关于交易中机器学习的文章
创建基于AI的交易机器人:与Python的原生集成,矩阵和向量,数学和统计库等。
了解如何在交易中使用机器学习。神经元、感知器、卷积和循环网络、预测模型 — 从基础开始,逐步开发您自己的AI。您将学习如何为金融市场的算法交易训练和应用神经网络。

重构经典策略:原油
在本文中,我们重新审视一种经典的原油交易策略,旨在通过利用监督机器学习算法来对其进行优化。我们将构建一个最小二乘模型,该模型基于布伦特原油(Brent)和西德克萨斯中质原油(WTI)之间的价差来预测未来布伦特原油价格。我们的目标是找到一个能够预测布伦特原油未来价格变化的领先指标。


神经网络变得轻松(第三十七部分):分散关注度
在上一篇文章中,我们讨论了在其架构中使用关注度机制的关系模型。 这些模型的具体特征之一是计算资源的密集功用。 在本文中,我们将研究于自我关注度模块内减少计算操作数量的机制之一。 这将提高模型的常规性能。
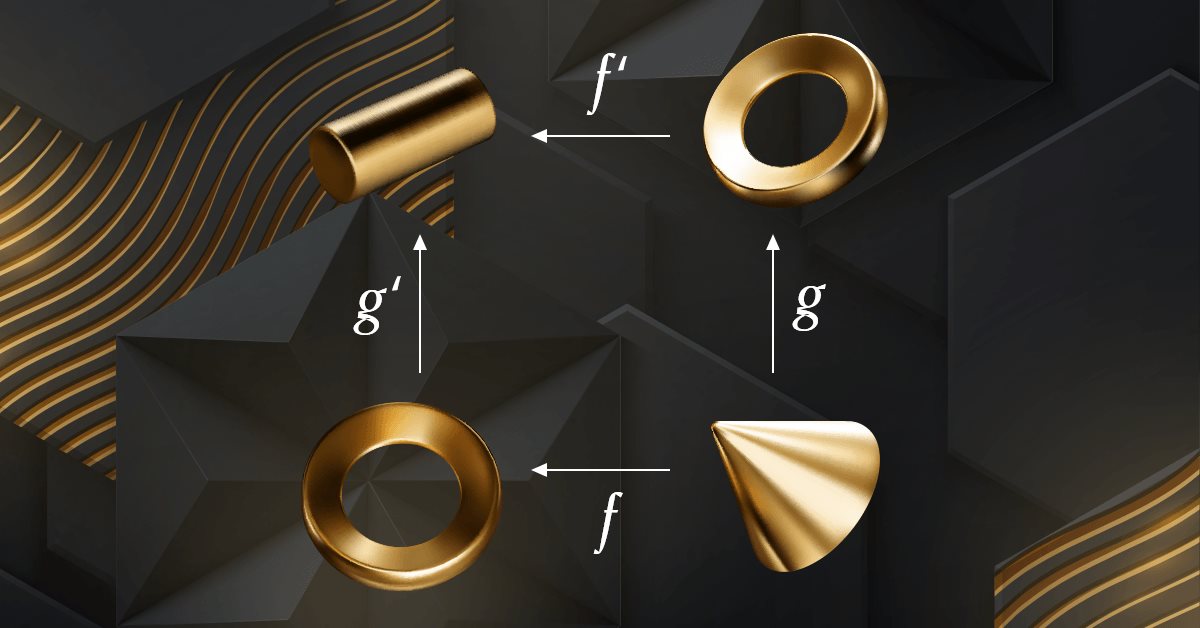
MQL5 中的范畴论 (第 6 部分):单态回拉和满态外推
范畴论是数学的一个多样化和不断扩展的分支,直到最近才在 MQL5 社区中得到一些报道。 这些系列文章旨在探索和验证一些概念和公理,其总体目标是建立一个开放的函数库,提供洞察力,同时也希望进一步在交易者的策略开发中运用这个非凡的领域。

神经网络变得简单(第 89 部分):频率增强分解变换器(FEDformer)
到目前为止,我们研究过的所有模型在分析环境状态时都将其当作时间序列。不过,时间序列也能以频率特征的形式表示。在本文中,我将向您介绍一种算法,即利用时间序列的频率分量来预测未来状态。




彗星尾算法(CTA)
在这篇文章中,我们将探讨彗星尾优化算法(CTA),该算法从独特的太空物体——彗星及其接近太阳时形成的壮观尾部中汲取灵感。该算法基于彗星及其尾部运动的概念设计而成,旨在寻找优化问题中的最优解。

神经网络变得简单(第 66 部分):离线学习中的探索问题
使用准备好的训练数据集中的数据对模型进行离线训练,这种方法虽然有一定的优势,但其不利的一面是,环境信息被大大压缩到训练数据集的大小。这反过来又限制了探索的可能性。在本文中,我们将探讨一种方法,这种方法可以用尽可能多样化的数据来填充训练数据集。

重构经典策略(第九部分):多时间框架分析(第二部分)
在今天的讨论中,我们探讨了多时间框架分析的策略,以确定我们的人工智能(AI)模型在哪个时间框架上表现最优。分析结果表明,在欧元兑美元(EURUSD)货币对上,月度和小时时间框架生成的模型具有相对较低的误差率。我们利用这一优势,开发了一个交易算法,该算法在月度时间框架上进行人工智能预测,并在小时时间框架上执行交易。

MQL5 中的范畴论 (第 2 部分)
范畴论是数学的一个多样化和不断扩展的分支,到目前为止,在 MQL5 社区中还相对难以发现。 这些系列文章旨在介绍和研究其一些概念,其总体目标是建立一个开放的函数库,吸引评论和研讨,同时希望在交易者的策略开发中进一步在运用这一非凡的领域。

矩阵实用工具,扩展矩阵和向量的标准库功能
矩阵作为机器学习算法和计算机的基础,因为它们能够有效地处理大型数学运算,标准库拥有所需的一切,但让我们看看如何在实用工具文件中引入若干个函数来扩展它,这些函数在标准库中尚未提供。

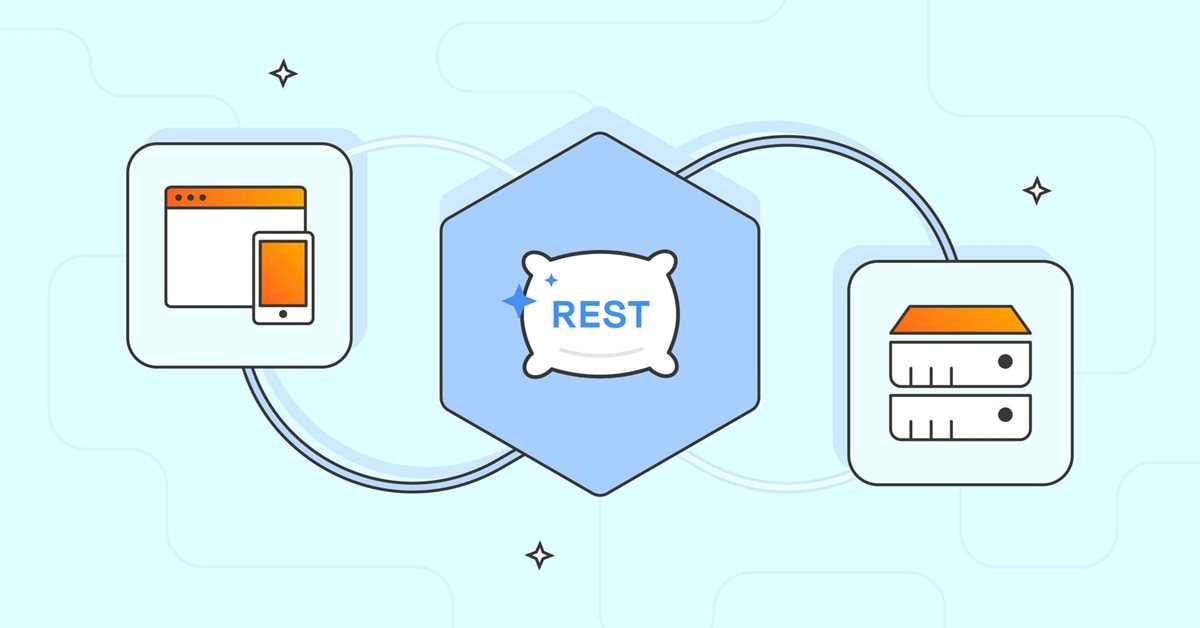
开发具有 RestAPI 集成的 MQL5 强化学习代理(第 1 部分):如何在 MQL5 中使用 RestAPI
在本文中,我们将讨论 API(Application Programming Interface,应用程序编程接口)对于不同应用程序和软件系统之间交互的重要性。我们将看到 API 在简化应用程序间交互方面的作用,使它们能够有效地共享数据和功能。

神经网络变得轻松(第五十二部分):研究乐观情绪和分布校正
由于模型是基于经验复现缓冲区进行训练,故当前的扮演者政策会越来越远离存储的样本,这会降低整个模型的训练效率。在本文中,我们将查看一些能在强化学习算法中提升样本使用效率的算法。

衡量指标信息
机器学习已成为策略制定的流行方法。 虽然人们更强调最大化盈利能力和预测准确性,但处理用于构建预测模型的数据的重要性,仍未受到太多关注。 在本文中,我们研究依据熵的概念来评估预测模型构建的指标的适配性,如 Timothy Masters 的《测试和优调市场交易系统》一书中所述。

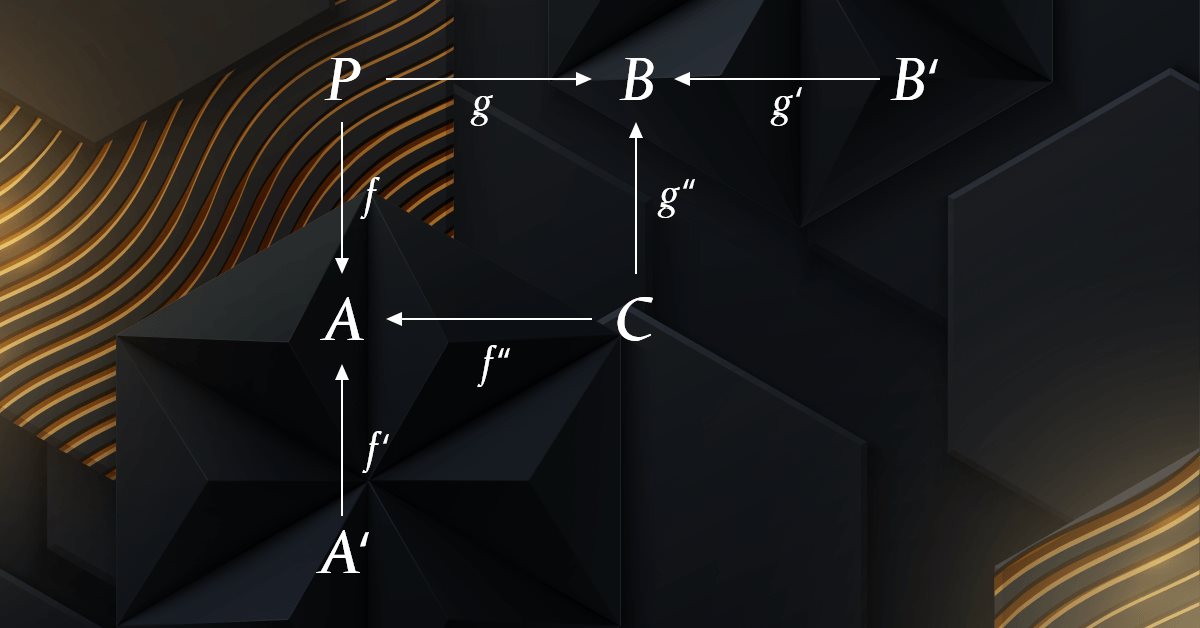
MQL5 中的范畴论 (第 4 部分):跨度、实验、及合成
范畴论是数学的一个多样化和不断扩展的分支,到目前为止,在 MQL5 社区中还相对难以发现。 这些系列文章旨在介绍和研究其一些概念,其总体目标是建立一个开放的函数库,提供洞察力,同时希望在交易者的策略开发中进一步运用这一非凡的领域。
MQL5 中的范畴论 (第 5 部分):均衡器
范畴论是数学的一个多样化和不断扩展的分支,直到最近才在 MQL5 社区中得到一些报道。 这些系列文章旨在探索和验证一些概念和公理,其总体目标是建立一个开放的函数库,提供洞察力,同时也希望进一步在交易者的策略开发中运用这个非凡的领域。

Python、ONNX 和 MetaTrader 5:利用 RobustScaler 和 PolynomialFeatures 数据预处理创建 RandomForest 模型
在本文中,我们将用 Python 创建一个随机森林(random forest)模型,训练该模型,并将其保存为带有数据预处理功能的 ONNX 管道。之后,我们将在 MetaTrader 5 终端中使用该模型。


重塑经典策略(第四部分):标普500指数与美国国债
在本系列文章中,我们使用现代算法分析经典交易策略,以确定是否可以利用人工智能改进这些策略。在今天的文章中,我们将重新审视一种利用标普500指数与美国国债之间关系的经典交易方法。

MQL5 中的范畴论 (第 2 部分)
范畴论是数学的一个多样化和不断扩展的分支,到目前为止,在 MQL5 社区中还相对难以发现。 这些系列文章旨在介绍和研究其一些概念,其总体目标是建立一个开放的函数库,提供洞察力,同时希望在交易者的策略开发中进一步运用这一非凡的领域。

神经网络变得轻松(第五十四部分):利用随机编码器(RE3)进行高效研究
无论何时我们研究强化学习方法时,我们都会面对有效探索环境的问题。解决这个问题通常会导致算法更复杂性,以及训练额外模型。在本文中,我们将看看解决此问题的替代方法。

使用PatchTST机器学习算法预测未来24小时的价格走势
在本文中,我们将应用2023年发布的一种相对复杂的神经网络算法——PatchTST,来预测未来24小时的价格走势。我们将使用官方仓库的代码,并对其进行一些微小的修改,训练一个针对EURUSD(欧元兑美元)的模型,然后在Python和MQL5环境中应用该模型进行未来预测。

利用 Python 实现价格走势离散方法
我们将考察使用 Python + MQL5 来离散价格的方法。在本文中,我将分享我开发 Python 函数库的实践经验,其以多种方式实现柱线形成 — 从经典的交易量和范围柱线,到更奇特的方法,如 Renko 和 Kagi。我们将研究三线突破蜡烛和范围柱线,分析它们的统计数据,并尝试定义如何将价格以离散化表示。

神经网络变得轻松(第二十八部分):政策梯度算法
我们继续研究强化学习方法。 在上一篇文章中,我们领略了深度 Q-学习方法。 按这种方法,已训练模型依据在特定情况下采取的行动来预测即将到来的奖励。 然后,根据政策和预期奖励执行动作。 但并不总是能够近似 Q-函数。 有时它的近似不会产生预期的结果。 在这种情况下,近似方法不应用于功用函数,而是应用于动作的直接政策(策略)。 其中一种方法是政策梯度。

数据科学与机器学习(第24部分):使用常规AI模型进行外汇时间序列预测
在外汇市场中,如果不了解过去的情况,就很难预测未来的趋势。很少有机器学习模型能够通过考虑过去的数据来做出未来预测。在本文中,我们将讨论如何使用经典(非时间序列)人工智能模型来战胜市场。
群体优化算法:螺旋动态优化 (SDO) 算法
文章介绍了一种基于自然界螺旋轨迹构造模式(如软体动物贝壳)的优化算法 - 螺旋动力学优化算法(Spiral Dynamics Optimization,SDO)。我对作者提出的算法进行了彻底的修改和完善,本文将探讨这些修改的必要性。

群体优化算法:混合蛙跳算法(SFL)
本文详细描述了混合蛙跳(Shuffled Frog-Leaping,SFL)算法及其在求解优化问题中的能力。SFL算法的灵感来源于青蛙在自然环境中的行为,为函数优化提供了一种新的方法。SFL算法是一种高效灵活的工具,能够处理各种数据类型并实现最佳解决方案。

使用PSAR、Heiken Ashi和深度学习进行交易
本项目探索深度学习与技术分析的融合,用于在外汇市场测试交易策略。使用Python脚本进行快速实验,结合ONNX模型和传统指标(如PSAR、SMA和RSI)来预测欧元/美元(EUR/USD )的走势。之后,MQL5脚本将此策略引入实时环境,利用历史数据和技术分析帮助交易者做出明智的交易决策。回测结果表明,该策略秉持保守且稳健的运作理念,始终将风险管控置于首位,追求持续稳定的收益增长模式,摒弃激进逐利的行为。

神经网络变得简单(第 62 部分):在层次化模型中运用决策转换器
在最近的文章中,我们已看到了运用决策转换器方法的若干选项。该方法不仅可以分析当前状态,还可以分析先前状态的轨迹,以及在其中执行的动作。在本文中,我们将专注于在层次化模型中运用该方法。

数据科学和机器学习(第 16 部分):全新面貌的决策树
在我们的数据科学和机器学习系列的最新一期中,深入到错综复杂的决策树世界。本文专为寻求策略洞察的交易者量身定制,全面回顾了决策树在分析市场趋势中所发挥的强大作用。探索这些算法树的根和分支,解锁它们的潜力,从而强化您的交易决策。加入我们,以全新的视角审视决策树,并探索它们如何在复杂的金融市场航行中成为您的盟友。



种群优化算法:模拟各向同性退火(SIA)算法。第 II 部分
第一部分专注于众所周知、且流行的算法 — 模拟退火。我们已经通盘研究了它的利弊。本文的第二部分专注于算法的彻底变换,将其转变为一种新的优化算法 — 模拟各向同性退火(SIA)。