplo, o lucro de uma ordem pendente é adicionado ao total. Para posições de compra, é calculado usando a seguinte fórmula. Aqui, o preço de abertura da posição é subtraído do último preço (no qual a posição deve ser fechada) e a distância para a ordem pendente selecionada na série é adicionada, tudo isso é multiplicado pelo fator de aumento do lote para esta ordem na grade. Para ordens de venda, o oposto é verdadeiro. Além disso, é considerada a marcação acumulada.
grid_stats['up_profit'] += (all_pr[-1] - all_pr[0] + grid_stats['up_state']) \ * coefficients[int(grid_stats['up_orders']-1)] grid_stats['up_profit'] -= MARKUP * coefficients[int(grid_stats['up_orders']-1)]
O próximo bloco de código verifica o lucro em relação às grades de compra e venda. Se o lucro, levando em consideração as marcações acumuladas, for maior que zero e máximo, então a amostra correspondente é adicionada ao conjunto de treinamento. Se nenhuma das condições for atendida, então uma marca 2.0 é adicionada, as amostras marcadas com este marcador são removidas do conjunto de dados de treinamento como não informativas. Essas condições podem ser alteradas posteriormente, dependendo das opções de geração de grade desejadas descritas acima.
Atualizamos o testador para trabalhar com uma grade de ordens
Para calcular corretamente o lucro obtido com a negociação da grade, devemos modificar o testador de estratégia. Decidi torná-lo o mais próximo possível do testador MetaTrader 5, no sentido de que o testador passa sequencialmente pelo histórico de cotações num loop e abre e fecha trades como se fosse uma transação real. Nesse caso, a compreensão do código é aprimorada e o peeping é eliminado. Vou me concentrar nos pontos principais do código para que você também entenda. Eu não publiquei a versão antiga do testador, mas você pode dar uma olhada nas listagens de artigos anteriores. Meu palpite é que, para a maioria dos leitores, o código abaixo é uma floresta escura, e eles gostariam de obter rapidamente o Graal, sem entrar em detalhes. No entanto, os pontos-chave devem ser esclarecidos.
def tester(dataset, markup, distances, coefficients, plot=False): last_deal = int(2) all_pr = np.array([]) report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] all_pr = np.append(all_pr, dataset['close'][i]) if last_deal == 2: last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 up_range = all_pr[0] - all_pr.min() up_state = 0 up_orders = 0 up_profit = (all_pr[-1] - all_pr[0]) - markup report.append(report[-1] + up_profit) up_profit = 0 for d in np.nditer(distances): if up_state + d <= up_range: up_state += d up_orders += 1 up_profit += (all_pr[-1] - all_pr[0] + up_state) \ * coefficients[int(up_orders-1)] up_profit -= markup * coefficients[int(up_orders-1)] report.append(report[-1] + up_profit) up_profit = 0 all_pr = np.array([dataset['close'][i]]) continue if last_deal == 1 and pred < 0.5: last_deal = 0 dwn_range = all_pr.max() - all_pr[0] dwn_state = 0 dwn_orders = 0 dwn_profit = (all_pr[0] - all_pr[-1]) - markup report.append(report[-1] + dwn_profit) dwn_profit = 0 for d in np.nditer(distances): if dwn_state + d <= dwn_range: dwn_state += d dwn_orders += 1 dwn_profit += (all_pr[0] + dwn_state - all_pr[-1]) \ * coefficients[int(dwn_orders-1)] dwn_profit -= markup * coefficients[int(dwn_orders-1)] report.append(report[-1] + dwn_profit) dwn_profit = 0 all_pr = np.array([dataset['close'][i]]) continue y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.figure(figsize=(12,7)) plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance") plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Historicamente, os produtores estão interessados apenas na curva de equilíbrio e a curva de patrimônio é ignorada. Vamos seguir essa tradição e não complicar um testador já complexo, exibiremos apenas o gráfico de equilíbrio. E a curva de patrimônio sempre pode ser visualizada no terminal MetaTrader 5.
Num loop, percorremos todos os preços e adicionamo-los à matriz all_pr. Depois, há três opções, marcadas. Como o testador foi estudado em artigos anteriores, só explicarei as opções para fechar a grade de ordens quando ocorrer um sinal oposto. Assim como ao marcar trades, a variávelup_range armazena a faixa de preços percorridos no momento do fechamento das posições abertas. A seguir, é calculado o lucro da primeira posição aberta a mercado. Em seguida, o ciclo verifica a presença de ordens pendentes acionadas e, se houverem acionadas, seu resultado é adicionado ao gráfico de equilíbrio. O mesmo acontece com as ordens/posições de venda. Assim, o gráfico de equilíbrio reflete todas as posições fechadas, não o lucro total por grupo.
