Aprendizaje automático y Data Science (Parte 11): Clasificador bayesiano ingenuo y teoría de la probabilidad en el trading

Cuarta ley de la termodinámica: si la probabilidad de éxito no está próxima a cero, estará cercana a cero.
A. Kondrashov
Introducción
Un clasificador bayesiano ingenuo es un algoritmo probabilístico usado en el aprendizaje automático para tareas de clasificación. El clasificador toma como base el teorema de Bayes (o fórmula de Bayes), que determina la probabilidad de una hipótesis con las pruebas disponibles. El clasificador probabilístico es un algoritmo simple pero eficaz en diversas situaciones. Se supone que los atributos usados para la clasificación son independientes entre sí. Por ejemplo, si queremos que el modelo clasifique a las personas (hombres y mujeres) según la altura, el tamaño de los pies, el peso y la anchura de los hombros, el modelo trataría todas estas variables como independientes entre sí. Ni siquiera se plantearía que el tamaño de las piernas y la altura de una persona están relacionados.
Como el algoritmo no intenta comprender los patrones entre las variables independientes, creo que merece la pena intentar usarlo en el trabajo para tomar decisiones comerciales. A mi juicio, de todas formas, nadie entiende al completo el patrón en el campo del trading, así que vamos a echar un vistazo al funcionamiento de un algoritmo bayesiano ingenuo.

Sin más preámbulos, llamaremos directamente a un ejemplar del modelo y lo utilizaremos. Más adelante hablaremos de los componentes de este modelo.
Preparación de los datos de entrenamiento
Para este ejemplo, hemos elegido 5 indicadores, la mayoría de los cuales son osciladores e indicadores de volumen. Creo que son buenas variables de clasificación y, además, tienen un número finito, lo cual las hace adecuadas para una distribución normal, que, a su vez, supone una de las ideas en las que se basa este algoritmo. No obstante, esta lista no es una referencia, por lo que podemos confeccionar nuestro propio conjunto y explorar los distintos indicadores y datos que nos convengan.
Vayamos por orden:
matrix Matrix(TrainBars, 6); int handles[5]; double buffer[]; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Preparing Data handles[0] = iBearsPower(Symbol(),TF, bears_period); handles[1] = iBullsPower(Symbol(),TF, bulls_period); handles[2] = iRSI(Symbol(),TF,rsi_period, rsi_price); handles[3] = iVolumes(Symbol(),TF,VOLUME_TICK); handles[4] = iMFI(Symbol(),TF,mfi_period,VOLUME_TICK ); //--- vector col_v; for (ulong i=0; i<5; i++) //Independent vars { CopyBuffer(handles[i],0,0,TrainBars, buffer); col_v = matrix_utils.ArrayToVector(buffer); Matrix.Col(col_v, i); } //-- Target var vector open, close; col_v.Resize(TrainBars); close.CopyRates(Symbol(),TF, COPY_RATES_CLOSE,0,TrainBars); open.CopyRates(Symbol(),TF, COPY_RATES_OPEN,0,TrainBars); for (int i=0; i<TrainBars; i++) { if (close[i] > open[i]) //price went up col_v[i] = 1; else col_v[i] = 0; } Matrix.Col(col_v, 5); //Adding independent variable to the last column of matrix //---
Las variables TF, bears_period y otras son variables de entrada definidas, y se determinan en la parte superior del código anterior.
Como estamos tratando con el aprendizaje, hemos tenido que introducir una variable objetivo. La lógica es simple: si el precio de cierre ha sido superior al precio de apertura, a la variable objetivo se le asignará una clase 1, de lo contrario la clase será 0. Así obtendremos el valor de la variable objetivo. A continuación, le mostramos el aspecto de una matriz con un conjunto de datos:
CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) "Bears" "Bulls" "Rsi" "Volumes" "MFI" "Target Var" CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-3.753148029472797e-06,0.008786246851970603,67.65238281791684,13489,55.24611392389958,0] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.002513216984025402,0.005616783015974569,50.29835423473968,12226,49.47293811405203,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.001829900272021678,0.0009700997279782353,47.33479153312328,7192,46.84320886771249,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.004718485947447171,-0.0001584859474472733,39.04848493977027,6267,44.61564654651691,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.004517273669240485,-0.001367273669240276,45.4127802340401,3867,47.8438816641815,0]
Después decidimos representar los datos en los gráficos de distribución para ver si coincidían con la distribución de probabilidad:





Si quiere saber más sobre los diferentes tipos de distribuciones de probabilidad, encontrará un artículo entero sobre este tema en el enlace.
Observemos con mayor detenimiento la matriz de coeficientes de correlación de todas las variables independientes:
string header[5] = {"Bears","Bulls","Rsi","Volumes","MFI"}; matrix vars_matrix = Matrix; //Independent variables only matrix_utils.RemoveCol(vars_matrix, 5); //remove target variable ArrayPrint(header); Print(vars_matrix.CorrCoef(false));
Información mostrada:
CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) "Bears" "Bulls" "Rsi" "Volumes" "MFI" CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [[1,0.7784600081627714,0.8201955846987788,-0.2874457184671095,0.6211980865273238] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.7784600081627714,1,0.8257210032763984,0.2650418244580489,0.6554288778228361] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.8201955846987788,0.8257210032763984,1,-0.01205084357067248,0.7578863565293196] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [-0.2874457184671095,0.2650418244580489,-0.01205084357067248,1,0.0531475992791923] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.6211980865273238,0.6554288778228361,0.7578863565293196,0.0531475992791923,1]]
Podemos observar que, salvo la correlación de los volúmenes con el resto, todas las variables están muy correlacionadas entre sí. En algunos casos la correlación resulta muy fuerte, por ejemplo entre el RSI y Bulls and Bears la correlación ha sido de alrededor del 82%. Los indicadores Volúmenes e IFM tienen partes en común -en concreto, los propios volúmenes-, por lo que su correlación del 62% es perfectamente comprensible. Como el método bayesiano ingenuo gaussiano no entra en detalles sobre estas razones, seguiremos adelante. Solo he pensado que sería una buena idea comprobar y analizar las variables.
Entrenamiento de modelos
El entrenamiento del método bayesiano ingenuo gaussiano es sencillo y rápido. Veamos cómo tiene lugar el proceso:
Print("\n---> Training the Model\n"); matrix x_train, x_test; vector y_train, y_test; matrix_utils.TrainTestSplitMatrices(Matrix,x_train,y_train,x_test,y_test,0.7,rand_state); //--- Train gaussian_naive = new CGaussianNaiveBayes(x_train,y_train); //Initializing and Training the model vector train_pred = gaussian_naive.GaussianNaiveBayes(x_train); //making predictions on trained data vector c= gaussian_naive.classes; //Classes in a dataset that was detected by mode metrics.confusion_matrix(y_train,train_pred,c); //analyzing the predictions in confusion matrix //---
La función TrainTestSplitMatrices divide los datos en x matrices de entrenamiento y x matrices de prueba, así como sus correspondientes vectores objetivo. Es similar a la función train_test_split en sklearn python. La función principal tendrá el aspecto que sigue:
void CMatrixutils::TrainTestSplitMatrices(matrix &matrix_,matrix &x_train,vector &y_train,matrix &x_test, vector &y_test,double train_size=0.7,int random_state=-1)
Por defecto, el 70% de los datos se destinarán a datos de entrenamiento, mientras que el resto se guardará como muestra de prueba. Podrá leer más información sobre esta división de datos aquí.
Lo que confunde a mucha gente sobre esta función es el parámetro random_state. En la comunidad Python ML, la gente a menudo establece random_state = 42, aunque en realidad cualquier número servirá, ya que este parámetro existe solo para asegurar que la matriz aleatoria/barajada se genere de la misma forma cada vez y así simplificar la depuración, ya que Random seed se utiliza para generar números aleatorios para barajar las filas de la matriz.
Podemos observar que las matrices de salida derivadas de esta función no están ordenadas en el orden por defecto. Podrá leer varias discusiones sobre la elección de este número 42, por ejemplo aquí.
Esto es lo que tenemos en la salida de este bloque de código:
CS 0 14:33:04.001 Naive Bayes Test (EURUSD,H1) ---> Training the Model CS 0 14:33:04.001 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) ---> GROUPS [0,1] CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) ---> Prior_proba [0.5457142857142857,0.4542857142857143] Evidence [382,318] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Confusion Matrix CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) [[236,146] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) [145,173]] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Classification Report CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) 0.0 0.62 0.62 0.54 0.62 382.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) 1.0 0.54 0.54 0.62 0.54 318.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Accuracy 0.58 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Average 0.58 0.58 0.58 0.58 700.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) W Avg 0.58 0.58 0.58 0.58 700.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1)
Según el informe de clasificación de la matriz de confusión, la precisión del modelo entrenado ha sido del 58%. Hay muchas cosas que entender de este informe, como la precisión que indica con qué exactitud se ha clasificado cada clase (más detalles). En general, parece que la Clase 0 está mejor clasificada que la Clase 1. En líneas generales, esto resulta comprensible, ya que el modelo lo ha predicho más que la segunda clase1, por no hablar de la probabilidad a priori (la principal probabilidad primaria en la muestra de datos). En este conjunto de datos, disponemos de estas probabilidades a priori:
Prior_proba [0.5457142857142857,0.4542857142857143] Evidence [382,318]. La probabilidad a priori se calcula como:
Probabilidad a priori = prueba/número total de eventos/resultados
En nuestro caso, Prior Proba [382/700, 318/700]. Recordemos que 700 es el tamaño de la muestra de entrenamiento resultante de dividir los datos para asignar el 70% al entrenamiento de una muestra total de 1.000.
Un modelo bayesiano gaussiano ingenuo busca primero las probabilidades de aparición de las clases con un conjunto de datos y, a continuación, las usa para adivinar lo que podría ocurrir en el futuro basándose en el cálculo de las pruebas. La clase con la prueba más alta tendrá una probabilidad más alta, y por lo tanto resultará preferida al algoritmo para el entrenamiento y la prueba. Tiene todo el sentido, ¿no? Este es uno de los inconvenientes de este algoritmo, porque cuando falta una clase en los datos de entrenamiento, el modelo asume que la clase no existe, por lo que le atribuye una probabilidad cero, lo cual significa que no habrá predicciones para esa clase en la muestra de prueba ni nunca en el futuro.
Pruebas con modelos
Tampoco resulta complicado probar el modelo. Todo lo que deberemos hacer es añadir los nuevos datos a la función GaussianNaiveBayes, que en este punto ya tiene los parámetros del modelo entrenado.
//--- Test Print("\n---> Testing the model\n"); vector test_pred = gaussian_naive.GaussianNaiveBayes(x_test); //giving the model test data to predict and obtain predictions to a vector metrics.confusion_matrix(y_test,test_pred, c); //analyzing the tested model
Resultados
CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) ---> Testing the model CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Confusion Matrix CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) [[96,54] CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) [65,85]] CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Classification Report CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) 0.0 0.60 0.64 0.57 0.62 150.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) 1.0 0.61 0.57 0.64 0.59 150.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Accuracy 0.60 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Average 0.60 0.60 0.60 0.60 300.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) W Avg 0.60 0.60 0.60 0.60 300.0
Bueno, el modelo ha funcionado ligeramente mejor en la muestra de prueba, mostrando una precisión del 60%, que es un 2% superior a la precisión de los datos de entrenamiento, así que son buenas noticias.
Modelo bayesiano gaussiano ingenuo en el simulador de estrategias
El uso de modelos de aprendizaje automático en el simulador de estrategias no suele ofrecer buenos resultados, no porque los modelos sean incapaces de hacer predicciones, sino porque solemos fijarnos en el gráfico de beneficios del simulador de estrategias. Un modelo de aprendizaje automático es capaz de adivinar hacia dónde se dirigirá el mercado a continuación, pero eso no implica necesariamente que vayamos a ganar dinero con él, sobre todo considerando la lógica simple que hemos utilizado para recopilar y preparar nuestro conjunto de datos. Veamos las muestras de datos recogidas en cada barra para el marco temporal establecido en el parámetro, en este caso PERIOD_H1 (TF de horas).
close.CopyRates(Symbol(),TF, COPY_RATES_CLOSE,0,TrainBars); open.CopyRates(Symbol(),TF, COPY_RATES_OPEN,0,TrainBars);
Hemos recopilado 1000 barras del marco temporal de horas y leído los valores de sus indicadores en variables independientes. A continuación, crearemos las variables objetivo que indicarán si la vela ha sido alcista, en cuyo caso el asesor establecerá la clase 1. En caso contrario, establecerá la clase en 0. Estos valores se considerarán en la función comercial. Como nuestro modelo predice la vela siguiente, se abrirán transacciones en cada vela nueva; en este caso, además, las transacciones anteriores se habrán cerrado. En esencia, hemos permitido que nuestro asesor comercie según cada señal en cada barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if (!train_state) TrainTest(); train_state = true; //--- vector v_inputs(5); //5 independent variables double buff[1]; //current indicator value for (ulong i=0; i<5; i++) //Independent vars { CopyBuffer(handles[i],0,0,1, buff); v_inputs[i] = buff[0]; } //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); int signal = -1; double min_volume = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (isNewBar()) { signal = gaussian_naive.GaussianNaiveBayes(v_inputs); Comment("SIGNAL ",signal); CloseAll(); if (signal == 1) { if (!PosExist()) m_trade.Buy(min_volume, Symbol(), ticks.ask, 0 , 0,"Naive Buy"); } else if (signal == 0) { if (!PosExist()) m_trade.Sell(min_volume, Symbol(), ticks.bid, 0 , 0,"Naive Sell"); } } }
Para que esta función opere tanto en el comercio real como en el simulador de estrategias, hemos tenido que cambiar un poco la lógica. La función CopyBuffer()y el entrenamiento se encuentran ahora dentro de la función TrainTest(). Esta función se inicia una vez en la función OnTick. Podemos hacer que funcione con mayor frecuencia y el modelo también se entrenará más a menudo. Lo dejamos a la discreción del lector.
Dado que la función Init no resulta adecuada para todos estos métodos copy buffer y copy rates (retornan valores cero en el simulador de estrategias), ahora trasladaremos todo a TrainTest().
int OnInit() { handles[0] = iBearsPower(Symbol(),TF, bears_period); handles[1] = iBullsPower(Symbol(),TF, bulls_period); handles[2] = iRSI(Symbol(),TF,rsi_period, rsi_price); handles[3] = iVolumes(Symbol(),TF,VOLUME_TICK); handles[4] = iMFI(Symbol(),TF,mfi_period,VOLUME_TICK ); //--- m_trade.SetExpertMagicNumber(MAGIC_NUMBER); m_trade.SetTypeFillingBySymbol(Symbol()); m_trade.SetMarginMode(); m_trade.SetDeviationInPoints(slippage); return(INIT_SUCCEEDED); }
Prueba única: marco temporal de horas
Hemos realizado la prueba con los datos de dos meses, del 1 de enero de 2023 al 14 de febrero de 2023.
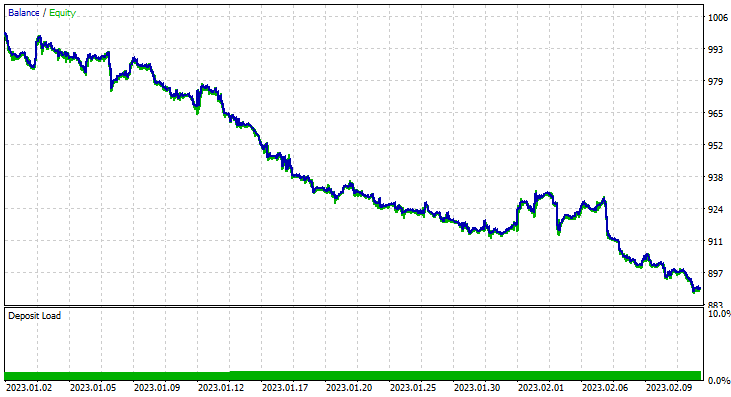
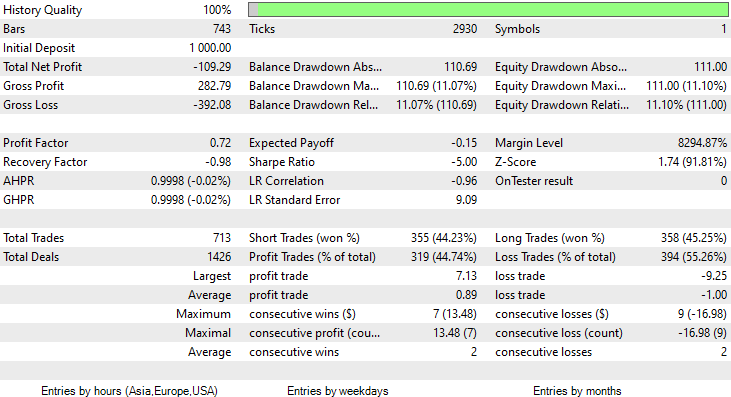
Hemos seleccionado este periodo de pruebas en concreto (2 meses) porque 1000 horas de barras no representan un periodo de entrenamiento tan grande. Son casi 41 días, por lo que el periodo de entrenamiento es corto, al igual que las pruebas. Con la función TrainTest() operando en el simulador, hemos obtenido una prueba con 700 barras.
¿Qué ha ocurrido?
El modelo ha causado una buena primera impresión al realizarse la prueba en el simulador de estrategias, ofreciendo una notable precisión del 60% con los datos de entrenamiento.
CS 0 08:30:13.816 Tester initial deposit 1000.00 USD, leverage 1:100 CS 0 08:30:13.818 Tester successfully initialized CS 0 08:30:13.818 Network 80 Kb of total initialization data received CS 0 08:30:13.819 Tester Intel Core i5 660 @ 3.33GHz, 6007 MB CS 0 08:30:13.900 Symbols EURUSD: symbol to be synchronized CS 0 08:30:13.901 Symbols EURUSD: symbol synchronized, 3720 bytes of symbol info received CS 0 08:30:13.901 History EURUSD: history synchronization started .... .... .... CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> Training the Model CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> GROUPS [0,1] CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> Prior_proba [0.4728571428571429,0.5271428571428571] Evidence [331,369] CS 0 08:30:14.377 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Confusion Matrix CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 [[200,131] CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 [150,219]] CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Classification Report CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 _ Precision Recall Specificity F1 score Support CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 0.0 0.57 0.60 0.59 0.59 331.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 1.0 0.63 0.59 0.60 0.61 369.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Accuracy 0.60 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Average 0.60 0.60 0.60 0.60 700.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 W Avg 0.60 0.60 0.60 0.60 700.0
Sin embargo, más adelante, el asesor no ha logrado realizar operaciones rentables con la precisión prometida o cerca de ella. A continuación, encontrará mis observaciones:
- La lógica resulta en cierta forma ciega, y la estrategia sacrifica calidad por cantidad. El asesor ha realizado 713 transacciones en dos meses. Eso es mucho, y este punto debe modificarse. Entrenaremos el modelo en un marco temporal más alto y comerciaremos también en marcos temporales más altos, con el tiempo, esto reducirá el número de transacciones realizadas.
- Esta vez reduciremos las barras para el entrenamiento: queremos entrenar el modelo usando los datos más recientes.
Para ello, hemos ejecutado la optimización en un marco temporal de seis horas, obteniendo Train Bars = 80, TF = 12 hours. La prueba se ha realizado con los datos de dos meses usando los nuevos parámetros. Todos los parámetros están disponibles en el archivo *set adjunto al final del artículo.
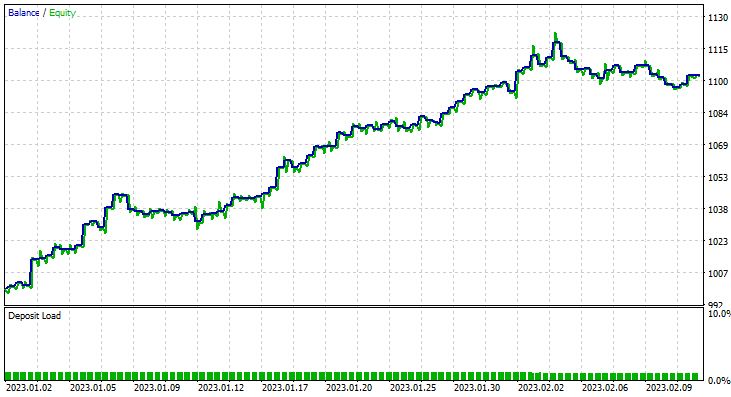
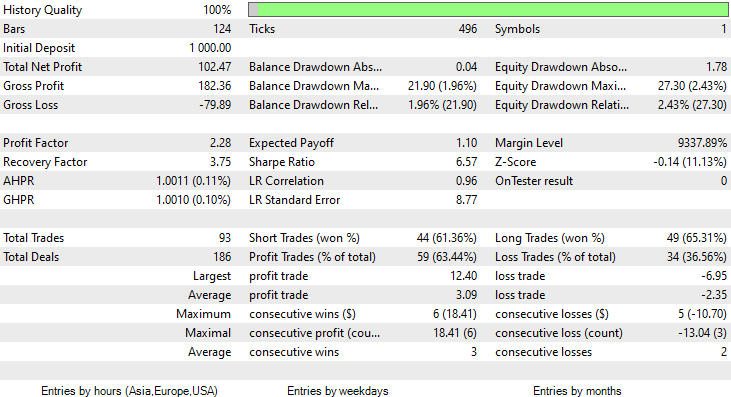
Esta vez, la precisión de entrenamiento del modelo bayesiano ingenuo gaussiano ha sido del 58%.
93 transacciones en un periodo de 2 meses: eso podría llamarse una actividad comercial saludable. De media hemos obtenido 2,3 transacciones diarias. Esta vez, el 63% de las transacciones realizadas por el asesor Gaussian Naïve Bayes han sido rentables. El beneficio ha sido del 10%.
Ya hemos visto cómo puede usarse un modelo bayesiano gaussiano ingenuo para tomar decisiones comerciales. Ahora veamos cómo funciona.
Teoría bayesiana ingenua
No se debe confundir con el método Bayesiano ingenuo gaussiano.
El algoritmo se denomina
- Ingenuo porque supone que las variables/funciones son independientes, lo cual en realidad no suele ser así.
-
Bayesiano, porque se basa en el teorema de Bayes
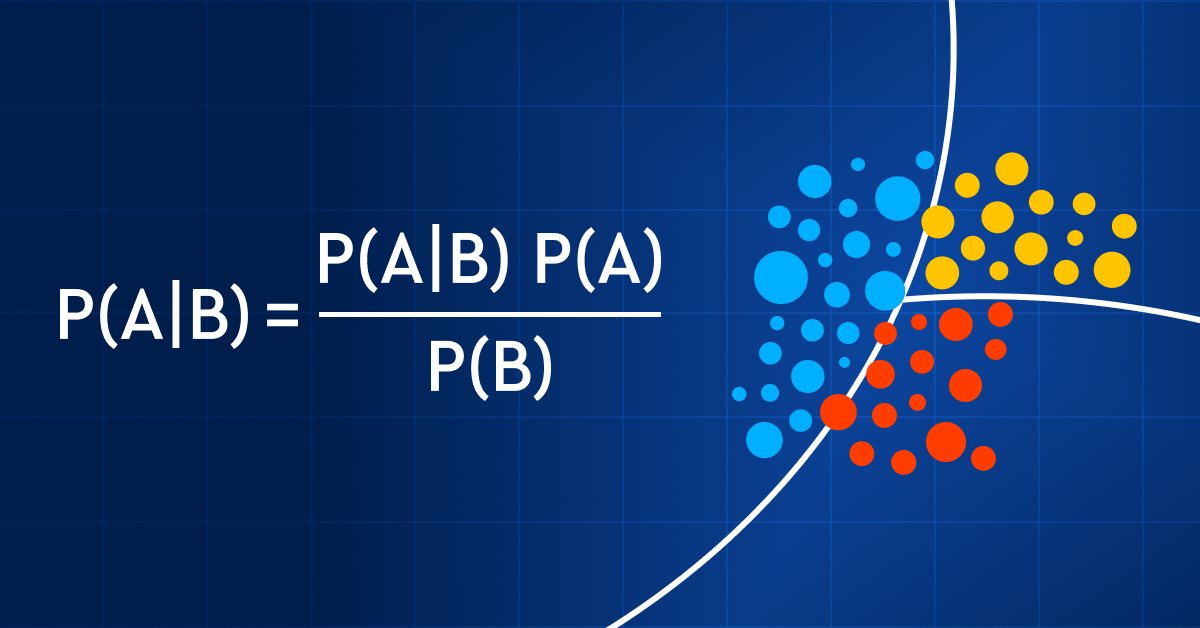
A continuación, ofrecemos la fórmula del teorema de Bayes:
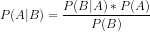
Donde:
P(A|B) — probabilidad a posteriori de la hipótesis (estado) A cuando se observa el suceso B
P(B|A) — probabilidad de que ocurra el suceso bajo la condición de que la probabilidad de la teoría sea correcta. En términos sencillos, es la probabilidad de B si A es cierta
P(A) — probabilidad a priori (incondicional) de A o la probabilidad de la hipótesis antes de que ocurra el evento
P(B) — probabilidad marginal de que se produzca el evento
Los términos de esta fórmula podrían parecer confusos al principio. Luego, a medida que trabajemos con nuestro algoritmo, las cosas se aclararán.
Trabajando con el clasificador
Veamos un ejemplo sencillo con una muestra de datos meteorológicos. Observemos la primera columna "Previsión". Primero deberemos entender lo que ocurre en ella, y luego trataremos de añadir otras columnas como variables independientes: se trata exactamente del mismo proceso.
| Previsión | Jugar al tenis |
|---|---|
| Soleado | No |
| Soleado | No |
| Nublado | Sí |
| Lluvia | Sí |
| Lluvia | Sí |
| Lluvia | No |
| Nublado | Sí |
| Soleado | No |
| Soleado | Sí |
| Lluvia | Sí |
| Soleado | Sí |
| Nublado | Sí |
| Nublado | Sí |
| Lluvia | No |
Ahora haremos lo mismo en el MetaEditor:
void OnStart() { //--- matrix Matrix = matrix_utils.ReadCsvEncode("weather dataset.csv"); int cols[3] = {1,2,3}; matrix_utils.RemoveMultCols(Matrix, cols); //removing Temperature Humidity and Wind ArrayRemove(matrix_utils.csv_header,1,3); //removing column headers ArrayPrint(matrix_utils.csv_header); Print(Matrix); matrix x_matrix; vector y_vector; matrix_utils.XandYSplitMatrices(Matrix, x_matrix, y_vector); }
Tenga en cuenta que Naive Bayes solo sirve para variables discretas/intermitentes. No hay que confundirlo con el modelo bayesiano gaussiano ingenuo que hemos visto en acción más arriba: él puede gestionar variables continuas, a diferencia de este modelo bayesiano ingenuo. Por eso, en este ejemplo, hemos optado por usar este conjunto de datos concreto, que contiene valores discretos. A continuación, representamos el resultado del código mostrado anteriormente.
CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) "Outlook" "Play" CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [[0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,0]]
Ahora encontraremos la probabilidad a priori en nuestro constructor de la clase NaïveBayes:
CNaiveBayes::CNaiveBayes(matrix &x_matrix, vector &y_vector) { XMatrix.Copy(x_matrix); YVector.Copy(y_vector); classes = matrix_utils.Classes(YVector); c_evidence.Resize((ulong)classes.Size()); n = YVector.Size(); if (n==0) { Print("--> n == 0 | Naive Bayes class failed"); return; } //--- vector v = {}; for (ulong i=0; i<c_evidence.Size(); i++) { v = matrix_utils.Search(YVector,(int)classes[i]); c_evidence[i] = (int)v.Size(); } //--- c_prior_proba.Resize(classes.Size()); for (ulong i=0; i<classes.Size(); i++) c_prior_proba[i] = c_evidence[i]/(double)n; #ifdef DEBUG_MODE Print("---> GROUPS ",classes); Print("Prior Class Proba ",c_prior_proba,"\nEvidence ",c_evidence); #endif }
Resultados
CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) ---> GROUPS [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) Prior Class Proba [0.3571428571428572,0.6428571428571429] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) Evidence [5,9]
La probabilidad a priori [Yes, No] es aproximadamente [0,36, 0,64].
Supongamos ahora que queremos conocer la probabilidad de que una persona juegue al tenis en un día soleado. Para ello, haremos lo siguiente:
P(Yes | Sunny) = P(Sunny | Yes) * P(Yes) / P(Sunny)
More details in simple English:
La probabilidad de que alguien juegue en un día soleado = cuántas veces probablemente hacía sol y alguien jugaba al tenis * cuántas veces en términos de probabilidad jugaba la gente al tenis / cuántas veces en términos de probabilidad era un día soleado.
P(Sunny | Yes) = 2/9
P(Yes) = 0.64
P(Sunny) = 5/14 = 0.357
El total es P(Yes | Sunny) = 0.333 x 0.64 / 0.357 = 0.4
En cuanto a la probabilidad (No| Sunny), podemos calcularla así: 1 - probabilidad Yes = 1 - 0,5972 = 0,4027. Así de fácil, pero, de todas formas, vamos a ver también esa parte.
P(No|Sunny) = (3/5) x 0.36 / (0.357) = 0.6
En el código, esto sucede así:
vector CNaiveBayes::calcProba(vector &v_features) { vector proba_v(classes.Size()); //vector to return if (v_features.Size() != XMatrix.Cols()) { printf("FATAL | Can't calculate probability, features columns size = %d is not equal to XMatrix columns =%d",v_features.Size(),XMatrix.Cols()); return proba_v; } //--- vector v = {}; for (ulong c=0; c<classes.Size(); c++) { double proba = 1; for (ulong i=0; i<XMatrix.Cols(); i++) { v = XMatrix.Col(i); int count =0; for (ulong j=0; j<v.Size(); j++) { if (v_features[i] == v[j] && classes[c] == YVector[j]) count++; } proba *= count==0 ? 1 : count/(double)c_evidence[c]; //do not calculate if there isn't enough evidence } proba_v[c] = proba*c_prior_proba[c]; } return proba_v; }
El vector de probabilidad ofrecido por esta función para el tiempo soleado:
2023.02.15 16:34:21.519 Naive Bayes theory script (EURUSD,H1) Probabilities [0.6,0.4]
Precisamente lo que esperábamos. Pero atención, esta función no nos ofrece la probabilidad. Me explico. Cuando solo hay dos clases en el conjunto de datos de pronóstico, en este escenario el resultado es una probabilidad, pero por otro lado la salida de esta función necesita ser comprobada en términos de probabilidad. Es algo bastante sencillo:
Tomamos la suma del vector que resulta de esta función, luego dividimos cada elemento por el total, y el vector restante serán los valores reales de probabilidad, que sumados serán iguales a uno.
probability_v = v[i]/probability_v.Sum()
Este pequeño proceso se realiza dentro de la función NaiveBayes(), que predice el resultado de la clase o clases con mayor probabilidad de todas:
int CNaiveBayes::NaiveBayes(vector &x_vector) { vector v = calcProba(x_vector); double sum = v.Sum(); for (ulong i=0; i<v.Size(); i++) //converting the values into probabilities v[i] = NormalizeDouble(v[i]/sum,2); vector p = v; #ifdef DEBUG_MODE Print("Probabilities ",p); #endif return((int)classes[p.ArgMax()]); }
Esto es todo. El algoritmo bayesiano ingenuo es muy simple. Ahora nos centraremos en el algoritmo bayesiano ingenuo gaussiano que hemos usado al principio de este artículo.
Método bayesiano ingenuo gaussiano
El método bayesiano ingenuo gaussiano supone que los signos siguen una distribución normal. Esto significa que si los predictores toman variables continuas en lugar de variables discretas, se supone que estos valores se tomarán de la distribución gaussiana.
Recordando la distribución normal
La distribución normal es una distribución de probabilidad continua que es simétrica respecto a su media. La mayoría de las observaciones se concentran en torno a un pico central, mientras que las probabilidades de los valores más alejados de la media se estrechan por igual en ambas direcciones. Los valores extremos en ambas colas de la distribución también resultan poco probables.

Esta curva de probabilidad en forma de campana resulta tan eficaz que se considera una de las herramientas más útiles del análisis estadístico. Muestra que existe aproximadamente un 34% de probabilidades de encontrar algo en una desviación estándar de la media y un 34% de probabilidades de encontrar algo en el otro lado de la curva de distribución normal. Esto significa que la probabilidad de encontrar un valor que halle dentro de una desviación típica de la media en ambos lados es de aproximadamente el 68%. Si quiere saber más sobre este tema, le recomiendo entrar aquí.
A partir de esta distribución normal/gaussiana, debemos encontrar la función de densidad de la probabilidad. Se calcula de acuerdo con la fórmula siguiente.
![]()
donde:
μ — valor medio
𝜎 — desviación típica
x — valor de entrada
Dado que esto forma parte de un algoritmo bayesiano ingenuo gaussiano, escribiremos el código correspondiente.
class CNormDistribution { public: double m_mean; //Assign the value of the mean double m_std; //Assign the value of Variance CNormDistribution(void); ~CNormDistribution(void); double PDF(double x); //Probability density function }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CNormDistribution::CNormDistribution(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CNormDistribution::~CNormDistribution(void) { ZeroMemory(m_mean); ZeroMemory(m_std); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CNormDistribution::PDF(double x) { double nurm = MathPow((x - m_mean),2)/(2*MathPow(m_std,2)); nurm = exp(-nurm); double denorm = 1.0/(MathSqrt(2*M_PI*MathPow(m_std,2))); return(nurm*denorm); }
Creando un modelo bayesiano ingenuo gaussiano
El constructor de la clase Gaussian Naïve Bayes resulta similar al constructor de la clase Naïve Bayes. Por ello, aquí no mostraremos ni explicaremos el código del constructor. A continuación, le mostramos nuestra función principal responsable del cálculo de la probabilidad.
vector CGaussianNaiveBayes::calcProba(vector &v_features) { vector proba_v(classes.Size()); //vector to return if (v_features.Size() != XMatrix.Cols()) { printf("FATAL | Can't calculate probability, features columns size = %d is not equal to XMatrix columns =%d",v_features.Size(),XMatrix.Cols()); return proba_v; } //--- vector v = {}; for (ulong c=0; c<classes.Size(); c++) { double proba = 1; for (ulong i=0; i<XMatrix.Cols(); i++) { v = XMatrix.Col(i); int count =0; vector calc_v = {}; for (ulong j=0; j<v.Size(); j++) { if (classes[c] == YVector[j]) { count++; calc_v.Resize(count); calc_v[count-1] = v[j]; } } norm_distribution.m_mean = calc_v.Mean(); //Assign these to Gaussian Normal distribution norm_distribution.m_std = calc_v.Std(); #ifdef DEBUG_MODE printf("mean %.5f std %.5f ",norm_distribution.m_mean,norm_distribution.m_std); #endif proba *= count==0 ? 1 : norm_distribution.PDF(v_features[i]); //do not calculate if there isn't enough evidence } proba_v[c] = proba*c_prior_proba[c]; //Turning the probability density into probability #ifdef DEBUG_MODE Print(">> Proba ",proba," prior proba ",c_prior_proba); #endif } return proba_v; }
Veamos cómo se comporta este modelo en la práctica.
Como ejemplo, tomaremos una muestra sobre datos de género.
| Altura (pies) | Peso (libras) | Tamaño del pie (pulgadas) | Sexo (0 - hombre, 1 - mujer) |
|---|---|---|---|
| 6 | 180 | 12 | 0 |
| 5.92 | 190 | 11 | 0 |
| 5.58 | 170 | 12 | 0 |
| 5.92 | 165 | 10 | 0 |
| 5 | 100 | 6 | 1 |
| 5.5 | 150 | 8 | 1 |
| 5.42 | 130 | 7 | 1 |
| 5.75 | 150 | 9 | 1 |
//--- Gaussian naive bayes Matrix = matrix_utils.ReadCsv("gender dataset.csv"); ArrayPrint(matrix_utils.csv_header); Print(Matrix); matrix_utils.XandYSplitMatrices(Matrix, x_matrix, y_vector); gaussian_naive = new CGaussianNaiveBayes(x_matrix, y_vector);
Información mostrada:
CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) ---> GROUPS [0,1] CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) ---> Prior_proba [0.5,0.5] Evidence [4,4]
Como 4 de los 8 eran del género masculino y los otros 4 eran de género femenino, el modelo tiene una probabilidad del 50% de predecir el género masculino o femenino.
Vamos a probar un modelo con los nuevos datos de una persona que mide 5,3, pesa 140 y tiene un pie de 7,5. Usted y yo entendemos que esta persona es probablemente una mujer.
vector person = {5.3, 140, 7.5}; Print("The Person is a ",gaussian_naive.GaussianNaiveBayes(person));
Información mostrada:
2023.02.15 19:14:40.424 Naive Bayes theory script (EURUSD,H1) The Person is a 1
Estupendo, la predicción ha salido bien: es una mujer.
La prueba de un modelo bayesiano ingenuo gaussiano también es relativamente sencilla. Bastará con transmitir la matriz con la que se ha entrenado el modelo y medir la precisión de las predicciones usando la matriz de confusión.
CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Confusion Matrix CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) [[4,0] CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) [0,4]] CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Classification Report CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) 0.0 1.00 1.00 1.00 1.00 4.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 4.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Accuracy 1.00 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Average 1.00 1.00 1.00 1.00 8.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) W Avg 1.00 1.00 1.00 1.00 8.0
La precisión del entrenamiento será del 100%. Nuestro modelo puede clasificar si una persona es hombre o mujer, usando para ello todos los datos como muestra de entrenamiento.
Ventajas de los clasificadores bayesianos ingenuos y gaussianos
- Son algunos de los algoritmos de aprendizaje automático más sencillos y rápidos utilizados para clasificar conjuntos de datos.
- Pueden usarse tanto para la clasificación binaria como para la clasificación multiclase.
- A pesar de su simplicidad, con frecuencia realizan un mejor trabajo de clasificación multiclase que la mayoría de los otros algoritmos.
- Se trata de la herramienta más popular para tareas de clasificación de textos.
Desventajas de estos clasificadores
Aunque el algoritmo bayesiano ingenuo es un algoritmo de aprendizaje automático sencillo y eficaz para la clasificación, muestra algunas limitaciones e inconvenientes que deben tenerse en cuenta.
Naive Bayes
- La suposición de independencia. El enfoque bayesiano ingenuo supone que todas las funciones son independientes entre sí, lo cual puede no resultar siempre cierto en la práctica. Esta suposición puede provocar una menor precisión en la clasificación si los rasgos son muy dependientes entre sí.
- Dispersión de datos. El enfoque bayesiano se basa en la disponibilidad de suficientes ejemplos de entrenamiento para cada clase para estimar con precisión los valores de clase a priori y las probabilidades condicionales. Si la muestra de datos es demasiado pequeña, las estimaciones podrían ser inexactas y la clasificación ineficaz.
- Sensibilidad respecto a características no relevantes. El método bayesiano ingenuo trata todos los atributos igualmente, con independencia de su relevancia para la tarea de clasificación. Esto puede provocar una peor clasificación si se incluyen características irrelevantes en el conjunto de datos. Resulta innegable que algunas características del conjunto de datos son más importantes que otras.
- Incapacidad para procesar variables continuas. El enfoque bayesiano ingenuo asume que todas las funciones son discretas o categóricas y no puede procesar directamente variables continuas. Para utilizar Naive Bayes con variables continuas, los datos deberán discretizarse, lo cual puede provocar una pérdida de información y reducir la precisión de la clasificación.
- Expresividad limitada. Un algoritmo bayesiano ingenuo solo puede modelar límites de decisión lineales, lo cual puede no ser suficiente para problemas de clasificación más complejos. Por ello, el rendimiento puede resultar peor si el límite de decisión no es lineal.
- Desequilibrio de clases. El método bayesiano ingenuo puede funcionar peor cuando la distribución de los ejemplos entre las clases está muy desequilibrada, ya que esto podría dar lugar a estimaciones apriorísticas sesgadas, así como a valoraciones deficientes de las probabilidades condicionales para la clase minoritaria. Si no existen pruebas suficientes, la clase no se pronosticará en absoluto.
Método bayesiano ingenuo gaussiano
El método bayesiano ingenuo gaussiano repite las desventajas anteriores y además tiene otras dos adicionales:
- Sensibilidad a los valores atípicos. El método bayesiano ingenuo gaussiano supone que los signos se distribuyen normalmente, lo cual significa que los valores extremos o atípicos pueden tener un impacto significativo en las estimaciones de la media y la varianza. Esto puede provocar una clasificación deficiente si el conjunto de datos contiene valores atípicos.
- No resulta adecuado para funciones con colas pesadas. El método bayesiano ingenuo gaussiano supone que los signos tienen una distribución normal con una varianza finita. No obstante, si hay colas pesadas, como la distribución de Cauchy, puede que el algoritmo no funcione bien.
Conclusión
Para que un modelo de aprendizaje automático produzca resultados en el simulador de estrategias, hace falta algo más que entrenar el modelo: deberemos luchar por la productividad, intentar conseguir un gráfico de beneficios ascendente. A veces no es necesario ejecutar el propio modelo de aprendizaje automático en el simulador de estrategias, porque para algunos modelos la prueba requiere demasiados recursos informáticos. No obstante, sin duda necesitaremos utilizar el simulador por otros motivos, como la optimización de los volúmenes comerciales, los marcos temporales, etc. Deberá analizar cuidadosamente la lógica antes de comenzar a comerciar en tiempo real en cualquier modalidad.
Saludos cordiales y mis mejores deseos.
Siga el desarrollo del tema en mi repositorio de GitHub https://github.com/MegaJoctan/MALE5
| Archivo | Contenido y uso |
|---|---|
| Naive Bayes.mqh | Contiene las clases de los modelos bayesianos ingenuos |
| Naive Bayes theory script.mq5 | Script para probar la biblioteca |
| Naive Bayes Test.mq5 | Asesor experto para comerciar según los patrones aprendidos |
| matrix_utils.mqh | Contiene funciones matriciales adicionales |
| metrics.mqh | Contiene funciones para analizar el rendimiento de los modelos de aprendizaje automático, como una matriz de confusión |
| naive bayes visualize.py | Script en Python para dibujar gráficos de distribución de todas las variables independientes usadas en el modelo |
| gender datasets.csv & weather dataset.csv | Muestras de datos utilizadas como ejemplo en este artículo |
¡Atención! Este artículo solo tiene fines educativos. El trading es un negocio arriesgado y debe ser consciente de todos los riesgos que conlleva. El autor no se hace responsable de eventuales pérdidas o daños derivados de la utilización de los modelos expuestos en este artículo. ¡Nunca arriesgue más dinero del que pueda permitirse perder sin perjuicio para sí mismo!
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/12184
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
todo es bueno y maravilloso, pero lo único es que los indicadores tomados no son independientes, son transposición mutua de una misma cosa. De las lecturas de uno se deducen los otros y las fórmulas son conocidas.
Bayes no hará nada.
Sólo descargarlo y ejecutarlo en un probador es un poco agotador. En el artículo no encontré instrucciones "para enseñar, pulse X"
Algo para los académicos de nuevo.
todo es bueno y maravilloso, lo único es que los indicadores tomados no son independientes, son transposiciones mutuas de una misma cosa. Las lecturas de uno pueden utilizarse para derivar los otros, y las fórmulas son conocidas
Bayes no hará nada.
¿Cómo funciona "eso"?
Sólo descargarlo y ejecutarlo en un probador es un poco agotador. No he encontrado instrucciones en el artículo "para entrenar, pulse X"
Algo para los académicos de nuevo.
Estudié probabilidades en la universidad cuando cursé la carrera de planificación financiera.
Nunca he utilizado las probabilidades en el comercio en su sentido tradicional de "fórmula de probabilidad" de"Probabilidad = Número de resultados favorables / Número total de resultados" para el análisis, ¡aunque probablemente debería hacerlo!
Dicho esto, siendo realistas, eso es lo que son las desviaciones estándar de todos modos, en el sentido de que proporcionan la desviación (y por lo tanto la probabilidad de reversión o continuación) de las operaciones de la media en un período de tiempo determinado. (es decir, si el precio se acerca a SD1 hay un 68% de probabilidad de volver hacia la media, si ha alcanzado SD2, un 95,5% de probabilidad, y SD3, un 99,7% de probabilidad), por lo que las desviaciones estándar pueden ser muy útiles cuando se trata de medir cuando las posiciones comerciales son propensos a girar y dirigirse en la dirección opuesta, especialmente si se utiliza algo así como un canal de desviación estándar.
Sin embargo, puedo ver las posibles aplicaciones de las probabilidades cuando se trata del análisis de redes neuronales en el entrenamiento y la reflexión de las RNA.