
Redes neurais em trading: Generalização de séries temporais sem vínculo com dados (Conclusão)

Introdução
Os mercados financeiros são um organismo vivo. Seu pulso é ditado por milhões de negociações, centenas de relatórios econômicos e uma sequência contínua de notícias. Nesse ambiente, obtém lucro quem sabe não apenas reagir rapidamente, mas antecipar os pontos de mudança de tendência. Foi exatamente para isso que o Mamba4Cast foi desenvolvido, um framework de previsão de séries temporais inspirado nos avanços mais recentes em arquitetura de redes neurais e adaptado às especificidades de sequências de alta frequência.
Chegamos à fase final de familiarização com esse framework. Inicialmente, analisamos a estrutura teórica e o esquema geral de processamento de características. Na segunda parte, aprofundamo-nos na mecânica. Agora, vamos reunir tudo para mostrar que o modelo não apenas existe no papel, mas também funciona em um ambiente real de mercado.
O próprio framework é organizado como uma cadeia de módulos, cada um executando sua função especializada. O primeiro bloco é responsável pela extração de características. Aqui, o modelo percebe dados brutos, como preço de abertura, fechamento, high/low e volumes. Todos eles passam por uma camada compacta que destaca padrões locais. Pode-se dizer que é como o olhar treinado de um trader, que percebe padrões no caos do gráfico.
Em seguida, entra em ação a etapa das camadas convolucionais. Esses blocos funcionam como filtros de mercado, extraindo sinais estáveis e reduzindo o ruído. Picos de volatilidade, tendências em enfraquecimento, fases de consolidação em formação, tudo isso é capturado e processado. Neste caso, utiliza-se uma arquitetura de múltiplas janelas, em que cada convolução é orientada a horizontes diferentes. Dessa forma, o framework aprende a enxergar simultaneamente tanto as flutuações imediatas quanto ciclos oscilatórios mais longos.
O módulo-chave, SSM (State Space Model), carrega consigo a capacidade de memória de longo prazo. Isso é especialmente importante em dados financeiros, onde os padrões muitas vezes não se manifestam de forma instantânea, mas em horizontes de dezenas de candles. Por exemplo, uma série de falsos rompimentos pode terminar em um impulso poderoso, e o modelo precisa estar preparado para esse cenário. É justamente SSM que permite não perder o contexto e manter uma previsão fundamentada mesmo em condições de incerteza de mercado.
Um valor especial do Mamba4Cast está no mecanismo de previsão para todo o horizonte de planejamento. Isso corresponde às tarefas reais dos traders. Uma abordagem desse tipo pode ser comparada ao trabalho de um motorista: ele observa o que está logo à frente das rodas, mas também mantém o olhar ao longe, interpretando a dinâmica do fluxo. Esse modo híbrido oferece uma política de comportamento mais estável e abrangente.
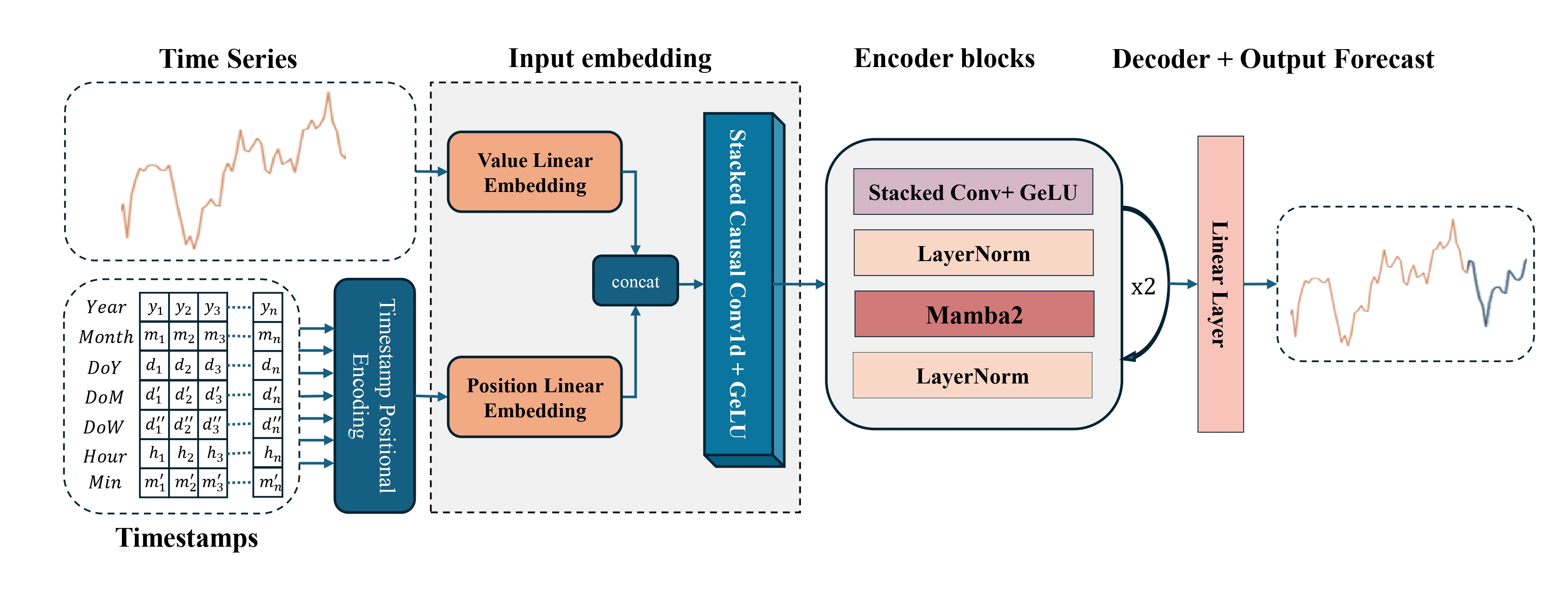
Neste artigo, você verá a forma final do modelo, sua arquitetura, os processos de treinamento e os resultados reais. Mostraremos como teoria e prática se conectam, como um modelo abstrato se transforma em uma ferramenta funcional de análise de mercado.
Arquitetura dos modelos
Hoje iniciaremos o trabalho com a construção da arquitetura do modelo treinável, um Agente de trading completo, capaz de tomar decisões e executar operações em tempo real. Assim como um trader que analisa atentamente a situação atual do mercado, avalia o comportamento do preço, os volumes, o sentimento do mercado e só então decide entrar em uma posição, nosso Agente também deve saber ver e compreender o mercado, e não seguir sinais cegamente. Por isso, não nos limitamos à tarefa de prever apenas o próximo preço; nosso objetivo é mais profundo: criar um modelo que seja capaz de reconhecer padrões de comportamento do mercado, reagir a condições que mudam rapidamente e se adaptar a diferentes fases do ciclo de mercado.
Nesse contexto, o framework Mamba4Cast é implementado como um dos elementos-chave do sistema geral, que é o Codificador do estado do ambiente. É exatamente aqui que começa a formação da percepção de mercado do modelo, transformando um conjunto de números em uma imagem significativa do que está acontecendo. Codificador se tornará uma espécie de olho de tradingAgente, treinado para reconhecer movimentos relevantes, padrões ocultos e potenciais pontos de entrada muito antes de sua confirmação no gráfico.
Neste trabalho, continuamos a seguir o framework de aprendizado Actor-Director-Critic. O sistema que estamos treinando inclui quatro modelos principais, cada um responsável por seu próprio aspecto da tomada de decisão em trading:
- Codificador do ambiente — olhos do agente, forma as incorporações do estado do mercado;
- Ator (Actor) — modelo que propõe ações de trading específicas com base na incorporação recebida;
- Diretor (Director) — modelo que classifica as ações propostas pelo Ator como boas ou ruins, orientando o processo de aprendizado e prevenindo decisões equivocadas;
- Crítico (Critic) — avalia o valor das ações do Ator no contexto do estado do mercado e forma o sinal de retorno para a otimização da estratégia.
A arquitetura de todos os modelos é definida pelo método CreateDescriptions, em cujos parâmetros são passados quatro ponteiros para arrays dinâmicos. É nesses arrays que, de forma sequencial, são gravadas as descrições das camadas e dos parâmetros de cada um dos modelos listados, do Codificador ao Crítico, o que permite controlar a estrutura de forma flexível e adaptar facilmente o framework a novos requisitos.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&actor, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
No corpo do método CreateDescriptions primeiro é verificada a atualidade dos ponteiros recebidos para os quatro arrays dinâmicos. Quando necessário, novos objetos são criados, o que garante a correção da gravação subsequente da descrição da arquitetura sem risco de conflitos de memória.
Em seguida, passamos à descrição da arquitetura do Codificador do estado do ambiente. Como objeto para obtenção dos dados brutos, utiliza-se uma camada totalmente conectada de tamanho suficiente. Nela, transferimos os dados brutos, sem pré-processamento, diretamente do terminal: preços de abertura e fechamento, high/low, volumes, bem como indicadores de indicadores técnicos.
Como esses dados possuem diferentes características estatísticas e escalas, para estabilizar o processo de treinamento do modelo é necessário o alinhamento das distribuições. Aqui entra em cena a camada de normalização em lote. Ela transforma os vetores de entrada de modo que cada característica tenha média próxima de zero e variância em torno de "1", o que contribui para uma convergência mais rápida e aumenta a estabilidade do treinamento. Em vez da implementação clássica, utilizamos uma variante modificada, nomeadamente a camada de normalização com adição de ruído. Essa solução ajuda a melhorar a capacidade de generalização do modelo por meio do aumento artificial da diversidade dos dados de treinamento.
Na saída desse conjunto Codificador recebe características unificadas, prontas para o processamento subsequente.//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, geramos incorporações dos passos temporais com o auxílio do módulo CMamba4CastEmbedding. É exatamente aqui que os vetores de características são enriquecidos com harmônicos de dois intervalos de tempo-chave, expecificamente H1 (horário) e D1 (diário). Com a adição de componentes senoidais e cossenoidais, o modelo passa a receber informações sobre oscilações horárias típicas e ritmos diários recorrentes. Isso permite que o Agente leve em conta ciclos de mercado característicos, aquecimentos matinais, tendências diurnas e fases de calmaria no período da noite.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = BarDescr; int prev_out = descr.window_out = NSkills; { int temp[] = {PeriodSeconds(PERIOD_H1), PeriodSeconds(PERIOD_D1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
O uso de um bloco convolucional multi-janela com três janelas de convolução permitirá tornar as incorporações mais ricas. Ao mesmo tempo, é importante notar que a convolução não é realizada ao longo do eixo temporal, mas horizontalmente, dentro de uma única barra, onde são analisadas as inter-relações entre as características.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.window_out * descr.windows.Size());
Na etapa final da codificação do sinal de entrada, adicionamos uma camada de normalização. Sua tarefa é eliminar distorções nas distribuições das características, tornar os dados analisados mais homogêneos e garantir o funcionamento estável do modelo durante o processo de treinamento. Esse passo ajuda a evitar o deslocamento dos gradientes e acelera a convergência sem perda de qualidade.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, passamos diretamente à construção da arquitetura do codificador. Aqui planejamos trabalhar no contexto de sequências temporais unitárias de características individuais. Por isso, realizamos previamente a transposição do nosso tensor de características.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; prev_out = descr.count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Vale observar que, neste ponto, já não lidamos mais com aquelas características que foram inicialmente recebidas do terminal. Nesta etapa, formaram-se características enriquecidas completamente diferentes, cada uma das quais representa um determinado recorte da descrição da barra anteriormente obtida a partir do terminal.
O bloco do codificador Mamba4Cast consiste em uma pilha de convoluções e o módulo SSM. Entre os módulos, é prevista uma camada de normalização para alinhar as características. Na pilha convolucional, aplicamos módulos de convolução multi-janela. Aqui, cada filtro se concentra em sua própria janela temporal e destaca os padrões de mercado correspondentes. Com o objetivo de preservar a dimensionalidade dos dados, após cada módulo de convolução multi-janela é utilizada uma camada de maxpooling, que seleciona o valor máximo do filtro em cada janela, reduzindo assim as dimensões espaciais sem alterar a profundidade das características.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; int filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
No SSM, substituímos o núcleo Mamba2 original do framework Mamba4Cast pelo módulo Chimera, permitindo considerar dependências cruzadas entre componentes temporais e espaciais.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronChimera; //--- Window { int temp[] = {prev_out, prev_out/2}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units { int temp[] = {prev_count, prev_count*2}; //In, Out if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.windows[1]; prev_count=descr.units[1]; //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
E o módulo é finalizado com uma camada de normalização em lote. Já discutimos anteriormente as vantagens dessa abordagem.
Na arquitetura do nosso codificador, estão previstos 2 blocos sequenciais, cada um consistindo em uma pilha convolucional multi-janela, uma camada de maxpooling e um módulo SSM Chimera, garantindo o enriquecimento gradual das características e a preservação do contexto.
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronChimera; //--- Window { int temp[] = {prev_out, prev_out/2}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units { int temp[] = {prev_count, prev_count*2}; //In, Out if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.windows[1]; prev_count=descr.units[1]; //--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Como decodificador para a previsão independente de sequências temporais unitárias, ao longo de todo o horizonte de planejamento utilizamos duas camadas convolucionais sequenciais. Entre elas, é aplicado SoftPlus, que fornece a não linearidade necessária. Na saída do decodificador, utiliza-se a tangente hiperbólica (tanh), pois seu intervalo de valores corresponde à escala dos dados normalizados, o que permite manter a consistência entre a entrada e a saída do modelo.
//--- layer 20 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = 4 * NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 21 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
No entanto, vale lembrar que, para a transição ao trabalho no modo de sequências temporais unitárias, realizamos previamente a transposição do tensor das características analisadas. Portanto, antes de encaminhar os resultados do decodificador adiante, é necessário restaurar sua forma original por meio da transposição inversa.
//--- layer 22 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; prev_out = descr.count; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
O próximo passo na restauração da estrutura dos dados é a redução da dimensionalidade, que foi aumentada durante o processo de formação das incorporações. Isso é necessário para trazer o tensor de resultados a uma forma compatível com os dados originais.
//--- layer 23 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = BarDescr; descr.layers = 1; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
A etapa final do funcionamento do codificador do estado da conta é a operação de normalização inversa. Nesse passo, os valores obtidos após todas as transformações retornam às escalas dos dados originais, o que permite interpretar corretamente o resultado do funcionamento do modelo.
//--- layer 24 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, passamos à descrição da arquitetura Ator. Sua principal tarefa é realizar a avaliação do estado atual da conta e das posições abertas no contexto do estado analisado do ambiente de mercado. Com base nas informações obtidas, o Ator forma uma decisão de trading, uma operação que potencialmente seja capaz de garantir a máxima rentabilidade com riscos mínimos.
Nesse contexto, é fornecido ao Ator um tensor que representa o estado atual da conta. Esse tensor contém informações agregadas sobre o saldo, os volumes das posições abertas, a direção das negociações e outros parâmetros-chave que refletem o estado financeiro do agente de trading.
CLayerDescription *latent = encoder.At(LatentLayer-1); //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os dados obtidos são processados por meio de uma camada de normalização em lote, que estabiliza a distribuição das características e acelera o processo de treinamento do modelo.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, é aplicada uma camada de atenção cruzada, que permite correlacionar o estado atual da conta com a situação do mercado. Nesse caso, como contexto, utiliza-se a representação latente do ambiente, previamente formada pelo Codificador.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {AccountDescr, // Inputs window latent.windows[1] // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {1, // Inputs units latent.units[1] // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.layers = 2; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
No âmbito deste experimento, utilizamos uma pilha composta por dois módulos de atenção cruzada dispostos sequencialmente. Essa configuração permite correlacionar de forma mais profunda o estado interno da conta com a dinâmica do ambiente de mercado, reforçando a capacidade do modelo de identificar relações de causa e efeito entre a posição atual e as condições externas.
É importante compreender que, para a camada de atenção cruzada, utilizamos como contexto não uma representação geral do estado atual do ambiente, mas a representação latente do Codificador, formada após o processamento do sinal original na forma de incorporações de sequências unitárias individuais de características. Em termos mais simples, o codificador, o bloco dentro do modelo do Codificador do estado do ambiente, traduz cada característica em seu próprio vetor compacto de sensibilidades, e são exatamente esses vetores que entram no módulo de atenção cruzada como contexto.
Imagine que o módulo de atenção cruzada seja um maestro. Ele possui as melodias de cada instrumento (incorporações das características) e a partitura do saldo atual da conta. O maestro determina quais instrumentos devem soar mais alto naquele momento, isto é, quais características são mais importantes para a tomada de decisão, e destaca justamente essas.
Graças a isso, o mecanismo de atenção cruzada correlaciona padrões ocultos do mercado com a posição atual e seleciona os sinais que ajudarão a tomar uma decisão de trading eficaz.
Os resultados da análise contextual passam por três camadas totalmente conectadas (MLP), cada uma das quais refina sequencialmente a representação da ação-alvo. Na saída da última camada, forma-se a decisão de trading, uma proposta concreta de abertura, manutenção ou fechamento de posição, levando em conta o estado atual da conta e a conjuntura de mercado.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os modelos Diretor e Crítico possuem arquitetura semelhante: eles analisam o tensor de ações propostas pelo Ator no contexto da situação atual do mercado. Na saída desses modelos, forma-se a avaliação correspondente, que consiste na aprovação ou rejeição da ação proposta do ponto de vista da estratégia e do risco.
A implementação detalhada das arquiteturas desses componentes proponho deixar para estudo independente. O código-fonte completo da descrição da arquitetura de todos os modelos treináveis, incluindo Diretor e Crítico, é apresentado no anexo.
Treinamento dos modelos
Após a familiarização com a arquitetura dos modelos, passamos diretamente à etapa de seu treinamento. Aqui é importante destacar que os autores do framework Mamba4Cast utilizaram séries temporais sintéticas para o teste e o treinamento de seus modelos. Essa decisão possui uma série de vantagens, especialmente no contexto do desenvolvimento e da depuração de arquiteturas de aprendizado profundo.
Em primeiro lugar, sintética oferece controle total sobre os parâmetros dos dados: é possível definir previamente amplitude, frequência, tendências, sazonalidade, nível de ruído e até incluir eventos raros ou anômalos. Isso permite verificar de forma pontual como o modelo reage a diferentes características das séries temporais e identificar seus pontos fracos em um ambiente rigorosamente controlado.
Em segundo lugar, séries geradas artificialmente eliminam a influência de dados sujos ou incompletos, o que é especialmente importante nas fases iniciais de treinamento. Diferentemente dos dados reais de mercado, a sintética não contém lacunas, artefatos de coleta ou distorções que possam mascarar erros reais do modelo.
A terceira vantagem é escalabilidade. A geração de dados sintéticos não exige custos com coleta e armazenamento de dados históricos e permite criar rapidamente conjuntos de treinamento do volume necessário para resolver tarefas de qualquer complexidade. Isso é especialmente relevante ao utilizar modelos que consomem muitos recursos, nos quais é necessário um ambiente de treinamento rico e equilibrado.
E, por fim, a sintética é uma ferramenta confiável para testes de estresse. Podemos modelar situações extremas de mercado sem precisar esperar que elas ocorram na vida real. Esses cenários permitem verificar a robustez do modelo diante de oscilações inesperadas.
Por outro lado, o mercado real não é um laboratório estéril, mas sim um mar agitado, onde as regras muitas vezes são escritas em tempo real. Justamente por isso, apesar de todas as vantagens dos dados sintéticos, treinar e validar o modelo exclusivamente com sintética é um caminho unilateral e potencialmente perigoso.
Em primeiro lugar, nos dados reais de mercado sempre estão presentes ruídos, lacunas, correlações não evidentes e trechos sujos, que não existem em um ambiente artificialmente criado. Um modelo que não foi treinado com essas particularidades pode se perder já no primeiro contato com a realidade, especialmente em ativos de baixa liquidez ou em períodos de alta volatilidade.
Em segundo lugar, o mercado está sujeito ao efeito surpresa: notícias, sanções, fusões, geopolítica, comportamento de grandes players, tudo isso influencia os preços, mas é praticamente impossível de ser modelado de forma confiável de maneira sintética. E aqui é especialmente importante que o modelo saiba se adaptar e trabalhar em condições de informação incompleta.
Em terceiro lugar, os padrões comportamentais dos participantes do mercado, do medo à ganância, criam uma dinâmica única, difícil de ser reproduzida por geradores. Um modelo que nunca tenha visto esses padrões corre o risco de se sobreajustar a um ambiente limpo e não reconhecer sinais importantes no trading real.
Por isso, a abordagem mais eficaz é considerada híbrida: a sintética é utilizada nas etapas iniciais, para calibrar a arquitetura, selecionar hiperparâmetros e depurar o treinamento. Em seguida, entram os dados reais, para ensinar o modelo a "viver em campo", aprender a errar, se adaptar e tomar decisões em um ambiente instável.
Hoje não temos à disposição um gerador completo de sequências financeiras sintéticas. No entanto, como diz o ditado, se a montanha não vai a Maomé…
Para a primeira etapa de treinamento, tentaremos aproximar as propriedades da sintética por meio do pré-processamento de dados históricos reais. Como já foi mencionado anteriormente, séries sintéticas normalmente não contêm artefatos, lacunas nem outro ruído de mercado. Para alcançar uma limpeza semelhante nos dados reais, aplicaremos uma média móvel simples com uma janela curta para cada uma das características analisadas. Isso permitirá:
- suavizar anomalias locais e picos bruscos,
- neutralizar a influência de valores atípicos isolados,
- aumentar a estabilidade do modelo na etapa de treinamento.
É importante ressaltar que escolhemos conscientemente uma janela de suavização pequena, para preservar a dinâmica e a forma do sinal. Nosso objetivo não é nivelar tudo até uma linha plana, mas apenas atenuar o ruído que pode induzir o modelo ao erro. Uma lógica semelhante será implementada no EA "…\MQL5\Experts\Mamba4Cast\StudyMA.mq5". No contexto deste artigo, consideraremos apenas o método Train, no qual está implementado o processo de treinamento dos modelos.
O algoritmo do método começa com a criação de um vetor de distribuição de probabilidades para a escolha de trajetórias individuais a partir do buffer de reprodução de experiência.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
Na etapa inicial, todas as trajetórias recebem probabilidades iguais, o que permite garantir um estudo mais completo de todo o histórico.
Em seguida, inicializamos variáveis locais que serão utilizadas para o armazenamento temporário de dados durante o processo de treinamento dos modelos.
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); matrix<float> hstate = matrix<float>::Zeros(1, HistoryBars * BarDescr); bool Stop = false; int average = 5; //--- uint ticks = GetTickCount();
Após a conclusão do trabalho preparatório, passamos à criação do sistema de laços de treinamento dos modelos. O laço externo é responsável por controlar o número total de iterações de treinamento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if( !cEncoder.Clear() || !cActor.Clear() || !cDirector.Clear() || !cCritic.Clear() ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } result = vector<float>::Zeros(NActions);
Aqui, realizamos a amostragem de uma trajetória do buffer de reprodução de experiência e do estado inicial do pacote de treinamento. Ao mesmo tempo, redefinimos o estado interno de todos os modelos, excluindo a influência de memória não relevante sobre os dados da nova trajetória. Depois disso, inicializamos o laço interno de treinamento dos modelos dentro do pacote.
for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!hstate.Assign(Buffer[tr].States[i].state) || MathAbs(hstate).Sum() == 0 || !hstate.Reshape(HistoryBars, BarDescr)) { iter -= Batch + start - i; break; }
No corpo do laço interno, carregamos do buffer de reprodução de experiência os dados históricos da descrição do estado do ambiente analisado e organizamos um laço para seu suavizamento por meio de média móvel.
for(int h = HistoryBars - 1; h > 0; h--) { state = vector<float>::Zeros(BarDescr); for(int a = MathMax(h - average + 1, 0); a <= h; a++) state += hstate.Row(a); if(!hstate.Row(state / MathMin(average, h + 1), h)) { iter -= Batch + start - i; break; } }
Os valores suavizados são transferidos para o buffer de dados da descrição do estado do ambiente analisado.
if(!hstate.Reshape(1, HistoryBars * BarDescr) || !bState.AssignArray(hstate.Row(0))) { iter -= Batch + start - i; break; }
Em seguida, é importante lembrar que, para o funcionamento correto do framework Mamba4Cast, precisamos das marcações temporais de cada barra. No entanto, na estrutura do buffer de reprodução de experiência que criamos anteriormente, é armazenada apenas uma marcação temporal para cada estado do ambiente, correspondente à última barra. Com o objetivo de criar o buffer necessário de marcações temporais, realizamos um percurso reverso pelos estados do ambiente no buffer de reprodução de experiência, a partir do estado atual até a profundidade de análise definida, coletando as marcações temporais.
bTime.Clear(); bTime.Reserve(HistoryBars); double time = (double)Buffer[tr].States[i].account[7]; for(int t = i; t >= MathMax(0, i - HistoryBars + 1); t--) if(!bTime.Add((float)(double)Buffer[tr].States[t].account[7])) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(bTime.Total() < HistoryBars) { float period = MathMin(Buffer[tr].States[i + 1].account[7] - Buffer[tr].States[i].account[7], Buffer[tr].States[i + 2].account[7] - Buffer[tr].States[i + 1].account[7]); do { if(!bTime.Add(bTime[-1] - period)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } } while(bTime.Total() < HistoryBars); } if(bTime.GetIndex() >= 0) if(!bTime.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
O algoritmo de preenchimento do buffer de descrição do estado da conta será transferido de programas análogos sem modificações.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; float profit = float(bState[0] / _Point * (result[0] - result[3])); bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Após a preparação dos dados brutos necessários, passamos à execução da propagação para frente de todos os modelos. O primeiro a realizar a propagação para frente é o Codificador do estado do ambiente. Em seu funcionamento, ele utiliza os dados suavizados da descrição do estado do mercado e o buffer de marcações temporais.
//--- Feed Forward if(!cEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, entra em ação o Ator. Ele analisa o buffer do estado da conta e o contexto do ambiente a partir do estado latente do Codificador.
if(!cActor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
O Codificador do estado do ambiente é treinado para prever estados subsequentes. É fundamental compreender que não geramos o alvo manualmente nem aplicamos média móvel, como é feito na etapa de preparação dos dados brutos. Em vez disso, simplesmente carregamos o estado do ambiente já existente no buffer de reprodução de experiência, com um deslocamento para frente correspondente ao horizonte de planejamento.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; } for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
E, após a formação dos valores-alvo, podemos realizar o ajuste dos parâmetros do Codificador, chamando o método de propagação reversa.
//--- State Encoder Result.AssignArray(fstate); if(!cEncoder.backProp(Result, (CBufferFloat*)NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, com base nos dados factuais disponíveis sobre o movimento futuro do preço, podemos formar uma decisão de trading "quase ideal".
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(pos > 0 && tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } } else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(pos > 0 && tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } else { ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); float max_sl = float(MaxSL * Point()); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] / 2 > MathAbs(target[argmin]) && MathAbs(target[argmin]) < max_sl) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin] / 2) && target[argmax] < max_sl) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); } if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(pos > 0 && tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } } else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(pos > 0 && tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } } } }
Vale ressaltar que essa decisão de trading é formada levando em conta a operação realizada no passo anterior. O Agente não trabalha com sinais isolados vácuo, mas constrói uma cadeia de ações. E cada decisão subsequente se apoia na operação já executada. Graças a essa abordagem, obtemos não um conjunto de ordens desconexas, mas uma estratégia completa, na qual cada decisão decorre logicamente da anterior. São exatamente essas quase ideais operações de trading que utilizamos para o treinamento do Ator.
//--- Actor Policy bActions.GetData(result); if(!cActor.backProp(GetPointer(bActions), (CNet*)GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Essas mesmas operações de trading também são utilizadas para o treinamento do Crítico. O objetivo é tornar a função de avaliação das ações o mais próxima possível da política real do Ator. Fornecemos ao Crítico a mesma quase ideal sequência de operações e definimos a recompensa com base na variação do preço no próximo barra.
//--- Critic if(!cCritic.feedForward(GetPointer(bActions), 1, false, (CNet*)GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } float reward = float((bActions[0] - bActions[3]) * fstate[0, 0] / Point()); Result.Clear(); if(!Result.Add(reward) || !cCritic.backProp(Result, (CNet*)GetPointer(cEncoder), LatentLayer) || !cEncoder.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer, true) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dessa forma, o Crítico aprende a fornecer uma avaliação adequada das ações do Ator, baseando-se na mudança real do preço, e ajuda a construir uma estratégia mais precisa e estável.
De forma um pouco diferente ocorre o treinamento do Diretor. Não é possível alimentar-lo apenas com casos positivos, caso contrário ele nunca aprenderá a distinguir ações ruins das boas. Por isso, a cada passo escolhemos aleatoriamente como será o exemplo de treinamento:
- Positivo. Alimentamos a entrada com a ação quase ideal que acabamos de calcular com base nos dados factuais e atribuímos o rótulo "1" (sucesso).
- Negativo. Formamos um vetor de valores aleatórios com a mesma dimensionalidade do espaço de ações e atribuímos o rótulo "0" (falha).
Após isso, chamamos os métodos de propagação para frente e propagação reversa do Diretor.
//--- Director Result.Clear(); if((MathRand() / 32767.0) > 0.5) Result.Add(1); else { target = vector<float>::Zeros(NActions); for(int i = 0; i < NActions; i++) target[i] = float(MathRand() / 32767.0); bActions.AssignArray(target); Result.Add(0); } if(!cDirector.feedForward(GetPointer(bActions), 1, false, (CNet*)GetPointer(cEncoder), LatentLayer) || !cDirector.backProp(Result, (CNet*)GetPointer(cEncoder), LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Essa abordagem garante que o Diretor aprenda não apenas a incentivar boas decisões, mas também a reconhecer os trapos das decisões ruins, ajudando o Ator a evitar ações ineficientes.
Agora, resta-nos informar o usuário sobre o andamento do treinamento e passar para a próxima iteração do sistema de laços.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Encoder", percent, cEncoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, cActor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Director", percent, cDirector.getRecentAverageError()); str += StringFormat("%-16s %6.2f%% -> Error %15.8f\n", "Critic", percent, cCritic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão do processo de treinamento dos modelos, exibimos no log os resultados obtidos e inicializamos o encerramento do funcionamento do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", cEncoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", cActor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Director", cDirector.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", cCritic.getRecentAverageError()); ExpertRemove(); //--- }
Nos programas de treinamento offline e online dos modelos com dados históricos reais, foram feitas apenas alterações pontuais no contexto da criação do buffer de marcações temporais. Não iremos nos deter agora em seu estudo detalhado. O código completo está apresentado no anexo, e você pode analisá-lo de forma independente. No mesmo local, também são apresentados os programas de interação com o ambiente.
O treinamento do nosso sistema é estruturado em três etapas, cada uma das quais prepara gradualmente o modelo para as condições reais do mercado.
Primeiro, realizamos o treinamento offline inicial com dados históricos reais, utilizando o método de suavização descrito acima. Essa etapa é executada sem atualização da amostra de treinamento. A camada de normalização em lote com adição de ruído utilizada por nós no Codificador do estado do ambiente permitirá criar uma augmentação suficiente dos dados originais e ampliará significativamente a amostra de treinamento na representação do modelo.
Imagine que cada candle e cada indicador passam por um filtro de leve deformação, isso cria múltiplas variações de uma mesma situação e impede que o modelo memorize apenas os mesmos padrões. Como resultado, o Codificador aprende a enxergar a essência do movimento, apesar das menores distorções.
Na segunda offline-etapa, são utilizados dados históricos sem suavização: o modelo conhece o verdadeiro rosto do mercado, com picos bruscos, quedas e flutuações ruidosas. Essa transição de um mercado idealizado para dados brutos ajuda o Agente a adaptar-se às oscilações reais, manter a estabilidade das previsões e não se assustar com anomalias repentinas. Monitoramos atentamente a dinâmica do erro de previsão e interrompemos o treinamento assim que a métrica permanece em um intervalo estreito por várias passagens, o que é sinal de que o modelo se familiarizou com os dados.
Finalmente, na terceira etapa, o agente entra no testador de estratégias para online-treinamento. Aqui observamos o comportamento da curva de saldo. Se, depois de várias passagens consecutivas, o saldo fica estagnado e não mostra o crescimento esperado, retornamos cuidadosamente ao offline-treinamento: ajustamos a política do Ator seguindo a trajetória quase ideal e reiniciamos o refinamento.
Esse processo por etapas garante simultaneamente alta precisão das previsões e robustez das decisões de trading em qualquer condição de mercado.
Teste
Realizamos um enorme trabalho de adaptação e implementação das abordagens propostas pelos autores do framework Mamba4Cast. Agora chega o momento da verdade, que consiste em verificar a eficácia do que foi implementado em dados reais.
Como amostra de treinamento, usamos cotações de um minuto do EURUSD durante todo 2024. Para garantir a pureza do experimento, o teste final foi feito com dados históricos de janeiro – março de 2025, período que não participou do treinamento. Todos os demais parâmetros permaneceram inalterados, para que a avaliação da estratégia fosse objetiva e justa.
Os resultados dos testes são apresentados abaixo.


É preciso reconhecer que observamos aqui uma frequência bastante alta de operações de trading. O tempo médio de permanência em posição é de pouco mais de 3 minutos. No total, durante o período de teste, o modelo realizou 2677 operações, das quais 1240 terminaram com lucro. Embora o número de posições perdedoras tenha sido um pouco maior, o modelo obteve lucro e vemos um crescimento confiante da linha de saldo. Em parte, isso se explica pela abertura de posições com um stop relativamente curto e seu posterior acompanhamento. Confirma tal suposição a pequena diferença entre a posição média perdedora e a posição máxima perdedora. Ao mesmo tempo, a posição vencedora máxima supera em quase 7 vezes o lucro médio por operação.
Considerações finais
Percorremos todo o caminho, da ideia e arquitetura do framework Mamba4Cast à sua implementação prática, treinamento e teste rigoroso em dados históricos reais. Ensinamos o Codificador a sentir o mercado, e o Ator a tomar decisões levando em conta os riscos. O Diretor a filtrar os melhores e piores sinais. O Crítico a avaliar as ações pelos resultados reais.
O teste no EURUSDM1 de janeiro – março 2025 mostrou que o Mamba4Cast sabe não apenas prever, mas também proteger-se do ruído, adaptar-se a imprevistos e manter a lucratividade a longo prazo.
Entretanto, todos os programas apresentados são demonstrativos e servem para ilustrar as possibilidades do Mamba4Cast. Antes de aplicar as soluções propostas no trading real, é necessário treinar os modelos em uma amostra realmente representativa e realizar testes abrangentes, somente assim será possível garantir a confiabilidade e a segurança da sua estratégia.
Links
- Mamba4Cast: Efficient Zero-Shot Time Series Forecasting with State Space Models
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert | EA coletor de exemplos |
| 2 | ResearchRealORL.mq5 | Expert | EA coletor de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert | EA de treinamento offline dos modelos |
| 4 | StudyMA.mq5 | Expert | EA de treinamento offline dos modelos em dados suavizados |
| 5 | StudyOnline.mq5 | Expert | EA de treinamento online dos modelos |
| 6 | Test.mq5 | Expert | EA para teste do modelo |
| 7 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 8 | NeuroNet.mqh | Biblioteca de classe | Biblioteca para criação da rede neural |
| 9 | NeuroNet.cl | Biblioteca | Biblioteca de código de programas em OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18219
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso