
交易中的神经网络:状态空间模型

概述
最段时间,大型模型适配新任务的范式变得越来越普遍。这些模型依据广泛的数据集进行预训练,其中包含来自各种领域的任意原生数据,包括文本、图像、音频、时间序列、以及更多。
尽管该概念与任何特定架构选择无关,但大多数模型都基于单一架构 – 变换器及其核心层自注意力。自注意力的效率归因于它有能力在情境窗口内密集引导信息,从而针对复杂数据建模。然而,该属性有本质上的局限性:无法针对超出有限窗口的任何东西建模,以及相对于窗口长度的二次缩放。
对于序列建模任务,另一种替代方案涉及在状态空间中使用结构化序列模型(空间序列建模,SSM)。这些模型可解释为递归神经网络(RNN)与卷积神经网络(CNN)的组合。这类模型可以遵照序列长度的线性或近线性缩放极其有效地计算。甚至,它还具有固有机制,即针对特定数据模态中的长期依赖关系进行建模。
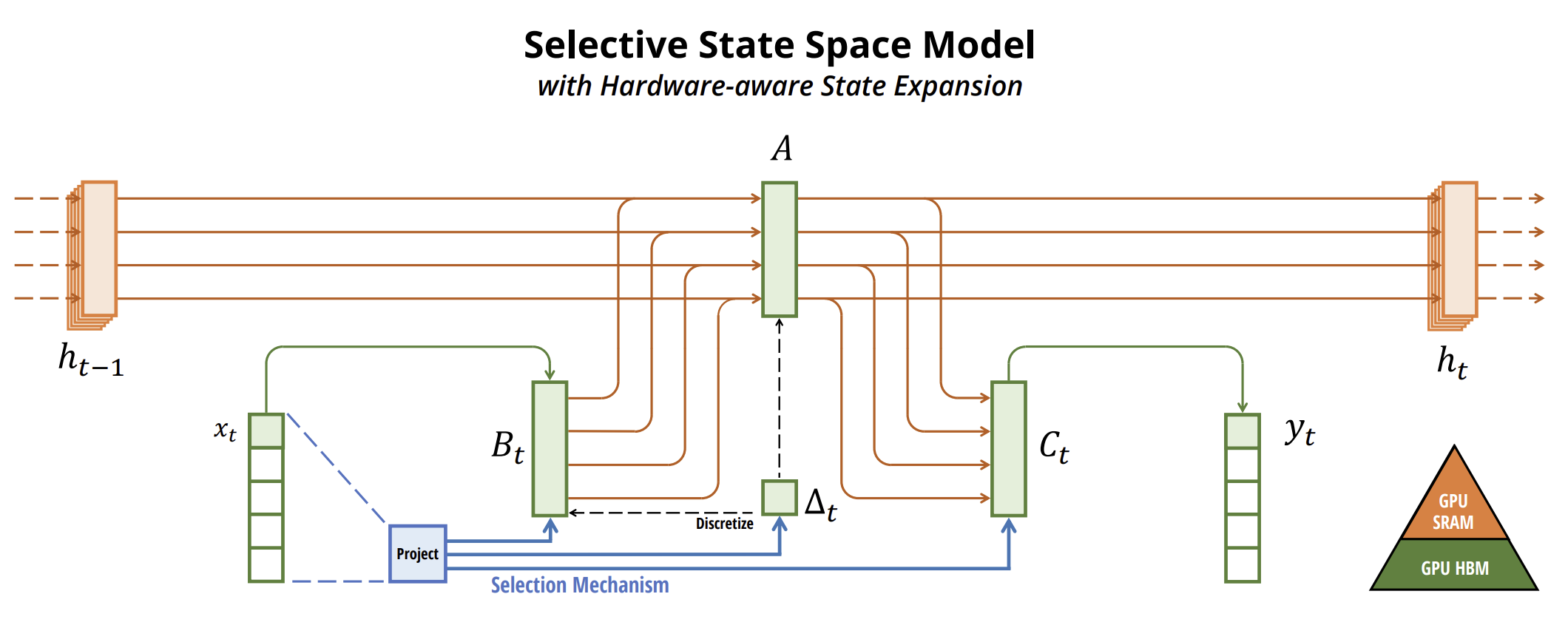
论文《曼巴(Mamba):配以可选性状态空间进行线性-时间序列建模》中介绍了一种启用状态空间模型进行时间序列预测的算法。该论文提出了一类新的选择性状态空间模型。
作者辨别出现有模型的一个关键限制:基于输入数据有效筛选信息的能力(即,关注特定的输入数据、或忽略它们)。他们开发了一种简单的选择机制,令 SSM 参数依赖于输入数据。这允许模型过滤掉不相关的信息,并无限期地保留相关信息。
作者简化了以前的深度序列模型架构,即把 SSM 架构与 MLP 设计集成到单一模块之中,成果是一个协同选择性状态空间的简单同构架构(曼巴)。
选择性 SSM,以及曼巴架构是配以关键属性的全递归模型,令它们适合当作基于序列的通用模型的基础。
- 高品质: 选择性确保在密集模态中的高性能。
- 快速训练和推理:在训练期间,计算和内存随序列长度线性伸缩,而推理期间部署自回归模型,每步只需要恒定的时间,因为它无需缓存以前的元素。
- 长期上下文关系:品质和效率的结合,可以在处理大型序列时强化性能。
1. 曼巴(Mamba)算法
曼巴作者的论调,序列建模的本质挑战就是将上下文关系压缩成更小的状态。可以从这个角度看出热门序列模型的权衡。例如,注意力同时是有效的和低效的,因为它根本没有明确地压缩上下文关系。这从事实中可以明显看出,自回归推理需要显式存储整个上下文(即键-值缓存),从而导致线性时间推理和二次时间变换器训练缓慢。
相较之,递归模型是高效的,因为它们维护有限状态,这意味着推理时间恒定,以及训练时间呈线性。不过,它们的效率受制于该状态压缩上下文的程度。
为了概括该原理,作者专注于解决两个合成任务:
- 选择性复制任务。它需要内容感知推理来记住相关标记,并过滤掉不相关的标记。
- 感应头任务。它解释了情境学习中的大多数 LLM 能力。解决该任务需要情境依赖推理,以便判定何时在相应情境中提取正确的输出。
这些任务揭示了 LTI 模型中的故障模式。从递归的角度,它们的固定动态阻止它们从情境中选择正确的信息,也不影响它们经由依据输入数据的序列传输隐藏状态。从卷积的角度,全局卷积可以解决原版复制任务,因为它只需要时间意识,但由于缺乏内容意识,它们要纠缠于选择性复制。具体来说,输入和输出之间的距离是变化的,且不能用静态卷积核建模。
因此,权衡序列模型效率的本征,是它们压缩状态的优劣。反之,作者提出,设计序列模型的基础原理是选择性,或者说情境依赖性是否有能力关注或过滤掉输入数据的顺序状态的。选择机制控制信息如何沿序列维度传播或交互。
将选择机制合并到模型中的一种方法,是令参数根据输入数据影响序列交互。关键的区别在于简单地对制定若干参数 ΔB、输入数据的 C 函数,延及张量形状的相应变化。具体来说,这些参数现在拥有了长度维度 L。这意味着模型从非时变转换为时变。
作者特别选择:
- SB(x) = LinearN(x)
- SC(x) = LinearN(x)
- SΔ(x) = BroadcastD(Linear1(x))
- τΔ = SoftPlus
选择 SΔ and τΔ 是由它们与 RNN 门控机制的连接驱动的。
作者的靶向是在现代硬件(GPU) 上令选择性 SSM 更高效。在高层次上,像 SSM 这样的递归模型总要在效率和速度之间取得平衡:具有较高隐藏状态维度的模型应当更高效,但速度更慢。因此,曼巴面临的挑战是在不牺牲模型速度、或增加内存消耗的情况下,隐藏状态维度最大化。
选择机制克服了 LTI 模型的局限性。不过,SSM 的计算挑战仍在。作者以三种经典技术解决了这个问题:内核融合、并行扫描、和重计算。他们进行了两个关键观察:
- 朴素的循环计算使用 O(BLDN)FLOP,而卷积计算需要 O(BLD log(L)) FLOP。前者的系数较低。因此,对于长序列和不太大的状态维度 N,递归模式实际上可以使用更少的 FLOPs。
- 两个主要挑战是重复周期的连续性和高内存使用率。为了解决后者,与卷积模式一样,他们试图避免计算全状态 h。
关键思路是动用现代加速器(GPU),仅在内存层次的更高效级别计算 h。大多数操作都会受内存带宽限制,包括扫描。作者使用内核融合来减少内存 I/O 操作,与标准实现相比,显著加快了执行速度。
此外,它们还小心翼翼地应用了经典的重计算技术来降低内存需求:不存储中间状态,而是在输入处理期间中逆向重计算。
选择性 SSM 函数作为自主序列转换,能灵活地嵌入到神经网络当中。
选择机制是一个更广泛的概念,能以不同方式应用于其它参数、或经由各种转换。
选择性允许我们删除相关输入数据中或许会出现的不相关噪声令牌。这样的一个例子是选择性复制问题,它发生在常见的数据模态中,尤其是针对离散数据。之所以出现该性质,是因为模型能够机械地过滤掉任何特定的输入数据 Xt。
实证观察表明,尽管原则上更多情境应当严格强化性能,但许多序列模型并没有随着更长情境而改进。解释则是,许多序列模型在必要时无法有效地忽略不相关的情境。
相较而言,选择性模型可以随时重置其状态,从而丢弃无关的历史记录,确保它们的性能在更长期情境中单向提高。
该方法的原始可视化如下所示。
2. 利用 MQL5 实现
在回顾了曼巴方法的理论层面之后,我们转向讨论所提议方式的 MQL5 真正实现。这项工作分为两个阶段。首先,我们构造实现 SSM 算法的类,其当作综合曼巴方法的嵌套层之一。然后,我们构建顶层算法流程。
2.1SSM 实现
有许多算法可用来构造 SSM。至于本实验,我略微偏离了原始的曼巴实现,创建了最简单的状态空间选择性模型之一。实现位于 CNeuronSSMOCL 类之中。作为父对象,我们使用完全连接神经层基类 CNeuronBaseOCL。新类结构如下所示。
class CNeuronSSMOCL : public CNeuronBaseOCL { protected: uint iWindowHidden; CNeuronBaseOCL cHiddenStates; CNeuronConvOCL cA; CNeuronConvOCL cB; CNeuronBaseOCL cAB; CNeuronConvOCL cC; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronSSMOCL(void) {}; ~CNeuronSSMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSSMOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
在所呈现的结构中,我们看到一个常量声明,其定义了一个元素(iWindowHidden),和 5 个内部神经层的隐藏状态维度。我们将在实现过程中考察它们的功能。
在我们类中,可重写方法集非常标准。我想您已经猜到了它们的功能意图。
类的所有内部对象都是静态声明的,这允许我们将类构造函数和析构函数留空。所有已声明和继承对象的初始化都在 Init 方法中执行。在该方法的参数中,我们会接收常量,其允许我们清楚地判定用户想要创建什么样的对象。
bool CNeuronSSMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
这里有 3 个这样的参数:
- window – 序列中一个元素的向量大小;
- window_key ― 序列中一个元素的内部表示向量的大小;
- units_count ― 正在分析的序列大小;
正如我曾提到的,在这个实验中,我们使用的是简化的 SSM 算法。特别是,它未实现将多模态序列切分为独立通道。
在方法主体中,我们立即调用父类中同名方法,其已经包含继承对象和变量的初始化,以及针对从外部程序接收的参数执行最小和必要的验证。
父类方法成功执行之后,我们转到初始化该类中声明的对象。首先,我们初始化负责存储隐藏状态的内部层。
if(!cHiddenStates.Init(0, 0, OpenCL, window_key * units_count, optimization, iBatch)) return false; cHiddenStates.SetActivationFunction(None); iWindowHidden = window_key;
我们还立即把单个序列元素的内部状态向量的大小存储到局部变量之中。
重点要注意,我们特意保存该参数值,且不执行任何验证。此处的思路是,我们首先有意识地初始化了内部层,其大小由这个参数决定。如果用户指定的数值不正确,则在初始化阶段,类本身将发生错误。因此,内部层的仔细初始化会隐式执行参数验证。这令在该阶段的额外检查变得多余。
还值得一提的是,cHiddenStates 对象仅临时数据存储,我们显式禁用了其内的激活函数。
接下来,我们初始化两个数据投影层,其控制输入数据如何影响结果。首先,我们初始化隐藏状态投影层:
if(!cA.Init(0, 1, OpenCL, iWindowHidden, iWindowHidden, iWindowHidden, units_count, 1, optimization, iBatch)) return false; cA.SetActivationFunction(SIGMOID);
于此,我们用到一个卷积层,它允许我们为每个序列元素执行隐藏状态的独立投影。为了监管每个元素对最终结果的影响,我们使用 sigmoid 作为该层的激活函数。如您所知,sigmoid 函数将数值映射到范围 [0, 1]。如果为 “0”,则元素不会影响整体结果。
然后,我们按类似的方式初始化输入数据投影层:
if(!cB.Init(0, 2, OpenCL, window, window, iWindowHidden, units_count, 1, optimization, iBatch)) return false; cB.SetActivationFunction(SIGMOID);
注意,两个投影层都返回与隐藏状态大小匹配的张量,即使它们的输入张量或许有不同的维度。这从数据窗口的大小及其初始化对象时的步骤中可以明显看出。
为了计算输入数据和隐藏状态对结果的综合影响,我们将使用权重合计。为了优化和降低运算数量,我们决定将该投影步骤合并到目标结果维度。因此,我们首先将数据沿序列元素维度级联成一个共用张量。
if(!cAB.Init(0, 3, OpenCL, 2 * iWindowHidden * units_count, optimization, iBatch)) return false; cAB.SetActivationFunction(None);
接下来,我们应用另一个内部卷积层。
if(!cC.Init(0, 4, OpenCL, 2*iWindowHidden, 2*iWindowHidden, window, units_count, 1, optimization, iBatch)) return false; cC.SetActivationFunction(None);
最后,在初始化方法的末尾,我们将指针重定向到类的结果和梯度缓冲区,以便指向内部结果投影层的等效缓冲区。这个简单步骤使我们能够避免在前向和后向通验期间那些不必要的数据复制。
SetActivationFunction(None); if(!SetOutput(cC.getOutput()) || !SetGradient(cC.getGradient())) return false; //--- return true; }
当然,我们还会监控所有操作成功与否,在方法结束时,我们将一个指示成功的布尔值返回给调用程序,。
类的初始化完成之后,我们转到构建前馈通验算法。如您所知,该功能是在重写的 feedForward 方法中实现的。此处的一切都非常简单。
bool CNeuronSSMOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cA.FeedForward(cHiddenStates.AsObject())) return false; if(!cB.FeedForward(NeuronOCL)) return false;
方法参数包括指向之前神经层对象的指针,该对象提供输入数据。
在方法内部,我们立即执行两次投影(输入数据和隐藏状态)到兼容格式。这是使用相应内部卷积层的前向通验方法完成的。
获得的投影沿序列元素维度级联为单个张量。
if(!Concat(cA.getOutput(), cB.getOutput(), cAB.getOutput(), iWindowHidden, iWindowHidden, cA.Neurons() / iWindowHidden)) return false;
最后,我们将连接层投影所需的结果维度。
if(!cC.FeedForward(cAB.AsObject())) return false;
此处有两点需要注意。首先,我们没有将结果复制到当前层的结果缓冲区当中 – 不需要该操作,因为我们重定向了数据缓冲区指针。
其次,您或许已注意到我们并未更新隐藏状态。因此,此刻,前向通验方法似乎不完整。然而,问题在于我们仍然需要当前的隐藏状态来进行反向传播。因此,在后向通验期间更新隐藏状态是有意义的,因为它仅供当前层算法内所用。
但是这有一个缺点:在模型推理(部署)期间,我们不能用反向传播方法。如果我们将隐藏状态更新推迟到反向传播通验,则它在推理过程中永远不会更新,从而违反了整个算法的逻辑。
因此,我们检查模型的当前运行模式,只有在推理期间,我们才会更新隐藏状态。我们通过对先前隐藏状态和输入数据的投影求,和并归一化来实现这一点。
if(!bTrain) if(!SumAndNormilize(cA.getOutput(), cB.getOutput(), cHiddenStates.getOutput(), iWindowHidden, true)) return false; //--- return true; }
据此,我们的前向通验方法就完成了,并且我们将操作成功的布尔值状态返回给调用程序。
实现前馈通验之后,我们进行反向传播传递方法。如常,我们覆盖两个方法:
- calcInputGradients — 用于误差梯度分派。
- updateInputWeights — 用于模型参数更新。
误差梯度分派算法以逆序镜像前馈通验。我建议您自己验证该方法 — 它在随附代码中提供。不过,参数更新方法值得特别注意。因为我们在模型训练中加入了隐藏状态更新过程。
bool CNeuronSSMOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cA.UpdateInputWeights(cHiddenStates.AsObject())) return false; if(!SumAndNormilize(cA.getOutput(), cB.getOutput(), cHiddenStates.getOutput(), iWindowHidden, true)) return false;
于此,我们首先调整内部隐藏状态投影层的参数。只有在那之后,我们才会更新隐藏状态本身。
注意,我们在此处不检查模型的运行模式,因为该方法仅在训练期间调用。
接下来,我们调用其余具有可学习参数的内部对象的相应参数更新方法。
if(!cB.UpdateInputWeights(NeuronOCL)) return false; if(!cC.UpdateInputWeights(cAB.AsObject())) return false; //--- return true; }
完成所有操作后,该方法返回布尔状态至调用程序。
针对 SSM 实现类方法的讨论到此结束。您可在附件中找到所有这些方法的完整代码。
2.2曼巴方法类
我们已为 SSM 层实现了类。现在,我们可以转到构建曼巴方法的顶层算法。为了实现该方法,我们将创建一个类 CNeuronMambaOCL,与上一个类一样,该类将从全连接层类 CNeuronBaseOCL 继承基本功能。新类结构如下所示。
class CNeuronMambaOCL : public CNeuronBaseOCL { protected: CNeuronConvOCL cXProject; CNeuronConvOCL cZProject; CNeuronConvOCL cInsideConv; CNeuronSSMOCL cSSM; CNeuronBaseOCL cZSSM; CNeuronConvOCL cOutProject; CBufferFloat Temp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronMambaOCL(void) {}; ~CNeuronMambaOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMambaOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
在此,我们可看到一组熟悉的可覆盖方法,和内部神经网络层的声明,我们将在类方法的实现过程中探索其功能。
同时,没有声明存储常量的内部变量。我们将讨论能令我们在实现阶段避免保存常量的决策。
如常,所有内部对象都声明为静态。因此,类的构造函数和析构函数都保持为空。对象的初始化在 Init 方法中执行。
bool CNeuronMambaOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
该方法中的参数列表类似于前面讨论的 CNeuronSSMOCL 类中同名方法。不难猜出它们具有相似的功能。
在方法主体中,我们首先调用父类初始化方法,其处理继承的对象和变量。
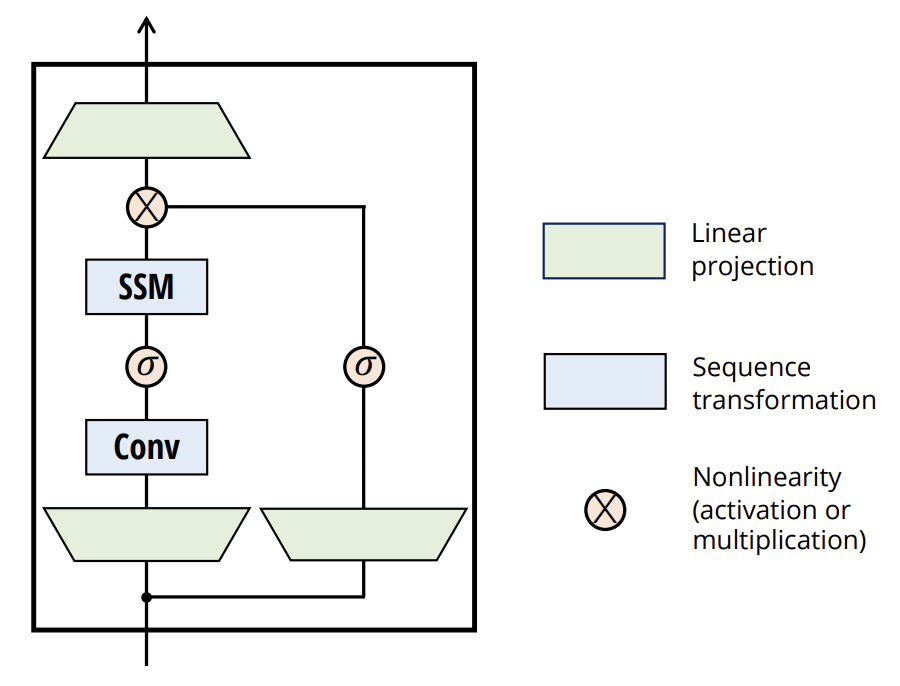
您或许还记得曼巴方法的理论解释,此处的输入数据遵循两个并行流。对于这两个流,我们执行数据投影,将用卷积层执行。
if(!cXProject.Init(0, 0, OpenCL, window, window, window_key + 2, units_count, 1, optimization, iBatch)) return false; cXProject.SetActivationFunction(None); if(!cZProject.Init(0, 1, OpenCL, window, window, window_key, units_count, 1, optimization, iBatch)) return false; cZProject.SetActivationFunction(SIGMOID);
在第一个流中,我们使用卷积层和 SSM 模块。在第二个中,我们应用一个激活函数,之后数据进入合并阶段。故此,两个流的输出必须是大小相当的张量。为了达成这一点,我们略微增加了第一个流的投影大小,这可以通过卷积期间的数据压缩来补偿。
注意,激活函数仅用于第二个流的投影。
下一步是初始化卷积层。
if(!cInsideConv.Init(0, 2, OpenCL, 3, 1, 1, window_key, units_count, optimization, iBatch)) return false; cInsideConv.SetActivationFunction(SIGMOID);
在此,我们在单独序列元素中执行独立的卷积。因此,我们将隐藏状态张量的大小指定为卷积元素的数量。我们还加上序列元素的数量,作为为自变量。
卷积窗口大小和步幅与我们为第一个数据流增加的投影大小一致。
此刻,我们还添加了一个激活函数,来确保两个流之间数据的可比性。
接下来是我们的 SSM 模块,它执行状态选择。
if(!cSSM.Init(0, 3, OpenCL, window_key, window_key, units_count, optimization, iBatch)) return false;
为了完成算法,并为两个数据流的合并引入非线性,我们将输出级联到一个统一张量。
if(!cZSSM.Init(0, 4, OpenCL, 2 * window_key * units_count, optimization, iBatch)) return false; cZSSM.SetActivationFunction(None);
然后,我们使用另一个卷积层,将结果数据在每个序列元素中投影到所需的大小。
if(!cOutProject.Init(0, 5, OpenCL, 2*window_key, 2*window_key, window, units_count, 1, optimization, iBatch)) return false; cOutProject.SetActivationFunction(None);
此外,我们分配了一个缓冲区来存储中间结果。
if(!Temp.BufferInit(window * units_count, 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false;
我们执行指针交换来引用这些缓冲区。
if(!SetOutput(cOutProject.getOutput())) return false; if(!SetGradient(cOutProject.getGradient())) return false; SetActivationFunction(None); //--- return true; }
最后,该方法将所执行操作的布尔结果返回给调用程序。
类初始化方法完成之后,我们转到在 feedForward 方法中实现前馈算法。在创建初始化方法期间已经提到了该算法的一部分。现在我们看看它在代码中的实现。
bool CNeuronMambaOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cXProject.FeedForward(NeuronOCL)) return false; if(!cZProject.FeedForward(NeuronOCL)) return false;
该方法接收指向前一层对象的指针,该对象的缓冲区包含我们的输入数据。在方法主体中,我们通过调用投影卷积层的前向通验方法来立即投影传入的数据。
此刻,我们完成了第二个信息流的操作。不过,我们仍然需要处理主数据流。在此,我们从数据卷积开始。
if(!cInsideConv.FeedForward(cXProject.AsObject())) return false;
之后我们执行状态选择。
if(!cSSM.FeedForward(cInsideConv.AsObject())) return false;
两个流的操作完成后,我们将结果合并到一个统一张量之中。
if(!Concat(cSSM.getOutput(), cZProject.getOutput(), cZSSM.getOutput(), 1, 1, cSSM.Neurons())) return false;
重点要注意,我们没有存储单个序列元素内部状态的维度。这不是问题。我们知道来自两个信息流的张量具有相同的维度。因此,我们能够按顺序从每个张量中组合一个元素,而不会破坏整体结构。
最后,我们将数据投影到所需的输出维度。
if(!cOutProject.FeedForward(cZSSM.AsObject())) return false; //--- return true; }
该方法最后返回一个布尔结果给调用程序,指示操作成功。
如您所见,前馈通验算法并不是特别复杂。这同样适用于反向传播通验方法。因此,我们不会在本文中详究它们的算法。该类及其所有方法的完整代码都包含在附件当中。
2.3模型架构
在前面的章节中,我们实现了曼巴作者所提议方法的解释。不过,所做的工作应发挥作用。为了评估已实现算法的效率,我们需要将它们集成到我们的模型当中。您或许已猜到,我们会将新创建的层添加到环境状态编码器模型之中。毕竟,我们训练的模型,是在预测未来价格走势的框架之内。
该模型的架构在 CreateEncoderDescriptions 方法中体现。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
该方法接收一个指向动态数组的指针,我们将在其中写入正在创建的模型的架构描述。
在方法主体中,我们检查接收到的指针相关性,并在必要时创建对象的新实例。在这个准备步骤之后,我们继续描述模型架构。
第一层预计将原始数据输入到模型之中。如常,我们使用足够大小的全连接层。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
通常,我们把来自终端的接收数据以“原生”形式输入到模型当中。自然,这些输入属于不同的分布。我们知道,当使用归一化和可比较的数值时,任何模型的效率都会显著提高。因此,为了将不同的输入数据达到可比的规模,我们使用了批量归一化层。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
接下来,我们创建一个包含三个相同曼巴层的模块。为此,我们为模块定义了一个架构描述,并按所需的次数将其添加到数组之中。
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMambaOCL; descr.window = BarDescr; //window descr.window_out = 4 * BarDescr; //Inside Dimension prev_count = descr.count = HistoryBars; //Units descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; for(int i = 2; i <= 4; i++) if(!encoder.Add(descr)) { delete descr; return false; }
注意,所分析数据窗口的大小对应于描述单个序列元素的元素数量,并且内部表示的大小是其四倍大。这遵循了作者的建议,即在曼巴方法中执行扩展投影。
序列元素的数量与所分析历史的深度相对应。
正如我在类实现中提到的,在这个版本中,我们没有分配单独的信息通道。无论如何,我们的算法处理独立的序列元素。若您需要分析独立通道,可以预先转置数据,并相应地调整层参数。但这是另一个实验的主题。
不过,我们将跨独立通道预测序列。因此,在曼巴模块之后,我们转置数据。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
然后,我们应用两个卷积层来预测独立通道的下一个数值。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = prev_count; descr.window_out = 4 * NForecast; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = 4 * NForecast; descr.window_out = NForecast; descr.activation = TANH; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
之后,我们将预测值返回到其原始表示形式。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
此外,我们还附加了在归一化过程中获得的原始数据分布的统计特征。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
我们模型的最后一步是在频域中调整结果。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
参与者和评论者模型的架构保持不变。此外,与环境交互的程序亦不需要修改。不过,我们不得不在模型训练计划中引入一些有针对性的更改。这是因为在 SSM 模块中使用隐藏状态,需要以递归模型特有的方式调整输入数据的顺序。每当使用具有隐藏状态的模型时,这种调整都是标准的,其中信息会随着时间的推移而积累。我鼓励您从附件中研究它们。该附件包含准备本文时的所有程序和类的完整代码。至此,我们的实现描述完毕,并转到基于真实历史数据进行实际测试。
3. 测试
我们的工作已接近完工,我们正在进入最后阶段 — 训练模型,并测试所取得的成果。这些模型依据 2023 年的 EURUSD 历史数据进行训练,时间帧为 H1。所有指标的参数都设置为默认值。
在第一阶段,我们训练环境状态编码器来预测指定时间横向范围的未来价格走势。该模型仅分析历史价格数据,完全忽略参与者的动作。这令我们能够取用以前收集的数据集进行全面的模型训练,而无需更新它们。不过,如果历史训练期间发生变化或延长,则或许有必要进行更新。
第一个观察结果是,该模型被证明是紧凑和快速的。训练过程相对稳定和稳健。该模型显示出有趣的结果。
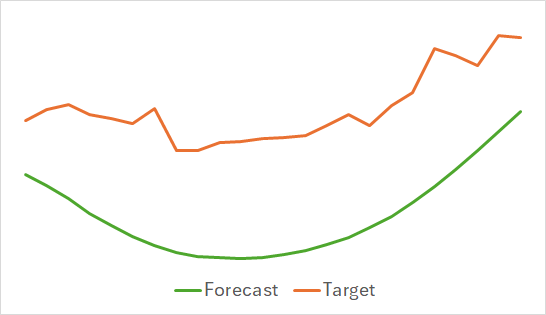
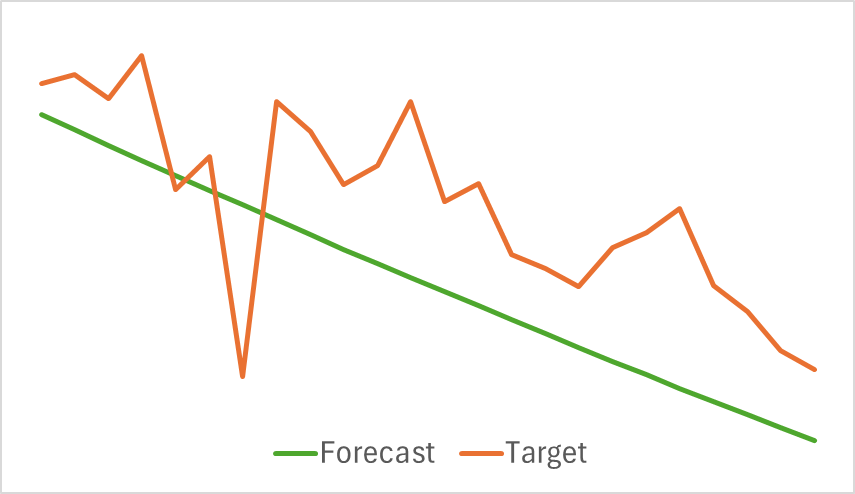
上图显示未来 24 小时的预测价格走势。值得注意的是,在第一张图片中,预测线平滑地示意趋势变化,而在第二种情况下,它几乎线性地反映了正在行进中的趋势。
在第二阶段,我们进行了迭代参与者政策训练。我们还训练了评论者数值函数。评论者的作用是指导参与者提高其政策效率。
如早前所述,第二个训练阶段是迭代的。这意味着,贯穿整个训练过程,我们会定期更新训练数据集,从而包含与当前参与者政策相关的数据。维护一份最新的训练集对于正确的模型训练至关重要。
然而,在训练期间,我们未能达成一个明确定义资金增长趋势的政策。尽管该模型设法在 2024 年 1 月的历史测试数据中产生了盈利,但没有观察到持续的趋势。
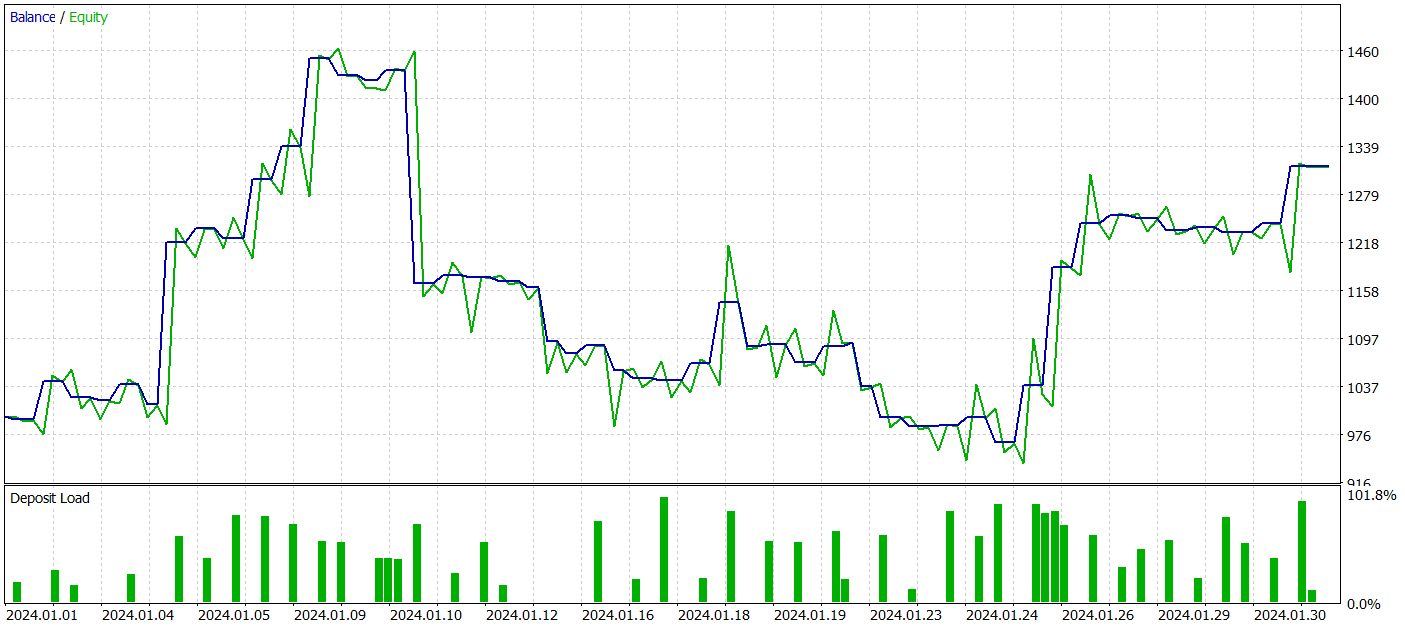
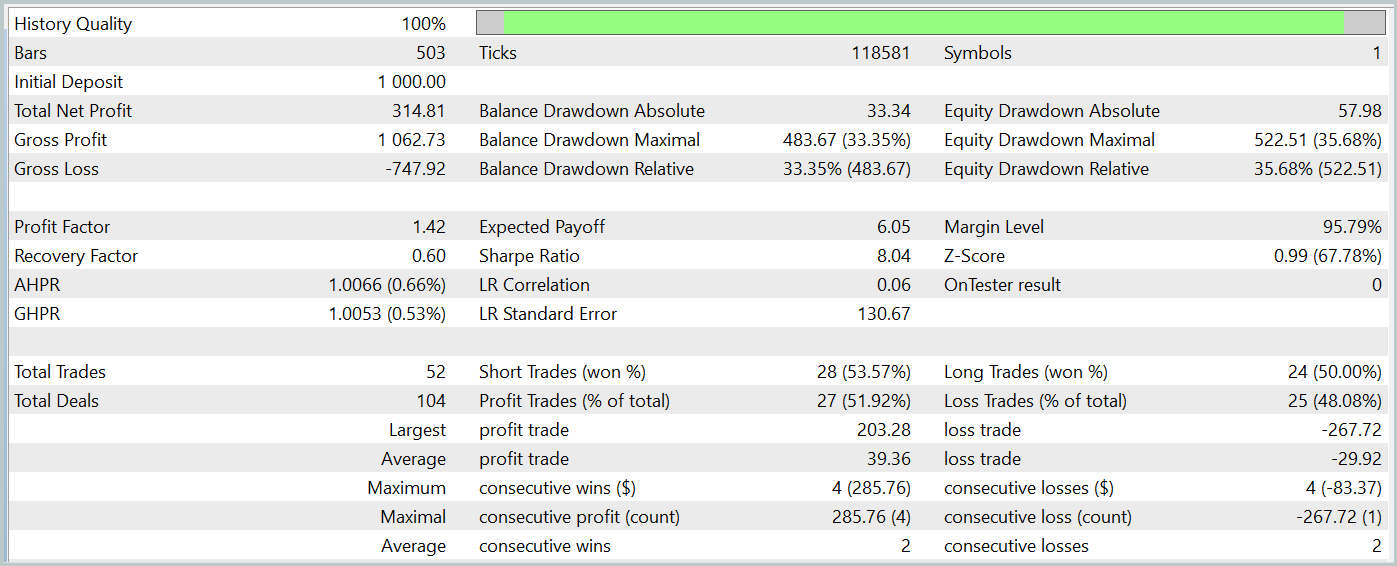
测试期间,该模型执行了 52 笔交易,其中 27 笔以盈利了结,即近 52%。平均盈利超过每笔交易平均亏损(39.36 对 -29.82)。尽管如此,最大亏损比最大盈利大 30%。此外,我们观察到净值回撤超 35% 以上。显然,这个模型需要进一步优调。
按小时和天划分的盈亏也很有趣。

周五明显盈利,而周三则亏损。还有特定的日内时段,其中盈利和亏损交易聚集。这需要深入分析。特别是由于平均持仓时间略多于一个小时,最长为两个小时。

结束语
在本文中,我们讨论了一种新的时间序列预测方法曼巴,它为变换器等传统架构提供了一种有效的替代方案。通过集成样本状态空间模型(SSM),曼巴提供了高吞吐量与序列长度的线性伸缩。
在本文的实践部分,我们利用 MQL5 实现了我们所提出方式的愿景。我们依据现实世界的数据训练模型,得到的结果喜忧参半。
参考
文章中所用程序
| # | Issued to | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 样本收集 EA |
| 2 | ResearchRealORL.mq5 | EA | 利用 Real ORL方法收集样本的 EA |
| 3 | Study.mq5 | EA | 模型训练 EA |
| 4 | StudyEncoder.mq5 | EA | 编码器训练 EA |
| 5 | Test.mq5 | EA | 模型测试 EA |
| 6 | Trajectory.mqh | 类库 | 系统状态描述结构 |
| 7 | NeuroNet.mqh | 类库 | 创建神经网络的类库 |
| 8 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15546
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

输出:TotalBase.dat(二进制轨迹数据)。
输出:TotalBase.dat(二进制轨迹数据)。
由于我们没有先前训练好的编码器(Enc.nnw)和行为器(Act.nnw),因此无法 运行 Research.mq5,而且我们 也 没有Signals\Signal1.csv 文件,因此也无法运行ResearchRealORL.mq5, 那么我们如何运行步骤 1 呢?
请查看新文章:交易中的神经网络:状态空间模型。
作者:Dmitriy Gizlyk德米特里-吉兹里克
据我所知,在您的管道步骤 1 中,我们需要运行 Research.mq5 或 ResearchRealORL.mq5,详情如下:
输出:TotalBase.dat(二进制轨迹数据)。
输出:TotalBase.dat(二进制轨迹数据)。
由于我们没有先前训练好的编码器(Enc.nnw)和行为器(Act.nnw),因此无法 运行 Research.mq5,而且我们 也 没有Signals\Signal1.csv 文件,因此也无法运行ResearchRealORL.mq5, 那么我们如何运行步骤 1 呢?
您好、
在 Research.mq5 中,您可以找到
因此,如果您没有预训练模型,EA 将以随机参数生成模型。您可以从随机轨迹中收集数据。
关于 ResearchRealORL.mq5 的更多信息,请参阅文章。
版主纠正了这次的格式问题。今后请正确使用代码格式,格式不正确的帖子可能会被删除。
在 trajectory.mqh,mamba 文件夹
中的第 2-4 层(第 604 行左右),我认为有一个问题:
,将 new CLayerDescription() 移到 Mamba 循环内,这样 3 层中的每一层都有自己的分配
,我是这样写的。
谁能告诉我是对还是错?
在 trajectory.mqh 中,mamba 文件夹中的第 2-4 层(第 604 行左右)
我觉得有一个问题:
在 Mamba 循环内移动了 new CLayerDescription(),因此 3 层中的每一层都有自己的分配
下面是我的写法。
谁能告诉我是对还是错?
下午好,Seyedsoroush Abtahiforooshani。
在这种情况下,我们并不形成一个层,而只是对其结构进行描述。程序会根据描述生成神经元层。在初始变体中,当 descr = new CLayerDescription() 在数组外形成时,我们为单层形成一个 descr 对象,并按要求的次数传递其指针。在形成模型层时,descr 对象不会改变。这就是为什么神经元层的结构完全相同,但每个神经元层都有自己的参数。
当你将对象形成移入一个循环时,正在创建的模型不会有任何变化。我们只是创建了额外的descr 复制,这些 复制将在模型形成后立即删除。这将在形成模型时增加一些额外的操作和内存消耗。这对模型操作没有影响。