
Redes neuronales: así de sencillo (Parte 28): Algoritmo de gradiente de políticas

Contenido
- Introducción
- 1. Características de la aplicación del gradiente de políticas
- 2. Principios de entrenamiento del modelo de políticas
- 3. Implementación del entrenamiento del modelo
- 4. Probando el modelo entrenado en el Simulador de Estrategias
- Conclusión
- Enlaces
- Programas usados en el artículo.
Introducción
Proseguimos nuestra inmersión en los métodos de aprendizaje por refuerzo. En el artículo anterior, nos familiarizamos con el método de aprendizaje Q profundo, Recordemos que el método aproxima la función de utilidad de una acción usando una red neuronal. Como resultado, obtendremos una herramienta para predecir la recompensa esperada al realizar una acción específica en un estado particular del sistema, y luego el agente realizará una acción basada en la política implementada y la cantidad de la recompensa esperada. No hemos discutido explícitamente el uso de la política, pero hemos asumido que se elige la acción con la mayor recompensa esperada. Esto se deriva de la fórmula de Bellman y del objetivo general del aprendizaje por refuerzo, que consiste en maximizar la recompensa por sesión analizada.
Observe que, al estudiar los métodos de aprendizaje por refuerzo, nunca hemos mencionado el reentrenamiento del modelo. De hecho, si observamos el modelo de aprendizaje por refuerzo, el objetivo del agente será aprender el entorno lo mejor posible, y en este caso, cuanto mejor conozca el agente el entorno, mayor éxito tendrá su actuación.
Sin embargo, cuando nos enfrentamos a un entorno cambiante como el mercado, a veces nos damos cuenta de que no hay límite para la variabilidad de este. Nunca existen 2 estados idénticos en él, pues, incluso partiendo de estados similares, podemos resultar en el siguiente paso en estados absolutamente opuestos.
La aproximación de la función Q nos ofrece solo la recompensa promedio esperada sin considerar la dispersión de los valores y la probabilidad de una recompensa positiva, mientras que el uso de una estrategia codiciosa en la que se elige la recompensa máxima siempre nos proporciona una elección de acción inequívoca. Por un lado, esto facilita el trabajo de nuestro agente, pero tal estrategia solo proporciona frutos mientras nuestro agente no se encuentre en algún tipo de confrontación con el entorno. En este caso, sus acciones se volverán predecibles para el entorno, por lo que podrá desarrollar los pasos necesarios para contrarrestar las acciones del agente y cambiar la política de recompensas, y el agente seguirá utilizando la función Q previamente aproximada, que ya no se corresponderá con el entorno modificado.
Para resolver estos problemas, se han propuesto métodos que no aproximan la política de recompensas del entorno, sino que desarrollan su propia estrategia de comportamiento. Precisamente a dichos métodos pertenece el gradiente de políticas, con el que proponemos al lector familiarizarse hoy.
1. Características de la aplicación del gradiente de políticas
Al comenzar el estudio de los métodos de aprendizaje por refuerzo, dijimos que el Agente interactúa con el entorno y realiza acciones según su estrategia; como resultado de ello, se realiza la transición de un estado a otro, y por cada transición, el agente obtiene una cierta recompensa del entorno, en función de la cual, el agente puede evaluar la utilidad de la acción realizada. El método del gradiente de políticas implica el desarrollo de una estrategia de comportamiento del agente.
Obviamente, no vamos a establecer de forma explícita la estrategia del agente, como se puede ver en el DQN: solo haremos una suposición sobre la existencia de una cierta función matemática de la política P que evaluará el estado actual del entorno y retornará la mejor acción realizada por el agente. Como podemos ver, este enfoque nos permitirá olvidarnos de todas las dificultades derivadas de la aproximación de la función Q, junto con la especificación de una política explícita de comportamiento del agente, seleccionando de alguna forma una acción con la máxima recompensa esperada (estrategia codiciosa).
Obviamente, por todo hay que pagar, y en lugar de aproximar la función Q, tendremos que aproximar la función P de la política de nuestro agente. En este artículo, nos centraremos en el método estocástico de gradiente de políticas. Dicho método asume que nuestra función de política, al evaluar el estado actual del entorno, retorna la distribución de probabilidad de la obtención de una recompensa positiva al realizar la acción correspondiente.
Al mismo tiempo, suponemos que las acciones de nuestro agente se distribuyen uniformemente, y para seleccionar una acción específica, bastará con que el agente muestree un valor de una distribución normal con probabilidades dadas. Claro que podemos usar la estrategia codiciosa y elegir la acción con la mayor probabilidad, pero es el muestreo lo que añade variabilidad al comportamiento de nuestro agente, y una mayor probabilidad aumentará la frecuencia de elección de esta acción en particular.
No olvidemos que, anteriormente, al entrenar modelos por refuerzo, introdujimos un hiperparámetro que es responsable del equilibrio entre investigación y explotación. En caso de usar el método estocástico de gradiente de políticas, este equilibrio será regulado por el modelo durante el aprendizaje precisamente gracias al muestreo de las acciones del agente con una probabilidad dada. Al inicio del entrenamiento del modelo, las probabilidades de todas las acciones serán casi iguales. Esto permitirá que el modelo explore el entorno estudiado tanto como sea posible. Durante el estudio del entorno, aumentaremos la probabilidad de las acciones que conduzcan a la maximización de la rentabilidad, mientras que reduciremos las probabilidades de elección para las acciones restantes. Así, el equilibrio entre investigación y explotación cambiará a favor de la elección de las acciones más rentables, lo cual nos permitirá construir una estrategia con la máxima rentabilidad.
Para aproximar la función P de la política del agente, usaremos una red neuronal, y, como podrá suponer, como necesitamos determinar la mejor acción del agente a partir de los datos iniciales del estado actual del entorno, podremos considerar esta tarea como una tarea de clasificación, donde cada acción será una clase aparte de estados iniciales. Y aquí, como hemos mencionado anteriormente, necesitaremos obtener en la salida de la capa neuronal una representación probabilística de la asignación del estado del entorno a un estado particular.
La representación probabilística impone algunas limitaciones al valor resultante. Estas deberán normalizarse entre 0% y 100%, y la suma de todas las probabilidades deberá ser 100%. En el campo del aprendizaje automático, resulta común usar fracciones de uno en lugar de porcentajes: en esta representación tendremos una limitación del rango de valores de 0 a 1, y la suma de todos los valores será igual a 1. Podemos conseguir este resultado utilizando la función SoftMax, que tiene la siguiente fórmula matemática.

Ya nos familiarizamos antes con esta función, cuando vimos los métodos de clusterización de datos. No obstante, si bien al estudiar los métodos de aprendizaje no supervisado, buscábamos similitudes en los datos de origen para determinar la clase, ahora distribuiremos el estado del entorno en acciones (clases) dependiendo de la recompensa obtenida, y la función SoftMax cumplirá plenamente nuestros requisitos. Dicha función permite transferir por completo los resultados de la red neuronal al dominio de las probabilidades y resulta diferenciable a todo lo largo de los valores, lo cual es muy importante para entrenar nuestro modelo.
2. Principios de entrenamiento del modelo de políticas
Ahora hablaremos un poco sobre los principios del entrenamiento del modelo de aproximación de funciones de política. El caso es que al entrenar el modelo DQN en cada nuevo estado, el entorno retornaba una recompensa, y nosotros entrenábamos el modelo para predecir la recompensa esperada con un error mínimo, lo cual no resultaba muy diferente de los enfoques utilizados anteriormente en el aprendizaje supervisado.
En el caso de la aproximación a la función P de la política del agente, en cada nuevo estado, también obtenemos una recompensa del entorno, pero queremos predecir la mejor acción, no la recompensa. El signo de la recompensa solo puede mostrarnos el impacto de la acción actual en el resultado, y nosotros entrenaremos el modelo para aumentar la probabilidad de elegir una acción con una recompensa positiva y disminuir la probabilidad de elegir una acción con una recompensa negativa,
por lo que aquí deberemos recordar que estamos entrenando un modelo de predicción de la probabilidad. Como mencionamos antes, los valores de las probabilidades pronosticadas están limitados al rango de 0 a 1, lo cual no es en absoluto comparable con la recompensa obtenida. que puede ser tanto positiva como negativa. Aquí usaremos la siguiente lógica: como necesitamos maximizar la probabilidad de elegir acciones con una recompensa positiva, para tales acciones estableceremos el valor objetivo en "1". Por lo tanto, el error del modelo se definirá como la desviación de la probabilidad prevista de una acción de 1. El uso de la desviación nos permitirá explotar el método de descenso de gradiente ya construido para entrenar nuestro modelo de aproximación de función de política, ya que al minimizar la desviación respecto a 1, maximizaremos la probabilidad de elegir una acción con una recompensa positiva.
También deberemos prestar atención a la elección de la función de pérdida de nuestro modelo. Aquí también podemos recurrir a métodos de aprendizaje supervisado y recordar que para los problemas de clasificación se usa la función de entropía cruzada.

donde p(y) son los valores reales de la distribución y p(y') son los valores pronosticados de nuestro modelo.
El uso del logaritmo también resulta de gran importancia para predecir eventos sucesivos. Sabemos por la teoría de la probabilidad que la probabilidad de que ocurran dos eventos sucesivos es igual al producto de las probabilidades de esos eventos, y para todos los logaritmos, la propiedad es verdadera.
![]()
Esto nos permitirá pasar del producto de las probabilidades a la suma de sus logaritmos, lo cual hará el entrenamiento de nuestro modelo más estable.
Al igual que sucede con el entrenamiento de DQN, para obtener recompensas, nuestro agente pasará por una sesión completa con parámetros fijos. Luego guardaremos los estados, acciones y recompensas en un búfer, y haremos una pasada inversa del modelo usando los datos acumulados.
Tenga en cuenta que como no tenemos una función de utilidad de la acción, reemplazaremos esta con la suma de los valores obtenidos durante la pasada de sesión. Para cada estado, el valor de la función Q será la suma de las recompensas posteriores hasta el final de la sesión.
El entrenamiento del modelo se repetirá hasta alcanzar el nivel de error deseado o el número máximo de sesiones de entrenamiento.
3. Implementación del entrenamiento del modelo
Después de estudiar los aspectos teóricos del método, procederemos a implementarlo usando MQL5. Primero, implementaremos la función SoftMax. No la hemos implementado antes como función de activación por las peculiaridades de su funcionamiento. Ahora, para no realizar cambios cardinales a los objetos creados previamente, proponemos al lector implementarla como una capa separada de nuestro modelo.
3.1 Implementación de SoftMax
Para ello, crearemos la nueva clase CNeuronSoftMaxOCL como heredera de la clase básica de neuronas CNeuronBaseOCL.
class CNeuronSoftMaxOCL : public CNeuronBaseOCL { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return true; } public: CNeuronSoftMaxOCL(void) {}; ~CNeuronSoftMaxOCL(void) {}; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); virtual bool calcOutputGradients(CArrayFloat *Target, float error) override; //--- virtual int Type(void) override const { return defNeuronSoftMaxOCL; } };
La nueva clase no requerirá la creación de búferes aparte, además, no utilizará todos los búferes de la clase principal, de los que hablaremos un poco más adelante. Así, el constructor y el destructor de la clase quedarán vacíos. Por el mismo motivo, no redefiniremos el método de inicialización de nuestra clase. En esencia, solo tendremos que redefinir el método de pasada directa feedForward y el método de distribución del gradiente de error calcOutputGradients.
Además, debido al uso de la nueva función de pérdida, redefiniremos el método para calcular el error del modelo y su gradiente calcOutputGradients.
Y, obviamente, redefiniremos el método de identificación de la claseType.
Vamos a comenzar con la organización del proceso de pasada directa. Como antes, realizaremos todas las operaciones computacionales en el modo multihilo usando la tecnología OpenCL. Entonces, primero crearemos un nuevo kernel SoftMax_FeedForward en el programa OpenCL. En los parámetros del kernel, transmitiremos los punteros a los búferes de datos y resultados iniciales, así como el tamaño de dichos búferes. El cálculo de la función no requiere ningún parámetro adicional.
En el cuerpo del kernel, como siempre, definiremos el identificador del hilo, que servirá como puntero al elemento correspondiente de la matriz de datos y resultados iniciales. Como esta es una implementación de la función de activación, el tamaño de los búferes de entrada y salida será igual, y, respectivamente, el puntero a los elementos de ambos búferes será el mismo.
__kernel void SoftMax_FeedForward(__global float *inputs, __global float *outputs, const ulong total) { uint i = (uint)get_global_id(0); uint l = (uint)get_local_id(0); uint ls = min((uint)get_local_size(0), (uint)256); //--- __local float temp[256];
Debemos señalar que el cálculo de la función SoftMax requiere la determinación de la suma de los valores exponenciales de todos los elementos del búfer de datos de entrada. No nos gustaría repetir el cálculo de este valor en cada hilo, además, preferiríamos distribuir el proceso de cálculo de este valor entre varios hilos. Pero aquí surge entonces el problema de la sincronización del funcionamiento de varios hilos y el intercambio de datos entre los mismos. La tecnología OpenCL no permite enviar datos de un hilo a otro, pero sí que permite, dentro de grupos de trabajo separados, crear variables y arrays comunes en la memoria local. Y para sincronizar el funcionamiento de los hilos dentro del grupo de trabajo, existe la función barrier(CLK_LOCAL_MEM_FENCE). Esto es precisamente lo que vamos a utilizar.
Por consiguiente, al mismo tiempo que definimos el identificador del hilo en el espacio de tareas global, definiremos el identificador del hilo en el grupo de trabajo, e inmediatamente declararemos un array en la memoria local. Lo usaremos para intercambiar datos entre los hilos del grupo de trabajo al calcular la suma total de valores exponenciales.
La dificultad reside en que OpenCL no permite el uso de arrays dinámicos en la memoria local, y nos veremos obligados a determinar el tamaño del array en la etapa de la creación del kernel. Con este tamaño, limitaremos el número de hilos involucrados en la suma de valores exponenciales.
En sí, el proceso de la suma de valores exponenciales se organiza partiendo de 2 ciclos sucesivos. En el cuerpo del primer ciclo, cada hilo que participa en el proceso de suma recorrerá el vector de valores iniciales completo con un paso igual al número de hilos de suma y recopilará su parte de la suma de valores exponenciales. Por ello, distribuiremos uniformemente el proceso de suma completo entre todos los hilos, y cada uno de ellos almacenará su valor en el elemento correspondiente del array local.
uint count = 0; if(l < 256) do { uint shift = count * ls + l; temp[l] = (count > 0 ? temp[l] : 0) + (count * ls + l < total ? exp(inputs[shift]) : 0); count++; } while((count * ls + l) < total); barrier(CLK_LOCAL_MEM_FENCE);
En esta etapa, sincronizaremos los hilos después de que se hayan completado las iteraciones del ciclo.
A continuación, deberemos recopilar la suma de todos los elementos del array local en un solo valor. Para ello, organizaremos un segundo ciclo. Aquí dividiremos el tamaño del array local por la mitad y sumaremos los valores en pares. Obviamente, cada operación de suma de 2 valores será realizada por un hilo separado. Después de ello, repetiremos las iteraciones del ciclo, dividiendo el número de elementos por la mitad y sumando los elementos en pares. Las iteraciones del ciclo se repetirán hasta obtener la suma total de los valores en el elemento del array con el índice "0".
count = ls; do { count = (count + 1) / 2; if(l < 256) temp[l] += (l < count && (l + count) < total ? temp[l + count] : 0); barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Como podemos ver, cada nueva iteración del ciclo solo puede comenzar después de que se hayan completado las operaciones de todos los hilos participantes. Por consiguiente, realizaremos una sincronización después de cada iteración del ciclo.
Aquí cabe señalar que la arquitectura OpenCL solo ofrece una sincronización completa de hilos, y todos los elementos del grupo de trabajo deberán llegar hasta el operador barrier correspondiente. De lo contrario, el programa se quedará «colgado». Por ello, al organizar el programa, deberemos tener mucho cuidado con los puntos de sincronización de los hilos. Le desaconsejamos encarecidamente establecerlos en el cuerpo de las declaraciones condicionales cuando el algoritmo del programa permita que al menos un hilo omita los puntos de sincronización.
Tras completar las iteraciones de los ciclos anteriores, hemos obtenido la suma de todos los valores exponenciales de los datos de origen y podemos completar el proceso de normalización de datos. Para ello, organizaremos otro ciclo en el que rellenaremos el búfer de datos de origen con los valores correspondientes.
float sum = temp[0]; if(sum != 0) { count = 0; while((count * ls + l) < total) { uint shift = count * ls + l; outputs[shift] = exp(inputs[shift]) / (sum + 1e-37f); count++; } } }
Con esto daremos por finalizado el trabajo con el kernel de pasada directa y proseguiremos con la creación de los kernels de pasada inversa.
Vamos a crear ahora los kernels de pasada inversa distribuyendo el gradiente con la ayuda de la función SoftMax. Aquí deberemos prestar atención a que la principal peculiaridad de esta función es la normalización de la suma de todos los valores de los resultados en "1". Por consiguiente, con solo cambiar un valor en la entrada de la función de activación, provocaremos el recálculo de todos los valores del vector de resultados. De forma análoga, al distribuir el gradiente de error, cada elemento de los datos de origen deberá recibir su parte del error de cada elemento del vector de resultados. A continuación, presentaremos la fórmula matemática para la influencia de cada elemento de los datos de origen en el resultado. Deberemos implementarla en el kernel SoftMax_HiddenGradient.
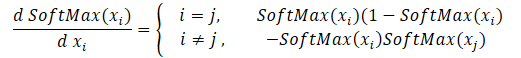
Este kernel obtendrá en los parámetros los punteros a 3 búferes de datos: los búferes de resultados después de la pasada directa, los gradientes de la capa anterior o de la función de pérdida, así como el búfer de gradiente de la capa anterior, en el cual escribiremos los resultados de este kernel.
En el cuerpo del kernel, definiremos el identificador del hilo y el número total de hilos en ejecución que nos señalarán al elemento de array para registrar el resultado del hilo actual y el tamaño de los búferes.
A continuación, prepararemos 2 variables privadas. En una copiaremos el valor del elemento correspondiente del vector de resultados de la pasada directa, mientras que la segunda la declararemos para recopilar los resultados del funcionamiento del hilo actual. El uso de variables privadas se debe a las particularidades de la arquitectura de los dispositivos OpenCL. Acceder a variables privadas resulta mucho más rápido que realizar operaciones similares con búferes en la memoria global. Por ello, este enfoque mejorará el rendimiento general del kernel.
Luego recopilaremos en un ciclo el gradiente de error de todos los elementos de los resultados de acuerdo con la fórmula anterior. Una vez que completadas las operaciones del ciclo, transmitiremos el valor de gradiente acumulado al elemento correspondiente del búfer de gradiente de la capa anterior y finalizaremos el trabajo del kernel.
__kernel void SoftMax_HiddenGradient(__global float* outputs, __global float* output_gr, __global float* input_gr) { size_t i = get_global_id(0); size_t outputs_total = get_global_size(0); float output = outputs[i]; float result = 0; for(int j = 0; j < outputs_total; j++) result += outputs[j] * output_gr[j] * ((float)(i == j ? 1 : 0) - output); input_gr[i] = result; }
Ahora solo nos queda implementar el kernel para determinar el gradiente de error de la función de pérdida SoftMax_OutputGradient. No olvidemos que en este caso usaremos LogLoss como función de pérdida.
Como distribuimos los gradientes en elementos de la acción correspondiente, también calcularemos la derivada elemento a elemento. Esto nos permitirá dividir el cálculo del gradiente de error entre los hilos. Gracias al curso de matemáticas de la escuela, sabemos que la derivada del logaritmo es igual a la razón de 1 respecto al argumento de la función. Así, la derivada de nuestra función de pérdida adquirirá la forma siguiente.
![]()
Solo deberemos implementar la fórmula matemática anterior en el kernel del programa OpenCL. Su código es bastante simple y cabe en las 2 líneas que vemos abajo.
__kernel void SoftMax_OutputGradient(__global float* outputs, __global float* targets, __global float* output_gr) { size_t i = get_global_id(0); output_gr[i] = -targets[i] / (outputs[i] + 1e-37f); }
Con esto concluimos el trabajo del lado del programa OpenCL y podemos comenzar a trabajar del lado del programa principal. Aquí añadiremos las constantes necesarias para trabajar con los nuevos kernels, agregaremos la declaración de los nuevos kernels y crearemos los métodos para llamarlos.
#define def_k_SoftMax_FeedForward 36 #define def_k_softmaxff_inputs 0 #define def_k_softmaxff_outputs 1 #define def_k_softmaxff_total 2 //--- #define def_k_SoftMax_HiddenGradient 37 #define def_k_softmaxhg_outputs 0 #define def_k_softmaxhg_output_gr 1 #define def_k_softmaxhg_input_gr 2 //--- #define def_k_SoftMax_OutputGradient 38 #define def_k_softmaxog_outputs 0 #define def_k_softmaxog_targets 1 #define def_k_softmaxog_output_gr 2
Los métodos para llamar a los kernels repiten al completo los algoritmos anteriormente utilizados de métodos similares. Podrá ver su código entero en el archivo adjunto.
Tras implementar la función SoftMax que falta, podemos comenzar a crear un asesor experto para implementar y entrenar el modelo de gradiente de políticas.
3.2 Construyendo un asesor experto para entrenar el modelo
Para entrenar el modelo de aproximación de la función de política de comportamiento del agente, crearemos un nuevo asesor experto en el archivo "REINFORCE.mq5". La funcionalidad principal de este asesor se tomará prestada de "Q-learning.mq5", que creamos en el último artículo para entrenar el modelo DQN. Debemos señalar que, a diferencia del modelo DQN, en el nuevo asesor usaremos solo una red neuronal, pero para implementar correctamente el algoritmo, necesitaremos crear tres pilas: la primera con los estados del entorno, la segunda con las acciones realizadas y la tercera con las recompensas obtenidas.
CNet StudyNet; CArrayObj States; vectorf vActions; vectorf vRewards;
Después cambiaremos ligeramente los parámetros externos del asesor según los requisitos del algoritmo.
input int SesionSize = 24 * 22; input int Iterations = 1000; input double DiscountFactor = 0.999;
El método de inicialización del asesor experto se ha mantenido prácticamente sin cambios. Solo hemos añadido la inicialización de la pila para acumular las acciones realizadas y las recompensas obtenidas.
if(!vActions.Resize(SesionSize) || !vRewards.Resize(SesionSize)) return INIT_FAILED;
El proceso de entrenamiento en sí está integrado en la función Train. Le propongo que la analicemos con mayor detalle.
Al inicio de la función, como antes, determinaremos el rango de la muestra de entrenamiento según los parámetros externos dados.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
Después de determinar el periodo de entrenamiento, cargamos la muestra de entrenamiento.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- int total = bars - (int)(HistoryBars + 2 * SesionSize);
Las operaciones previas no se distinguen de las utilizadas en los asesores expertos anteriores. A continuación, viene el sistema de ciclos de entrenamiento del modelo, que implementa los principales enfoques para entrenar el modelo.
El ciclo externo se encarga de iterar sobre las sesiones de entrenamiento del modelo. Al inicio del ciclo, determinaremos aleatoriamente la barra de inicio de la sesión en el pool general de la historia cargada.
CBufferFloat* State; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0,1,error_code)),1) * (total) + SesionSize); States.Clear();
Luego organizaremos un ciclo en el que nuestro agente, paso a paso, irá completando la sesión. En el cuerpo del ciclo, primero llenaremos el búfer del estado actual del sistema con los datos históricos para el periodo analizado. Luego realizaremos una operación similar al entrenar los modelos anteriores antes de cada pasada directa,
for(int batch = 0; batch < SesionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; } int r = i + (int)HistoryBars; if(r > bars) continue; for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) break; }
y realizaremos una pasada directa de nuestro modelo.
if(IsStopped()) { ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) continue; if(!StudyNet.feedForward(GetPointer(State), 12, true)) { ExpertRemove(); return; }
Según los resultados de la pasada directa, obtendremos la distribución de la probabilidad de las acciones y muestrearemos la siguiente acción de la distribución normal, teniendo en cuenta la distribución de probabilidad resultante. El muestreo se realizará usando la función aparte GetAction, en cuyos parámetros se transmitirá la distribución de probabilidad.
StudyNet.getResults(TempData); int action = GetAction(TempData); if(action < 0) { ExpertRemove(); return; }
Después de muestrear la acción, determinaremos la recompensa por la acción seleccionada según el tamaño de la siguiente vela. Luego utilizaremos la política de recompensa adoptada en el último artículo,
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -2; break; case 1: if(reward > 0) reward *= -2; else reward *= -1; break; default: reward = -fabs(reward); break; }
y almacenaremos el conjunto de datos completo en la pila. Aquí debemos decir que simplemente añadiremos los estados y las acciones a las pilas, pero mantendremos la recompensa considerando el factor de descuento. Aquí será necesario determinar en la etapa de diseño cómo descontaremos las recompensas. Existen 2 opciones para el descuento. Podemos descontar las primeras recompensas dando más valor a las recompensas posteriores. Este enfoque se usará con mayor frecuencia cuando el agente obtenga recompensas intermedias durante la pasada por la sesión, pero la tarea principal del agente será llegar al final de la sesión, donde recibirá la máxima recompensa.
El segundo enfoque será el inverso: le daremos más peso a las primeras recompensas, y se descontarán las recompensas posteriores. Esta opción será aceptable cuando aspiremos a la recompensa máxima y más rápida. Este es exactamente el enfoque que hemos utilizado. Después de todo, resulta esencial para nosotros obtener inmediatamente el máximo beneficio y no esperar a las pérdidas, anticipándonos a una reversión del mercado después de la transacción.
Una cosa más: Después de completar la pasada de la sesión, deberemos calcular la recompensa total de cada estado hasta el final de la sesión. Las operaciones vectoriales de MQL5 nos permiten calcular solo la suma acumulada directa. Por ello, simplemente almacenaremos todos los valores de recompensa en un vector en orden inverso, y después de que finalice el ciclo, usaremos una operación vectorial para calcular la suma acumulada.
if(!States.Add(State)) { ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)(reward * pow(DiscountFactor, (double)batch)); vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
Después de guardar los datos, pasaremos a la siguiente iteración del ciclo. Por lo tanto, recopilaremos los datos para toda la sesión.
Tras completar todas las iteraciones del ciclo, calcularemos la recompensa total de la sesión, teniendo en cuenta el descuento, el vector de cantidades de recompensas totales de cada estado hasta el final de la sesión y el valor de la función de pérdida.
Aquí mismo guardaremos el modelo actual, pero solo si se actualiza la recompensa máxima.
float cum_reward = vRewards.Sum(); vRewards = vRewards.CumSum(); vRewards = vRewards / fmax(vRewards.Max(), fabs(vRewards.Min())); float loss = (vRewards * MathLog(vProbs) * (-1)).Sum(); if(MaxProfit < cum_reward) { if(!StudyNet.Save(FileName + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false)) return; MaxProfit = cum_reward; }
Ahora que tenemos los valores de las recompensas a lo largo de la ruta de la sesión del agente, podemos organizar un ciclo de entrenamiento para el modelo de la función de política. Para ello, organizaremos otro ciclo. En él, extraeremos alternativamente los estados del entorno de nuestro búfer y realizaremos una pasada directa del modelo. Esto será necesario para restaurar todos los valores internos del modelo para el estado correspondiente del entorno.
Luego prepararemos un vector de valores de referencia para el estado actual del entorno. No olvidemos que vamos a maximizar las probabilidades de elegir una acción con una recompensa positiva y a minimizar las probabilidades de las demás. Por consiguiente, si durante la ejecución de la acción obtenemos un valor positivo, llenaremos el vector de probabilidades de referencia con valores cero, y solo para una acción perfecta, estableceremos la probabilidad en 1. En caso de obtener una recompensa negativa, llenaremos el vector de probabilidades de referencia con unidades, y solo para la acción seleccionada, estableceremos la probabilidad en cero.
for(int batch = 0; batch < SessionSize; batch++) { State = States.At(batch); if(!StudyNet.feedForward(State)) { ExpertRemove(); return; } if((vRewards[SessionSize - batch - 1] >= 0 ? (!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], 1)) : (!TempData.BufferInit(Actions, 1) || !TempData.Update((int)vActions[batch], 0)) )) { ExpertRemove(); return; } if(!StudyNet.backProp(TempData)) { ExpertRemove(); return; } }
Después realizaremos una pasada inversa para actualizar los coeficientes de peso de nuestro modelo. Las iteraciones se repetirán para todos los estados de entorno guardados.
Tras completar todas las iteraciones del ciclo, enviaremos un mensaje informativo al diario de registro y pasaremos a la siguiente sesión.
PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, cum_reward, loss); } Comment(""); //--- ExpertRemove(); }
No olvide controlar el proceso de ejecución de las operaciones en cada paso. Una vez todas las iteraciones se hayan ejecutado con éxito, saldremos de la función y generaremos el evento de cierre del terminal. Podrá encontrar el código completo del asesor en el archivo adjunto.
También debemos decir que para aproximar la función de política de nuestro modelo, usaremos una red neuronal con una arquitectura similar al entrenamiento de la función Q del último artículo. Además, tomaremos el modelo entrenado del último artículo y reemplazaremos el bloque de decisión añadiendo SoftMax como la última capa de la red neuronal para normalizar los datos.
El proceso de entrenamiento del modelo es completamente análogo al proceso de entrenamiento de cualquier otro modelo. Existen muchos ejemplos de este tipo en cada artículo de esta serie, y para resumir el trabajo en este artículo, hemos decidido desviarnos un poco del formato de plantilla del artículo. En su lugar, le sugerimos mirar el funcionamiento de los modelos entrenados en el simulador de estrategias.
4. Probando el modelo entrenado en el Simulador de Estrategias
En el artículo anterior, entrenamos un modelo de DQN. En este, crearemos y entrenaremos un modelo de gradiente de políticas. Le proponemos crear asesores expertos de prueba que nos permitirán ver el funcionamiento de los modelos en el simulador de estrategias. Para ello, crearemos 2 asesores expertos "Q-learning-test.mq5" y "REINFORCE-test.mq5". Por el nombre de los archivos, podemos adivinar fácilmente qué modelo está probando cada asesor experto.
La estructura de la construcción de los asesores es totalmente idéntica, por lo tanto, analizaremos solo uno. Encontrará el código completo de ambos asesores en el archivo adjunto.
El nuevo asesor experto "REINFORCE-test.mq5" se basa en el asesor experto "REINFORCE.mq5" mencionado anteriormente, pero, como el asesor no entrenará el modelo, eliminaremos la función Train. En este caso, además, transferiremos la funcionalidad principal a la función OnTick, que procesa cada evento de aparición de un nuevo tick.
Nuestro modelo entrenado evaluará el estado del entorno usando las velas cerradas. Por consiguiente, en el cuerpo de la función OnTick, verificaremos la apertura de una nueva vela, y solo cuando aparezca una nueva vela, se realizarán las operaciones restantes de la función.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if(lastBar >= iTime(Symb.Name(), TimeFrame, 0)) return;
Cuando aparezca una nueva vela, cargaremos los últimos datos históricos y rellenaremos el búfer de descripción del estado del sistema.
int bars = CopyRates(Symb.Name(), TimeFrame, 0, HistoryBars+1, Rates); if(!ArraySetAsSeries(Rates, true)) return; RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- State1.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = (int)HistoryBars - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- if(!State1.Add((float)Rates[bar_t].close - open) || !State1.Add((float)Rates[bar_t].high - open) || !State1.Add((float)Rates[bar_t].low - open) || !State1.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State1.Add(sTime.hour) || !State1.Add(sTime.day_of_week) || !State1.Add(sTime.mon) || !State1.Add(rsi) || !State1.Add(cci) || !State1.Add(atr) || !State1.Add(macd) || !State1.Add(sign)) break; }
Luego comprobaremos que los datos se hayan rellenado correctamente y solicitaremos una pasada directa en nuestro modelo.
if(State1.Total() < (int)(HistoryBars * 12)) return; if(!StudyNet.feedForward(GetPointer(State1), 12, true)) return; StudyNet.getResults(TempData); if(!TempData) return;
Como resultado de la pasada directa, obtendremos una distribución de probabilidad de las posibles acciones, de la cual muestrearemos una acción aleatoria.
lastBar = Rates[0].time; int action = GetAction(TempData); delete TempData;
A continuación, deberemos realizar la acción seleccionada. Pero antes de pasar a abrir una nueva operación, comprobaremos la presencia de posiciones ya abiertas. Para ello, definiremos 2 banderas: Buy y Sell. Al declarar variables, las estableceremos en false.
Después de ello, organizaremos un ciclo con iteración de todos los valores, y al encontrar una posición abierta para el símbolo analizado, cambiaremos el valor de la bandera correspondiente.
bool Buy = false; bool Sell = false; for(int i = 0; i < PositionsTotal(); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((ENUM_POSITION_TYPE)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: Buy = true; break; case POSITION_TYPE_SELL: Sell = true; break; } }
Luego vendrá el bloque de operaciones comerciales. Aquí usaremos el operador switch para bifurcar el algoritmo del bloque dependiendo de la acción realizada. Si la elección ha recaído en la apertura de una nueva posición, comprobaremos las banderas de las posiciones abiertas. En caso de que ya se haya abierto una posición en la dirección correspondiente, simplemente la dejaremos en el mercado y esperaremos la apertura de una nueva vela.
Si en el momento de tomar la decisión se encuentra abierta una posición opuesta, primero cerraremos la posición abierta y solo después abrimos una nueva.
switch(action) { case 0: if(!Buy) { if((Sell && !Trade.PositionClose(Symb.Name())) || !Trade.Buy(Symb.LotsMin(), Symb.Name())) { lastBar = 0; return; } } break; case 1: if(!Sell) { if((Buy && !Trade.PositionClose(Symb.Name())) || !Trade.Sell(Symb.LotsMin(), Symb.Name())) { lastBar = 0; return; } } break; case 2: if(Buy || Sell) if(!Trade.PositionClose(Symb.Name())) { lastBar = 0; return; } break; } //--- }
Si el agente necesita cerrar todas las posiciones, llamaremos a la función de cierre de posiciones para el símbolo actual. La función se llamará solo si al menos una posición está abierta.
Y, por supuesto, no nos olvidaremos de supervisar el proceso de las operaciones en cada paso.
Podrá encontrar el código completo del asesor en el archivo adjunto.
Primero pusimos a prueba el modelo de DQN. Y aquí nos esperaba una sorpresa inesperada. El modelo obtuvo beneficios, pero al mismo tiempo, solo realizó una operación comercial, que estuvo abierta durante toda la prueba. El gráfico del instrumento con la transacción realizada se muestra a continuación.

Al evaluar la transacción en el gráfico de instrumentos, no podemos dejar de estar de acuerdo con que el modelo ha identificado claramente la tendencia global y ha abierto una transacción en su dirección. La transacción es rentable, pero nos queda una pregunta sin respuesta: ¿será capaz el modelo de cerrar a tiempo una transacción así? En realidad, hemos entrenado el modelo con datos históricos de los últimos 2 años, y durante los 2 años, el mercado ha estado dominado por una tendencia bajista para el instrumento analizado. Por lo tanto, nos preguntamos si el modelo podrá cerrar la transacción a tiempo.
Y aquí debemos decir que al usar la estrategia codiciosa, el modelo de gradiente de políticas ofrece resultados similares. Recuerde que cuando comenzamos a estudiar los métodos de aprendizaje por refuerzo, enfatizamos repetidamente la necesidad de elegir correctamente la política de recompensas, y luego decidimos experimentar con ella. En particular, para evitar quedarnos más tiempo en una posición con pérdidas, decidimos aumentar las sanciones por las posiciones no rentables, y, en consecuencia, entrenamos el modelo de gradiente de políticas considerando la nueva política de recompensas. Después de varios experimentos con los hiperparámetros del modelo, hemos logrado alcanzar un 60% de rentabilidad en las operaciones. A continuación, mostramos el gráfico de pruebas.
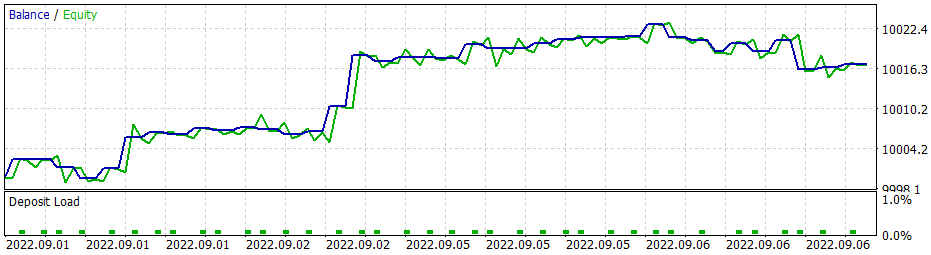
El tiempo medio de mantenimiento de una posición es de 1 hora y 40 minutos.
Conclusión
En este artículo, hemos analizado otro algoritmo de los métodos de aprendizaje por refuerzo. Asimismo, hemos creado y entrenado el modelo usando el método de gradiente de políticas.
A diferencia de otros artículos de esta serie, en este artículo hemos entrenado y probado los modelos en el simulador de estrategias. Según los resultados de las pruebas, podemos concluir que los modelos son bastante capaces de generar señales para realizar transacciones comerciales rentables. Al mismo tiempo, debemos destacar una vez más la importancia de elegir una política de recompensas y una función de pérdida adecuadas para lograr el resultado deseado.
Enlaces
- Redes neuronales: así de sencillo (Parte 25): Practicando el Transfer Learning
- Redes neuronales: así de sencillo (Parte 26): Aprendizaje por refuerzo
- Redes neuronales: así de sencillo (Parte 27): Aprendizaje Q profundo (DQN)
Programas usados en el artículo.
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | REINFORCE.mq5 | Asesor | Asesor para el entrenamiento de modelos |
| 2 | REINFORCE-test.mq5 | Asesor | Asesor Experto para Pruebas de Modelos en el Probador de Estrategias |
| 1 | Q-learning-test.mq5 | Asesor | Asesor experto paraprobar el modelo DQN en el simulador de estrategias |
| 2 | NeuroNet.mqh | Biblioteca de clases | Biblioteca para organizar modelos de redes neuronales |
| 3 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL para organizar modelos de redes neuronales |
…
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11392
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Aprendiendo a diseñar un sistema de trading con DeMarker
Aprendiendo a diseñar un sistema de trading con DeMarker
 Aprendiendo a diseñar un sistema de trading con VIDYA
Aprendiendo a diseñar un sistema de trading con VIDYA
 Redes neuronales: así de sencillo (Parte 27): Aprendizaje Q profundo (DQN)
Redes neuronales: así de sencillo (Parte 27): Aprendizaje Q profundo (DQN)
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
He intentado añadir la línea #include <Math\Stat\Normal . mqh> directamente en el archivo VAE .mqh, pero no ha funcionado. El compilador sigue escribiendo 'MathRandomNormal' - identificador no declarado VAE.mqh 92 8. Si borras esta función y empiezas a escribir de nuevo, aparece un tooltip con esta función, que, según tengo entendido, indica que se puede ver desde el fichero VAE.mqh.
En general, he probado en otro ordenador con una versión diferente incluso de la vinda, y el resultado es el mismo - no ve la función y no compila. mt5 última versión betta 3420 del 5 de septiembre de 2022.
Dmitry, ¿tiene alguna configuración habilitada en el editor?
En general, lo he probado en otro ordenador con otra versión de Windows, y el resultado es el mismo - no ve la función y no compila. mt5 última versión betta 3420 del 5 de septiembre de 2022.
Dmitry, ¿tienes alguna configuración habilitada en el editor?
Prueba a comentar la línea"namespace Math
Dmitry Tengo la versión 3391 de terminal del 5 de agosto de 2022 (última versión estable). Ahora he intentado actualizar a la versión beta 3420 del 5 de septiembre de 2022. El error con values.Assign ha desaparecido. Pero el error con MathRandomNormal no desaparece. Tengo una biblioteca con esta función en la ruta tal como escribiste. Pero en el archivo VAE.m qh no tiene una referencia a esta biblioteca, pero en el archivo NeuroNet.mqh especifica esta biblioteca de la siguiente manera:
namespace Math
{
#include <Math\Stat\Normal.mqh>
}
Pero así no es como estoy consiguiendo que funcione. :(
PD: Si directamente en el archivo VAE.mqh especificar la ruta a la biblioteca. ¿Es posible hacer eso? No entiendo muy bien cómo se pone la librería en el archivo NeuroNet.mqh, ¿no habrá conflicto?
3445 del 23 de septiembre - lo mismo.
Necesito consejo :) Acabo de entrar en el terminal después de la reinstalación, quiero hacer la formación y da un error
Hola.
Necesito consejo :) Acabo de entrar en el terminal después de la reinstalación, quiero hacer la formación y da un error