
Construindo Expert Advisors Auto-Otimizáveis em MQL5 (Parte 4): Dimensionamento Dinâmico de Posição

Computadores eletrônicos e digitais existem desde a década de 1950, mas os mercados financeiros existem há séculos. Traders humanos historicamente tiveram sucesso sem ferramentas computacionais avançadas, o que representa um desafio no design de softwares modernos de trading. Devemos aproveitar todo o poder computacional ou nos alinhar aos princípios bem-sucedidos do trading humano? Este artigo defende o equilíbrio entre simplicidade e tecnologia moderna. Apesar das ferramentas avançadas disponíveis hoje, muitos traders tiveram sucesso em sistemas descentralizados complexos sem softwares de alto desempenho como a API MQL5.
A maioria dos processos de tomada de decisão do dia a dia que utilizamos como humanos pode ser difícil de transmitir de forma significativa a um computador. Por exemplo, ao operar, é comum ouvir alguém comentar: “Eu estava muito confiante na minha decisão, então aumentei o tamanho do lote”. Como podemos instruir nossas aplicações de trading a fazer o mesmo e aumentar o tamanho da posição se ela “se sentir” confiante em relação à operação?
Espero que seja imediatamente óbvio ao leitor que não é possível atingir esse objetivo sem introduzir complexidade no sistema para medir o quão “confiante” o computador “se sente”. Uma abordagem é construir modelos probabilísticos para quantificar a “confiança” de uma operação. Neste artigo, construiremos um modelo simples de regressão logística para medir a confiança de nossas operações, permitindo que nossa aplicação escale as posições de forma independente.
Vamos nos concentrar na estratégia de Bandas de Bollinger, conforme originalmente proposta por John Bollinger. Nosso objetivo é refinar essa estratégia, abordando suas limitações sem perder a essência da ideia.
Nossa aplicação de trading terá como objetivo:
- Abrir uma operação adicional com um tamanho de lote maior se o modelo estiver confiante na operação
- Abrir uma única operação com um tamanho de lote menor se o modelo estiver menos confiante
A estratégia original de trading proposta por John Bollinger realizou 493 operações em nosso back-test da estratégia. De todas as operações realizadas, 62% foram lucrativas. Embora essa seja uma proporção saudável de operações vencedoras, não foi suficiente para produzir uma estratégia de trading lucrativa. Perdemos -$813 ao longo do período do back-test e produzimos um índice de Sharpe de -0,33. Nossa versão refinada do algoritmo realizou 495 operações no total, com 63% de todas as operações sendo lucrativas. Nosso lucro total ao final do back-test aumentou drasticamente para $2 427 no mesmo período de tempo e nosso índice de Sharpe se estabeleceu em 0,74.
O objetivo deste artigo não é diminuir o poder de ferramentas computacionais avançadas, como DNNs ou algoritmos de aprendizado por reforço. Pelo contrário, estou profundamente entusiasmado com as possibilidades que essas tecnologias trazem. No entanto, é importante reconhecer que complexidade por si só não necessariamente leva a melhores resultados.
Compreendo os desafios que acompanham ser um novo membro de uma comunidade de trading algorítmico. Já estive nessa posição, cheio de ambição, mas sem saber como começar. É fácil se sentir sobrecarregado pela vasta quantidade de ferramentas, técnicas e opções disponíveis ao seu alcance.
Este artigo tem como objetivo fornecer um roteiro para aqueles que estão apenas começando. Ao começar de forma simples, você pode construir a confiança necessária para enfrentar problemas mais complexos por conta própria, com uma compreensão mais profunda de sua aplicação. Obtivemos os resultados publicados neste artigo preservando as regras originais e simples de trading sugeridas por John Bollinger e complementando-as com complexidade para emular o processo de tomada de decisão humano, em vez de introduzir complexidade por si só.
Visão Geral da Estratégia de Trading

Fig 1: Uma imagem da nossa Estratégia de Bandas de Bollinger em ação
Nossa estratégia de trading é baseada em seguir os sinais de trading propostos por John Bollinger. As regras originais da estratégia são satisfeitas se vendermos sempre que os níveis de preço rompem a Banda de Bollinger superior, e compraremos se os níveis de preço caírem abaixo da banda inferior.
De modo geral, podemos estender essas regras para que também sirvam como nossas condições de saída. Ou seja, sempre que os níveis de preço aparecerem acima da banda superior, fecharemos quaisquer operações de compra que possam estar abertas, além de abrir nossas operações de venda. Esse conjunto de regras é suficiente para criar um sistema autogerenciado que sabe quando abrir e fechar suas posições por conta própria.
Testaremos nossa estratégia de trading no par GBPUSD de 1º de janeiro de 2022 até 30 de dezembro de 2024 no período gráfico M15.
Introdução ao MQL5
Para dar início no MQL5, começamos definindo constantes do sistema, como o par a ser negociado, o tamanho do lote a ser utilizado e outras constantes que não queremos que o usuário altere.
//+------------------------------------------------------------------+ //| GBPUSD BB Breakout Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define BB_SHIFT 0 // Our bollinger band should not be shifted #define SYMBOL "GBPUSD" // The intended pair for our trading system #define BB_PRICE PRICE_CLOSE // The price our bollinger band should work on #define LOT 0.1 // Our intended lot size
A partir daí, vamos carregar a biblioteca de trade.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Alguns aspectos da estratégia de trading podem ser controlados pelo usuário final, como o período gráfico que devemos usar para os cálculos dos indicadores técnicos e o período do indicador Bandas de Bollinger.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Technical Indicators" input ENUM_TIMEFRAMES TF = PERIOD_M15; // Intended time frame input int BB_PERIOD = 30; // The period for our bollinger bands input double BB_SD = 2.0; // The standard deviation for our bollinger bands
Também precisaremos definir variáveis globais usadas ao longo de todo o nosso programa.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int bb_handler; double bb_u[],bb_m[],bb_l[]; //+------------------------------------------------------------------+ //| System variables | //+------------------------------------------------------------------+ int state; double o,h,l,c,bid,ask;
Quando nossa aplicação de trading for carregada pela primeira vez, chamaremos nossa função de inicialização.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our system if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Se nossa aplicação não estiver mais em uso, liberaremos os indicadores técnicos que não estivermos utilizando.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release resources we no longer need release(); }
Ao receber informações de preço atualizadas, precisamos armazenar os novos dados de preço e processá-los para tomar uma decisão de trading.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update our system variables update(); } //+------------------------------------------------------------------+
Esta função é responsável por configurar nosso indicador técnico.
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Setup our technical indicators and other variables | //+------------------------------------------------------------------+ bool setup(void) { //--- Setup our system bb_handler = iBands(SYMBOL,TF,BB_PERIOD,BB_SHIFT,BB_SD,BB_PRICE); state = 0; //--- Validate our system has been setup correctly if((bb_handler != INVALID_HANDLE) && (Symbol() == SYMBOL)) return(true); //--- Something went wrong! return(false); }
Se não estivermos mais utilizando nossa aplicação de trading, liberaremos a memória que estava associada ao indicador técnico selecionado.
//+------------------------------------------------------------------+ //| Release the resources we no longer need | //+------------------------------------------------------------------+ void release(void) { //--- Free up system resources for our end user IndicatorRelease(bb_handler); }
Quando recebermos informações de preço atualizadas do mercado, atualizaremos nossas variáveis globais e, em seguida, verificaremos se existem configurações válidas de trade caso não tenhamos posições abertas.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime timestamp; datetime current_time = iTime(Symbol(),PERIOD_CURRENT,0); if(timestamp != current_time) { timestamp = current_time; //--- Update our system CopyBuffer(bb_handler,0,1,1,bb_m); CopyBuffer(bb_handler,1,1,1,bb_u); CopyBuffer(bb_handler,2,1,1,bb_l); Comment("U: ",bb_u[0],"\nM: ",bb_m[0],"\nL: ",bb_l[0]); //--- Market prices o = iOpen(SYMBOL,PERIOD_CURRENT,1); c = iClose(SYMBOL,PERIOD_CURRENT,1); h = iHigh(SYMBOL,PERIOD_CURRENT,1); l = iLow(SYMBOL,PERIOD_CURRENT,1); bid = SymbolInfoDouble(SYMBOL,SYMBOL_BID); ask = SymbolInfoDouble(SYMBOL,SYMBOL_ASK); //--- Should we reset our system state? if(PositionsTotal() == 0) { state = 0; find_setup(); } if(PositionsTotal() == 1) { manage_setup(); } } }
Nossas regras para encontrar entradas de trade são as regras originais propostas por John Bollinger.
//+------------------------------------------------------------------+ //| Find an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Check if we have breached the bollinger bands if(c > bb_u[0]) { Trade.Sell(LOT,SYMBOL,bid); state = -1; return; } if(c < bb_l[0]) { Trade.Buy(LOT,SYMBOL,ask); state = 1; } }
Como afirmamos anteriormente, as regras fornecidas por John Bollinger também podem ser usadas para criar regras de saída que definem perfeitamente quando fechar uma posição.
//+------------------------------------------------------------------+ //| Manage our open trades | //+------------------------------------------------------------------+ void manage_setup(void) { if(((c < bb_l[0]) && (state == -1))||((c > bb_u[0]) && (state == 1))) Trade.PositionClose(SYMBOL); } //+------------------------------------------------------------------+
Começaremos selecionando inicialmente o período gráfico pretendido como M15. Esses períodos gráficos de baixo nível são excelentes para estratégias de scalping como a nossa, que buscam aproveitar padrões formados diariamente nos mercados financeiros. Nosso símbolo de escolha é o par GBPUSD, e realizaremos nosso teste de 1º de janeiro de 2022 até 30 de dezembro de 2024.

Fig 2: Selecionando o período gráfico para o nosso back-test
Agora iremos ajustar com mais precisão os parâmetros do nosso teste. Selecionar “Atraso aleatório” permitirá verificar o quão confiável é nosso sistema de trading quando as condições de mercado são instáveis. Além disso, selecionei “Cada tick com base em ticks reais”, pois isso nos fornece a simulação mais realista dos dados históricos de mercado. Nesse modo de modelagem, o Terminal MetaTrader 5 buscará todos os ticks em tempo real que foram enviados pelo corretor naquele dia. Esse processo pode ser demorado, dependendo da velocidade da sua internet. No entanto, ao final, é provável que produza resultados próximos da realidade.
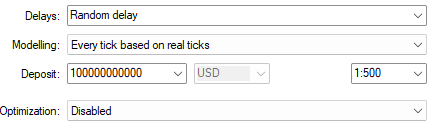
Fig 3: Selecionando as condições de back-test para o nosso teste
Por fim, definiremos as configurações que controlarão o comportamento da nossa aplicação. Observe que, em nosso segundo teste, as configurações que selecionamos na Fig 4 serão mantidas constantes utilizando nossas variáveis de sistema. Portanto, não daremos à segunda versão da nossa aplicação uma vantagem injusta em relação a esta versão atual que estamos prestes a testar.
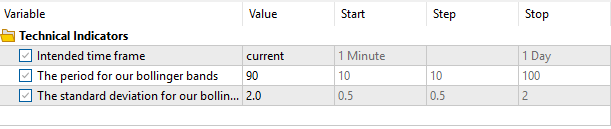
Fig 4: Os parâmetros de entrada para o nosso expert advisor durante este back-test único
A curva de lucro produzida pelo nosso algoritmo atual é inerentemente instável. Ela passa de forma imprevisível por períodos de crescimento rápido e perdas excessivas. A versão atual da nossa estratégia de trading passou a maior parte do tempo se recuperando de períodos de drawdown, em vez de acumular lucros e ocasionalmente sofrer perdas. Isso está longe do ideal. Ao final do nosso teste, nosso algoritmo conseguiu apenas perder nosso capital. É evidente que ainda há muito trabalho a ser feito antes que possamos sequer considerar utilizar esse algoritmo.

Fig 5: A curva de equity produzida pela versão atual da estratégia de trading original
Ao analisarmos de perto os resultados do nosso back-test, observamos que nosso sistema teve uma proporção saudável de operações vencedoras: 63% de todas as operações realizadas foram lucrativas. O problema é que nossos lucros tinham quase metade do tamanho das nossas perdas. Como não desejamos alterar as regras originais de trading, nosso novo objetivo é direcionar o crescimento do nosso lucro médio para mais perto do seu máximo, garantindo ao mesmo tempo que nossas operações perdedoras cresçam a uma taxa menor. Esse delicado equilíbrio nos proporcionará os resultados que desejamos.

Fig 6: Uma análise detalhada dos resultados produzidos pela versão original da estratégia de trading
Melhorando Nossos Resultados Iniciais
Como podemos ver, os resultados iniciais não são muito encorajadores. No entanto, sabemos que o trader humano que inventou as Bandas de Bollinger e propôs essas regras de trading era ele próprio um trader bem-sucedido por qualquer medida. Então, onde está a lacuna entre as regras criadas por John Bollinger e os resultados que obtivemos ao seguir essas regras de forma algorítmica?

Fig 7: O inventor das Bandas de Bollinger, John Bollinger
Parte da diferença pode estar na aplicação humana dessas regras. É provável que, ao longo do tempo, Bollinger tenha desenvolvido uma intuição sobre as condições de mercado nas quais sua estratégia prospera e aquelas nas quais tende a falhar. Nossa aplicação atual arrisca constantemente a mesma quantia em cada trade e trata todas as oportunidades de trading de forma igual. No entanto, os seres humanos podem usar seu discernimento para arriscar mais ou menos, dependendo de suas expectativas aprendidas e níveis de confiança em relação ao futuro.
Traders humanos procuram assumir risco quando acreditam que é mais provável que ele compense; eles não seguem rigidamente um determinado conjunto de regras. Queremos dar ao nosso computador um nível adicional de flexibilidade, além da estratégia original. Alcançar esse objetivo pode, esperamos, explicar a lacuna entre os resultados que esperávamos e aqueles que produzimos até agora. Portanto, introduziremos complexidade para tentar aproximar nossa máquina do que profissionais humanos fazem diariamente, em vez de simplesmente tentar prever diretamente os níveis futuros de preço.
Podemos construir um modelo de regressão logística para dar à nossa aplicação uma noção de “confiança”. Os parâmetros do nosso modelo serão otimizados usando dados históricos de mercado que iremos buscar a partir do nosso terminal MetaTrader 5. Nossa implementação nativa em MQL5 significa que nosso Expert Advisor pode funcionar em qualquer período gráfico, desde que haja dados suficientes nesse período.
Um modelo de regressão logística é possivelmente o modelo mais simples que podemos construir hoje. Existem muitas formas de modelos logísticos, no entanto, a forma que abordaremos hoje só pode ser usada para modelar 2 classes. Leitores que desejam classificar mais de 2 classes devem considerar a leitura de mais literatura sobre modelos logísticos.
Para implementar as mudanças desejadas e aproximar o processo de tomada de decisão da nossa aplicação ao processo de tomada de decisão humano, implementaremos algumas mudanças importantes na versão atual do sistema de trading:
| Mudança Proposta | Finalidade Pretendida |
|---|---|
| Constantes Adicionais do Sistema | Precisaremos criar novas constantes de sistema para acomodar o modelo probabilístico que queremos construir e todas as outras novas partes do sistema de que precisaremos. |
| Análise Técnica Suplementar | Utilizar 2 estratégias ao mesmo tempo pode desbloquear maiores níveis de lucratividade para o nosso sistema. Também buscaremos confirmação do oscilador estocástico antes de abrir nossos trades, para aumentar as probabilidades de obter operações lucrativas. |
| Novas Entradas do Usuário | Para permitir que o usuário controle as novas partes do nosso sistema, precisamos criar novas entradas de usuário que controlem a nova funcionalidade que estamos implementando. |
| Modificação de Funções Personalizadas | As funções personalizadas que construímos até agora precisam ser revisadas e estendidas para acomodar todas as novas variáveis e tarefas que nossa aplicação deverá executar |
Primeiros Passos
Para começar a construir nossa versão revisada da aplicação de trading, precisaremos primeiro criar novas constantes de sistema para manter nossos testes consistentes em todas as versões propostas do algoritmo.
//+------------------------------------------------------------------+ //| GBPUSD BB Breakout Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define BB_SHIFT 0 // Our bollinger band should not be shifted #define SYMBOL "GBPUSD" // The intended pair for our trading system #define BB_PRICE PRICE_CLOSE // The price our bollinger band should work on #define BB_PERIOD 90 // The period for our bollinger bands #define BB_SD 2.0 // The standard deviation for our bollinger bands #define LOT 0.1 // Our intended lot size #define TF PERIOD_M15 // Our intended time frame #define ATR_MULTIPLE 20 // ATR Multiple #define ATR_PERIOD 14 // ATR Period #define K_PERIOD 12 // Stochastic K period #define D_PERIOD 20 // Stochastic D period #define STO_SMOOTHING 12 // Stochastic smoothing #define LOGISTIC_MODEL_PARAMS 5 // Total inputs to our logistic model
Além disso, queremos que o usuário controle a funcionalidade do nosso modelo de regressão logística. A entrada “fetch” determina quanta informação deve ser usada para construir nosso modelo. Observe que, de modo geral, quanto maior o período gráfico que o usuário deseja utilizar, menos dados teremos. Por outro lado, “look_ahead” determina o quão distante no futuro nosso modelo deve tentar prever.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int fetch = 5; // How many historical bars of data should we fetch? input int look_ahead = 10; // How far ahead into the future should we forecast?
Além disso, precisaremos de novas variáveis globais em nossa aplicação. Essas variáveis servirão como manipuladores para nossos novos indicadores técnicos, bem como para as partes móveis do nosso modelo de regressão logística.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int bb_handler,atr_handler,stoch_handler; double bb_u[],bb_m[],bb_l[],atr[],stoch[]; double logistic_prediction; double learning_rate = 5E-3; vector open_price = vector::Zeros(fetch); vector open_price_old = vector::Zeros(fetch); vector close_price = vector::Zeros(fetch); vector close_price_old = vector::Zeros(fetch); vector high_price = vector::Zeros(fetch); vector high_price_old = vector::Zeros(fetch); vector low_price = vector::Zeros(fetch); vector low_price_old = vector::Zeros(fetch); vector target = vector::Zeros(fetch); vector coef = vector::Zeros(LOGISTIC_MODEL_PARAMS); double max_forecast = 0; double min_forecast = 0; double baseline_forecast = 0;
A maioria das outras partes do nosso sistema de trading permanecerá a mesma, exceto por algumas funções que precisam ser estendidas e novas funções que precisamos definir. A primeira da lista a ser editada é nossa função de inicialização. Temos etapas adicionais a executar antes de estarmos prontos para começar a operar. Precisaremos configurar o ATR e o modelo estocástico e, adicionalmente, devemos definir a função “setup_logistic_model()”.
//+------------------------------------------------------------------+ //| Setup our technical indicators and other variables | //+------------------------------------------------------------------+ bool setup(void) { //--- Setup our system bb_handler = iBands(SYMBOL,TF,BB_PERIOD,BB_SHIFT,BB_SD,BB_PRICE); atr_handler = iATR(SYMBOL,TF,ATR_PERIOD); stoch_handler = iStochastic(SYMBOL,TF,K_PERIOD,D_PERIOD,STO_SMOOTHING,MODE_EMA,STO_LOWHIGH); state = 0; higher_state = 0; setup_logistic_model(); //--- Validate our system has been setup correctly if((bb_handler != INVALID_HANDLE) && (Symbol() == SYMBOL)) return(true); //--- Something went wrong! return(false); }
Nosso modelo de regressão logística recebe um conjunto de entradas e prevê uma probabilidade entre zero e um de que a variável alvo pertença à classe padrão, dado o valor atual de x. O modelo utiliza uma função sigmoide, representada na Fig 8 abaixo, para calcular essas probabilidades.
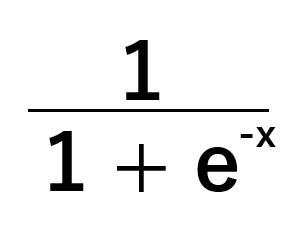
Imagine que estamos interessados em resolver o seguinte problema: “Dado o peso e a altura de uma pessoa, qual é a probabilidade de ela ser do sexo masculino?”. Neste exemplo, ser do sexo masculino é a classe padrão. Probabilidades acima de 0,5 implicam que se acredita que a pessoa seja do sexo masculino, e probabilidades abaixo de 0,5 implicam que o gênero assumido seja feminino. Esta é a versão mais simples possível do modelo logístico. Existem versões do modelo logístico que podem classificar mais de 2 alvos, mas não as consideraremos hoje.
A função sigmoide generalizada na Fig 8 acima transformará qualquer valor de x e nos fornecerá um valor de saída entre 0 e 1, conforme ilustrado na Fig 9 abaixo.
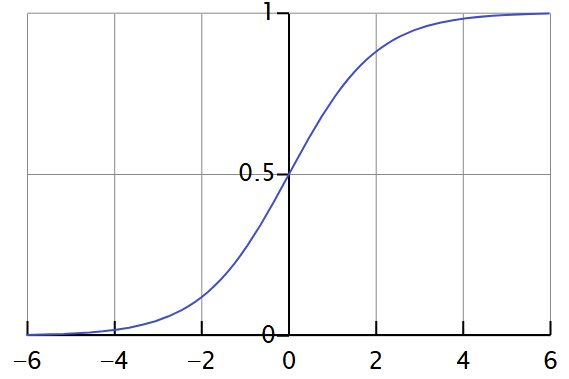
Fig 9: Visualizando a transformação de uma função sigmoide
Podemos calibrar cuidadosamente nossa função sigmoide para que ela produza estimativas próximas de 1 para todas as observações em nossos dados de treinamento que pertencem à classe 1 e, da mesma forma, estimativas próximas de 0 para todos os valores em nossos dados de treinamento que pertencem à classe 0. Esse algoritmo é conhecido como estimativa de máxima verossimilhança. Podemos aproximar esses resultados usando um algoritmo muito mais simples conhecido como descida do gradiente.
No código fornecido abaixo, começamos primeiro preparando nossos dados de entrada. Encontramos a variação do preço de abertura, máxima, mínima e fechamento; estes serão nossos inputs para o modelo. Em seguida, registramos a variação futura associada do preço. Se os níveis de preço caírem, registraremos isso como classe 0. A classe 0 é a nossa classe padrão. Previsões acima do nosso ponto de corte implicam que nosso modelo espera que os níveis futuros de preço caiam. Da mesma forma, previsões abaixo do ponto de corte implicam que a classe padrão não é verdadeira ou, no nosso caso, que o modelo espera que os níveis de preço subam. Normalmente, um ponto de corte de 0,5 é o preferido.
Após rotular nossos dados, inicializamos todos os coeficientes do modelo em 0 e, em seguida, prosseguimos para fazer a primeira previsão com esses coeficientes inadequados. A cada previsão, corrigimos os coeficientes usando a diferença entre nossa previsão e o rótulo verdadeiro. Esse processo é repetido para cada barra que buscamos.
Por fim, mencionei anteriormente que um ponto de corte de 0,5 é classicamente preferido. No entanto, os mercados financeiros não são conhecidos por serem ambientes bem comportados. A abordagem clássica não produziu probabilidades úteis para nós como traders, então estendi o algoritmo clássico e o calibrei ainda mais.
Incluí uma etapa adicional para calcular um ponto de corte ideal, registrando primeiro as probabilidades máximas e mínimas previstas pelo nosso modelo. Em seguida, dividimos ao meio o intervalo real das previsões fornecidas pelo modelo para encontrar nosso ponto de corte. Considerando que o mercado financeiro pode ser ruidoso, pode ser desafiador para nossos modelos aprenderem de forma eficaz, e talvez precisemos ser criativos e encontrar novas formas de interpretar nossos modelos. Esse ponto de corte dinâmico ajudará nosso modelo a tomar decisões de forma independente do nosso viés inerente.

Fig 10: Visualizando como definimos dinamicamente nosso ponto de corte
Portanto, no nosso caso, probabilidades acima do nosso ponto de corte dinâmico serão interpretadas como a classe padrão, o que significa que nosso modelo acredita que devemos “vender”. E o oposto é verdadeiro para previsões que ficam abaixo do nosso ponto de corte dinâmico.
//+------------------------------------------------------------------+ //| Setup our logistic regression model | //+------------------------------------------------------------------+ void setup_logistic_model(void) { open_price.CopyRates(SYMBOL,TF,COPY_RATES_OPEN,(fetch + look_ahead),fetch); open_price_old.CopyRates(SYMBOL,TF,COPY_RATES_OPEN,(fetch + (look_ahead * 2)),fetch); high_price.CopyRates(SYMBOL,TF,COPY_RATES_HIGH,(fetch + look_ahead),fetch); high_price_old.CopyRates(SYMBOL,TF,COPY_RATES_HIGH,(fetch + (look_ahead * 2)),fetch); low_price.CopyRates(SYMBOL,TF,COPY_RATES_LOW,(fetch + look_ahead),fetch); low_price_old.CopyRates(SYMBOL,TF,COPY_RATES_LOW,(fetch + (look_ahead * 2)),fetch); close_price.CopyRates(SYMBOL,TF,COPY_RATES_CLOSE,(fetch + look_ahead),fetch); close_price_old.CopyRates(SYMBOL,TF,COPY_RATES_CLOSE,(fetch + (look_ahead * 2)),fetch); open_price = open_price - open_price_old; high_price = high_price - high_price_old; low_price = low_price - low_price_old; close_price = close_price - close_price_old; CopyBuffer(atr_handler,0,0,fetch,atr); for(int i = (fetch + look_ahead); i > look_ahead; i--) { if(iClose(SYMBOL,TF,i) > iClose(SYMBOL,TF,i - look_ahead)) target[i-look_ahead-1] = 0; if(iClose(SYMBOL,TF,i) < iClose(SYMBOL,TF,i - look_ahead)) target[i-look_ahead-1] = 1; } //Fitting our coefficients coef[0] = 0; coef[1] = 0; coef[2] = 0; coef[3] = 0; coef[4] = 0; for(int i =0; i < fetch; i++) { double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_price[i]) + (coef[2] * high_price[i]) + (coef[3] * low_price[i]) + (coef[4] * close_price[i])))); coef[0] = coef[0] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * 1.0; coef[1] = coef[1] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * open_price[i]; coef[2] = coef[2] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * high_price[i]; coef[3] = coef[3] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * low_price[i]; coef[4] = coef[4] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * close_price[i]; } for(int i =0; i < fetch; i++) { double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_price[i]) + (coef[2] * high_price[i]) + (coef[3] * low_price[i]) + (coef[4] * close_price[i])))); if(i == 0) { max_forecast = prediction; min_forecast = prediction; } max_forecast = (prediction > max_forecast) ? (prediction) : max_forecast; min_forecast = (prediction < min_forecast) ? (prediction) : min_forecast; } baseline_forecast = ((max_forecast + min_forecast) / 2); Print(coef); Print("Baseline: ",baseline_forecast); }
Se não estivermos utilizando nosso Expert Advisor, há alguns indicadores técnicos adicionais que precisamos liberar.
//+------------------------------------------------------------------+ //| Release the resources we no longer need | //+------------------------------------------------------------------+ void release(void) { //--- Free up system resources for our end user IndicatorRelease(bb_handler); IndicatorRelease(atr_handler); IndicatorRelease(stoch_handler); }
Nossas condições para configurar posições permanecem praticamente as mesmas, exceto que, se as previsões do nosso modelo estiverem alinhadas com as regras de trading propostas por John Bollinger, iremos reforçar essa oportunidade e instruir nossa aplicação a assumir mais risco apenas nessas condições.
//+------------------------------------------------------------------+ //| Find an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { double open_input = iOpen(SYMBOL,TF,0) - iOpen(SYMBOL,TF,look_ahead); double close_input = iClose(SYMBOL,TF,0) - iClose(SYMBOL,TF,look_ahead); double high_input = iHigh(SYMBOL,TF,0) - iHigh(SYMBOL,TF,look_ahead); double low_input = iLow(SYMBOL,TF,0) - iLow(SYMBOL,TF,look_ahead); double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_input) + (coef[2] * high_input) + (coef[3] * low_input) + (coef[4] * close_input)))); Print("Odds: ",prediction - baseline_forecast); //--- Check if we have breached the bollinger bands if((c > bb_u[0]) && (stoch[0] < 50)) { Trade.Sell(LOT,SYMBOL,bid); state = -1; if(((prediction - baseline_forecast) > 0)) { Trade.Sell((LOT * 2),SYMBOL,bid); Trade.Sell((LOT * 2),SYMBOL,bid); state = -1; } return; } if((c < bb_l[0]) && (stoch[0] > 50)) { Trade.Buy(LOT,SYMBOL,ask); state = 1; if(((prediction - baseline_forecast) < 0)) { Trade.Buy((LOT * 2),SYMBOL,ask); Trade.Buy((LOT * 2),SYMBOL,ask); state = 1; } return; } }
Além disso, queremos ter um stop loss que acompanhe o preço se nosso trade estiver ganhando e, caso contrário, permaneça fixo. Isso garantirá que reduzamos nosso risco quando estivermos ganhando, algo inteligente que traders humanos fazem o tempo todo.
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_setup(void) { if(((c < bb_l[0]) && (state == -1))||((c > bb_u[0]) && (state == 1))) Trade.PositionClose(SYMBOL); //--- Update the stop loss for(int i = PositionsTotal() -1; i >= 0; i--) { string symbol = PositionGetSymbol(i); if(_Symbol == symbol) { double position_size = PositionGetDouble(POSITION_VOLUME); double risk_factor = 1; if(position_size == (LOT * 2)) risk_factor = 2; double atr_stop = atr[0] * ATR_MULTIPLE * risk_factor; ulong ticket = PositionGetInteger(POSITION_TICKET); double position_price = PositionGetDouble(POSITION_PRICE_OPEN); long type = PositionGetInteger(POSITION_TYPE); double current_take_profit = PositionGetDouble(POSITION_TP); double current_stop_loss = PositionGetDouble(POSITION_SL); if(type == POSITION_TYPE_BUY) { double atr_stop_loss = (bid - (atr_stop)); double atr_take_profit = (bid + (atr_stop)); if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,current_take_profit); } } else+ if(type == POSITION_TYPE_SELL) { double atr_stop_loss = (ask + (atr_stop)); double atr_take_profit = (ask - (atr_stop)); if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,current_take_profit); } } } } } //+------------------------------------------------------------------+
As configurações que controlam a duração e o período gráfico do back-test serão mantidas as mesmas; a única variável que devemos alterar aqui é o Expert selecionado. Selecionamos a versão revisada da aplicação que acabamos de refatorar juntos na seção anterior deste artigo. Certifique-se também de manter suas configurações iguais ao selecionar a nova versão da aplicação.
Fig 11: Selecionando o período gráfico e o intervalo para o nosso segundo back-test a fim de avaliar a eficácia das configurações escolhidas
Como sempre, certifique-se de selecionar configurações de alavancagem que correspondam ao seu acordo com o corretor. Especificar incorretamente as configurações de alavancagem pode gerar expectativas irreais sobre a lucratividade das suas aplicações de trading. Para piorar, você pode achar difícil reproduzir os resultados obtidos no back-test, especialmente se as configurações de alavancagem da sua conta real não corresponderem às configurações utilizadas no back-test. Essa é uma fonte de erro comumente negligenciada ao realizar back-tests, portanto, reserve um tempo para isso.
Fig 12: Back-tests são sensíveis às configurações selecionadas ao iniciar o back-test. Certifique-se de acertar na primeira vez
Agora iremos definir quanta informação nossa aplicação de trading deve buscar para estimar os parâmetros do nosso modelo de regressão logística e o horizonte de previsão do modelo. Não tente buscar mais dados do que aqueles que o seu corretor fornece. Caso contrário, a aplicação não funcionará conforme o esperado! Além disso, defina um horizonte de previsão que esteja alinhado com sua tolerância ao risco.
Por exemplo, você pode desejar treinar sua aplicação para olhar 2000 passos à frente no futuro. No entanto, é preciso ter em mente que 2000 passos no período gráfico M15 correspondem a cerca de 20 dias. Se você, como ser humano, não prevê realisticamente tão longe no futuro ao realizar seus trades, então não tente forçar a aplicação a fazê-lo. Lembre-se de que nosso objetivo é construir uma aplicação que emule o que você faz todos os dias como trader humano.

Fig 13: Os parâmetros que controlam o comportamento da nossa aplicação de trading e do nosso modelo de regressão logística
Agora chegamos à parte mais informativa do nosso teste. Nosso novo sistema produziu um lucro médio de $79. Inicialmente, esperávamos um lucro médio de $45. Portanto, a diferença entre nosso lucro esperado atual ($79) e nosso lucro esperado anterior ($45) é de $34. Essa diferença de $34 corresponde a um crescimento de aproximadamente 75% do lucro esperado original.
Simultaneamente, nossa nova perda esperada é de $-122, enquanto nossa perda esperada inicial era de $-81. Isso representa uma diferença de $41 e corresponde a um crescimento de aproximadamente 50% no tamanho da nossa perda média. Portanto, alcançamos com sucesso nosso objetivo!
Nossas novas configurações garantem que nossos lucros cresçam a uma taxa maior do que nossas perdas. Essa também é a razão pela qual conseguimos corrigir com sucesso nosso índice de Sharpe e o retorno esperado. Nossa versão inicial da estratégia de trading acumulou uma perda de $-791, enquanto nosso novo sistema acumulou um lucro de $2 274 sem alterar as regras do algoritmo ou o período do back-test.
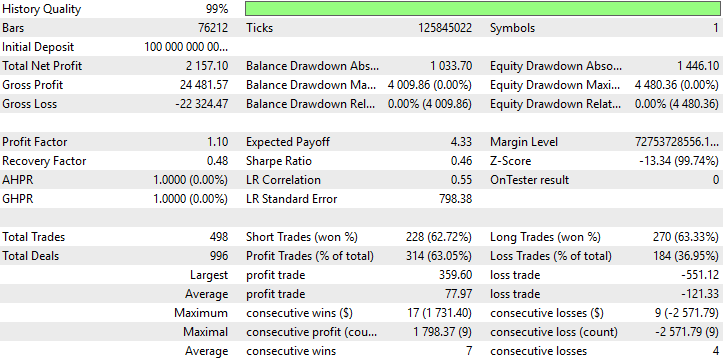
Fig 14: Idealmente, gostaríamos que nossas perdas tivessem uma taxa de crescimento igual a 0, mas o mundo real não é ideal
Quando observamos agora a curva de equity que nosso algoritmo produz, podemos ver claramente que ele é mais estável do que era inicialmente. Todas as estratégias de trading passam por períodos de drawdown. No entanto, estamos interessados na capacidade da estratégia de se recuperar das perdas e, eventualmente, preservar seus lucros. Uma estratégia excessivamente avessa ao risco pode mal gerar lucros e, por outro lado, uma estratégia com forte afinidade ao risco pode rapidamente perder todos os lucros que obtém. Portanto, conseguimos atingir um equilíbrio intermediário.
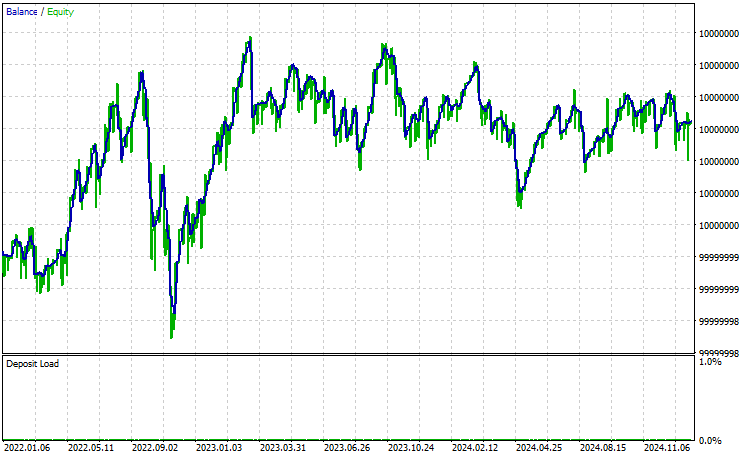
Fig 15: A curva de equity produzida pela nova versão do algoritmo de trading é mais desejável do que nossos resultados iniciais
Conclusão
Controlar a quantidade de risco assumida por nossas aplicações de trading é fundamental para garantir um trading lucrativo e sustentável. Este artigo demonstrou como você pode projetar suas aplicações para aumentar de forma independente o tamanho do lote se a aplicação detectar que o trade tem uma alta chance de ser lucrativo. Caso contrário, se nossa expectativa for de que o trade possa não dar certo, a aplicação assumirá o menor risco possível. Esse dimensionamento dinâmico de posição é crucial para o trading lucrativo, pois garante que estamos aproveitando ao máximo cada oportunidade que temos e gerenciando nossos níveis de risco de forma responsável. Ao construir juntos um modelo logístico probabilístico, aprendemos uma possível maneira de garantir que nossa aplicação esteja selecionando o tamanho de posição ideal, com base no que ela aprendeu sobre o mercado em questão. | Arquivo Anexado | Descrição |
|---|---|
| GBPUSD BB Breakout Benchmark | Esta é a versão inicial da nossa aplicação de trading e não foi lucrativa em nosso primeiro teste. |
| GBPUSD BB Breakout Benchmark V2 | O algoritmo refinado, baseado nas mesmas regras de trading, mas projetado para aumentar de forma inteligente nossos tamanhos de posição se detectar que temos uma boa chance de ganhar. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16925
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Dominando Registros de Log (Parte 4): Salvando logs em arquivos
Dominando Registros de Log (Parte 4): Salvando logs em arquivos
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso