
Redes neurais em trading: Treinamento multitarefa baseado no modelo ResNeXt (Conclusão)

Introdução
Na parte anterior vimos os aspectos teóricos do framework de aprendizado multitarefa baseado na arquitetura ResNeXt, proposto para a criação de sistemas de análise dos mercados financeiros. O aprendizado multitarefa (Multi-Task Learning, MTL) utiliza um único codificador para processar os dados brutos e várias "cabeças" especializadas (saídas), cada uma projetada para resolver uma tarefa específica. Essa abordagem oferece diversas vantagens.
Primeiro, o uso de um codificador comum facilita a detecção de padrões universais mais estáveis nos dados, que acabam sendo úteis na resolução de tarefas distintas. Diferente dos métodos tradicionais, onde cada modelo é treinado com um subconjunto diferente de dados, a arquitetura multitarefa constrói representações que carregam relações mais fundamentais. Isso torna o modelo mais robusto e menos sensível à presença de ruído nos dados brutos.
Segundo, o treinamento conjunto de várias tarefas reduz a chance de o modelo sofrer overfitting. Se uma das subtarefas estiver lidando com dados de baixa qualidade ou pouco relevantes, as demais tarefas ajudam a neutralizar esse impacto graças à estrutura compartilhada do codificador. Isso melhora a estabilidade e a confiabilidade do modelo, principalmente frente à alta volatilidade dos mercados financeiros.
Terceiro, essa abordagem é mais eficiente em termos de recursos computacionais. Em vez de treinar múltiplos modelos separados com funções semelhantes, o aprendizado multitarefa permite o uso de um único codificador, reduzindo o excesso de cálculo e acelerando o treinamento. Isso é especialmente relevante no trading algorítmico, onde a velocidade do modelo é crucial para tomar decisões comerciais no momento certo.
No contexto dos mercados financeiros, MTL oferece vantagens adicionais por possibilitar a análise simultânea de diversos fatores de mercado. Por exemplo, o modelo pode ao mesmo tempo prever a volatilidade, identificar tendências de mercado, avaliar riscos e considerar o impacto de notícias. A interconexão entre esses aspectos torna o aprendizado multitarefa uma ferramenta poderosa para modelar sistemas de mercado complexos e prever com mais precisão o comportamento dos preços.
Uma das principais vantagens do aprendizado multitarefa é sua capacidade de alterar dinamicamente as prioridades entre diferentes subtarefas. Isso significa que o modelo pode se adaptar às mudanças do ambiente de mercado, dedicando mais atenção aos aspectos que exercem maior influência sobre os movimentos atuais dos preços.
A arquitetura ResNeXt, escolhida pelos autores do framework como base para o codificador, se destaca pela modularidade e alta eficiência. Ela utiliza convoluções agrupadas, o que permite aumentar significativamente o desempenho do modelo sem elevar demais a complexidade computacional. Isso é especialmente importante no processamento de grandes fluxos de dados de mercado em tempo real. A flexibilidade da arquitetura também permite configurar os parâmetros do modelo para tarefas específicas: variar a profundidade da rede, a configuração dos blocos de convolução e os métodos de normalização dos dados, o que torna possível adaptar o sistema a diferentes condições operacionais.
A combinação do aprendizado multitarefa com a arquitetura ResNeXt cria uma ferramenta analítica poderosa, capaz de integrar e processar com eficiência diversas fontes de informação. Essa abordagem não apenas melhora a precisão das previsões, como também permite que o sistema se adapte rapidamente às mudanças do mercado, identificando dependências ocultas e padrões. A identificação automática de características relevantes torna o modelo mais resistente a anomalias e ajuda a minimizar o impacto de ruídos aleatórios do mercado.
Na parte prática da seção anterior, examinamos em detalhe a implementação dos principais componentes da arquitetura ResNeXt usando os recursos do MQL5. Durante esse processo, foi criado um módulo de convolução agrupada com conexão residual, representado pelo objeto CNeuronResNeXtBlock. Essa abordagem proporciona alta flexibilidade ao sistema, bem como sua escalabilidade e eficiência no processamento de dados financeiros.
