取引における機械学習に関する記事
AIベースの取引ロボットの作成: ネイティブPythonとの統合、行列とベクトル、数学と統計のライブラリなど
取引に機械学習を使用する方法をご覧ください。ニューロン、パーセプトロン、畳み込みネットワークと再帰型ネットワーク、予測モデルなどの基本から始めて、独自のAIの開発に取り組みます。金融市場でのアルゴリズム取引のためにニューラル ネットワークを訓練して適用する方法を学びます。
新しい記事を追加

取引の機会を逃しています。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索

知っておくべきMQL5ウィザードのテクニック(第10回):型破りなRBM
制限ボルツマンマシン(Restrictive Boltzmann Machine、RBM)は、基本的なレベルでは、次元削減による教師なし分類に長けた2層のニューラルネットワークです。その基本原理を採用し、常識にとらわれない方法で設計し直して訓練すれば有用なシグナルフィルタが得られるかどうかを検証します。

母集団最適化アルゴリズム:2進数遺伝的アルゴリズム(BGA)(第1回)
この記事では、2進数遺伝的アルゴリズムやその他の集団アルゴリズムで使用されるさまざまな手法を探ります。選択、交叉、突然変異といったアルゴリズムの主な構成要素と、それらが最適化に与える影響について見ていきます。さらに、データの表示手法と、それが最適化結果に与える影響についても研究します。
ニューラルネットワークが簡単に(第45回):状態探索スキルの訓練
明示的な報酬関数なしに有用なスキルを訓練することは、階層的強化学習における主な課題の1つです。前回までに、この問題を解くための2つのアルゴリズムを紹介しましたが、環境調査の完全性についての疑問は残されています。この記事では、スキル訓練に対する異なるアプローチを示します。その使用は、システムの現在の状態に直接依存します。
母集団最適化アルゴリズム:2進数遺伝的アルゴリズム(BGA)(第2回)
この記事では、自然界の生物の遺伝物質で起こる自然なプロセスをモデル化した2進数遺伝的アルゴリズム(binary genetic algorithm:BGA)を見ていきます。

母集団最適化アルゴリズム:SSG(Saplings Sowing and Growing up、苗木の播種と育成)
SSG(Saplings Sowing and Growing up、苗木の播種と育成)アルゴリズムは、様々な条件下で優れた生存能力を発揮する、地球上で最も回復力のある生物の1つからインスピレーションを得ています。

知っておくべきMQL5ウィザードのテクニック(第09回):K平均法とフラクタル波の組み合わせ
K平均法では、まず無作為に生成されたクラスタ重心を使用するデータセットのマクロビューに焦点を当てたプロセスとしてデータポイントを集団化するアプローチを採用し、その後ズームインしてこれらの重心を調整してデータセットを正確に表現します。これを見て、その使用例をいくつか活用していきます。

初心者のためのMQL5によるSP500取引戦略
MQL5を活用してS&P500指数を正確に予測する方法をご紹介します。古典的なテクニカル分析とアルゴリズム、そして長年の経験に裏打ちされた原理を組み合わせることで、安定性を高め、確かな市場洞察力を得られます。

ニューラルネットワークが簡単に(第64回):ConserWeightive Behavioral Cloning (CWBC)法
以前の記事でおこなったテストの結果、訓練された戦略の最適性は、使用する訓練セットに大きく依存するという結論に達しました。この記事では、モデルを訓練するための軌道を選択するための、シンプルかつ効果的な手法を紹介します。

母集団最適化アルゴリズム:Intelligent Water Drops (IWD)アルゴリズム
この記事では、無生物由来の興味深いアルゴリズム、つまり川床形成プロセスをシミュレーションするIntelligent Water Drops (IWD)について考察しています。このアルゴリズムのアイデアにより、従来の格付けのリーダーであったSDSを大幅に改善することが可能になりました。いつものように、新しいリーダー(修正SDSm)は添付ファイルにあります。


母集団最適化アルゴリズム:群鳥アルゴリズム(BSA)
本稿では、自然界における鳥の群れの集団的な相互作用に着想を得た、鳥の群れに基づくアルゴリズム(BSA)を探求します。飛行、警戒、採餌行動の切り替えなど、BSAの個体にはさまざまな探索戦略があるため、このアルゴリズムは多面的なものとなっています。鳥の群れ、コミュニケーション、適応性、先導と追随の原理を利用し、効率的に最適解を見つけます。

機械学習の限界を克服する(第3回):既約誤差に関する新たな視点
本記事では、モデルがおこなうすべての予測に密かに影響を与える、隠れた幾何学的誤差の源に新たな視点を提供します。取引における機械学習予測の評価方法と活用法を再考することで、従来見過ごされてきたこの視点が、より鋭い意思決定、より高いリターン、そして、すでに理解していると思っていたモデルをより賢く活用する道を開くことを示します。

ニューラルネットワークが簡単に(第68回):オフライン選好誘導方策最適化
最初の記事で強化学習を扱って以来、何らかの形で、環境の探索と報酬関数の決定という2つの問題に触れてきました。最近の記事は、オフライン学習における探索の問題に費やされています。今回は、作者が報酬関数を完全に排除したアルゴリズムを紹介したいと思います。

知っておくべきMQL5ウィザードのテクニック(第28回):学習率に関する入門書によるGANの再検討
学習率(Learning Rate)とは、多くの機械学習アルゴリズムの学習プロセスにおいて、学習目標に向かうステップの大きさのことです。以前の記事で検証したニューラルネットワークの一種である生成的敵対的ネットワーク(GAN: Generative Adversarial Network)のパフォーマンスに、その多くのスケジュールと形式が与える影響を検証します。

知っておくべきMQL5ウィザードのテクニック(第21回):経済指標カレンダーデータによるテスト
経済指標カレンダーのデータは、デフォルトではストラテジーテスターのエキスパートアドバイザー(EA)でテストすることはできません。この制限を回避するために、データベースがどのように役立つかを考察します。そこでこの記事では、SQLiteデータベースを使用して経済指標カレンダーのニュースをアーカイブし、ウィザードで組み立てられたEAがこれを使用して売買シグナルを生成できるようにする方法を探ります。

ニューラルネットワークが簡単に(第66回):オフライン学習における探索問題
モデルは、用意された訓練データセットのデータを使用してオフラインで訓練されます。一定の利点がある反面、環境に関する情報が訓練データセットのサイズに大きく圧縮されてしまうというマイナス面もあります。それが逆に、探求の可能性を狭めています。この記事では、可能な限り多様なデータで訓練データセットを埋めることができる方法について考えます。

人工散布アルゴリズム(ASHA)
この記事では、一般的な最適化問題を解決するために開発された新しいメタヒューリスティック手法、人工散布アルゴリズム(ASHA: Artificial Showering Algorithm)を紹介します。ASHAは、水の流れと蓄積のプロセスをシミュレーションすることで、各リソース単位(水)が最適解を探索する「理想フィールド」という概念を構築します。本稿では、ASHAがフローと蓄積の原理をどのように適応させ、探索空間内でリソースを効率的に割り当てるかを解説し、その実装およびテスト結果を紹介します。

知っておくべきMQL5ウィザードのテクニック(第08回):パーセプトロン
パーセプトロン(単一隠れ層ネットワーク)は、基本的な自動取引に精通していて、ニューラルネットワークを試してみようとしている人にとって、優れた入門編となります。エキスパートアドバイザー(EA)用のMQL5ウィザードクラスの一部であるシグナルクラスアセンブリでこれをどのように実現できるかを段階的に見ていきます。

知っておくべきMQL5ウィザードのテクニック(第45回):モンテカルロ法による強化学習
モンテカルロは、ウィザードで組み立てられたエキスパートアドバイザー(EA)における実装を検討するために取り上げる、強化学習の4つ目の異なるアルゴリズムです。ランダムサンプリングに基づいていますが、多様なシミュレーション手法を活用できる点が特徴です。

母集団最適化アルゴリズム:社会集団の進化(ESG)
多母集団アルゴリズムの構成原理を考えます。この種のアルゴリズムの一例として、新しいカスタムアルゴリズムであるESG (Evolution of Social Groups)を見てみましょう。このアルゴリズムの基本概念、母集団相互作用メカニズム、利点を分析し、最適化問題におけるパフォーマンスを検証します。

古典的な戦略を再構築する(第10回):AIはMACDを強化できるか?
MACDインジケーターを経験的に分析し、インジケーターを含む戦略にAIを適用することで、EURUSDの予測精度が向上するかどうかをテストします。さらに、インジケーター自体が価格より予測しやすいのか、またインジケーターの値が将来の価格水準を予測できるのかも同時に評価します。これにより、AI取引戦略にMACDを統合することに投資する価値があるかどうかを判断するための情報を提供します。
細菌走化性最適化(BCO)
この記事では、細菌走化性最適化(BCO)アルゴリズムのオリジナルバージョンとその改良版を紹介します。新バージョン「BCOm」では、細菌の移動メカニズムを簡素化し、位置履歴への依78ytf存を軽減するとともに、計算負荷の大きかった元のバージョンに比べて、より単純な数学的手法を採用しています。この記事では両者の違いを詳しく検討し、とくにBCOmの特徴に焦点を当てます。また、テストを実施し、その結果をまとめます。

既存のMQL5取引戦略へのAIモデルの統合
このトピックでは、強化学習モデル(LSTMなど)や機械学習ベースの予測モデルのような訓練済みAIモデルを、既存のMQL5取引戦略に組み込むことに焦点を当てています。

知っておくべきMQL5ウィザードのテクニック(第11回):ナンバーウォール
ナンバーウォールは、リニアシフトバックレジスタの一種で、収束を確認することにより、予測可能な数列を事前にスクリーニングします。これらのアイデアがMQL5でどのように役立つかを見ていきます。

知っておくべきMQL5ウィザードのテクニック(第49回):近接方策最適化による強化学習
近接方策最適化は、強化学習におけるアルゴリズムの一つで、モデルの安定性を確保するために、しばしばネットワーク形式で非常に小さな増分で方策を更新します。前回の記事と同様に、ウィザードで作成したエキスパートアドバイザー(EA)において、これがどのように役立つかを探ります。

ダーバスボックスブレイクアウト戦略における高度な機械学習技術の探究
ニコラス・ダーバスによって考案された「ダーバスボックスブレイクアウト戦略」は、株価が一定の「ボックス」レンジを上抜けたときに強い上昇モメンタムが示唆されることから、買いシグナルを見極めるためのテクニカル取引手法です。本記事では、この戦略コンセプトを例として用い、機械学習の3つの高度な技術を探っていきます。それは、取引をフィルタリングするのではなくシグナルを生成するために機械学習モデルを使用すること、離散的ではなく連続的なシグナルを用いること、異なる時間枠で学習されたモデルを使って取引を確認すること、の3点です。

コードロックアルゴリズム(CLA)
この記事では、コードロックを単なるセキュリティメカニズムとしてではなく、複雑な最適化問題を解くためのツールとして再考し、新たな視点から捉えます。セキュリティ装置にとどまらず、最適化への革新的アプローチのインスピレーション源となるコードロックの世界をご紹介します。各ロックが特定の問題の解を表す「ロック」の母集団を作り、機械学習や取引システム開発など様々な分野でこれらのロックを「ピッキング」し、最適解を見つけるアルゴリズムを構築します。

ニューラルネットワークが簡単に(第72回):ノイズ環境における軌道予測
前回説明した目標条件付き予測符号化(GCPC)法では、将来の状態予測の質が重要な役割を果たします。この記事では、金融市場のような確率的環境における予測品質を大幅に向上させるアルゴリズムを紹介したいとおもいます。
データサイエンスとML(第41回):YOLOv8を用いた外国為替および株式市場のパターン検出
金融市場でパターンを検出するのは、チャート上の内容を確認する必要があるため困難ですが、これは画像の制限によりMQL5では実行が困難です。この記事では、最小限の労力でチャート上のパターンを検出するのに役立つ、Pythonで作成された適切なモデルについて説明します。
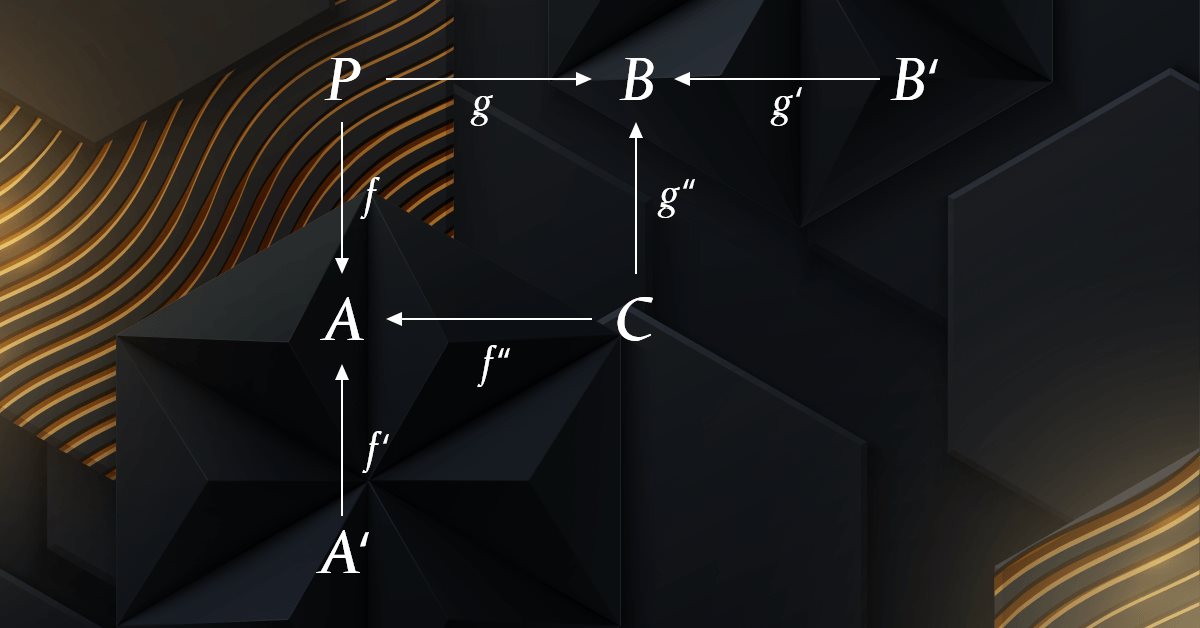
MQL5の圏論(第4回):スパン、実験、合成
圏論は数学の一分野であり、多様な広がりを見せていますが、MQL5コミュニティでは今のところ比較的知られていません。この連載では、その概念のいくつかを紹介して考察することで、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。

Candlestick Trend Constraintモデルの構築(第9回):マルチ戦略エキスパートアドバイザー(I)
今日は、MQL5を使って複数の戦略をエキスパートアドバイザー(EA)に組み込む可能性を探ります。EAは、指標やスクリプトよりも幅広い機能を提供し、変化する市場環境に適応できる、より洗練された取引アプローチを可能にします。詳しくは、この記事のディスカッションをご覧ください。

未来のトレンドを見通す鍵としての取引量ニューラルネットワーク分析
この記事では、テクニカル分析の原理とLSTMニューラルネットワークの構造を統合することで、取引量分析に基づく価格予測の改善可能性を探ります。特に、異常な取引量の検出と解釈、クラスタリングの活用、および機械学習の文脈における取引量に基づく特徴量の作成と定義に注目しています。

機械学習の限界を克服する(第9回):自己教師あり学習を用いた金融における相関ベース特徴学習
自己教師あり学習は、観測値そのものから生成された教師信号を探索する統計学習の強力なパラダイムです。このアプローチは、教師なし学習における困難な問題を、より馴染みのある教師あり学習問題へと再定式化します。この技術は、アルゴリズムトレーダーコミュニティの目的に対して、見過ごされてきた応用可能性を持っています。したがって本記事の議論は、読者に対して自己教師あり学習という未開拓の研究領域への橋渡しを提供し、さらに小規模データセットへの過学習を回避しながら、金融市場の頑健で信頼性の高い統計モデルを提供する実践的応用を提示することを目的としています。

MQL5の圏論(第21回):LDAによる自然変換
連載21回目となるこの記事では、自然変換と、線形判別分析を使ったその実装方法について引き続き見ていきます。前回同様、シグナルクラス形式でその応用例を紹介します。

PythonとMQL5における局所的特徴量選択の適用
この記事では、Narges Armanfardらの論文「Local Feature Selection for Data Classification」で提案された特徴量選択アルゴリズムを紹介します。このアルゴリズムはPythonで実装されており、MetaTrader 5アプリケーションに統合可能なバイナリ分類モデルの構築に使用されます。

機械学習の限界を克服する(第1回):相互運用可能な指標の欠如
私たちのコミュニティがAIをあらゆる形態で活用した信頼性の高い取引戦略を構築しようとする努力を、静かに蝕んでいる強力で広範な力があります。本稿では、私たちが直面している問題の一部は、「ベストプラクティス」に盲目的に従うことに根ざしていることを明らかにします。読者に対して、実際の市場に基づくシンプルな証拠を提供することで、なぜそのような行動を避け、むしろドメイン固有のベストプラクティスを採用すべきかを論理的に示します。これによって、私たちのコミュニティがAIの潜在的な可能性を回復するチャンスを少しでも持てるようになるのです。

データサイエンスとML(第33回):MQL5におけるPandas DataFrame、ML使用のためのデータ収集が簡単に
機械学習モデルを使用する際は、学習・検証・テストに使用するデータの一貫性を確保することが重要です。この記事では、MQL5の外部(多くの学習がおこなわれる環境)とMQL5内部の両方で同じデータを利用できるようにするため、MQL5で独自のPandasライブラリを作成します。

Pythonでの見せかけの回帰
見せかけの回帰は、2つの時系列がまったくの偶然で高い相関を示し、回帰分析で誤解を招く結果をもたらす場合に発生します。このような場合、変数が関連しているように見えても、その相関関係は偶然であり、モデルの信頼性は低くなります。

時間進化移動アルゴリズム(TETA)
これは私自身のアルゴリズムです。本記事では、並行宇宙や時間の流れの概念に着想を得た「時間進化移動アルゴリズム(TETA: Time Evolution Travel Algorithm)」を紹介します。本アルゴリズムの基本的な考え方は、従来の意味でのタイムトラベルは不可能であるものの、異なる現実に至る一連の出来事の順序を選択することができるという点にあります。
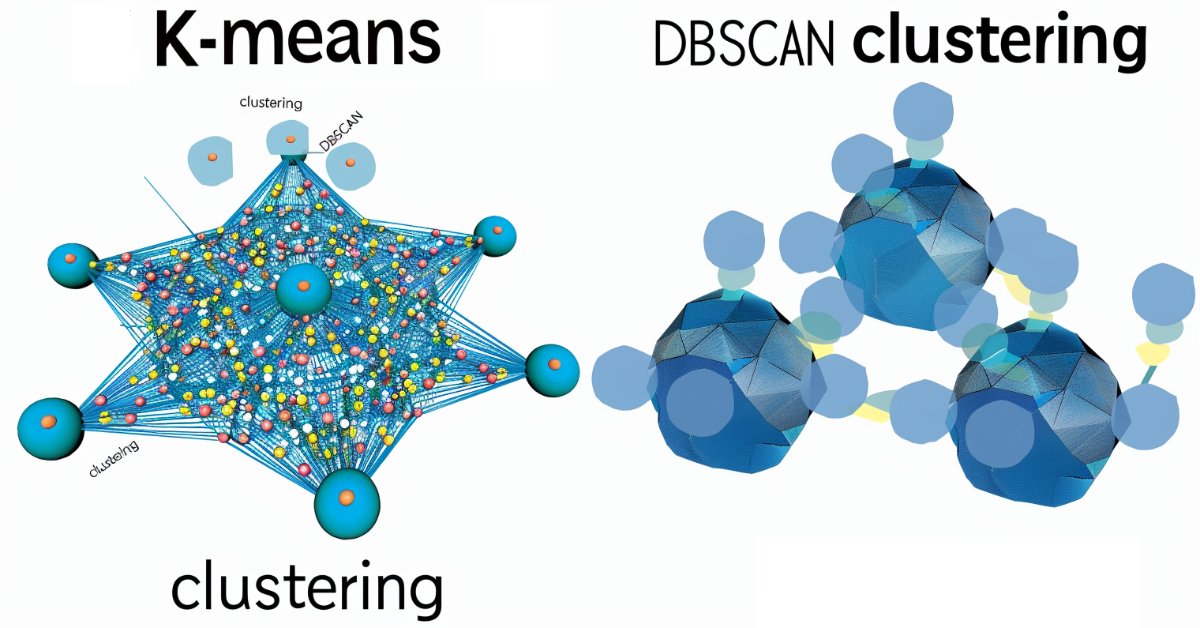
知っておくべきMQL5ウィザードのテクニック(第13回):ExpertSignalクラスのためのDBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)は、データをグループ化する教師なし形式であり、入力パラメータをほとんど必要としません。入力パラメータは2つだけであり、K平均法などの他のアプローチと比較すると利点が得られます。ウィザードで組み立てたEAを使用してテストし、最終的に取引するために、これがどのように建設的であり得るかを掘り下げます。