Artículos sobre análisis de datos y estadísticas en MQL5
Los artículos sobre los modelos matemáticos y leyes de probabilidades serán interesantes para muchos operadores. Es que las matemáticas han sido puestas como base de los indicadores, y el conocimiento de las estadísticas es necesario para el análisis de los resultados del trading y el desarrollo de las estrategias.
Lea sobre la lógica difusa, filtros digitales, perfil del mercado, mapas de Kohonen, gas neuronal y muchas otras herramientas que pueden ser utilizadas para el trading.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Trabajando con los precios en la biblioteca DoEasy (Parte 60): Lista de serie de datos de tick del símbolo
En este artículo, vamos a crear una lista para almacenar los datos de tick del símbolo único, después, verificaremos su creación y obtención de los datos requeridos en el Asesor Experto. Dichas listas —siendo aplicada cada una de ellas para cada símbolo usado— van a componer luego la colección de datos de tick.
Trabajando con los precios en la biblioteca DoEasy (Parte 64): Profundidad del mercado, clases del objeto de instantánea y del objeto de serie de instantáneas del DOM
En este artículo, vamos a crear dos clases: la clase del objeto de instantánea del DOM y la clase del objeto de serie de instantáneas del DOM, además, simularemos la creación de la serie de datos del DOM.

Aprendizaje automático y Data Science (Parte 24): Predicción de series temporales de divisas mediante modelos de IA convencionales
En los mercados de divisas es muy difícil predecir la tendencia futura sin tener una idea del pasado. Muy pocos modelos de aprendizaje automático son capaces de hacer predicciones futuras considerando valores pasados. En este artículo, vamos a discutir cómo podemos utilizar modelos de inteligencia artificial clásicos (no de series temporales) para superar al mercado.

Modelos de regresión no lineal en la bolsa de valores
Modelos de regresión no lineal en la bolsa de valores: ¿Es posible predecir los mercados financieros? Consideremos la creación de un modelo para pronosticar precios para EURUSD y crear dos robots basados en él: en Python y MQL5.

Marcado de datos en el análisis de series temporales (Parte 5): Aplicación y comprobación de asesores usando Socket
En esta serie de artículos, presentaremos varias técnicas de marcado de series temporales que pueden producir datos que se ajusten a la mayoría de los modelos de inteligencia artificial (IA). El marcado dirigido de datos puede hacer que un modelo de IA entrenado resulte más relevante para las metas y objetivos del usuario, mejorando la precisión del modelo y ayudando a este a dar un salto de calidad.
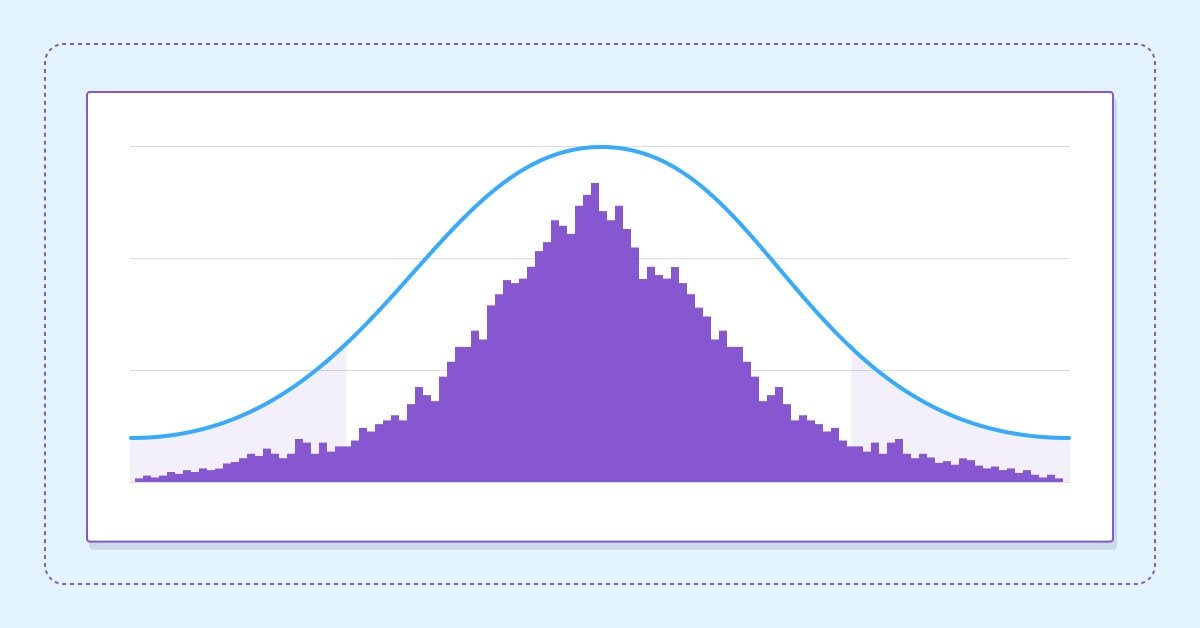
Estimamos la rentabilidad futura usando intervalos de confianza
En este artículo, nos adentraremos en la aplicación de técnicas de bootstrapping como forma de evaluar la rentabilidad futura de una estrategia automatizada.

Fibonacci en Forex (Parte I): Comprobamos la relación tiempo-precio
¿Cómo se desplaza el mercado por una relación basada en los números de Fibonacci? Esta secuencia, en la que cada número sucesivo es igual a la suma de los dos anteriores (1, 1, 2, 3, 3, 5, 8, 13, 21...), no solo describe el crecimiento de la población de conejos. Hoy vamos a analizar la hipótesis de Pitágoras de que todo en el mundo obedece a ciertas relaciones de números....

Implementando el factor Janus en MQL5
Gary Anderson desarrolló un método de análisis de mercado basado en una teoría que denominó el factor Janus. La teoría describe un conjunto de indicadores que se pueden usar para identificar tendencias y evaluar el riesgo de mercado. En este artículo, implementaremos dichas herramientas en MQL5.

Desarrollo de un sistema de repetición (Parte 28): Proyecto Expert Advisor — Clase C_Mouse (I)
Cuando los primeros sistemas capaces de factorizar algo comenzaron a ser producidos, todo requería la intervención de ingenieros con un amplio conocimiento sobre lo que se estaba diseñando. Estamos hablando de los albores de la computación, una época en la que ni siquiera existían terminales que permitieran la programación de algo. A medida que el desarrollo avanzaba y crecía el interés para que más personas pudieran crear algo, surgían nuevas ideas y métodos para programar esas máquinas, que antes dependían de la modificación de la posición de los conectores. Fue entonces cuando aparecieron los primeros terminales.

Trabajamos con matrices: ampliando la funcionalidad de la biblioteca estándar de matrices y vectores.
Las matrices sirven de base a los algoritmos de aprendizaje automático y a las computadoras en general por su capacidad para procesar con eficacia grandes operaciones matemáticas. La biblioteca estándar tiene todo lo que necesitamos, pero también podemos ampliarla añadiendo varias funciones al archivo utils.
Trabajando con los precios en la biblioteca DoEasy (Parte 59): Objeto para almacenar los datos de un tick
A partir de este artículo, procedemos a la creación de la funcionalidad de la biblioteca para trabajar con los datos de precios. Hoy, crearemos una clase del objeto que va a almacenar todos los datos de los precios que llegan con un tick.

Permutación de las barras de precio en MQL5
En este artículo, presentaremos un algoritmo de permutación de barras de precio y detallaremos cómo se pueden utilizar las pruebas de permutación para identificar los casos en los que se ha fabricado el rendimiento de la estrategia para engañar a los posibles compradores del asesor.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 15): Nacimiento del SIMULADOR (V) - RANDOM WALK
En este artículo, vamos a finalizar la fase en la que estamos desarrollando el simulador para nuestro sistema. El propósito principal aquí será ajustar el algoritmo visto en el artículo anterior. Este algoritmo tiene como objetivo crear el movimiento de RANDOM WALK. Por lo tanto, es fundamental comprender el contenido de los artículos anteriores para seguir lo que se explicará aquí. Si no has seguido el desarrollo del simulador, te aconsejo que veas esta secuencia desde el principio. De lo contrario, podrías perderte en lo que se explicará aquí.

Funciones de activación neuronal durante el aprendizaje: ¿la clave de una convergencia rápida?
En este artículo presentamos un estudio de la interacción de distintas funciones de activación con algoritmos de optimización en el contexto del entrenamiento de redes neuronales. Se presta especial atención a la comparación entre el ADAM clásico y su versión poblacional al tratar con una amplia gama de funciones de activación, incluidas las funciones oscilatorias ACON y Snake. Usando una arquitectura MLP minimalista (1-1-1) y un único ejemplo de entrenamiento, la influencia de las funciones de activación en el proceso de optimización se aísla de otros factores. Asimismo, propondremos un enfoque para controlar los pesos de la red mediante los límites de las funciones de activación y un mecanismo de reflexión de pesos que evitará los problemas de saturación y estancamiento en el aprendizaje.
Desarrollo de un sistema de repetición (Parte 41): Inicio de la segunda fase (II)
Si hasta ahora todo te ha parecido correcto, significa que no estás pensando realmente a largo plazo. Donde empiezas a desarrollar aplicaciones y, con el tiempo, ya no necesitas programar nuevas aplicaciones. Solo tienes que conseguir que trabajen juntos. Veamos cómo terminar de montar el indicador del ratón.

Características del Wizard MQL5 que debe conocer (Parte 08): Perceptrones
Los perceptrones, o redes con una sola capa oculta, pueden ser una buena opción para quienes estén familiarizados con los fundamentos del comercio automatizado y quieran sumergirse en las redes neuronales. Paso a paso veremos como se pueden implementar en el ensamblado de clases de señales que forma parte de las clases del Wizard MQL5 para asesores expertos.

Aprendizaje automático y Data Science (Parte 22): Aprovechar las redes neuronales de autocodificadores para realizar operaciones más inteligentes pasando del ruido a la señal
En el vertiginoso mundo de los mercados financieros, separar las señales significativas del ruido es crucial para operar con éxito. Al emplear sofisticadas arquitecturas de redes neuronales, los autocodificadores destacan a la hora de descubrir patrones ocultos en los datos de mercado, transformando datos ruidosos en información práctica. En este artículo, exploramos cómo los autocodificadores están revolucionando las prácticas de negociación, ofreciendo a los operadores una poderosa herramienta para mejorar la toma de decisiones y obtener una ventaja competitiva en los dinámicos mercados actuales.

Desarrollo de un sistema de repetición (Parte 31): Proyecto Expert Advisor — Clase C_Mouse (V)
Desarrollar una manera de poner un cronómetro, de modo que durante una repetición/simulación, éste pueda decirnos cuánto tiempo falta, puede parecer a primera vista una tarea simple y de rápida solución. Muchos simplemente intentarían adaptar y usar el mismo sistema que se utiliza cuando tenemos el servidor comercial a nuestro lado. Pero aquí reside un punto que muchos quizás no consideran al pensar en tal solución. Cuando estás haciendo una repetición, y esto para no hablar del hecho de la simulación, el reloj no funciona de la misma manera. Este tipo de cosa hace complejo construir tal sistema.

Simulación de mercado (Parte 06): Transfiriendo información desde MetaTrader 5 hacia Excel
A muchas personas, especialmente a los no programadores, les resulta muy difícil transferir información entre MetaTrader 5 y otros programas. Uno de esos programas es Excel. Muchos utilizan Excel para gestionar y controlar sus riesgos, ya que es un programa muy bueno y fácil de aprender, incluso para quienes no son programadores de VBA. A continuación, voy a mostrar cómo establecer la comunicación entre MetaTrader 5 y Excel (un método muy sencillo).

Algoritmo de búsqueda por vecindad — Across Neighbourhood Search (ANS)
El artículo revela el potencial del algoritmo ANS como paso importante en el desarrollo de métodos de optimización flexibles e inteligentes capaces de considerar la especificidad del problema y la dinámica del entorno en el espacio de búsqueda.

Integración de MQL5 con paquetes de procesamiento de datos (Parte 2): Aprendizaje automático (Machine Learning, ML) y análisis predictivo
En nuestra serie sobre la integración de MQL5 con paquetes de procesamiento de datos, nos adentramos en la poderosa combinación del aprendizaje automático y el análisis predictivo. Exploraremos cómo conectar a la perfección MQL5 con librerías populares de aprendizaje automático, para habilitar sofisticados modelos predictivos para los mercados financieros.

Teoría de categorías en MQL5 (Parte 7): Dominios múltiples, relativos e indexados
La teoría de categorías es un apartado diverso y en expansión de las matemáticas, que solo recientemente ha comenzado a ser trabajado por la comunidad MQL5. Esta serie de artículos tiene por objetivo repasar algunos de sus conceptos para crear una biblioteca abierta y seguir usando este maravilloso apartado en la creación de estrategias comerciales.

Desarrollo de un sistema de repetición — Simulación de mercado (Parte 18): Ticks y más ticks (II)
En este caso, es extremadamente claro que las métricas están muy lejos del tiempo ideal para la creación de barras de 1 minuto. Entonces, lo primero que realmente corregiremos es precisamente esto. Corregir la cuestión de la temporización no es algo complicado. Por más increíble que parezca, en realidad es bastante simple de hacer. Sin embargo, no realicé la corrección en el artículo anterior porque allí el objetivo era explicar cómo llevar los datos de los ticks que se estaban utilizando para generar las barras de 1 minuto en el gráfico a la ventana de observación del mercado.

Validación cruzada y fundamentos de la inferencia causal en modelos CatBoost, exportación a formato ONNX
En este artículo veremos un método de autor para crear bots utilizando el aprendizaje automático.
Redes neuronales: así de sencillo (Parte 25): Practicando el Transfer Learning
En los últimos dos artículos, hemos creado una herramienta que nos permite crear y editar modelos de redes neuronales. Ahora es el momento de evaluar el uso potencial de la tecnología de Transfer Learning en ejemplos prácticos.

Desarrollamos un asesor experto multidivisa (Parte 8): Realizamos pruebas de carga y procesamos la nueva barra
Conforme hemos ido avanzado, hemos utilizado cada vez más instancias simultáneas de estrategias comerciales en un mismo asesor experto. Hoy intentaremos averiguar a cuántas instancias podemos llegar antes de encontrarnos con limitaciones de recursos.

Información mutua como criterio para la selección de características paso a paso
En este artículo, presentamos una implementación MQL5 de selección de características paso a paso basada en la información mutua entre un conjunto de predictores óptimos y una variable objetivo.

Operar con noticias de manera sencilla (Parte 3): Ejecución de operaciones
En este artículo, nuestro experto en negociación de noticias comenzará a abrir operaciones basándose en el calendario económico almacenado en nuestra base de datos. Además, mejoraremos los gráficos del experto para mostrar información más relevante sobre los próximos acontecimientos del calendario económico.

Desarrollo de un factor de calidad para los EAs
En este artículo, te explicaremos cómo desarrollar un factor de calidad que tu Asesor Experto (EA) pueda mostrar en el simulador de estrategias. Te presentaremos dos formas de cálculo muy conocidas (Van Tharp y Sunny Harris).

Características del Wizard MQL5 que debe conocer (Parte 16): Método de componentes principales con vectores propios
En este artículo analizaremos el método de componentes principales, una técnica de reducción de la dimensionalidad para el análisis de datos, y cómo podemos aplicar este utilizando valores propios y vectores. Como siempre, intentaremos desarrollar un prototipo de la clase de señales del asesor experto que se pueda utilizar en el Wizard MQL5.

Teoría de categorías en MQL5 (Parte 21): Transformaciones naturales con ayuda de LDA
Este artículo, el número 21 de nuestra serie, continuaremos analizando las transformaciones naturales y cómo se pueden implementar mediante el análisis discriminante lineal. Como en el artículo anterior, la implementación se presentará en formato de clase de señal.

Algoritmo basado en fractales — Fractal-Based Algorithm (FBA)
Hoy veremos un nuevo método metaheurístico basado en un enfoque fractal que permite particionar el espacio de búsqueda para resolver problemas de optimización. El algoritmo identifica y separa secuencialmente las áreas prometedoras, creando una estructura fractal autosimilar que concentra los recursos computacionales en las áreas más prometedoras. El mecanismo de mutación único orientado a las mejores soluciones garantiza un equilibrio óptimo entre la exploración y la explotación del espacio de búsqueda, aumentando significativamente la eficiencia del algoritmo.

Algoritmo de Partenogénesis Cíclica - Cyclic Parthenogenesis Algorithm (CPA)
En este trabajo, analizaremos un nuevo algoritmo de optimización basado en la población, el CPA (Cyclic Parthenogenesis Algorithm), inspirado en la estrategia reproductiva única de los pulgones. El algoritmo combina dos mecanismos de reproducción: la partenogénesis y la reproducción sexual, y utiliza una estructura de población colonial con posibilidad de migración entre colonias. Las características clave del algoritmo son el cambio adaptativo entre diferentes estrategias de cría y un sistema de intercambio de información entre colonias usando un mecanismo de vuelo.

Indicador de previsión de volatilidad con Python
Hoy pronosticaremos la volatilidad extrema futura utilizando una clasificación binaria. Asimismo, crearemos un indicador de previsión de volatilidad extrema usando el aprendizaje automático.

Desarrollo de un sistema de repetición (Parte 59): Un nuevo futuro
La correcta comprensión de las cosas nos permite hacer más con menos esfuerzo. En este artículo, explicaré por qué es necesario ajustar la aplicación de la plantilla antes de que el servicio comience a interactuar realmente con el gráfico. Además, ¿qué tal si mejoramos el indicador del mouse para que podamos hacer más cosas con él?

Desarrollo de un sistema de repetición (Parte 78): Un nuevo Chart Trade (V)
En este artículo, veremos cómo deberemos implementar la parte del receptor. Es decir, aquí implementaremos una versión del Asesor Experto, solo para probar y aprender cómo funciona la comunicación vía protocolo. El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación cuya finalidad no sea el aprendizaje y el estudio de los conceptos mostrados.

De novato a experto: Sistema de análisis autogeométrico
Los patrones geométricos ofrecen a los operadores una forma concisa de interpretar la acción del precio. Muchos analistas dibujan líneas de tendencia, rectángulos y otras formas a mano y luego basan sus decisiones comerciales en las formaciones que ven. En este artículo exploramos una alternativa automatizada: aprovechar MQL5 para detectar y analizar los patrones geométricos más populares. Desglosaremos la metodología, discutiremos los detalles de implementación y destacaremos cómo el reconocimiento de patrones automatizado puede agudizar el conocimiento del mercado de un comerciante.

Aplicación de la teoría de juegos a algoritmos comerciales
Hoy crearemos un asesor comercial adaptativo de autoaprendizaje basado en DQN de aprendizaje automático, con inferencia causal multivariante, que negociará con éxito simultáneamente en 7 pares de divisas, con agentes de diferentes pares intercambiando información entre sí.
Trabajando con los precios en la biblioteca DoEasy (Parte 62): Actualización de las series de tick en tiempo real, preparando para trabajar con la Profundidad del mercado
En este artículo, vamos a desarrollar la actualización de la colección de datos de tick en tiempo real, y prepararemos una clase del objeto de símbolo para manejar la Profundidad del mercado, con la que empezaremos a trabajar a partir del siguiente artículo.

Algoritmos de optimización de la población: Algoritmo Mind Evolutionary Computation (Computación Evolutiva Mental, (MEC)
En este artículo, analizaremos un algoritmo de la familia MEC llamado algoritmo MEC Simple de evolución mental (Simple MEC, SMEC). El algoritmo se caracteriza por la belleza de la idea expuesta y su sencillez de aplicación.