
知っておくべきMQL5ウィザードのテクニック(第36回):マルコフ連鎖を用いたQ学習
はじめに
ウィザードで構築されたエキスパートアドバイザー(EA)のカスタムシグナルクラスには、検討する価値のある多様な役割が期待できます。本調査では、マルコフ連鎖と組み合わせたQ学習アルゴリズムが多層パーセプトロン(MLP)ネットワークの学習プロセスの改善にどのように寄与するかを追求していきます。Q学習は強化学習の複数(およそ12)のアルゴリズムの1つであるため、本稿では、これをカスタムシグナルとして実装し、ウィザードで構築したEA内でテストする方法も説明します。
この記事の構成としては、まず強化学習の基本について解説し、続いてQ学習アルゴリズムとそのサイクルステージを詳しく説明し、次にマルコフ連鎖をQ学習に統合する方法を検討し、最後にストラテジーテスターレポートで結論を示します。強化学習とは、「Actor」が関与する「環境」ごとに結果を「報酬」として定量化するサイクル(「エピソード」)から成る学習形式であるため、独立したシグナル生成器としても使用可能です。これらの用語については、以下で詳しく説明します。ただし、強化学習は生のシグナルとして使用するのではなく、MLPに補完的に用いることで学習プロセスのさらなる促進を図っています。
強化学習は教師あり学習と教師なし学習に次ぐ機械学習の第3の標準として位置付けられており、「Critic報酬」や「環境状態」などの概念を介して、ある意味で教師あり学習と教師なし学習の仲介役を果たします。そのため、MLPの損失関数にも強化学習をより多く取り入れることができると考えました。これらの用語は次のセクションで詳述しますが、この手法により、予測の多くは引き続きMLPに依存しつつも、強化学習が補助的な役割を担う形になります。また、マルコフ連鎖の導入は、Q学習アルゴリズムの「Qマップ」から「Actor」を選択する過程を補完するものであり、テスト結果に差異が見られる場合にその原因を特定する目的で含めています。
強化学習の概要
先に述べたように、強化学習は機械学習訓練における第三の柱として、訓練プロセス中に「探索」と「活用」のバランスをとる方法です。これは、各訓練ラウンド(エピソード)を評価する反復的なアプローチにより実現されます。このサイクルの全体像は、次の図で示しています。
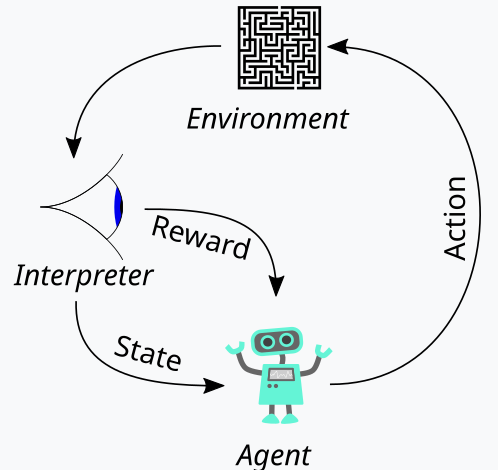
ここで、強化学習プロセスの具体的な手順について説明します。まず「エージェント」が登場します。これは、この場合MLPを代表して行動し、更新されたQ学習マップ、カーネル、または行列に基づいて最適な行動方針を選択します。 このQ学習マップは、すべての可能な環境状態の記録と、それぞれの状態における行動の確率分布です。
強化学習プロセスを説明するには、この記事で使用する環境の具体的な実装手順を順を追って確認するのが最適でしょう。トレーダーとして、私たちは市場を短期的な動きだけでなく、トレンドや長期的な特徴からも定義したいと考えます。そのため、強気・弱気・横ばいの3つの基本指標に焦点を当て、さらにこれら各指標に対して短期・長期の時間枠を設定します。つまり、「環境」は9つのインデックス空間(短期 x 長期の3 x 3行列)で構成され、インデックス0は短期・長期ともに弱気、インデックス4は短期・長期ともに横ばい、インデックス8は両方の時間枠で強気を示す構造です。
環境は、このように設定された指標空間から選択され、関連する関数を用いて実装されます。そのソースコードは次の通りです。
//+------------------------------------------------------------------+ // Indexing new Environment data to conform with states //+------------------------------------------------------------------+ void Cql::Environment(vector &E_Row, vector &E_Col, vector &E) { if(E_Row.Size() == E_Col.Size() && E_Col.Size() > 0) { E.Init(E_Row.Size()); E.Fill(0.0); for(int i = 0; i < int(E_Row.Size()); i++) { if(E_Row[i] > 0.0 && E_Col[i] > 0.0) { E[i] = 0.0; } else if(E_Row[i] > 0.0 && E_Col[i] == 0.0) { E[i] = 1.0; } else if(E_Row[i] > 0.0 && E_Col[i] < 0.0) { E[i] = 2.0; } else if(E_Row[i] == 0.0 && E_Col[i] > 0.0) { E[i] = 3.0; } else if(E_Row[i] == 0.0 && E_Col[i] == 0.0) { E[i] = 4.0; } else if(E_Row[i] == 0.0 && E_Col[i] < 0.0) { E[i] = 5.0; } else if(E_Row[i] < 0.0 && E_Col[i] > 0.0) { E[i] = 6.0; } else if(E_Row[i] < 0.0 && E_Col[i] == 0.0) { E[i] = 7.0; } else if(E_Row[i] < 0.0 && E_Col[i] < 0.0) { E[i] = 8.0; } } } }
