
Redes neuronales: así de sencillo (Parte 29): Algoritmo actor-crítico con ventaja (Advantage actor-critic)

Contenido
- Introducción
- 1. Puntos fuertes de los métodos de aprendizaje por refuerzo analizados anteriormente
- 2. El algoritmo actor-crítico con ventaja
- 3. Implementación
- 4. Simulación
- Conclusión
- Enlaces
- Programas usados en el artículo.
Introducción
Continuamos estudiando los métodos de aprendizaje por refuerzo. En artículos anteriores, analizamos varios métodos para aproximar la función de recompensa de aprendizaje Q profundo e implementar el aprendizaje con la función de política policy gradient. Cada método posee sus propias ventajas y desventajas, y, obviamente, en el proceso de construcción y entrenamiento de nuestro modelo, nos gustaría aprovechar al máximo sus ventajas. Al buscar métodos para minimizar los defectos de los algoritmos utilizados, con frecuencia intentamos construir ciertos conglomerados a partir de varios algoritmos y métodos conocidos. En este artículo, hablaremos sobre la combinación de los dos algoritmos anteriores en un solo método de entrenamiento de modelos, denominado Actor-Crítico con ventaja (Advantage actor-critic).
1. Puntos fuertes de los métodos de aprendizaje por refuerzo analizados anteriormente
Antes de proceder a combinar algoritmos, recordemos sus fortalezas y debilidades.
En el proceso de interacción con el Entorno, el Agente realiza determinadas acciones, influyendo en el Entorno. Al mismo tiempo, como resultado de la influencia de factores externos y de las acciones del Agente, el estado del entorno cambia. Y después de cada cambio de estado, el entorno informa al agente transmitiendo alguna recompensa. Esta recompensa puede ser tanto positiva como negativa. La cantidad y el signo de la recompensa indica la utilidad del nuevo estado para el Agente. La naturaleza de la formación de la recompensa del Agente se desconoce. El objetivo del Agente consiste en aprender a realizar tales acciones para recibir la máxima recompensa posible en el proceso de interacción con el Entorno.
Primero estudiaremos el algoritmo de aproximación de la función de recompensa del Aprendizaje Q. Para ello, entrenaremos a nuestro modelo de tal forma que aprenda a predecir la próxima recompensa con la mayor precisión posible después de realizar una u otra acción en un estado particular del entorno. Luego el agente realizará las acciones subsiguientes según la magnitud de la recompensa prevista y la política de comportamiento del agente. Por regla general, aquí se usa la estrategia codiciosa o ɛ-codiciosa. Una estrategia codiciosa implica elegir la acción con la mayor recompensa prevista, y con mayor frecuencia se utiliza durante la explotación industrial del agente.
La segunda estrategia, ɛ-codiciosa, resulta similar a la estrategia codiciosa en algo más que el nombre. También implica elegir la acción con la mayor recompensa pronosticada, pero al mismo tiempo, permite elegir una acción aleatoria con probabilidad ɛ, lo cual se utiliza en la etapa de entrenamiento del modelo para comprender mejor el entorno. Y es que, en caso contrario, una vez obtenida una recompensa positiva, el modelo repetirá constantemente una acción y no analizará otras opciones. En este caso, nunca sabrá cómo de óptima ha sido su acción. ¿Podrían otras acciones llevar a la obtención de recompensas mayores? Lo que nosotros queremos es obligar al agente a analizar el entorno tanto como sea posible, y sacarle el máximo partido.
Las ventajas del método de aprendizaje Qson bastante obvias. El modelo está entrenado para pronosticar recompensas, concretamente, la recompensa que recibimos del entorno, así que tenemos una relación directa entre los valores de los resultados del modelo y los valores de referencia obtenidos del entorno. En esta interpretación, el aprendizaje resulta similar a los métodos de aprendizaje supervisado. Al entrenar el modelo, utilizamos el error estándar como función de pérdida.
Aquí debes estar atentos: el modelo entrenado retornará la recompensa media acumulada hasta el final de la sesión, considerando el factor de descuento que ha obtenido el agente del entorno tras realizar una acción concreta en un estado similar del entorno al entrenar al modelo, mientras que el entorno retornará una recompensa por cada transición específica a un nuevo estado. Y aquí vemos un hueco que se cubre tras el paso completo del episodio por parte del Agente.
Entre las desventajas del algoritmo, podemos destacar lo complejo que resulta entrenar el modelo. Recuerde que para entrenar el modelo necesitábamos introducir una serie de entidades y trucos. En primer lugar, los estados sucesivos del entorno están fuertemente correlacionados entre sí, y, en la mayoría de los casos, difieren solo en detalles menores. El entrenamiento directo con estos datos provoca un constante reentrenamiento del modelo para el estado actual con una pérdida completa de la capacidad de generalizar los datos. Por ello, necesitábamos crear un búfer de datos históricos en los que se entrenaba el modelo. Al entrenar el modelo, seleccionábamos aleatoriamente estados del búfer de datos históricos, lo cual hacía posible minimizar la correlación entre los 2 estados utilizados secuencialmente para el entrenamiento.
Al entrenar el modelo con los datos reales de la recompensa obtenida del entorno, obtenemos un modelo con poca variación de datos, es decir, la dispersión de los valores retornados por el modelo para cada estado es aceptablemente pequeña, y este es un factor positivo. Sin embargo, debemos recordar que el entorno devuelve una recompensa por cada transición específica, y como necesitamos maximizar el beneficio durante todo el periodo previsible, para su cálculo resulta necesario que el agente complete la sesión. No obstante, gracias al uso del búfer de datos históricos y la adición del modelo de predicción de recompensas futuras, lográbamos construir un algoritmo que podía reentrenar el modelo durante su uso práctico. Por así decirlo, se construía un proceso de aprendizaje on-line, pero teníamos que pagar por esto con un error en la predicción de las recompensas.
El hecho es que usando el segundo modelo para predecir futuras recompensas, entendimos y aceptamos perfectamente los riesgos derivados de los errores en dichos pronósticos, pero cada error cometido se tenía en cuenta al entrenar el modelo e influía en todas las predicciones posteriores. Así, obtuvimos un modelo capaz de predecir resultados con una pequeña varianza pero con un gran desplazamiento. Esto puede pasarse por alto al utilizar la estrategia codiciosa. Después de todo, eligiendo la recompensa máxima, solo la comparamos con el resto. Cambiar o escalar valores en este caso no afectará el resultado final de la selección de la acción.

Y, obviamente, al usar aprendizaje Q, nuestro modelo solo estará entrenado para predecir recompensas. Para seleccionar las acciones, necesitaremos especificar la política (estrategia) de comportamiento del agente en la etapa de creación del modelo, y usar la estrategia codiciosa nos permite trabajar con éxito solo en entornos deterministas. Eso no resulta del todo aplicable a la construcción de estrategias estocásticas.
El uso de gradiente de políticas, por el contrario, no requiere que definamos la política (estrategia) de comportamiento del agente en la etapa de creación del modelo. Este método permite al agente construir su propia política de comportamiento, que podrá ser tanto codiciosa como estocástica.
El modelo entrenado con el método del gradiente de políticas retornará la distribución de probabilidad de conseguir el resultado deseado al elegir una u otra acción en cada estado específico del entorno.
Al entrenar el modelo, también usamos las recompensas obtenidas del entorno, y para seleccionar la estrategia óptima en cada estado del entorno, se usa la recompensa acumulada hasta el final de la sesión. Obviamente, para actualizar los pesos del modelo, el agente deberá pasar por toda la sesión. Quizás esta sea la principal desventaja de este método: no podemos construir un modelo de aprendizaje on-line porque no conocemos las recompensas futuras.
Al mismo tiempo, el uso de la recompensa acumulada real nos permite minimizar el error constante del desplazamiento de los datos predichos respecto a su valor real, cosa en la que pecaba el aprendizaje Q debido al uso de valores predictivos de recompensas futuras.
No obstante, conviene recordar que en el gradiente de política, entrenamos el modelo para predecir no la recompensa esperada, sino la distribución de probabilidad de conseguir el resultado deseado cuando un agente realiza una acción en un estado particular del entorno, y como función de pérdida, usamos la función logarítmica.
")
Para determinar analíticamente la dirección de la minimización del error, como siempre, usaremos la derivada de la función de pérdida. En este caso, la propiedad de la derivada del logaritmo resultará muy conveniente.

Al multiplicar la derivada de la función de pérdida por la recompensa positiva, aumentaremos la probabilidad de elegir tal acción. Y al multiplicar la derivada de la función de pérdida por una recompensa negativa, ajustaremos nuestros pesos en la dirección opuesta, reduciendo así la probabilidad de elegir tal acción. La cantidad del módulo de recompensa determinará el paso de ajuste de los pesos.
Como podemos ver, al actualizar la matriz de pesos de nuestro modelo, el uso de recompensas se produce de forma indirecta. Por consiguiente, obtendremos un modelo cuyos resultados tienen un pequeño desplazamiento en relación con los datos reales, pero una varianza bastante grande (dispersión de valores).

Los aspectos positivos del método incluyen su capacidad para analizar el entorno. Después de todo, si al usar el aprendizaje Q y la estrategia ɛ-codiciosa, determinamos el equilibrio entre la investigación y la explotación usando el parámetro ɛ, entonces el gradiente de políticas usará el muestreo de acciones de una distribución dada.
Al inicio del entrenamiento, la probabilidad de realizar todas las acciones es casi igual, y el modelo tiende a maximizar el análisis del entorno, eligiendo una u otra acción del agente con igual probabilidad. Durante el entrenamiento del modelo, la distribución probabilística de acciones cambia. La probabilidad de elegir acciones rentables aumenta, mientras que la probabilidad de elegir acciones no rentables disminuye. Esto reduce la tendencia del modelo a investigar, y el equilibrio se desplaza hacia la explotación.
Asimismo, debemos prestar atención a un punto más. Usando la recompensa acumulada, nos centraremos en lograr un resultado al final de la sesión, y al mismo tiempo, no evaluaremos el impacto de cada paso específico. Este enfoque, por ejemplo, puede enseñar a nuestro agente a mantener posiciones no rentables en previsión de un cambio de tendencia, o ejecutar un gran número de transacciones perdedoras cuyas pérdidas serán cubiertas por transacciones rentables poco frecuentes, pero con alta rentabilidad. Después de todo, tras obtener el beneficio total al final de la sesión, el modelo lo considerará un resultado positivo y aumentará la probabilidad de dichas transacciones. Obviamente, la ejecución de un gran número de iteraciones está diseñada para minimizar este factor, dado que la capacidad del método para analizar el entorno debería ayudar al modelo a encontrar la estrategia óptima. Pero esto provocará que el proceso de entrenamiento del modelo se alargue.
Resumiendo: Los modelos de aprendizaje Q tienen una varianza baja pero un alto desplazamiento. El gradiente de políticas, por el contrario, nos permite entrenar un modelo con un pequeño desplazamiento y una gran varianza. Nos gustaría poder entrenar el modelo con una varianza y un desplazamiento mínimos.
El gradiente de políticas crea una estrategia holística sin considerar el impacto de cada paso individual, y nos gustaría obtener el máximo beneficio en cada paso, cosa que el aprendizaje Q nos permite hacer. Recuerde la función de Bellman: su uso implica elegir la mejor acción en cada paso.
El uso de métodos de aproximación de la función Q requiere la definición de la política de comportamiento del agente en la etapa de creación del modelo, pero preferimos que el propio modelo determine la estrategia basándose en la experiencia de interacción con el entorno. Y, por supuesto, no nos gustaría limitarnos a estrategias conductuales deterministas: esto nos permitiría implementar métodos de aprendizaje de políticas.
Y aquí se hace bastante evidente el deseo de combinar dos métodos para obtener los mejores resultados.
2. El algoritmo actor-crítico con ventaja
Los intentos más exitosos de combinar la aproximación de la función de recompensa y los métodos de aprendizaje de políticas son los métodos de la familia Actor-Crítico. Hoy proponemos al lector familiarizarse con el algoritmo denominado "Actor-Crítico con ventaja" (Advantage actor-critic).
La familia de métodos actor-crítico implica usar dos modelos. Uno de los modelos, el Actor, será responsable de elegir la acción del agente y será entrenado por métodos de aproximación de la función de política. El segundo modelo, el Crítico, se entrenará con los métodos de aprendizaje Q y evaluará las acciones elegidas por el Actor.
Lo primero que queremos hacer es reducir la varianza de los datos en el modelo de política. Echemos otro vistazo a la función de pérdida de nuestro modelo de política: aquí, multiplicamos cada vez el logaritmo de la probabilidad predicha de la acción seleccionada por el tamaño de la recompensa acumulada, teniendo en cuenta el descuento. El valor de la probabilidad pronosticada se normaliza en el rango [0, 1].
![]()
Para que disminuya la varianza, podemos reducir el valor de la recompensa acumulada, pero deberemos hacerlo de tal forma que no perturbe la influencia de las acciones en el resultado general, y al mismo tiempo, deberemos observar la comparabilidad de los datos para las diferentes sesiones de entrenamiento del agente. Como opción alternativa, siempre podemos restar alguna constante fija o la recompensa promedio de toda la sesión.
![]()
La segunda propiedad que nos que querríamos implementar es el aprendizaje del modelo en cuanto a la evaluación de la contribución de cada acción individual. A primera vista, la simple idea de abandonar la recompensa acumulada y usar solo la recompensa para la transición actual para el entrenamiento podría resultar perjudicial. En primer lugar, obtener una gran recompensa en el paso actual no nos garantiza una recompensa igual de cuantiosa en el futuro. Podemos obtener una gran recompensa por pasar a un estado desfavorable: por así decirlo, podemos encontrar "un trozo de queso en una ratonera".
Por otro lado, la recompensa no siempre dependerá de la acción. Con mucha frecuencia, uno puede llegar a una situación en la que la recompensa depende más del estado del entorno que de la capacidad del agente para evaluar dicho estado. Por ejemplo, al realizar transacciones en la dirección de la tendencia global, el Agente puede esperar las tendencias correctivas contra la tendencia y esperar a que el precio se mueva en la dirección adecuada, y para ello, el Agente no necesitará analizar con detalle el estado actual para identificar tendencias. Bastará con determinar correctamente la tendencia global. En este caso, existirá una alta probabilidad de entrar en una posición que no sea al mejor precio. De hecho, con el análisis detallado correcto, sería posible esperar una corrección y entrar en una posición a un mejor precio, pero, si hay muchas pérdidas, corremos el riesgo de que la corrección se convierta en un cambio de tendencia, y luego, sin esperar una reversión, una posición abierta conllevará grandes pérdidas.
Por consiguiente, sería útil comparar exactamente la recompensa acumulada con un determinado resultado de referencia. ¿Pero dónde podemos conseguirlo? Precisamente aquí es donde el Crítico viene al rescate. Con su ayuda, podremos evaluar el trabajo de nuestro Actor.
La idea es que el modelo Crítico esté capacitado para evaluar el estado actual del entorno, es decir, qué recompensa puede obtener el Actor (en potencia) del estado actual antes del final de la sesión. Al mismo tiempo, el Actor aprende a seleccionar las acciones que potencialmente generarán recompensas mayores que el promedio de las sesiones de entrenamiento anteriores. Por lo tanto, reemplazaremos la constante en la fórmula de la función de pérdida anterior con la evaluación del estado.
![]()
donde V(s) será la función de evaluación del estado del entorno.
Para entrenar la función de evaluación del estado, usaremos el mismo error cuadrático medio.
![]()
Debemos decir que en la práctica existen varios enfoques para construir un modelo usando este algoritmo. Usaremos dos redes neuronales separadas. Uno para el Actor, y otra para el Crítico. No obstante, con frecuencia se utiliza una arquitectura de red neuronal con dos salidas, la llamada red neuronal de "dos cabezas", en la que parte de las capas neuronales es común y se encarga de procesar los datos iniciales. Al mismo tiempo, varias capas de toma de decisiones son divididas según las direcciones. Una parte es responsable de la política del modelo (Actor), mientras que la otra se encarga de evaluar el estado (Crítico). No podemos negar que tanto el Actor como el Crítico trabajan con el mismo estado del entorno, y esto significa que la función de reconocimiento del estado puede tener una función común.
Además, existen implementaciones de aprendizaje on-line de modelos actor-crítico con ventaja. En ellos, por analogía con el aprendizaje Q, se sustituye la recompensa acumulada por la suma de la recompensa obtenida en la última transición, y la valoración del estado posterior, teniendo en cuenta el factor de descuento. Entonces las funciones de pérdida tomarán la siguiente forma.
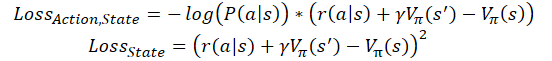
donde ɣ es el factor de descuento.
No obstante, por el aprendizaje on-line hay que pagar. Este modelo tiene un gran error y es más difícil de entrenar.
3. Implementación
Después de familiarizarnos con los aspectos teóricos del método, podemos pasar a la parte práctica de este artículo y construir el proceso de entrenamiento del modelo usando las herramientas de MQL5. A la hora de comenzar a implementar el algoritmo descrito, debemos decir que esta implementación no requerirá cambios cardinales en la arquitectura de construcción de nuestros modelos. No vamos a construir un modelo de dos cabezas, nos limitaremos a construir 2 redes neuronales aparte para el Actor y el Crítico con los medios ya existentes.
Además, no entrenaremos modelos completamente nuevos: en lugar de ello, usaremos 2 modelos de los últimos 2 artículos. El modelo del artículo de aprendizaje Q se utilizará como Crítico, mientras que el modelo del artículo de gradiente de políticas ejercerá de Actor.
Aquí debemos mencionar algunas pequeñas desviaciones respecto al material teórico anterior. El modelo de Actor cumple totalmente con los requisitos del algoritmo analizado, pero en contraste con él, el modelo de Crítico que usaremos será ligeramente diferente de la función de evaluación del estado del entorno descrita anteriormente. El hecho es que la evaluación del estado del entorno no depende de la acción realizada por el agente. Después de todo, el coste de un estado es el beneficio máximo que nuestro Agente puede obtener de dicho estado, y si observamos la función Q que hemos entrenado anteriormente, el coste del estado será igual al valor máximo del vector de resultados de esta función. Sin embargo, para entrenar correctamente el modelo tendremos que considerar la acción que realiza el Agente en el estado analizado.
Ahora proponemos al lector mirar el código de implementación del método. Para entrenar el modelo, crearemos un asesor experto con el elocuente nombre "Actor_Critic.mq5". La plantilla del asesor se ha tomado prestada de los asesores de artículos anteriores. Como hemos mencionado anteriormente, usaremos 2 modelos pre-entrenados. Los modelos han sido entrenados por separado y guardados en diferentes archivos. Por consiguiente, primero definiremos los archivos para cargar los modelos. En su título se lee claramente una referencia a los artículos anteriormente mencionados.
#define ACTOR Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_REINFORCE" #define CRITIC Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_Q-learning"
Para los 2 modelos, necesitamos 2 ejemplares de la clase de red neuronal. Para que el código resulte más transparente, los modelos se nombrarán según su función en el algoritmo que estamos construyendo.
CNet Actor; CNet Critic;
En el método de inicialización del asesor, cargaremos los modelos e inmediatamente compararemos los tamaños de las capas de los datos iniciales y los resultados. Al cargar los modelos, no podemos evaluar la comparabilidad de los modelos para entrenarlos con muestras comparables: simplemente tendremos que verificar la comparabilidad de las arquitecturas de los modelos. En particular, verificaremos el tamaño de la capa de datos de origen. Esto nos dará la confianza de que ambos modelos usan el mismo patrón de descripción del estado para evaluar el estado del entorno.
Luego comprobaremos el tamaño de la capa de resultados de ambos modelos, lo cual nos permitirá comparar la discrecionalidad de las posibles acciones de los agentes.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ................ ................ ................ //--- float temp1, temp2; if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) || !Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false)) return INIT_FAILED; //--- if(!Actor.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; Actor.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; if(!vActions.Resize(SessionSize) || !vRewards.Resize(SessionSize) || !vProbs.Resize(SessionSize)) return INIT_FAILED; //--- if(!Critic.GetLayerOutput(0, TempData)) return INIT_FAILED; if(HistoryBars != TempData.Total() / 12) return INIT_PARAMETERS_INCORRECT; Critic.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; //--- ................ ................ ................ //--- return(INIT_SUCCEEDED); }
Al mismo tiempo, no nos olvidaremos de controlar el proceso de realización de las operaciones y guardaremos los datos necesarios en las variables correspondientes. En particular, guardaremos el número de velas del patrón analizado que se corresponda con el tamaño de la capa de datos inicial de los modelos cargados.
Bueno, la implementación real del algoritmo de entrenamiento del modelo se ha realizado en la función Train. Al inicio de la función, como siempre, determinaremos el rango de la muestra de entrenamiento,
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
y también cargaremos los datos históricos. Al mismo tiempo, deberemos comprobar el resultado de todas las operaciones.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Aquí estimaremos la cantidad de datos cargados y prepararemos las variables locales.
int total = bars - (int)(HistoryBars + SessionSize+2); //--- CBufferFloat* State; float loss = 0; uint count = 0;
A continuación, organizaremos un sistema de ciclos de entrenamiento del modelo. El ciclo exterior contará el número de épocas de entrenamiento. En consecuencia, en el cuerpo del ciclo definiremos el punto de inicio de la sesión, el cual se elegirá aleatoriamente de los datos históricos cargados. A la hora de elegir este punto, tendremos en cuenta 2 factores. El primero: el punto de inicio de la sesión deberá estar precedido por una cantidad de datos históricos suficiente para formar un patrón. El segundo: desde el punto de inicio de la sesión hasta el final de la muestra de entrenamiento, la cantidad de datos históricos deberá ser suficiente para completar la sesión.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0, 1, error_code)), 1) * (total) + SessionSize);
Debemos decir que no hemos implementado el algoritmo de aprendizaje on-line, ya que estamos entrenando el modelo con datos históricos. Y usar una sesión completa generalmente ofrece mejores resultados. Pero al mismo tiempo, el trabajo en el mercado es interminable, así que nos decidimos por una implementación por lotes del algoritmo en la que el tamaño de la sesión estará limitado por el tamaño del paquete de actualización de datos. Este valor será especificado por el usuario en el parámetro externoSessionSize.
Luego crearemos un ciclo anidado para la iteración inicial de la sesión. En el cuerpo de este ciclo, primero crearemos un objeto para registrar los parámetros de la descripción del estado del sistema, y no nos olvidaremos de comprobar el resultado de la creación del nuevo objeto.
States.Clear(); for(int batch = 0; batch < SessionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; }
Después de ello, guardaremos los parámetros del estado actual del entorno. Por así decirlo, prepararemos un patrón para el análisis en el paso actual del algoritmo.
int r = i + (int)HistoryBars; if(r > bars) { delete State; continue; } for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) { delete State; continue; } //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) { delete State; break; } }
Después verificaremos la integridad de los datos guardados y llamaremos al método de pasada directa del modelo de política.
if(IsStopped()) { delete State; ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) { delete State; continue; } if(!Actor.feedForward(GetPointer(State), 12, true)) { delete State; ExpertRemove(); return; }
Luego muestrearemos la acción del agente de la distribución obtenida,
Actor.getResults(TempData); int action = GetAction(TempData); if(action < 0) { delete State; ExpertRemove(); return; }
y determinaremos la recompensa por la acción seleccionada. Debemos decir que la política de recompensas no ha cambiado en absoluto desde los últimos experimentos del artículo anterior, así que planeamos obtener resultados de prueba comparables en cuanto al funcionamiento del método. Esto nos permitirá comparar el impacto del cambio del algoritmo de aprendizaje en el resultado final del modelo, en comparación con las pruebas anteriores.
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -20; else reward *= 1; break; case 1: if(reward > 0) reward *= -20; else reward *= -1; break; default: if(batch == 0) reward = -fabs(reward); else { switch((int)vActions[batch - 1]) { case 0: reward *= -1; break; case 1: break; default: reward = -fabs(reward); break; } } break; }
Después guardaremos los valores obtenidos en búferes para usarlos posteriormente durante la actualización de los pesos del modelo.
if(!States.Add(State)) { delete State; ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)reward; vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
Con esto concluirán las iteraciones del primer ciclo anidado de recopilación de información sobre la sesión, y después de recorrer todos los estados de la sesión, obtendremos un conjunto completo de datos para actualizar los modelos.
A continuación, calcularemos la recompensa acumulada descontada para cada estado del entorno.
vectorf rewards = vectorf::Full(SessionSize, 1); rewards = MathAbs(rewards.CumSum() - SessionSize); rewards = (vRewards * MathPow(vectorf::Full(SessionSize, DiscountFactor), rewards)).CumSum(); rewards = rewards / fmax(rewards.Max(), fabs(rewards.Min()));
Aquí calcularemos el valor de la función de pérdida y guardaremos los modelos cuando logremos los mejores resultados.
loss = (fmin(count, 9) * loss + (rewards * MathLog(vProbs) * (-1)).Sum() / SessionSize) / fmin(count + 1, 10); count++; float total_reward = vRewards.Sum(); if(BestLoss >= loss) { if(!Actor.Save(ACTOR + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false) || !Critic.Save(CRITIC + ".nnw", Critic.getRecentAverageError(), 0, 0, Rates[shift - SessionSize].time, false)) return; BestLoss = loss; }
Tenga en cuenta que guardaremos los modelos antes de actualizar las matrices de peso. Después de todo, ha sido con estos parámetros que el modelo ha logrado los resultados que hemos estimado según la función de pérdida. Después de actualizar las matrices, el modelo obtendrá los parámetros actualizados: los resultados del trabajo con los nuevos parámetros los veremos solo al final de la próxima sesión.
Tras finalizar las iteraciones de la época de entrenamiento, deberemos organizar otro ciclo anidado en el que organizaremos la actualización de los parámetros del modelo. Aquí buscaremos por orden los estados del entorno del búfer y realizaremos una pasada directa por ambos modelos con el estado eliminado. Y, obviamente, no nos olvidaremos de supervisar las operaciones.
for(int batch = SessionSize - 1; batch >= 0; batch--) { State = States.At(batch); if(!Actor.feedForward(State) || !Critic.feedForward(State)) { ExpertRemove(); return; }
Cabe señalar que la implementación de una pasada directa para cada modelo es obligatoria, incluso si guardamos todos los datos necesarios en los búferes. El hecho es que durante la pasada inversa, el algoritmo de aprendizaje utiliza los datos intermedios de los cálculos de las capas neuronales, y para distribuir correctamente el gradiente de error, y con él la actualización de los pesos, necesitaremos alinear claramente la cadena completa de todos los valores intermedios del modelo para cada estado.
A continuación, primero actualizaremos el parámetro del Crítico, y aquí podremos ver que la actualización del modelo se aplica solo a la acción seleccionada por el Agente. En este caso, el gradiente de las acciones restantes se considerará cero: esta diferencia respecto al material teórico descrito anteriormente se debe precisamente al uso de la función Q previamente entrenada, que retorna la recompensa prevista según la acción elegida por el agente. El entrenamiento de la función de evaluación del estado propuesto por los autores del método no dependerá de la acción que se está realizando y no requerirá semejante nivel de detalle.
Critic.getResults(TempData); float value = TempData.At(TempData.Maximum(0, 3)); if(!TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1])) { ExpertRemove(); return; } if(!Critic.backProp(TempData)) { ExpertRemove(); return; }
Después de actualizar con éxito los parámetros del Crítico, actualizaremos los parámetros del Actor de la misma forma. Aquí, como hemos mencionado anteriormente, para evaluar la acción elegida por el Agente, usaremos el valor máximo del vector de resultados de la función Q para el estado analizado del entorno.
if(!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1] - value)) { ExpertRemove(); return; } if(!Actor.backProp(TempData)) { ExpertRemove(); return; } } PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, total_reward, loss); }
Una vez completadas todas las iteraciones de actualización de los parámetros del modelo, mostraremos un mensaje informativo al usuario y pasaremos a la siguiente época.
El proceso de entrenamiento del modelo finalizará tras completarse el número total de épocas, a menos que el usuario interrumpa antes la ejecución.
Comment(""); //--- ExpertRemove(); }
Las operaciones de función se completarán con la limpieza del campo de comentarios y la llamada a la función de finalización del asesor experto.
Encontrará el código completo del asesor en los anexos de este artículo.
4. Simulación
Tras crear el asesor de entrenamiento del modelo, hemos realizado una prueba completa del método Actor-crítico con ventaja . Primero, hemos iniciado el proceso de entrenamiento del modelo. En concreto, el entrenamiento adicional de los modelos de los dos artículos anteriores.
Luego hemos realizado el entrenamiento con el instrumento EURUSD y el marco temporal H1, cargando la historia de los últimos 2 años. Asimismo, hemos utilizado los parámetros del indicador por defecto. Como podemos ver, los parámetros de entrenamiento de los modelos se utilizan casi sin cambios a lo largo de la serie de artículos.
Como ventaja del reentrenamiento de los modelos de los artículos anteriores, podemos mencionar la posibilidad de utilizar los asesores de prueba del artículo anterior para comprobar los resultados de nuestro entrenamiento. Precisamente esto hemos aprovechado. Después de entrenar el modelo, tomamos el modelo de política reentrenado e iniciamos el asesor "REINFORCE-test.mq5" en el simulador de estrategias usando el modelo mencionado. Ya describimos su algoritmo de construcción en el artículo anterior. Asimismo, podrá encontrar su código completo en el archivo adjunto.
A continuación, le mostramos el gráfico del balance del asesor durante la prueba. Cabe señalar que el balance ha aumentado de forma bastante uniforme durante las pruebas. Tenga en cuenta que el modelo se ha puesto a prueba con datos no incluidos en el conjunto de entrenamiento, lo cual habla de la consistencia del enfoque a la hora de construir un sistema comercial. Para que la verificación del funcionamiento del modelo resulte más pura, todas las operaciones se han realizado con un lote mínimo fijo sin usar stop-loss y take-profit. Le desaconsejamos encarecidamente el uso de dicho asesor para el comercio real, aunque, eso sí, muestra muy bien el funcionamiento del modelo entrenado.

En el gráfico de precios, podemos ver cómo de rápido se cierran las transacciones perdedoras, y cómo se mantienen un poco las posiciones rentables. Aquí deberemos prestar atención a que todas las operaciones se realicen en la apertura de una nueva vela. Al mismo tiempo, podemos ver varias operaciones comerciales realizadas casi en la apertura de velas de inversión (fractales).

En general, durante el proceso de prueba, el asesor ha mostrado un factor de beneficio en el nivel de 2,20. La proporción de transacciones rentables ha superado el 56%. Al mismo tiempo, la operación rentable promedio ha superado la operación perdedora promedio en un 70%.

Al mismo tiempo, debemos advertirle contra el uso de este asesor experto en el comercio real, ya que ha sido creado solo para probar el modelo. En primer lugar, el periodo de prueba del asesor es demasiado corto para transferirlo al comercio real. En segundo lugar, el asesor carece de bloques de gestión de dinero y gestión de riesgos. Todas las operaciones comerciales carecen de stop-loss y take-profit, lo cual se desaconseja rigurosamente su uso en operaciones reales.
Conclusión
En este artículo, nos hemos familiarizado con otro algoritmo de aprendizaje por refuerzo: el Actor-crítico con ventaja. Este algoritmo combina enfoques previamente estudiados, como el aprendizaje Q y el gradiente de políticas en su mejor momento. Esto nos permite subir el listón de los resultados obtenidos durante el entrenamiento de modelos con refuerzo. Asimismo, hemos construido el algoritmo analizado usando MQL5, entrenando y probando el modelo con datos históricos reales. Según los resultados de la prueba, el modelo ha mostrado la capacidad de generar beneficio, lo cual nos permite sacar conclusiones sobre la posibilidad de construir sistemas comerciales utilizando este algoritmo de entrenamiento del modelo.
Debemos decir que en las realidades actuales, la familia de algoritmos Actor-Critico probablemente ofrezca los mejores resultados de los métodos de aprendizaje por refuerzo. Sin embargo, antes de usar los modelos para el comercio real, necesitaremos un largo entrenamiento y pruebas exhaustivas utilizando varias pruebas de estrés.
Enlaces
- Asynchronous Methods for Deep Reinforcement Learning
- Redes neuronales: así de sencillo (Parte 26): Aprendizaje por refuerzo
- Redes neuronales: así de sencillo (Parte 27): Aprendizaje Q profundo (DQN)
- Redes neuronales: así de sencillo (Parte 28): Algoritmo de gradiente de políticas
Programas usados en el artículo.
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Actor-Critic.mq5 | Asesor | Asesor para el entrenamiento de modelos |
| 2 | REINFORCE-test.mq5 | Asesor | Asesor Experto para probar modelos en el Simulador de Estrategias |
| 3 | NeuroNet.mqh | Biblioteca de clases | Biblioteca para organizar modelos de redes neuronales |
| 4 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL para organizar modelos de redes neuronales |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11452
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Aprendiendo a diseñar un sistema de trading con Awesome Oscillator
Aprendiendo a diseñar un sistema de trading con Awesome Oscillator
 Aprendiendo a diseñar un sistema de trading con Relative Vigor Index
Aprendiendo a diseñar un sistema de trading con Relative Vigor Index
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
...Bueno, por alguna razón la librería Normal es inalcanzable en VAE.mqh si se llama desde NeuroNet, realmente no sé por qué (lo he intentado en 2 versiones diferentes)...
Así que lo resolví añadiendo la llamada a Normal directamente en VAE y Neuronet, pero tuve que deshacerme del espacio Math en el FQF:
raro... pero funcionó:
La inicialización ha fallado debido a la ausencia de EURUSD_PERIOD_H1_REINFORCE.nnw al ejecutar las siguientes sentencias
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||| Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false)
Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
return INIT_FAILED;
¿Cómo solucionar este problema? Gracias.
Otra solución para una advertencia "... método oculto llamando ..."
En la línea 327 de Actor_Critic.mq5:
Me aparece la advertencia "comportamiento obsoleto, la llamada a métodos ocultos se desactivará en una futura versión del compilador MQL":
Esto se refiere a la llamada de "Máximo(0, 3)", que debe ser cambiado a:
Así que en este caso tenemos que añadir "CArrayFloat::" para especificar el método en cuestión. El método Maximum() es sobrescrito por la clase CBufferFloat, pero ésta no tiene parámetros.
Aunque la llamada debería ser inequívoca porque tiene dos parámetros, el compilador quiere que seamos conscientes ;-)
La inicialización falló debido a la ausencia de EURUSD_PERIOD_H1_REINFORCE.nnw al ejecutar las siguientes sentencias
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||
Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
return INIT_FAILED;
¿Cómo solucionar este problema? Gracias.
En estas líneas se carga la estructura de red que se debe entrenar. Tienes que construir la red y guardarla en el archivo nombrado antes de iniciar este EA. Puedes utilizar, por ejemplo, la herramienta de construcción de modelos del artículo nº 23
https://www.mql5.com/es/articles/11273
¿Puede usted explicar más sobre el código para calcular la recompensa. Porque en la Parte 27, la política de recompensa es la siguiente, difiere con el código anterior: