
データサイエンスとML(第30回):株式市場を予測するパワーカップル、畳み込みニューラルネットワーク(CNN)と再帰型ニューラルネットワーク(RNN)

内容
はじめに
これまでの記事では、畳み込みニューラルネットワーク(CNN)と再帰型ニューラルネットワーク(RNN)それぞれがどれほど強力であるか、また、貴重な売買シグナルを提供することで市場を打ち負かすためにどのように活用できるかを見てきました。
今回の記事では、CNNとRNNという2つの最も強力な技術を組み合わせ、株式市場における予測精度にどのような影響を与えるかを観察します。ただし、その前に、CNNとRNNの概要について簡単に理解しておきましょう。
畳み込みニューラルネットワーク(CNN)と再帰型ニューラルネットワーク(RNN)について
畳み込みニューラルネットワーク(CNN)は、もともと画像認識タスクのために開発されたものの、データ内のパターンや特徴を認識するよう設計されています。そのため、時系列予測のために特別に構造化された表形式データにおいても優れた性能を発揮します。
以前の記事で述べたように、CNNはまず入力データにフィルタを適用し、次に予測に役立つ高レベルの特徴を抽出します。株式市場データの場合、これらの特徴にはトレンド、季節的な効果、そして異常値が含まれます。

CNNアーキテクチャ
CNNの階層的な性質を活用することで、データ表現の階層構造を明らかにし、それぞれの層が市場のさまざまな側面についての洞察を提供します。
一方、再帰型ニューラルネットワーク(RNN)は、時系列データや言語、動画などの一連のデータに含まれるパターンを認識するために設計されています。
従来のニューラルネットワークが入力を互いに独立したものと仮定するのに対し、RNNは連続するデータからパターンを検出し、理解することが可能です。

RNNは連続データの解析に特化しており、以前の入力を記憶するアーキテクチャを備えています。そのため、データ内の時間的依存性を把握でき、特に株式市場の予測など時系列データの分析に非常に適しています。正確な予測には、こうした時間的依存性の理解が不可欠です。
連載第25回で説明したように、RNNには、バニラ再帰型ニューラルネットワーク(RNN)、長期短期記憶(LSTM)ネットワーク、ゲート付き回帰型ユニット(GRU)の3つの(一般的に使用される)特定のタイプがあります。
CNNはデータから特徴を抽出し検出することに優れていますが、RNNはこれらの特徴を時系列にわたって解釈することに長けています。この2つを組み合わせることで、株式市場におけるより良い予測が可能な強力で堅牢なモデルを構築できるかどうかを探るというのが、今回の取り組みのアイデアです。
CNNとRNNの相乗効果
この2つを統合するために、3つのステップでモデルを作成します。
- CNNによる特徴量抽出
- RNNによる時間モデリング
- 訓練して予測を得る
このRNNとLSTMの両方からなるロバストモデルを、順を追って構築していきましょう。
01:CNNによる特徴量抽出
CNNモデルはデータを処理し、重要なパターンを識別し、関連する特徴量を抽出します。
始値、高値、安値、終値で構成されるテスラ株式データセットを使用しました。まず、CNNやRNNが許容する3D時系列フォーマットにデータを準備することから始めましょう。
分類問題のターゲット変数を作ってみましょう。
Pythonコード
target_var = [] open_price = new_df["Open"] close_price = new_df["Close"] for i in range(len(open_price)): if close_price[i] > open_price[i]: # Closing price is greater than opening price target_var.append(1) # buy signal else: target_var.append(0) # sell signal
StandardScalerを使用してデータを正規化し、ML目的に対してロバストにします。
X = new_df.iloc[:, :-1] y = target_var # Scalling the data scaler = StandardScaler() X = scaler.fit_transform(X) # Train-test split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) print(f"x_train = {X_train.shape} - x_test = {X_test.shape}\n\ny_train = {len(y_train)} - y_test = {len(y_test)}")
出力
x_train = (799, 3) - x_test = (200, 3) y_train = 799 - y_test = 200
次に、データを時系列形式に準備することができます。
# creating the sequence
X_train, y_train = create_sequences(X_train, y_train, time_step)
X_test, y_test = create_sequences(X_test, y_test, time_step) これは分類問題なので、ターゲット変数を一発符号化します。
from tensorflow.keras.utils import to_categorical
y_train_encoded = to_categorical(y_train)
y_test_encoded = to_categorical(y_test)
print(f"One hot encoded\n\ny_train {y_train_encoded.shape}\ny_test {y_test_encoded.shape}") 出力
One hot encoded y_train (794, 2) y_test (195, 2)
特徴抽出はCNNモデル自身がおこないます。先ほど用意した生データをモデルに与えてみましょう。
model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2))
02:RNNによる時間モデリング
前のステップで抽出された特徴量はRNNモデルに渡されます。モデルは、データ内の時間的順序と依存関係を考慮しながら、これらの特徴量を処理します。
本連載第27回で使用したCNNモデルアーキテクチャとは異なり、Flatten層の直後に全結合ニューラルネットワーク層を使用しました。今回は、これらの通常のニューラルネットワーク(NN)層を再帰型ニューラルネットワーク(RNN)層に置き換えます。
CNNアーキテクチャ画像に見られる「Flatten層」の削除も忘れてはいけません。
RNN(バニラRNN、LSTM、GRU)は、(バッチサイズ、時間ステップ、特徴量)の形で3D入力データを期待する一方で、この層は通常、3D入力を2D出力に変換するために使用されるため、CNNアーキテクチャのFlatten層を削除します。
model.add(MaxPooling1D(pool_size=2)) model.add(SimpleRNN(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # Softmax for binary classification (1 buy, 0 sell signal)
03:訓練して予測を得る
最後に、前の2つのステップで構築したモデルの訓練に進み、その後、モデルを検証し、そのパフォーマンスを測定し、予測値を得ます。
Pythonコード
model.summary()
# Compile the model
optimizer = Adam(learning_rate=0.0001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
history = model.fit(X_train, y_train_encoded, epochs=1000, batch_size=16, validation_split=0.2, callbacks=[early_stopping])
plt.figure(figsize=(7.5, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.savefig("training loss curve-rnn-cnn-clf.png")
plt.show()
# Evaluating the Trained Model
y_pred = model.predict(X_test)
classes_in_y = np.unique(y)
y_pred_binary = classes_in_y[np.argmax(y_pred, axis=1)]
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix RNN + CNN.png") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary))
出力
14エポック後にモデルを評価した結果、テストデータに対するモデルの精度は54%でした。

7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step Classification Report precision recall f1-score support 0 0.70 0.40 0.51 117 1 0.45 0.74 0.56 78 accuracy 0.54 195 macro avg 0.58 0.57 0.54 195 weighted avg 0.60 0.54 0.53 195
最終的なモデルの訓練は、層を増やすと時間がかかることは特筆に値するが、これは組み合わせた2つのモデルの複雑な性質によるものです。
訓練の後、最終モデルをONNX形式で保存しなければなりませんでした。
Pythonコード
onnx_file_name = "rnn+cnn.TSLA.D1.onnx" spec = (tf.TensorSpec((None, time_step, X_train.shape[2]), tf.float16, name="input"),) model.output_names = ['outputs'] onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13) # Save the ONNX model to a file with open(onnx_file_name, "wb") as f: f.write(onnx_model.SerializeToString())
StandardScalerのパラメータも忘れずに保存します。
# Save the mean and scale parameters to binary files scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin") scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
保存したONNXモデルをNetronで開きました。これは巨大なものです。

以前、畳み込みニューラルネットワーク(CNN)を導入したときと同じように、同じライブラリを使って、MQL5でこの巨大なモデルを楽に読み込む作業を支援することができます。
#include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler; //from preprocessing.mqh
しかしその前に、ONNXモデルとStandardScalerパラメータをリソースとしてエキスパートアドバイザー(EA)に追加しなければなりません。
#resource "\\Files\\rnn+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\rnn+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[]
OnInit関数の中で最初にしなければならないことは、この2つ(StandardScalerとCNNモデル)を初期化することです。
int OnInit() { //--- if (!cnn.Init(onnx_model)) //Initialize the Convolutional neural network return INIT_FAILED; scaler = new StandardizationScaler(standardization_mean, standardization_std); //Initialize the saved scaler by populating it with values ... ... return (INIT_SUCCEEDED); }
予測を得るためには、このプリロードされたスケーラーを使って入力データを正規化しなければなりません。次に、正規化されたデータをCNNモデルに適用し、予測された信号と確率を得ます。
if (NewBar()) //Trade at the opening of a new candle { CopyRates(Symbol(), PERIOD_D1, 1, time_step, rates); for (ulong i=0; i<x_data.Rows(); i++) { x_data[i][0] = rates[i].open; x_data[i][1] = rates[i].high; x_data[i][2] = rates[i].low; } //--- x_data = scaler.transform(x_data); //Normalize the data int signal = cnn.predict_bin(x_data, classes_in_data_); //getting a trading signal from the RNN model vector probabilities = cnn.predict_proba(x_data); //probability for each class Comment("Probability = ",probabilities,"\nSignal = ",signal);
以下は、このコメントがチャート上でどのように見えるかです。

確率ベクトルは、訓練データのターゲット変数に存在したクラスに依存します。訓練データから、売りシグナルが0、買いシグナルが1を示すターゲット変数を用意しました。クラスの識別子または番号は昇順でなければなりません。
input int time_step = 5; input int magic_number = 24092024; input int slippage = 100; MqlRates rates[]; matrix x_data(time_step, 3); //3 columns for open, high and low vector classes_in_data_ = {0, 1}; //unique target variables as they are in the target variable in your training data int OldNumBars = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //---
x_dataという行列は、市場からの独立変数(特徴量)を一時的に格納する役割を担っています。この行列は、3つの特徴量(Open、High、Low)でモデルを訓練したため、3列にサイズ変更され、時間ステップ値と同じ行数にリサイズされます。
時間ステップの値は、逐次学習データを作成する際に使用したものと同様でなければなりません。
構築したモデルが提供するシグナルに基づいて、簡単な戦略を立てることができます。
double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { ClosePos(POSITION_TYPE_SELL); //close sell trades when the signal is buy if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions { if (!m_trade.Buy(min_lot, Symbol(), ticks.ask, 0 , 0)) //Open a buy trade printf("Failed to open a buy position err=%d",GetLastError()); } } else if (signal==0) //Bearish signal { ClosePos(POSITION_TYPE_BUY); //close all buy trades when the signal is sell if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions { if (!m_trade.Sell(min_lot, Symbol(), ticks.bid, 0 , 0)) //open a sell trade printf("Failed to open a sell position err=%d",GetLastError()); } } else //There was an error return;
モデルがロードされ、予測をおこなう準備ができたので、2020.01.01から2024.09.01までテストをおこないました。以下はテスターの完全な構成画像です。
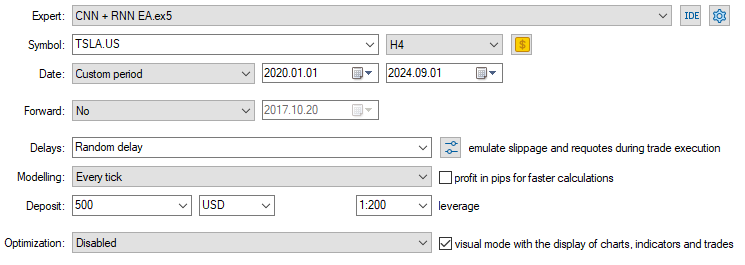
テスラの株価データが収集された日足ではなく、4時間足チャートにEAを適用したことに注目してください。これは、新しいローソク足が開いた瞬間に戦略とモデルが起動するようにプログラムされているためですが、通常、日足のローソク足は市場が閉じたときに開かれるため、EAが翌日まで取引できない原因となっています。
EAを下位時間枠(この場合は4時間枠)に適用することで、4時間ごとに継続的に市場を監視し、いくつかの取引活動をおこなうことを保証します。
CopyRates関数を日足時間枠に適用したため、EAに提供されるデータには影響しません(取引判断は依然として日足チャートに依存します)。
以下はテスターの結果です。
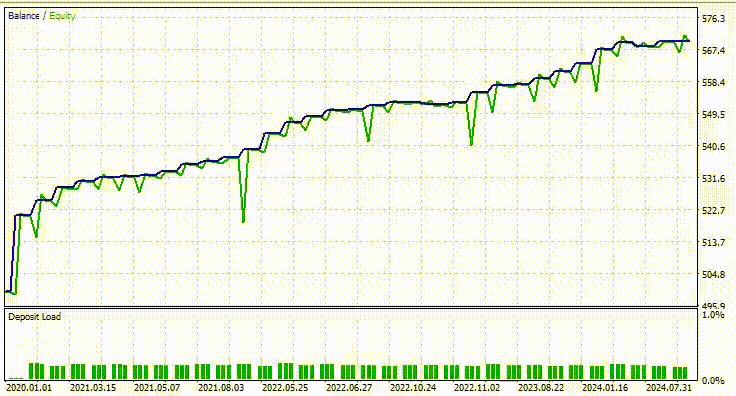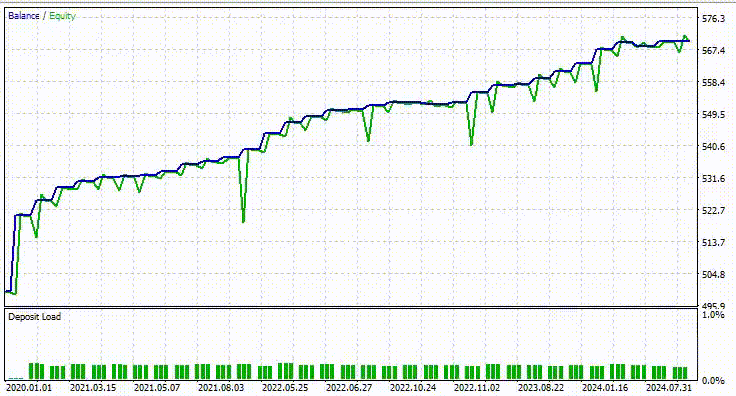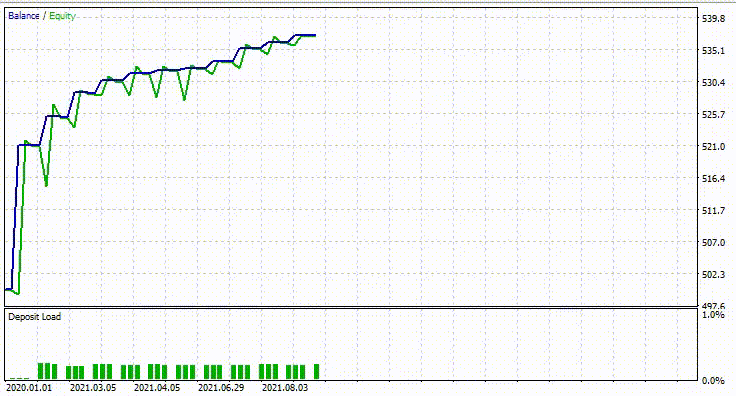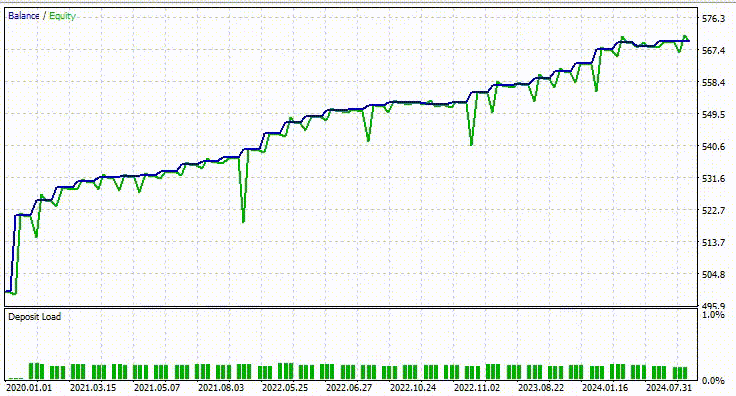
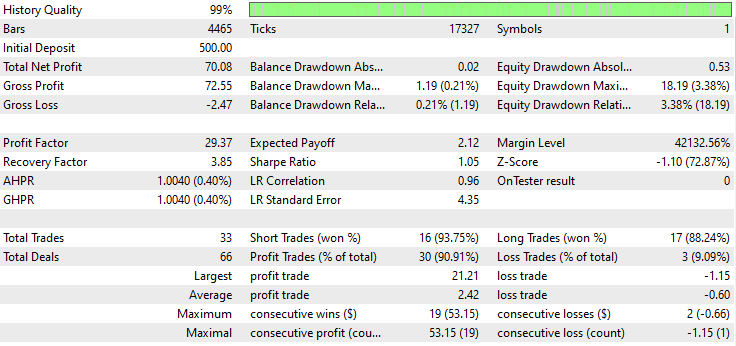
印象的です。このEAは90%の利益を上げています。AIモデルは単なる単純RNNでした。
では、LSTMとGRUが同じ市場でどの程度のパフォーマンスを発揮するか見てみましょう。
畳み込みニューラルネットワーク(CNN)と長期短期記憶(LSTM)ネットワークの組み合わせ
長いデータ列や情報のパターンを理解することができない単純RNNとは異なり、LSTMは長い情報列の関係やパターンを理解することができます。
LSTMは多くの場合、単純RNNよりも効率的で正確です。LSTMを組み込んだCNNモデルを作成し、テスラ株での結果を観察してみましょう。
Pythonコード
from tensorflow.keras.layers import LSTM # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(LSTM(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
RNNはすべて同じ方法で実装できるため、単純RNNを作成するために使用するコードブロックに1つだけ変更を加える必要がありました。
モデルの訓練と検証の結果、テストデータでの精度は53%でした。
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 36ms/step Classification Report precision recall f1-score support 0 0.67 0.44 0.53 117 1 0.45 0.68 0.54 78 accuracy 0.53 195 macro avg 0.56 0.56 0.53 195 weighted avg 0.58 0.53 0.53 195
MQL5プログラミング言語では、単純RNN EAで使用したのと同じライブラリを使用できます。
#resource "\\Files\\lstm+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\lstm+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
残りのコードは、CNN + RNN EAと同じにしています。
前回と同じテスターの設定を使用した結果は以下の通りです。
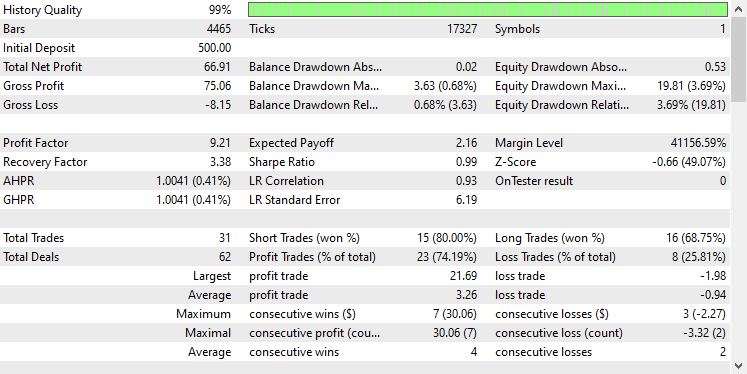
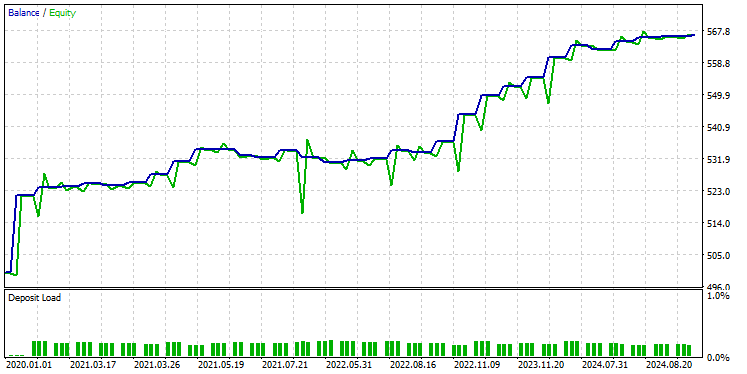
今回の全体的な取引の精度は約74%で、以前のモデルよりは低いが、それでも傑出しています。
畳み込みニューラルネットワーク(CNN)とゲート付き再帰型ユニット(GRU)ネットワークの組み合わせ
LSTMと同様に、GRUモデルもまた、LSTMモデルに比べてミニマムなアプローチであるにもかかわらず、長い情報シーケンスやデータ間の関係を理解することができます。
他のRNNモデルと同じように実装することができ、CNNモデルのアーキテクチャを構築するコードでモデルの種類を変更するだけです。
from tensorflow.keras.layers import GRU # Define the CNN model model = Sequential() model.add(Conv1D(filters=16, kernel_size=3, activation='relu', strides=2, padding='causal', input_shape=(time_step, X_train.shape[2]) ) ) model.add(MaxPooling1D(pool_size=2)) model.add(GRU(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(50, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=len(np.unique(y)), activation='softmax')) # For binary classification (e.g., buy/sell signal) model.summary()
学習と検証の結果、このモデルはテストデータにおいてLSTMと同程度の精度、53%を達成しました。
7/7 ━━━━━━━━━━━━━━━━━━━━ 1s 41ms/step Classification Report precision recall f1-score support 0 0.69 0.39 0.50 117 1 0.45 0.73 0.55 78 accuracy 0.53 195 macro avg 0.57 0.56 0.53 195 weighted avg 0.59 0.53 0.52 195
GRUモデルをONNX形式で、スケーラーパラメータをバイナリファイルでロードします。
#resource "\\Files\\gru+cnn.TSLA.D1.onnx" as uchar onnx_model[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_mean.bin" as double standardization_mean[] #resource "\\Files\\gru+cnn.TSLA.D1.standard_scaler_scale.bin" as double standardization_std[] #include <MALE5\Convolutional Neural Networks(CNNs)\ConvNet.mqh> #include <MALE5\preprocessing.mqh> CConvNet cnn; StandardizationScaler *scaler;
ここでも、残りのコードは単純RNN EAで使用したものと同じです。
このモデルをテスターで同じ設定でテストしたところ、以下のような結果になりました。
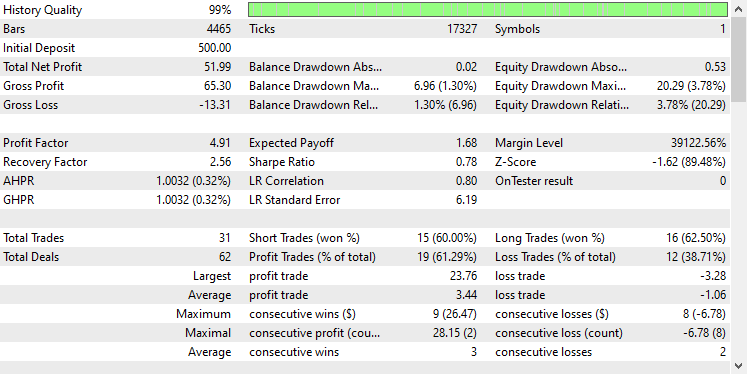
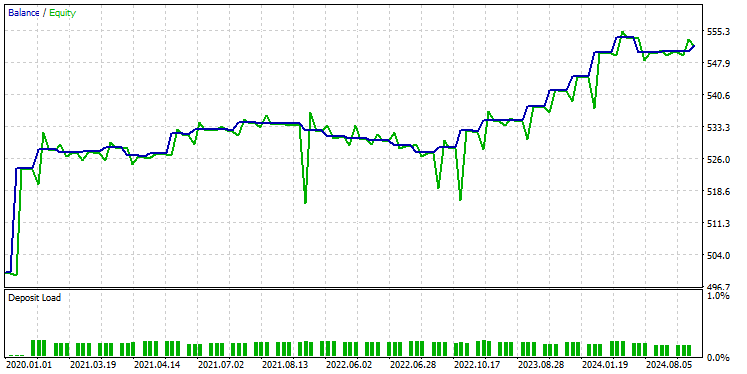
GRUモデルの精度は約61%で、先の2つのモデルほどではないが、まずまずの精度です。
最後に
畳み込みニューラルネットワーク(CNN)と再帰型ニューラルネットワーク(RNN)の統合は、株式市場予測において強力なアプローチとなり得ます。この統合は、データの隠れたパターンや時間的依存関係を明らかにする可能性を提供します。しかし、この組み合わせは比較的珍しく、いくつかの課題を伴います。主なリスクのひとつは過剰適合です。特に、比較的単純な問題にこのような高度なモデルを適用する場合、過剰適合はモデルが訓練データでは優れた性能を示す一方で、新しいデータへの汎化ができなくなる原因となります。
さらに、CNNとRNNを組み合わせることによる複雑さは、特に密な層を追加したり、ニューロンの数を増やしたりしてモデルをスケールアップする場合、大きな計算コストにつながります。モデルの複雑さと、利用可能なリソースや解決すべき問題とのバランスを注意深く取ることが不可欠です。
では、また。
機械学習モデルの開発を追跡し、本連載で説明されている多くのことは、このGitHubレポに掲載されています。
添付ファイルの表
ファイル名 | ファイルタイプ | 説明と使用法 |
|---|---|---|
Experts\CNN + GRU EA.mq5 Experts\CNN + LSTM EA.mq5 Experts\CNN + RNN EA.mq5 | EA | MetaTrader 5でONNXモデルをロードし、取引戦略をテストするための自動売買ロボット |
ConvNet.mqh preprocessing.mqh | インクルードファイル |
|
Files\ *.onnx | ONNXモデル | この記事で取り上げた機械学習モデル(ONNX形式) |
| Files\*.bin | バイナリファイル | 各モデルのStandardScalerパラメータをロードするためのバイナリファイル |
Jupyter Notebook\cnns-rnns.ipynb | python/Jupyterノートブック | この記事で説明するすべてのPythonコードは、このノートブックの中にあります。 |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15585
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索