
Cuantificación en el aprendizaje automático (Parte 2): Preprocesamiento de datos, selección de tablas, entrenamiento del modelo CatBoost

Introducción
En este artículo, hablaremos de la aplicación práctica de la cuantificación en la construcción de modelos arbóreos. El material se presentará sin fórmulas matemáticas complejas, en un lenguaje accesible. Este artículo supone la segunda parte del artículo "Cuantificación y otros métodos de preprocesamiento en el aprendizaje automático", por lo que le recomiendo encarecidamente que empiece familiarizándose con él, y aquí hablaremos de lo siguiente:
- En la primera parte vimos algunos métodos de preprocesamiento de datos de muestra implementados en MQL5.
- En la segunda parte, realizaremos un experimento que ofrecerá información sobre la viabilidad de la cuantificación de datos.
1. Métodos adicionales de preprocesamiento de datos
En el ejemplo sobre la descripción de la funcionalidad de la secuencia de comandos "Q_Error_Otbor" nos familiarizaremos con los métodos de preprocesamiento de datos que implementamos.
Si describimos brevemente la finalidad del script "Q_Error_Otbor", esta consiste en cargar una muestra del archivo "train.csv", transferir el contenido a un array, preprocesar los datos y, alternativamente, cargar tablas cuantificadas y evaluar el error de los datos recuperados en relación con los datos originales para cada predictor. Luego almacenaremos los resultados de la evaluación de cada tabla cuantificada en un array. Tras comprobar todas las variantes, crearemos una tabla resumen con los errores para cada predictor, seleccionando las mejores variantes de tablas cuantificadas para cada predictor según el criterio dado. Hoy crearemos y guardaremos la tabla cuantificada de resumen, el archivo con la configuración de CatBoost, en el que se añadirán los excluidos de la lista para los predictores de entrenamiento, con la indicación de los números de serie de sus columnas. También crearemos otros archivos relacionados, dependiendo de la configuración de script seleccionada.
Asimismo, echaremos un vistazo más de cerca a la configuración de la secuencia de comandos que he enumerado a continuación por grupo.
Carga de datos
- Directorio con la muestra1
- Directorio para la cuantificación 2
1 Especificamos la ruta del directorio donde se encuentra el directorio "Setup", que contiene los archivos csv con las muestras. Este directorio se denominará en lo sucesivo "directorio del proyecto".
2 Especificamos la ruta del directorio "Q", donde se encuentran los archivos csv con las tablas cuantificadas.
Configuración del procesamiento de valores atípicos
- Uso de la comprobación de valores atípicos 1
- Método de conversión de los valores atípicos:2
- Conversión de los valores atípicos a un valor cercano al split del valor 2.1
- Conversión de la magnitud de los valores atípicos a un valor aleatorio dentro del rango de fuera de los valores atípicos 2.2
- Sustitución de los datos tras el procesamiento de valores atípicos3
- Almacenar o no la muestra train con valores atípicos transformados4
- Adición de información a las submuestras sobre valores atípicos5
- Eliminación de filas con un gran número de valores atípicos5.1
- Porcentaje máximo de valores atípicos de los predictores en la fila de la muestra5.2
1 Al seleccionar "true", se activará el procesamiento de valores atípicos. Los valores atípicos se consideran valores de predicción poco frecuentes. Los valores poco frecuentes pueden resultar estadísticamente insignificantes, pero en los modelos, por lo general, esto no se tiene en cuenta, lo cual puede dar lugar a reglas cuestionables para estimar la probabilidad de clasificación. En la figura nº 1 puede verse un ejemplo de este tipo de valores atípicos. Si establecemos límites que separen los datos atípicos de los normales, podremos añadir los valores atípicos a un único conjunto, lo cual aumentará la confianza estadística y los datos podrán tratarse como normales o excluirse por completo del entrenamiento.
2 Seleccionamos uno de los métodos de transformación de valores atípicos con el que se modificará el valor del predictor, lo cual permitirá incluir este ejemplo en la muestra de entrenamiento en lugar de excluirlo como anómalo. Para determinar los valores atípicos, hemos utilizado el 2,5% de los datos de cada lado de la serie numérica. Debemos destacar que los valores numéricos idénticos se han agrupado, asignándoles rangos a los grupos, y si el rango siguiente supera el 2,5%, el último rango con valores atípicos se considerará el rango pasado. Los predictores con pocos rangos se reconocen como categóricos y en ellos no existe tratamiento de valores atípicos. La información en forma de lista de predictores categóricos se almacena en la siguiente ruta relativa al directorio del proyecto "../\CB\Categ.txt". Un método habitual para determinar los valores atípicos es la regla de las tres sigmas, que consiste en desplazar tres desviaciones estándar a la izquierda y la derecha de la media de los datos, y todo lo que quede fuera de este límite se considerará un valor atípico. En los gráficos siguientes podremos ver en negro tres líneas horizontales: el centro, la diferencia y la suma de tres sigmas a partir del centro. Las líneas azules del gráfico indicarán los límites dentro de los cuales se encuentran los datos que aparecen con frecuencia en el algoritmo propuesto.
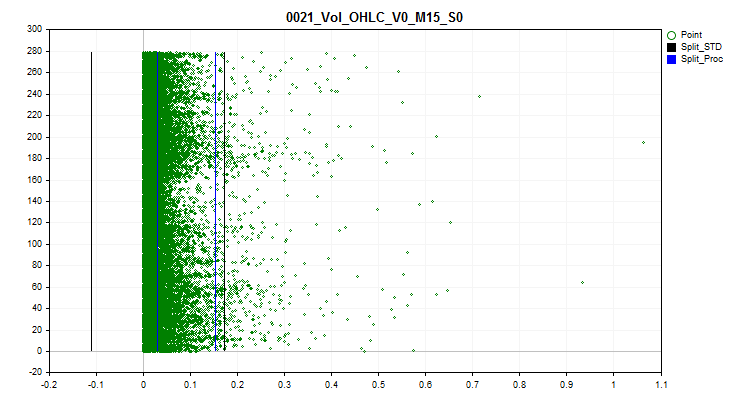
Figura 1 "Definición de los límites de la valores atípicos"
2.1 Este método sustituye todos las magnitudes de valores atípicos por un valor próximo al límite (split). Este enfoque garantizará que no se distorsione la estimación de la aproximación de la tabla cuantificada dentro de los límites de valores atípicos.
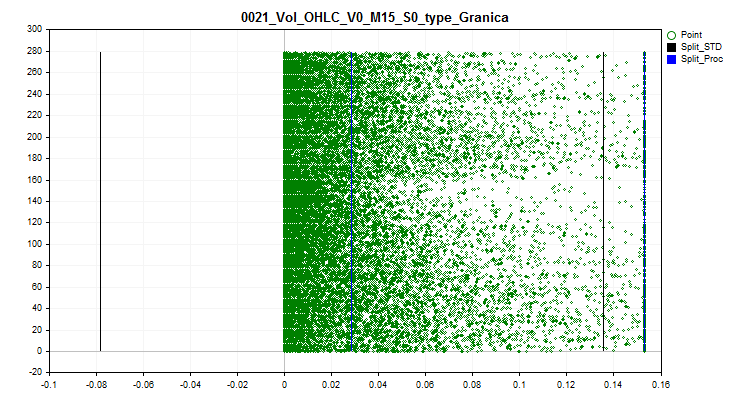
Figura 2 "Magnitud de los valores atípicos convertida a un valor cercano al split"
2.2 Este método sustituye todos los valores atípicos por valores aleatorios, según los rangos, dentro de los límites con datos normales. Dicho enfoque nos permite disipar el error de estimación de la aproximación de la tabla cuantificada.
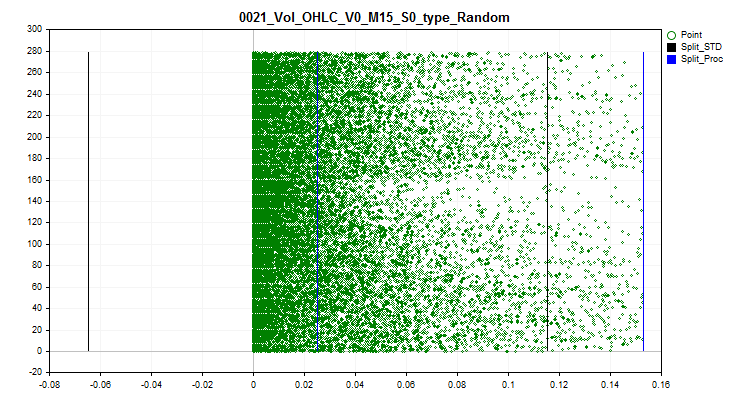
Figura 3 "Valor de valores atípicos convertido a un valor aleatorio en el rango de fuera de valores atípicos"
3 Si es necesario evaluar y seleccionar tablas cuantificadas considerando los valores atípicos transformados, elegiremos "true". Al activar esta función, el array en forma de matriz con los datos originales se modificará, las magnitudes de los predictores con valores atípicos pasarán a ser las que se seleccionaron según el método de transformación de valores atípicos.
4 Podemos guardar la selección train.csv, se almacenará en el directorio "..\CB\Q_Vibros_Viborka". Puede ser necesario para realizar la cuantificación con CatBoost, ya que los datos ya se cambiarán al transformarse, y las tablas de cuantificación pueden diferir, y también puede permitir reducir el número de separadores (splits) para alcanzar el umbral mínimo de error en una estimación de la calidad de aproximación por la tabla cuantificada.
5 Al activar esta configuración y establecer la variable en "true" se producirá una descarga secuencial de los archivos de las submuestras train.csv, test.csv y exam.csv. En cada fila de la submuestra se contará el número de valores predictores en la región de valores atípicos; el resultado total se registrará en la columna creada adicionalmente "Proc_Vibros". La muestra modificada se almacenará en el directorio "..\CB\ADD_Drop_Info_Viborka".
Independientemente de si esta configuración está activada o no, se creará un archivo independiente en el directorio del proyecto en la siguiente ruta "..\CB\Proc_Vibros_Train.csv". Este archivo solo contendrá información sobre los valores atípicos en la muestra train.
5.1 La activación de este ajuste eliminará las filas con valores atípicos de las muestras. A veces merece la pena tratar de entrenar un modelo con datos sin valores atípicos.
5.2 Si decidimos eliminar las filas con valores atípicos, merecerá la pena estimar el porcentaje de predictores que se encuentran dentro de la zona de detección de valores atípicos.
Establecimiento de la estimación de la correlación
- Uso de la estimación de la correlación para excluir los predictores1
- Método de exclusión de predictores correlacionados, define el método de selección (exclusión de predictores) a elegir:2
- Selección inversa de predictores2.1
- Selección de predictores generalizables2.2
- Selección de predictores poco frecuentes2.3
- Coeficiente de correlación3
1 Al seleccionar "true" se activará la estimación de la correlación de Pearson. El resultado de esta funcionalidad será una tabla de correlación de predictores en la siguiente ruta "../CB" donde el nombre del archivo constará del nombre "Corr_Matrix_" y el tamaño del coeficiente de correlación, "Corr_Matrix_70.csv". Se excluirán los predictores fuertemente correlacionados.
2 Podemos elegir entre tres métodos de exclusión de predictores.
2.1 Este método busca en orden inverso predictores correlacionados, y si hay uno anterior, la columna actual con el predictor se excluirá del entrenamiento.
2.2 Este método realiza una estimación del número de predictores correlacionados con cada predictor y selecciona iterativamente el que correlaciona con un mayor número de predictores, excluyendo otros predictores que se correlacionen con él. La lógica aquí es que estamos seleccionando los predictores con información que contienen en mayor medida la información de otros predictores, por lo que obtendremos dicha generalización de la información.
2.3 Este método resulta similar al anterior, pero aquí seleccionaremos los predictores que tienen menos similitud con los demás. Aquí se intentará lo contrario: encontrar un predictor con información única.
3 Aquí deberá indicarse el coeficiente de correlación de Pearson. Solo después de alcanzar o superar el valor del coeficiente especificado, los predictores se considerarán similares para manipularlos y excluirlos de la muestra.
