
Redes neurais em trading: Transformador hierárquico com duas torres (Conclusão)

Introdução
No artigo anterior, exploramos os aspectos teóricos do framework Hidformer, desenvolvido especialmente para análise e previsão de séries temporais multivariadas complexas. O modelo demonstra alta eficiência no processamento de dados dinâmicos e voláteis, graças à sua arquitetura única.
O elemento-chave do Hidformer é a utilização de mecanismos de atenção aprimorados, que permitem não apenas identificar dependências explícitas nos dados, mas também revelar conexões profundas e ocultas. Para isso, o modelo emprega um codificador com duas torres, cada uma realizando uma análise independente dos dados brutos. Uma torre se especializa na análise da estrutura temporal, identificando tendências e padrões, enquanto a outra realiza uma investigação no domínio da frequência. Essa abordagem oferece uma visão abrangente da dinâmica do mercado, permitindo considerar tanto as mudanças de curto quanto de longo prazo nas séries de preços.
Um aspecto inovador do modelo é a aplicação de um mecanismo de atenção recursiva para analisar as dependências temporais, permitindo o acúmulo sequencial de informações sobre padrões dinâmicos complexos do instrumento financeiro analisado. Em conjunto com o mecanismo de atenção linear, usado para analisar o espectro de frequência dos dados brutos, essa abordagem otimiza os custos computacionais e garante a estabilidade do treinamento. Isso permite ao framework Hidformer adaptar-se de forma eficaz à multidimensionalidade e não linearidade dos dados analisados, oferecendo previsões mais confiáveis em cenários de alta volatilidade do mercado.
O decodificador do modelo, construído com base em um perceptron multicamada, possibilita a previsão de toda a sequência de preços em um único passo, minimizando o risco de acúmulo de erros típico da previsão passo a passo. Isso melhora significativamente a qualidade das previsões de longo prazo, tornando o modelo especialmente valioso para aplicações práticas na análise financeira.
A visualização autoral do framework Hidformer é apresentada abaixo.
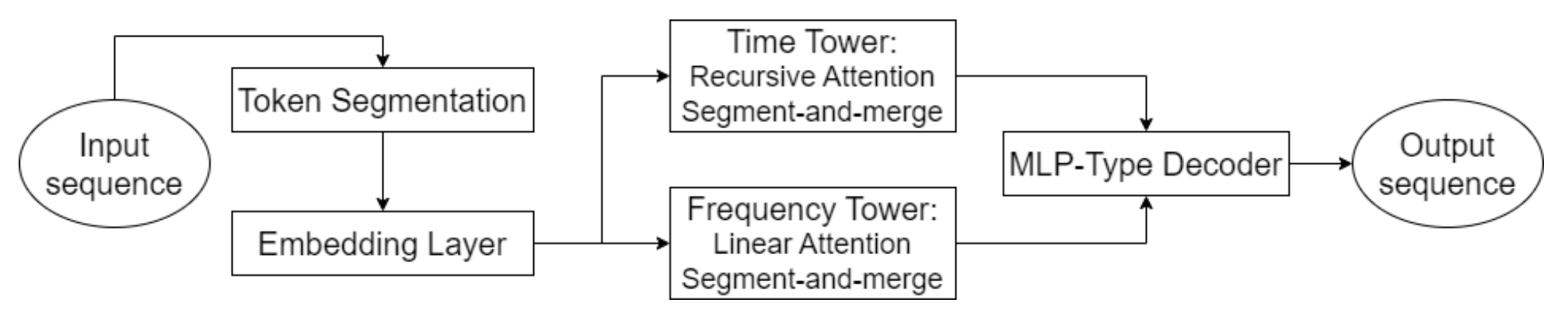
Na parte prática do artigo anterior, realizamos o trabalho preparatório e já implementamos nossa visão dos algoritmos de atenção recursiva e linear. E hoje, continuaremos o trabalho iniciado na construção das abordagens propostas pelos autores do framework Hidformer.
Análise de sequências temporais
Os autores do framework Hidformer propuseram uma arquitetura de codificador com duas torres, que tomamos como base. Em nossa implementação, cada torre do codificador será representada como um objeto separado, o que permite adaptar o modelo de forma flexível a diferentes tarefas. No entanto, ao contrário do framework original, introduzimos uma série de modificações, ditadas pela mudança no objetivo da tarefa a ser resolvida pelo modelo. Originalmente, o framework foi desenvolvido para prever a continuação da série temporal analisada, mas nós fomos um pouco além.
Baseando-nos na experiência adquirida na implementação dos frameworks MacroHFT e FinCon, utilizamos as torres do codificador como agentes independentes, responsáveis por gerar opções de operações de trading futuras. Essa abordagem permitiu expandir significativamente as funcionalidades do sistema.
Assim como na arquitetura original do Hidformer, nossos agentes irão analisar os dados de mercado sob a forma de sequências temporais multivariadas e suas características no domínio da frequência. O uso do mecanismo de atenção recursiva permite identificar dependências em séries temporais multivariadas, enquanto a análise do espectro de frequência é realizada por meio de objetos de atenção linear. Essa abordagem oferece uma compreensão mais profunda das estruturas presentes nos dados e permite que o modelo se adapte em tempo real às mudanças nas condições de mercado, o que é especialmente importante no trading algorítmico e de alta frequência.
Adicionalmente, cada agente é equipado com um módulo de análise recorrente da sequência de decisões tomadas, o que possibilita avaliá-las no contexto da dinâmica da situação de mercado. Esse módulo permite a análise de decisões anteriores, a identificação das estratégias mais bem-sucedidas e a adaptação do modelo às condições de mercado em constante mudança.
O agente de análise da sequência temporal é construído como um objeto CNeuronHidformerTSAgent, cuja estrutura é apresentada abaixo.
class CNeuronHidformerTSAgent : public CResidualConv { protected: CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveState; CResidualConv cResidualState; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerTSAgent(void) {}; ~CNeuronHidformerTSAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerTSAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Como classe pai, neste caso, utilizamos um bloco convolucional com feedback, que atuará como o bloco FeedForward de um dos blocos internos de atenção.
Vale destacar que a estrutura apresentada inclui uma ampla gama de componentes diversos, cada um desempenhando sua função única na implementação dos algoritmos dessa nova classe. Esses elementos garantem a versatilidade da abordagem, permitindo ao modelo adaptar-se a diferentes cenários de processamento de informação e análise de padrões complexos. Vamos conhecer cada um desses componentes com mais detalhes durante a construção dos métodos da classe.
Todos os objetos internos foram declarados de forma estática, o que nos permite deixar o construtor e o destrutor da classe vazios. A inicialização de todos os objetos internos herdados e declarados é realizada no método Init. Nos parâmetros desse método, recebemos uma série de constantes que fornecem uma visão clara da arquitetura do objeto que está sendo criado.
bool CNeuronHidformerTSAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
As operações de inicialização do objeto começam com a chamada do método correspondente da classe pai, onde já estão organizados os pontos necessários de controle e inicialização dos objetos herdados. Deve-se considerar que as interfaces do objeto pai devem produzir os resultados esperados do funcionamento do agente. Neste caso, esperamos obter na saída do agente um tensor de operações de trading, onde cada operação é representada por três parâmetros principais: volume da operação, e os níveis de stop loss e take profit. As operações de compra e venda são representadas por linhas separadas nesta matriz. Assim, ao chamar o método de inicialização da classe pai, definimos o tamanho das janelas dos dados brutos e dos resultados como igual a 3, e o comprimento da sequência como sendo três vezes menor que o vetor de ações do agente.
Após a execução bem-sucedida das operações da classe pai, realiza-se a inicialização dos objetos internos recém-declarados. Primeiro são inicializadas as estruturas responsáveis pela formação do tensor de papéis do agente. A concepção dessas estruturas foi emprestada da arquitetura do framework FinCon e adaptada à tarefa atual. A principal vantagem dessa concepção está na divisão das funções de análise dos dados brutos entre diversos agentes trabalhando em paralelo, permitindo que concentrem sua atenção em aspectos distintos da sequência analisada.
//--- Role int index = 0; if(!caRole[0].Init(10 * window_key, index, OpenCL, 1, optimization, iBatch)) return false; caRole[0].getOutput().Fill(1); index++; if(!caRole[1].Init(0, index, OpenCL, 10 * window_key, optimization, iBatch)) return false;
Em seguida, é feita a inicialização do módulo de atenção cruzada relativa, que permite destacar características-chave dos dados brutos, de acordo com o contexto do papel do agente.
//--- State to Role index++; if(!cStateToRole.Init(0, index, OpenCL, window, window_key, units_count, heads, window_key, 10, optimization, iBatch)) return false;
Após essa etapa de pré-processamento dos dados brutos, retornamos à arquitetura original do framework Hidformer, que prevê um mecanismo de segmentação dos dados antes de sua entrada no codificador. É importante destacar que a segmentação é feita de forma independente em cada torre, o que evita correlações indesejadas entre diferentes fluxos de dados e aumenta a adaptabilidade do modelo a sequências de entrada heterogêneas.
Em nossa versão modificada, complementamos a funcionalidade do agente substituindo a segmentação clássica por um módulo especializado S3. Esse módulo não apenas realiza a segmentação dos dados, mas também implementa um mecanismo de embaralhamento treinável dos segmentos. Essa abordagem permite identificar melhor as dependências ocultas entre diferentes partes da sequência. Como resultado, o agente passa a ter a capacidade de formar representações mais estáveis e generalizadas.
//--- State index++; if(!cShuffle.Init(0, index, OpenCL, window, window * units_count, optimization, iBatch)) return false;
Os dados preparados nas etapas anteriores são enviados para o codificador, composto por um módulo de atenção recursiva e um bloco convolucional com feedback.
index++; if(!cRecursiveState.Init(0, index, OpenCL, window, window_key, units_count, heads, stack_size, optimization, iBatch)) return false; index++; if(!cResidualState.Init(0, index, OpenCL, window, window, units_count, optimization, iBatch)) return false;
Esse tipo de codificador nos permite analisar a sequência original no contexto do último preço, identificando prováveis níveis de suporte e resistência, ou estruturas que formam padrões consistentes.
Na etapa seguinte, mais uma vez nos afastamos da versão original do framework Hidformer e adicionamos um módulo de análise das ações anteriores tomadas pelo agente. Aqui, começamos analisando de forma recursiva as últimas decisões do agente no contexto da sequência histórica.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Em seguida, utilizamos o módulo de atenção cruzada multiescalar para analisar a política adotada pelo agente no contexto da dinâmica da situação de mercado.
index++; if(!cActionToState.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
A funcionalidade do bloco FeedForward é implementada com os recursos da classe pai.
Após a inicialização bem-sucedida de todos os objetos internos, retornamos o resultado lógico da execução das operações ao programa chamador e encerramos o funcionamento do método.
Na etapa seguinte, passamos à construção dos algoritmos de propagação para frente, que organizamos no método feedForward. Nos parâmetros desse método, recebemos um ponteiro para o objeto que contém os dados brutos.
bool CNeuronHidformerTSAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
No corpo do método, começamos gerando o tensor que descreve o papel do agente atual. No entanto, essa operação é realizada apenas durante o treinamento do modelo. Não é difícil imaginar que, no processo de utilização prática do modelo, a cada iteração da propagação para frente será gerado um tensor de papel fixo. O que torna essa operação desnecessária. Por isso, primeiro verificamos o modo de funcionamento do modelo e só então chamamos o método de propagação para frente da camada interna totalmente conectada responsável pela geração do tensor de papel. Essa abordagem nos permite eliminar operações desnecessárias no modo de utilização prática do modelo e reduzir o tempo gasto no processo de tomada de decisão.
Em seguida, passamos ao processamento dos dados brutos recebidos. Aqui, primeiro identificamos os momentos relevantes para o papel do nosso agente. Essa operação é realizada pelos recursos do objeto de atenção cruzada.
//--- State to Role if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false;
Depois disso, o estado analisado do ambiente, já com os devidos focos destacados, é segmentado e embaralhado.
//--- State if(!cShuffle.FeedForward(cStateToRole.AsObject())) return false;
Depois disso, ele é processado no módulo de atenção recursiva, onde a descrição do estado analisado do ambiente é enriquecida com os dados da dinâmica anterior do movimento de preços.
if(!cRecursiveState.FeedForward(cShuffle.AsObject())) return false; if(!cResidualState.FeedForward(cRecursiveState.AsObject())) return false;
Na etapa seguinte, realizamos uma análise aprofundada da política de comportamento do agente. Em primeiro lugar, é analisada a última decisão tomada no contexto das ações anteriores, armazenadas na memória do módulo de atenção recursiva.
//--- Action if(!cRecursiveAction.FeedForward(AsObject())) return false;
Em seguida, analisamos a política de ações do agente no contexto da dinâmica das mudanças do ambiente, utilizando os recursos do módulo de atenção cruzada multiescalar.
if(!cActionToState.FeedForward(cRecursiveAction.AsObject(), cResidualState.getOutput())) return false;
É fácil notar que a arquitetura do módulo de análise das ações do agente foi inspirada no decodificador clássico do Transformer. O decodificador tradicional utiliza sequencialmente os módulos Self-Attention → Cross-Attention → FeedForward. No nosso caso, o módulo Self-Attention foi substituído pelo objeto de atenção recursiva, conforme os princípios do framework Hidformer. Seguindo esses mesmos princípios, substituímos a multicaudalidade do Cross-Attention pela multiescalaridade. Resta adicionar o bloco FeedForward. Sua função será desempenhada pelos recursos da classe pai. Mas, antes de utilizá-los, devemos observar que na entrada desse decodificador modificado são fornecidos os resultados da propagação para frente anterior do nosso método. E para que as operações de propagação reversa sejam executadas corretamente, é recomendável que salvemos esses resultados. Para isso, vamos alterar os ponteiros para os buffers de dados herdados, e só depois chamamos o método de propagação para frente da classe pai.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CResidualConv::feedForward(cActionToState.AsObject()); }
O resultado lógico da execução das operações é retornado ao programa chamador, encerrando assim a execução do método.
Na próxima etapa do nosso trabalho, passamos à construção dos algoritmos de propagação reversa. Como você sabe, o processo de propagação reversa em nossos objetos é representado por dois métodos: calcInputGradients e updateInputWeights. O primeiro é responsável pela distribuição correta do gradiente de erro entre todos os objetos envolvidos no processo de tomada de decisão, conforme sua influência no resultado final. O segundo realiza a otimização dos parâmetros treináveis do modelo com o objetivo de minimizar o erro total. O algoritmo do segundo método, geralmente, não apresenta dificuldades. Nele, normalmente, apenas chamamos os métodos de mesmo nome dos objetos internos que contêm os parâmetros treináveis, passando os dados brutos utilizados durante a propagação para frente. Já o algoritmo do método de distribuição do gradiente de erro está intimamente ligado aos fluxos de informação da propagação para frente e exige uma descrição mais detalhada.
Nos parâmetros do método de distribuição do gradiente de erro, calcInputGradients, recebemos um ponteiro para o objeto de dados brutos. Trata-se do mesmo objeto que foi passado durante a propagação para frente. Só que, desta vez, devemos transmitir a ele o gradiente de erro correspondente à influência dos dados brutos sobre o resultado do modelo. É evidente que, para transferir os dados, precisamos de um ponteiro válido para o objeto. Por isso, no corpo do método, verificamos imediatamente a validade do ponteiro recebido.
bool CNeuronHidformerTSAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Após a validação bem-sucedida em um pequeno bloco de controle, passamos à construção do algoritmo de distribuição do gradiente de erro.
Já mencionamos diversas vezes que os fluxos de informação na distribuição do gradiente repetem completamente os fluxos equivalentes da propagação para frente, apenas em direção oposta. As operações do método de propagação para frente se encerraram com a chamada ao método da classe pai. Logo, a distribuição do gradiente de erro começa utilizando os recursos herdados. Aqui, chamamos o método homônimo da classe pai para transmitir o erro ao nível do objeto de atenção cruzada multiescalar, que analisa a política de comportamento do agente e a dinâmica do mercado.
if(!CResidualConv::calcInputGradients(cActionToState.AsObject())) return false;
Em seguida, precisamos dividir o gradiente de erro recebido entre dois fluxos de informação: o da análise da política de comportamento do agente e o do estado do ambiente, representado por uma série temporal multivariada.
if(!cRecursiveAction.calcHiddenGradients(cActionToState.AsObject(), cResidualState.getOutput(), cResidualState.getGradient(), (ENUM_ACTIVATION)cResidualState.Activation())) return false;
Primeiramente, vamos distribuir o gradiente de erro pela linha de análise da política do agente. Para isso, será necessário passá-lo pelo módulo de atenção recursiva das ações do agente. Mas, aqui, é importante destacar que os dados de entrada para esse bloco eram os resultados da última propagação para frente do nosso objeto. Esses dados foram previamente salvos em um buffer especial. Agora, para garantir a correta distribuição do erro, precisamos restaurá-los temporariamente no buffer de resultados, sem perder os dados atuais. Para isso, mais uma vez substituímos os ponteiros dos buffers de dados.
Além disso, durante o processo de distribuição do gradiente de erro, os dados existentes serão sobrescritos no buffer correspondente às interfaces do nosso objeto. Isso é extremamente indesejável, já que ainda precisaremos desses dados para ajustar os parâmetros treináveis. Assim, também realizamos a substituição do ponteiro e do buffer de gradientes de erro.
Somente após garantir que todos os dados necessários foram preservados, realizamos as operações de distribuição do gradiente de erro através do módulo de atenção recursiva. E, após a execução bem-sucedida dessas operações, restauramos os ponteiros dos buffers de dados ao seu estado original.
//--- Action CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cRecursiveAction.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cRecursiveAction.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Em seguida, passamos à distribuição do gradiente de erro pela linha de análise da série temporal multivariada que descreve o estado do ambiente. Aqui, primeiro propagamos os erros até o nível do módulo de atenção recursiva que analisa o estado do ambiente.
//--- State if(!cRecursiveState.calcHiddenGradients(cResidualState.AsObject())) return false;
Depois disso, transmitimos os erros ao nível do bloco de segmentação e embaralhamento.
if(!cShuffle.calcHiddenGradients(cRecursiveState.AsObject())) return false;
Seguindo por essa linha, encaminhamos as informações ao nível do objeto de atenção cruzada, que analisa os dados brutos no contexto do papel do agente.
if(!cStateToRole.calcHiddenGradients(cShuffle.AsObject())) return false;
A partir daí, o gradiente de erro é novamente dividido em dois fluxos de informação: um direcionado ao objeto de dados brutos e outro à linha de formação do papel do agente.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
Aqui vale destacar que, na linha de formação do papel do agente, não continuamos a distribuição do gradiente de erro. Afinal, a primeira camada dessa MLP possui valor fixo, e os parâmetros treináveis estão somente na segunda camada neural, cujo erro já foi transmitido.
Agora, resta-nos apenas retornar o resultado lógico da execução das operações ao programa chamador e finalizar o método.
Com isso, concluímos a análise dos algoritmos utilizados na construção dos métodos do agente de análise da sequência temporal do estado do ambiente. O código completo do objeto apresentado e de todos os seus métodos pode ser consultado no anexo.
Trabalho com o domínio da frequência
A próxima etapa do nosso trabalho é a construção do agente de análise das características no domínio da frequência do sinal analisado. Desde já, podemos dizer que a estrutura desse agente é bastante semelhante à do agente de análise da sequência temporal criado anteriormente. Mas, ao mesmo tempo, ela apresenta algumas particularidades relacionadas à transformação do sinal original em seu espectro de frequência. Para destacar os componentes de alta e baixa frequência do sinal que descreve o estado do ambiente, utilizamos em nossa implementação a transformada wavelet discreta, conforme aplicada no framework Multitask-Stockformer.
Os algoritmos do agente do domínio da frequência são implementados como um objeto CNeuronHidformerFreqAgent, cuja estrutura está apresentada a seguir.
class CNeuronHidformerFreqAgent : public CResidualConv { protected: CNeuronTransposeOCL cTranspose; CNeuronLegendreWaveletsHL cLegendre; CNeuronTransposeRCDOCL cHLState; CNeuronLinerAttention cAttentionState; CResidualConv cResidualState; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerFreqAgent(void) {}; ~CNeuronHidformerFreqAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerFreqAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Na estrutura apresentada, é fácil notar nomes semelhantes entre os objetos internos, o que indica a estrutura correlata dos agentes dos domínios temporal e frequencial. Mas também há diferenças, que analisaremos com mais detalhes ao longo da construção dos algoritmos dos métodos da nova classe.
Todos os objetos internos são declarados de forma estática, o que nos permite deixar o construtor e o destrutor do objeto vazios. A inicialização de todos os objetos recém-declarados e herdados é realizada no método Init.
bool CNeuronHidformerFreqAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
Nos parâmetros deste método, recebemos uma série de constantes que permitem interpretar de forma clara a arquitetura do objeto que está sendo criado. E no corpo do método, chamamos diretamente o método homônimo da classe pai, no qual já estão implementados os pontos necessários de controle e a inicialização dos objetos e interfaces herdados. Aqui é importante destacar que, apesar da diferença nos domínios dos dados analisados, na saída do agente continuamos esperando o mesmo tensor de operações de trading. Por isso, as abordagens descritas anteriormente para a chamada do método de inicialização da classe pai no agente de análise da série temporal também se aplicam aqui.
Em seguida, passamos à inicialização dos objetos recém-declarados. E aqui já percebemos uma diferença na construção dos agentes de domínios distintos. O agente de análise das características de frequência não possui módulo de geração de papel. Em nossa implementação, não planejamos usar um grande número de agentes do domínio da frequência.
Além disso, o bloco de segmentação foi substituído por um módulo de transformada wavelet discreta. A conversão da série temporal para o domínio da frequência é feita em termos de sequências unitárias. E, para facilitar o trabalho com essas sequências, precisamos previamente transpor a matriz de dados brutos.
int index = 0; if(!cTranspose.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
As séries temporais unitárias são divididas em segmentos de tamanho igual. Para cada segmento, é realizada a transformada wavelet discreta, o que permite destacar componentes estruturais relevantes nas dependências temporais. O tamanho mínimo de segmento é limitado a cinco elementos, o que garante um equilíbrio entre precisão analítica e custo computacional.
index++; uint wind = (units_count>=20 ? (units_count + 3) / 4 : units_count); uint units = (units_count + wind - 1) / wind; if(!cLegendre.Init(0, index, OpenCL, wind, wind, units, filters, window, optimization, batch)) return false;
Aqui é importante observar que, na saída do módulo de transformada wavelet discreta, obtemos um tensor que contém as componentes de alta e baixa frequência do sinal analisado. A componente de alta frequência segue diretamente após a de baixa frequência em cada segmento individual, e os dados podem ser representados como um tensor tridimensional [Segment, [Low, High], Filters].
Para a análise posterior, é importante separar os dados em componentes correspondentes. No entanto, como se espera que ambos os tipos de sinal passem por operações idênticas, é mais racional processá-los em paralelo. Por isso, não fazemos uma separação explícita do sinal em objetos distintos, mas realizamos uma transposição do tensor, o que permite gerenciar de forma mais eficiente os recursos computacionais e acelerar o processamento dos dados.
index++; if(!cHLState.Init(0, index, OpenCL, units * window, 2, filters, optimization, iBatch)) return false;
Agora, conforme previsto pelos autores do framework Hidformer, utilizamos o algoritmo de atenção linear. Em nosso caso, realizamos uma análise separada das componentes de alta e baixa frequência, o que permite destacar os padrões mais relevantes e adaptar dinamicamente a estratégia de processamento de sinais de acordo com suas características espectrais.
index++; if(!cAttentionState.Init(0, index, OpenCL, filters, filters, units* window, 2, optimization, iBatch)) return false;
Os resultados obtidos são processados por um bloco convolucional com feedback, que desempenha o papel do módulo FeedForward em nosso codificador do domínio da frequência.
index++; if(!cResidualState.Init(0, index, OpenCL, filters, filters, 2 * units * window, optimization, iBatch)) return false;
Em seguida, inicializamos o bloco de análise da política utilizada pelo agente, semelhante ao que já foi abordado anteriormente na construção do agente de análise da sequência temporal. Mas aqui há uma particularidade. Enquanto no funcionamento do módulo de atenção linear a ordem dos segmentos não é importante — já que a análise é feita sobre toda a sequência de uma vez —, no caso do módulo de atenção cruzada multiescalar, nos deparamos com a questão da priorização dos segmentos. Afinal, nosso módulo de atenção cruzada multiescalar foi projetado para operar com sequência temporal e dá prioridade aos elementos mais recentes.
Para resolver esse problema, utilizamos o objeto de segmentação e embaralhamento. Neste caso, nossos dados já estão segmentados, e o foco está no processo de embaralhamento treinável dos segmentos. Essa abordagem permitirá que o modelo aprenda por si só a prioridade entre os segmentos, com base nos dados apresentados durante o treinamento.
index++; if(!cShuffle.Init(0, index, OpenCL, filters, cResidualState.Neurons(), optimization, iBatch)) return false;
Não vamos nos deter aqui na descrição da funcionalidade dos objetos utilizados no módulo de análise da política do agente, já que mantivemos os mesmos princípios apresentados na construção do agente de análise da sequência temporal.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false; index++; if(!cActionToState.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, filters, 2 * units * window, optimization, iBatch)) return false; //--- return true; }
Após a inicialização bem-sucedida de todos os objetos internos, encerramos a execução do método, retornando antes disso o resultado lógico de sua execução ao programa chamador.
Com o objetivo de poupar espaço neste artigo, proponho deixar para estudo individual os métodos de propagação para frente e propagação reversa. Seus algoritmos foram construídos com base nos mesmos princípios descritos anteriormente na implementação dos métodos correspondentes do agente de análise da sequência temporal. O código completo dos objetos de ambos os agentes e de seus métodos está disponível no anexo.
Objeto de nível superior
Após a construção dos objetos das torres de análise da série temporal multivariada e de suas características no domínio da frequência, para completar o framework Hidformer, basta unificá-los em uma estrutura única e adicionar o decodificador. Os autores do framework Hidformer utilizaram MLP como decodificador para prever a continuação esperada da série temporal analisada. Apesar de termos alterado o objetivo da tarefa resolvida pelo modelo, é igualmente possível utilizar um perceptron para gerar a decisão final. No entanto, fomos um pouco além e tomamos emprestada a ideia hiperagente presente no framework MacroHFT. Inspirados por essa ideia, criamos um novo objeto, CNeuronHidformer, cuja estrutura é apresentada a seguir.
class CNeuronHidformer : public CNeuronBaseOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronHidformerTSAgent caTSAgents[4]; CNeuronHidformerFreqAgent caFreqAgents[2]; CNeuronMacroHFTHyperAgent cHyperAgent; CNeuronBaseOCL cConcatenated; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformer(void) {}; ~CNeuronHidformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint stack_size, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Na arquitetura apresentada do novo objeto, é fácil identificar a semelhança estrutural com a classe CNeuronMacroHFT, que faz parte do framework MacroHFT. Na prática, essa nova estrutura representa uma versão modificada da anterior, na qual os princípios fundamentais foram preservados, mas alterações específicas foram implementadas para aumentar a eficiência no processamento dos dados.
A principal diferença está na configuração alterada dos agentes de análise do ambiente. Nesta versão, são utilizados seis agentes especializados: quatro deles realizam a análise de séries temporais multivariadas e dois são destinados ao processamento dos dados brutos no domínio da frequência. Para garantir uma análise equilibrada, todos os agentes são distribuídos de forma uniforme entre os dados brutos em sua forma original e transposta. Essa arquitetura permite investigar com mais profundidade diferentes aspectos dos dados brutos, identificando padrões ocultos e ajustando de forma adaptativa a estratégia de processamento.
De modo geral, a alteração na estrutura dos agentes introduziu apenas mudanças sutis nos algoritmos dos métodos do novo objeto. A lógica principal de funcionamento permaneceu intacta, e todos os princípios-chave do modelo foram preservados. Com base nisso, convido você a explorar por conta própria os algoritmos de construção dos métodos. O código completo desse objeto e de todos os seus métodos está disponível no anexo.
Arquitetura do modelo
Algumas palavras sobre a arquitetura do modelo treinável. Acredito que você tenha percebido que a arquitetura que construímos representa uma espécie de fusão entre os frameworks Hidformer e MacroHFT. A arquitetura do modelo treinável e os métodos de treinamento não são exceção. Em nosso trabalho, copiamos a arquitetura do modelo construída na implementação do framework MacroHFT e substituímos apenas uma camada.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHidformer; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Scales descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
No restante, a arquitetura operacional permanece inalterada, incluindo o uso de um agente de gerenciamento de risco. A descrição completa da arquitetura do modelo pode ser consultada no anexo. No mesmo local, está o código completo dos programas de treinamento e teste do modelo, os quais foram totalmente transferidos do artigo anterior sem modificações.
Testes
Realizamos juntos um extenso trabalho de implementação da nossa própria interpretação das abordagens propostas pelos autores do framework Hidformer. E agora nos aproximamos do momento mais crítico, especificamente da verificação da eficácia das soluções implementadas em dados históricos reais. Em nossa implementação, aproveitamos muitos elementos do framework MacroHFT. E, de forma bastante lógica, decidimos comparar o desempenho do novo modelo justamente com esse framework. Para isso, treinamos o novo modelo com o mesmo conjunto de dados de treinamento anteriormente utilizado para treinar o modelo da nossa implementação do framework MacroHFT.
Lembro que o conjunto de dados de treinamento foi coletado com base em dados históricos de todo o ano de 2024 para o par de moedas EURUSD no timeframe M1. Os parâmetros de todos os indicadores analisados foram utilizados em seus valores padrão.
Para o treinamento e teste do modelo, foram utilizados os mesmos EAs (Expert Advisors). O teste da modelo foi realizado com dados históricos de janeiro de 2025, mantendo todos os demais parâmetros inalterados. Os resultados do teste estão apresentados abaixo.
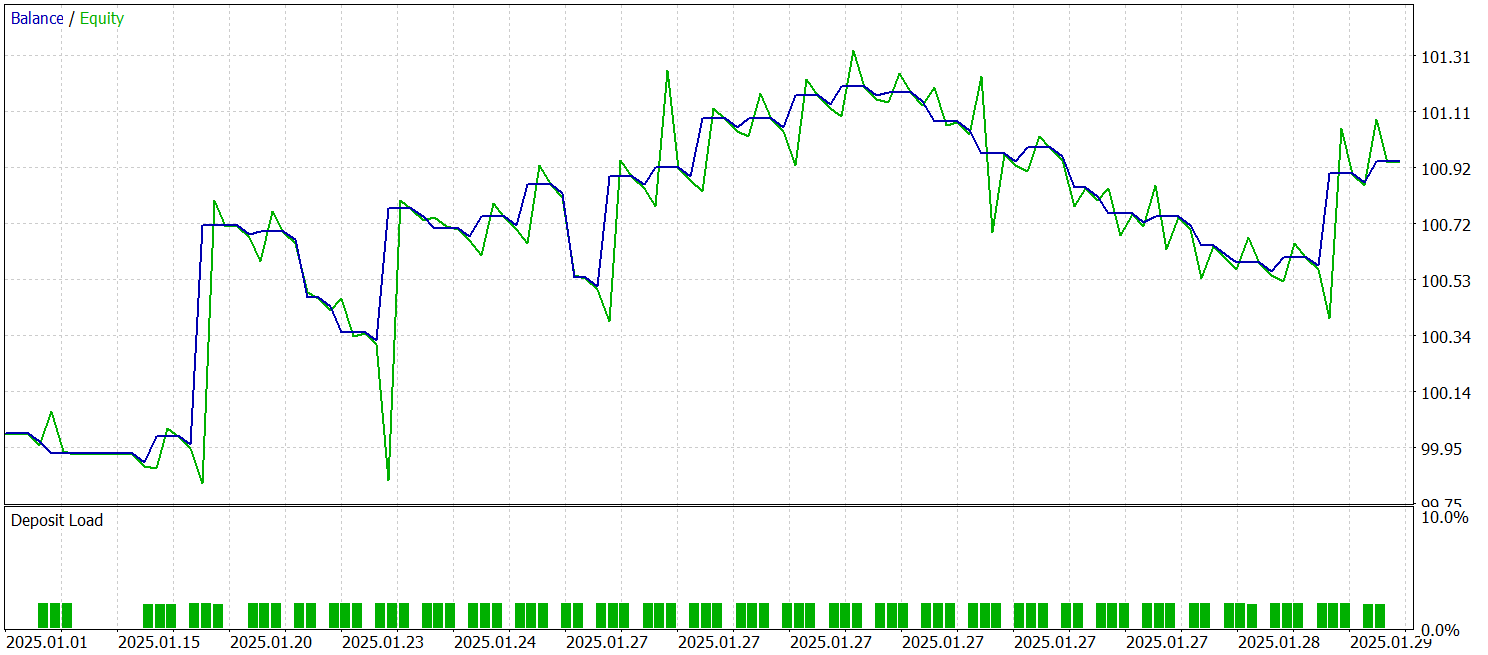
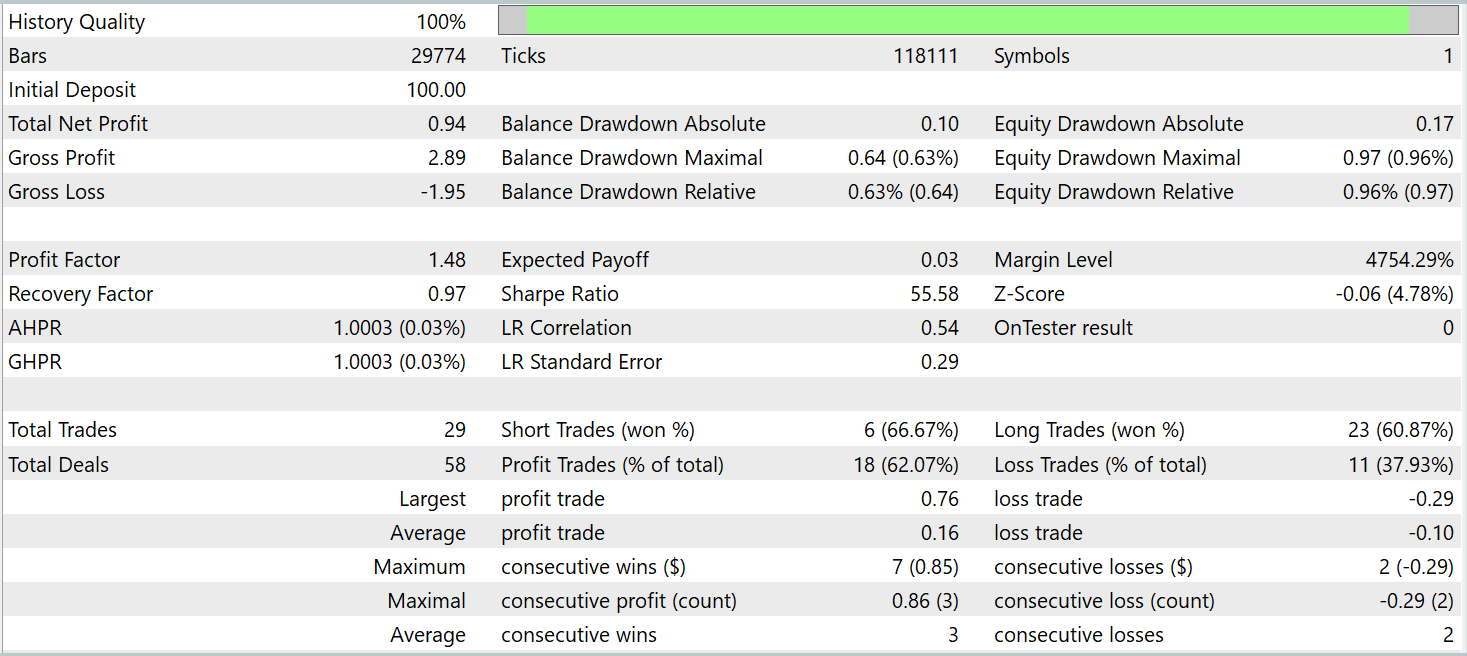
Com base nos resultados do teste, o modelo conseguiu obter lucro em dados históricos fora do conjunto de treinamento. No total, durante o mês-calendário, o modelo executou 29 operações. Isso representa, em média, pouco mais de uma operação por dia útil, o que é naturalmente pouco para trading de alta frequência. No entanto, tivemos mais de 60% de operações lucrativas, e o lucro médio das operações vencedoras superou em 60% a média das operações perdedoras.
Considerações finais
Conhecemos o framework Hidformer, projetado para análise e previsão de séries temporais multivariadas complexas. O modelo demonstra alta eficiência, graças à sua arquitetura única de codificador com duas torres. Uma torre é especializada na análise da estrutura temporal dos dados brutos, enquanto a outra atua sobre sua representação no domínio da frequência. O uso do mecanismo de atenção recursiva permite detectar padrões complexos nas variações de preço, enquanto o mecanismo de atenção linear contribui para reduzir a complexidade computacional da análise de sequências longas.
Na parte prática do nosso trabalho, apresentamos a implementação da nossa própria visão das abordagens propostas, utilizando recursos do MQL5. Treinamos o modelo com dados históricos reais e realizamos seu teste com dados que não faziam parte do conjunto de treinamento. Os resultados dos testes demonstram o potencial do modelo. No entanto, antes de utilizá-lo em operações reais de mercado, é necessário treiná-lo com dados mais representativos, seguido de uma testagem completa e rigorosa.
Links
- Hidformer: Transformer-Style Neural Network in Stock Price Forecasting
- Hidformer: Hierarchical dual-tower transformer using multi-scale mergence for long-term time series forecasting
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos usando o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de treinamento de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17104
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso