
Trabajamos con matrices: ampliando la funcionalidad de la biblioteca estándar de matrices y vectores.

«Nunca alcanzará la perfección, porque siempre se puede mejorar.
Sin embargo, recorriendo el camino hacia la perfección, aprenderá a mejorar».
Introducción
La clase Utils en Python es una clase de utilidad general con funciones y líneas de código que podemos reutilizar sin crear un ejemplar de una clase.
La biblioteca estándar tiene algunas funciones y métodos muy importantes que podemos usar para la inicialización, la transformación, la manipulación y otro tipo de trabajo con matrices. Pero, al igual que, cualquier biblioteca jamás creada, puede ampliarse para realizar acciones adicionales, eventualmente necesarias en algunas aplicaciones.
En este artículo, hablaremos de las funciones y métodos que puede ver más abajo.
Contenido:
- Leer una matriz desde un archivo CSV
- Leer valores codificados desde un archivo CSV
- Escribir una matriz en un archivo CSV
- Convertir una matriz en un vector
- Convertir un vector en una matriz
- Convertir un array en un vector
- Convertir un vector en un array
- Eliminar una columna de una matriz
- Eliminar varias columnas de una matriz
- Eliminar una fila de una matriz
- Eliminar un valor de un vector
- Dividir la matriz en una matriz de entrenamiento y una matriz de prueba
- Dividir las matrices X e Y
- Crear una matriz de planificación
- Matriz de codificación con un estado activo
- Obtener clases a partir de un vector
- Crear un vector de valores aleatorios
- Añadir un vector a otro
- Copiar un vector en otro
Leer una matriz desde un archivo CSV
Se trata de una función muy importante, pues nos permite cargar sin esfuerzo bases de datos desde un archivo CSV y almacenarlas en una matriz. No es necesario insistir en la importancia de esta función, ya que al escribir código para sistemas comerciales, con frecuencia debemos cargar archivos CSV que contienen señales comerciales o una historia de transacciones a las que nuestro software debe tener acceso.
El primer paso será leer el archivo CSV. Se supone que la primera línea del archivo CSV solo contiene filas, por lo que, aunque haya valores en la primera línea, no se incluirán en la matriz. Como la matriz no puede contener valores de cadena, los valores de la primera fila se almacenarán en el array csv_header.while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(csv_header,column+1); csv_header[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); column++; //---
Esta matriz ayudará a mantener un registro de los nombres de las columnas del archivo CSV que acabamos de leer.
Código completo:
matrix CMatrixutils::ReadCsv(string file_name,string delimiter=",") { matrix mat_ = {}; int rows_total=0; int handle = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,delimiter); ResetLastError(); if(handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",file_name,GetLastError()); Print(GetLastError()==0?" TIP | File Might be in use Somewhere else or in another Directory":""); } else { int column = 0, rows=0; while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(csv_header,column+1); csv_header[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); column++; //--- if(FileIsLineEnding(handle)) { rows++; mat_.Resize(rows,column); column = 0; } } rows_total = rows; FileClose(handle); } mat_.Resize(rows_total-1,mat_.Cols()); return(mat_); }
Uso:
Aquí tenemos el archivo CSV que queremos cargar en la matriz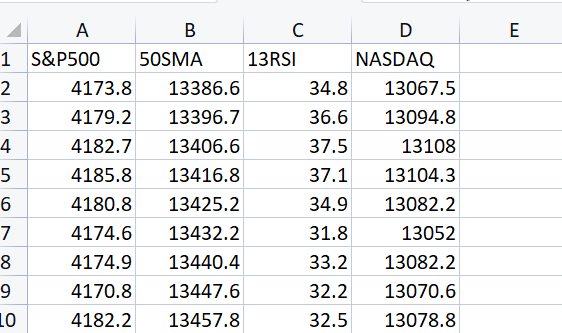
Cargamos un archivo CSV en una matriz:
Print("---> Reading a CSV file to Matrix\n"); Matrix = matrix_utils.ReadCsv("NASDAQ_DATA.csv"); ArrayPrint(matrix_utils.csv_header); Print(Matrix);Resultado:
CS 0 06:48:21.228 matrix test (EURUSD,H1) "S&P500" "50SMA" "13RSI" "NASDAQ" CS 0 06:48:21.228 matrix test (EURUSD,H1) [[4173.8,13386.6,34.8,13067.5] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4179.2,13396.7,36.6,13094.8] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4182.7,13406.6,37.5,13108] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4185.8,13416.8,37.1,13104.3] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4180.8,13425.2,34.9,13082.2] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4174.6,13432.2,31.8,13052] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4174.9,13440.4,33.2,13082.2] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4170.8,13447.6,32.2,13070.6] CS 0 06:48:21.228 matrix test (EURUSD,H1) [4182.2,13457.8,32.5,13078.8]
Hemos decidido crear esta función porque no hallábamos la manera de leer el archivo CSV desde la Biblioteca Estándar. Contábamos con poder cargar valores desde el archivo CSV Matrix.FromFile().

Sin embargo, esto no sucedió. Si alguien ha encontrado en la documentación cómo hacerlo, puede comunicármelo en los comentarios del artículo.
Leer valores codificados desde un archivo CSV
Con frecuencia, podemos necesitar leer un archivo CSV que contiene valores de cadena. Los archivos CSV que contienen cadenas se encuentran a menudo al buscar algoritmos de clasificación. A continuación, le mostramos un conjunto de datos sobre el tiempo;

Para poder codificar este archivo CSV, leeremos todos sus datos en un array de valores de cadena, ya que las matrices no pueden contener valores de cadena. Lo primero que deberemos hacer en ReadCsvEncode() es leer las columnas presentes en este fichero CSV. En segundo lugar, realizaremos un ciclo con las columnas en las que, como en cada iteración, se abre el CSV y se lee una columna por entero. Los valores de esta columna se almacenarán en un array con todos los valores toArr[].
//--- Obtaining the columns matrix Matrix={}; //--- Loading the entire Matrix to an Array int csv_columns=0, rows_total=0; int handle = CSVOpen(file_name,delimiter); if (handle != INVALID_HANDLE) { while (!FileIsEnding(handle)) { string data = FileReadString(handle); csv_columns++; //--- if (FileIsLineEnding(handle)) break; } } FileClose(handle); ArrayResize(csv_header,csv_columns); //--- string toArr[]; int counter=0; for (int i=0; i<csv_columns; i++) { if ((handle = CSVOpen(file_name,delimiter)) != INVALID_HANDLE) { int column = 0, rows=0; while (!FileIsEnding(handle)) { string data = FileReadString(handle); column++; //--- if (column==i+1) { if (rows>=1) //Avoid the first column which contains the column's header { counter++; ArrayResize(toArr,counter); //array size for all the columns toArr[counter-1]=data; } else csv_header[column-1] = data; } //--- if (FileIsLineEnding(handle)) { rows++; column = 0; } } rows_total += rows-1; } FileClose(handle); } //---
Ahora toArr[] tendrá el aspecto siguiente cuando se imprima:
CS 0 06:00:15.952 matrix test (US500,D1) [ 0] "Sunny" "Sunny" "Overcast" "Rain" "Rain" "Rain" "Overcast" "Sunny" "Sunny" "Rain" "Sunny" "Overcast" CS 0 06:00:15.952 matrix test (US500,D1) [12] "Overcast" "Rain" "Hot" "Hot" "Hot" "Mild" "Cool" "Cool" "Cool" "Mild" "Cool" "Mild" CS 0 06:00:15.952 matrix test (US500,D1) [24] "Mild" "Mild" "Hot" "Mild" "High" "High" "High" "High" "Normal" "Normal" "Normal" "High" CS 0 06:00:15.952 matrix test (US500,D1) [36] "Normal" "Normal" "Normal" "High" "Normal" "High" "Weak" "Strong" "Weak" "Weak" "Weak" "Strong" CS 0 06:00:15.952 matrix test (US500,D1) [48] "Strong" "Weak" "Weak" "Weak" "Strong" "Strong" "Weak" "Strong" "No" "No" "Yes" "Yes" CS 0 06:00:15.952 matrix test (US500,D1) [60] "Yes" "No" "Yes" "No" "Yes" "Yes" "Yes" "Yes" "Yes" "No"
Si prestamos atención a este array, veremos que los valores del archivo CSV están en el orden en que se recuperaron de él. Del índice 0 al 13 se encuentra la primera columna; del índice 14 al 27 se encuentra la segunda columna, etcétera. Ahora podremos extraer fácilmente los valores y codificarlos para guardarlos finalmente en una matriz.
ulong mat_cols = 0,mat_rows = 0; if (ArraySize(toArr) % csv_columns !=0) printf("This CSV file named %s has unequal number of columns = %d and rows %d Its size = %d",file_name,csv_columns,ArraySize(toArr) / csv_columns,ArraySize(toArr)); else //preparing the number of columns and rows that out matrix needs { mat_cols = (ulong)csv_columns; mat_rows = (ulong)ArraySize(toArr)/mat_cols; } //--- Encoding the CSV Matrix.Resize(mat_rows,mat_cols); //--- string Arr[]; //temporary array to carry the values of a single column int start =0; vector v = {}; for (ulong j=0; j<mat_cols; j++) { ArrayCopy(Arr,toArr,0,start,(int)mat_rows); v = LabelEncoder(Arr); Matrix.Col(v, j); start += (int)mat_rows; } return (Matrix);
La función LabelEncoder() etiqueta atributos similares en un array de columnas.
vector CMatrixutils::LabelEncoder(string &Arr[]) { string classes[]; vector Encoded((ulong)ArraySize(Arr)); Classes(Arr,classes); for (ulong A=0; A<classes.Size(); A++) for (ulong i=0; i<Encoded.Size(); i++) { if (classes[A] == Arr[i]) Encoded[i] = (int)A; } return Encoded; }
Esta sencilla función realizará un ciclo entre las clases definidas para todo el array para encontrar y marcar características similares. La mayor parte del trabajo se realiza dentro de la función Classes() (marcada en negro).
void CMatrixutils::Classes(const string &Array[],string &classes_arr[]) { string temp_arr[]; ArrayResize(classes_arr,1); ArrayCopy(temp_arr,Array); classes_arr[0] = Array[0]; for(int i=0, count =1; i<ArraySize(Array); i++) //counting the different neighbors { for(int j=0; j<ArraySize(Array); j++) { if(Array[i] == temp_arr[j] && temp_arr[j] != "nan") { bool count_ready = false; for(int n=0; n<ArraySize(classes_arr); n++) if(Array[i] == classes_arr[n]) count_ready = true; if(!count_ready) { count++; ArrayResize(classes_arr,count); classes_arr[count-1] = Array[i]; temp_arr[j] = "nan"; //modify so that it can no more be counted } else break; //Print("t vectors vector ",v); } else continue; } } }
Esta función obtiene las clases presentes en el array y las transmite al array de referencia classes_arr[]. La función también puede buscar clases en un vector. Encontrará más información sobre la función aquí.
vector CMatrixutils::Classes(vector &v)
A continuación, le mostraremos cómo utilizar esta función:
Matrix = matrix_utils.ReadCsvEncode("weather dataset.csv"); ArrayPrint(matrix_utils.csv_header); Print(Matrix);
Resultado:
CS 0 06:35:10.798 matrix test (US500,D1) "Outlook" "Temperature" "Humidity" "Wind" "Play" CS 0 06:35:10.798 matrix test (US500,D1) [[0,0,0,0,0] CS 0 06:35:10.798 matrix test (US500,D1) [0,0,0,1,0] CS 0 06:35:10.798 matrix test (US500,D1) [1,0,0,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,1,0,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,2,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,2,1,1,0] CS 0 06:35:10.798 matrix test (US500,D1) [1,2,1,1,1] CS 0 06:35:10.798 matrix test (US500,D1) [0,1,0,0,0] CS 0 06:35:10.798 matrix test (US500,D1) [0,2,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,1,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [0,1,1,1,1] CS 0 06:35:10.798 matrix test (US500,D1) [1,1,0,1,1] CS 0 06:35:10.798 matrix test (US500,D1) [1,0,1,0,1] CS 0 06:35:10.798 matrix test (US500,D1) [2,1,0,1,0]]
Escribir una matriz en un archivo CSV
Esta es otra característica importante que puede ser de ayuda al escribir una matriz en un archivo CSV sin necesidad de codificación dura cada vez que se añade una nueva columna a la matriz. La escritura flexible en un archivo CSV ha sido un problema para muchos miembros del foro: post 1, post 2, post 3. Aquí vemos cómo hacerlo usando matrices;row = Matrix.Row(i); for(ulong j=0, cols =1; j<row.Size(); j++, cols++) { concstring += (string)NormalizeDouble(row[j],digits) + (cols == Matrix.Cols() ? "" : ","); }
Al final tendrá el mismo aspecto que un archivo CSV escrito manualmente con diferentes columnas. Como la matriz no puede contener valores de cadena, hemos tenido que utilizar un array de cadenas para poder escribir el encabezado en este archivo CSV.
Vamos a intentar escribir esta matriz, extraída del archivo CSV, en un nuevo archivo CSV.
string csv_name = "matrix CSV.csv"; Print("\n---> Writing a Matrix to a CSV File > ",csv_name); string header[4] = {"S&P500","SMA","RSI","NASDAQ"}; matrix_utils.WriteCsv(csv_name,Matrix,header);
A continuación, le mostramos el nuevo archivo CSV;

Todo está en orden.
Convertir una matriz en un vector
Cabe preguntarse para qué convertir una matriz en vector. Esto resulta útil en muchas áreas porque podemos no necesitar una matriz todo el tiempo, así que esta función convertirá la matriz en un vector. Por ejemplo, cuando leemos una matriz desde un archivo CSV al crear un modelo de regresión lineal, la variable independiente será una matriz nx1 o 1xn. Al intentar utilizar unafunción de pérdida como el MSE, no podremos usar la matriz para estimar el modelo, en su lugar utilizaremos un vector de esta variable independiente y un vector con los valores predichos por el modelo.
El código se muestra a continuación:vector CMatrixutils::MatrixToVector(const matrix &mat) { vector v = {}; if (!v.Assign(mat)) Print("Failed to turn the matrix to a vector"); return(v); }
Uso:
matrix mat = { {1,2,3}, {4,5,6}, {7,8,9} }; Print("\nMatrix to play with\n",mat,"\n"); //--- Print("---> Matrix to Vector"); vector vec = matrix_utils.MatrixToVector(mat); Print(vec);
Resultado:
2022.12.20 05:39:00.286 matrix test (US500,D1) ---> Matrix to Vector 2022.12.20 05:39:00.286 matrix test (US500,D1) [1,2,3,4,5,6,7,8,9]
Convertir un vector en una matriz
Es exactamente lo contrario de la función que acabamos de analizar, pero resulta más importante de lo que parece a primera vista. En la mayoría de los modelos de aprendizaje automático, necesitamos efectuar operaciones de multiplicación entre distintas matrices. Como las variables independientes suelen almacenarse en un vector, es posible que tengamos que convertirlas en una matriz nx1 para realizar las operaciones. Estas dos funciones opuestas son importantes porque implementan nuestro código para un menor número de variables, ajustando las ya existentes.matrix CMatrixutils::VectorToMatrix(const vector &v) { matrix mat = {}; if (!mat.Assign(v)) Print("Failed to turn the vector to a 1xn matrix"); return(mat); }
Uso:
Print("\n---> Vector ",vec," to Matrix"); mat = matrix_utils.VectorToMatrix(vec); Print(mat);
Resultado:
2022.12.20 05:50:05.680 matrix test (US500,D1) ---> Vector [1,2,3,4,5,6,7,8,9] to Matrix 2022.12.20 05:50:05.680 matrix test (US500,D1) [[1,2,3,4,5,6,7,8,9]]
Convertir un array en un vector
¿Quién necesita muchos arrays en los programas de aprendizaje automático? Los arrays son muy útiles, pero resultan muy sensibles al tamaño. Configurarlos puede ayudar al terminal a eliminar nuestros programas del gráfico cuando se produce un error de salida fuera de los límites del array. Los vectores hacen lo mismo, pero resultan ligeramente más flexibles que los arrays, por no mencionar que están orientados a objetos. Puede retornar un vector de una función, pero si intenta hacer esto con un array, recibirá errores de compilación de código y advertencias.
vector CMatrixutils::ArrayToVector(const double &Arr[]) { vector v((ulong)ArraySize(Arr)); for(ulong i=0; i<v.Size(); i++) v[i] = Arr[i]; return (v); }
Uso:
Print("---> Array to vector"); double Arr[3] = {1,2,3}; vec = matrix_utils.ArrayToVector(Arr); Print(vec);
Resultado:
CS 0 05:51:58.853 matrix test (US500,D1) ---> Array to vector CS 0 05:51:58.853 matrix test (US500,D1) [1,2,3]
Convertir un vector en un array
Aún no podemos prescindir por completo de los arrays, ya que pueden darse casos en los que un vector deba convertirse en un array que tenga que conectarse a un argumento de una función, o puede que necesitemos realizar una clasificación de arrays, una segmentación de los mismos o alguna otra acción que no podamos hacer con vectores. bool CMatrixutils::VectorToArray(const vector &v,double &arr[]) { ArrayResize(arr,(int)v.Size()); if(ArraySize(arr) == 0) return(false); for(ulong i=0; i<v.Size(); i++) arr[i] = v[i]; return(true); }
Uso:
Print("---> Vector to Array"); double new_array[]; matrix_utils.VectorToArray(vec,new_array); ArrayPrint(new_array);
Resultado:
CS 0 06:19:14.647 matrix test (US500,D1) ---> Vector to Array CS 0 06:19:14.647 matrix test (US500,D1) 1.0 2.0 3.0
Borrar una columna de la matriz
El hecho de que hayamos cargado una columna CSV en una matriz no significa que necesitemos todas las columnas de la misma. Al crear un modelo de aprendizaje automático supervisado, necesitamos eliminar algunas columnas irrelevantes, por no mencionar que podríamos requerir eliminar una variable de respuesta de una matriz llena de variables independientes.
A continuación, le mostraremos el código necesario:
void CMatrixutils::MatrixRemoveCol(matrix &mat, ulong col) { matrix new_matrix(mat.Rows(),mat.Cols()-1); //Remove the one Column for (ulong i=0, new_col=0; i<mat.Cols(); i++) { if (i == col) continue; else { new_matrix.Col(mat.Col(i),new_col); new_col++; } } mat.Copy(new_matrix); }
Dentro de la función no hay nada raro. Creamos una nueva matriz con el mismo número de filas que la matriz original, pero una columna menos.
matrix new_matrix(mat.Rows(),mat.Cols()-1); //Remove the one columnEn la nueva matriz, ignoramos la columna ya innecesaria de nuestra nueva matriz; todo lo demás se guardará.
Al final de la función, copiamos la nueva matriz en la matriz antigua.
mat.Copy(new_matrix);
Ahora, vamos a eliminar la columna con el índice 1 (segunda columna) de la matriz que acabamos de leer del archivo CSV.
Print("Col 1 ","Removed from Matrix"); matrix_utils.MatrixRemoveCol(Matrix,1); Print("New Matrix\n",Matrix);
Resultado:
CS 0 07:23:59.612 matrix test (EURUSD,H1) Column of index 1 removed new Matrix CS 0 07:23:59.612 matrix test (EURUSD,H1) [[4173.8,34.8,13067.5] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4179.2,36.6,13094.8] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4182.7,37.5,13108] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4185.8,37.1,13104.3] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4180.8,34.9,13082.2] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4174.6,31.8,13052] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4174.9,33.2,13082.2] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4170.8,32.2,13070.6] CS 0 07:23:59.612 matrix test (EURUSD,H1) [4182.2,32.5,13078.8]
Eliminar varias columnas de una matriz
Hasta ahora, hemos intentado eliminar una columna, pero, a veces, hay matrices grandes que contienen muchas columnas que queremos eliminar al mismo tiempo. Al mismo tiempo, resulta importante evitar borrar las columnas necesarias e intentar acceder a valores fuera del rango para borrar columnas de forma segura.
El número/tamaño de columnas de la nueva matriz debe ser igual al número total de columnas restadas de las columnas que deseamos eliminar. El número de filas de cada columna permanecerá constante (como en la matriz antigua).
Lo primero que deberemos hacer es iterar por todas las columnas seleccionadas que queremos eliminar, comparándolas con todas las columnas disponibles en la matriz antigua. Si las columnas se van a eliminar, pondremos a cero todos los valores de estas columnas.vector zeros(mat.Rows()); zeros.Fill(0); for(ulong i=0; i<size; i++) for(ulong j=0; j<mat.Cols(); j++) { if(cols[i] == j) mat.Col(zeros,j); }Lo último que deberemos hacer es iterar de nuevo por la matriz, volver a comprobar todas las columnas llenas de valores nulos y eliminarlas una a una.
vector column_vector; for(ulong A=0; A<mat.Cols(); A++) for(ulong i=0; i<mat.Cols(); i++) { column_vector = mat.Col(i); if(column_vector.Sum()==0) MatrixRemoveCol(mat,i); }
¿Ha notado los ciclos dobles? Son muy importantes porque el tamaño de la matriz se corrige tras eliminar cada columna, por lo que resulta esencial volver atrás para comprobar si nos hemos saltado alguna columna.
A continuación, le mostraremos el código completo de la función:void CMatrixutils::MatrixRemoveMultCols(matrix &mat,int &cols[]) { ulong size = (int)ArraySize(cols); if(size > mat.Cols()) { Print(__FUNCTION__," Columns to remove can't be more than the available columns"); return; } vector zeros(mat.Rows()); zeros.Fill(0); for(ulong i=0; i<size; i++) for(ulong j=0; j<mat.Cols(); j++) { if(cols[i] == j) mat.Col(zeros,j); } //--- vector column_vector; for(ulong A=0; A<mat.Cols(); A++) for(ulong i=0; i<mat.Cols(); i++) { column_vector = mat.Col(i); if(column_vector.Sum()==0) MatrixRemoveCol(mat,i); } }
Veamos esta función en acción. Ahora, intentaremos borrar la columna con el índice 0 y el índice 2:
Print("\nRemoving multiple columns"); int cols[2] = {0,2}; matrix_utils.MatrixRemoveMultCols(Matrix,cols); Print("Columns at 0,2 index removed New Matrix\n",Matrix);
Resultado:
CS 0 07:32:10.923 matrix test (EURUSD,H1) Columns at 0,2 index removed New Matrix CS 0 07:32:10.923 matrix test (EURUSD,H1) [[13386.6,13067.5] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13396.7,13094.8] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13406.6,13108] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13416.8,13104.3] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13425.2,13082.2] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13432.2,13052] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13440.4,13082.2] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13447.6,13070.6] CS 0 07:32:10.923 matrix test (EURUSD,H1) [13457.8,13078.8]
Eliminar una fila de una matriz
También podría ser necesario eliminar una fila del conjunto de datos porque no sea necesaria, o porque queramos reducir el número de columnas, solo para ver qué funciona y qué no. Esta función no tiene tanta importancia como eliminar una columna de una matriz, por lo que mostramos la función para eliminar solo una fila. Si lo desea, podrá escribir su propio código para eliminar algunas filas.
La misma idea se ha aplicado al intentar eliminar una fila de una matriz. Simplemente ignoraremos la fila innecesaria en la nueva matriz que creamos.
void CMatrixutils::MatrixRemoveRow(matrix &mat, ulong row) { matrix new_matrix(mat.Rows()-1,mat.Cols()); //Remove the one Row for(ulong i=0, new_rows=0; i<mat.Rows(); i++) { if(i == row) continue; else { new_matrix.Row(mat.Row(i),new_rows); new_rows++; } } mat.Copy(new_matrix); }
Uso:
Print("Removing row 1 from matrix"); matrix_utils.MatrixRemoveRow(Matrix,1); printf("Row %d Removed New Matrix[%d][%d]",0,Matrix.Rows(),Matrix.Cols()); Print(Matrix);
Resultado:
CS 0 06:36:36.773 matrix test (US500,D1) Removing row 1 from matrix CS 0 06:36:36.773 matrix test (US500,D1) Row 1 Removed New Matrix[743][4] CS 0 06:36:36.773 matrix test (US500,D1) [[4173.8,13386.6,34.8,13067.5] CS 0 06:36:36.773 matrix test (US500,D1) [4182.7,13406.6,37.5,13108] CS 0 06:36:36.773 matrix test (US500,D1) [4185.8,13416.8,37.1,13104.3] CS 0 06:36:36.773 matrix test (US500,D1) [4180.8,13425.2,34.9,13082.2] CS 0 06:36:36.773 matrix test (US500,D1) [4174.6,13432.2,31.8,13052] CS 0 06:36:36.773 matrix test (US500,D1) [4174.9,13440.4,33.2,13082.2] CS 0 06:36:36.773 matrix test (US500,D1) [4170.8,13447.6,32.2,13070.6]
Índice de eliminación de vectores
Esta pequeña función ayudará a eliminar un elemento según el índice específico de un vector. Simplemente ignora el número situado en el índice dado del vector. Los valores restantes se almacenarán en un nuevo vector que se copiará en el vector primario/de referencia del argumento de la función.
void CMatrixutils::VectorRemoveIndex(vector &v, ulong index) { vector new_v(v.Size()-1); for(ulong i=0, count = 0; i<v.Size(); i++) if(i != index) { new_v[count] = v[i]; count++; } v.Copy(new_v); }
A continuación, le mostraremos la aplicación de la función:
vector v= {0,1,2,3,4}; Print("Vector remove index 3"); matrix_utils.VectorRemoveIndex(v,3); Print(v);
Resultado:
2022.12.20 06:40:30.928 matrix test (US500,D1) Vector remove index 3 2022.12.20 06:40:30.928 matrix test (US500,D1) [0,1,2,4]
Dividir la matriz en una matriz de entrenamiento y una matriz de prueba
No me canso de repetir lo importante que es esta función a la hora de crear un modelo de aprendizaje automático supervisado. Con frecuencia, necesitamos dividir un conjunto de datos en conjuntos de datos de entrenamiento y de prueba, de modo que podamos entrenar un conjunto de datos con un conjunto y probarlo con otro conjunto de datos que el modelo nunca haya visto antes.
Por defecto, esta función utiliza el 70% del conjunto de datos para la muestra de entrenamiento y el 30% restante para la muestra de prueba: no existe un estado accidental. Los datos se seleccionan según el orden cronológico de la matriz. El primer 70% de los datos se almacena en la matriz de entrenamiento y el 30% restante en la matriz de prueba.
Print("---> Train / Test Split"); matrix TrainMatrix, TestMatrix; matrix_utils.TrainTestSplitMatrices(Matrix,TrainMatrix,TestMatrix); Print("\nTrain Matrix(",TrainMatrix.Rows(),",",TrainMatrix.Cols(),")\n",TrainMatrix); Print("\nTestMatrix(",TestMatrix.Rows(),",",TestMatrix.Cols(),")\n",TestMatrix);
Resultado:
CS 0 07:38:46.011 matrix test (EURUSD,H1) Train Matrix(521,4) CS 0 07:38:46.011 matrix test (EURUSD,H1) [[4173.8,13386.6,34.8,13067.5] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4179.2,13396.7,36.6,13094.8] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4182.7,13406.6,37.5,13108] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4185.8,13416.8,37.1,13104.3] CS 0 07:38:46.011 matrix test (EURUSD,H1) [4180.8,13425.2,34.9,13082.2] .... .... CS 0 07:38:46.012 matrix test (EURUSD,H1) TestMatrix(223,4) CS 0 07:38:46.012 matrix test (EURUSD,H1) [[4578.1,14797.9,65.90000000000001,15021.1] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4574.9,14789.2,63.9,15006.2] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4573.6,14781.4,63,14999] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4571.4,14773.9,62.1,14992.6] CS 0 07:38:46.012 matrix test (EURUSD,H1) [4572.8,14766.3,65.2,15007.1]
Dividir las matrices X e Y
Cuando intentamos crear modelos de aprendizaje supervisado, tras cargar un conjunto de datos en una matriz, necesitamos extraer las variables objetivo de la matriz y almacenarlas de forma independiente del mismo modo que queremos que se guarden las variables independientes en su matriz de valores. La función actual hace precisamente esto:if(y_index == -1) value = matrix_.Cols()-1; //Last column in the matrix
Uso:
Print("---> X and Y split matrices"); matrix x; vector y; matrix_utils.XandYSplitMatrices(Matrix,x,y); Print("independent vars\n",x); Print("Target variables\n",y);
Resultado:
CS 0 05:05:03.467 matrix test (US500,D1) ---> X and Y split matrices CS 0 05:05:03.467 matrix test (US500,D1) independent vars CS 0 05:05:03.468 matrix test (US500,D1) [[4173.8,13386.6,34.8] CS 0 05:05:03.468 matrix test (US500,D1) [4179.2,13396.7,36.6] CS 0 05:05:03.468 matrix test (US500,D1) [4182.7,13406.6,37.5] CS 0 05:05:03.468 matrix test (US500,D1) [4185.8,13416.8,37.1] CS 0 05:05:03.468 matrix test (US500,D1) [4180.8,13425.2,34.9] CS 0 05:05:03.468 matrix test (US500,D1) [4174.6,13432.2,31.8] CS 0 05:05:03.468 matrix test (US500,D1) [4174.9,13440.4,33.2] CS 0 05:05:03.468 matrix test (US500,D1) [4170.8,13447.6,32.2] CS 0 05:05:03.468 matrix test (US500,D1) [4182.2,13457.8,32.5] .... .... 2022.12.20 05:05:03.470 matrix test (US500,D1) Target variables 2022.12.20 05:05:03.470 matrix test (US500,D1) [13067.5,13094.8,13108,13104.3,13082.2,13052,13082.2,13070.6,13078.8,...]
Dentro de la función de división X e Y, la columna seleccionada como variable y se almacena en la matriz Y, mientras que el resto de columnas se almacenan en la matriz X.
void CMatrixutils::XandYSplitMatrices(const matrix &matrix_,matrix &xmatrix,vector &y_vector,int y_index=-1) { ulong value = y_index; if(y_index == -1) value = matrix_.Cols()-1; //Last column in the matrix //--- y_vector = matrix_.Col(value); xmatrix.Copy(matrix_); MatrixRemoveCol(xmatrix, value); //Remove the y column }
Crear una matriz de planificación
La matriz de planificación es importante para el algoritmo de mínimos cuadrados. Es una matriz x (matriz de variables independientes) con la primera columna llena de unidades. La matriz de planificación nos ayuda a obtener los coeficientes del modelo de regresión lineal. Dentro de la función DesignMatrix(), se crea un vector lleno de unidades. A continuación, este se inserta en la primera columna de la matriz, mientras que el resto de columnas se colocan en el siguiente orden:Código completo:
matrix CMatrixutils::DesignMatrix(matrix &x_matrix) { matrix out_matrix(x_matrix.Rows(),x_matrix.Cols()+1); vector ones(x_matrix.Rows()); ones.Fill(1); out_matrix.Col(ones,0); vector new_vector; for(ulong i=1; i<out_matrix.Cols(); i++) { new_vector = x_matrix.Col(i-1); out_matrix.Col(new_vector,i); } return (out_matrix); }
Uso:
Print("---> Design Matrix\n"); matrix design = matrix_utils.DesignMatrix(x); Print(design);
Resultado:
CS 0 05:28:51.786 matrix test (US500,D1) ---> Design Matrix CS 0 05:28:51.786 matrix test (US500,D1) CS 0 05:28:51.786 matrix test (US500,D1) [[1,4173.8,13386.6,34.8] CS 0 05:28:51.786 matrix test (US500,D1) [1,4179.2,13396.7,36.6] CS 0 05:28:51.786 matrix test (US500,D1) [1,4182.7,13406.6,37.5] CS 0 05:28:51.786 matrix test (US500,D1) [1,4185.8,13416.8,37.1] CS 0 05:28:51.786 matrix test (US500,D1) [1,4180.8,13425.2,34.9] CS 0 05:28:51.786 matrix test (US500,D1) [1,4174.6,13432.2,31.8] CS 0 05:28:51.786 matrix test (US500,D1) [1,4174.9,13440.4,33.2] CS 0 05:28:51.786 matrix test (US500,D1) [1,4170.8,13447.6,32.2] CS 0 05:28:51.786 matrix test (US500,D1) [1,4182.2,13457.8,32.5]
Matriz de codificación con un estado activo
Se trata de una característica muy importante que necesitaremos al crear redes neuronales de clasificación. La función es muy importante, porque indica al perceptrón multicapa que debe vincular los datos de salida de la neurona de la última capa con los valores reales.
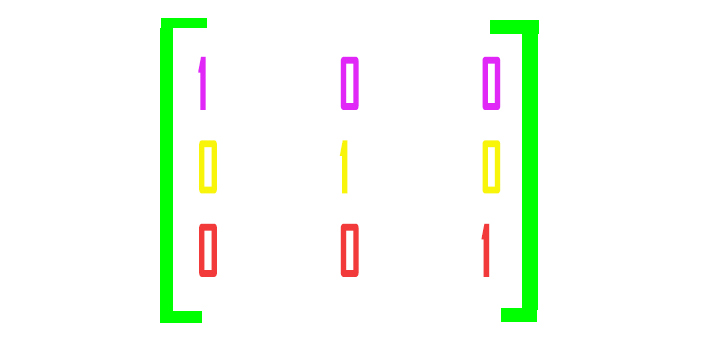
En una matriz de codificación con un estado activo, el vector de cada fila esta formado por valores cero, salvo un valor que se corresponde con el valor correcto de 1 que queremos obtener.
Para mayor claridad, vamos a analizar el siguiente ejemplo:
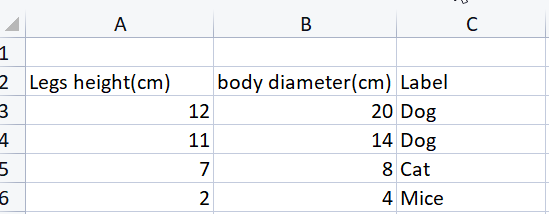
Supongamos que tenemos un conjunto de datos que queremos entrenar para que una red neuronal sea capaz de clasificar tres clases: perro (dog), gato (cat) y ratón (mice), basándose en la altura de las patas (Legs Height) y el diámetro del cuerpo (Body Diameter).
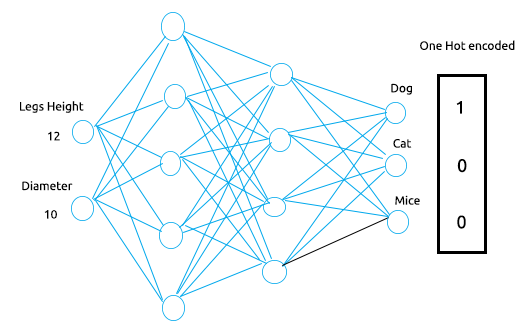
Un perceptrón multicapa tendrá 2 nodos/neuronas de entrada: uno para la altura de la pata y otro para el diámetro del cuerpo en la capa de entrada, mientras que la capa de salida tendrá 3 nodos que representarán 3 resultados: perro, gato y ratón.
Ahora bien, si suministramos al perceptrón los valores 12 y 20 para la altura y el diámetro respectivamente, podemos esperar que la red neuronal clasifique la clase como perro, ¿verdad? Lo que hace la codificación en caliente es poner un valor igual a la unidad en el nodo que tiene el valor correcto para el conjunto de datos de entrenamiento,así pues, en este caso, en el nodo para el perro se pondrá un valor de 1, mientras que el resto llevará valores cero.
Cuando codificamos con un estado abierto, podemos calcular la función de coste sustituyendo los valores del vector de codificación por cada una de las probabilidades que nos ha ofrecido el modelo. Este error se propagará nuevamente en la red en los nodos anteriores correspondientes de la capa anterior.
Veamos ahora en acción la codificación con un solo estado abierto.
Esta es nuestra matriz en el MetaEditor:
matrix dataset = { {12,28, 1}, {11,14, 1}, {7,8, 2}, {2,4, 3} };
Este es el mismo conjunto de datos que vimos en CSV, salvo que los objetivos están marcados con números enteros, ya que no podemos tener filas en la matriz (por cierto, ¿cuándo y dónde podemos usar filas en los cálculos?):
matrix dataset = { {12,28, 1}, {11,14, 1}, {7,8, 2}, {2,4, 3} }; vector y_vector = dataset.Col(2); //obtain the column to encode uint classes = 3; //number of classes in the column Print("One Hot encoded matrix \n",matrix_utils.OneHotEncoding(y_vector,classes));
A continuación, le mostraremos el resultado:
CS 0 08:54:04.744 matrix test (EURUSD,H1) One Hot encoded matrix CS 0 08:54:04.744 matrix test (EURUSD,H1) [[1,0,0] CS 0 08:54:04.744 matrix test (EURUSD,H1) [1,0,0] CS 0 08:54:04.744 matrix test (EURUSD,H1) [0,1,0] CS 0 08:54:04.744 matrix test (EURUSD,H1) [0,0,1]]
Obtener clases a partir de un vector
La función retorna un vector que contiene las clases disponibles en este vector. Por ejemplo, el vector [1,2,3] tiene tres clases diferentes. El vector [1,0,1,0] tiene dos clases diferentes. El papel de la función consiste en retornar las clases individuales disponibles.
vector v = {1,0,0,0,1,0,1,0}; Print("classes ",matrix_utils.Classes(v));
Resultado:
2022.12.27 06:41:54.758 matrix test (US500,D1) classes [1,0]
Crear un vector de valores aleatorios
A veces necesitamos generar un vector que contenga variables aleatorias, y la función se encarga precisamente de ello. Esta función se usa sobre todo para generar los pesos y un vector de desplazamiento para el algoritmo del vecino más próximo (NN). También puede usarlo para crear muestras aleatorias de los datos.
vector Random(int min, int max, int size); vector Random(double min, double max, int size);
Uso:
v = matrix_utils.Random(1.0,2.0,10); Print("v ",v);
Resultado:
2022.12.27 06:50:03.055 matrix test (US500,D1) v [1.717642750328074,1.276955473494675,1.346263008514664,1.32959990234077,1.006469924008911,1.992980742820521,1.788445692312387,1.218909268471328,1.732139042329173,1.512405774101993]
Añadir un vector a otro
Se trata de algo semejante a la concatenación de líneas, pero, en lugar de ello, concatenamos vectores. A nuestro juicio, la función puede ser útil en muchos casos. A continuación, podemos mostrarle en qué consiste.
vector CMatrixutils::Append(vector &v1, vector &v2) { vector v_out = v1; v_out.Resize(v1.Size()+v2.Size()); for (ulong i=v2.Size(),i2=0; i<v_out.Size(); i++, i2++) v_out[i] = v2[i2]; return (v_out); }
Uso:
vector v1 = {1,2,3}, v2 = {4,5,6}; Print("Vector 1 & 2 ",matrix_utils.Append(v1,v2));
Resultado:
2022.12.27 06:59:25.252 matrix test (US500,D1) Vector 1 & 2 [1,2,3,4,5,6]
Copiar un vector en otro
Por último, pero no menos importante, vamos a copiar un vector en otro vector, manipulándolo de la misma forma que Arraycopy. Con frecuencia, no necesitamos copiar un vector entero en otro. A menudo solo necesitamos una parte. El método Copy de la Biblioteca Estándar no funciona en esta situación.
bool CMatrixutils::Copy(const vector &src,vector &dst,ulong src_start,ulong total=WHOLE_ARRAY) { if (total == WHOLE_ARRAY) total = src.Size()-src_start; if ( total <= 0 || src.Size() == 0) { printf("Can't copy a vector | Size %d total %d src_start %d ",src.Size(),total,src_start); return (false); } dst.Resize(total); dst.Fill(0); for (ulong i=src_start, index =0; i<total+src_start; i++) { dst[index] = src[i]; index++; } return (true); }
Uso:
vector all = {1,2,3,4,5,6}; matrix_utils.Copy(all,v,3); Print("copied vector ",v);
Resultado:
2022.12.27 07:15:41.420 matrix test (US500,D1) copied vector [4,5,6]
Reflexiones finales
Podemos añadir muchas funciones al archivo de utilidades, pero las funciones y métodos expuestos en este artículo resultarán más necesarios si usamos las matrices para crear sistemas comerciales complejos, en particular sistemas basados en el aprendizaje automático.
Puede seguir el desarrollo de mi clase Utility Matrix en mi repositorio GitHub > https://github.com/MegaJoctan/MALE5
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/11858
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Gracias por el artículo, es realmente inspirador.
por cierto, lo que he encontrado a ser difícil de tratar es la formación NN basado ea en Metatreader.
el uso de matrices y vectores me ahorra muchos esfuerzos, pero aún así la formación de un montón de variables en Metatreader optimizador es difícil de hacer. he tratado de escribir los pesos y sesgos de archivo CSV para ser cargado por el agente de formación en Metatrader optimizador, sin embargo, su acaba de parar en el paso menos de 100. más que eso, su mirada como el agente es sólo romper el archivo CSV. su ya no contienen los pesos y sesgos de valor como se supone que es.
¿tienes alguna idea para entrenar tal número de variables?
gracias por el artículo, es realmente inspirador.
por cierto, lo que me pareció difícil de tratar es la formación NN basado ea en Metatreader.
el uso de matrices y vectores me ahorra un montón de esfuerzos, pero aún así la formación de un montón de variables en el optimizador de Metatreader es difícil de hacer. he tratado de escribir los pesos y sesgos a un archivo CSV para ser cargado por el agente de formación en el optimizador de Metatrader, sin embargo, su acaba de parar en el paso menos de 100. más que eso, su mirada como el agente es sólo romper el archivo CSV. su ya no contienen los pesos y sesgos valor como se supone que es.
¿tiene alguna idea para entrenar tal número de variables?
Es difícil de decir sin ver el código y todo lo involucrado. Yo no entreno la NN en el probador de estrategias, prefiero entrenar los parámetros de operación allí. Todos mis NN son auto entrenados
gracias por el artículo, es realmente inspirador.
por cierto, lo que me pareció difícil de tratar es la formación NN basado ea en Metatreader.
el uso de matrices y vectores me ahorra un montón de esfuerzos, pero aún así la formación de un montón de variables en el optimizador de Metatreader es difícil de hacer. he tratado de escribir los pesos y sesgos a un archivo CSV para ser cargado por el agente de formación en el optimizador de Metatrader, sin embargo, su acaba de parar en el paso menos de 100. más que eso, su mirada como el agente es sólo romper el archivo CSV. su ya no contienen los pesos y sesgos valor como se supone que es.
¿tienes alguna idea para entrenar tal número de variables?
Si usted está utilizando el algoritmo genético rápido del probador debe tener cuidado, ya que tiene diferentes "motivaciones" en función de la forma de configurar la recompensa.
Como dijo el Sr. Msigwa, es preferible entrenar las redes con retropropagación. Puede entrenar más pesos y la única recompensa de la red es aumentar la "precisión".