
Redes neurais em trading: Otimização de LSTM para fins de previsão de séries temporais multidimensionais (Conclusão)

Introdução
No artigo anterior, nos familiarizamos com os aspectos teóricos do framework DA-CG-LSTM, especialmente desenvolvido para resolver tarefas complexas de previsão de séries temporais dinâmicas e multidimensionais.
Os mercados financeiros modernos representam sistemas dinâmicos complexos, nos quais interagem continuamente diversos fatores: indicadores macroeconômicos, notícias, mudanças nas taxas de juros, comportamento de grandes participantes e muitos outros parâmetros, frequentemente ocultos. As séries temporais que refletem a dinâmica de preços e volumes de negociação tornam-se a principal fonte de informação sobre os processos em curso. No entanto, a análise dessas séries exige que o modelo seja capaz de considerar simultaneamente tanto tendências de longo prazo quanto flutuações de curto prazo, além de conseguir distinguir sinais realmente importantes do ruído de fundo.
Os métodos clássicos de processamento de séries temporais, muitas vezes, mostram-se insuficientemente flexíveis e sensíveis à diversidade de fatores de mercado. Sua capacidade limitada de atenção seletiva a características-chave e intervalos temporais leva à perda de qualidade das previsões em condições de alta variabilidade do mercado. Justamente essas limitações se tornaram o ponto de partida para a criação do framework DA-CG-LSTM, uma arquitetura que combina um mecanismo de atenção dupla e uma estrutura modificada de blocos recorrentes.
Um dos aspectos-chave do DA-CG-LSTM é a flexibilidade no processamento de dados multimodais. Em cenários reais de trading, é importante analisar não apenas níveis de preços, mas também indicadores derivados, assim como eventos econômicos externos. O framework que estamos considerando permite adaptar-se dinamicamente às mudanças na importância das características em cada passo temporal, redistribuindo automaticamente a atenção para as fontes de informação mais significativas. Dessa forma, o modelo é capaz de identificar com eficiência inter-relações complexas entre múltiplas características e ajustar as previsões de acordo com o contexto da situação atual do mercado.
Um valor especial é representado pelo mecanismo de atenção dupla em cascata implementado na arquitetura. No primeiro nível, a atenção do modelo se concentra nas características, isto é, determina-se quais atributos, no momento atual, exercem maior influência sobre a dinâmica do mercado. No segundo nível, a atenção se desloca para os intervalos temporais. O modelo avalia quais trechos do histórico, no momento atual, possuem maior valor para a construção da previsão do movimento mais provável. Esse processo em duas etapas garante uma filtragem profunda da informação, permitindo que o sistema ignore dados secundários e se concentre em sinais realmente significativos, sejam grandes mudanças de tendência ou anomalias locais.
A próxima vantagem importante do DA-CG-LSTM foi a alta resistência a dados ruidosos, o que é criticamente importante para a aplicação em condições reais de mercado. As séries temporais financeiras, via de regra, contêm muitas flutuações aleatórias, causadas não por motivos de mercado, mas por fatores externos ou internos aleatórios. O bloco CG-LSTM modificado dentro do framework atua como um filtro adaptativo, capaz de reduzir dinamicamente a influência de características ruidosas. Graças aos mecanismos internos de controle dos pesos das características e dos passos temporais, o modelo se concentra na identificação de padrões estáveis e recorrentes de comportamento do preço, o que aumenta de forma perceptível a qualidade das previsões.
Outra característica distintiva do DA-CG-LSTM é a capacidade de trabalhar de forma eficiente com séries temporais longas sem perder sensibilidade a mudanças de curto prazo. Em redes recorrentes padrão, o aumento do comprimento da sequência analisada frequentemente leva ao efeito de desaparecimento do gradiente e à redução da qualidade do processamento de dependências distantes. Na arquitetura proposta pelos autores do framework, esse problema é resolvido por meio de uma etapa inicial de filtragem da informação com o uso da atenção primária e de uma organização especial da memória no bloco CG-LSTM. Isso permite manter em foco tanto as tendências de longo prazo quanto reagir rapidamente a flutuações de curta duração, como notícias ou picos intradiários de volatilidade.
Isso permite que o framework DA-CG-LSTM combine com sucesso adaptabilidade a dados multidimensionais, capacidade de filtragem profunda da informação, resistência ao ruído e alta capacidade de aprendizado em longos intervalos temporais. Essas qualidades o tornam uma ferramenta poderosa para a construção de sistemas modernos de previsão de séries temporais.
O algoritmo DA-CG-LSTM é construído com base no processamento sequencial dos dados por meio de vários módulos-chave.
Na primeira etapa, a representação original da série temporal multidimensional passa pelo módulo de atenção primária, que pondera a importância das características individuais em cada passo temporal. Isso permite comprimir e enfatizar a informação analisada até as características mais significativas, livrando o modelo de ruído informacional excessivo.
Na etapa seguinte, os dados são direcionados ao módulo de atenção secundária, no qual o foco se desloca para os intervalos temporais. O modelo avalia quais segmentos do histórico temporal desempenham papel-chave para a formação dos valores de previsão.
Os dados processados são então encaminhados para o bloco CG-LSTM modificado, no qual ocorre a agregação das características levando em conta sua importância interna e interação. O bloco CG-LSTM se diferencia do LSTM clássico por incluir mecanismos adicionais de controle que influenciam o funcionamento das células de memória de acordo com a importância das características e dos intervalos temporais. Isso permite modelar com maior precisão dependências multidimensionais complexas entre os fatores de mercado.
A representação agregada final, formada com o auxílio de dois níveis de atenção e do CG-LSTM, é então utilizada para a previsão da variável alvo, por exemplo, o preço futuro de um ativo ou a direção de sua variação.
Essa arquitetura em múltiplas etapas permite que o modelo considere simultaneamente dependências de curto e de longo prazo, minimize a influência do ruído e altere de forma adaptativa a estratégia de processamento dos dados, dependendo do contexto atual do mercado.
A visualização autoral do framework DA-CG-LSTM é apresentada abaixo.

No presente artigo, daremos o próximo passo na construção de nossa própria visão dos abordagens propostas pelos autores do framework DA-CG-LSTM, utilizando os recursos do MQL5. O foco principal será direcionado ao desenvolvimento da arquitetura de modelos treináveis
Arquitetura dos modelos
Como já observado anteriormente, a base da arquitetura do framework DA-CG-LSTM é composta por dois componentes fundamentais: os módulos de atenção e o bloco recorrente CG-LSTM modificado. Esses elementos formam uma estrutura sólida do modelo, garantindo a ele a flexibilidade necessária, resistência aos ruídos de mercado e a capacidade de capturar dependências temporais complexas em múltiplos níveis. Em condições de alta volatilidade e caoticidade dos mercados financeiros, tais qualidades deixam de ser apenas desejáveis e se tornam criticamente necessárias para a construção de sistemas de trading confiáveis.
Na parte prática do artigo anterior, analisamos em detalhe o processo de criação do bloco CG-LSTM utilizando MQL5. O componente desenvolvido implementa com sucesso três funções fundamentais: a filtragem de características para eliminar ruído excessivo, o gerenciamento eficiente do estado interno do modelo para preservar informações de longo prazo e a agregação de dados em diferentes níveis temporais. A capacidade do bloco de suprimir ruído não estruturado e manter uma dinâmica estável de treinamento permite construir modelos que não perdem a qualidade das previsões em longos intervalos de dados históricos.
Para identificar e analisar as inter-relações entre características e sequências temporais, os autores do DA-CG-LSTM propuseram o uso de uma versão aprimorada do mecanismo de atenção linear. No âmbito do nosso trabalho, decidimos utilizar o objeto CNeuronLinearAttention desenvolvido anteriormente, criado durante o trabalho no framework Hidformer. Embora as características arquiteturais das duas soluções apresentem certas diferenças, o conceito básico permanece comum.
Levando esses fatores em consideração, tomamos a decisão de utilizar o módulo de atenção já pronto, sem a introdução de adaptações adicionais. Isso permitiu acelerar significativamente o processo de desenvolvimento e minimizar os riscos de implementação de soluções novas e insuficientemente testadas. Assim, nesta etapa, dispomos de um conjunto completo de componentes para a construção do framework DA-CG-LSTM.
O próximo passo lógico é o projeto da arquitetura de modelos treináveis com base nos componentes preparados. Aqui fomos além da tarefa clássica de previsão de valores futuros de uma série temporal. Nos mercados financeiros, é importante não apenas saber prever a dinâmica dos preços, mas também utilizar corretamente essas previsões para a tomada de decisões de trading, otimizando o risco e o retorno potencial.
Para alcançar esse objetivo, integramos as melhores ideias da arquitetura HiSSD, que comprovou sua eficácia no combate ao ruído e no processamento de dependências não lineares complexas. A estrutura DA-CG-LSTM foi integrada ao codificador por meio da criação de um espaço latente de habilidades globais e locais dos agentes, que descrevem o estado do ambiente de mercado. Esse espaço serve como base para as etapas subsequentes de análise e tomada de decisão.
Sobre a estrutura básica foi aplicada um sistema de aprendizado por reforço Actor-Director-Critic. Essa integração permite não apenas construir previsões, mas também selecionar estrategicamente ações com o maior benefício esperado.
A arquitetura dos modelos treináveis é formada no método CreateDescriptions. Em seus parâmetros são passados ponteiros para seis objetos de arrays dinâmicos, cada um dos quais reflete um nível separado da arquitetura complexa do modelo:
- Codificador do estado do ambiente — é responsável pela construção do espaço latente de habilidades globais dos agentes. Ele generaliza informações sobre o estado atual do mercado, identificando dependências ocultas entre os fatores analisados que influenciam a dinâmica de mercado.
- Controlador de baixo nível — forma as habilidades locais dos agentes com base nas características analisadas do ambiente. Ao analisá-las no contexto das habilidades globais, o controlador sintetiza um tensor de possíveis ações, que reflete os cenários de trading mais promissores, considerando tendências de mercado de curto e longo prazo.
- Actor — recebe do controlador o tensor de variantes de ações e, ao avaliá-lo no contexto do estado atual da conta, do nível de risco e dos objetivos estratégicos definidos, gera a decisão de trading final, orientada à maximização do lucro com controle das perdas admissíveis.
- Modelo probabilístico de previsão de tendências — contribui para a formação de habilidades globais mais informativas dos agentes, enriquecendo-as com uma representação probabilística da direção do movimento esperado do mercado. Isso permite que o modelo considere a natureza probabilística dos processos de mercado e construa estratégias mais robustas.
- Diretor — realiza a filtragem primária das ações, reduzindo a probabilidade de adoção de decisões com nível de risco deliberadamente elevado. Ele direciona a política de comportamento do Actor para cenários mais conservadores e confiáveis, compatíveis com as condições atuais do mercado.
- Crítico — analisa a eficácia das estratégias escolhidas no horizonte futuro, ajustando o comportamento dos agentes de modo a maximizar, no longo prazo, o lucro total com um nível de risco razoável.
O método CreateDescriptions inclui uma verificação rigorosa da validade dos ponteiros obtidos. Quando necessário, são criadas novas instâncias de objetos descritivos, garantindo a integridade e a correção da arquitetura do modelo em todas as etapas de sua construção.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Comecemos com a descrição da arquitetura do codificador do estado do ambiente. Como objeto de dados de entrada, assim como nos trabalhos anteriores, é utilizada uma camada neural totalmente conectada de dimensionalidade suficiente. Essa camada atua como uma espécie de portal de entrada do modelo, recebendo dados brutos sem qualquer processamento manual prévio.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A fonte de informação são os dados diretos do terminal: cotações de preços, volumes de negociação, indicadores de sentimento de mercado e outros parâmetros importantes. Optamos conscientemente por abdicar da etapa de pré-processamento do lado do programa. Essa estratégia, sem dúvida, torna o processo de treinamento do modelo mais complexo, pois impõe exigências significativamente mais altas quanto à capacidade de autoaprendizado e de filtragem de ruído. No entanto, essa abordagem permite alcançar uma robustez muito maior na fase de aplicação prática.
É importante compreender: o modelo treinado demonstrará resultados confiáveis e reprodutíveis somente se os dados que chegam à sua entrada em condições reais de utilização apresentarem uma distribuição semelhante àquela usada durante o processo de treinamento. O pré-processamento manual dos dados fora do modelo aumenta o risco de desvios imprevisíveis, pois até mesmo a menor alteração em filtros ou parâmetros pode mudar radicalmente a natureza dos dados de entrada. Consequentemente, o processamento interno dos dados torna-se uma parte obrigatória da própria arquitetura do modelo.
Com o objetivo de minimizar riscos e elevar a qualidade do treinamento, integramos a etapa básica de processamento de dados diretamente na estrutura do codificador. Essa função é desempenhada pela camada de normalização em lote com mecanismo de adição de ruído aleatório controlado CNeuronBatchNormWithNoise. A normalização em lote traz dados multimodais heterogêneos para uma escala comum, melhorando a estabilidade do treinamento e acelerando a convergência do modelo. Além disso, uma pequena ampliação por meio de ruído ajuda a aumentar a capacidade de generalização do modelo, reduzindo a probabilidade de sobreajuste em volumes limitados de dados.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados normalizados são encaminhados ao módulo de atenção linear, responsável pela análise das interdependências entre as características individuais dentro de cada passo temporal.
Nesta etapa, atenção especial é dada à interpretação correta da estrutura interna dos dados. Apesar de o modelo processar uma série temporal, em cada passo temporal específico ele lida com o mesmo conjunto fixo de características que descrevem o estado do ambiente.
Considerando a natureza repetitiva da estrutura dos dados em cada recorte temporal, tomamos a decisão de utilizar uma única matriz de parâmetros treináveis para a análise de todos os passos temporais. Em outras palavras, o modelo aplica um mecanismo de atenção comum e universal para toda a série temporal. Isso permite alcançar simultaneamente vários efeitos de importância crítica:
- aumentar a consistência da interpretação das características em diferentes intervalos temporais;
- reduzir de forma significativa a quantidade de parâmetros treináveis, o que é especialmente importante em condições de conjuntos de treinamento limitados;
- melhorar a capacidade de generalização do modelo, minimizando o sobreajuste;
- acelerar o processo de treinamento por meio da otimização dos cálculos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.layers = 1; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Após a análise das interdependências entre as características em cada passo temporal, a próxima etapa importante passa a ser a análise temporal dos dados de entrada. Para a implementação dessa tarefa, inicialmente aplicamos a transposição do tensor original, o que nos permite considerar cada característica individual como uma sequência de observações ao longo do tempo.
O tensor transposto é encaminhado ao segundo módulo de atenção linear, especialmente projetado para a análise da dinâmica temporal dos dados.
Cabe destacar que, após a transposição, passamos a lidar, na prática, com um conjunto de sequências temporais unitárias, cada uma das quais representa a evolução de uma característica específica ao longo do tempo. Essas características podem pertencer a diferentes modalidades de dados. É importante compreender que diferentes modalidades podem demonstrar padrões característicos distintos de reação aos mesmos eventos de mercado. Portanto, nesta etapa, implementamos uma abordagem mais flexível: para cada sequência unitária é utilizada sua própria matriz de parâmetros treináveis. Esse mecanismo permite:
- levar em conta a especificidade de cada modalidade na interpretação de sua dinâmica temporal;
- identificar padrões únicos na reação de diferentes características aos mesmos gatilhos de mercado;
- aumentar a sensibilidade do modelo a sinais fracos, porém importantes, em canais individuais de dados;
- evitar a mistura de informações entre características de natureza não comparável.
Uma arquitetura desse tipo é especialmente eficaz nos mercados financeiros, onde dados de naturezas distintas podem reagir a eventos fundamentais ou técnicos com velocidades, amplitudes e direções diferentes.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; descr.count = 1; descr.window = HistoryBars; descr.layers = BarDescr; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Após a passagem por dois níveis de atenção, os dados analisados adquirem uma estrutura substancialmente mais rica. Eles já incorporam informações tanto sobre as inter-relações internas entre as características quanto sobre as dependências temporais características de cada modalidade. No entanto, para a construção de uma estratégia eficaz de tomada de decisão nos mercados financeiros, é necessário ser capaz de agregar esses dados em uma forma mais compacta e significativa.
Os dados enriquecidos por conexões internas são encaminhados ao bloco CG-LSTM, no qual é realizada a análise independente das sequências unitárias formadas na etapa anterior. Vale ressaltar que essa abordagem difere de forma significativa da concepção original dos autores do framework DA-CG-LSTM. Na arquitetura clássica do DA-CG-LSTM, as células do bloco recorrente processam representações multimodais de passos temporais individuais. Esse método permite considerar dependências intermodais complexas.
No entanto, em nosso projeto, optamos conscientemente por uma estratégia alternativa. Desenvolvemos as ideias incorporadas na arquitetura HiSSD, na qual é dada atenção especial à previsão independente de sequências unitárias relacionadas a agentes individuais. Essa abordagem permite capturar de forma mais flexível e precisa os padrões comportamentais específicos de cada modalidade, minimizando a influência de potenciais ruídos cruzados entre diferentes fontes de dados.
A variante de processamento de dados utilizada no bloco CG-LSTM garante:
- uma especialização mais clara dos estados ocultos para aspectos específicos dos dados;
- maior robustez do modelo a mudanças na estrutura da informação de mercado;
- aumento da interpretabilidade das habilidades globais, pois cada vetor de habilidades está associado a uma modalidade específica dos dados analisados.
No projeto do bloco recorrente, tomamos uma decisão de importância fundamental: o tamanho do estado oculto de cada elemento CG-LSTM foi definido como igual ao tamanho do vetor de habilidades globais de um agente. Isso permite que cada sequência unitária forme uma representação de saída de tamanho fixo, na qual estão codificados os aspectos mais importantes de seu comportamento de longo prazo. Essas representações tornam-se a base para as etapas subsequentes de tomada de decisão no modelo.
É importante enfatizar que a construção da matriz de habilidades globais ocorre em um regime totalmente treinável. O próprio modelo determina quais aspectos do comportamento das características são mais significativos para o funcionamento bem-sucedido em condições reais de trading.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGLSTMOCL; descr.count = NSkills; // Common Skkills descr.window = HistoryBars; // Sequence descr.layers = BarDescr; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Vale lembrar que o planejador de alto nível do framework HiSSD aprende a formar habilidades globais por meio do processo de codificação do estado latente, com o objetivo de prever com a máxima precisão o próximo estado do sistema. De forma semelhante, a principal tarefa do framework DA-CG-LSTM consiste em prever com a maior precisão possível a série temporal multimodal. Toda a sua arquitetura é construída em torno desse objetivo: um sistema complexo de atenção, blocos recorrentes poderosos e um decodificador são direcionados à extração de padrões ocultos e ao aumento da qualidade das previsões.
Entretanto, utilizamos uma abordagem conceitualmente diferente e reorientamos deliberadamente a arquitetura para outra tarefa: o treinamento de um estado latente maximamente informativo, as chamadas habilidades globais dos agentes. Não é tão importante para nós prever com exatidão cada próximo valor da série temporal, mas sim criar uma representação interna do mercado que se torne uma base sólida para o treinamento subsequente da política ótima de comportamento dos agentes.
Nesse contexto, optamos conscientemente por abandonar a arquitetura complexa do decodificador original do DA-CG-LSTM. Seus mecanismos profundos de análise do espaço latente poderiam distorcer ou reinterpretar as habilidades globais, tornando-as menos adequadas para os objetivos de controle dos agentes.
Em vez disso, escolhemos um decodificador minimalista, composto por duas camadas convolucionais sequenciais. Essa construção garante um processamento direto das representações ocultas, mínima interferência na estrutura das habilidades globais, alta interpretabilidade dos resultados e processamento independente das sequências unitárias de características.
Essa abordagem permite preservar a pureza e o valor do espaço latente formado, abrindo caminho para um treinamento mais eficiente da política de comportamento do Actor.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; int prev_out = descr.window_out = 4 * NForecast; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Para o correto alinhamento dos valores previstos com os dados reais, na etapa final do processamento dos resultados do decodificador realizamos a transposição do tensor de saída de volta para a estrutura original dos dados.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
No entanto, mesmo após a restauração da forma, os valores previstos permanecem em formato normalizado. Portanto, o próximo passo importante é a transformação inversa, na qual são adicionados os parâmetros estatísticos da distribuição original das características, previamente registrados na etapa de normalização em lote.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, passamos à análise da arquitetura do controlador de baixo nível. Esse modelo desempenha um papel fundamental na construção de estratégias locais de comportamento dos agentes, com base na análise do estado do ambiente em cada momento específico no tempo.
O controlador recebe como entrada dados brutos do ambiente — de forma análoga ao que ocorre no codificador de habilidades globais. Na base de sua arquitetura encontra-se, essencialmente, a mesma estrutura: normalização primária dos dados com adição de ruído aleatório, processo de análise em duas etapas por meio de módulos de atenção linear, bem como o uso do bloco recorrente CG-LSTM para processamento sequencial.
A diferença fundamental entre habilidades globais e locais não reside no mecanismo de sua construção, mas nas tarefas que os agentes resolvem durante o processo de aprendizado. No caso da formação de habilidades globais, o foco está na criação de um espaço latente generalizado, capaz de integrar dependências de longo prazo e características-chave do mercado. Já as habilidades locais são orientadas à adaptação operacional ao estado atual do mercado e à geração de ações de trading específicas para cada passo temporal individual.
Por isso, simplesmente copiamos a arquitetura do codificador de habilidades.
//--- Task task.Clear(); //--- Task Encoder for(int i = 0; i <= LatentLayer; i++) if(!task.Add(encoder.At(i))) return false;
Após a formação das habilidades locais, o próximo passo consiste em enriquecê-las com a informação contextual das habilidades globais dos agentes. Para resolver essa tarefa, utilizamos um bloco de atenção cruzada de duas camadas.
As habilidades dos agentes atuam no papel de consultas (Query), enquanto as habilidades globais de todos os agentes são utilizadas no papel de chaves (Key) e valores (Value). Um ponto fundamental é que as habilidades locais de cada agente individual não são interpretadas de forma isolada, mas sim no amplo contexto do espaço latente comum de todo o sistema de agentes. Isso permite a tomada de decisões mais equilibradas.
Uma característica da arquitetura do bloco é a organização em duas etapas do mecanismo de cross-attention. Na primeira etapa, é implementado o Cross-Attention. As consultas locais extraem os fragmentos mais relevantes da informação global. Essa operação permite que os agentes adaptem de forma flexível seu comportamento de curto prazo, de acordo com o estado atual do ambiente e com as tendências estratégicas registradas nas habilidades globais.
Na segunda etapa, a integração é reforçada por meio de uma camada adicional de atenção, que possibilita identificar inter-relações mais complexas e profundas entre objetivos de curto prazo e orientações estratégicas de longo prazo.
É justamente graças à integração dos contextos local e global que o modelo adquire a capacidade de gerar decisões de trading mais equilibradas e fundamentadas, aumentando a resistência dos agentes a sinais falsos e a ruídos de mercado de curto prazo.
//--- layer LatentLayer+1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {NSkills, NSkills}; // WIndow if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {BarDescr, BarDescr}; // Units if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; descr.window_out = 32; descr.layers = 2; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!task.Add(descr)) { delete descr; return false; }
As habilidades locais, enriquecidas com o contexto global, são encaminhadas ao bloco de tomada de decisão. Aqui, um papel central é desempenhado pelo uso de duas camadas convolucionais sequenciais. Essa arquitetura permite organizar de forma eficiente o trabalho paralelo de MLP para cada agente individual.
Cada agente interpreta seu próprio espaço latente local e toma decisões sem interferir diretamente no funcionamento de outros agentes. Graças à estrutura convolucional, alcança-se alta eficiência computacional, pois todos os agentes são processados simultaneamente. Ao mesmo tempo, cada um trabalha com sua própria matriz de parâmetros do modelo.
A dupla sequência de camadas convolucionais garante flexibilidade adicional à arquitetura, o primeiro nível é responsável pela agregação e transformação primária das características, enquanto o segundo nível refina as representações locais e forma o tensor final de ações. Essa abordagem permite alcançar maior adaptabilidade e estabilidade do comportamento dos agentes em condições de alta volatilidade dos mercados financeiros.
//--- layer LatentLayer+2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; prev_out = descr.window_out = 4 * NActions; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!task.Add(descr)) { delete descr; return false; } //--- layer LatentLayer+3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NActions; descr.layers = prev_count; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
As arquiteturas dos modelos do Actor, do Diretor e do Crítico de nível superior foram integralmente transferidas do trabalho anterior. Sua descrição detalhada pode ser encontrada no link e não nos deteremos nelas agora. A descrição completa da arquitetura de todos os modelos é apresentada no anexo.
Treinamento
O processo de treinamento dos modelos é organizado em três etapas: formação do conjunto de treinamento, treinamento offline de todos os componentes do modelo e posterior ajuste fino em modo online. Essa abordagem combina a robustez fundamental obtida a partir de dados históricos com a adaptação flexível às condições atuais do mercado.
Todos os programas utilizados no processo de treinamento foram transferidos sem alterações do trabalho anterior, portanto não nos deteremos em uma análise detalhada de seus algoritmos. Repetiremos apenas os princípios básicos do processo.
O treinamento dos modelos começa com a formação do conjunto de treinamento. Para esse fim, é utilizado o EA Research.mq5, que é executado no testador de estratégias do MetaTrader5 para a coleta de dados históricos do par de moedas EURUSD, utilizando o timeframe de um minuto ao longo de todo o ano de 2024. Para minimizar a carga, cada execução é limitada a um mês de histórico, e a diversidade do comportamento dos agentes é alcançada por meio de políticas aleatórias. Após o fechamento de cada candle, são registrados os estados do mercado, os valores dos indicadores, as características da conta e as ações dos agentes, formando trajetórias completas para o buffer de replay de experiência.
Os dados coletados tornam-se a base para o treinamento offline de todos os componentes, que é realizado com o auxílio do EA Study.mq5. A partir do buffer, trajetórias e pontos iniciais são selecionados aleatoriamente para a formação de pacotes de treinamento de estados sequenciais. Para acelerar a convergência, é aplicada a metodologia de trajetória quase ideal, que permite ao codificador prever vários passos à frente. Nessa etapa são treinados os codificadores de habilidades, o Actor, o Diretor e o Crítico, formando a política básica de comportamento do agente.
Após a conclusão do treinamento offline, passamos para a etapa de ajuste fino em modo de tempo real. Aqui é utilizado o EA StudyOnline.mq5. A principal atenção é dedicada ao treinamento do Actor sob o controle do Diretor e do Crítico. Após o fechamento de cada novo candle, é realizada a análise do estado do ambiente, a atualização das avaliações das ações e o ajuste dos parâmetros dos modelos. A atualização suave periódica dos modelos-alvo ajuda a manter o equilíbrio entre estabilidade e adaptabilidade da estratégia.
Essa abordagem em etapas, que combina o acúmulo de conhecimento em modo offline com a adaptação online, garante alta eficiência e robustez dos modelos ao operar em condições reais de mercado.
Teste
Uma avaliação objetiva da eficácia das soluções implementadas e da política de trading formada pode ser obtida com dados que não participaram do treinamento dos modelos. Para esse fim, foi utilizado um período de teste — janeiro–março de 2025. O uso de dados históricos fora do conjunto de treinamento permite eliminar o risco de sobreajuste e confere aos resultados um valor prático real.
Todos os demais parâmetros do experimento, ambiente de mercado, timeframe e configurações do terminal, foram mantidos sem alterações. Isso garantiu a pureza da verificação exatamente da qualidade da estratégia aprendida, sem a influência de fatores externos.
Os resultados do teste são apresentados abaixo e demonstram de forma clara o modelo de comportamento do agente em condições reais de operação.


Durante o período de teste, o modelo realizou 37 operações de trading. Pouco mais de 40% delas foram encerradas com lucro. Ainda assim, o modelo conseguiu obter lucro devido ao fato de que a média das operações lucrativas supera em mais de 2 vezes o mesmo indicador das operações perdedoras. O indicador de profit-factor foi registrado no nível de 1.67.
Considerações finais
Neste trabalho, nos familiarizamos com os aspectos teóricos do framework DA-CG-LSTM, que se diferencia dos modelos clássicos pela presença de componentes inovadores, como o CG-LSTM e o mecanismo de atenção dupla. Esses elementos proporcionam uma extração mais precisa das dependências temporais e permitem considerar tanto flutuações de curto prazo quanto tendências de longo prazo.
Na parte prática, foi apresentada uma arquitetura modificada, adaptada para as tarefas de treinamento de agentes de trading. A simplificação dos decodificadores em favor de blocos convolucionais permitiu concentrar o treinamento na extração de habilidades globais, fator-chave para a posterior construção de uma estratégia estável e adaptativa.
A eficácia das abordagens implementadas foi verificada em um conjunto de teste fora do período de treinamento. Apesar de a proporção de operações lucrativas ter sido pouco superior a 40%, a relação entre os lucros e prejuízos médios garantiu um resultado geral positivo.
Cabe destacar que os modelos descritos ainda possuem caráter exploratório. Antes da aplicação prática em trading real, eles exigem treinamento em dados mais representativos e a realização de testes abrangentes em diferentes condições de mercado.
Referências
- A Dual-Staged Attention Based Conversion-Gated Long Short Term Memory for Multivariable Time Series Prediction
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento offline de modelos |
| 4 | StudyOnline.mq5 | EA | EA de treinamento online de modelos |
| 4 | Test.mq5 | EA | EA para teste de modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17939
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
|
Ran Research 1 mês de 5 minutos, obteve 300 MB de DACGLSTM.bd. Executou o estudo. As taxas de erro são assustadoras. Ou isso é normal para a primeira execução?
Depois do Study, apareceram os arquivos .nnw da rede neural. Iniciei uma segunda rodada de coleta de dados, no mês seguinte - a pesquisa parou de fazer negócios....
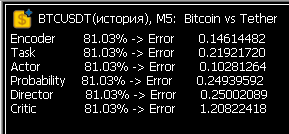
Muito bom! Após várias semanas de dança do pandeiro, os valores de erro no Study finalmente voltaram ao normal! Agora o neurônio está realmente aprendendo.
Tivemos de ampliar o algoritmo de recompensas e penalidades
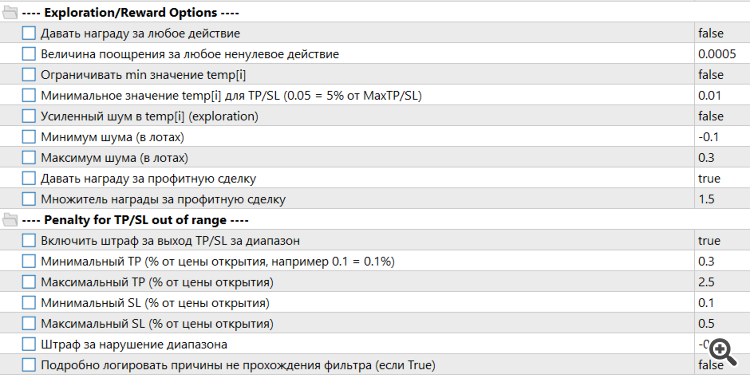
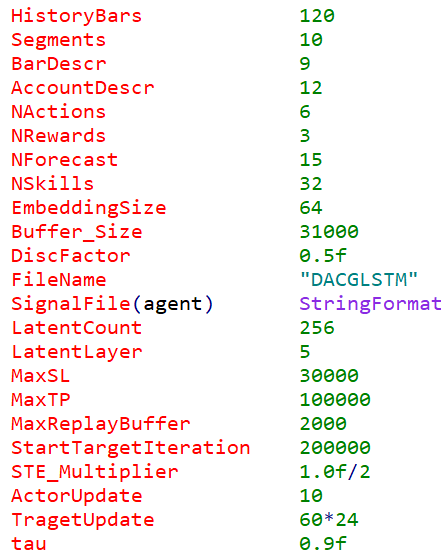
Também tivemos que fazer alguns ajustes importantes nos parâmetros de entrada do Trajectory.
Muito bom! Após várias semanas de dança do pandeiro, os valores de erro no Study finalmente voltaram ao normal! Agora o neurônio está realmente aprendendo.
O mais interessante agora é como ele negociará com novos dados... Estou fazendo modelos de madeira - eles são mais claros. Mas, com os novos dados, a negociação é quase aleatória, pois não há recursos significativos.
Agora, o mais interessante é como ele será negociado com novos dados... Estou fazendo modelos de madeira - eles são mais claros. Mas, com novos dados, a negociação é quase aleatória, pois não há características significativas.
Após algumas rodadas de Research-Study, as negociações começam a ser fechadas muito rapidamente. A Neuronka está aprendendo a sobreviver, não a ganhar dinheiro. E quanto mais curta a negociação, mais ela sente que está recebendo uma penalidade menor. A dança do pandeiro continua. Preciso acertar o algoritmo de recompensa e penalidade, e essa parece ser a parte mais difícil. Até agora, estou apenas tentando estabelecer alguns limites rígidos. Por exemplo, não permito definir paradas e retiradas menores que o valor limite. Também estou tentando limitar a vida útil mínima de uma negociação para que ela não seja fechada quase imediatamente após a abertura. Uso o LLM, o Grok ou o ChatGPT 4.1, mas às vezes eles são tão estúpidos que minha cabeça não consegue suportar. Mas, pouco a pouco, o progresso ainda está sendo feito. Muito tempo é gasto em círculos de aprendizado. Eu também gostaria de unir forças com alguém, pois o assunto é muito promissor.