このコードは厳密に9インデックスの環境に適用され、異なるサイズの環境行列では使用できません。この環境行列を定義するために、scaleと呼ばれる追加の入力パラメータを使用しています。このscaleは、長期フレームの期間を短期フレームのウィンドウと比例または比率で関連付けるために役立ちます。デフォルト値は5であり、これは環境行列の1つの軸上で、もう1つの軸の値が「プロット」されている期間の5倍に相当する期間にわたる価格変化をもとに、状態を強気・横ばい・弱気として分類することを意味します。「プロット」としているのは、これら2つの軸が現在の状態の座標点を示すに過ぎないからです。インデックス0から8は、この行列を単に配列に平坦化したものであり、添付のソースコードを見るとわかる通り、「行」と「列」への参照は、現在の状態を定義する環境行列からの可能なx座標とy座標の読み取りを示しています。
Q学習マップは、環境状態の配列に対し、これらの環境状態ごとに実行可能な行動へ重み付けを追加することで表現されます。この場合、各状態での3つの行動(buy、sell、またはhold)を考慮しているため、Q学習マップの各状態には、どの行動が最適かをスコアとして示す3つの配列要素が含まれています。スコアが高いほど、その行動の適性が高いことを意味します。上記のサイクル図のもう1つの重要なエンティティは、オブザーバーであり、これを「critic」と呼びます。criticはactorの行動に対する「報酬」を決定する役割を担います。報酬とは何かについては、強化学習の用途によって異なりますが、ここでは、actorの3つの行動に基づいて、価格変動による生ティック値の利益を報酬として使用しています。
たとえば、価格変動がマイナスで最後の行動がsellだった場合、その変動幅が報酬としてカウントされます。また、前回の行動がbuyで、変動がプラスだった場合も同様です。しかし、最後の行動がbuyで価格変動がマイナスだった場合、その変動幅はペナルティとして機能します。同様に、sellに続く価格変動がプラスだった場合もペナルティが適用されます。こうしたペナルティは、その特定の状態(つまり、市場の短期・長期の価格変動状況またはインデックス)での行動に対する罰則として働きます。
ただし、この報酬値は正規化する必要があり、CriticReward関数を用いて0.0から1.0の範囲に収めます。負の値は0.0から0.5に、正の値は0.5から1.0に正規化されます。この処理をおこなうコードを以下に示します。
//+------------------------------------------------------------------+ // Normalize reward via off-policy //+------------------------------------------------------------------+ double Cql::CriticReward(double MaxProfit, double MaxLoss, double Float) { double _reward = 0.0; if(MaxProfit >= Float && Float >= MaxLoss && MaxLoss < MaxProfit) { _reward = (Float - MaxLoss) / (MaxProfit - MaxLoss); } return(_reward); }
報酬値の更新は、訓練プロセスの途中で常におこなわれ、最初に1回だけおこなうわけではありません。つまり、reward-max、reward-min、reward-floatの値を更新するパラメータをバックプロパゲーション関数に常に渡し、プロセスに組み込む必要があります。これを実現するためには、まずバックプロパゲーションの実行ごとに呼び出し可能な学習変数を格納するために使用される学習構造体を変更します。構造体を使用することで、新しい変数を既存の変数リストに簡単に追加できるため、コードの変更が容易になります。これは、エラーが発生しにくい明確な方法です。対照的に、構造体内の変数を必要とする関数に入力パラメータのリストを変更する必要がある場合、扱いにくくなることは間違いありません。変更された学習構造体は次のようになります。
//+------------------------------------------------------------------+ //| Learning Struct | //+------------------------------------------------------------------+ struct Slearning { Elearning type; int epochs; double rate; double initial_rate; double prior_rate; double min_rate; double decay_rate_a; double decay_rate_b; int decay_epoch_steps; double polynomial_power; double ql_reward_max; double ql_reward_min; double ql_reward_float; vector ql_e; Slearning() { type = LEARNING_FIXED; rate = 0.005; prior_rate = 0.1; epochs = 50; initial_rate = 0.1; min_rate = __EPSILON; decay_rate_a = 0.25; decay_rate_b = 0.75; decay_epoch_steps = 10; polynomial_power = 1.0; ql_reward_max = 0.0; ql_reward_min = 0.0; ql_reward_float = 0.0; ql_e.Init(1); ql_e.Fill(0.0); }; ~Slearning() {}; };
さらに、損失関数を呼び出す際には、バックプロパゲーション関数にいくつかの変更を加える必要があります。これは、損失関数に新しいまたは従属的な列挙を導入したためです。そのコードは次のとおりです。
//+------------------------------------------------------------------+ //| Custom Loss-Function Enumerator | //+------------------------------------------------------------------+ enum Eloss { LOSS_TYPICAL = -1, LOSS_SVR = 1, LOSS_QL = 2 };
列挙の1つは「LOSS_SVR」で、これは前回の記事で取り上げたアプローチであるサポートベクター回帰を使用して損失を測定するものです。他の2つのうち1つは「LOSS_TYPICAL」損失で、これを選択するとMQL5に組み込まれている損失関数のリストがデフォルトで設定されます。もう1つは「LOSS_QL」で、QLはQ-Learning(Q学習)の略で、これを選択すると、Q学習による強化学習によってMLP予測を比較するためのターゲット(またはラベル)ベクトルが提供され、学習プロセスに通知されます。バックプロパゲーション関数内のif文は、次のようにこれをチェックします。
//+------------------------------------------------------------------+ //| BACKWARD PROPAGATION OF THE MULTI-LAYER-PERCEPTRON. | //+------------------------------------------------------------------+ //| | //| -Extra Validation check of MLP architecture settings is performed| //| at run-time. | //| Chcecking of 'validation' parameter should ideally be performed | //| at class instance initialisation. | //| | //| -Run-time Validation of learning rate, decay rates and epoch | //| index is performed as these are optimisable inputs. | //+------------------------------------------------------------------+ void Cmlp::Backward(Slearning &Learning, int EpochIndex = 1) { ... if(THIS.loss_custom == LOSS_SVR) { _last_loss = SVR_Loss(); } else if(THIS.loss_custom == LOSS_QL) { double _reward = QL.CriticReward(Learning.ql_reward_max, Learning.ql_reward_min, Learning.ql_reward_float); if(QL.act == 0) { _reward *= -1.0; } else if(QL.act == 1) { _reward = -1.0 * fabs(_reward); } QL.CriticState(_reward, Learning.ql_e); _last_loss = output.LossGradient(QL.Q_Loss(), THIS.loss_typical); } ... }
このカスタム損失関数を追加しても、MQL5内の組み込み列挙に基づいて使用されていた古い損失関数の必要性が必ずしもなくなるわけではありません。単にlossからtypical_lossに名前を変更しただけで、入力custom_lossがLOSS_TYPICALの場合は、この値を指定する必要があります。
報酬値が正規化された後、それはCriticState関数のQ学習マップを更新するために使用されます。Q値の更新は、次の式によって制御されます。
![]()
ここで
- Q(s,a):状態sで行動aを起こしたときのQ値。これは、その状態と行動のペアに対する将来の期待報酬を表しています。
- α:学習率。0から1の間の値で、新しい情報が古い情報を上書きする量を制御します。αが小さいほどエージェントの学習速度が遅くなり、αが大きいほどエージェントは最近の経験に対してより敏感になります。
- r:状態Sで行動を起こした後に受け取った直近の報酬。
- γ:将来の報酬を割り引く割引係数。0から1の間の値です。γが高いほどエージェントは長期的な報酬を重視し、γが低いほどエージェントは即時の報酬に重点を置きます。
- max a′ Q(s′,a′):次の状態s′におけるすべての可能な行動a′の最大Q値。これは、次の状態s′から始まるエージェントの最良の将来の報酬の推定を表します。
Q学習マップの実際の更新は、MQL5で次のように実装できます。
//+------------------------------------------------------------------+ // Update Q-value using off-policy (Q-learning formula) //+------------------------------------------------------------------+ void Cql::CriticState(double Reward, vector &E) { int _e_row_new = 0, _e_col_new = 0; SetMarkov(int(E[E.Size() - 1]), _e_row_new, _e_col_new); e_row[1] = e_row[0]; e_col[1] = e_col[0]; e_row[0] = _e_row_new; e_col[0] = _e_col_new; int _new_best_q = Action(); double _weighting = Q[e_row[0]][e_col[0]][_new_best_q]; if(THIS.use_markov) { LetMarkov(e_row[1], e_col[1], E); int _old_index = GetMarkov(e_row[1], e_col[1]); int _new_index = GetMarkov(e_row[0], e_col[0]); _weighting *= markov[_old_index][_new_index]; } Q[e_row[1]][e_col[1]][act] += THIS.alpha * (Reward + (THIS.gamma * _weighting) - Q[e_row[1]][e_col[1]][act]); }
マップの更新では、次の状態の最適な行動を使用して古い行動を更新する方策外更新ルールが適用されます。これは、現在の行動が次の状態で同じ更新をおこなうために使用される方策内行動とは対照的です。これは、行座標と環境行列内の列座標によって定義されるすべての状態に対して、エージェントが実行できる可能性のある行動の標準配列があるためです。Q学習で使用される方策外更新では、最適な重み付け行動が選択されますが、方策内更新を使用するアルゴリズムでは、更新の実行時に現在の行動が維持されます。最適な行動の選択は、「Action」関数によって実行されます。そのコードを以下に示します。
//+------------------------------------------------------------------+ // Choose an action using epsilon-greedy //+------------------------------------------------------------------+ int Cql::Action() { int _best_act = 0; if (double((rand() % SHORT_MAX) / SHORT_MAX) < THIS.epsilon) { // Explore: Choose random action _best_act = (rand() % THIS.actions); } else { // Exploit: Choose best action double _best_value = Q[e_row[0]][e_col[0]][0]; for (int i = 1; i < THIS.actions; i++) { if (Q[e_row[0]][e_col[0]][i] > _best_value) { _best_value = Q[e_row[0]][e_col[0]][i]; _best_act = i; } } } //update last action act = _best_act; return(_best_act); }
強化学習は、各環境状態での行動の重み付けを調整および微調整するために使用される報酬メトリックがあるという点で、教師あり学習に少し似ています。一方で、環境行列の使用は与えられた教師なし学習のようにも見えます。環境行列の座標値(行インデックスと列インデックスの2つの値)は、それを使用するMLPへの入力として機能します。したがって、MLPは、環境状態座標が入力として提示されたときに、3つの適用可能な行動の正しい確率分布を決定しようとする分類器として機能します。その後、他の分類器MLPと同様に訓練がおこなわれますが、今回は、MLPへの入力として提供されるQ学習マップ座標でのQ学習カーネルの確率分布とMLPの投影された確率分布との差を最小化することを目指します。
マルコフ遷移の役割
マルコフ連鎖は、遷移行列を使用して、これらの状態の時系列シーケンスが入力されたときに、ある状態から別の状態に移行する確率をマップする確率モデルです。これらの確率モデルは本質的にメモリレスです。次の状態に移行する確率は、現在の状態のみに基づいており、それ以前の状態の履歴には基づいていないためです。これらの遷移を使用して、環境行列内で定義されているさまざまな状態に重要性を付与できます。
ここで、カスタムシグナルの使用例の環境行列は、短期および長期の期間における強気、弱気、平坦の3つの市場状態のみを考慮し、3 x 3 行列になります。つまり、9つの状態が考えられます。状態が9つあるため、マルコフ遷移行列は、ある環境状態から別の環境状態への遷移をマップするために9 x 9 行列になります。したがって、環境行列内のインデックスのペアを、マルコフ遷移行列で使用できる単一のインデックスに変換できることが必要になります。実際には、環境行と列のインデックスのペアをマルコフ行列の単一のインデックスに変換する関数と、マルコフ遷移行列インデックスが提示されたときに環境行列の行と列のインデックスを再構築する関数の2つの関数が必要になります。これらの2つの関数は、それぞれGetMarkovとSetMarkovという名前で、そのソースは次のとおりです。まず、GetMarkovです。
//+------------------------------------------------------------------+ // Getting markov index from environment row & col //+------------------------------------------------------------------+ int Cql::GetMarkov(int Row, int Col) { return(Row + (THIS.environments * Col)); }
次にSetMarkovです。
//+------------------------------------------------------------------+ // Getting environment row & col from markov index //+------------------------------------------------------------------+ void Cql::SetMarkov(int Index, int &Row, int &Col) { Col = int(floor(Index / THIS.environments)); Row = int(fmod(Index, THIS.environments)); }
この状態から遷移するため、マルコフ計算の実行開始時に2つの環境状態座標のマルコフ等価インデックスを取得する必要があります。そのインデックスを取得したら、遷移行列のこの列に沿って他の状態に遷移する確率を取得します。それぞれが重みとして機能するためです。予想どおり、それらはすべての合計は1になり、ActorはQマップから次の状態をすでに選択しているため、その確率を分子、分母に1を使用します。つまり、学習プロセス中にQマップの新しい値を増分するための重みとして、その確率のみが使用されるということです。これを実装するソースコードは、上記のCriticState関数で既に共有されています。
この学習プロセスは、基本的にマルコフ遷移行列における確率に比例して学習増分を割り引きます。
さらに、新バーが登録され、価格の時系列が更新されるたびに、遷移行列の計算を実行します。これらの計算をおこなうためのコードを以下に示します。
//+------------------------------------------------------------------+ // Function to update markov matrix //+------------------------------------------------------------------+ void Cql::LetMarkov(int OldRow, int OldCol, vector &E) // { matrix _transitions; // Count the transitions _transitions.Init(markov.Rows(), markov.Cols()); _transitions.Fill(0.0); vector _states; // Count the occurrences of each state _states.Init(markov.Rows()); _states.Fill(0.0); // Count transitions from state i to state ii for (int i = 0; i < int(E.Size()) - 1; i++) { int _old_state = int(E[i]); int _new_state = int(E[i + 1]); _transitions[_old_state][_new_state]++; _states[_old_state]++; } // Reset prior values to zero. markov.Fill(0.0); // Compute probabilities by normalizing transition counts for (int i = 0; i < int(markov.Rows()); i++) { for (int ii = 0; ii < int(markov.Cols()); ii++) { if (_states[i] > 0) { markov[i][ii] = double(_transitions[i][ii] / _states[i]); } else { markov[i][ii] = 0.0; // No transitions from this state } } } }
メモリレスの遷移行列であるため、上記のコードは常に新しく宣言された行列で始まり、確率を保持するクラス変数もゼロ値で埋められ、以前の履歴がキャンセルされます。遷移を計算する方法は簡単です。最初のforループで各状態のシーケンスの数を取得し、その後に別のforループを実行して、各遷移で取得した累積カウントを、遷移元の状態の総数で割ります。
カスタムシグナルクラスの実装
すでに述べたように、私たちは主な予測を処理する分類器であるMLPを使用しています。強化学習は損失関数として従属的な役割のみを果たします。強化学習は、Criticの報酬を最大化することで、使用可能な取引シグナルを出力するように最適化または訓練することもできますが、ここでおこなっているのはそれではなく、その役割は多層パーセプトロンの二次的なものであり、教師あり学習と教師なし学習と同様に、目的関数を定量化するために使用されます。
MLPを使用した過去の記事と同様に、データ入力の起点として価格変動を使用しています。この記事で使用した環境行列は3 x 3行列であり、下位および上位の時間枠で重み付けされた市場の可能な状態のグリッドとして機能することを思い出してください。下位時間枠と上位時間枠にはそれぞれ、強気から横ばい、弱気までのメトリックまたは読み取り値があり、3 x 3グリッドを構成します。この行列に類似しているQ学習行列またはマップには、この3 x 3グリッドに加えて、各状態の各行動の適合性のスコアを保持する、Actorに開かれた可能な行動の配列があります。この適合性配列が、MLPのラベルまたは学習ターゲットとして機能します。
ただし、MLPへの入力は、MLPに関する最近の記事で取り上げたような生の価格変動ではなく、下位および上位の時間枠における最新または現在の価格変動の環境状態座標になります。ここでの「時間枠」の使用は、価格変動が測定される異なる時間スケールまたは期間を示すためだけに使用されています。シグナルクラスへの入力として、これらの変動の測定をガイドする2つの別個の時間枠があるのではなく、「m_scale」というラベルの付いた単一の入力整数パラメータがあり、これは「上位時間枠」が下位時間枠に対してどれだけ大きいかの倍数です。下位時間枠は単一の価格バーにわたる変動を使用するため、「上位時間枠」は、このスケール入力パラメータに相当する期間の変動の読み取りを取得します。この処理は、次のようにGetOutput関数で実行されます。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CSignalQLM::GetOutput(int &Output) { m_learning.rate = m_learning_rate; for(int i = m_epochs; i >= 1; i--) { MLP.LearningType(m_learning, i); for(int ii = m_train_set; ii >= 0; ii--) { vector _in, _in_row, _in_row_old, _in_col, _in_col_old; if ( _in_row.Init(m_scale) && _in_row.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, m_scale) && _in_row.Size() == m_scale && _in_row_old.Init(m_scale) && _in_row_old.CopyRates(m_symbol.Name(), m_period, 8, ii + 1 + 1, m_scale) && _in_row_old.Size() == m_scale && _in_col.Init(m_scale) && _in_col.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, m_scale) && _in_col.Size() == m_scale && _in_col_old.Init(m_scale) && _in_col_old.CopyRates(m_symbol.Name(), m_period, 8, m_scale + ii + 1, m_scale) && _in_col_old.Size() == m_scale ) { _in_row -= _in_row_old; _in_col -= _in_col_old; vector _in_e; _in_e.Init(m_scale); MLP.QL.Environment(_in_row, _in_col, _in_e); int _row = 0, _col = 0; MLP.QL.SetMarkov(int(_in_e[m_scale - 1]), _row, _col); _in.Init(__MLP_INPUTS); _in[0] = _row; _in[1] = _col; MLP.Set(_in); MLP.Forward(); if(ii > 0) { vector _target, _target_data; if ( _target_data.Init(2) && _target_data.CopyRates(m_symbol.Name(), m_period, 8, ii, 2) && _target_data.Size() == 2 ) { _target.Init(__MLP_OUTPUTS); _target.Fill(0.0); double _type = _target_data[0] - _in_row[1]; int _index = (_type < 0.0 ? 0 : (_type > 0.0 ? 2 : 1)); _target[_index] = 1.0; MLP.Get(_target); m_learning.ql_e = _in_e; m_learning.ql_reward_float = _in_row[m_scale - 1]; m_learning.ql_reward_max = _in_row.Max(); m_learning.ql_reward_min = _in_row.Min(); if(i == m_epochs && ii == m_train_set) { MLP.QL.Action(); } MLP.Backward(m_learning, i); } } Output = (MLP.output.Max()==MLP.output[0]?0:(MLP.output.Max()==MLP.output[1]?1:2)); } } } }
したがって、上記のソースコードからわかるように、MLP入力の座標の読み取りには4つのベクトルが必要です。これらが決定したら、2つの価格変更を単一のマルコフインデックスに変換するEnvironment関数と、マルコフインデックスからこれらの2つの座標を提供するSetMarkov関数の助けを借りて、それらを入力である「in」ベクトルに入力します。MLP分類器は、2つの入力、8サイズの隠し層、およびActorに可能な3つの行動に対応する3つの出力を表す2-8-3の非常に基本的なアーキテクチャを備えています。MLPの出力は、基本的に、ショート(インデックス0の下)、何もしない(インデックス1の下)、ロング(インデックス2の下)のいずれかの値を示す確率マップです。
強化学習の学習プロセスでは、これらの出力が各環境状態に添付された類似のベクトルからどれだけ離れているかを測定します。
ストラテジーテスターの結果
したがって、いつものように、このシグナルクラスを使用してMQL5ウィザードで組み立てられたEAが基本的な機能をどのようにおこなえるかを示すためだけに、実際のティックデータを使用して最適化とテストを実行します。MQL5ウィザードで添付コードを使用するためのガイドは、こちらとこちらにあります。組み立てられたEAまたは取引システムをライブアカウント対応にするための多くの注意深い作業は、これらの記事では扱われず、読者に委ねられています。私たちは、2023年のGBPJPYペアを日次時間枠で実行します。Q学習マップ値の重み付けの代替としてマルコフ連鎖を導入したため、マルコフ連鎖の重み付けなしと重み付けありの2つのテストを実行します。そして、結果は次のとおりです。


そして、マルコフ加重なしの結果はこうです。


これらのテスト結果は、最適な最適化設定で達成されたものではなく、これらの設定でウォークフォワードテストが実行されたものでもないため、正当な議論とより包括的なテスト体制によってその使用を主張することはできますが、Q学習によるマルコフ連鎖の補足的な使用自体を推奨するものではありません。
結論
この記事では、教師あり学習と教師なし学習という確立された方法以外の機械学習学習の代替手段である強化学習を紹介することで、MQL5ウィザードで他に何ができるかを強調しました。これを生のシグナル発生器として使用するのではなく、学習プロセスを通知およびガイドすることで、分類器MLPの学習に使用しようとしました(生のシグナル発生器として使用することも可能です)。その際、Q学習アルゴリズムに焦点を当てながら、強化学習プロセスの重みとして機能できる遷移確率行列であるマルコフ連鎖を活用し、マルコフ連鎖なしで学習した場合とマルコフ連鎖を使用して学習した場合の2つのシナリオで取引EAのテスト実行を示しました。
これは、カスタムシグナルに2つのクラスを参照し、多くの敏感な入力パラメータが大きな調整なしでデフォルト値で使用されていることを考えると、以前の記事に比べて少し複雑になっていると思います。このテーマに馴染みのない人のために、多くの新しい用語を紹介する必要があります。しかし、これは強化学習というこの幅広く奥深いテーマに取り組む始まりであり、今後の記事でこのテーマを再び取り上げるときには、それほど困難ではないことを願っています。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15743
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索