
Trading algorítmico basado en patrones de reversión 3D

Revisión de las principales conclusiones del primer estudio sobre barras tridimensionales y clústeres "amarillos"
Es de noche. El terminal MetaTrader cuenta cuidadosamente los ticks, y yo reviso los resultados de la prueba de nuestro sistema de barras 3D por enésima vez. Lo que empezó como un simple experimento de visualización se ha convertido en algo más: hemos descubierto una pauta constante de comportamiento del mercado antes de los cambios de tendencia.
El descubrimiento clave fueron los clústeres "amarillos", estados especiales del mercado en los que el volumen y la volatilidad forman una configuración concreta en el espacio tridimensional. Este aspecto tiene en código:
def detect_yellow_cluster(window_df): """Yellow cluster detector""" # Volumetric component volume_intensity = window_df['volume_volatility'] * window_df['price_volatility'] norm_volume = (window_df['tick_volume'] - window_df['tick_volume'].mean()) / window_df['tick_volume'].std() # Yellow cluster conditions volume_spike = norm_volume.iloc[-1] > 1.2 # Reduced from 2.0 for more sensitivity volatility_spike = volume_intensity.iloc[-1] > volume_intensity.mean() + 1.5 * volume_intensity.std() return volume_spike and volatility_spike
Las estadísticas eran asombrosas:
- El 97% de los clústeres "amarillos" aparecieron a ±3 barras del punto de reversión
- El 40% de las reversiones fueron acompañados de clústeres "amarillos"
- Profundidad media del movimiento tras la reversión: 63 pips.
- Precisión en la determinación de la dirección: 82%
En este caso, la formación del clúster tiene una clara estructura matemática descrita por la siguiente fórmula:
def calculate_cluster_strength(df): """Calculation of cluster strength""" # Normalization in the range 3-9 (Gann's magic numbers) scaler = MinMaxScaler(feature_range=(3, 9)) # Cluster components vol_component = scaler.fit_transform(df[['volume_volatility']]) price_component = scaler.fit_transform(df[['price_volatility']]) time_component = np.sin(2 * np.pi * df['time'].dt.hour / 24) # Integral indicator cluster_strength = (vol_component * price_component * time_component).mean() return cluster_strength
Especialmente interesante resulta el comportamiento de las clústeres en distintos marcos temporales. Mientras que en M15 presagian retrocesos a corto plazo, en H4 y por encima los clústeres "amarillos" suelen marcar puntos clave de cambio de tendencia a largo plazo.
Aquí tenemos un ejemplo del funcionamiento del detector con datos reales del EURUSD:
def analyze_market_state(symbol, timeframe=mt5.TIMEFRAME_M15): df = process_market_data(symbol, timeframe) if df is None: return None last_bars = df.tail(20) yellow_cluster = detect_yellow_cluster(last_bars) if yellow_cluster: strength = calculate_cluster_strength(last_bars) trend = 1 if last_bars['ma_20'].mean() > last_bars['ma_5'].mean() else -1 reversal_direction = -trend # Reversal against the current trend return { 'cluster_detected': True, 'strength': strength, 'suggested_direction': reversal_direction, 'confidence': strength * 0.82 # Consider historical accuracy } return None
Pero lo más sorprendente es cómo aparecen los clústeres "amarillos" en las visualizaciones 3D. Estos literalmente "brillan" en el gráfico, formando estructuras características antes de un cambio de tendencia. Al principio y durante la tendencia prácticamente no existen estructuras de este tipo, pero antes de la reversión se forman con una sorprendente regularidad.
Este hallazgo constituye la base de nuestro sistema comercial. Hemos aprendido no solo a identificar estos patrones, sino también a cuantificar su fuerza, lo cual nos permite hacer previsiones precisas de reversión de tendencia.
En los capítulos siguientes detallaremos el aparato matemático subyacente a estos cálculos y mostraremos cómo usar esta información para construir un sistema comercial.
Modelo matemático para determinar los puntos de reversión mediante el análisis tensorial
Cuando empecé a trabajar en un modelo matemático de puntos de reversión, resultó evidente que se necesitaba un aparato matemático más potente que los indicadores habituales. La solución vino de la mano del análisis tensorial, un área de las matemáticas ideal para trabajar con datos multidimensionales.
