
Redes neuronales en el trading: Resultados prácticos del método TEMPO

Introducción
En el artículo anterior, presentamos los aspectos teóricos del método TEMPO, que ofrece un enfoque original para utilizar modelos de lenguaje pre-entrenados para resolver problemas de pronóstico de series temporales. Permítame recordarle brevemente las principales innovaciones del algoritmo propuesto.
El método TEMPO se basa en el uso de un modelo de lenguaje pre-entrenado. En particular, los autores del método usan un modelo GPT-2 previamente entrenado en sus experimentos. La idea principal de este enfoque radica en utilizar el conocimiento del modelo obtenido durante el entrenamiento preliminar para pronosticar series temporales. Obviamente, aquí vale la pena establecer paralelos no obvios entre el habla y las series temporales. Después de todo, en esencia, nuestro habla es una serie temporal de sonidos que se registran mediante letras, y las diferentes entonaciones se fijan mediante signos de puntuación.
El segundo momento a considerar es que el modelo extenso de lenguaje (Long Language Model — LLM), en este caso GPT-2, ha sido entrenado previamente con un gran conjunto de datos (a menudo, en múltiples idiomas) y ha aprendido una gran cantidad de dependencias distintas en la secuencia temporal de palabras que nos gustaría usar en el pronóstico de series temporales. Pero las secuencias de letras y palabras se distinguen en gran medida de los datos de las series temporales analizadas. Y siempre hemos dicho que para el correcto funcionamiento de cualquier modelo, resulta esencial mantener la distribución de datos en las muestras de entrenamiento y prueba, sobre todo de los datos analizados durante el funcionamiento del modelo. Y aquí debemos recordar que cualquier modelo de lenguaje no funciona con el texto al que estamos acostumbrados en su forma pura: primero pasa por la etapa de incorporación (codificación), durante la cual el texto al que estamos acostumbrados se transforma en un determinado código numérico (estado oculto) con quien ya está trabajando la modelo. A la salida del modelo se generan las probabilidades de uso posterior de las letras y signos de puntuación. A partir de los caracteres, con bastante probabilidad, se formará el texto que leeremos.
Los autores del método TEMPO han aprovechado esta propiedad. Durante el entrenamiento de un modelo de pronóstico de series temporales, se "congelan" los parámetros del modelo de lenguaje y se optimizan los parámetros para convertir los datos de origen en incorporaciones que resulten comprensibles para el modelo utilizado. Aquí los autores del método TEMPO ofrecen un enfoque integral que permite dotar al modelo de la máxima cantidad de información útil. En primer lugar, la serie temporal analizada se desglosa en sus componentes constitutivos: tendencia, estacionalidad, etc. Luego, cada componente se segmenta y se transforma en incorporaciones que resultan comprensibles para el modelo de lenguaje. Y para orientar el modelo lingüístico en la dirección correcta (análisis de tendencias o estacionalidad), los autores del método han desarrollado un sistema de “sugerencias suaves”.
En general, este enfoque hace que el modelo resulte interpretable al máximo, y también nos permite juzgar la influencia de un componente particular en el resultado de la predicción de valores posteriores.
A continuación le presentamos la visualización del método por parte del autor.
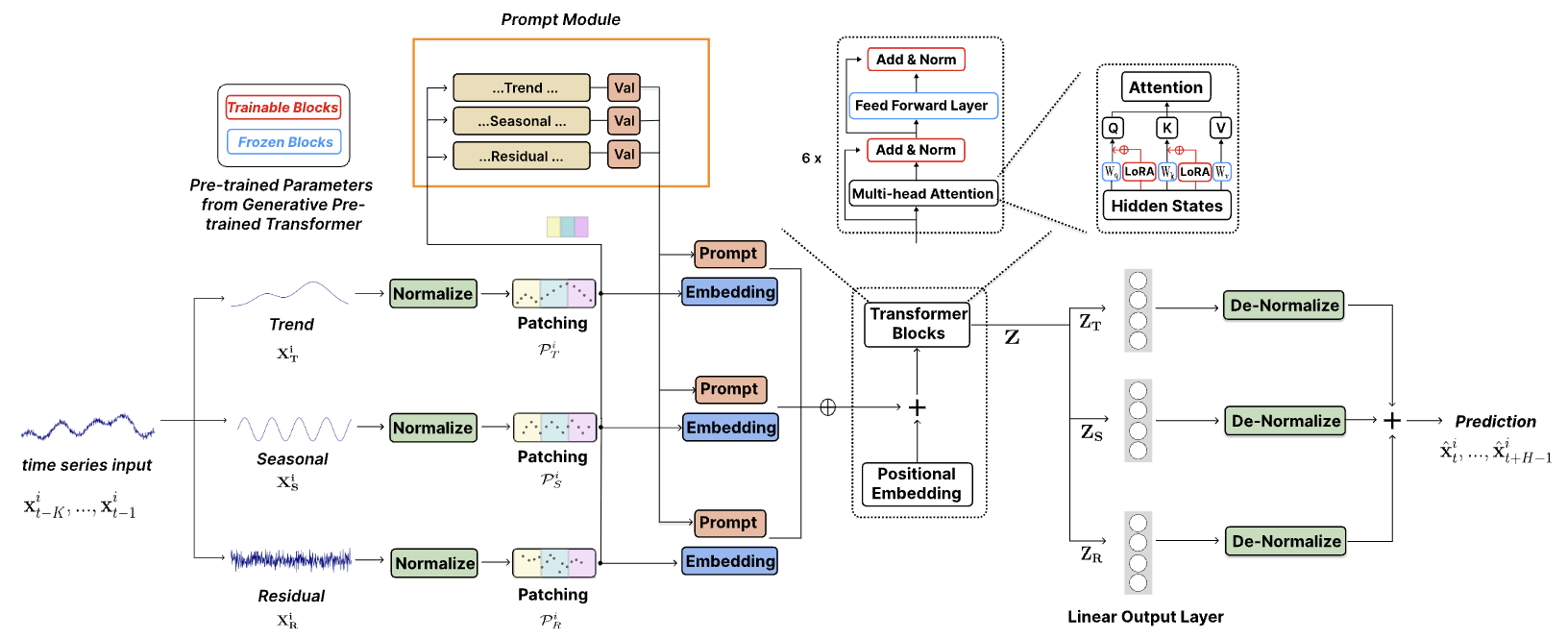
1. Arquitectura de los modelos
La arquitectura del modelo propuesto resulta bastante compleja, pues contiene una serie de ramas y flujos de datos paralelos que se suman a la salida del modelo. Un algoritmo de este tipo resulta bastante difícil de implementar en el marco del modelo lineal que utilizamos. Por eso hemos realizado bastante trabajo para implementar todo el algoritmo dentro de un bloque, que es esencialmente una capa de nuestro modelo. Esta implementación, hasta cierto punto, limita la capacidad del usuario para experimentar con modelos de diversa complejidad; después de todo, la variabilidad de la estructura del módulo está limitada por los parámetros del método Init de la clase CNeuronTEMPOOCL que creamos. Pero existe un reverso de la moneda: simplificamos al máximo el proceso de creación de un nuevo modelo. El usuario no necesitará profundizar en todos los detalles de la arquitectura del método en consideración, solo tendrá que especificar unos pocos parámetros para construir una arquitectura compleja y potente. En mi opinión, esta opción resulta más aceptable para la mayoría de usuarios.
Y, obviamente, vale la pena prestar atención a otro punto bastante importante. Los autores del método usan el modelo de lenguaje GPT-2 previamente entrenado en sus experimentos. Si se implementa en Python, podemos encontrar dichos modelos. Por ejemplo, en la biblioteca Hugging Face. Pero en nuestra implementación no existe semejante modelo pre-entrenado. Así que lo reemplazaremos con un bloqueo de atención cruzada, y lo entrenaremos junto con el modelo.
Los autores posicionan el método TEMPO como un modelo para la predicción de series temporales. Por consiguiente, como hemos hecho antes en casos similares, implementaremos los enfoques propuestos en nuestro modelo de Codificador del estado del entorno. La arquitectura de este modelo se presenta en el método CreateEncoderDescriptions.
En los parámetros del método especificado, transmitiremos el puntero a un array dinámico en cuyos elementos se escribirán los parámetros arquitectónicos de las capas neuronales del modelo creado.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
En el cuerpo del método, verificaremos la relevancia del puntero recibido y, de ser necesario, crearemos una nueva instancia del objeto.
A continuación le mostramos una descripción del modelo. Primero especificaremos una capa completamente conectada para escribir los datos de origen. El tamaño de la capa creada deberá coincidir con el tamaño del tensor de datos de origen.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Permítame recordarle que transmitiremos el tensor de datos de origen sin procesar al modelo en la forma en que lo recibimos del terminal. El siguiente paso en todos nuestros modelos anteriores era utilizar una capa de normalización de datos por lotes que realizaba el procesamiento primario de los datos y los llevaba a una forma comparable.
Sin embargo, en este caso hemos excluido la capa de normalización de lotes, y la razón de esto, curiosamente, ha sido la arquitectura del método TEMPO. Como podemos ver en la visualización del método presentado anteriormente, los datos de origen ingresan inmediatamente al bloque de descomposición, en el cual la serie temporal analizada se descompone en sus 3 componentes: tendencia, estacionalidad, etc. La descomposición en componentes se efectúa de forma independiente para cada serie temporal unitaria (el parámetro analizado de la serie temporal multimodal). La comparabilidad de valores dentro de una misma serie unitaria estará garantizada por la naturaleza del origen de los valores.
En primer lugar, se extraerá el componente de tendencia de los datos de origen. En nuestra implementación, realizaremos esta operación utilizando el método de representación lineal por partes de la serie temporal. Como sabe, el algoritmo de este método permite extraer segmentos comparables independientemente de la escala y desplazamiento de la distribución de los datos de origen, lo cual se realiza durante la normalización.
En el siguiente paso, tomaremos los datos de origen menos el componente de tendencia y determinaremos el componente de estacionalidad. Para ello, utilizaremos la transformada de Fourier discreta para descomponer la señal en un espectro de frecuencia, cuya amplitud puede usarse para identificar las dependencias periódicas más significativas. La descomposición de frecuencia también resultará insensible a la escala y desplazamiento de los datos de origen.
Y para determinar el tercer componente, solo necesitaremos restar los 2 componentes encontrados anteriormente de los datos de origen.
Creo que aquí resulta obvio que, desde el punto de vista de la lógica de construcción del modelo, la normalización preliminar de los datos no nos ofrecerá beneficios adicionales. Por otro lado, la normalización de datos requerirá recursos computacionales adicionales, lo que en sí mismo resulta poco deseable.
Pero debemos mirar más allá. Los autores del método introducen la normalización de los componentes seleccionados, lo que sin duda es importante para operaciones posteriores con datos multimodales. ¿Quizás podríamos cambiar el punto de normalización de datos? ¿Normalizar los datos de origen antes de dividirlos en componentes y luego eliminar la normalización posterior de los datos de los componentes individuales? Resulta obvio que el volumen de los datos de origen es 3 veces menor que el volumen total de los 3 componentes. Mi opinión: más bien “no” que “sí”.
Como ejemplo, tomaremos un gráfico abstracto y resaltaremos las principales tendencias en él. Obviamente, el componente tendencial “absorberá” un mayor volumen de información.
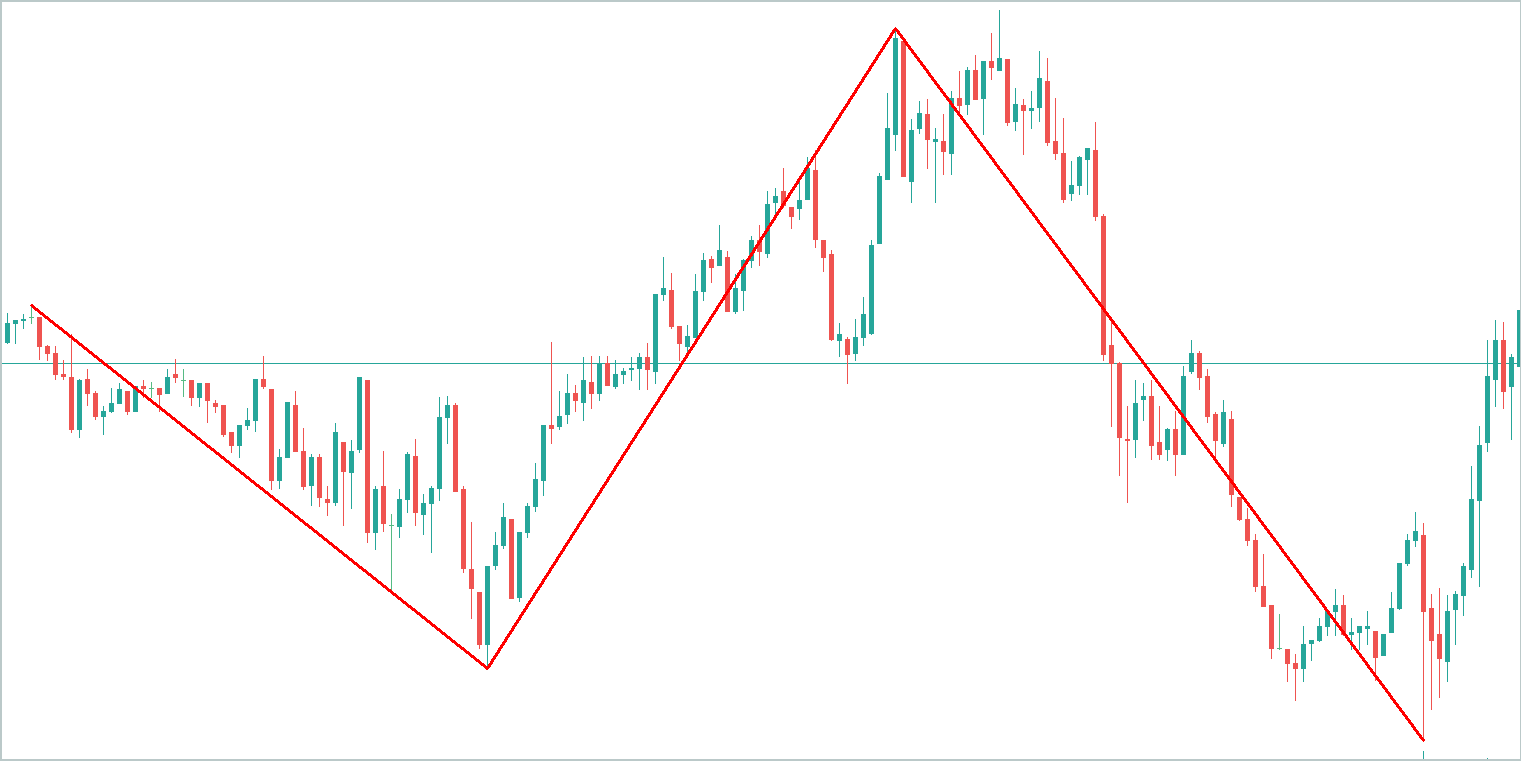
El componente estacional representa fluctuaciones de ondas alrededor de la línea de tendencia. La amplitud de sus valores será significativamente inferior al componente tendencial.
El tercer componente de los otros valores recibirá una amplitud aún menor de valores, que en mayor medida suponen ruido. Sin embargo, no podemos ignorarlos, porque el trasfondo de noticias y otros factores no contabilizados que no son de naturaleza sistémica se reflejan en este ruido.
La normalización de los datos de origen antes de dividir la señal en componentes nos permitirá resolver el problema de la comparabilidad de los datos de las series unitarias individuales. Pero no será capaz de resolver el problema de comparabilidad de los datos de los componentes individuales extraídos de la señal analizada. Por consiguiente, para lograr que el modelo resulte estable, será preferible realizar la normalización posterior de los datos de los componentes individuales.
Siguiendo el razonamiento anterior, excluiremos la capa de normalización por lotes de los datos de origen. Inmediatamente después de la capa de datos de origen configuraremos nuestro nuevo bloque de método TEMPO.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTEMPOOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = NForecast;
Y especificaremos el tamaño de la secuencia multimodal analizada, el número de series temporales unitarias en ella y el horizonte de planificación usando las constantes previamente especificadas.
Como parte del experimento en la preparación de este artículo, hemos indicado 4 cabezas de atención.
descr.window_out = 4;
Y 4 capas anidadas en el bloque de atención.
descr.layers = 4;
Aquí quisiera recordarle que estos parámetros se utilizan en 2 bloques de atención anidados:
- un bloque de atención del dominio de frecuencia usado para identificar las dependencias entre las características de frecuencia de secuencias unitarias individuales;
- un bloque de atención cruzada para detectar dependencias en una secuencia de series temporales.
A continuación, especificaremos el tamaño del lote de normalización y el método de optimización del modelo.
descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
En este punto, el modelo podría considerarse completo, ya que a la salida del bloque CNeuronTEMPOOCL ya obtendremos los valores de pronóstico deseados de la serie temporal analizada. Sin embargo, añadiremos el toque final como una capa de concordancia de frecuencia de la serie temporal de pronóstico CNeuronFreDFOCL.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Como resultado, obtendremos una arquitectura de modelo corta y concisa en forma de 3 capas neuronales. No obstante, debajo de todo esto se oculta un algoritmo complejo e integrado. Después de todo, sabemos que bajo la "punta del iceberg" de CNeuronTEMPOOCL existen 24 capas anidadas, 12 de las cuales contienen parámetros entrenables. Además, 2 de estas capas anidadas son bloques de atención, para los cuales especificamos la creación de una arquitectura de Self-Attention de 4 capas con 4 cabezas de atención cada una. Y esto hace que nuestro modelo resulte verdaderamente complejo y profundo.
Usaremos los valores de pronóstico obtenidos del próximo movimiento de precios para entrenar la política de comportamiento del Actor. Aquí hemos conservado en gran medida las arquitecturas de los artículos anteriores, pero debido a la complejidad del Codificador del estado del entorno y al aumento esperado en el coste de su entrenamiento, hemos tomado la decisión de reducir el número de capas anidadas en los bloques de atención cruzada de los modelos del Actor y el Crítico. Permítame recordarle que la descripción de la arquitectura de los modelos especificados se presenta en el método CreateDescriptions, en cuyos parámetros transmitimos los punteros a 2 arrays dinámicos. Escribiremos la descripción de la arquitectura de nuestros modelos en estos arrays.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
En el cuerpo del método, verificaremos la relevancia de los punteros recibidos y, de ser necesario, crearemos nuevas instancias de objetos.
En primer lugar, describiremos la arquitectura del Actor, a cuya entrada suministraremos el tensor que describe el estado de la cuenta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Tenga en cuenta que aquí hablamos del estado de la cuenta, no del entorno. Con "estado del entorno" nos referimos a los parámetros de la dinámica del movimiento de precios y los indicadores analizados, mientras que en el concepto "estado de la cuenta" incluimos el valor actual del balance de la cuenta y el volumen y la dirección de las posiciones abiertas, así como el beneficio o las pérdidas acumuladas en ellas.
La información recibida en la entrada del modelo la transformaremos en un estado oculto utilizando una capa básica completamente conectada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, usaremos un bloque de atención cruzada donde compararemos el estado actual de la cuenta con el valor previsto del próximo movimiento de precios obtenido del Codificador del estado del entorno.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLCrossAttentionMLKV; { int temp[] = {1, NForecast}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, BarDescr}; ArrayCopy(descr.windows, temp); } { int temp[] = {4, 2}; ArrayCopy(descr.heads, temp); } descr.layers = 4; descr.step = 1; descr.window_out = 32; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y aquí hay que prestar atención a un momento importante: el subespacio de valores de los datos obtenidos del Codificador del estado de la cuenta. Sí, ya hemos usado exactamente el mismo enfoque antes, pero entonces no nos molestaba. ¿Qué ha pasado?
"El diablo se oculta en los detalles". Antes, utilizábamos una capa de normalización por lotes en la entrada del Codificador del estado del entorno para hacer comparables los datos de origen. Y en la salida del modelo, utilizando la capa CNeuronRevINDenormOCL, se realizaba la operación inversa, devolviendo los datos al subespacio original. Para el propósito del Actor y el Crítico, utilizábamos el valor latente de los valores predichos en una forma comparable antes de las operaciones de desplazamiento y escala en los subespacios de los datos de origen. Y en este caso, para el análisis posterior obtenemos datos comparables con los que habitualmente trabaja el modelo.
En el caso de CNeuronTEMPOOCL, entonces abandonamos la normalización preliminar de los datos de origen, que discutimos anteriormente. Pero ahora se espera que el modelo produzca valores no normalizados del movimiento de precios previsto, lo cual puede complicar el trabajo del Actor y el Crítico, y, como consecuencia, reducir su eficacia. Una posible solución sería pre-normalizar los valores de las series temporales de pronóstico antes de utilizarlos. La forma más sencilla de hacerlo sería crear un pequeño modelo de preprocesamiento de datos adicional con una capa de normalización. Sin embargo, no lo hemos hecho.
Me gustaría recordarle que en la salida del bloque CNeuronTEMPOOCL, en lugar de la suma simple de los valores predichos de los 3 componentes (tendencia, estacionalidad, etc.), hemos utilizado una capa convolucional sin función de activación que sustituye la suma simple de los datos obtenidos con una ponderada.
if(!cSum.Init(0, 24, OpenCL, 3, 3, 1, iVariables, iForecast, optimization, iBatch)) return false; cSum.SetActivationFunction(None);
Entre tanto, la limitación del valor máximo de los parámetros del modelo a menos de 1 nos permite excluir valores obviamente grandes en la salida del modelo.
#define MAX_WEIGHT 1.0e-3f
Obviamente, este enfoque limita de antemano la precisión de nuestro Codificador del estado del entorno. Después de todo, ¿cómo podemos comparar, por ejemplo, las lecturas reales del indicador RSI (el rango de sus valores va de 0 a 100), con los resultados previstos, cuyo valor absoluto es menor que 1? En este caso, usando el MSE como función de pérdida, podemos obtener con alta probabilidad valores predichos en el máximo nivel posible. Precisamente por eso añadimos a la salida del Codificador del estado del entorno un bloque de resultados de concordancia de frecuencia CNeuronFreDFOCL, que resultará menos sensible al escalamiento de datos, y nos permitirá conocer la estructura del próximo movimiento de precios, que en este caso será más importante que los valores absolutos.
Aquí debo reconocer que la solución propuesta no resulta obvia y puede ser algo difícil de entender. Por eso evaluaremos su eficacia según los resultados prácticos de nuestros modelos.
Pero volvamos a la arquitectura de nuestro Actor. Tras el bloque de atención cruzada, utilizaremos un perceptrón completamente conectado de 3 capas para la toma de decisiones,
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
a cuya salida añadiremos estocasticidad a la política de nuestro Actor.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y coordinaremos las características de frecuencia de la solución adoptada.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
La arquitectura del Crítico repite casi por completo la arquitectura del Actor presentada anteriormente. Solo hay pequeñas diferencias. Concretamente, suministraremos a la entrada del modelo no el estado de la cuenta, sino el tensor de acción del Actor.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Mientras que en la salida del modelo no utilizaremos estocasticidad, lo cual ofrecerá una evaluación clara de las acciones propuestas.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Podrá familiarizarse con el código completo de la solución arquitectónica de todos los modelos utilizados en el archivo adjunto.
2. Entrenamiento de modelos
Como podemos ver en la descripción anterior de la solución arquitectónica de los modelos entrenados, la implementación de los enfoques del método TEMPO considerado no ha introducido ningún cambio en la estructura de los datos de origen ni en los resultados de los modelos entrenados. Por consiguiente, podemos utilizar de forma segura muestras de entrenamiento recopiladas previamente para el entrenamiento inicial de los modelos. Además, podremos recopilar los datos en un conjunto de entrenamiento, entrenar los modelos y actualizar el conjunto de entrenamiento utilizando programas previamente creados para interactuar con el entorno y el entrenamiento de modelos.
Permítame recordarle que para interactuar con el entorno y recolectar datos de muestra de entrenamiento utilizamos 2 programas:
- "...\Experts\TEMPO\ResearchRealORL.mq5" — se utiliza para recopilar los datos sobre un conjunto de historias de transacciones reales. El método se describe en detalle en el artículo del enlace.
- "...\Experts\TEMPO\Research.mq5" — el asesor está destinado en mayor medida a analizar la efectividad de una política previamente entrenada y a actualizar los datos de la muestra de entrenamiento en un entorno determinado de la política actual, lo que posteriormente permite un ajuste más preciso de la política del Actor en función de las recompensas reales por sus acciones. No obstante, este asesor también se puede utilizar para recopilar un conjunto primario de datos de entrenamiento basado en la política de comportamiento del Actor inicializada con parámetros aleatorios.
Independientemente de si hemos recopilado previamente los datos de la interacción con el entorno, podemos ejecutar cualquiera de los EA anteriores en el simulador de estrategias de MetaTrader 5 para crear una nueva muestra de entrenamiento o actualizar una existente.
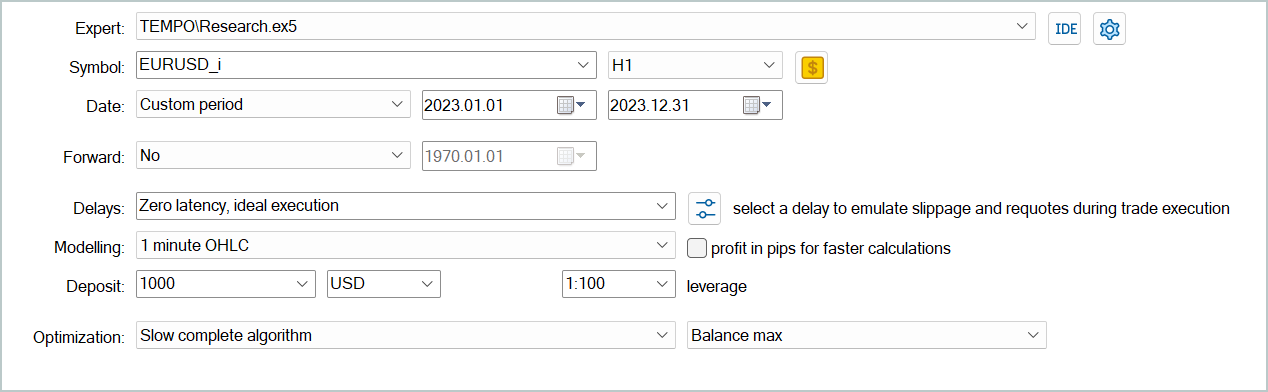
Los datos de entrenamiento recopilados se utilizarán primero para entrenar el modelo del Codificador del estado del entorno para predecir el movimiento de precios posterior. Para ello, iniciaremos el asesor "...\Experts\TEMPO\StudyEncoder.mq5" en tiempo real en MetaTrader 5.
Aquí cabe señalar que durante el proceso de aprendizaje, el Codificador del estado del entorno trabaja únicamente con los parámetros de la dinámica del movimiento de precios y los indicadores analizados, que no se ven afectados por las acciones del Agente. Por consiguiente, todos las pasadas en el conjunto de entrenamiento en un intervalo histórico para el modelo serán idénticas. Y durante el entrenamiento del Codificador, la actualización de la muestra de entrenamiento no proporcionará información adicional. Por consiguiente, seremos pacientes y entrenaremos el modelo hasta obtener los resultados deseados.
Una vez más, quiero recordarles que, debido a las particularidades de nuestra solución arquitectónica (que ya hemos discutido antes), en esta etapa no esperamos valores de error "bajos". Pero aún así lograremos los resultados mínimos posibles. Y detendremos el proceso de entrenamiento del modelo cuando el error de pronóstico se estabilice en un rango estrecho.
En la segunda etapa, realizaremos el entrenamiento iterativo de los modelos del Actor y el Crítico. En esta etapa utilizaremos el asesor "...\Experts\TEMPO\Study.mq5", que también se ejecuta en tiempo real. Esta vez "congelaremos" los parámetros del Codificador del estado del entorno y entrenaremos 2 modelos (Actor y Crítico) en paralelo.
El Crítico aprenderá la función de recompensa del entorno a partir del conjunto de entrenamiento, comparando el estado previsto del entorno y las acciones del Agente del conjunto de entrenamiento en un intento de predecir la recompensa del entorno. Esta etapa se corresponderá con los principios del aprendizaje supervisado, ya que la recompensa real por las acciones realizadas se almacenará en la muestra de entrenamiento.
El Actor entonces, siguiendo las “sugerencias” del Crítico, optimizará su política en un intento de maximizar la rentabilidad general.
Este proceso será de naturaleza iterativa, ya que durante el aprendizaje el subespacio de acciones del Actor cambiará. Y necesitaremos actualizar el conjunto de entrenamiento para obtener recompensas reales en el nuevo subespacio de acciones. Esto permitirá al Crítico ajustar la función de recompensa y dar una evaluación más correcta de las acciones del Actor, lo que, a su vez, permitirá ajustar la política del Actor en la dirección correcta.
Con el fin de actualizar el conjunto de entrenamiento, volveremos a ejecutar el proceso de optimización lenta del asesor "...\Experts\TEMPO\Research.mq5".
En esta etapa, podrían surgir preguntas sobre la conveniencia de entrenar por separado el Codificador del estado de la cuenta. Por un lado, el Codificador del estado de la cuenta previamente entrenado nos ofrece el movimiento de mercado posterior más probable, y por tanto actúa como un filtro digital, reduciendo el ruido inherente a los datos de origen. Al mismo tiempo, usamos un horizonte de planificación significativamente menor que la profundidad de la historia analizada. De esta forma el Codificador también comprime los datos para su posterior análisis, lo que, en general, aumenta potencialmente la eficiencia del Actor y del Crítico.
Por otra parte, ¿hasta qué punto necesitamos una previsión del próximo movimiento de precios? Al fin y al cabo, ya hemos dicho que para nosotros lo más importante es una interpretación clara del estado actual que nos permita seleccionar la acción óptima del Agente con la máxima precisión. Para responder a esta pregunta, hemos creado otro modelo de asesor de entrenamiento "...\Experts\TEMPO\Study2.mq5". Este programa ha sido creado sobre la base del asesor "...\Experts\TEMPO\Study.mq5". Por consiguiente, analizaremos únicamente el método de entrenamiento directo de modelos Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false;
En el cuerpo del método, primero generaremos un vector de probabilidades para elegir trayectorias a partir del búfer de reproducción de experiencias en función de la rentabilidad total de las pasadas. Después de esto inicializaremos las variables locales necesarias.
En este punto finalizaremos el trabajo preparatorio y organizaremos el ciclo de entrenamiento directo de modelos.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) { iter --; continue; }
En el cuerpo del ciclo, tomaremos una muestra de una trayectoria del búfer de reproducción de experiencias y seleccionaremos aleatoriamente un estado del entorno en ella.
Luego transferiremos la descripción del estado del entorno seleccionado de la muestra de entrenamiento al búfer de datos y realizaremos una pasada directa del Codificador del estado del entorno.
bState.AssignArray(state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Luego tomaremos del búfer de reproducción de experiencias las acciones del Agente realizadas en el estado seleccionado al interactuar con el entorno, y se realizá su evaluación por parte del Crítico.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite(); Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que el búfer de reproducción de experiencias contiene la evaluación real de estas acciones y podemos ajustar la función de recompensa aprendida por el Crítico en la dirección de la minimización del error. Para ello, extraeremos la recompensa real recibida del búfer de reproducción de experiencias y realizaremos una pasada inversa del Crítico.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
En este paso, agregaremos una pasada inversa del Codificador del estado del entorno para atraer la atención del modelo hacia los puntos de referencia, lo cual permitirá realizar estimaciones más precisas de las acciones.
El siguiente paso consistirá en ajustar la política del Actor. En primer lugar, prepararemos a partir del búfer de reproducción de experiencias una descripción del estado de la cuenta correspondiente al estado del entorno previamente seleccionado.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Y realizaremos una pasada directa del Actor para generar un vector de acción considerando la política actual.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación, deshabilitaremos el modo de entrenamiento del Crítico y evaluaremos las acciones generadas por el Actor.
Critic.TrainMode(false); if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ajustaremos la política del Actor en 2 etapas. En primer lugar, comprobaremos la eficacia de la pasada actual. Si, durante la interacción con el entorno, estada pasada ha resultado rentable, entonces ajustaremos la política de acción del Actor hacia las acciones almacenadas en el búfer de reproducción de experiencias.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder), LatentLayer) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Al hacerlo, también ajustaremos los parámetros del Codificador del estado del entorno para resaltar los puntos de datos de origen que influyen en la efectividad de la política del actor.
En la segunda etapa del entrenamiento de la política del Actor, sugeriremos al Crítico que indique la dirección de los ajustes de acción del agente para aumentar la rentabilidad/disminuir las pérdidas en un 1%. Para ello, tomaremos la calificación actual de las acciones del Actor y la mejoramos en un 1%.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Utilizaremos el resultado obtenido como referencia para la pasada inversa del Crítico. Permítame recordarles que en esta etapa hemos desactivado el proceso de entrenamiento del Crítico. Por consiguiente, al realizar una pasada inversa, sus parámetros no se ajustarán. Pero el Actor obtendrá el gradiente de error. Y podremos ajustar los parámetros del Actor en la dirección del aumento de la efectividad de su política.
if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder), LatentLayer) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), LatentLayer, -1, true) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Entonces, todo lo que deberemos hacer es informar al usuario sobre el progreso del entrenamiento del modelo y pasar a la siguiente iteración del ciclo.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez finalizado el proceso de entrenamiento, borraremos el campo de comentarios del gráfico del instrumento.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Luego enviaremos los resultados del entrenamiento del modelo al registro de la terminal e inicializaremos el proceso de finalización del programa.
Encontrará el código completo de este asesor, así como todos los programas utilizados en la elaboración de este artículo, en el archivo adjunto.
3. Simulación
Después del trabajo realizado, hemos llegado al punto culminante, la evaluación práctica de los resultados de los modelos entrenados.
Permítame recordarles que los modelos han sido entrenados con datos históricos para todo el año 2023 del instrumento EURUDS, marco temporal H1. Los parámetros de todos los indicadores analizados se han usado por defecto.
Las pruebas de los modelos entrenados se han realizado con los datos históricos de enero de 2024, manteniendo todos los demás parámetros. De esta forma conseguiremos la máxima aproximación a las condiciones de funcionamiento real de los modelos.
En el primer paso, hemos entrenado el modelo del Codificador del estado del entorno. A continuación le mostramos un gráfico de visualización del movimiento de precios real y previsto para 24 horas con un paso de pronóstico de 1 paso, que se corresponde con los siguientes días en el marco temporal H1. Precisamente han sido estos datos del marco temporal los que hemos utilizado para nuestro análisis.
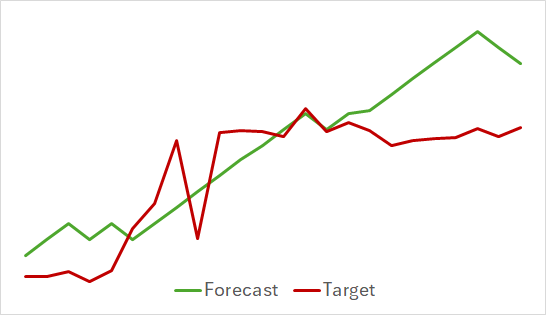
En el gráfico presentado se puede observar que el pronóstico obtenido en su conjunto ha captado la dirección principal del movimiento futuro. Incluso se puede notar la coincidencia en el tiempo y la dirección de algunos extremos locales. Al mismo tiempo, el gráfico de movimiento previsto resulta más suave y recuerda más a las líneas de tendencia trazadas en el gráfico de movimiento de precios del instrumento.
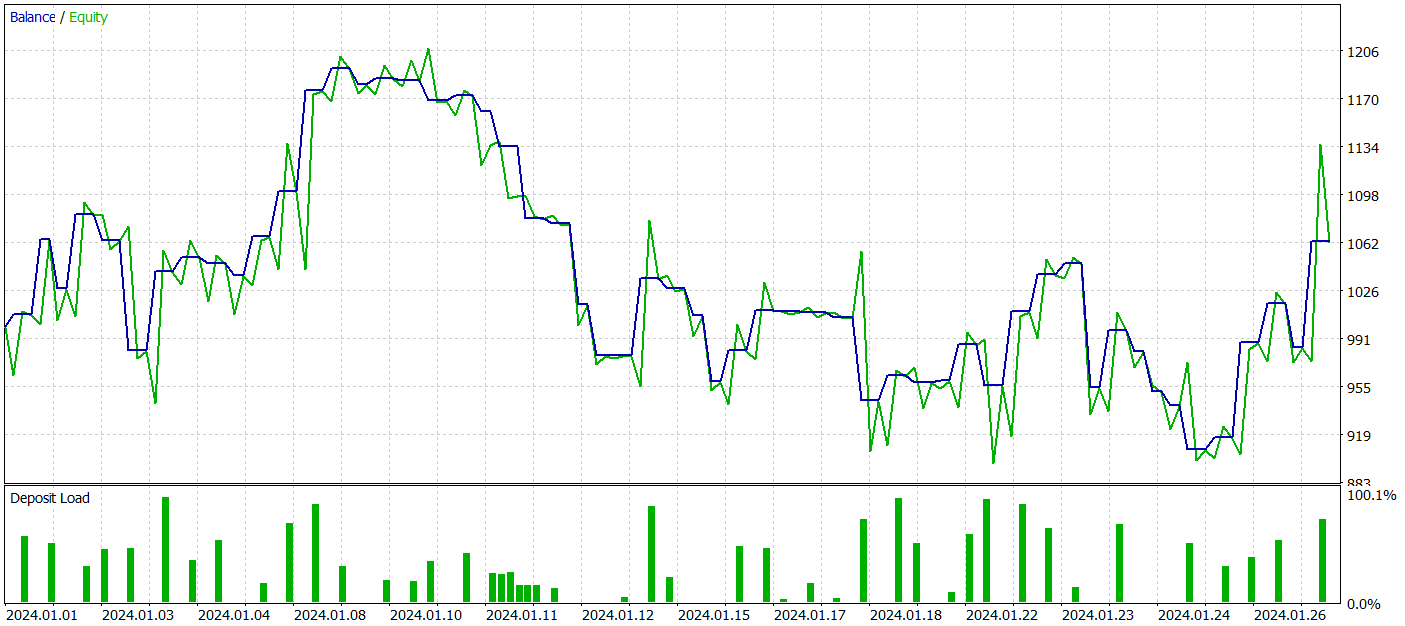
En la segunda etapa, hemos entrenado los modelos del Actor y el Crítico. No vamos a analizar la calidad de la valoración que el Crítico hace de las acciones. Después de todo, su tarea principal consiste en orientar el entrenamiento de la política del Actor en la dirección correcta. Veamos la rentabilidad de la política del Actor aprendida en el intervalo de tiempo de prueba. A continuación le presentamos los resultados de las acciones del Actor en el simulador de estrategias.
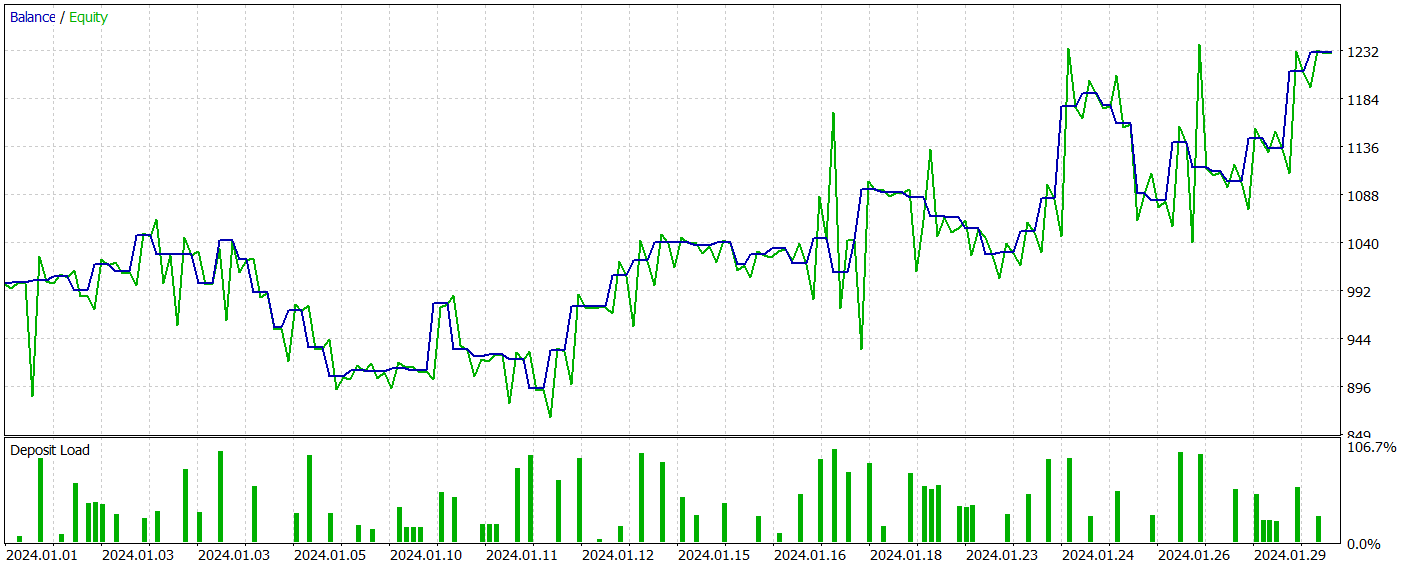
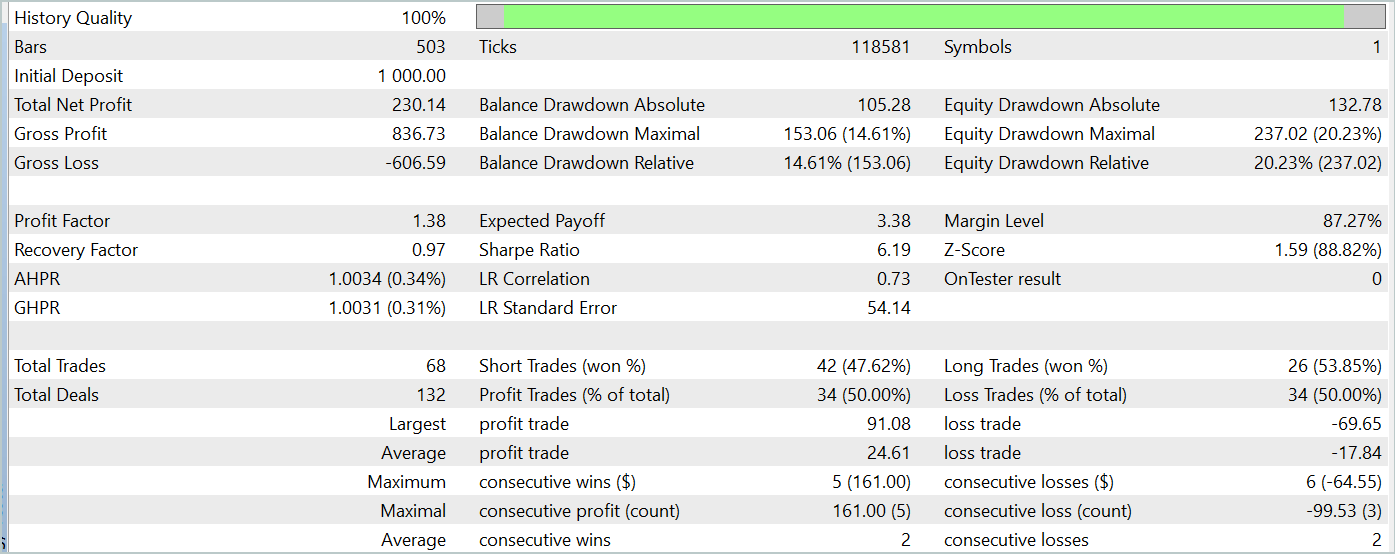
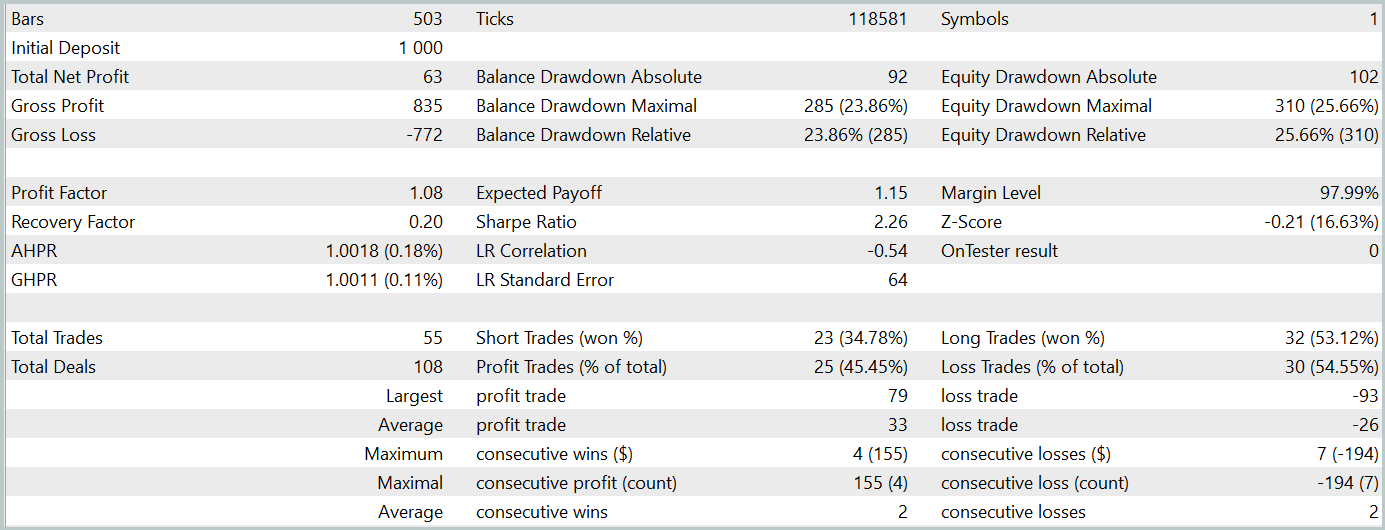
Durante el periodo de prueba (enero de 2024), el Actor ha realizado 68 transacciones, la mitad de las cuales se han cerrado con beneficios. Y gracias a que tanto las operaciones rentables máximas como las medias han superado las lecturas perdedoras correspondientes (91,08 y 24,61 frente a -69,85 y -17,84 respectivamente), el modelo ha logrado unos beneficios del 23%.
Sin embargo, en el gráfico de balance, podemos ver picos de equidad significativos tanto por encima como por debajo de la línea de balance. El primer pensamiento: "aguanta las pérdidas" y sale de la posición tarde. Pero si prestamos atención al hecho de que en esos momentos la carga del depósito es cercana al 100%, entonces ya podemos pensar en el aumento de los riesgos. Otra prueba de ello es también la caída máxima de la equidad, que supera el 20%.
El siguiente paso ha sido entrenar aún más la política del Actor ajustando los parámetros del Codificador del estado del entorno. Aquí vale la pena señalar que el entrenamiento adicional se ha realizado sin actualizar la muestra de entrenamiento. En otras palabras, la base de entrenamiento sigue siendo la misma. Sin embargo, semejante entrenamiento ha tenido un efecto negativo: la eficiencia del modelo ha disminuido, el número de transacciones completadas se ha reducido, y la proporción de transacciones rentables ha caído al 45%. La rentabilidad global del modelo ha disminuido, mientras que la reducción de la equidad ha superado el 25%.
Cabe destacar que la calidad de los pronósticos sobre las futuras trayectorias de movimiento de precios también ha cambiado.
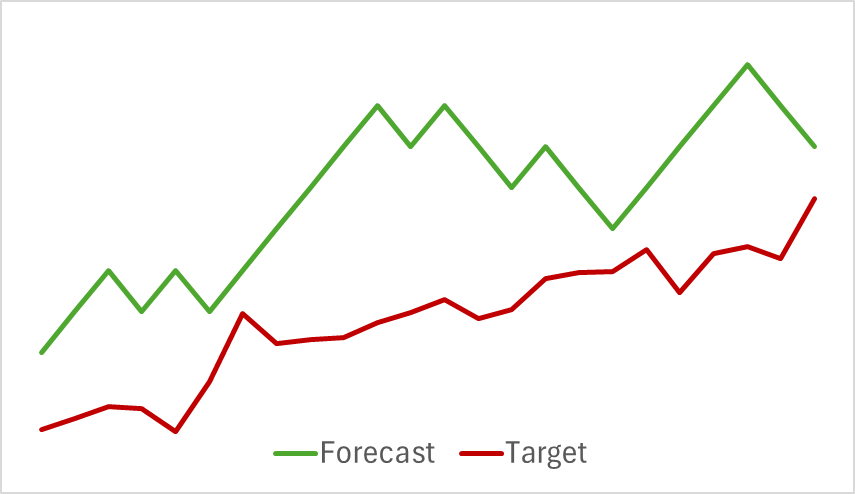
Mi opinión es que cuando empezamos a optimizar los parámetros del Codificador del entorno para los objetivos del Actor y el Crítico, estamos agregando ruido a la salida del Codificador. Y es que, si bien durante el entrenamiento del modelo para predecir el próximo movimiento hemos tenido una correspondencia clara entre los datos de origen y los resultados, y durante el proceso de aprendizaje, el modelo ha aprendido y generalizado estos patrones, el gradiente de error obtenido del Actor y el Crítico agrega ruido multidireccional a medida que el modelo intenta minimizar su error con los datos de entrada obtenidos del Codificador del estado del entorno. Como resultado, el Codificador ya no actúa como un filtro para los datos de origen y obtenemos una disminución de la eficiencia de los modelos en todas las direcciones.
Conclusión
Hoy nos hemos familiarizado con un método interesante y complejo de pronóstico de series temporales, el modelo TEMPO, cuyos autores proponen utilizar modelos de lenguaje previamente entrenados para resolver problemas de pronóstico de series temporales. El algoritmo propuesto implementa un nuevo enfoque para la descomposición de series temporales que permite aumentar la eficiencia del aprendizaje de la representación de los datos de origen.
Asimismo, hemos realizado un trabajo considerable en la implementación de los enfoques propuestos utilizando MQL5. Y a pesar de que no teníamos a nuestra disposición un modelo de lenguaje previamente entrenado, los experimentos han arrojado algunos resultados interesantes.
En general, los enfoques propuestos se pueden usar para construir modelos comerciales reales. Sin embargo, debemos considerar que el entrenamiento de modelos que utilizan la arquitectura del Transformer requiere la recopilación previa de cantidades significativas de datos y puede resultar costoso durante el proceso de entrenamiento.
Enlaces
- TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del Codificador |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
| 9 | Study2.mq5 | Asesor | Asesor para el entrenamiento de los modelos del Actor y el Crítico con ajuste de los parámetros del Codificador |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15469
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Actitud hacia los usuarios
Claramente
Sólo a los que piensan que el autor le debe algo.....
El estafador tampoco le debe nada a nadie.
Pero la gente cae en su trampa por alguna razón.
Si los artículos no contuvieran detonantes y motivaciones flagrantes como "...el modelo es capaz de generar beneficios", entonces no pasa nada. Nuestros problemas.
Y cuando se manipula información no contrastada, no es realmente nuestro problema.
Teniendo en cuenta que el primer usuario fue baneado por criticar, yo también acabaré para siempre. Puedes rebatir con contraargumentos, yo lo dejaré mejor sin respuesta.
...Si los artículos no contuvieran detonantes y motivaciones flagrantes como "...el modelo es capaz de generar beneficios", entonces que así sea. Nuestros problemas.
Y cuando manipulan información no contrastada - no son realmente nuestros problemas....
Bajo algún artículo de Dmitry en los comentarios le pedí que escribiera un artículo específicamente sobre la formación de sus Asesores Expertos. Podría tomar cualquiera de sus modelos de cualquier artículo y explicar completamente en el artículo cómo lo enseña. Desde cero hasta el resultado, en detalle, con todos los matices. En qué fijarse, en qué secuencia enseña, cuántas veces, en qué equipos, qué hace si no aprende, en qué errores se fija. Aquí está todo el detalle posible sobre el entrenamiento al estilo "para dummies". Pero Dmitry por alguna razón ignoró o no se dio cuenta de esta petición y no ha escrito tal artículo hasta ahora. Creo que mucha gente se lo agradecerá.
Dmitry escribe un artículo así, por favor.
Hay un libro de Dmitry - Conoce el libro "Redes Neuronales en Algoritmo de Trading en MQL5 "