Neste trabalho, deixaremos de lado a criação do codificador como um objeto monolítico. Em vez disso, os usuários poderão montar a arquitetura do codificador por conta própria, utilizando os blocos construtivos já implementados. Isso garantirá não apenas flexibilidade, mas também ampliará as possibilidades de adaptação do sistema a diferentes tipos de dados financeiros e estratégias de trading. Hoje, o foco principal será no desenvolvimento e treinamento dos modelos dentro do framework de aprendizado multitarefa.
Arquitetura dos modelos
Antes de partir para a implementação técnica, é necessário definir as tarefas principais que os modelos deverão executar. Um dos modelos terá a função de Agente, sendo responsável por formar os parâmetros das operações de trading. Ele irá gerar os parâmetros das ordens, de forma similar às arquiteturas discutidas anteriormente. Essa abordagem permite evitar duplicações desnecessárias de cálculos, aumentar a coerência das previsões e criar uma estratégia unificada de tomada de decisão.
No entanto, essa estrutura por si só não aproveita plenamente o potencial do aprendizado multitarefa. Para alcançar o efeito desejado, será adicionada ao sistema uma segunda modelo, treinada para prever tendências futuras do mercado. Esse bloco preditivo permitirá melhorar a precisão das previsões e a resistência do modelo frente a mudanças repentinas do mercado. Em cenários de alta volatilidade, esse mecanismo permitirá que o modelo se adapte rapidamente às novas informações e tome decisões de trading mais assertivas.
A inclusão de múltiplas tarefas em um único modelo criará um sistema analítico completo, capaz de considerar diversos fatores de mercado e interagir com eles em tempo real. Espera-se que essa abordagem proporcione um grau mais elevado de generalização do conhecimento, possibilite previsões mais precisas e reduza os riscos associados a decisões de trading equivocadas.
A arquitetura dos modelos treináveis é definida no método CreateDescriptions. Nos parâmetros do método, recebemos dois ponteiros para objetos de arrays dinâmicos, onde será descrita a arquitetura dos modelos.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
A principal característica dessa implementação é a criação de dois modelos especializados: o Ator e o modelo preditivo, responsável por estimar a direção futura do preço com base em probabilidade. O codificador do estado do ambiente está diretamente integrado à arquitetura do Ator, o que permite a ele formar representações ricas dos dados de mercado e considerar dependências complexas. Por sua vez, o segundo modelo recebe os dados brutos do espaço latente do Ator, utilizando suas representações treinadas para gerar previsões mais precisas. Essa abordagem não apenas melhora a eficiência das previsões, como também reduz a carga computacional, garantindo a operação coordenada dos dois modelos dentro de um mesmo sistema.
No corpo do método, verificamos imediatamente a validade dos ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos de arrays dinâmicos.
Em seguida, passamos para a criação da arquitetura do nosso Ator, começando pelo Codificador do ambiente. O primeiro componente é uma camada neural básica, destinada a receber os dados brutos. O tamanho da camada é definido com base no volume de dados analisados.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Não utilizamos funções de ativação neste ponto, pois, na prática, os dados brutos obtidos do ambiente são simplesmente transferidos para o buffer de resultados desta camada. No nosso caso, esses dados vêm diretamente do terminal, o que permite preservar sua estrutura original. No entanto, essa abordagem apresenta uma limitação importante: a ausência de um pré-processamento pode prejudicar a capacidade de aprendizado do modelo, já que os dados brutos contêm valores heterogêneos, com escalas e distribuições distintas.
Para resolver essa limitação, logo após a primeira camada aplicamos um mecanismo de normalização em lote (batch normalization). Ele executa a padronização preliminar dos dados, ajustando-os para uma escala comum e melhorando sua comparabilidade. Isso aumenta significativamente a estabilidade do treinamento, acelera a convergência do modelo e reduz o risco de explosão ou desaparecimento do gradiente. Como resultado, mesmo ao lidar com dados de mercado altamente voláteis, o modelo consegue formar representações mais precisas e consistentes, algo essencial para a posterior análise multitarefa.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, utilizamos uma camada convolucional que transforma o espaço de características, padronizando o seu tamanho. Isso permite gerar uma representação unificada dos dados, garantindo consistência nos níveis seguintes do processamento. A função de ativação escolhida é Leaky ReLU (LReLU), o que ajuda a reduzir o impacto de pequenas flutuações e ruídos aleatórios, preservando ao mesmo tempo as informações relevantes dos dados brutos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Após a conclusão do pré-processamento dos dados, iniciamos o projeto da arquitetura do Codificador do estado do ambiente, que exerce papel central na análise e interpretação dos dados brutos. A principal função do Codificador é identificar padrões estáveis e estruturas ocultas no conjunto de dados analisado, o que permite gerar uma representação informativa a ser usada pelas demais partes do modelo responsáveis pela tomada de decisão.
Nosso Codificador será composto por 3 blocos consecutivos da arquitetura ResNeXt, cada um utilizando convoluções agrupadas para extração eficiente de características. Cada bloco emprega um filtro convolucional com janela de tamanho 3 elementos da série temporal multivariada analisada, com passo de convolução de 2 elementos. Isso reduz pela metade a dimensionalidade da sequência original em cada bloco.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {128, 256}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {HistoryBars, 4, 32}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } int units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Seguindo os princípios de construção da arquitetura ResNeXt, a redução da dimensionalidade da série temporal multivariada é compensada por um aumento proporcional na dimensionalidade das características. Essa abordagem preserva a riqueza informacional dos dados, permitindo uma representação mais detalhada das estruturas presentes na série temporal.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Além disso, à medida que aumentamos a dimensionalidade do espaço de características, também expandimos proporcionalmente a quantidade de grupos de convolução, mantendo fixo o tamanho de cada grupo. Isso permite escalar a arquitetura de forma eficiente, garantindo um equilíbrio entre a complexidade computacional e a capacidade do modelo de extrair padrões complexos dos dados.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Após os 3 blocos ResNeXt, a dimensionalidade das características foi aumentada para 1024, com uma redução proporcional na extensão da sequência analisada.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {512, 1024}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 128}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Na sequência, a arquitetura ResNeXt prevê a compactação da sequência analisada no eixo temporal, destacando apenas as características mais relevantes do estado do ambiente analisado. Para isso, primeiro transpomos os dados obtidos:
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = units_out; descr.window = 1024; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, aplicamos uma camada de pooling, que reduz a dimensionalidade dos dados preservando as características mais significativas. Isso permite ao modelo focar nos traços essenciais, eliminando ruídos desnecessários e garantindo uma representação mais compacta dos dados brutos.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = 1024; descr.step = descr.window = units_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Anote o número de ordem dessa camada. Ela representa a última camada do nosso Codificador do estado do ambiente, e será a partir dela que extrairemos os dados brutos para a segunda modelo.
Logo após, vem o Decodificador do nosso Agente, composto por duas camadas totalmente conectadas em sequência.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Ambas as camadas utilizam a função sigmoide como ativação e vão gradualmente reduzindo a dimensionalidade do tensor até atingir o espaço de ações definido para o Agente.
É importante observar que o Agente criado acima analisa apenas o estado bruto do ambiente e não possui nenhum módulo de gerenciamento de risco. Compensaremos essa limitação adicionando uma camada de agente de gerenciamento de risco, implementada segundo o framework MacroHFT.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E adicionaremos uma camada convolucional com função de ativação sigmoide, que ajustará os resultados do Agente ao espaço de valores desejado. Utilizamos uma janela de convolução de tamanho 3, o que corresponde aos parâmetros de uma única operação. Essa abordagem permite obter características das operações mais consistentes.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O próximo passo será descrever o modelo de previsão das probabilidades do movimento futuro do preço. Como mencionado anteriormente, nosso modelo preditivo recebe os dados brutos do estado latente do Agente. Para garantir a consistência entre a dimensionalidade do estado latente e a camada de entrada da segunda modelo, decidimos não ajustar manualmente a arquitetura. Em vez disso, extraímos a descrição da camada de estado latente a partir da descrição da arquitetura do Agente.
