关于交易中机器学习的文章
创建基于AI的交易机器人:与Python的原生集成,矩阵和向量,数学和统计库等。
了解如何在交易中使用机器学习。神经元、感知器、卷积和循环网络、预测模型 — 从基础开始,逐步开发您自己的AI。您将学习如何为金融市场的算法交易训练和应用神经网络。

开发交易机器人:Python与MQL5结合(第二部分):模型选择、创建与训练,以及Python自定义测试器
我们继续关于使用Python和MQL5开发交易机器人的系列文章。今天我们将解决模型选择、训练、测试、交叉验证、网格搜索以及模型集成的问题。


神经网络变得轻松(第四十四部分):动态学习技能
在上一篇文章中,我们讲解了 DIAYN 方法,它提供了学习各种技能的算法。 获得的技能可用在各种任务。 但这些技能可能非常难以预测,而这可能令它们难以运用。 在本文中,我们要研究一种针对学习可预测技能的算法。


神经网络变得轻松(第十九部分):使用 MQL5 的关联规则
我们继续研究关联规则。 在前一篇文章中,我们讨论了这种类型问题的理论层面。 在本文中,我将展示利用 MQL5 实现 FP-Growth 方法。 我们还将采用真实数据测试所实现的解决方案。


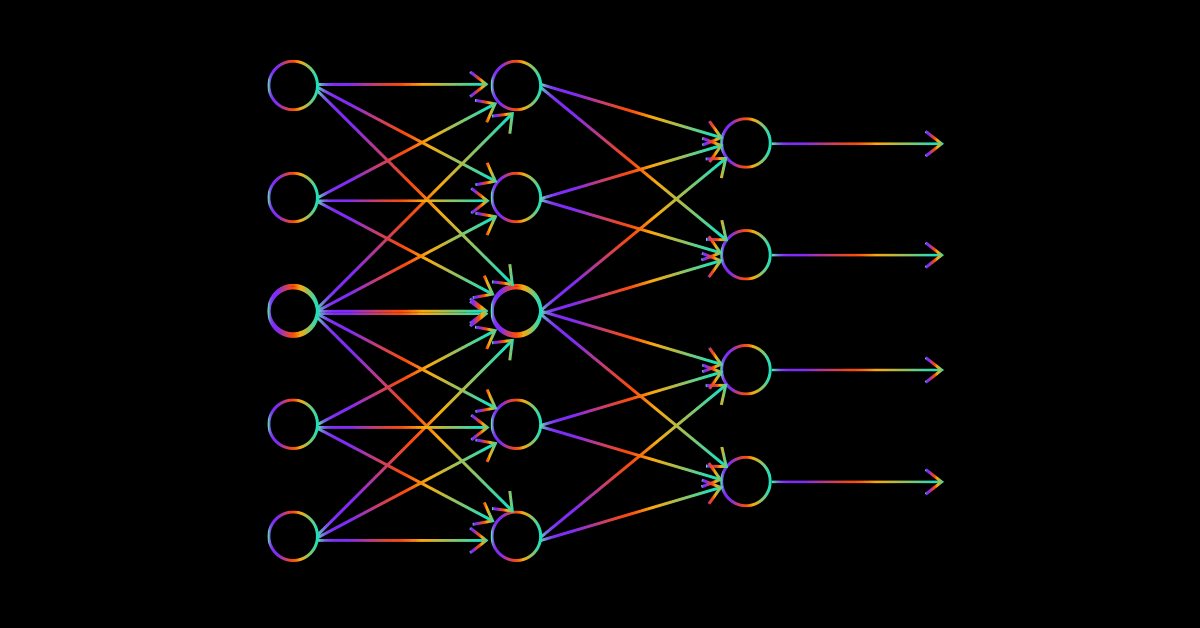
数据科学与机器学习 — 神经网络(第 02 部分):前馈神经网络架构设计
在我们透彻之前,还有一些涵盖前馈神经网络的次要事情,设计就是其中之一。 针对我们的输入,看看我们如何构建和设计一个灵活的神经网络、隐藏层的数量、以及每个网络的节点。

神经网络变得轻松(第三十六部分):关系强化学习
在上一篇文章中讨论的强化学习模型中,我们用到了卷积网络的各种变体,这些变体能够识别原始数据中的各种对象。 卷积网络的主要优点是能够识别对象,无关它们的位置。 与此同时,当物体存在各种变形和噪声时,卷积网络并不能始终表现良好。 这些是关系模型可以解决的问题。

MQL5 简介(第 2 部分):浏览预定义变量、通用函数和控制流语句
通过我们的 MQL5 系列第二部分,开启一段启迪心灵的旅程。这些文章不仅是教程,还是通往魔法世界的大门,在那里,编程新手和魔法师将团结在一起。是什么让这段旅程变得如此神奇?我们的 MQL5 系列第二部分以令人耳目一新的简洁性脱颖而出,使复杂的概念变得通俗易懂。与我们互动,我们会回答您的问题,确保您获得丰富和个性化的学习体验。让我们建立一个社区,让理解 MQL5 成为每个人的冒险。欢迎来到魔法世界!

数据科学和机器学习(第 04 部分):预测当前股市崩盘
在本文中,我将尝试运用我们的逻辑模型,基于美国经济的基本面,来预测股市崩盘,我们将重点关注 NETFLIX 和苹果。利用 2019 年和 2020 年之前的股市崩盘,我们看看我们的模型在当前的厄运和低迷中会表现如何。

数据科学和机器学习(第 27 部分):MetaTrader 5 中训练卷积神经网络(CNN)交易机器人 — 值得吗?
卷积神经网络(CNN)以其在检测图像和视频形态方面的出色能力而闻名,其应用涵盖众多领域。在本文中,我们探讨了 CNN 在金融市场中识别有价值形态,并为 MetaTrader 5 交易机器人生成有效交易信号的潜力。我们来发现这种深度机器学习技术如何能撬动更聪明的交易决策。

神经网络实验(第 3 部分):实际应用
在本系列文章中,我会采用实验和非标准方法来开发一个可盈利的交易系统,并检查神经网络是否对交易者有任何帮助。 若在交易中运用神经网络,MetaTrader 5 则可作为近乎自给自足的工具。

使用 Python 的深度学习 GRU 模型到使用 EA 的 ONNX,以及 GRU 与 LSTM 模型的比较
我们将指导您完成使用 Python 进行 DL 制作 GRU ONNX 模型的整个过程,最终创建一个用于交易的专家顾问 (EA),然后将 GRU 模型与 LSTM 模型进行比较。

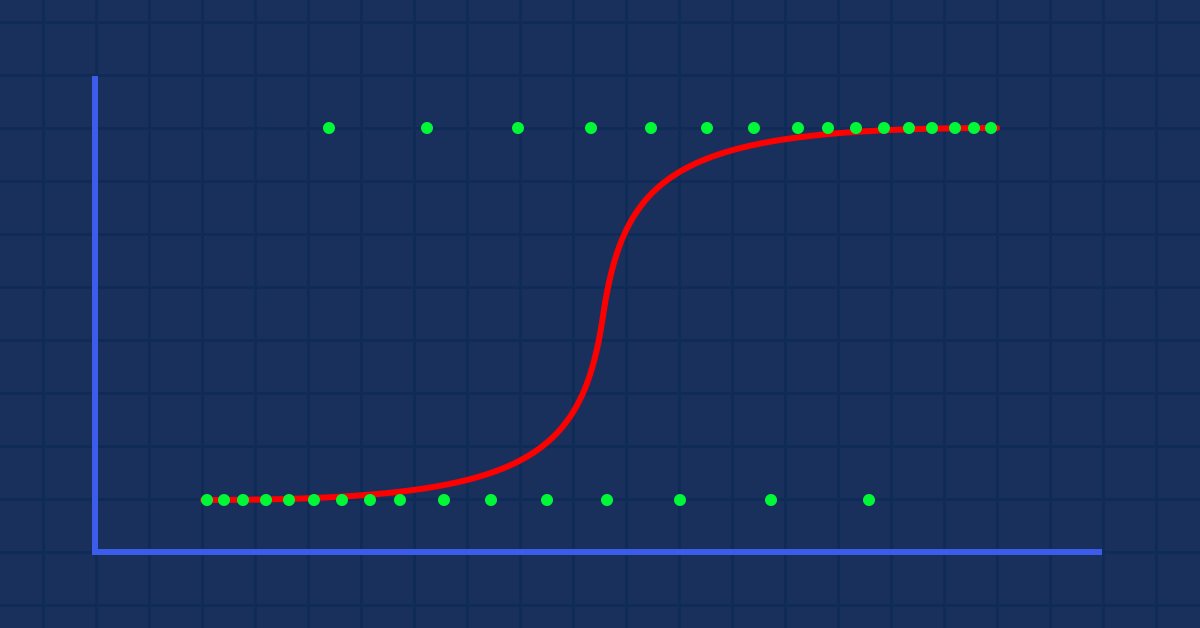
数据科学与机器学习(第 02 部分):逻辑回归
数据分类对于算法交易者和程序员来说是至关重要的。 在本文中,我们将重点关注一种分类逻辑算法,它有帮于我们识别“确定或否定”、“上行或下行”、“做多或做空”。
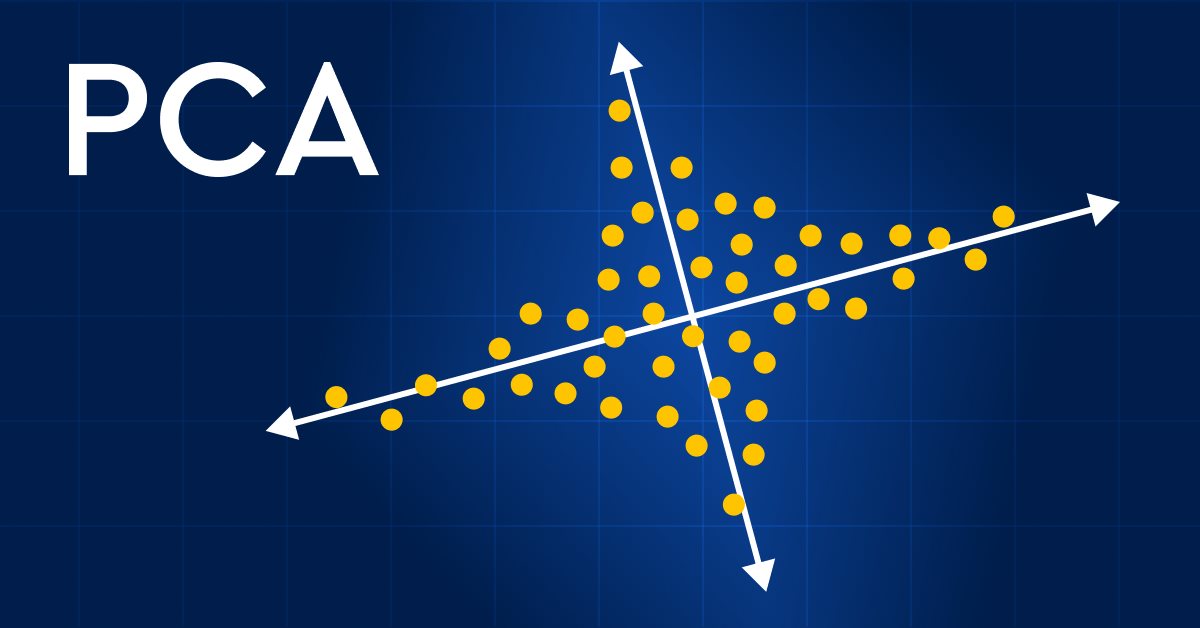
数据科学和机器学习(第 13 部分):配合主成分分析(PCA)改善您的金融市场分析
运用主成分分析(PCA)彻底革新您的金融市场分析! 发现这种强大的技术如何解锁数据中隐藏的形态,揭示潜在的市场趋势,并优化您的投资策略。 在本文中,我们将探讨 PCA 如何为分析复杂的金融数据提供新的视角,揭示传统方法会错过的见解。 发掘 PCA 应用于金融市场数据如何为您带来竞争优势,并帮助您保持领先地位。

掌握ONNX:MQL5交易者的游戏规则改变者
深入ONNX的世界,这是一种用于交换机器学习模型的强大的开放标准格式。了解利用ONNX如何彻底改变MQL5中的算法交易,使交易员能够无缝集成尖端的人工智能模型,并将其策略提升到新的高度。揭开跨平台兼容性的秘密,学习如何在您的MQL5交易活动中释放ONNX的全部潜力。通过这篇掌握ONNX的全面指南提升您的交易游戏

神经网络变得轻松(第四十三部分):无需奖励函数精通技能
强化学习的问题在于需要定义奖励函数。 它可能很复杂,或难以形式化。 为了定解这个问题,我们正在探索一些基于行动和基于环境的方式,无需明确的奖励函数即可学习技能。
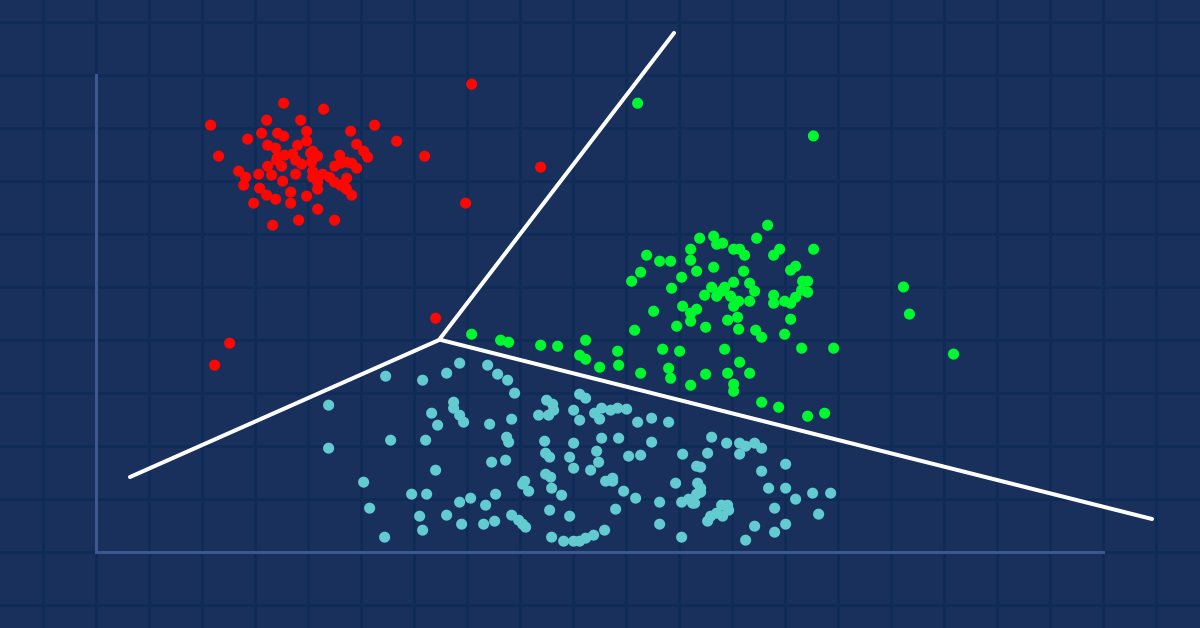
数据科学与机器学习(第 09 部分):以 MQL5 平铺直叙 K-均值聚类
数据挖掘在数据科学家和交易者看来至关重要,因为很多时候,数据并非如我们想象的那么简单。 人类的肉眼无法理解数据集中的不显眼底层形态和关系,也许 K-means 算法可以帮助我们解决这个问题。 我们来发掘一下...

利用 Python 和 MQL5 构建您的第一个玻璃盒模型
如果我们想从机器学习这些先进技术中获得任何价值,那么很难解释和理解为什么我们的模型偏离我们的期望至关重要。如果对模型内部工作原理的没有全面了解,我们可能无法发现破坏模型性能的错误,我们可能会在无法预测的参照特征上浪费时间,从长远来看,我们有可能没有充分利用这些模型的功能。幸运的是,有一个复杂且维护良好的多合一解决方案,令我们能够准确地看到我们的模型在引擎盖下正在做什么。

将您自己的LLM集成到EA中(第2部分):环境部署示例
随着人工智能的快速发展,语言模型(LLMs)是人工智能的重要组成部分,因此我们应该思考如何将强大的语言模型集成到我们的算法交易中。对大多数人来说,很难根据他们的需求对这些强大的模型进行微调,在本地部署,然后将其应用于算法交易。本系列文章将采取循序渐进的方法来实现这一目标。

神经网络变得轻松(第十五部分):利用 MQL5 进行数据聚类
我们继续研究聚类方法。 在本文中,我们将创建一个新的 CKmeans 类来实现最常见的聚类方法之一:k-均值。 在测试期间,该模型成功地识别了大约 500 种形态。

Scikit-Learn 库中的分类模型及其导出到 ONNX
在本文中,我们将探讨使用 Scikit-Learn 库中所有可用的分类模型来解决 Fisher 鸢尾花数据集的分类任务。我们将尝试把这些模型转换为 ONNX 格式,并在 MQL5 程序中使用生成的模型。此外,我们将在完整的鸢尾花数据集上比较原始模型与其 ONNX 版本的准确性。
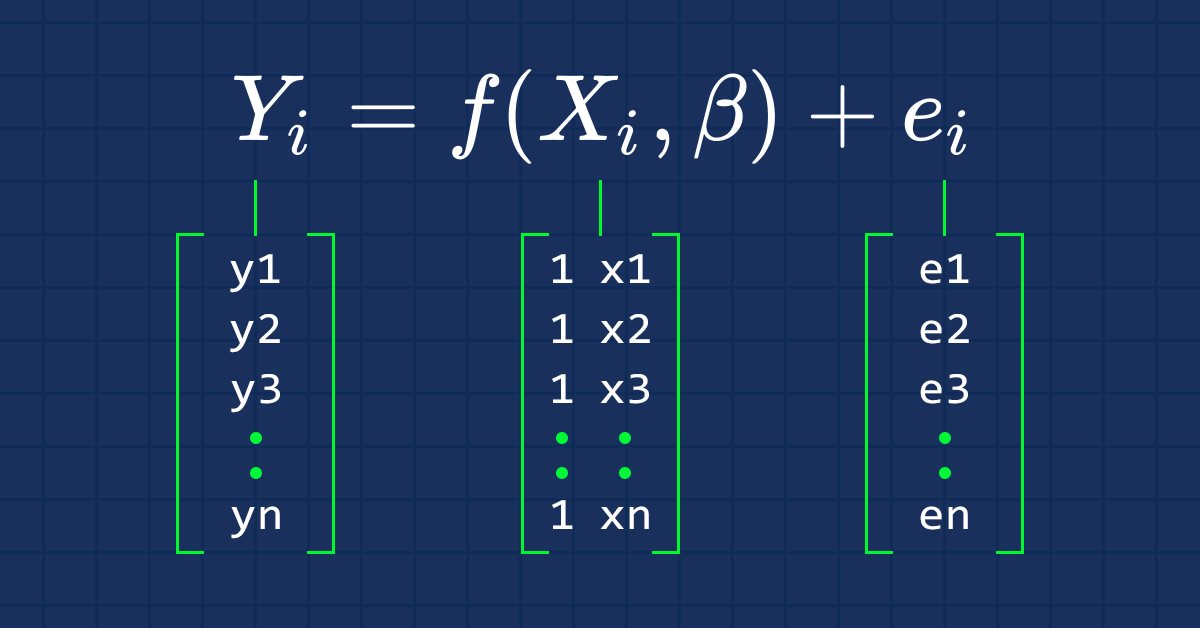
数据科学与机器学习(第 03 部分):矩阵回归
这一次,我们的模型是由矩阵构建的,它更具灵活性,同时它允许我们构建更强大的模型,不仅可以处理五个独立变量,但凡我们保持在计算机的计算极限之内,它还可以处理更多变量,这篇文章肯定会是一篇阅读起来很有趣的文章。


时间序列挖掘的数据标签(第1部分):通过EA操作图制作具有趋势标记的数据集
本系列文章介绍了几种时间序列标记方法,这些方法可以创建符合大多数人工智能模型的数据,而根据需要进行有针对性的数据标记可以使训练后的人工智能模型更符合预期设计,提高我们模型的准确性,甚至帮助模型实现质的飞跃!


将您自己的LLM集成到EA中(第1部分):硬件和环境部署
随着人工智能的快速发展,大型语言模型(LLM)成为人工智能的重要组成部分,因此我们应该思考如何将强大的语言模型集成到我们的算法交易中。对大多数人来说,很难根据他们的需求对这些强大的模型进行微调,在本地部署,然后将其应用于算法交易。本系列文章将采取循序渐进的方法来实现这一目标。

神经网络变得轻松(第三十九部分):Go-Explore,一种不同的探索方式
我们继续在强化学习模型中研究环境。 在本文中,我们将见识到另一种算法 — Go-Explore,它允许您在模型训练阶段有效地探索环境。

MQL5 中的矩阵和向量:激活函数
在此,我们将只讲述机器学习的一个方面 — 激活函数。 在人工神经网络中,神经元激活函数会根据一个或一组输入信号的数值,计算输出信号值。 我们将深入研究该过程的内部运作。
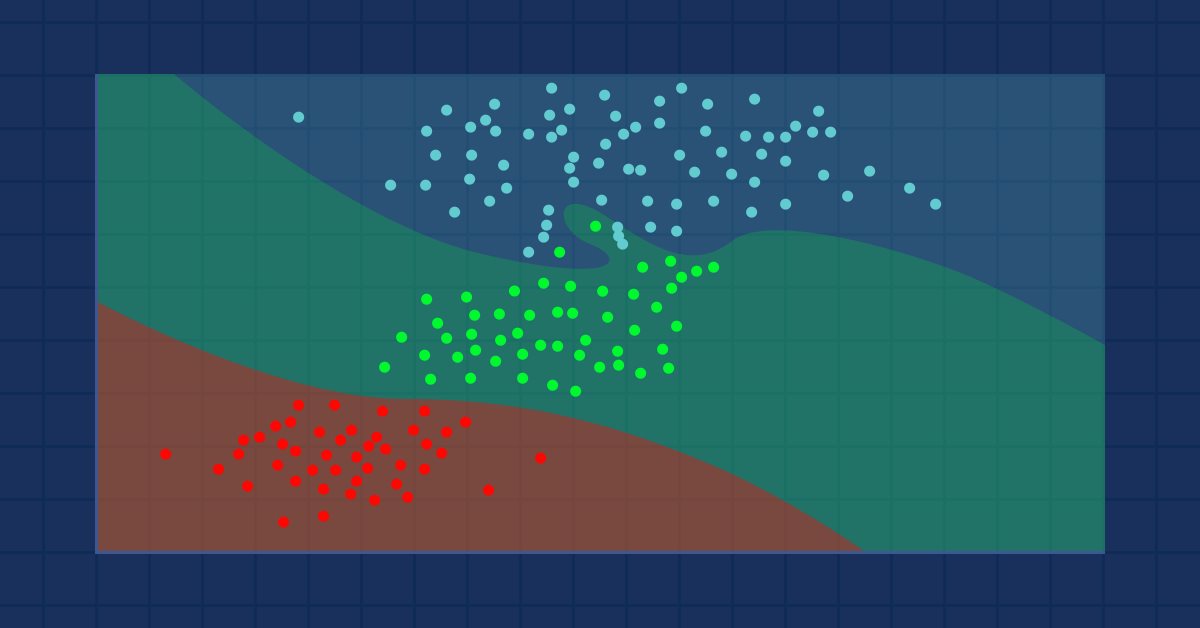
数据科学与机器学习(第 09 部分):K-最近邻算法(KNN)
这是一种惰性算法,它不是基于训练数据集学习,而是以存储数据集替代,并在给定新样本时立即采取行动。 尽管它很简单,但它能用于各种实际应用。


神经网络变得轻松(第十八部分):关联规则
作为本系列文章的延续,我们来研究无监督学习方法中的另一类问题:挖掘关联规则。 这种问题类型首先用于零售业,即超市等,来分析市场篮子。 在本文中,我们将讨论这些算法在交易中的适用性。

神经网络变得轻松(第二十九部分):优势扮演者-评价者算法
在本系列的前几篇文章中,我们见识到两种增强的学习算法。 它们中的每一个都有自己的优点和缺点。 正如在这种情况下经常发生的那样,接下来的思路是将这两种方法合并到一个算法,使用两者间的最佳者。 这将弥补它们每种的短处。 本文将讨论其中一种方法。

数据科学和机器学习(第 18 部分):掌握市场复杂性博弈,截断型 SVD 对比 NMF
截断型奇异值分解(SVD)和非负矩阵分解(NMF)都是降维技术。它们在制定数据驱动的交易策略方面都发挥着重要作用。探索降维的艺术,揭示洞察和优化定量分析,以明智的方式航行在错综复杂的金融市场。
数据科学与机器学习(第 07 部分):多项式回归
与线性回归不同,多项式回归是一种很灵活的模型,旨在更好地执行线性回归模型无法处理的任务,我们来找出如何在 MQL5 中制作多项式模型,并据其做出积极东西。

混沌博弈优化(CGO)
本文提出了一种新型元启发式算法——混沌博弈优化算法(CGO),该算法在处理高维问题时展现出独特的保持高效率的能力。与大多数优化算法不同,CGO在问题规模扩大时不仅不会降低性能,有时甚至还会提升性能,这便是其关键特性。

时间序列挖掘的数据标签(第2部分):使用Python制作带有趋势标记的数据集
本系列文章介绍了几种时间序列标记方法,这些方法可以创建符合大多数人工智能模型的数据,而根据需要进行有针对性的数据标记可以使训练后的人工智能模型更符合预期设计,提高我们模型的准确性,甚至帮助模型实现质的飞跃!