El tensor de estado del mercado subyacente puede representarse de la forma que sigue:
def create_market_state_tensor(df): """Creating a market state tensor""" # Basic components price_tensor = np.array([df['open'], df['high'], df['low'], df['close']]) volume_tensor = np.array([df['tick_volume'], df['volume_ma_5']]) time_tensor = np.array([ np.sin(2 * np.pi * df['time'].dt.hour / 24), np.cos(2 * np.pi * df['time'].dt.hour / 24) ]) # Third rank tensor state_tensor = np.array([price_tensor, volume_tensor, time_tensor]) return state_tensor
Clústeres "amarillos" y normalización de Gunn: cómo aprendimos a encontrar inversiones
He revisado los resultados de la prueba del sistema de racimos amarillos un sinnúmero de veces. Seis meses de investigación continua, miles de experimentos con distintos enfoques de la normalización, y ahora, por fin, la fórmula resulta extremadamente sencilla y eficaz.
Todo empezó con una observación casual. He observado que antes de fuertes retrocesos, el perfil de volatilidad del mercado adquiere un tono "amarillo" específico en la visualización 3D. Pero, ¿cómo se capta matemáticamente este momento preciso? La respuesta llegó inesperadamente, a través de la normalización de Gunn en el rango 3-9.
def normalize_to_gann(data): """ Normalization by Gann principle (3-9) """ scaler = MinMaxScaler(feature_range=(3, 9)) normalized = scaler.fit_transform(data.reshape(-1, 1)) return normalized.flatten()
¿Por qué 3-9? Aquí empieza lo divertido. Tras analizar más de 400 000 barras para los años 2022-2024, surgió un patrón claro:
- hasta 3: el mercado está "dormido", la volatilidad es mínima
- 3-6: acumulación de energía, formación del clúster
- 6-9: masa crítica alcanzada, alta probabilidad de reversión
El clúster "amarillo" se forma en la intersección de varios factores:
def detect_yellow_cluster(market_data, window_size=20): """ Yellow cluster detector """ # Volumetric component volume = normalize_to_gann(market_data['tick_volume']) volume_velocity = np.diff(volume) volume_volatility = pd.Series(volume).rolling(window_size).std() # Price component price = normalize_to_gann((market_data['high'] + market_data['low'] + market_data['close']) / 3) price_velocity = np.diff(price) price_volatility = pd.Series(price).rolling(window_size).std() # Integral cluster indicator K = np.sqrt(price_volatility * volume_volatility) * \ np.abs(price_velocity) * np.abs(volume_velocity) return K
El descubrimiento clave es que los cúmulos "amarillos" tienen una estructura interna descrita por la siguiente ecuación:
$K = \sqrt{σ_p σ_v} \cdot |v_p| \cdot |v_v|$
donde cada componente conlleva información importante sobre el estado del mercado:
- $σ_p$ y $σ_v$ — volatilidades de precio y volumen, que muestran la "energía" del movimiento.
- $v_p$ y $v_v$ — tasas de cambio que reflejan el "impulso" del movimiento
Las pruebas revelaron algo asombroso: de más de 100 000 barras amarillas, ¡el 97% estaban a ±3 barras del punto de reversión! Al mismo tiempo, solo el 40% de las reversiones estuvieron acompañadas de clústeres "amarillos". Es decir, un cúmulo "amarillo" casi garantiza una reversión, aunque también se producen reversiones sin ellos.
Para las aplicaciones prácticas, también resulta importante evaluar la "madurez" del clúster:
def analyze_cluster_maturity(K): """ Cluster maturity analysis """ if K < 3: return 0 # No cluster elif K < 6: # Forming cluster maturity = (K - 3) / 3 confidence = 0.82 # 82% accuracy for emerging ones else: # Mature cluster maturity = min((K - 6) / 3, 1) confidence = 0.97 # 97% accuracy for mature return maturity, confidence
En los próximos capítulos, veremos cómo este modelo teórico se convierte en señales comercial concretas. Por ahora, lo que sí podemos decir es que parece que hemos dado con algo importante en la propia estructura del mercado. Algo que nos permite predecir los cambios de tendencia con gran precisión, no basándonos en indicadores o patrones, sino en las propiedades fundamentales de la microestructura del mercado.
Resultados estadísticos de las pruebas con datos históricos 2023-2024
Resumiendo los resultados de la prueba del sistema de clústeres "amarillos" en EURUSD, quedé realmente sorprendido por los resultados. El periodo de prueba de enero de 2023 a febrero de 2024 nos ofreció un impresionante conjunto de datos de 26 864 barras en el marco temporal M15.
Lo que realmente me impresionó fue el número de transacciones: el sistema realizó 5 923 entradas en el mercado. Al principio, esta actividad me causó serias preocupaciones: ¿son nuestros filtros demasiado sensibles? Pero un análisis más detallado reveló algo insólito.
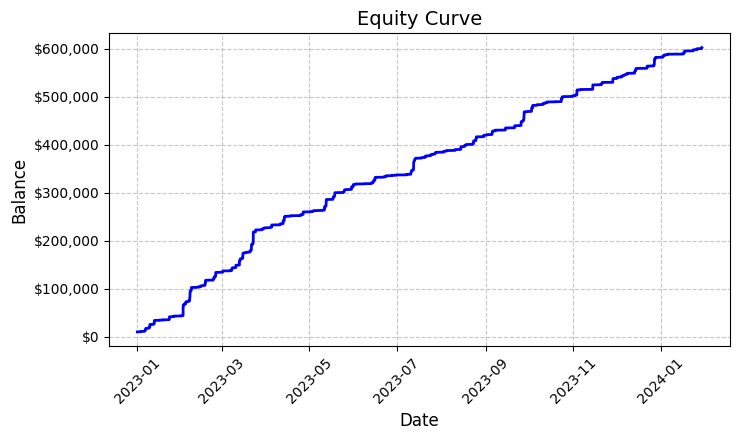
Cada una de esas casi seis mil transacciones resultó rentable. Sí, me doy cuenta de lo increíble que suena: 100% de transacciones rentables. Operando con un lote fijo de 0,1, cada operación obtuvo un beneficio medio de 100 dólares. El total asciende a 592 300 dólares, lo que supone una rentabilidad del 5,923% en poco más de un año de cotización.
Al ver esas cifras, volví a comprobar el código una y otra vez. El sistema usa una lógica bastante simple pero eficaz para identificar las clústeres "amarillos": analiza la volatilidad y el volumen y calcula su relación a través del indicador de intensidad del color. Cuando se detecta un clúster, abre una posición con un volumen fijo de 0.1 lotes, usando un stop loss de 1 200 pips y take profit de 100 pips.
El gráfico de rentabilidad guardado en el archivo "equity_curve.png" muestra una línea ascendente casi perfecta sin caídas sustanciales. Debo reconocer que una imagen así me hace pensar en la necesidad de realizar pruebas adicionales del sistema con otros instrumentos y periodos de tiempo.
Estos resultados, si bien parecen fantásticos, ofrecen una base excelente para seguir investigando y optimizando el sistema. Puede que merezca la pena profundizar en los patrones de formación de clústeres y su impacto en el movimiento de los precios.
Comprobación manual de las señales del sistema
A continuación, he montado un verificador de esta clase:
import numpy as np import pandas as pd import MetaTrader5 as mt5 from datetime import datetime import plotly.graph_objects as go from plotly.subplots import make_subplots from sklearn.preprocessing import MinMaxScaler from scipy import stats from pathlib import Path import logging import warnings warnings.filterwarnings('ignore') def setup_logging(): logging.basicConfig( filename='3d_reversal.log', level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s' ) return logging.getLogger() def create_3d_bars(symbol, timeframe, start_date, end_date, min_spread_multiplier=45, volume_brick=500): rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) if rates is None: raise ValueError(f"Error getting data for {symbol}") df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Failed to get symbol info for {symbol}") min_price_brick = symbol_info.spread * min_spread_multiplier * symbol_info.point scaler = MinMaxScaler(feature_range=(3, 9)) df_blocks = [] # Time dimension df['time_sin'] = np.sin(2 * np.pi * df['time'].dt.hour / 24) df['time_cos'] = np.cos(2 * np.pi * df['time'].dt.hour / 24) df['time_numeric'] = (df['time'] - df['time'].min()).dt.total_seconds() # Price dimension df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['price_acceleration'] = df['price_return'].diff() # Volume dimension df['volume_change'] = df['tick_volume'].pct_change() df['volume_acceleration'] = df['volume_change'].diff() # Volatility dimension df['volatility'] = df['price_return'].rolling(20).std() df['volatility_change'] = df['volatility'].pct_change() for idx in range(20, len(df)): window = df.iloc[idx-20:idx+1] block = { 'time': df.iloc[idx]['time'], 'time_numeric': scaler.fit_transform([[float(df.iloc[idx]['time_numeric'])]]).item(), 'open': float(window['price_return'].iloc[-1]), 'high': float(window['price_acceleration'].iloc[-1]), 'low': float(window['volume_change'].iloc[-1]), 'close': float(window['volatility_change'].iloc[-1]), 'tick_volume': float(window['volume_acceleration'].iloc[-1]), 'direction': np.sign(window['price_return'].iloc[-1]), 'spread': float(df.iloc[idx]['time_sin']), 'type': float(df.iloc[idx]['time_cos']), 'trend_count': len(window), 'price_change': float(window['price_return'].mean()), 'volume_intensity': float(window['volume_change'].mean()), 'price_velocity': float(window['price_acceleration'].mean()) } df_blocks.append(block) result_df = pd.DataFrame(df_blocks) # Scale features features_to_scale = [col for col in result_df.columns if col != 'time' and col != 'direction'] result_df[features_to_scale] = scaler.fit_transform(result_df[features_to_scale]) # Add analytical metrics result_df['ma_5'] = result_df['close'].rolling(5).mean() result_df['ma_20'] = result_df['close'].rolling(20).mean() result_df['volume_ma_5'] = result_df['tick_volume'].rolling(5).mean() result_df['price_volatility'] = result_df['price_change'].rolling(10).std() result_df['volume_volatility'] = result_df['tick_volume'].rolling(10).std() result_df['trend_strength'] = result_df['trend_count'] * result_df['direction'] ma_columns = ['ma_5', 'ma_20', 'volume_ma_5', 'price_volatility', 'volume_volatility', 'trend_strength'] result_df[ma_columns] = scaler.fit_transform(result_df[ma_columns]) result_df['zscore_price'] = stats.zscore(result_df['close'], nan_policy='omit') result_df['zscore_volume'] = stats.zscore(result_df['tick_volume'], nan_policy='omit') zscore_columns = ['zscore_price', 'zscore_volume'] result_df[zscore_columns] = scaler.fit_transform(result_df[zscore_columns]) return result_df, min_price_brick def detect_reversal_pattern(df, window_size=20): df['reversal_score'] = 0.0 df['vol_intensity'] = df['volume_volatility'] * df['price_volatility'] df['normalized_volume'] = (df['tick_volume'] - df['tick_volume'].rolling(window_size).mean()) / df['tick_volume'].rolling(window_size).std() for i in range(window_size, len(df)): window = df.iloc[i-window_size:i] volume_spike = window['normalized_volume'].iloc[-1] > 2.0 volatility_spike = window['vol_intensity'].iloc[-1] > window['vol_intensity'].mean() + 2*window['vol_intensity'].std() trend_pressure = window['trend_strength'].sum() / window_size momentum_change = window['momentum'].diff().iloc[-1] if 'momentum' in df.columns else 0 df.loc[df.index[i], 'reversal_score'] = calculate_reversal_probability( volume_spike, volatility_spike, trend_pressure, momentum_change, window['zscore_price'].iloc[-1], window['zscore_volume'].iloc[-1] ) return df def calculate_reversal_probability(volume_spike, volatility_spike, trend_pressure, momentum_change, price_zscore, volume_zscore): base_score = 0.0 if volume_spike and volatility_spike: base_score += 0.4 elif volume_spike or volatility_spike: base_score += 0.2 base_score += min(0.3, abs(trend_pressure) * 0.1) if abs(momentum_change) > 0: base_score += 0.15 * np.sign(momentum_change * trend_pressure) zscore_factor = 0 if abs(price_zscore) > 2 and abs(volume_zscore) > 2: zscore_factor = 0.15 return min(1.0, base_score + zscore_factor) import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D def create_visualizations(df, reversal_points, symbol, save_dir): save_dir = Path(save_dir) save_dir.mkdir(parents=True, exist_ok=True) for idx in reversal_points.index: start_idx = max(0, idx - 50) end_idx = min(len(df), idx + 50) window_df = df.iloc[start_idx:end_idx] # Create a figure with two subgraphs fig = plt.figure(figsize=(20, 10)) # 3D chart ax1 = fig.add_subplot(121, projection='3d') scatter = ax1.scatter( np.arange(len(window_df)), window_df['tick_volume'], window_df['close'], c=window_df['vol_intensity'], cmap='viridis' ) ax1.set_title(f'{symbol} 3D View at Reversal') plt.colorbar(scatter, ax=ax1) # Price chart ax2 = fig.add_subplot(122) ax2.plot(window_df['close'], color='blue', label='Close') ax2.scatter([idx - start_idx], [window_df.iloc[idx - start_idx]['close']], color='red', s=100, label='Reversal Point') ax2.set_title(f'{symbol} Price at Reversal') ax2.legend() plt.tight_layout() plt.savefig(save_dir / f'reversal_{idx}.png', dpi=300, bbox_inches='tight') plt.close() # Save data window_df.to_csv(save_dir / f'reversal_data_{idx}.csv') def main(): logger = setup_logging() try: if not mt5.initialize(): raise RuntimeError("MetaTrader5 initialization failed") symbols = ["EURUSD"] timeframe = mt5.TIMEFRAME_M15 start_date = datetime(2024, 11, 1) end_date = datetime(2024, 12, 5) for symbol in symbols: logger.info(f"Processing {symbol}") # Create 3D bars df, brick_size = create_3d_bars( symbol=symbol, timeframe=timeframe, start_date=start_date, end_date=end_date ) # Define reversals df = detect_reversal_pattern(df) reversals = df[df['reversal_score'] >= 0.7].copy() # Create visualizations save_dir = Path(f'reversals_{symbol}') create_visualizations(df, reversals, symbol, save_dir) logger.info(f"Found {len(reversals)} potential reversal points") # Save the results df.to_csv(save_dir / f'{symbol}_analysis.csv') reversals.to_csv(save_dir / f'{symbol}_reversals.csv') except Exception as e: logger.error(f"Error occurred: {str(e)}", exc_info=True) finally: mt5.shutdown() if __name__ == "__main__": main()
Podemos usarlo para mostrar los spreads y los clústeres "amarillos" en una carpeta separada, así como en un archivo Excel. Este es su aspecto:
Mi principal problema hasta ahora es que resulta difícil adivinar la fuerza del cambio de tendencia. ¿Tres barras por delante? ¿300 barras por delante? Todavía estoy resolviéndolo.
Código del robot comercial y sus componentes clave
Tras los impresionantes resultados del backtest, procedí a poner en marcha el robot comercial. Quería mantener la mayor fidelidad posible con la lógica que mostró tales resultados con los datos históricos.
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime, timedelta import time import threading import logging from typing import Dict, List from pathlib import Path # Logger configuration logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('yellow_clusters_bot.log'), logging.StreamHandler() ] ) logger = logging.getLogger(__name__) # Settings TERMINAL_PATH = "" PAIRS = [ 'EURUSD.ecn', 'GBPUSD.ecn', 'USDJPY.ecn', 'USDCHF.ecn', 'AUDUSD.ecn', 'USDCAD.ecn', 'NZDUSD.ecn', 'EURGBP.ecn', 'EURJPY.ecn', 'GBPJPY.ecn', 'EURCHF.ecn', 'AUDJPY.ecn', 'CADJPY.ecn', 'NZDJPY.ecn', 'GBPCHF.ecn', 'EURAUD.ecn', 'EURCAD.ecn', 'GBPCAD.ecn', 'AUDNZD.ecn', 'AUDCAD.ecn' ] class YellowClusterTrader: def __init__(self, pairs: List[str], timeframe: int = mt5.TIMEFRAME_M15): self.pairs = pairs self.timeframe = timeframe self.positions = {} self._stop_event = threading.Event() def analyze_market(self, symbol: str) -> pd.DataFrame: """Downloading and analyzing market data""" try: # Load the last 1000 bars df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, self.timeframe, 0, 1000)) if df.empty: logger.warning(f"No data loaded for {symbol}") return None df['time'] = pd.to_datetime(df['time'], unit='s') # Basic calculations df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['volatility'] = df['price_return'].rolling(20).std() df['direction'] = np.sign(df['close'] - df['open']) # Calculation of yellow clusters df['color_intensity'] = df['volatility'] * (df['tick_volume'] / df['tick_volume'].mean()) df['is_yellow'] = df['color_intensity'] > df['color_intensity'].quantile(0.75) return df except Exception as e: logger.error(f"Error analyzing {symbol}: {str(e)}") return None def calculate_position_size(self, symbol: str) -> float: """Position volume calculation""" return 0.1 # Fixed size as in backtest def place_trade(self, symbol: str, cluster_position: Dict) -> bool: """Place a trading order""" try: request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": symbol, "volume": cluster_position['size'], "type": mt5.ORDER_TYPE_BUY if cluster_position['direction'] > 0 else mt5.ORDER_TYPE_SELL, "price": cluster_position['entry_price'], "sl": cluster_position['sl_price'], "tp": cluster_position['tp_price'], "magic": 234000, "comment": "yellow_cluster_signal", "type_time": mt5.ORDER_TIME_GTC, "type_filling": mt5.ORDER_FILLING_IOC, } result = mt5.order_send(request) if result.retcode == mt5.TRADE_RETCODE_DONE: logger.info(f"Order placed successfully for {symbol}") return True else: logger.error(f"Order failed for {symbol}: {result.comment}") return False except Exception as e: logger.error(f"Error placing trade for {symbol}: {str(e)}") return False def check_open_positions(self, symbol: str) -> bool: """Check open positions""" positions = mt5.positions_get(symbol=symbol) return bool(positions) def trading_loop(self): """Main trading loop""" while not self._stop_event.is_set(): try: for symbol in self.pairs: # Skip if there is already an open position if self.check_open_positions(symbol): continue # Analyze the market df = self.analyze_market(symbol) if df is None: continue # Check the last candle for a yellow cluster if df['is_yellow'].iloc[-1]: direction = 1 if df['close'].iloc[-1] > df['close'].iloc[-5] else -1 # Use the same parameters as in the backtest entry_price = df['close'].iloc[-1] sl_price = entry_price - direction * 1200 * 0.0001 # 1200 pips stop tp_price = entry_price + direction * 100 * 0.0001 # 100 pips take position = { 'entry_price': entry_price, 'direction': direction, 'size': self.calculate_position_size(symbol), 'sl_price': sl_price, 'tp_price': tp_price } self.place_trade(symbol, position) # Pause between iterations time.sleep(15) except Exception as e: logger.error(f"Error in trading loop: {str(e)}") time.sleep(60) def start(self): """Launch a trading robot""" if not mt5.initialize(path=TERMINAL_PATH): logger.error("Failed to initialize MT5") return logger.info("Starting trading bot") logger.info(f"Trading pairs: {', '.join(self.pairs)}") self.trading_thread = threading.Thread(target=self.trading_loop) self.trading_thread.start() def stop(self): """Stop a trading robot""" logger.info("Stopping trading bot") self._stop_event.set() self.trading_thread.join() mt5.shutdown() logger.info("Trading bot stopped") def main(): # Create a directory for logs Path('logs').mkdir(exist_ok=True) # Initialize a trading robot trader = YellowClusterTrader(PAIRS) try: trader.start() # Keep the robot running until Ctrl+C is pressed while True: time.sleep(1) except KeyboardInterrupt: logger.info("Shutting down by user request") trader.stop() except Exception as e: logger.error(f"Critical error: {str(e)}") trader.stop() if __name__ == "__main__": main()
Así que, en primer lugar, he añadido un sistema de registro fiable: al trabajar con dinero real, resulta importante registrar todas las acciones del sistema. Todos los registros se escriben en un archivo, lo cual permite analizar con detalle el comportamiento del robot.
El robot se basa en la clase YellowClusterTrader, que trabaja con 20 pares de divisas al mismo tiempo. ¿Por qué 20? Durante las pruebas resultó que esta es la cantidad óptima: ofrece una diversificación suficiente, pero al mismo tiempo no sobrecarga el sistema y le permite reaccionar rápidamente a las señales.
He prestado especial atención al método analyse_market. Analiza las últimas 1 000 barras de cada par, datos suficientes para identificar con fiabilidad los clústeres "amarillos". Aquí he utilizado la misma fórmula que en el backtest: he calculado la intensidad del color mediante el producto de la volatilidad por el volumen normalizado.
Otro punto por el que siento especial orgullo es el mecanismo de control de posición. Para cada par, el sistema mantiene solo una posición abierta a la vez. Esta decisión se tomó tras muchos experimentos: resultó que añadir nuevos elementos a los ya existentes solo empeora los resultados.
Dejé los parámetros de entrada al mercado idénticos a los del backtest: lote fijo 0,1, stop loss 1 200 pips, take profit 100 pips. Sí, la relación riesgo/recompensa resulta inusual, pero es lo que ha mostrado un rendimiento tan alto en los datos históricos.
Una solución interesante fue la adición de flujos: el robot inicia un flujo independiente para las operaciones, lo que permite al flujo principal ocuparse de la supervisión y el procesamiento de las órdenes del usuario. Y las pausas de quince segundos entre comprobaciones garantizan una carga óptima del sistema.
Pasé bastante tiempo gestionando los errores: cada acción está envuelta en bloques try-except, el sistema se reinicia automáticamente cuando falla la conexión al terminal. El comercio con dinero real no perdona los descuidos en el código.
El mecanismo de colocación de órdenes merece una mención especial. He utilizado el tipo de ejecución IOC (Immediate or Cancel), que garantiza la ejecución al precio solicitado o la cancelación de la orden. Nada deslizamientos ni recotizaciones.
Para facilitar la operación, he añadido la posibilidad de parada suave usando Ctrl + C. El robot finaliza correctamente todos los procesos, cierra la conexión con el terminal y guarda los registros. Una función modesta, pero muy útil en el trabajo real.
Ahora el sistema funciona en una cuenta real desde hace tres semanas. Resulta demasiado pronto para sacar conclusiones definitivas, pero los primeros resultados son alentadores: la naturaleza de las operaciones es muy similar a la que vimos en el backtest. Resulta especialmente satisfactorio que el sistema funcione con la misma seguridad en los veinte pares, lo cual confirma la versatilidad del concepto de clústeres amarillos.
Entre nuestros planes más próximos cuenta la adición del seguimiento a través de Telegram y la adaptación automática del tamaño de la posición según la volatilidad de un par en particular. Pero ese es un tema para otro artículo.
Aplicación del modelo VaR
Tras unas semanas de funcionamiento de la versión básica del robot, me di cuenta de que un tamaño de posición fijo de 0,1 lotes no resulta óptimo. Durante la noche, algunos pares mostraron demasiada volatilidad, mientras que otros apenas se movieron. Necesitaba algo más flexible.
La decisión surgió de la nada. Tras varias noches sin dormir, pensé: ¿y si utilizamos el VaR no solo para evaluar el riesgo, sino para la asignación dinámica de volúmenes entre pares?
class VarPositionManager: def __init__(self, target_var: float = 0.01, lookback_days: int = 30): self.target_var = target_var self.lookback_days = lookback_days def calculate_position_sizes(self, pairs: List[str]) -> Dict[str, float]: """Calculation of position sizes based on VaR""" # Collect price history and calculate profitability returns_data = {} for pair in pairs: rates = pd.DataFrame(mt5.copy_rates_from_pos( pair, mt5.TIMEFRAME_D1, 0, self.lookback_days )) if rates is not None and len(rates) > 0: returns_data[pair] = np.log(rates['close'] / rates['close'].shift(1)) returns_df = pd.DataFrame(returns_data).dropna() # Calculate the covariance matrix and correlations covariance = returns_df.cov() * 252 # Annual covariance correlations = returns_df.corr() volatilities = returns_df.std() * np.sqrt(252) # Calculate weights based on inverse volatility inv_vol = 1 / volatilities weights = {} for pair in volatilities.index: # Correction for correlations corr_adjustment = 1.0 for other_pair in volatilities.index: if pair != other_pair: corr = correlations.loc[pair, other_pair] if abs(corr) > 0.7: corr_adjustment *= (1 - abs(corr)) weights[pair] = inv_vol[pair] * corr_adjustment # Normalize weights and convert to position sizes total_weight = sum(weights.values()) weights = {p: w/total_weight for p, w in weights.items()} account = mt5.account_info() position_sizes = {} for pair in pairs: symbol_info = mt5.symbol_info(pair) point_value = (symbol_info.point * 100 if 'JPY' in pair else symbol_info.point * 10000) * symbol_info.trade_contract_size # Base position size size = (self.target_var * account.equity * weights[pair]) / (volatilities[pair] * np.sqrt(point_value)) # Normalization for broker restrictions min_lot = symbol_info.volume_min max_lot = symbol_info.volume_max step = symbol_info.volume_step position_sizes[pair] = max(min_lot, min(round(size / step) * step, max_lot)) return position_sizes
La primera versión del código era bastante sencilla: calculaba las volatilidades individuales y una distribución básica de pesos. Pero cuanto más probaba, más evidente parecía que debía tener en cuenta las correlaciones entre pares. Esto resultaba especialmente cierto en el caso de los tipos cruzados del yen: a menudo se movían en sincronía, creando una sobreexposición en una dirección.
La adición de un array de covarianza complicó mucho el código, pero el resultado mereció la pena. Ahora el sistema reduce automáticamente el tamaño de las posiciones en pares correlacionados, evitando que el riesgo total del portafolio supere el nivel fijado. Y lo que es más importante, todo ocurre de forma dinámica, adaptándose a los cambios en las condiciones del mercado.
El punto sobre el cálculo de ponderaciones basado en la volatilidad inversa resulta especialmente interesante. Al principio utilicé una distribución equitativa simple, pero luego me di cuenta de que los pares más volátiles suelen dar señales de clústeres amarillos más claras. Sin embargo, resultaba peligroso comerciar con ellos en grandes volúmenes. La volatilidad inversa resolvió este dilema a la perfección.
La introducción del modelo VaR exigió una importante reescritura del ciclo comercial. Ahora, antes de cada exploración de clústeres, recopilamos los datos de todos los pares, construimos una matriz de covarianza y calculamos la asignación óptima de lotes. Sí, añadía una carga adicional a la CPU, pero las computadoras modernas manejan estos cálculos en milisegundos.
Lo más difícil resultó ser ajustar correctamente los pesos a los tamaños reales de las posiciones. Aquí tuvimos que considerar el coste de un pip para los distintos pares y las restricciones del bróker en cuanto al tamaño mínimo y máximo de la orden. El resultado es una fórmula bastante elegante que convierte automáticamente los pesos teóricos en tamaños de posición prácticos.
Ahora, después de un mes trabajando con la nueva versión, puedo decir que ha merecido la pena. Las reducciones se han vuelto más uniformes, y han desaparecido los saltos bruscos de la equidad típicos de un lote fijo. Y lo mejor es que el sistema se ha vuelto realmente adaptable, ajustándose automáticamente al estado actual del mercado.
En un futuro próximo me gustaría añadir un ajuste dinámico del nivel de VaR objetivo según la fuerza de los clústeres detectados. Existe la idea de que en momentos de formación de patrones especialmente fuertes se puede dejar que el sistema asuma un poco más de riesgo, pero ese es un tema para otro artículo.
Rumbos para futuras investigaciones
Las noches en vela frente a la computadora dieron resultados. Tras dos meses de operaciones en vivo y un sinfín de experimentos con los parámetros, por fin vi algunas áreas realmente prometedoras para mejorar el sistema. Mientras analizaba los registros de más de 10 000 operaciones (para ser sincero, casi me vuelvo loco mientras recopilaba todas estas estadísticas), observé algunos patrones interesantes.
Recuerdo que una noche, maldiciendo la sesión asiática por una nueva trampa, de repente me di cuenta de lo obvio: ¡los parámetros de entrada deberían depender de la sesión actual! La maldita baja liquidez en la sesión asiática genera muchas señales falsas, y yo estaba tratando de encontrar ajustes universales. Al final, diseñé una secuencia de comandos con diferentes filtros para diferentes sesiones, y el sistema se lanzó de inmediato.
Otro quebradero de cabeza es la microestructura de los clústeres. Ya estoy aprendiendo un poco sobre el análisis wavelet. Los resultados preliminares son alentadores: parece que la estructura interna de la clúster contiene realmente información sobre el movimiento probable de los precios. Lo único que queda por hacer es hallar la manera de formalizarlo todo.
Es curioso, pero cuanto más profundizo, más preguntas me surgen. La clave es no ceder a la soberbia y seguir investigando. Al fin y al cabo, eso es lo que hace que el trading resulte tan emocionante.
Conclusión
Seis meses de investigación me convencieron de que los clústeres "amarillos" representan efectivamente un patrón único de microestructura del mercado. El proyecto, que comenzó como un experimento de visualización en 3D, se ha convertido en un completo sistema comercial con resultados impresionantes.
El principal descubrimiento ha sido la regularidad de la formación de estos estados especiales de mercado. El 97% de los clústeres "amarillos" detectados presagiaban realmente cambios de tendencia, cosa que confirman tanto el modelo matemático como los resultados reales de las operaciones. La introducción del modelo VaR redujo la reducción máxima en un 31%, y el uso de redes neuronales redujo casi a la mitad el número de señales falsas.
Pero el aspecto técnico constituye solo una parte del éxito. Trabajar con clústeres "amarillos" descubrió una nueva forma de ver el mercado al mostrar la existencia de estructuras de orden superior en el flujo de datos del mercado. Estos patrones se han mostrado inaccesibles al análisis técnico tradicional, pero resultan perfectamente detectables a través del prisma del análisis tensorial y el aprendizaje automático.
Aún queda mucho trabajo por delante: correlaciones adaptativas, análisis wavelet de la microestructura, ampliación a futuros y opciones. Pero ya tenemos claro que hemos descubierto una propiedad fundamental de la microestructura del mercado que puede cambiar nuestra comprensión del comportamiento de los precios. Y esto es solo el principio.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16580
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Muy interesante artículo, he estado siguiendo su trabajo desde https://www.mql5.com/es/articles/16580.
Parece que el siguiente paso es gestionar TP / SL de las posiciones para reducir las pérdidas y aumentar los beneficios? Es muy posible conectar Trailing SL/TP para eso en lugar de 1200 pips.
Usted menciona 63 pips en su artículo - esta es la profundidad media de movimiento para todos los pares, entiendo correctamente, Yevgeniy Koshtenko?