//--- Probability probability.Clear(); //--- Input layer CLayerDescription *latent = actor.At(LatentLayer); if(!latent) return false;
Os parâmetros da descrição extraída do estado latente serão transferidos para a camada de entrada da nova modelo.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.count; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
O uso do estado latente de outro modelo como dado de entrada nos permite trabalhar com dados que já foram processados e padronizados. Assim, não há necessidade de aplicar uma camada de normalização em lote para o pré-processamento dos dados brutos. Além disso, na saída do bloco ResNeXt já é realizada a normalização dos resultados na saída.
Para obter os valores previstos da direção futura do movimento dos preços, utilizamos 2 camadas totalmente conectadas em sequência, com função de ativação sigmoide entre elas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Os resultados dessas camadas densas são convertidos em probabilidades por meio da função SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; prev_count = descr.count = prev_count; descr.step = 1; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
É importante destacar que nossa modelo faz previsões de probabilidade apenas para dois sentidos do movimento de preços: alta e baixa. A probabilidade de movimento lateral (fletado) é propositalmente ignorada, pois até mesmo uma tendência lateral consiste, na prática, em uma sequência de oscilações curtas com amplitude semelhante e direções opostas. Essa abordagem permite que o modelo se concentre na identificação dos padrões dinâmicos fundamentais do mercado, sem desperdiçar recursos computacionais na descrição de estados laterais complexos e menos relevantes.
Com a descrição da arquitetura das modelos concluída, resta apenas retornar o resultado lógico da execução para o programa que chamou o método e encerrar sua execução.
Treinamento dos modelos
Agora que definimos a arquitetura das modelos, podemos passar à próxima etapa, nomeadamente o treinamento. Para isso, utilizaremos o conjunto de dados de treino montado durante o desenvolvimento do framework MacroHFT. O processo de montagem desse conjunto de dados de treino foi detalhado no artigo correspondente. Relembrando, esse conjunto foi gerado a partir de dados históricos do par de moedas EURUSD, ao longo de todo o ano de 2024, no timeframe M1.
No entanto, para realizar o treinamento das modelos, será necessário fazer alguns ajustes no algoritmo do EA localizado em "…\MQL5\Experts\ResNeXt\Study.mq5". Nesta seção, vamos nos concentrar exclusivamente no algoritmo do método Train, pois é justamente nesse método que todo o processo de treinamento é organizado.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
No início do método de treinamento, normalmente calculamos os vetores de probabilidade de escolha entre diferentes trajetórias, com base em sua rentabilidade. Isso permite corrigir o desequilíbrio entre episódios lucrativos e não lucrativos, já que, na maioria dos casos, a quantidade de sequências com prejuízo supera significativamente a de sequências com lucro. No entanto, neste trabalho, o treinamento das modelos será feito com trajetórias praticamente ideais, onde a sequência de ações do Agente é construída com base em dados históricos do movimento de preços. Por isso, o vetor de probabilidades é preenchido com valores iguais, garantindo uma representação uniforme de todo o conjunto de dados de treino. Essa abordagem permite que o modelo aprenda as características principais dos dados de mercado sem um viés artificial favorecendo certos cenários em detrimento de outros, o que favorece a capacidade de generalização e a robustez do modelo.
Em seguida, declaramos um conjunto de variáveis locais necessárias para armazenar temporariamente dados durante a execução das operações.
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
Com isso, finalizamos a etapa de preparação. Agora, criamos o sistema de ciclos de treinamento das modelos.
Vale ressaltar que a arquitetura ResNeXt por si só, não utiliza blocos recorrentes. Portanto, o ideal é que seu treinamento seja realizado dentro de um único ciclo com seleção aleatória de estados do conjunto de treino. No entanto, adicionamos o Agente de gerenciamento de risco, que utiliza módulos de memória sobre decisões tomadas e mudanças no estado da conta como resultado dessas decisões. O treinamento desse módulo exige que a sequência histórica dos dados brutos seja mantida.
No corpo do laço externo, fazemos o amostragem do estado inicial de um mini-batch da sequência histórica a partir do conjunto de treino.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; }
E limpamos a memória dos blocos recorrentes.
if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nesse ponto, preenchemos com zeros o vetor dos valores-alvo anteriores das ações do Agente e, em seguida, organizamos o laço aninhado que percorre os estados do mini-batch respeitando sua ordem histórica.
result = vector<float>::Zeros(NActions); for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
Dentro do laço aninhado, começamos transferindo a descrição do estado do ambiente da base de treino para o buffer correspondente. Em seguida, partimos para a formação do tensor de descrição do estado da conta. Aqui, preparamos as harmônicas do timestamp do estado do ambiente que está sendo analisado.
//--- bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Extraímos do buffer de replay de experiência os dados de saldo e patrimônio (equity).
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
E também calculamos o retorno da última operação-alvo que poderia ter sido executada no barra histórico anterior.
float profit = float(bState[0] / _Point * (result[0] - result[3]));
Na preparação do vetor de descrição do estado da conta, partimos do pressuposto de que no barra anterior todas as posições abertas foram encerradas e uma operação potencial da ação-alvo, definida na iteração anterior do laço de treinamento, foi executada. É fácil concluir que, na primeira iteração desse laço, o vetor de ações-alvo está preenchido com zeros (nenhuma operação foi realizada). Portanto, o coeficiente de variação do saldo é igual a "1", e os indicadores de patrimônio são gerados com base no lucro potencial do último barra, calculado anteriormente.
bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Assim, as informações sobre posições abertas também são formadas com base na operação de trade alvo.
Depois de preparar os dados brutos, realizamos a propagação para frente das modelos em treinamento. Primeiro, chamamos o método de propagação para frente do Agente, passando os dados de entrada que foram formados anteriormente.
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, chamamos o método equivalente do modelo preditivo de probabilidades do movimento futuro do preço. Aqui, utilizamos o estado latente do Agente como dados de entrada.
if(!Probability.feedForward(GetPointer(Actor), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
O próximo passo é formar os valores-alvo para o treinamento das modelos. Como mencionado anteriormente, planejamos treinar os modelos em condições de "trajetórias quase ideais". Portanto, os valores-alvo serão definidos "olhando para o futuro", com base nos dados da nossa base de treino. Para isso, extraímos da base de treino os dados históricos reais subsequentes do estado do ambiente, dentro de um horizonte de previsão definido, e os transferimos para uma matriz, onde cada barra será representada por uma linha separada.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
Vale destacar que os dados extraídos estão em ordem histórica reversa. Por isso, organizamos um laço para reordenar as linhas da matriz.
for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Agora que temos os dados sobre o movimento futuro dos preços, partimos para a formação do vetor da operação de trade alvo. Aqui, o algoritmo se ramifica conforme a operação anterior. Em outras palavras, a operação de trade anterior muda o objetivo do Agente nesta etapa. E isso é perfeitamente lógico. Com uma posição aberta, buscamos o ponto de saída; na ausência de posição, buscamos o ponto de entrada.
Se, na iteração anterior, nossa operação de trade alvo foi a abertura de uma posição comprada, verificamos se o nível de stop-loss será atingido num futuro próximo.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); }
Nesse processo, utilizamos o preço máximo até o momento em que o stop-loss seja atingido como valor-alvo para o take-profit.
Os valores obtidos são transferidos como parâmetros da operação de compra alvo, ao mesmo tempo em que os parâmetros da operação de venda são zerados.
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
Operações semelhantes são realizadas para a busca do ponto de saída de uma posição vendida.
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } }
Na ausência de posição aberta, realizamos a busca por um ponto de entrada. Para isso, determinamos a direção da tendência futura do movimento dos preços.
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax]/2 > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin]/2)) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
Em caso de tendência futura de alta, definimos os parâmetros da operação de compra. Os parâmetros da operação de trade são definidos da mesma forma que na busca do ponto de saída. O stop-loss, nesse caso, é fixado no nível do valor máximo.
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01, 0.011)); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
Da mesma forma, definimos os parâmetros da operação de venda no caso de uma tendência de queda no preço.
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01,0.011)); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } } } } }
Com o tensor de operação de trade alvo devidamente formado, podemos realizar as operações de propagação reversa do nosso Agente, com o objetivo de minimizar o desvio entre a decisão de trade gerada e a decisão alvo.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, precisamos formar os valores-alvo do modelo preditivo. Aqui, é bastante evidente que uma operação de compra está associada a uma tendência de alta, enquanto uma de venda, a uma tendência de baixa. Como as operações foram formadas com base na análise de dados históricos, temos 100% de certeza quanto à tendência futura. Portanto, o valor-alvo para a tendência correspondente é 1, e 0 para a oposta.
target = vector<float>::Zeros(NActions / 3); for(int a = 0; a < NActions; a += 3) target[a / 3] = float(result[a] > 0);
Agora podemos realizar as operações de propagação reversa também para o modelo preditivo. Durante esse processo, ajustamos os parâmetros do codificador do estado do ambiente, o que está alinhado com as práticas de aprendizado multitarefa.
if(!Result.AssignArray(target) || !Probability.backProp(Result, GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Resta apenas informar o usuário sobre o andamento do processo de treinamento e passar para a próxima iteração dos ciclos do sistema.x
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a execução bem-sucedida da quantidade definida de iterações de treinamento, limpamos o campo de comentários do gráfico, onde eram exibidas as mensagens informativas sobre o progresso do treinamento dos modelos.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
Os resultados do treinamento são exibidos no diário do terminal, e iniciamos o processo de encerramento da execução do programa de treinamento. O código completo do programa de treinamento dos modelos pode ser consultado no material anexado ao artigo.
Na próxima etapa, passamos diretamente ao processo de treinamento dos modelos. Para isso, abrimos o terminal MetaTrader 5 e executamos o EA criado anteriormente no modo de tempo real. O EA que criamos não realiza operações de trading, portanto sua execução não apresenta riscos para o saldo da conta.
Vale destacar que estamos realizando o treinamento simultâneo de ambos os modelos. Mas há um detalhe importante no funcionamento do Agente. Como mencionado anteriormente, à arquitetura dessa modelo foi adicionado um bloco de gerenciamento de risco, que utiliza módulos de memória sobre o estado da conta e as decisões tomadas. Nesse processo, o módulo de memória das ações anteriores armazena informações provenientes da representação latente do Agente.
No entanto, ao observar o código de treinamento das modelos apresentado acima, nota-se que o vetor de descrição do estado da conta está sendo formado com base nos valores-alvo. Isso cria um descompasso, isto é, o bloco de gerenciamento de risco avalia a variação do saldo segundo uma política de comportamento completamente diferente. Para minimizar esse efeito, foi tomada a decisão de realizar o treinamento em 2 etapas.
Na primeira etapa do treinamento, definimos o tamanho do mini-batch como igual a um único estado.
Essa configuração permite, na prática, desativar os módulos de memória durante a fase inicial de treinamento. Embora esse não seja o modo operacional ideal do nosso modelo, ele nos permite aproximar ao máximo a política de comportamento do Agente da política alvo, minimizando o desvio entre as operações de trade previstas e as operações de trade alvo.
Na segunda etapa do treinamento, aumentamos o tamanho do mini-batch, definindo-o como um valor pelo menos um pouco maior que a capacidade dos módulos de memória. Isso possibilita um ajuste mais fino do funcionamento do modelo, incluindo o gerenciamento de risco com controle sobre o impacto da política utilizada nos estados da conta.
Testes das modelos
Após o treinamento das modelos, passamos à etapa de teste da política de comportamento do Agente obtida. E aqui vale destacar algumas alterações feitas no algoritmo do programa de teste. As modificações foram pontuais. Por isso, não analisaremos o código completo, que está disponível para consulta no material anexo. O ponto principal é que adicionamos ao algoritmo a nossa modelo de previsão de probabilidades do movimento futuro. E a operação de trade só será realizada caso haja coincidência entre a direção da operação prevista pelo Agente e a tendência considerada mais provável.
O teste da política treinada foi realizado no testador de estratégias do MetaTrader 5, utilizando dados históricos de janeiro de 2025, mantendo todos os demais parâmetros da coleta da base de treino. É fácil notar que o período de teste não faz parte da base de treino. Isso permite que as condições de teste se aproximem ao máximo de um ambiente real operando com dados desconhecidos.
Os resultados dos testes são apresentados a seguir.
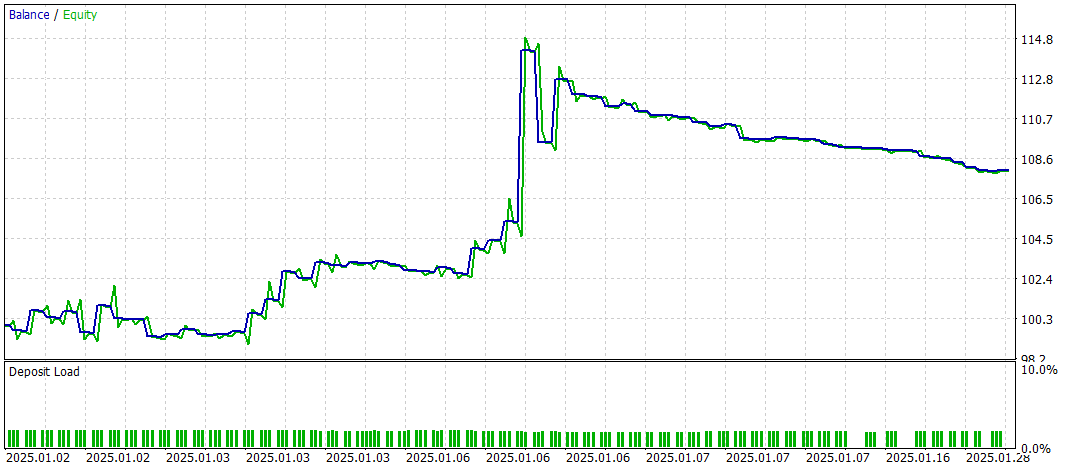
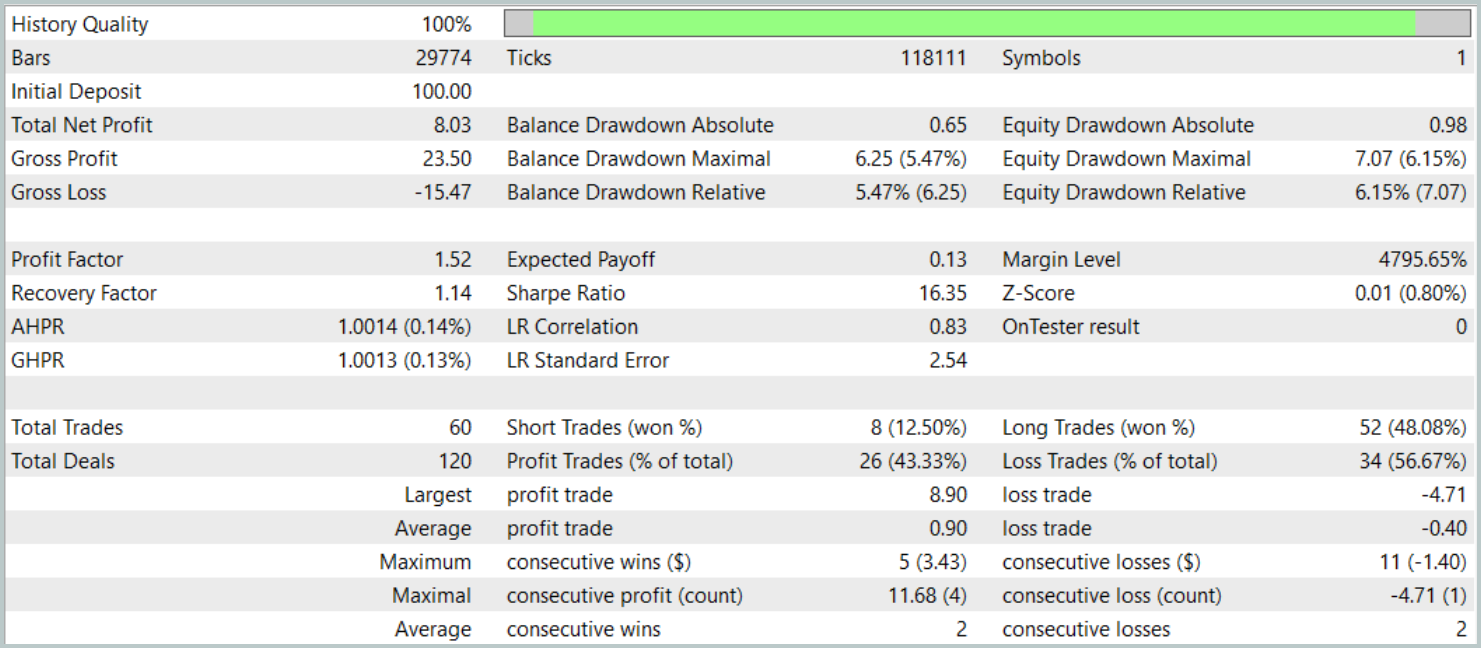
Durante o período de testes, a modelo realizou 60 operações de trade, o que corresponde, em média, a cerca de 3 operações por dia útil. Mais de 43% das posições abertas foram encerradas com lucro. Graças ao fato de que o lucro médio e o lucro máximo por operação foram quase o dobro dos valores correspondentes das operações com prejuízo, o teste foi concluído com um resultado financeiro positivo. O profit factor ficou em 1.52 e o fator de recuperação alcançou 1.14.
Considerações finais
O framework de aprendizado multitarefa baseado na arquitetura ResNeXt, apresentado neste artigo, abre novas possibilidades para a análise dos mercados financeiros. Com o uso de um codificador comum e de "cabeças" especializadas, o modelo é capaz de identificar com eficiência padrões estáveis nos dados, se adaptar às condições de mercado em constante mudança e gerar previsões mais precisas. A aplicação do aprendizado multitarefa permite minimizar o risco de overfitting, já que o modelo é treinado em múltiplas tarefas simultaneamente, o que contribui para a formação de representações mais generalizadas do mercado.
Além disso, a alta modularidade da arquitetura ResNeXt permite ajustar os parâmetros do modelo de acordo com as condições específicas de operação, o que a torna uma ferramenta versátil para o trading algorítmico.
A implementação apresentada, baseada em nossa própria interpretação das abordagens propostas e realizada por meio do MQL5, demonstrou eficácia na análise de séries temporais e na previsão de tendências de mercado. A inclusão de um bloco adicional para previsão de tendências de mercado reforçou significativamente a capacidade analítica do modelo, tornando-o mais resistente a mudanças inesperadas nos preços.
De forma geral, o sistema proposto demonstra grande potencial de aplicação no trading automatizado e na análise algorítmica de dados financeiros. No entanto, antes de utilizar o modelo em condições reais de mercado, é necessário treiná-lo com um conjunto de dados mais representativo, seguido de uma bateria completa de testes.
Referências
- Aggregated Residual Transformations for Deep Neural Networks
- Collaborative Optimization in Financial Data Mining Through Deep Learning and ResNeXt
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos usando o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento dos modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para programa em OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17157
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso