Artigos com exemplos de como programar robôs de negociação na linguagem MQL5
Os experts são o coração da negociação automatizada e o objetivo de toda pessoa que programa estratégias de trading. Você pode criar seu próprio robô de negociação com a ajuda dos artigos desta seção. Os principiantes podem seguir passo a passo todas as etapas dos sistemas de negociação automatizados: criação, depuração e teste.
Os artigos ensinam não apenas como programar em MQL5, mas também mostram como implementar quaisquer ideias e técnicas de negociação. Aprenda a programar um trailing stop, a aplicar o gerenciamento de dinheiro, a calcular o valor de um indicador e muito, muito mais.
Novo artigo

Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se

Introdução ao MQL5 (Parte 11): Um guia para iniciantes sobre como trabalhar com indicadores incorporados no MQL5 (II)
Descubra como desenvolver um Expert Advisor (EA) em MQL5 usando múltiplos indicadores como RSI, MA e Oscilador Estocástico para detectar divergências ocultas de alta e de baixa. Aprenda a implementar um gerenciamento de risco eficaz e a automatizar negociações com exemplos detalhados e código-fonte totalmente comentado para fins educacionais!

Redes neurais em trading: Otimização de LSTM para fins de previsão de séries temporais multidimensionais (Conclusão)
Continuamos a implementação do framework DA-CG-LSTM, que propõe métodos inovadores de análise e previsão de séries temporais. O uso de CG-LSTM e do mecanismo de atenção dupla permite identificar com maior precisão tanto dependências de longo prazo quanto de curto prazo nos dados, o que é especialmente útil para o trabalho com mercados financeiros.

Integração de APIs de Corretoras com Expert Advisors usando MQL5 e Python
Neste artigo, discutiremos a implementação do MQL5 em parceria com o Python para realizar operações relacionadas à corretora. Imagine ter um Expert Advisor (EA) em execução contínua hospedado em um VPS, executando negociações em seu nome. Em determinado momento, a capacidade do EA de gerenciar fundos torna-se fundamental. Isso inclui operações como adicionar fundos à sua conta de negociação e iniciar retiradas. Nesta discussão, iremos esclarecer as vantagens e a implementação prática desses recursos, garantindo a integração perfeita do gerenciamento de fundos à sua estratégia de negociação. Fique atento!

Redes neurais em trading: Otimização de LSTM para fins de previsão de séries temporais multivariadas (DA-CG-LSTM)
Este artigo apresenta o algoritmo DA-CG-LSTM, que propõe novas abordagens para análise e previsão de séries temporais. Você verá como mecanismos de atenção inovadores e a flexibilidade da arquitetura contribuem para o aumento da precisão das previsões.

Previsão de barras Renko com a ajuda de IA CatBoost
Como usar barras Renko junto com IA? Vamos analisar o Renko-trading no Forex com precisão de previsões de até 59.27%. Exploraremos as vantagens das barras Renko para filtrar o ruído do mercado, entenderemos por que indicadores de volume são mais importantes do que padrões de preço e como configurar o tamanho ideal do bloco Renko para EURUSD. Um guia passo a passo para integrar CatBoost, Python e MetaTrader 5 para criar seu próprio sistema de previsão Renko Forex. Perfeito para traders que desejam ir além da análise técnica tradicional.

Trading por pares: negociação algorítmica com auto-otimização baseada na diferença de pontuação Z
Neste artigo, analisaremos o que é o trading por pares e como ocorre a negociação baseada em correlações. Também criaremos um EA para automatizar o trading por pares e adicionaremos a possibilidade de otimização automática desse algoritmo de negociação com base em dados históricos. Além disso, dentro do projeto, aprenderemos a calcular as divergências entre dois pares por meio da pontuação Z.

Redes neurais em trading: Ator–Diretor–Crítico (Conclusão)
O framework Actor–Director–Critic representa uma evolução da arquitetura clássica de aprendizado por agentes. O artigo apresenta uma experiência prática de sua implementação e adaptação às condições dos mercados financeiros.

Critérios de tendência. Conclusão
Neste artigo, analisaremos as particularidades da aplicação prática de alguns critérios de tendência. Além disso, tentaremos desenvolver alguns novos critérios. A principal atenção será dada à eficácia desses critérios na análise de dados de mercado e no trading.

Redes neurais em trading: Detecção de anomalias no domínio da frequência (Conclusão)
Damos continuidade ao trabalho de implementação das abordagens do framework CATCH, que combina a transformada de Fourier e o mecanismo de patching em frequência, possibilitando a detecção precisa de anomalias de mercado. Nesta etapa, concluímos a realização da nossa própria versão das abordagens propostas e conduziremos testes com os novos modelos utilizando dados históricos reais.

Gerenciamento de riscos (Parte 5): Integração do sistema de gerenciamento de riscos ao EA
Neste artigo, implementaremos o sistema de gerenciamento de risco desenvolvido em publicações anteriores e adicionaremos o indicador Order Blocks apresentado em outros artigos. Além disso, será realizado um backtest para comparar os resultados com a aplicação do sistema de gerenciamento de risco e para avaliar o impacto do risco dinâmico.

Desenvolvimento de um sistema de monitoramento de entradas de swing (EA)
À medida que o ano se aproxima do fim, traders de longo prazo costumam refletir sobre o histórico do mercado para analisar seu comportamento e tendências, visando projetar potenciais movimentos futuros. Neste artigo, exploraremos o desenvolvimento de um Expert Advisor (EA) de monitoramento de entradas de longo prazo usando MQL5. O objetivo é abordar o desafio das oportunidades de negociação de longo prazo perdidas devido ao trading manual e à ausência de sistemas automatizados de monitoramento. Usaremos um dos pares mais negociados como exemplo para estruturar e desenvolver nossa solução de forma eficaz.
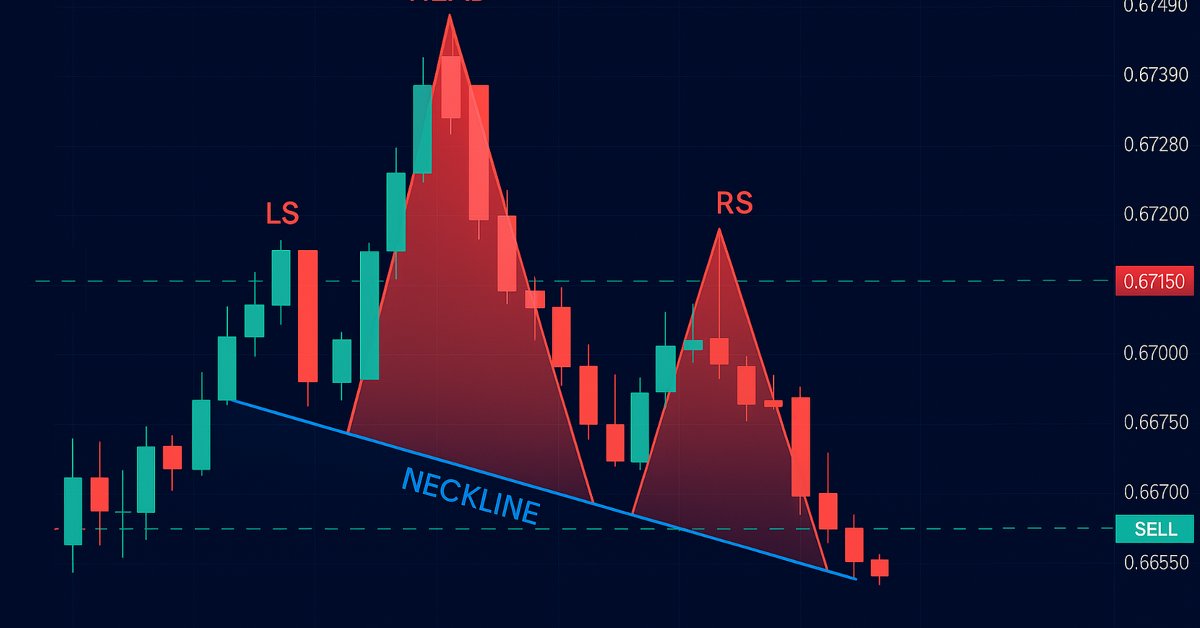
Automatização de estratégias de trading com MQL5 (Parte 13): Criação de um algoritmo de negociação para o padrão "Cabeça e Ombros"
Neste artigo, automatizaremos o padrão "Cabeça e Ombros" em MQL5. Analisaremos sua arquitetura, implementaremos um EA para sua detecção e negociação, e testaremos os resultados no histórico. Esse processo revela um algoritmo de negociação prático, que pode ser aprimorado.
Automatizando Estratégias de Negociação em MQL5 (Parte 3): O Sistema Zone Recovery RSI para Gestão Dinâmica de Operações
Neste artigo, criamos um Sistema EA Zone Recovery RSI em MQL5, utilizando sinais de RSI para acionar operações e uma estratégia de recuperação para gerenciar perdas. Implementamos uma classe "ZoneRecovery" para automatizar as entradas de operações, a lógica de recuperação e o gerenciamento de posições. O artigo conclui com insights de backtesting para otimizar a performance e aprimorar a eficácia do EA.

Construindo um Modelo de Restrição de Tendência com Candlestick (Parte 10): Golden Cross e Death Cross Estratégicos (EA)
Você sabia que as estratégias Golden Cross e Death Cross, baseadas no cruzamento de médias móveis, são alguns dos indicadores mais confiáveis para identificar tendências de mercado de longo prazo? Um Golden Cross sinaliza uma tendência de alta quando uma média móvel mais curta cruza acima de uma média mais longa, enquanto o Death Cross indica uma tendência de baixa quando a média mais curta cruza abaixo. Apesar de sua simplicidade e eficácia, aplicar essas estratégias manualmente frequentemente leva a oportunidades perdidas ou negociações atrasadas.

Automatizando Estratégias de Trading em MQL5 (Parte 2): O Sistema Kumo Breakout com Ichimoku e Awesome Oscillator
Neste artigo, criamos um Expert Advisor (EA) que automatiza a estratégia Kumo Breakout utilizando o indicador Ichimoku Kinko Hyo e o Awesome Oscillator. Percorremos o processo de inicialização dos identificadores de indicadores, detecção das condições de breakout e codificação das entradas e saídas automatizadas de trades. Além disso, implementamos trailing stops e lógica de gerenciamento de posição para aprimorar o desempenho e a adaptabilidade do EA às condições de mercado.

Dominando Operações de Arquivos em MQL5: Do I/O Básico à Construção de um Leitor CSV Personalizado
Este artigo aborda técnicas essenciais de manipulação de arquivos em MQL5, abrangendo logs de operações, processamento de CSV e integração de dados externos. Ele oferece tanto compreensão conceitual quanto orientação prática de codificação. Os leitores aprenderão a construir uma classe personalizada de importação CSV passo a passo, adquirindo habilidades práticas para aplicações reais.
Desenvolvimento de ferramentas para análise do movimento de preços (Parte 7): Expert Advisor Signal Pulse
Libere o potencial da análise multitimeframe com o Signal Pulse, um EA em MQL5 que combina as Bandas de Bollinger e o Oscilador Estocástico para fornecer sinais de negociação precisos com alta probabilidade de ocorrência. Descubra como implementar essa estratégia e visualizar de forma eficiente oportunidades de compra e venda usando setas. O EA é ideal para traders que buscam aprimorar suas decisões por meio de análise automática em vários timeframes.
Construa EAs auto-otimizáveis em MQL5 (Parte 3): Acompanhamento dinâmico de tendência e retorno à média
Os mercados financeiros geralmente são classificados como estando em consolidação (movimento lateral) ou em tendência. Essa visão estática do mercado pode facilitar o trading no curto prazo. No entanto, ela está desconectada da realidade do mercado. Neste artigo, vamos tentar compreender melhor como exatamente os mercados financeiros transitam entre esses dois possíveis regimes e vamos tentar compreender melhor como exatamente os mercados financeiros transitam entre esses dois possíveis regimes e como podemos utilizar esse novo entendimento do comportamento do mercado para ganhar confiança em nossas estratégias de trading algorítmico.

Simplificando a negociação com base em notícias (Parte 6): Executando trades (III)
Neste artigo será implementada a ordenação de notícias para eventos econômicos individuais com base em seus identificadores. Além disso, as consultas SQL anteriores serão aprimoradas para fornecer informações adicionais ou reduzir o tempo de execução da consulta. O código criado nos artigos anteriores se tornará funcional.

Redes neurais em trading: Ator–Diretor–Crítico (Actor–Director–Critic)
Propomos conhecer o framework Actor-Director-Critic, que combina aprendizado hierárquico e uma arquitetura com múltiplos componentes para criar estratégias de trading adaptativas. Neste artigo, analisamos em detalhe como o uso do Diretor para classificar as ações do Ator ajuda a otimizar decisões de trading de forma eficiente e a aumentar a robustez dos modelos nas condições dos mercados financeiros.
Desenvolvimento do Kit de Ferramentas de Análise de Price Action (Parte 5): Volatility Navigator EA
Determinar a direção do mercado pode ser simples, mas saber quando entrar pode ser desafiador. Como parte da série intitulada "Desenvolvimento do Kit de Ferramentas de Análise de Price Action", tenho o prazer de apresentar mais uma ferramenta que fornece pontos de entrada, níveis de take profit e definições de stop loss. Para isso, utilizamos a linguagem de programação MQL5. Vamos nos aprofundar em cada etapa neste artigo.

Construindo um Modelo de Restrição de Tendência com Candlesticks (Parte 9): Expert Advisor de Múltiplas Estratégias (III)
Bem-vindo à terceira parte da nossa série sobre tendências! Hoje, vamos nos aprofundar no uso de divergência como estratégia para identificar pontos de entrada ideais dentro da tendência diária predominante. Também apresentaremos um mecanismo personalizado de proteção de lucro, semelhante a um trailing stop-loss, mas com melhorias exclusivas. Além disso, vamos atualizar o Trend Constraint Expert para uma versão mais avançada, incorporando uma nova condição de execução de trade para complementar as já existentes. À medida que avançamos, continuaremos explorando a aplicação prática do MQL5 no desenvolvimento algorítmico, fornecendo a você percepções mais detalhadas e técnicas acionáveis.

Redes neurais em trading: Hierarquia de habilidades para comportamento adaptativo de agentes (Conclusão)
O artigo analisa a implementação prática do framework HiSSD em tarefas de trading algorítmico. É mostrado como a hierarquia de habilidades e a arquitetura adaptativa podem ser utilizadas para desenvolver estratégias de negociação robustas.

Redes neurais em trading: Hierarquia de habilidades para comportamento adaptativo de agentes (HiSSD)
Apresentamos o framework HiSSD, que combina aprendizado hierárquico e abordagens multiagente para a criação de sistemas adaptativos. Neste trabalho, exploramos em detalhe como essa abordagem inovadora ajuda a identificar padrões ocultos nos mercados financeiros e a otimizar estratégias de trading em condições de descentralização.

Expert Advisor de scalping Ilan 3.0 AI com aprendizado de máquina
Lembra do EA Ilan 1.6 Dynamic? Vamos tentar aprimorá-lo com aprendizado de máquina! Vamos reviver esse antigo projeto neste artigo e adicionar aprendizado de máquina com uma tabela Q. Passo a passo.

Criando um Painel de Administração de Trading em MQL5 (Parte VIII): Painel de Análises
Hoje, aprofundamos a incorporação de métricas de trading úteis dentro de uma janela especializada integrada ao EA do Painel de Administração. Esta discussão foca na implementação em MQL5 para desenvolver um Painel de Análises e destaca o valor dos dados que ele fornece aos administradores de trading. O impacto é amplamente educacional, pois lições valiosas são extraídas do processo de desenvolvimento, beneficiando tanto desenvolvedores iniciantes quanto experientes. Este recurso demonstra as oportunidades ilimitadas que esta série de desenvolvimento oferece ao equipar gestores de operações com ferramentas avançadas de software. Além disso, exploraremos a implementação das classes PieChart e ChartCanvas como parte da expansão contínua das capacidades do painel de Administração de Trading.

Negociando com o Calendário Econômico do MQL5 (Parte 5): Aprimorando o Painel com Controles Responsivos e Botões de Filtro
Neste artigo, criamos botões para filtros de pares de moedas, níveis de importância, filtros de tempo e uma opção de cancelamento para melhorar o controle do painel. Esses botões são programados para responder dinamicamente às ações do usuário, permitindo uma interação contínua. Também automatizamos seu comportamento para refletir mudanças em tempo real no painel. Isso aprimora a funcionalidade geral, a mobilidade e a responsividade do painel.

Ondas triangulares e em forma de serra: ferramentas para o trader
Um dos métodos de análise técnica é a análise de ondas. Neste artigo, vamos examinar ondas de um tipo um pouco incomum, nomeadamente as triangulares e as em forma de serra. Com base nessas ondas, é possível construir vários indicadores técnicos que permitem analisar o movimento do preço no mercado.

Redes neurais em trading: Detecção adaptativa de anomalias de mercado (Conclusão)
Continuamos a construção dos algoritmos que formam a base do DADA, um framework avançado para detecção de anomalias em séries temporais. Essa abordagem permite distinguir, de maneira eficiente, as flutuações aleatórias dos desvios realmente significativos. Ao contrário dos métodos clássicos, o DADA se adapta dinamicamente a diferentes tipos de dados, selecionando o nível ideal de compressão para cada caso específico.

Desenvolvimento do Conjunto de Ferramentas de Análise de Price Action – Parte (4): Analytics Forecaster EA
Estamos indo além de simplesmente visualizar métricas analisadas nos gráficos, ampliando a perspectiva para incluir a integração com o Telegram. Essa melhoria permite que resultados importantes sejam entregues diretamente ao seu dispositivo móvel por meio do aplicativo Telegram. Junte-se a nós enquanto exploramos essa jornada neste artigo.

Redes neurais em trading: Detecção Adaptativa de Anomalias de Mercado (DADA)
Apresentamos o DADA, um framework inovador para identificação de anomalias em séries temporais. Ele ajuda a distinguir oscilações aleatórias de desvios suspeitos. Ao contrário dos métodos tradicionais, o DADA se ajusta de maneira flexível a diferentes conjuntos de dados. Em vez de usar um nível fixo de compressão, ele testa vários níveis e escolhe o mais adequado para cada situação.

Aplicação da teoria dos jogos em algoritmos de trading
Criamos um Expert Advisor adaptativo e autodidata, baseado em aprendizado de máquina DQN com inferência causal multidimensional. Ele negociará com sucesso simultaneamente em sete pares de moedas, enquanto os agentes de diferentes pares trocarão informações entre si.

Arbitragem de swap no Forex: Montando uma carteira sintética e criando um fluxo estável de swaps
Quer saber como lucrar com a diferença entre taxas de juros? Neste artigo, veremos como usar a arbitragem de swap no Forex para obter uma renda estável todas as noites, criando uma carteira resistente às oscilações do mercado.

Arbitragem no Forex: Um bot market maker simples de sintéticos para começar
Hoje vamos analisar meu primeiro robô na área de arbitragem, que é um provedor de liquidez (se é que podemos chamá-lo assim) em ativos sintéticos. Atualmente, esse bot funciona com sucesso como um módulo dentro de um grande sistema baseado em aprendizado de máquina, mas eu resgatei o antigo robô de arbitragem no Forex da nuvem, então vamos olhar para ele e pensar no que podemos fazer com ele hoje.

Visualização de estratégias em MQL5: distribuindo os resultados da otimização em gráficos de critérios
Neste artigo, escreveremos um exemplo de visualização do processo de otimização e exibiremos os três melhores passes para quatro critérios de otimização. Além disso, implementaremos a possibilidade de selecionar um dos três melhores passes para exibir seus dados em tabelas e no gráfico.

Redes neurais em trading: Dupla clusterização de séries temporais (Conclusão)
Damos continuidade à implementação dos métodos propostos pelos autores do framework DUET, que apresenta uma abordagem inovadora para a análise de séries temporais, combinando clusterização temporal e de canais para revelar padrões ocultos nos dados analisados.

Redes neurais no trading: Dupla clusterização de séries temporais (DUET)
O framework DUET propõe uma abordagem inovadora para a análise de séries temporais, combinando clusterização temporal e de canais para identificar padrões ocultos nos dados analisados. Isso permite adaptar os modelos às mudanças ao longo do tempo e aumentar a precisão das previsões por meio da eliminação de ruídos.
Negociando com o Calendário Econômico MQL5 (Parte 4): Implementando Atualizações de Notícias em Tempo Real no Painel
Este artigo aprimora nosso painel do Calendário Econômico implementando atualizações de notícias em tempo real para manter as informações de mercado atuais e acionáveis. Integramos técnicas de busca de dados ao vivo no MQL5 para atualizar os eventos no painel continuamente, melhorando a capacidade de resposta da interface. Essa atualização garante que possamos acessar as últimas notícias econômicas diretamente do painel, otimizando as decisões de negociação com base nos dados mais recentes.

Negociando com o Calendário Econômico do MQL5 (Parte 3): Adicionando Filtros de Moeda, Importância e Tempo
Neste artigo, implementamos filtros no painel do Calendário Econômico do MQL5 para refinar a exibição dos eventos de notícias por moeda, importância e tempo. Primeiro, estabelecemos critérios de filtro para cada categoria e depois os integramos ao painel para exibir apenas os eventos relevantes. Por fim, garantimos que cada filtro seja atualizado dinamicamente para fornecer aos traders insights econômicos focados e em tempo real.

Criando um painel de administração de trading em MQL5 (Parte VII): Usuário confiável, recuperação e criptografia
Alertas de segurança, como aqueles que aparecem sempre que o gráfico é atualizado, uma nova par é adicionada ao chat do painel administrativo do EA ou o terminal é reiniciado, podem se tornar cansativos. Nesta discussão, vamos analisar e implementar uma função que rastreia o número de tentativas de login para identificar um usuário confiável. Após um determinado número de tentativas malsucedidas, o aplicativo passará para um procedimento avançado de login, que também facilita a recuperação de senha para usuários que possam tê-la esquecido. Além disso, veremos como é possível integrar de forma eficiente a criptografia no painel administrativo para aumentar a segurança.