Testemos novos métodos de trabalho com grades de ordens
O estágio de preparação de dados para aprendizado de máquina parece habitual. Primeiro, obtemos preços e um conjunto de recursos, depois marcamos os dados (criamos tags para compra e venda) e, em seguida, verificamos a marcação num testador personalizado.
# Get prices and labels and test it pr = get_prices(START_DATE, END_DATE) pr = add_labels(pr, 15, 15, GRID_DISTANCES, GRID_COEFFICIENTS) tester(pr, MARKUP, GRID_DISTANCES, GRID_COEFFICIENTS, plot=True)
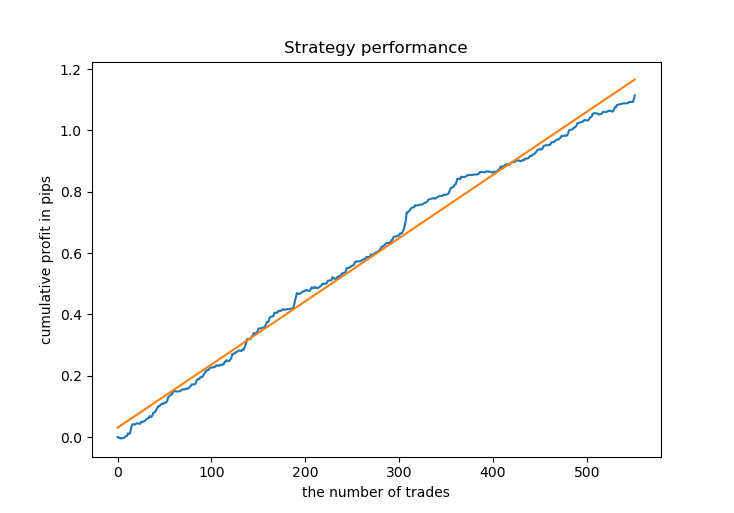
Agora precisamos treinar o modelo CatBoost e testá-lo com base em novos dados. Decidi deixar o treinamento com base em dados sintéticos gerados pelo modelo de mistura gaussiana porque funciona bem.
# Learn and test CatBoost model gmm = mixture.GaussianMixture( n_components=N_COMPONENTS, covariance_type='full', n_init=1).fit(pr[pr.columns[1:]]) res = [] for i in range(10): res.append(brute_force(10000)) print('Iteration: ', i, 'R^2: ', res[-1][0]) res.sort() test_model(res[-1])
Neste exemplo, treinaremos dez modelos com base em 10 000 amostras geradas e escolheremos o melhor por meio de uma pontuação de R^2. O processo de aprendizagem é o seguinte.
Iteration: 0 R^2: 0.8719436661855786 Iteration: 1 R^2: 0.912006346274096 Iteration: 2 R^2: 0.9532278725035132 Iteration: 3 R^2: 0.900845571741786 Iteration: 4 R^2: 0.9651728908727953 Iteration: 5 R^2: 0.966531822300101 Iteration: 6 R^2: 0.9688263099200539 Iteration: 7 R^2: 0.8789927823514787 Iteration: 8 R^2: 0.6084261786804662 Iteration: 9 R^2: 0.884741078512629
A maioria dos modelos tem uma pontuação alta de R^2 em novos dados, o que indica uma alta estabilidade do modelo. Como resultado, o gráfico de equilíbrio dos dados de treinamento e dados fora do treinamento ficou assim.
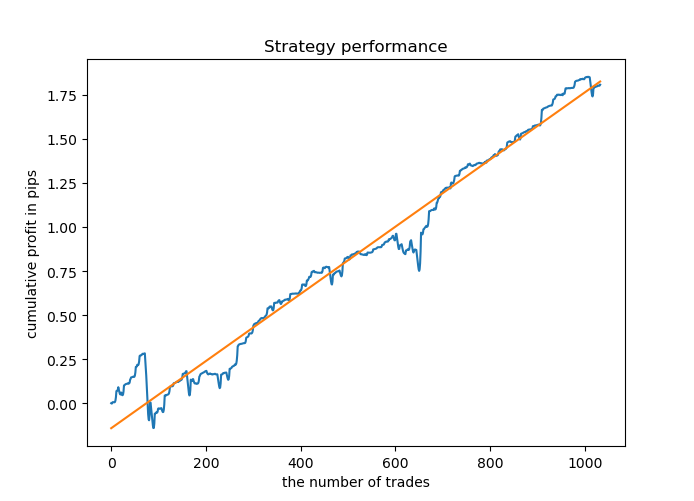
Parece bom. Agora podemos exportar o modelo treinado para MetaTrader 5 e verificar seu desempenho no testador de terminal. Para fazer isso, precisamos preparar um Expert Advisor de negociação e um arquivo de inclusão. Cada modelo treinado terá um arquivo próprio, por isso é fácil armazená-los e alterá-los entre si.
Exportamos modelo CatBoost para MQL5
Para exportar o modelo, chamamos a função.
export_model_to_MQL_code(res[-1][1])
A função sofreu algumas alterações que devem ser explicadas.
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
# add variables
code = '#include <Math\Stat\Math.mqh>'
code += '\n'
code += 'int MAs[' + str(len(MA_PERIODS)) + \
'] = {' + ','.join(map(str, MA_PERIODS)) + '};'
code += '\n'
code += 'int grid_size = ' + str(GRID_SIZE) + ';'
code += '\n'
code += 'double grid_distances[' + str(len(GRID_DISTANCES)) + \
'] = {' + ','.join(map(str, GRID_DISTANCES)) + '};'
code += '\n'
code += 'double grid_coefficients[' + str(len(GRID_COEFFICIENTS)) + \
'] = {' + ','.join(map(str, GRID_COEFFICIENTS)) + '};'
code += '\n'
# get features
code += 'void fill_arays( double &features[]) {\n'
code += ' double pr[], ret[];\n'
code += ' ArrayResize(ret, 1);\n'
code += ' for(int i=ArraySize(MAs)-1; i>=0; i--) {\n'
code += ' CopyClose(NULL,PERIOD_CURRENT,1,MAs[i],pr);\n'
code += ' double mean = MathMean(pr);\n'
code += ' ret[0] = pr[MAs[i]-1] - mean;\n'
code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n'
code += ' ArraySetAsSeries(features, true);\n'
code += '}\n\n'
# add CatBosst
code += 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth")
:data.find("double Scale = 1;")]
code += '\n\n'
code += 'return ' + \
'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' +
str(SYMBOL) + '_cat_model_martin' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc') As configurações de grade que foram usadas durante o treinamento agora estão salvas. Elas também serão usadas durante a negociação.
A média móvel fornecida com o terminal e os buffers do indicador não são mais usados. Em vez disso, todos os recursos são calculados no corpo da função. Ao adicionar recursos próprios, também precisamos adicioná-los à função de exportação.
O caminho para a pasta Include do terminal é marcado em verde para salvar o arquivo .mqh e anexá-lo ao Expert Advisor.
Vamos ver como o próprio arquivo .mqh fica agora (o modelo CatBoost é omitido aqui)
#include <Math\Stat\Math.mqh> int MAs[14] = {5,25,55,75,100,125,150,200,250,300,350,400,450,500}; int grid_size = 10; double grid_distances[10] = {0.003,0.0035555555555555557,0.004111111111111111,0.004666666666666666,0.005222222222222222, 0.0057777777777777775,0.006333333333333333,0.006888888888888889,0.0074444444444444445,0.008}; double grid_coefficients[10] = {1.0,1.4444444444444444,1.8888888888888888,2.333333333333333, 2.7777777777777777,3.2222222222222223,3.6666666666666665,4.111111111111111,4.555555555555555,5.0}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(MAs)-1; i>=0; i--) { CopyClose(NULL,PERIOD_CURRENT,1,MAs[i],pr); double mean = MathMean(pr); ret[0] = pr[MAs[i]-1] - mean; ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Como se pode ver, todas as configurações da grade foram salvas e o modelo está pronto para funcionar, basta anexá-lo ao Expert Advisor.
#include <EURUSD_cat_model_martin.mqh> Agora devemos explicar a lógica do processamento de sinais pelo Expert Advisor usando o exemplo de tudo que funciona na função OnTick(). O bot usa a biblioteca MT4Orders, que deve ser baixada.
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); // закрываем позиции по противоположному сигналу if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // удаляем все отложки, если нет маркет ордеров if(!count_market_orders(0) && !count_market_orders(1)) { for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 2 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic ) if(OrderDelete(OrderTicket())) { } if(OrderType() == 3 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic ) if(OrderDelete(OrderTicket())) { } } } // открываем позиции и отложки по сигналам if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); double p = Ask; for(int i=0; i<grid_size; i++) { p = NormalizeDouble(p - grid_distances[i], _Digits); double gl = NormalizeDouble(l * grid_coefficients[i], 2); OrderSend(Symbol(),OP_BUYLIMIT,gl, p, 0, p-stoploss*_Point, p+takeprofit*_Point, NULL, OrderMagic); } } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); double p = Ask; for(int i=0; i<grid_size; i++) { p = NormalizeDouble(p + grid_distances[i], _Digits); double gl = NormalizeDouble(l * grid_coefficients[i], 2); OrderSend(Symbol(),OP_SELLLIMIT,gl, p, 0, p+stoploss*_Point, p-takeprofit*_Point, NULL, OrderMagic); } } } }
A função fill_arraysprepara recursos para o modelo CatBoost preenchendo com eles uma matriz features. Em seguida, este array é passado para a função catboost_model()que retorna um sinal no intervalo 0;1.
O exemplo de ordens de compra mostra que é usada a variável grid_size(número de ordens pendentes), que estão separados à distância grid_distances entre eles. O lote padrão é multiplicado pelo coeficiente da matriz grid_coefficients, que corresponde ao número da ordem.
Depois que o bot for compilado, podemos prosseguir para o teste.
Verificação de bot no testador MetaTrader 5
É necessário testar o timeframe para o qual o bot foi treinado. Nesse caso, é H1. Podemos testar com base em preços de abertura, já que o bot tem controle explícito sobre a abertura das barras. Mas também é usada uma grade, para maior precisão, podemos selecionar M1 OHLC.
Este bot em particular foi treinado para o período:
START_DATE = datetime(2020, 5, 1) TSTART_DATE = datetime(2019, 1, 1) FULL_DATE = datetime(2018, 1, 1) END_DATE = datetime(2022, 1, 1)
- Do quinto mês do ano 20 até os dias atuais, este é o período de treinamento, que é dividido 50/50 em subamostras de treinamento e validação.
- A partir do 1º mês de 2019, o modelo foi avaliado de acordo com o R^2 e escolhido o melhor.
- Desde 1 mês de 2018, o modelo foi testado com testador personalizado.
- Tomamos dados sintéticos para o treinamento (gerados pelo modelo de mistura gaussiana)
- O modelo CatBoost tem forte regularização, portanto, não se encaixa no conjunto de treinamento.
Todos esses fatores indicam (e o testador personalizado confirma) que um certo padrão foi encontrado no intervalo de 2018 até os dias atuais.
Vamos ver como fica no testador MT5.
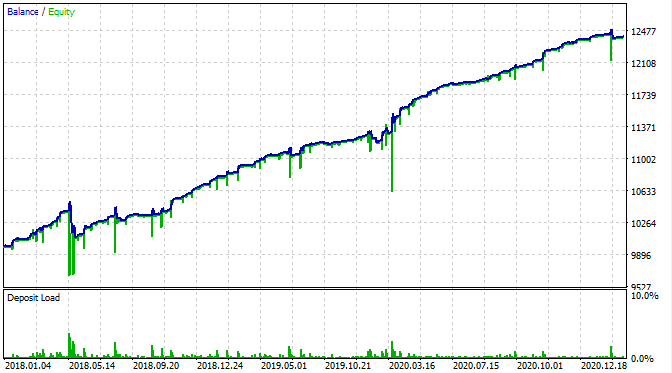
Com a exceção de que os rebaixamentos de capital agora são visíveis, o gráfico de saldo parece o mesmo que no meu testador personalizado. É uma boa notícia. Vamos verificar se o bot está operando com base na grade e nada mais.
Testei o bot desde o início de 2015 e ele mostrou o seguinte resultado.
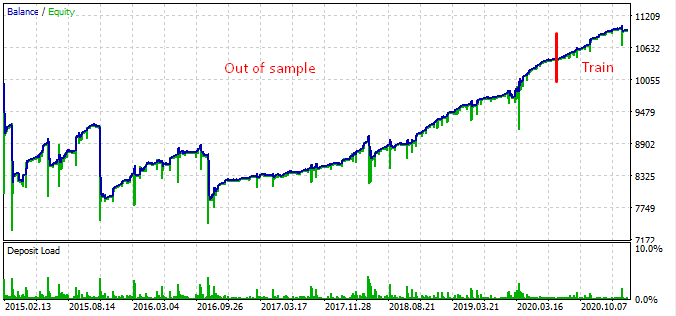
O gráfico indica que o padrão encontrado funciona do final de 2016 até os dias atuais e, em seguida, quebra. O lote inicial neste caso é mínimo, por isso, o bot não deu perda. Bem, sabemos que o bot está em execução desde o início de 2017 e pode aumentar o risco para aumentar a lucratividade. Nesse caso, mostra uns impressionantes 1 600% ao longo de 3 anos com um rebaixamento de 40% e um risco hipotético de uma perder completa.
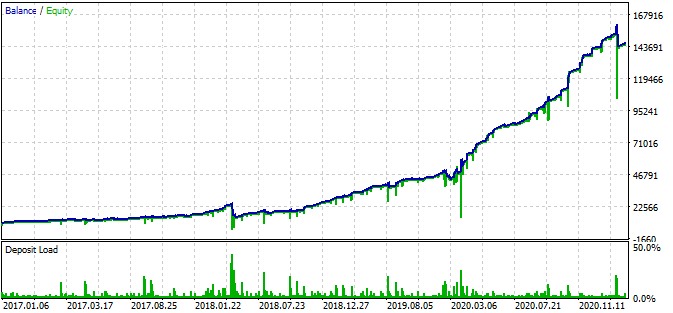
O robô também possui um stop loss e take profit para cada posição. Eles podem ser usados sacrificando o desempenho e, ao mesmo tempo, limitando os riscos.
Vale a pena ressaltar que usei uma grade bastante agressiva.
GRID_COEFFICIENTS = np.linspace(1, 5, num= GRID_SIZE)
array([1. , 1.44444444, 1.88888889, 2.33333333, 2.77777778, 3.22222222, 3.66666667, 4.11111111, 4.55555556, 5. ])
O último fator é cinco. Isso significa que o lote da última ordem da série é cinco vezes maior que o inicial, o que acarreta riscos adicionais. Você pode escolher modos mais suaves.
Por que o bot parou de funcionar em 2016 e antes? Não tenho uma boa resposta para esta pergunta. Parece que existem longos ciclos de sete anos no FOREX ou mais curtos, cujos padrões não estão de forma alguma relacionados uns com os outros. Este é um tópico separado que requer consideração cuidadosa.
Fim do artigo
Neste artigo, tentei descrever a técnica pela qual podemos treinar boosting ou uma rede neural para operar usando martingale. Foi proposta uma solução pronta que permite criar bots prontos para negociação.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/8826
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
 Força bruta para encontrar padrões (Parte IV): funcionalidade mínima
Força bruta para encontrar padrões (Parte IV): funcionalidade mínima
 Redes Neurais de Maneira Fácil (Parte 12): Dropout
Redes Neurais de Maneira Fácil (Parte 12): Dropout
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Com tempos extraordinários em que os bancos centrais estão imprimindo dinheiro como nunca antes, é muito provável que muitos ativos estejam inclinados para uma direção (para cima). Com o backtesting dos últimos 3 anos apenas, esse sistema de negociação está propenso a enfrentar um risco maior quando os bancos centrais tiverem que aumentar as taxas (você pode argumentar, se quiser, que isso nunca acontece, mas você pode garantir isso 100%?)
Então, os saques serão maiores do que os ~40% relatados no artigo. Para qualquer investidor sério, esses riscos não são aceitáveis.
Muito obrigado por seu interessante artigo.
Posso concluir que seu sistema adapta automaticamente a etapa e o coeficiente de martingale de acordo com as condições do mercado, ou é preciso fazer um backtest em python e gerar o arquivo de inclusão periodicamente.
Mais uma vez, obrigado.
O sistema Martingale é bom para ganhar algum dinheiro no curto prazo (com sorte), mas no longo prazo você vai à falência. Não importa quão complicada seja sua escolha.
Concordo. Grid, hedging e martingale são populares por sua rentabilidade rápida e regular. Elas também são responsáveis por todas as reclamações contra o fato de a EA ser uma fraude, por causa da chamada de margem que ela expõe como uma constante.
É um problema lógico e matemático, aquele que o resolver - de uma forma ou de outra - ganhará muuuuito dinheiro!
According to the graph, the found pattern works from the end of 2016 to the present day, in the rest interval it fails.Aqui está outra tentativa com aprendizado de máquina...
Há muitos anos, tenho um código-fonte de um EA que usa essas técnicas e, de vez em quando, quando tenho uma ideia, faço uma tentativa... 😉