Configuración del procesamiento de predictores variables en el tiempo
- Uso de la comprobación de la media de los valores de cada parte de la muestra1
- Porcentaje de variación de los valores medios de las submuestras2
1Al seleccionar "true" se activará una comprobación de las fluctuaciones del valor medio del índice del predictor en cada 1/10 de la muestra. Esta prueba nos permitirá excluir los predictores cuyos resultados varíen mucho con el tiempo. Dichos predictores, en teoría, dificultan el aprendizaje. Un ejemplo de este tipo de predictor puede verse en la figura nº 4, mientras que la visualización del proceso de estimación se puede ver en la figura nº 5. El predictor dado en el ejemplo se basaba en el indicador Variable Index Dynamic Average (iVIDyA), que esencialmente muestra un valor de precio medio, y su uso en el modelo dará lugar a un comportamiento memorizado a un determinado precio absoluto.
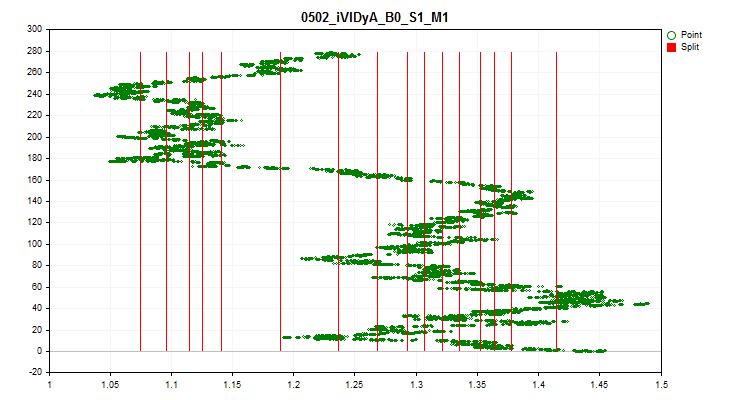
Figura "№4 "El predictor iVIDyA_B0_S1_M1 tiene un fuerte desplazamiento"
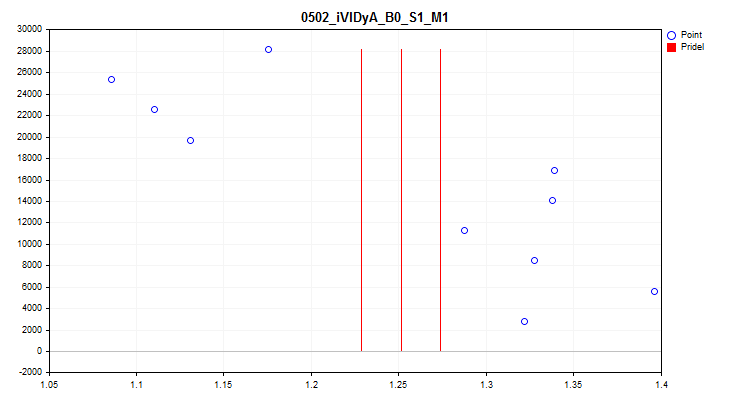
Figura №5 "Predictor iVIDyA_B0_S1_M1, dispersión del valor medio"
2 Aquí se indica la amplitud del intervalo en porcentaje para cada límite, que se definirá a partir del intervalo completo de valores del predictor, en relación con el valor medio de todo el periodo.
Configuración de la creación de una tabla cuantificada uniforme
- Creación de una tabla cuantificada uniforme1
- Número de intervalos en los que dividir (sin cuantificar) los datos originales2
1 Al seleccionar "true" se activará el algoritmo para crear una tabla de cuantificación uniforme para todos los predictores de la muestra. La tabla se almacenará en el subdirectorio del proyecto "Q_Bit".
2 Especifica el número de intervalos en los que se dividirá el predictor.
Configuración de una tabla cuantificada con un elemento aleatorio
- Crear la tabla cuantificada aleatoria1
- Número inicial para el generador de números aleatorios2
- Número de iteraciones para encontrar la mejor opción3
- Número de intervalos en los que dividir (cuantificar) los datos originales4
1 Seleccionando "true" se activará el algoritmo para crear una tabla de cuantificación aleatoria para todos los predictores de la muestra. La tabla se guardará en el subdirectorio del proyecto "Q_Random".
2 El número ofrece la posibilidad de hacer repetible el resultado de la generación aleatoria. Cambiando el número, podremos cambiar las secuencias de números generadas.
3 El algoritmo estima el error de aproximación después de cada generación de tablas aleatorias y elige la mejor opción. Cuantos más intentos, más posibilidades habrá de encontrar la opción más acertada.
4 Indica el número de intervalos en los que se dividirá el predictor.
Configuración de la selección de tablas cuantificadas
- Iniciar la selección de tablas cuantificadas1
- Utilizar el umbral para la selección de predictores2
- Error máximo de cuantificación permitido3
1 Si seleccionamos el valor "true", se activará el algoritmo de enumeración y evaluación de tablas cuantificadas del subdirectorio "Q" del proyecto, en caso contrario el programa se detendrá. El resultado de la ejecución de esta función del script será la creación de dos directorios:
En el directorio "..\CB\Setup", habrá 3 archivos:
- "Auxiliary.txt" - archivo auxiliar con los números de índice de los predictores excluidos
- "Quant_CB.csv" - archivo con tablas cuantificadas para los predictores que participarán en el entrenamiento
- "Test_CB_Setup_0_000000000" - archivo con información para CatBoost, qué columnas excluir del entrenamiento, qué columna considerar como objetivo.
En el directorio "Test_Error" se encuentra el archivo "arr_Svod.csv", que contiene los resultados resumidos del cálculo del error de recuperación (aproximación) para cada predictor al aplicar diferentes tablas de cuantificación. La primera columna contiene la lista de predictores, los resultados posteriores al aplicar una tabla cuantificada determinad, mientras que la última columna contiene el índice de la tabla cuantificada que ha mostrado el mejor resultado. El mejor resultado lo hemos usado para crear una tabla cuantificada de resumen "Quant_CB.csv".
2 Si el valor de ajuste está en "false", solo se utilizará el error de recuperación (aproximación) para evaluar las tablas cuantificadas, y se seleccionará la tabla con el menor error.
Si el valor de ajuste es "true", para estimar las tablas cuantificadas usaremos el error de recuperación (aproximación) dividido por el número de splits de la tabla cuantificada. Este enfoque nos permite considerar el número de tablas cuantificadas en la estimación, lo cual evitará una cuantificación excesiva. Las tablas solo participarán en la selección si su error resulta inferior al especificado en el siguiente parámetro de configuración.
3 Aquí indicamos el error máximo permitido de recuperación (aproximación) de los valores predictores.
Configuración del almacenamiento de la muestra convertida
- Conversión y almacenamiento la muestra1
- Opción de conversión de datos:2
- Guardar como índices2.1
- Guardar como centroides2.2
1 Si seleccionamos "true", la muestra (tres archivos csv) se convertirá y se guardará en el subdirectorio del proyecto "..\CB\Index_Viborka". Esta configuración permite usar tablas cuantificadas en algoritmos de aprendizaje automático para los que no estaban previstas originalmente. Otra aplicación sería compartir públicamente los datos para el entrenamiento de los modelos sin revelar las puntuaciones de los predictores, lo cual podría proteger contra revelaciones a la competencia sobre las fuentes de datos utilizadas. Además, el almacenamiento como índices puede reducir significativamente la cantidad de espacio ocupado en el disco por los archivos de muestra, así como reducir la cantidad de RAM para manipular la muestra.
2 Elegimos una de las dos opciones para convertir los valores predictores, después de aplicar la tabla resumen de cuantificación final.
2.1 Se almacenarán los valores de los índices de los segmentos de la tabla cuantificada en cuyo rango cae el número predictor.
2.2 Se mantendrá un valor entre los dos límites en los que el número predictor se halla dentro del intervalo.
Configuración del almacenamiento de gráficos
- Almacenamiento de gráficos1
- Anchura del gráfico2
- Altura del gráfico3
- Tamaño de la fuente en la leyenda4
1 Seleccionando "true" se activará la función para crear y guardar gráficos. En el directorio "Grafics" se crearán archivos gráficos con información sobre cada predictor de la muestra. El nombre del archivo comienza con el número del predictor, seguido del nombre del predictor del encabezado de la columna de muestra y, a continuación, el nombre condicional del gráfico. Veamos los gráficos obtenidos para el predictor "iCCI_B0_S1_M1":
- El primer muestra la densidad de los valores predictores en un intervalo concreto: cuanto mayor sea la densidad, mayor será la inclinación ascendente de la curva del gráfico en ese intervalo. En el eje X está el valor del predictor y en el eje Y se encuentra el número de observaciones clasificadas según su valor. El gráfico puede usarse para estimar la densidad de las observaciones de la muestra que caen en intervalos específicos y para ver los valores atípicos.
Figura nº 6 "Densidad de los valores de predictor"
- El segundo gráfico muestra en qué intervalos se han observado los valores del predictor en el objetivo "0" y "1", por lo que el azul representa los valores para el cero y el rojo para el uno. Así, podremos ver en qué intervalos del predictor se representa en mayor medida el valor del objetivo. Le recomiendo trazar el gráfico más ancho que en la ilustración del artículo.
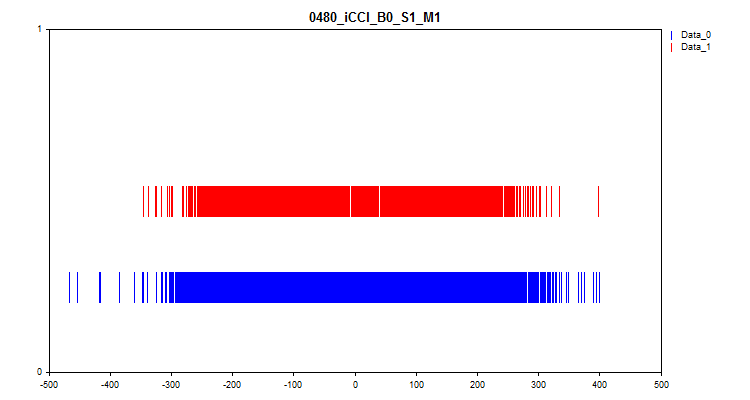
Figura nº 7 "Correspondencia del valor de predictor con el marcado de destino"
- El tercer gráfico supone un histograma en el que el eje Y representa el porcentaje de observaciones de todas las observaciones de la muestra. El gráfico permite estimar las valores atípicos y hacer una suposición sobre la densidad de la distribución.
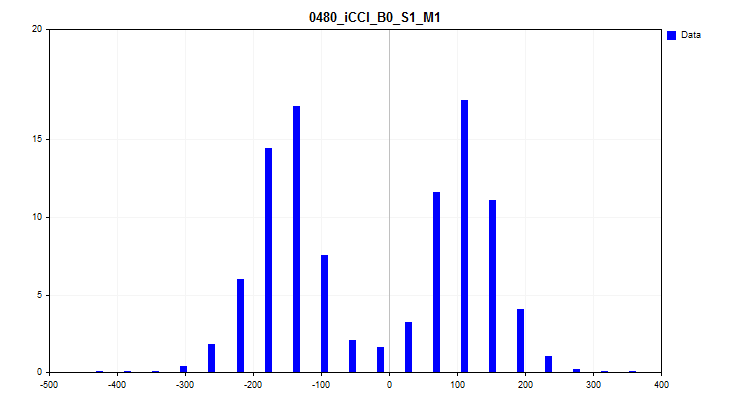
Figura 8 "Histograma de la densidad de distribución"
- El cuarto gráfico muestra el rellenado del rango de la escala de predicción con sus valores en orden cronológico, y también muestra los niveles que se han seleccionado para la cuantificación final. El eje X es el valor del predictor, mientras que el eje Y es el número del grupo de 100 observaciones.
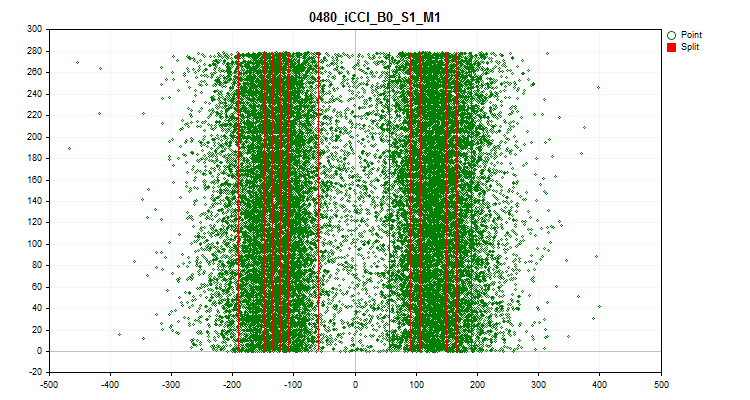
Figura №9 "Tabla cuantificada".
- El quinto gráfico muestra el valor medio del predictor durante los 10 intervalos de muestreo. Si la dispersión es alta, le recomendamos excluir el predictor. El eje X es la media del predictor, mientras que el eje Y es el número de un grupo de N observaciones.
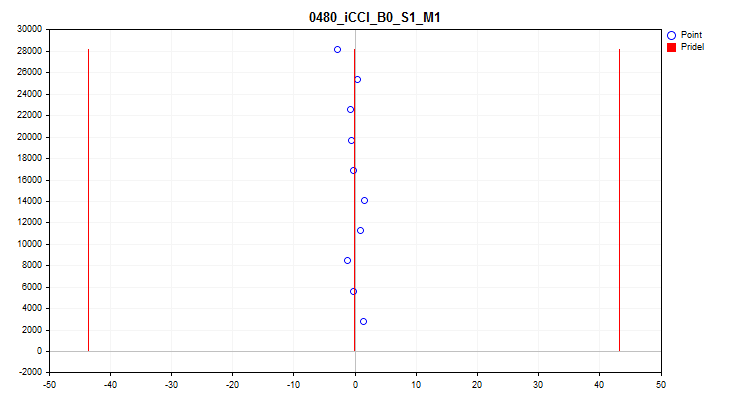
Figura №10 "Variación del valor medio"
- El sexto gráfico muestra las valores atípicos estimados. Las 3 líneas negras del gráfico son la media, y más y menos tres desviaciones típicas. Los límites azules se aproximan al 2,5% de las observaciones contadas desde el principio y el final del intervalo de la muestra. El eje X es el valor predictor, mientras que el eje Y es el número de grupo con un número fijo de observaciones.
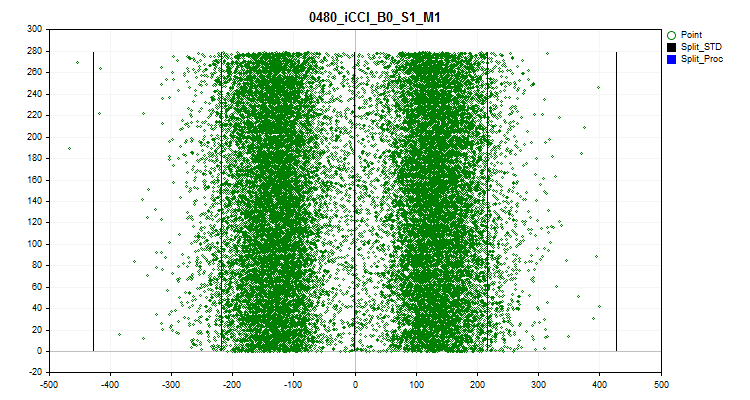
Figura №11 "valores atípicos"
2 Se especifica la anchura del gráfico en píxeles.
3 Se especifica la altura del gráfico en píxeles.
4 Se especifican el tamaño de fuente y el tamaño de las etiquetas de las curvas en la leyenda de los gráficos.
Configuración de la enumeración de escenarios de configuración
- Iteración de los escenarios de configuración1
1 Activa la anulación de los ajustes según el algoritmo establecido, podrá leer más información en el artículo sobre los detalles.
2. Ejecución de un experimento comparativo para evaluar el efecto de la cuantificación
Puesta en marcha del experimento: objetivos
Tenemos una herramienta con una funcionalidad considerable, ¡es hora de evaluar sus capacidades para trabajar! Vamos a realizar un experimento que responda a las preguntas que nos preocupan:
- ¿Existe algún sentido en todas estas acciones y manipulaciones con la selección de tablas cuantificadas para los predictores, tal vez sea más fácil usar la configuración por defecto de CatBoost?
- ¿Cuántos splits (límites) mínimos necesitamos para lograr un resultado similar al de la configuración predeterminada de CatBoost?
- ¿Deberíamos usar métodos de cuantificación como "uniforme" y "aleatorio"?
- ¿Existe una diferencia significativa entre los métodos de selección de las tablas cuantificadas?
Para responder a estas preguntas realizaremos un entrenamiento con diferentes tablas cuantificadas obtenidas con diferentes configuraciones del script "Q_Error_Otbor". Le sugiero que revise los siguientes ajustes:
Método de selección:
- Para estimar las tablas cuantificadas solo se utilizará el error de recuperación (aproximación).
- Para estimar las tablas cuantificadas, se usará el error de recuperación (aproximación) dividido por el número de splits de la tabla cuantificada, con un error máximo del 1%.
- Para estimar las tablas cuantificadas, se usará el error de recuperación (aproximación) dividido por el número de splits de la tabla cuantificada, con un error máximo del 0,5%.
Fuente de las tablas cuantificadas:
- Tablas derivadas de CatBoost.
- Tablas obtenidas por el método de cuantificación uniforme.
- Tablas obtenidas por split aleatorio.
Conjunto de tablas cuantificadas:
- Conjunto "1": se utilizarán todas las tablas cuantificadas disponibles en el directorio de origen.
- Conjunto "2": solo se utilizarán tablas cuantificadas con 16 splits o intervalos.
- Conjunto "3": solo se utilizarán tablas cuantificadas con 32 splits o intervalos.
- Conjunto "4": solo se utilizarán tablas cuantificadas con 64 splits o intervalos.
- Conjunto "5": solo se utilizarán tablas cuantificadas con 128 splits o intervalos.
- Conjunto "6": solo se utilizarán tablas cuantificadas con 256 splits o intervalos.
Todas las combinaciones de ajustes que ofrecemos en la tabla como figura 12, en el código esta tarea se implementará como tres ciclos anidados que cambiarán la configuración correspondiente, que se activará estableciendo en la configuración la variable llamada "Iterar escenarios de configuración" en el modo true.
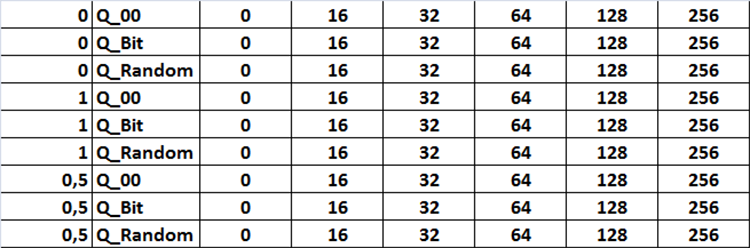
Figura nº12 "Tabla de combinaciones de ajustes de búsqueda"
Vamos a entrenar 101 modelos con cada combinación de ajustes, variando el parámetro Seed de 0 a 800 en pasos de 8. Esto nos permitirá promediar el resultado obtenido para evaluar los ajustes con el fin de excluir un resultado aleatorio.
Este es el tipo de indicadores que propongo usar para la evaluación comparativa:
- Beneficio medio de todos los modelos: llamaremos al indicador "Profit_Avr";
- Esperanza matemática media de los modelos: llamaremos al indicador "MO_Avr";
- Precisión media de la clasificación del modelo: llamaremos al indicador "Precision_Avr";
- Exhaustividad media de llamada de los modelos: llamaremos al indicador "Recall_Avr";
- Número medio de modelos que han mostrado un beneficio de más de 3000 unidades: llamaremos al indicador "N_Modelo_Examen";
- Beneficio máximo medio de todos los modelos: llamaremos al indicador "Profit_Max".
Una vez calculados los indicadores, le propongo sumarlos y dividirlos por el número de indicadores, con lo cual obtendremos un indicador generalizado de la calidad de los ajustes de selección de la tabla cuantificada, llamémoslo simplemente "Q_Avr".
Preparación de los datos para el experimento
Para obtener una muestra, usaremos el mismo asesor y scripts que hemos usado antes al familiarizarnos con CatBoost en el artículo "Aprendizaje de máquinas de Yándex (CatBoost) sin estudiar Python y R".
Hemos utilizado la siguiente configuración:
А. Ajustes del simulador:
- Símbolo: EURUSD
- Marco temporal: M1
- Intervalo del 01.01.2010 al 01.09.2023
B. Ajustes de estrategia del asesor CB_Exp:
- Periodo: 104
- Marco temporal: 2 minutos
- Método de medias móviles: Suavizado
- Precio básico de cálculo: Precio Close
Después de obtener la muestra y dividirla en 3 partes (train, test, exam), de forma similar a la que hemos descrito anteriormente en el artículo, deberemos obtener las tablas cuantificadas. Para ello, hemos modificado el script CB_Bat (adjunto a este artículo) y ahora al seleccionar "Brut_Quantilisation_grid" en el ajuste "Brut Object", el script creará el archivo "_01_Quant_All.txt". La configuración de la iteración de rango sigue siendo la misma: se establecerá el valor inicial de la variable, el valor final de la variable y el paso de cambio; hemos utilizado una iteración de 8 a 256 en pasos de 8. Como resultado del funcionamiento del script, se prepararán comandos para obtener tablas de cuantificación con todos los tipos con el número especificado de límites. El archivo de la tabla de cuantificación tendrá la siguiente estructura de nombres: el nombre del archivo como el nombre semántico del archivo "quant", el número de separadores y el número ordinal del tipo de división; los índices irán unidos por guiones bajos, los propios archivos se guardarán en el directorio "Q", que es el mismo que el directorio "Setup" del proyecto.
quant_"+IntegerToString(Seed,3,'0')+"_"+IntegerToString(ENUM_feature_border_type_NAME(Q),0)+".csv";
El archivo resultante "_01_Quant_All.txt", después de funcionar el script, deberá cambiar la extensión a "*.bat", ubicar en el directorio con él la versión de CatBoost previamente especificada en el script y ejecutarla haciendo clic dos veces.
Una vez ejecutado el script, aparecerá un conjunto de archivos en el subdirectorio "Q": serán las tablas de cuantificación con las que trabajaremos más adelante.

Figura 13 "Contenido del subdirectorio Q"
Usando el script "Q_Error_Otbor" generaremos tablas cuantificadas uniformes y aleatorias con el número de intervalos 16, 32, 64, 128, 256; los archivos correspondientes aparecerán en los directorios "Q_Bit" y "Q_Random". Luego haremos una copia del directorio "Q" en el directorio del proyecto y pondremos al nuevo directorio el nombre "Q_00".
Genial, ya tenemos todo lo necesario para crear un paquete de tareas de entrenamiento. Ahora ejecutaremos el script "Q_Error_Otbor" y en su configuración cambiaremos el parámetro "Go through settings scripts" a "true", clicando a continuación en "Ok". El script, según el escenario establecido en el código, creará los archivos con la tabla cuantificada y los ajustes para el entrenamiento.
Para usar tablas cuantificadas para cada configuración de los ajustes de CatBoost durante el entrenamiento, el script añadirá al nombre habitual de la tabla cuantificada "Quant_CB.csv" el nombre del archivo de configuración.
Vamos a obtener los archivos para el entrenamiento con el script "CB_Bat_v_02"; hemos elegido la enumeración para Seed de 0 a 800 con el paso 8, especificando el directorio del proyecto.
Ahora tendremos que editar un poco el archivo para el entrenamiento, sustituyendo el nombre del archivo "Quant_CB.csv" por "Quant_CB_%%a.csv", este cambio nos permitirá utilizar como variable el nombre de los ajustes, cuyo número dependerá del número de ciclos de entrenamiento. Luego copiaremos los archivos creados en el directorio "Setup" del proyecto y ejecutaremos el entrenamiento renombrando el archivo de "_00_Start.txt" a "_00_Start.bat" y pulsando dos veces sobre el archivo "_00_Start.bat".
Valoración de los resultados del experimento
Una vez finalizado el entrenamiento, aplicaremos el script "CB_Calc_Svod" que calculará las métricas de cada modelo. Ya describimos con detalle la configuración del script en el último artículo, así que no nos repetiremos.
También hemos entrenado 101 modelos con la configuración predeterminada de la tabla cuantificada, y estos son los resultados:
- Profit_Avr=2810,17;
- MO_Avr=28,33;
- Precision _Avr=0,3625;
- Recall_Avr=0,023;
- N_Exam_Model=43;
-
Profit_Max=8026.
Veamos con detalle las tablas y gráficos de resultados de cada indicador antes de sacar conclusiones generalizables.
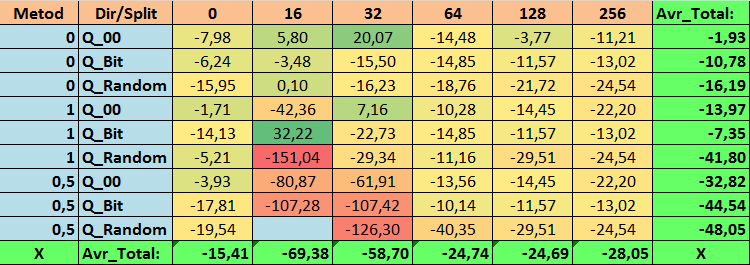
Tabla nº14 "Valores resumidos de la métrica Profit_Avr
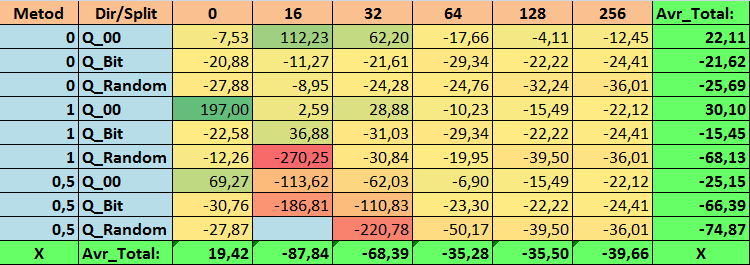
Tabla nº15 "Valores resumidos de la métrica MO_Avr"
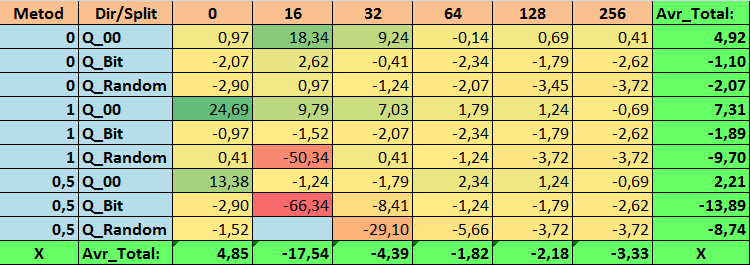
Tabla nº16 "Valores resumidos de la métrica Precision_Avr"
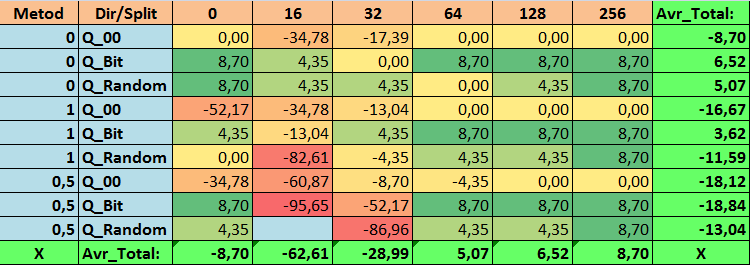
Tabla nº17 "Valores resumidos de la métrica Recall_Avr"
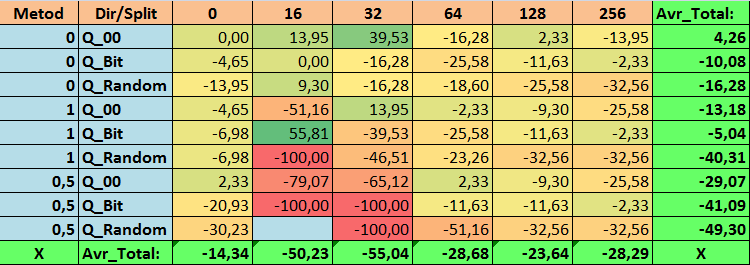
Tabla nº18 "Valores resumidos de la métrica N_Exam_Model"
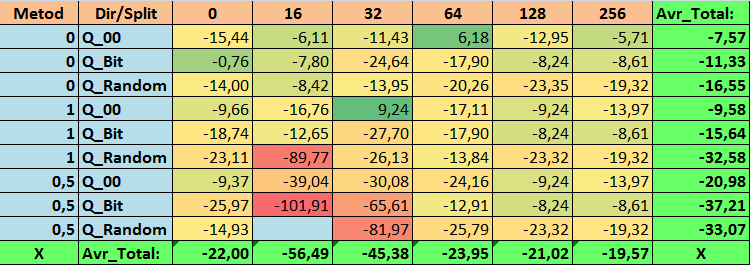
Tabla nº19 "Valores resumidos de la métrica Profit_Max"

Tabla nº20 "Valores resumidos de la métrica Q_Avr"
Al revisar nuestras tablas informativas, hemos podido comprobar que la variación en el rendimiento es bastante grande, lo cual indica el efecto de la configuración general sobre el resultado del aprendizaje. Podemos ver que las tablas obtenidas por split aleatorio (Q_Random) han mostrado el resultado más débil en relación con las tablas cuantificadas creadas por otros métodos. Lo que parece interesante es que el aumento del número de splits provoca en la mayoría de los casos un deterioro del rendimiento de nuestras métricas, con la excepción de la métrica Recall_Avr. Esto se debe probablemente al hecho de que la información de los segmentos cuantificados es muy escasa, lo cual lleva a realizar únicamente manipulaciones matemáticas durante el entrenamiento que acaban con un aumento de la confianza del modelo, pero con un descenso de la precisión y, por consiguiente, del beneficio medio. Entonces nos surge la siguiente pregunta: "¿por qué el modelo se entrena con éxito con 254 divisiones por defecto?". Pues porque el valor por defecto es un método de construcción de rejilla como GreedyLogSum, que, como hemos visto antes, construye la rejilla en incrementos no uniformes. Como la rejilla no se construye uniformemente, a menudo nuestra métrica elegida para evaluar la calidad de la construcción de la rejilla muestra un resultado peor que una rejilla uniforme; como resultado, al elegir las tablas de cuantificación del conjunto obtenido por todos los métodos CatBoost, no se suele elegir un método como GreedyLogSum. Incluso podemos ver estadísticas sobre la frecuencia con que se ha elegido este método. Así, para la combinación (0;Q_00;256), esto supondrá un total de 121 predictores de 2408. ¿Y por qué las partes extremas de los rangos de los predictores resultan ser tan significativas?: ¡escriba sus conjeturas en los comentarios de este artículo!
Bien, las tablas con un gran número de divisiones y con split aleatorio no han mostrado un buen resultado, pero ¿qué pasa con la diferencia en los métodos de selección de las tablas cuantificadas? Empezaremos por lo malo: a pesar de todo, el requisito de error del 0,5% se ha sobreestimado para los valores de tabla de 16 a 64, como resultado de lo cual han participado en el entrenamiento muchos menos predictores de los que había inicialmente, pero al mismo tiempo las tablas con un gran número de splits han superado con éxito este umbral, pero como ya hemos sugerido, no ha sido eficiente. No obstante, al elegir entre todas las tablas disponibles (primer conjunto en orden) se han obtenido tablas que no están mal equilibradas, especialmente el conjunto de tablas CatBoost. Al mismo tiempo, el método de selección de predictores con requisitos menos estrictos -un error de aproximación mínimo del 1%- se ha mostrado como una solución que merece más atención.
Pasemos ahora a responder a las preguntas planteadas; al fin y al cabo, responderlas es precisamente el objetivo de este experimento.
Respuestas a las preguntas:
1. La tabla de cuantificación por defecto usada en CatBoost, objetivamente, muestra un buen resultado en nuestros datos, ¡pero resulta que se puede mejorar significativamente! Examinemos el rendimiento de nuestras métricas para los mejores métodos de obtención de tablas cuantificadas:
- Profit _Avr - combinación de (1;Q_Bit;16) con un valor un 32,22% mejor que los ajustes básicos.
- MO_Avr - combinación de (1;Q_00;0) con un valor 197,00% mejor que los ajustes básicos.
- Precision_Avr - combinación de (1;Q_00;0) con un valor un 24,69% mejor que los ajustes básicos.
- Recall_Avr, aquí existen muchas combinaciones, y todas son un 8,7% mejores que los ajustes básicos.
- N_Exam_Model - combinación (1;Q_Bit;16) con un valor un 55,81% mejor que los ajustes básicos.
- N_Profit_Max - combinación (1;Q_00;32) con un valor 9,24 % mejor que los ajustes básicos.
Así pues, podemos dar objetivamente una respuesta positiva a esta pregunta: ¿merece la pena intentar seleccionar mejores tablas cuantificadas, que puedan mejorar los resultados en las métricas que son importantes para nosotros?
2. Finalmente, resulta que para nuestra muestra apenas 16 splits son suficientes para obtener un buen valor de Q_Avr, por lo que para la combinación de ajustes (1;Q_Bit;16) es igual a 16,28, y para la combinación (0;Q_00;16) ya es de 18,24.
3. El método uniforme ha resultado bastante aceptable, especialmente interesante es el hecho de que haya permitido obtener el mayor número de modelos en la combinación (1;Q_Bit;16), que es un 55,81% superior a los ajustes básicos, y teniendo en cuenta que ha mostrado uno de los mejores resultados en términos de esperanza matemática -mejor que los ajustes básicos en un 36,88%-, creo que valdrá la pena utilizar este método a la hora de elegir tablas de cuantificación e implementarlo en otros proyectos relacionados con el aprendizaje automático. En cuanto a las tablas obtenidas por split aleatorio, este enfoque debe utilizarse con precaución, quizá de forma selectiva cuando no supere el umbral de un determinado criterio de selección de tablas cuantificadas. Cabe señalar que 10 000 variantes pueden no haber sido suficientes para encontrar la mejor división del predictor en segmentos cuantificados.
4. Como muestran los resultados experimentales, el método de selección de las tablas cuantificadas tiene un efecto significativo en los resultados. No obstante, un solo experimento no basta para recomendar con seguridad el uso de uno solo de los métodos. Los distintos métodos y sus ajustes permiten al modelo hacer hincapié en distintas partes de los datos de la muestra seleccionando diferentes tablas cuantificadas, lo cual puede ayudar a encontrar la solución óptima.
Conclusión
En este artículo, hemos presentado el algoritmo de selección de tablas cuantificadas y hemos realizado un gran experimento para evaluar la viabilidad de la selección de tablas cuantificadas. Asimismo, hemos analizado superficialmente otros métodos de preprocesamiento de datos, sin estudiar el código ni evaluar la eficacia de estos métodos, porque realizar una serie de experimentos y describir sus resultados requeriría un trabajo considerable: si este artículo es de interés para los lectores, podríamos realizar experimentos y describirlos en otros artículos.
En el artículo no hemos usado gráficos de balance, aunque existen buenos ejemplos de modelos. Le recomendaría utilizar más predictores para seleccionar y luego construir modelos para la negociación real en los mercados financieros.
Hemos utilizado una puntuación de aproximación para seleccionar los cuadros cuantificados, pero merece la pena intentar aplicar otras puntuaciones que puedan evaluar la homogeneidad y utilidad de los datos.
| № | Anexo | Descripción |
|---|---|---|
| 1 | Q_Error_Otbor.mq5 | Script responsable del preprocesamiento de datos y la selección de tablas de cuantificación para cada predictor. |
| 2 | CB_Bat_v_02.mq5 | Sscript responsable de generar tareas para el entrenamiento de modelos con CatBoost - nueva versión 2.0 |
| 3 | CSV fast.mqh | Clase para trabajar con archivos CSV; todos los derechos de autor sobre el código del programa pertenecen a Aliaksandr Hryshyn. Deberá descargar usted mismo los archivos que faltan desde el enlace. |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13648
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Añadimos un LLM personalizado a un robot comercial (Parte 2): Ejemplo de despliegue del entorno
Añadimos un LLM personalizado a un robot comercial (Parte 2): Ejemplo de despliegue del entorno
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso