
Aprendizaje de máquinas de Yándex (CatBoost) sin estudiar Python y R

Introducción
Estimado lector, en este artículo, describiremos el proceso de creación de varios modelos que describen un patrón del mercado con un conjunto limitado de variables, así como la presencia de una hipótesis sobre el patrón de su comportamiento; ambos son resultado del trabajo con el algoritmo de aprendizaje automático CatBoost de Yándex. Para obtener los modelos, no necesitaremos conocer ningún lenguaje de programación como Python o R. Los conocimientos requeridos de MQL5 no serán profundos, iguales, por cierto, que los del autor del presente artículo; por eso, esperamos que este artículo sirva de guía para un amplio círculo de lectores que deseen valorar de forma experimental las posibilidades del aprendizaje de máquinas e implementar estas en sus desarrollos. En el artículo, expondremos una cantidad mínima de conocimientos académicos; para familiarizarse con ellos, recomendamos la serie de artículos de Vladímir Perervenko.
Sobre la diferencia entre el enfoque clásico y el aprendizaje de máquinas en el trading
Una vez iniciados activamente en el trading, muchos tráders tienen tiempo de familiarizarse con el concepto "Estrategia Comercial", y si estos han tenido la fortuna de comerciar con ayuda de los productos de MetaQuotes Ltd., el tema de la automatización del comercio salta a un primer plano. Si descartamos del código el entorno comercial, mayormente, todas las estrategias se reducirán a una selección de desigualdades; por lo general, el precio se opone al indicador en el gráfico, o bien se usan las lecturas del indicador y sus límites para activar la decisión de entrar en el mercado (abrir una posición) y salir del mismo.
Todo aquel que ha desarrollado una estrategia comercial, ha podido experimentar con una serie de conocimientos heurísticos expresados en la adición de más y más nuevas condiciones comerciales, de nuevas desigualdades. Cada adición de una nueva condición daba como resultado un cambio en los resultados financieros durante un periodo de tiempo, pero adoptando un intervalo de tiempo diferente o modificando un periodo temporal distinto; eso por no mencionar el cambio del propio instrumento comercial, donde generalmente llegaba la decepción: el sistema comercial había dejado de funcionar y se hacía necesario buscar un patrón nuevo tras otro, nuevas condiciones, y con la adición de cada una de estas, se reducía el número de transacciones.
Normalmente, a esto le siguía un proceso de optimización de las variables de desigualdad usadas para tomar las decisiones comerciales. En sí mismo, dicho proceso de optimización se reduce a una enumeración de parámetros que con frecuencia van más allá de los valores de los datos iniciales, o bien los valores de las desigualdades generadas por la enumeración ocurren con tan poca frecuencia que pueden considerarse más una desviación estadística que un patrón detectado, aunque podrían mejorar la curva de balance o cualquier otra función optimizada. Como resultado de las acciones mencionadas, al optimizar los parámetros, la heurística en nuestra estrategia comercial se ajusta a los datos de mercado disponibles. Este enfoque tiene razón de ser, pero no resulta muy eficaz en cuanto a los recursos computacionales invertidos en hallar la solución óptima si la presencia de variables y su número de valores es grande.
Los métodos de aprendizaje de máquinas nos permiten acelerar la optimización de parámetros y encontrar patrones entre ellos generando reglas de desigualdad y enumerando solo aquellos valores de las variables que existían en los datos investigados. Los diferentes métodos para crear modelos usan un enfoque distinto, pero su esencia consiste en limitar la búsqueda de la solución a un problema según los datos disponibles para el entrenamiento. En lugar de crear desigualdades que se encarguen de la lógica de las decisiones comerciales, el aprendizaje de máquinas ofrece solo los valores de las variables que contienen información sobre el precio y los factores que influyen en su formación. Estos datos se llaman rasgos (predictores).
Los rasgos deben influir en el resultado que queremos obtener al solicitar estos. El resultado, por lo común, se expresa como valor digital: así, para la clasificación, será el número el número de la clase, mientras que para la regresión será el valor del punto establecido. Este resultado se llama normalmente "objetivo", como abreviatura de "función objetivo". Si los métodos de aprendizaje de máquinas no tienen objetivo, por ejemplo, en la clusterización diversa, no hablaremos de ellos.
Bien, vamos a necesitar los predictores y la función objetivo.
Los predictores
Podemos usar como predictores la hora, el precio OHLC de un instrumento comercial y sus derivados: diferentes tipos de indicadores. También podemos usar otros predictores, como los indicadores económicos, el volumen de las transacciones, el interés abierto, los patrones de la profundidad de mercado, las griegas del precio de ejercicio de opciones y otras fuentes de información que influyen en el mercado. En nuestra opinión, no solo debe llegarnos la información que se ha formado en el actual momento temporal, sino también aquella que describe el movimiento en ese momento. Hablando con rigor, los predictores deben ofrecer información sobre el movimiento de los precios durante un cierto periodo temporal.
Destacaremos los siguientes tipos de predictores:
- Niveles significativos que pueden ser:
- Horizontales (por ejemplo, el precio de apertura de una sesión comercial)
- Lineales (por ejemplo, un canal de regresión)
- Quebrados (no se calculan según una función lineal, como por ejemplo las medias móviles)
- Posición del precio y el nivel:
- En un intervalo fijo en puntos
- En un intervalo fijo en porcentaje
- Respecto al precio de apertura de un día o un nivel
- Respecto a un nivel de volatilidad
- Respecto a los segmentos de tendencia de diferentes TF
- Que describan la oscilación del precio (volatilidad)
- Información sobre la fecha/hora de un evento:
- Número de barras transcurridas desde el inicio de un evento significativo (respecto a la barra inicial o el comienzo de otro periodo, por ejemplo, un día)
- Número de barras transcurridas desde la finalización de un evento significativo (respecto a la barra inicial o el comienzo de otro periodo, por ejemplo, un día)
- Númeor de barras transcurridas desde el comienzo o la finalización de un evento: duración del evento
- Fecha/hora actual en forma de hora, día de la semana, número de decena, mes, u otro
- Información sobre la dinámica del evento:
- Número de cruzamientos de los niveles significativos (incluyendo el cálculo de la frecuencia de la desaparición/repetición del evento)
- Precio máximo/mínimo en el momento del primer/último evento (el precio es relativo)
- Velocidad de desarrollo del evento en forma de puntos por unidad temporal
- Conversión de datos de OHLC en otras coordinadas de superficie
- Valores de los indicadores de tipo oscilador.
La información para los predictores se puede tomar de diferentes marcos de tiempo e instrumentos comerciales relacionados con el que se utilizará para el comercio. Por supuesto, estas no son todas variaciones, y puede pensar en otras formas de proporcionar información, pero es deseable proporcionar tanta que sea posible reproducir la dinámica principal del precio de un instrumento negociado. La ventaja aquí es que una vez que se han creado los predictores, se pueden usar más para diferentes objetivos, lo que simplifica enormemente el proceso de encontrar un modelo que funcione de acuerdo con las condiciones básicas de una estrategia comercial.
Función objetivo
En este artículo, utilizaremos una función objetivo binaria de clasificación, es decir, 0 y 1; esto se debe a una limitación de la que hablaremos más tarde. Bien, ¿qué sentido podemos introducir en el cero y el uno? Pues podríamos pensar en dos variantes:
- la primera opción sería: "1" — abrir una posición (otra acción) y "0" — no abrir una posición (otra acción);
- la segunda opción sería: "1" — abrir una posición de compra (primera acción) y "0" — abrir una posición de venta (segunda acción);
Para generar una señal con la función objetivo, podemos usar estrategias básicas sencillas que nos permitirán conseguir un número suficiente de señales para el aprendizaje automático:
- Abrir una posición cuando se cruza un nivel de precio de compra o venta: cualquier indicador puede actuar como nivel;
- Abrir una posición en la barra N partiendo del comienzo de la hora, o bien ignorar la apertura, dependiendo de la posición del precio respecto al precio de apertura del día actual;
Debemos considerar que resulta preferible encontrar una estrategia básica que genere aproximadamente el mismo número de ceros y unos, lo cual facilitará un aprendizaje más adecuado.
Herramienta para el aprendizaje de máquinas
Como herramienta para el aprendizaje de máquinas, proponemos usar el producto programático CatBoost, cuya última versión se puede descargar en este enlace. Como el artículo habla de una versión autónoma que no necesita de otros lenguajes de programación, bastará con descargar el archivo de la última versión con la extensión "exe", por ejemplo, el archivo "catboost-0.24.1.exe".
CatBoost es un producto que la conocida empresa Yándex usa para resolver problemas reales en el campo del aprendizaje de máquinas, lo cual nos permitirá esperar soporte del producto, así como mejoras y corrección de errores, a pesar de que el código del producto se encuentre disponible para todos.
Y quién mejor que los propios creadores para hablar del producto: podrá tener más detalles sobre el mismo en el vídeo a continuación o en esta presentación.
En resumen, CatBoost construye un conjunto de árboles de decisión de tal forma que cada árbol siguiente mejore el rendimiento de la respuesta probabilística total de todos los árboles anteriores: esta acción en suma se llama potenciación del gradiente.
Preparando los datos para el aprendizaje de máquinas
Generalmente, los datos que contienen los predictores y la función objetivo se denominan muestra, pero, en sí mismos, suponen una matriz de datos con una lista de predictores en forma de columnas, donde cada fila constituye el momento del registro de los indicadores y contiene las lecturas de los predictores en ese momento. Las medidas anotadas en una línea se pueden obtener con una determinada frecuencia temporal, y también representar diferentes objetos, por ejemplo, imágenes. Como formato de archivo, normalmente se utiliza CSV, en el que se registran con un separador condicional los indicadores y sus encabezados (no es obligatorio).
Como ejemplo, usaremos los siguientes predictores:
- Hora / horas / fracciones de horas/ día de la semana;
- Posición relativa de las barras;
- Osciladores.
Como función objetivo, usaremos la señal de cruzamiento de la media móvil, y no el contacto con la misma en la siguiente barra; si compramos por encima de la media móvil y vendemos por debajo de esta, cada vez que cerremos una posición abierta al llegar una señal, la función objetivo responderá a la siguiente pregunta: ¿abrimos una posición o no?
No recomendamos usar un script para generar la función objetivo y los predictores: mejor utilizar un asesor experto que permita detectar los errores lógicos en el código al generar la muestra, y simular con mayor detalle la obtención de datos, como sucedería en el trading real, incluso considerando la desincronización temporal en la apertura de diferentes instrumentos. Si la función objetivo funciona con instrumentos distintos, deberemos considerar el retraso en la obtención y el procesamiento de la información, evitar mirar hacia el futuro, detectar el redibujado y la lógica de los indicadores que no sea adecuada para el aprendizaje; como resultado de ello, los predictores se tendrán que calcular con la barra en tiempo real al usar el modelo en la práctica.
Últimamente, en la comunidad de tráders algorítmicos, en particular entre aquellos que se dedican al aprendizaje de máquinas, se ha afianzado la opinión de que los indicadores del paquete estándar son en su mayoría inútiles. Este argumento se basa en que dichos indicadores tienen importantes inconvenientes: suelen retrasarse y constituyen un derivado del precio, lo que conlleva la ausencia de información sobre el precio; además, y esto es lo más importante, las redes neuronales pueden crear cualquier indicador calculado. En realidad, las redes neuronales son capaces de mucho más, pero, tras el aparato matemático, desarrollado principalmente en el siglo XX, existe un gran poder de computación cuyo control no está al alcance del tráder privado, y la complejidad de la topología de estas redes no le permitirá dominarlas rápidamente. Los métodos de aprendizaje de áquinas basados en árboles de decisión no pueden competir con las redes neuronales en cuanto a la creación de nuevas entidades matemáticas, ya que no abarcan el proceso de transformación de los datos de entrada. Por otro lado, sí que se muestran más eficientes que las redes neuronales en la identificación de dependencias directas, especialmente al trabajar con matrices de datos voluminosos y heterogéneos. En esencia, la misión de las redes neuronales consiste en generar nuevos patrones (parámetros que describan el mercado y los modelos construidos sobre árboles de decisión) para identificar patrones entre los conjuntos de dichos patrones. Al usar los indicadores del paquete estándar como predictor, básicamente, estamos tomando un patrón utilizado en su trabajo por miles de tráders en diferentes mercados bursátiles y extrabursátiles en diferentes países; por consiguiente, existe una base teórica para creer que podremos identificar una dependencia inversa en los indicadores: el comportamiento de los tráders a partir de las lecturas de los indicadores que influyen en el instrumento con el que se comercia. No hemos utilizado osciladores anteriormente, por lo que resultará interesenta comprobar con los lectores qué saldrá como resultado.
Vamos a usar los siguientes indicadores del paquete estándar:
- Accelerator Oscillator
- Average Directional Movement Index
- Average Directional Movement Index by Welles Wilder
- Average True Range
- Bears Power
- Bulls Power
- Commodity Channel Index
- Chaikin Oscillator
- DeMarker
- Force Index
- Gator
- Market Facilitation Index
- Momentum
- Money Flow Index
- Moving Average of Oscillator
- Moving Averages Convergence/Divergence
- Relative Strength Index
- Relative Vigor Index
- Standard Deviation
- Stochastic Oscillator
- Triple Exponential Moving Averages Oscillator
- Williams' Percent Range
- Variable Index Dynamic Average
- Volume
Los indicadores se calculan según todos los marcos temporales disponibles en MetaTrader 5, incluyendo el marco de días.
Durante la elaboración del presente artículo, resultó que los valores de los indicadores de la lista que sigue dependían en gran medida de la fecha de comienzo de las simulaciones en el terminal, por lo que decidimos excluirlos. No obstante, podemos intentar usar la diferencia en los valores de las diferentes barras del indicador, cosa que no haremos aquí, para no complicarnos en exceso.
Lista de indicadores descartados:
- Awesome Oscillator
- On Balance Volume
- Accumulation/Distribution
Para trabajar con los recuadros CSV, utilizaremos la magnífica biblioteca "CSV fast.mqh" de Aliaksandr Hryshyn. Esta biblioteca permite:
- Crear recuadros, leerlos desde un archivo y guardarlos en un archivo.
- Leer y registrar (usando una dirección) información en cualquier celda de un recuadro.
- Las columnas de un recuadro pueden guardar diferentes tipos de datos, lo cual nos ahorrará RAM para su ubicación.
- Los segmentos del recuadro se pueden copiar por entero de las direcciones indicadas a la dirección especificada de otro recuadro especificado.
- Asimismo, podemos realizar el filtrado según cualquier columna del recuadro.
- También disponemos de una clasificación descendente y ascendente de varios niveles en el recuadro, según los valores indicados en las celdas de la columna del recuadro.
- Además, podemos reindexar y ocultar las columnas.
- Hay multitud de pequeñas cosas útiles que hacen del trabajo con el recuadro algo cómodo y agradable.
Componentes del asesor
Estrategia básica:
Hemos decidido utilizar como estrategia básica para generar la señal una estrategia con condiciones simples; entraremos en el mercado si se cumplen las siguientes condiciones:
- El precio ha cruzado el indicador de media móvil del valor de precio,
- Tras suceder el punto 1, el precio por primera vez no ha tocado la media móvil cruzada en la barra anterior.
Hay que reconocer que esta fue la primera estrategia usada por al autor, inventada en la segunda mitad de la primera década del siglo XXI. A pesar de su sencillez, esta estrategia pertenece a la clase de tendencia, y demuestra buenos resultados en los segmentos correspondientes del historial comercial. Vamos a tratar de utilizar el aprendizaje de máquinas para reducir la cantidad de entradas erróneas en los sementos planos.
Vamos a representar el generador de señales de la manera siguiente:
//+-----------------------------------------------------------------+ //| Returns a buy or Sell signal - basic strategy | //+-----------------------------------------------------------------+ bool Signal() { // Reset position opening blocking flag SellPrIMA=false; // Open a pending sell order BuyPrIMA=false; // Open a pending buy order SellNow=false; // Open a market sell order BuyNow=false; // Open a market buy order bool Signal=false;// Function operation result int BarN=0; // The number of bars on which MA is not touched if(iOpen(Symbol(),Signal_MA_TF,0)>MA_Signal(0) && iLow(Symbol(),Signal_MA_TF,1)>MA_Signal(1)) { for(int i=2; i<100; i++) { if(iLow(Symbol(),Signal_MA_TF,i)>MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)<MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)>=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x))break;// Signal has already been processed on this cycle if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x)) { BarN=x; BuyNow=true; break; } } } } } if(iOpen(Symbol(),Signal_MA_TF,0)<MA_Signal(0) && iHigh(Symbol(),Signal_MA_TF,1)<MA_Signal(1)) { for(int i=2; i<100; i++) { if(iHigh(Symbol(),Signal_MA_TF,i)<MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)>MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)<=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x))break;// Signal has already been processed on this cycle if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x)) { BarN=x; SellNow=true; break; } } } } } if(BuyNow==true || SellNow==true)Signal=true; return Signal; }
Obtenemos los valores de los predictores:
Obtendremos los predictores con la ayuda de funciones; su código se adjunta al artículo. No obstante, mostraremos cómo lograr esto fácilmente para una gran cantidad de indicadores. Debemos tener en cuenta que tomaremos las lecturas de los indicadores en 3 puntos: las barras formadas 1 y 2, que teóricamente nos permitirán localizar el llamado nivel de señal en el indicador, y la barra con un desplazamiento de 15, que nos permitirá imaginar aproximadamente la dinámica de movimiento del indicador. Obviamente, se trata de una forma simplificada de obtener información y se puede mejorar sustancialmente.
Escribiremos todos los predictores en un recuadro formado en la RAM de la computadora. El recuadro contendrá una fila que se usará más tarde como vector de los datos numéricos de entrada para el intérprete del modelo CatBoost.
#include "CSV fast.mqh"; // Class for working with tables CSV *csv_CB=new CSV(); // Create a table class instance, in which current predictor values will be stored //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CB_Tabl();// Creating a table with predictors return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Create a table with predictors | //+------------------------------------------------------------------+ void CB_Tabl() { //--- Columns for oscillators Size_arr_Buf_OSC=ArraySize(arr_Buf_OSC); Size_arr_Name_OSC=ArraySize(arr_Name_OSC); Size_TF_OSC=ArraySize(arr_TF_OSC); for(int n=0; n<Size_arr_Buf_OSC; n++)SummBuf_OSC=SummBuf_OSC+arr_Buf_OSC[n]; Size_OSC=3*Size_TF_OSC*SummBuf_OSC; for(int S=0; S<3; S++)// Loop by the number of shifts { string Shift="0"; if(S==0)Shift="1"; if(S==1)Shift="2"; if(S==2)Shift="15"; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { name_P=arr_Name_OSC[o]+"_B"+IntegerToString(b,0)+"_S"+Shift+"_"+arr_TF_OSC[T]; csv_CB.Add_column(dt_double,name_P);// Add a new column with a name to identify a predictor } } } } } //+------------------------------------------------------------------+ //--- Call predictor calculation //+------------------------------------------------------------------+ void Pred_Calc() { //--- Get information from oscillator indicators double arr_OSC[]; iOSC_Calc(arr_OSC); for(int p=0; p<Size_OSC; p++) { csv_CB.Set_value(0,s(),arr_OSC[p],false); } } //+------------------------------------------------------------------+ //| Get values of oscillator indicators | //+------------------------------------------------------------------+ void iOSC_Calc(double &arr_OSC[]) { ArrayResize(arr_OSC,Size_OSC); int n=0;// Indicator handle index int x=0;// Total number of iterations for(int S=0; S<3; S++)// Loop by the number of shifts { n=0; int Shift=0; if(S==0)Shift=1; if(S==1)Shift=2; if(S==2)Shift=15; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { arr_OSC[x++]=iOSC(n, b,Shift); } n++;// Mark shift to the next indicator handle for calculation } } } } //+------------------------------------------------------------------+ //| Get the value of the indicator buffer | //+------------------------------------------------------------------+ double iOSC(int OSC, int Bufer,int index) { double MA[1]= {0.0}; int handle_ind=arr_Handle[OSC];// Indicator handle ResetLastError(); if(CopyBuffer(handle_ind,0,index,1,MA)<0) { PrintFormat("Failed to copy data from the OSC indicator, error code %d",GetLastError()); return(0.0); } return (MA[0]); }
Acumulación y marcado de la muestra:
Para crear la muestra y luego guardarla, vamos a acumular las lecturas de los predictores copiándolas del recuadro "csv_CB" al recuadro "csv_Arhiv".
Después de leer la fecha de la última señal y definir el precio de entrada y salida de la transacción, podemos conocer su resultado y asignar la etiqueta apropiada: "1" — positivo, y "0" — negativo. También podemos marcar el tipo de transacción según la señal: esto ayudará a construir el gráfico de balance: "1" — compra y "-1" — venta. Aquí mismo, calculamos el resultado financiero de la transacción comercial; para el resultado financiero, utilizamos por separado las columnas con el resultado de compra y venta. Esto resulta adecuado si la estrategia básica es un poco más compleja que la descrita en este artículo, o tiene elementos de acompañamiento de posición que produzcan diferentes resultados financieros para el módulo con respecto a la transacción comercial.
//+-----------------------------------------------------------------+ //| The function copies predictors to archive | //+-----------------------------------------------------------------+ void Copy_Arhiv() { int Strok_Arhiv=csv_Arhiv.Get_lines_count();// Number of rows in the table int Stroka_Load=0;// Starting row in the source table int Stolb_Load=1;// Starting column in the source table int Stroka_Save=0;// Starting row to write in the table int Stolb_Save=1;// Starting column to write in the table int TotalCopy_Strok=-1;// Number of rows to copy from the source. -1 copy to the last row int TotalCopy_Stolb=-1;// Number of columns to copy from the source, if -1 copy to the last column Stroka_Save=Strok_Arhiv;// Copy the last row csv_Arhiv.Copy_from(csv_CB,Stroka_Load,Stolb_Load,TotalCopy_Strok,TotalCopy_Stolb,Stroka_Save,Stolb_Save,false,false,false);// Copying function //--- Calculate the financial result and set the target label, if it is not the first market entry int Stolb_Time=csv_Arhiv.Get_column_position("Time",false);// Find out the index of the "Time" column int Vektor_P=0;// Specify entry direction: "+1" - buy, "-1" - sell if(BuyNow==true)Vektor_P=1;// Buy entry else Vektor_P=-1;// Sell entry csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+1,Vektor_P,false); if(Strok_Arhiv>0) { int Stolb_Target_P=csv_Arhiv.Get_column_position("Target_P",false);// Find out the index of the "Time" column int Load_Vektor_P=csv_Arhiv.Get_int(Strok_Arhiv-1,Stolb_Target_P,false);// Find out the previous operation type datetime Load_Data_Start=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv-1,Stolb_Time,false));// Read the position opening date datetime Load_Data_Stop=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv,Stolb_Time,false));// Read the position closing date double F_Rez_Buy=0.0;// Financial result in case of a buy operation double F_Rez_Sell=0.0;// Financial result in case of a sell operation double P_Open=0.0;// Position open price double P_Close=0.0;// Position close price int Metka=0;// Label for target variable P_Open=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Start,false)); P_Close=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Stop,false)); F_Rez_Buy=P_Close-P_Open;// Previous entry was buying F_Rez_Sell=P_Open-P_Close;// Previous entry was selling if((F_Rez_Buy-comission*Point()>0 && Load_Vektor_P>0) || (F_Rez_Sell-comission*Point()>0 && Load_Vektor_P<0))Metka=1; else Metka=0; csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+2,Metka,false);// Write label to a cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+3,F_Rez_Buy,false);// Write the financial result of a conditional buy operation to the cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+4,F_Rez_Sell,false);// Write the financial result of a conditional sell operation to the cell csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+2,-1,false);// Add a negative label to the labels to control labels } }
Aplicación del modelo:
Con la ayuda de la clase "Catboost.mqh" de Aliaksandr Hryshyn, ubicada aquí, interpretaremos los datos con la ayuda del modelo CatBoost obtenido.
Para la depuración, hemos añadido el recuadro "csv_Chek": en caso necesario, podremos guadar en él la lectura del modelo CatBoost.
//+-----------------------------------------------------------------+ //| The function applies predictors in the CatBoost model | //+-----------------------------------------------------------------+ void Model_CB() { CB_Siganl=1; csv_CB.Get_array_from_row(0,1,Solb_Copy_CB,features); double model_result=Catboost::ApplyCatboostModel(features,TreeDepth,TreeSplits,BorderCounts,Borders,LeafValues); double result=Logistic(model_result); if (result<Porog || result>Pridel) { BuyNow=false; SellNow=false; CB_Siganl=0; } if(Use_Save_Result==true) { int str=csv_Chek.Add_line(); csv_Chek.Set_value(str,1,TimeToString(iTime(Symbol(),PERIOD_CURRENT,0),TIME_DATE|TIME_MINUTES)); csv_Chek.Set_value(str,2,result); } }
Muestras guardadas en el archivo:
Al finalizar la pasada de prueba, guardamos el recuadro e indicamos el separador del número entero en forma de coma.
//+------------------------------------------------------------------+ // Function writing predictors to a file | //+------------------------------------------------------------------+ void Save_Pred_All() { //--- Save predictors to a file if(Save_Pred==true) { int Stolb_Target=csv_Arhiv.Get_column_position("Target_100",false);// Find out the index of the Target_100 column csv_Arhiv.Filter_rows_add(Stolb_Target,op_neq,-1,true);// Exclude lines with label "-1" in target variable csv_Arhiv.Filter_rows_apply(true);// Apply filter csv_Arhiv.decimal_separator=',';// Set a decimal separator string name=Symbol()+"CB_Save_Pred.csv";// File name csv_Arhiv.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save the file up to 5 characters } //--- Save the model values to a debug file if(Use_Save_Result==true) { csv_Chek.decimal_separator=',';// Set a decimal separator string name=Symbol()+"Chek.csv";// File name csv_Chek.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save file up to 5 decimal places } }
Indicador de calidad personalizado de los ajustes de la estrategia:
Ahora, deberemos buscar la configuración adecuada para el indicador usado por el modelo base, así que calcularemos un indicador para el simulador de estrategias que determine el mínimo de transacciones y retorne el tanto por ciento de transacciones rentables. Cuantos más objetos de entrenamiento (transacciones) tenga y más equilibrada esté la muestra (es decir, el porcentaje de operaciones rentables se deberá acercar al 50%), mejor será el entrenamiento. El cálculo del indicador personalizado tiene lugar en la función que mostramos a continuación.
//+------------------------------------------------------------------+ //| Custom variable calculating function | //+------------------------------------------------------------------+ double CustomPokazatelf(int VariantPokazatel) { double custom_Pokazatel=0.0; if(VariantPokazatel==1) { double Total_Tr=(double)TesterStatistics(STAT_TRADES); double Pr_Tr=(double)TesterStatistics(STAT_PROFIT_TRADES); if(Total_Tr>0 && Total_Tr>15000)custom_Pokazatel=Pr_Tr/Total_Tr*100.0; } return(custom_Pokazatel); }
Control de la frecuencia de ejecución de la parte principal del código:
Tenemos que obtener las soluciones comerciales para la apertura de una nueva barra, por eso, comprobaremos esta circunstancia con la ayuda de la siguiente función.
//+-----------------------------------------------------------------+ //| Returns TRUE if a new bar has appeared on the current TF | //+-----------------------------------------------------------------+ bool isNewBar() { datetime tm[]; static datetime prevBarTime=0; if(CopyTime(Symbol(),Signal_MA_TF,0,1,tm)<0) { Print("%s CopyTime error = %d",__FUNCTION__,GetLastError()); } else { if(prevBarTime!=tm[0]) { prevBarTime=tm[0]; return true; } return false; } return true; }
Funciones comerciales:
En el asesor, se usa la clase comercial "cPoza6", su idea fue desarrollada por el autor del presente artículo, y la implementación principal, por Vasiliy Pushkaryov. La clase se puso a prueba en la Bolsa de Moscú, pero su concepto no ha sido implementado por completo. Por eso, invitamos a cualquiera que lo desee a que lo finalice, es decir, a implementar las funciones para trabajar con el historial. Para el artículo, hemos desactivado la verificación del tipo de cuenta, así que deberá tener cuidado, la clase se creó originalmente para cuentas de compensación, pero para este asesor funcionará lo suficiente como para estudiar el aprendizaje de máquinas en el marco de este artículo.
El código del asesor se muestra sin la descripción de las funciones, para mayor claridad:
Si no consideramos una serie de funciones auxiliares y sacamos las funciones anteriores entre corchetes, el código del asesor experto en esta etapa se puede mostrar de la forma siguiente:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Check the correctness of model response interpretation values if(Porog>=Pridel || Pridel<=Porog)return(INIT_PARAMETERS_INCORRECT); if(Use_Pred_Calc==true) { if(Init_Pred()==INIT_FAILED)return(INIT_FAILED);// Initialize indicator handles CB_Tabl();// Creating a table with predictors Solb_Copy_CB=csv_CB.Get_columns_count()-3;// Number of columns in the predictor table } //---объявляем handle_MA_Slow handle_MA_Signal=iMA(Symbol(),Signal_MA_TF,Signal_MA_Period,1,Signal_MA_Metod,Signal_MA_Price); if(handle_MA_Signal==INVALID_HANDLE) { PrintFormat("Failed to create handle of the handle_MA_Signal indicator for the symbol %s/%s, error code %d", Symbol(),EnumToString(Period()),GetLastError()); return(INIT_FAILED); } //--- Create a table to write model values - for debugging purposes if(Use_Save_Result==true) { csv_Chek.Add_column(dt_string,"Data"); csv_Chek.Add_column(dt_double,"Rez"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(Save_Pred==true)Save_Pred_All();// Call a function to write predictors to a file delete csv_CB;// Delete the class instance delete csv_Arhiv;// Delete the class instance delete csv_Chek;// Delete the class instance } //+------------------------------------------------------------------+ //| Test completion event handler | //+------------------------------------------------------------------+ double OnTester() { return(CustomPokazatelf(1)); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Operations are only executed when the next bar appears if(!isNewBar()) return; //--- Get information on trading environment (deals/orders) OpenOrdersInfo(); //--- Get signal from the basic strategy if(Signal()==true) { //--- Calculate predictors if(Use_Pred_Calc==true)Pred_Calc(); //---Apply the CatBoost model if(Use_Model_CB==true)Model_CB(); //--- If there is an open position at the signal generation time, close it if(PosType!="0")ClosePositions("Close Signal"); //--- Open a new position if (BuyNow==true)OpenPositions(BUY,1,0,0,"Open_Buy"); if (SellNow==true)OpenPositions(SELL,1,0,0,"Open_Sell"); //--- Copy the table with the current predictors to the archive table if(Save_Pred==true)Copy_Arhiv(); } }
Ajustes externos del asesor:
Después de familiarizarnos con el código de las funciones del asesor, merce la pena aclarar qué ajustes tiene:
1. Ajuste de las acciones con los predictores:
- "Calcular predictores" — establecemos "true" si queremos guardar una muestra o aplicar el modelo CatBoost con los datos;
- "Guardar predictores" — establecemos "true" si queremos guardar los predictores en un archivo para su posterior entrenamiento;
- "Tipo de volumen en los indicadores" — establecemos el tipo de volumen, según los ticks o según el volumen bursátil real;
- "Representar en el gráfico los indicadores de los predictores" — si queremos ver los indicadores, establecemos "true" ;
- "Comisión y spread en puntos para el registro en la función objetivo" — se ha diseñado para registrar las comisiones y el spread en el marcado de la función objetivo, así como filtrar las transacciones positivas poco significativas;
2. Parámetros del indicador MA para la señal de la estrategia básica:
- "Periodo";
- "Marco temporal";
- "Métodos de medias móviles";
- "Base de precio del cálculo";
3. Parámetros de aplicación del modelo CatBoost:
- "Aplicar a los datos el modelo CatBoost" — después de entrenar y compilar el asesor con el modelo entrenado, debemos establecer "true";
- "Umbral de clasificación de la unidad por el modelo" — umbral con el que el valor del modelo se interpretará como una unidad;
- "Límite de clasificación de la unidad por el modelo" — límite hasta el cual el valor del modelo se interpretará como una unidad;
- "Guardar en un archivo la lectura del modelo" — estableceremos "true" si queremos obtener un archivo para comprobar si el funcionamiento del modelo es correcto.
Buscando ajustes adecuados para la estrategia básica
Tras analizar el código y configurar el asesor experto, vamos a optimizar el indicador de la estrategia básica. Para ello, seleccionaremos un criterio personalizado para valorar la calidad de la configuración de la estrategia. Como parte del artículo, hemos realizado una simulación sobre la cohesión de contratos de futuros de Si para el activo básico USDRUB_TOM del bróker Otkrytie, con un instrumento llamado "Si Splice", un intervalo de fechas que va del 01/06/2014 al 31/10/2020, y un marco temporal M1. Modo de simulación de precios OHLC en M1.
Parámetros de EA optimizados:
- "Periodo": de 8 a 256, salto 8;
- "Marco temporal": de M1 a D1, sin salto;
- "Métodos de medias móviles": de SMA a LWMA, sin salto;
- "Base de precio del cálculo": de CLOSE a WEIGHTED.

Fig. 1 "Resultados de la optimizacón"
Partiendo de los resultados obtenidos, tenemos que buscar y seleccionar las configuraciones con un indicador personalizado alto, preferiblemente del 35%; con un número de transacciones no inferior a 15,000 o superior, y mirando, si así lo deseamos, otros indicadores econométricos.
Para mostrar el potencial del método de creación de estrategias comerciales utilizando el aprendizaje de máquinas, hemos seleccionado el conjunto con la siguiente configuración:
- "Periodo": 8;
- "Marco temporal": 2 Minutes;
- "Métodos de medias móviles": Linear weighted;
- "Base de precio del cálculo": High price.
Realizamos una pasada única y echamos un vistazo al gráfico.

Fig. 2 "Balance antes del entrenamiento"
Ningún tráder en su sano juicio pensaría en usar estas configuraciones de estrategia en el comercio. La señal contiene demasiado ruido y ofrece entradas erróneas en la transacción: vamos a intentar limpiarla un poco. No obstante, a diferencia de quienes se dedican a probar muchos parámetros de diferentes indicadores de filtrado de señales e inviertir copiosos recursos informáticos en áreas de iteración con intervalos donde la lectura del indicador no se ha dado o lo ha hecho rara vez y de forma estadísticamente insignificante, vamos a trabajar solo con aquellas áreas donde las lecturas del indicador han ofrecido realmente información.
Para ello, modificaremos la configuración del asesor para calcular y guardar los predictores, y luego hacer una sola pasada:
Ajuste de las acciones con los predictores:
- "Calcular predictores" — establecemos "true";
- "Guardar predictores" — establecemos "true";
- "Tipo de volumen en los indicadores" — establecemos el tipo de volumen, según los ticks o según el volumen bursátil real;
- "Representar en el gráfico los indicadores de los predictores" — dejamos "false";
- "Comisión y spread en puntos para el registro en la función objetivo" — establecemos 50.
Dejamos sin cambio los demás ajustes y realizamos una pasada única en el simulador de estrategias. Los cálculos serán más lentos, porque ahora se calculan y recopilan los datos de casi 2000 mil búferes de indicadores, y también se calculan otros predictores.
Encontramos nuestro archivo en la dirección de funcionamiento del agente (el autor trabaja en el modo portátil, por lo que tiene la dirección "F:\FX\Открытие Брокер_Demo\Tester\Agent-127.0.0.1-3002\MQL5\Files", " 3002" y esto indica que se han utilizado 3 flujos para el funcionamiento del agente) y comprobamos su contenido. Si hemos logrado abrir el archivo con el recuadro, significa que todo va según el plan.
Fig. 3 "Resumen del recuadro con los predictores"
Dividiendo la muestra
Para el entrenamiento, necesitaremos dividir la muestra en 3 partes y guardar estas en archivos:
- train.csv — muestra con la que se realizará el entrenamiento
- test.csv — muestra con la que se controlará y detendrá el resultado del entrenamiento
- exam.csv — muestra para valorar el resultado del entrenamiento
Utilizaremos con este cometido el script "CB_CSV_to3x.mq5".
Debemos indicar la ruta al directorio en el que se creará el modelo comercial y el nombre del archivo con la muestra.
Asimismo, creamos el archivo "Test_CB_Setup_0_000000000", que contiene los números de las columnas partiendo de cero, a los que se puede aplicar la condición: desactivar la etiqueta "Auxiliary" y marcar la columna que constituye la etiqueta "Label" de destino. Para nuestra muestra, el archivo tendrá el siguiente contenido:
2408 Auxiliary 2409 Auxiliary 2410 Label 2411 Auxiliary 2412 Auxiliary
El archivo se ubicará en el mismo lugar que la muestra preparada por el script.
Parámetros de CatBoost
CatBoost dispone de muchos parámetros y configuraciones; algunos de ellos influyen significativamente en el resultado del entrenamiento, mientras que otros apenas ejercen efecto sobre él. Podrá encontrar todos los parámetros para entrenar el modelo en este enlace. Vamos a marcar los parámetros principales (y sus claves entre paréntesis, si las hubiera) que influyen en mayor medida en los resultados del entrenamiento del modelo y que se encuentran disponibles para la configuración en el script "CB_Bat":
- "Directorio del proyecto" — aquí debemos indicar la ruta al directorio donde se encuentra la muestra, hasta el directorio "Setup";
- "Nombre de archivo exe de CatBoost" — en este artículo, utilizamos la versión del archivo catboost-0.24.1.exe; si el lector ha descargado una versión más reciente del sitio web del proyecto CatBoost, indique esta;
- "Tipo de potenciación (esquema de refuerzo del modelo)" (boosting-type) — se seleccionan dos opciones de tipo de potenciación:
- Ordered — entrenamiento de calidad, pero lento y con una muestra pequeña.
- Plain — esquema clásico de potenciación del gradiente.
- "Profundidad del árbol" (depth) — se indica la profundidad del árbol de decisión simétrico. Los desarrolladores recomiendan los parámetros en el intervalo de 6 a 10;
- "Número máximo de iteraciones (árboles)" (iterations) — indica el número máximo de árboles construidos en el modelo de forma secuencial. El número de árboles en el modelo después del entrenamiento puede ser menor si el modelo no mejora en la prueba (muestra de validación). El número de iteraciones debe modificarse según el cambio en el parámetro "tasa de aprendizaje" (learning-rate);
- "Tasa de aprendizaje" (learning-rate) — velocidad del salto por el gradiente, es decir, criterio de generalización al construir cada árbol de decisión posterior. Cuanto menor sea el valor, más lento y más completo será el entrenamiento, aunque requerirá más tiempo y se necesitarán más iteraciones, así que mejor modificar este indicador junto con "Número máximo de iteraciones (árboles)" (iterations);
- "Seleccionar el método para calcular automáticamente los pesos de las clases de la función objetivo" (class-weights) — este parámetro nos permite mejorar el entrenamiento de una muestra no equilibrada según el número de ejemplos en cada clase. Existen diferentes métodos de equilibrado:
- None — todos los pesos de las clases se establecen iguales a 1
- Balanced — el peso de la clase se basa en el peso total
- SqrtBalanced — el peso de la clase se basa en el número total de objetos en cada clase
- "Método de selección de los pesos de los objetos" (bootstrap-type) — el parámetros se encarga del modo de cálculo de los objetos al buscar los predictores para construir un nuevo árbol. Se ofrecen las siguientes opciones a elegir:
- Bayesian;
- Bernoulli;
- MVS;
- No;
- "Intervalo de pesos aleatorios de los coeficientes para seleccionar objetos" (bagging-temperature) - se usa si hemos seleccionado el método de cálculo de objetos al buscar predictores para construir un nuevo árbol "bayesian"; este parámetro añade aleatoriedad al seleccionar predictores para construir un árbol, dicha aleatoriedad permite reducir el reentrenamiento (memorización de datos) y mejorar la detección de patrones; el parámetro puede adquirir un valor que va de cero a infinito, según las instrucciones.
- "Frecuencia de muestreo de pesos y objetos al construir los árboles" (sampling-frequency) - este parámetro nos permite modificar la frecuencia de reevaluación de los predictores para construir un árbol; puede adquirir uno de los siguientes valores:
- PerTree — antes de construir cada nuevo árbol;
- PerTreeLevel — antes de seleccionar cada nueva bifuración del árbol;
- "Porcentaje de predictores analizados con una tasa de aprendizaje 1=100%" (rsm) - este parámetro influye en el número de predictores que se tomarán aleatoriamente para encontrar el mejor de ellos al construir un árbol aparte; la reducción del parámetro permite acelerar el proceso de aprendizaje. Añade un poco de aleatoriedad, pero incrementa el número de iteraciones (árboles) en el modelo final;
- "Regularización L2" (l2-leaf-reg) - en teoría, este parámetro nos permite reducir el ajuste según la muestra, y afecta a la calidad del modelo final;
- "Valor aleatorio (semilla) usado en el entrenamiento" (random-seed) - no existe una descripción clara en la documentación, por lo general, se trata de un generador de pesos aleatorios al inicio del entrenamiento. Por propia expriencia, podemos decir que este influye significativamente en el entrenamiento del modelo, debe ser iterado;
- "Cantidad de aleatoriedad para valorar la estructura del árbol (random-strength)" - este parámetro influye en la valoración de la bifurcación al construir el árbol. Recomendamos iterarlo, lo cual puede mejorar la calidad del modelo;
- "Número de saltos a lo largo del gradiente para seleccionar el valor de una hoja" (leaf-estimation-iterations) - cuando un árbol ya ha sido seleccionado y construido, se calculan los valores en las hojas; podemos calcular varios pasos a lo largo del gradiente, este parámetro influye en la calidad y velocidad del aprendizaje;
- "Modo de cuantificación para objetos numéricos" (feature-border-type) - este parámetro trabaja con diferentes algoritmos de cuantificación (construcción de cuadrícula) en los objetos de la muestra; el parámetro influye considerablemente en la capacidad de entrenamiento del modelo. Las siguientes opciones están disponibles:
- Median,
- Uniform,
- UniformAndQuantiles,
- MaxLogSum,
- MinEntropy,
- GreedyLogSum,
- "Número de divisiones de la cuadrícula en intervalos" (border-count) — este parámetro se encarga del número de divisiones de todo el intervalo de lecturas de cada predictor; de hecho, el número de divisiones resulta menor cuanto mayor sea el parámetro y más estrecha sea la cuadrícula, lo que significa menor porcentaje de ejemplos. Deberemos seleccionar este parámetro, pues influye significativamente en la calidad y la velocidad del aprendizaje;
- "Guardar archivo con bordes" (output-borders-file) — podemos guardar cuadrículas de cuantificación (bifurcación) para realizar un análisis aparte o usar estas durante el entrenamiento posterior; influye en la velocidad de aprendizaje, ya que guarda los datos en un archivo al crear cada nuevo modelo;
- "Función de métrica de valoración de errores para corregir el entrenamiento" (loss-function) - se selecciona la función según la cual se valorará el error al entrenar el modelo. No hemos notado especial diferencia que influya en la calidad, pero hay dos opciones:
- Logloss;
- CrossEntropy;
- "Número de árboles sin mejora para interrumpir el entrenamiento" (od-wait)) — el nombre muestra perfectamente el contenido, si el entrenamiento se detiene rápidamente, merecerá la pena intentar aumentar el número de espera en un orden de magnitud; a veces, hay muestras que son muy distintas para el entrenamiento y el control de la prueba (validación), y esto puede resultarles de ayuda para el aprendizaje. Asimismo, debemos incrementar este parámetro al modificar la velocidad de entrenamiento: cuanto menor sea la velocidad, más tiempo tendremos que esperar las mejoras antes de detener el aprendizaje;
- "Función de métrica de valoración de errores para detener el entrenamiento" (eval-metric) — permite indicar una métrica entre las presentes en la lista que se utilizará para podar el árbol y detener el entrenamiento; tenemos las siguientes métricas a nuestra disposición:
- Logloss;
- CrossEntropy;
- Precision;
- Recall;
- F1;
- BalancedAccuracy;
- BalancedErrorRate;
- MCC;
- Accuracy;
- CtrFactor;
- NormalizedGini;
- BrierScore;
- HingeLoss;
- HammingLoss;
- ZeroOneLoss;
- Kappa;
- WKappa;
- LogLikelihoodOfPrediction;
- "Objeto de iteración" — permite seleccionar el parámetro del modelo para la iteración; los siguientes parámetros están disponibles:
- No iterar;
- Random-seed — valor aleatorio (semilla) utilizado para el entrenamiento;
- Random-strength — número de aleatoriedades para valorar la estructura del árbol;
- Border-count — número de bifurcaciones de la cuadrícula en intervalos;
- l2-Leaf-reg — regularización L2;
- Bagging-temperature — intervalo de coeficientes de peso aleatorios para seleccionar los objetos;
- Leaf_estimation_iterations — número de saltos por el gradiente para seleccionar los valores en la hoja;
- "Valor inicial de la variable" — establecemos el valor inicial para la iteración;
- "Valor final de la variable" — establecemos el valor final para la iteración;
- "Salto de cambio" — establecemos el salto de cambio del valor de la variable para la iteración;
- "Tipo de representación de los resultados de clasificación"(prediction-type) — seleccionamos cómo se registrarán las respuestas del modelo en las muestras; no influye en el entrenamiento, y se utiliza después del entrenamiento al aplicar el modelo en las muestras:
- Probability — probabilidad;
- Class — clase;
- RawFormulaVal
- Exponent
- LogProbability
- "Número de árboles en el modelo, 0 - todos" - número de árboles en el modelo que se usarán para la clasificación; nos permite valorar los cambios en la calidad de la clasificación cuando el modelo se aplica en muestras;
- "Modo de análisis del modelo" (fstr-type) — hay disponibles diferentes métodos de análisis del modelo, lo cual nos permite valorar la importancia de los predictores para un modelo en concreto. Queremos sugerir a los lectores que los analicen por su cuenta y compartan los resultados con el autor; están disponibles las siguientes opciones:
- PredictionValuesChange — cómo cambia el pronóstico al modificar los valores del objeto;
- LossFunctionChange — cómo cambia el pronóstico al excluir el objeto;
- InternalFeatureImportance
- Interaction
- InternalInteraction
- ShapValues
El script nos permite iterar una serie de parámetros de ajuste del modelo; para ello, tenemos que seleccionar un objeto de iteración distinto de "NONE" e indicar el valor inicial de la variable, el valor final de la misma y el salto de cambio del parámetro.
Estrategia de aprendizaje
Dividiremos la estrategia de aprendizaje en tres etapas:
- Configuración básica, es decir, los parámetros encargados de la profundidad y el número de árboles en el modelo, así como de la tasa de entrenamiento, el peso de las clases en el modelo y otros ajustes para iniciar el proceso de entrenamiento. Normalmente, estos parámetros no se iteran; en la mayoría de los casos, los ajustes predeterminados generados por el script serán suficientes.
- Búsquede de la cuadrícula óptima para dividir los parámetros: CatBoost procesa previamente el recuadro con los predictores para iterar sobre el intervalo de valores a lo largo de los límites de la cuadrícula, así que debemos encontrar la cuadrícula en la que se produzca el mejor entrenamiento. Tiene sentido iterar sobre todos los tipos de cuadrículas con un intervalo de 8-512; nosotros hemos utilizado incrementos de salto en cada valor: 8, 16, 32, etcétera.
- Ajustamos el script de nuevo y establecemos en la configuración la cuadrícula encontrada para la división (cuantificación) de los predictores. Podemos iterar sobre los otros parámetros disponibles; generalmente, nos limitamos a un "Seed" de 1-1000.
En el marco de este artículo, para la primera etapa de la "estrategia de aprendizaje", usaremos los ajustes predeterminados del script "CB_Bat", ajustaremos el método de división en "MinEntropy" e iteraremos sobre la cuadrícula de 16 a 512 con un salto de 16.
Para configurar los anteriores parámetros, utilizaremos el script "CB_Bat", que creará archivos de texto con las claves necesarias para entrenar los modelos, así como un archivo auxiliar:
- _00_Dir_All.txt - archivo auxiliar
- _01_Train_All.txt - ajustes para el entrenamiento
- _02_Rezultat_Exam.txt - ajustes para registrar la clasificación por modelos de la muestra de examen
- _02_Rezultat_test.txt - ajustes para registrar la clasificación por modelos de la muestra de prueba
- _02_Rezultat_Train.txt - ajustes para registrar la clasificación por modelos de la muestra de entrenamiento
- _03_Metrik_Exam.txt - ajustes para registrar las métricas de cada árbol de modelos de la muestra de examen
- _03_Metrik_Test.txt - ajustes para registrar las métricas de cada árbol de modelos de la muestra de prueba
- _03_Metrik_Train.txt - ajustes para registrar las métricas de cada árbol de modelos de la muestra de entrenamiento
- _04_Analiz_Exam.txt - ajustes para registrar la valoración de la significación de los predictores de los modelos de la muestra de examen
- _04_Analiz_Test.txt - ajustes para registrar la valoración de la significación de los predictores de los modelos de la muestra de prueba
- _04_Analiz_Train.txt - ajustes para registrar la valoración de la significación de los predictores de los modelos de la muestra de entrenamiento
Podríamos crear un archivo que ejecutara acciones secuencialmente después del entrenamiento, pero, para usar de manera óptima la CPU, algo especialmente importante en las versiones anteriores de CatBoost, hemos lanzado de 6 archivos a la vez después del entrenamiento.
Entrenamiento de modelos
Después de obtener los archivos, cambiamos el nombre del archivo "_00_Dir_All.txt" a "_00_Dir_All.bat" y lo ejecutamos: este creará los directorios necesarios para ubicar los modelos y cambiará la extensión de los archivos restantes a "bat".
Bien, ahora ya tenemos el directorio "Setup" en el directorio del proyecto, con el contenido siguiente:
- _00_Dir_All.bat - archivo auxiliar
- _01_Train_All.bat - configuración para el entrenamiento
- _02_Rezultat_Exam.bat — ajustes para registrar la clasificación por modelos de la muestra de examen
- _02_Rezultat_test.bat — ajustes para registrar la clasificación por modelos de la muestra de prueba
- _02_Rezultat_Train.bat — ajustes para registrar la clasificación por modelos de la muestra de entrenamiento
- _03_Metrik_Exam.bat — ajustes para registrar las métricas de cada árbol de modelos de la muestra de examen
- _03_Metrik_Test.bat — ajustes para registrar las métricas de cada árbol de modelos de la muestra de prueba
- _03_Metrik_Train.bat — ajustes para registrar las métricas de cada árbol de modelos de la muestra de entrenamiento
- _04_Analiz_Exam.bat — ajustes para registrar la valoración de la significación de los predictores de los modelos de la muestra de examen
- _04_Analiz_Test.bat — ajustes para registrar la valoración de la significación de los predictores de los modelos de la muestra de prueba
- _04_Analiz_Train.bat — ajustes para registrar la valoración de la significación de los predictores de los modelos de la muestra de entrenamiento
- catboost-0.24.1.exe — archivo ejecutable para entrenar los modelos CatBoost
- train.csv — muestra con la que se realizará el entrenamiento
- test.csv — muestra con la que se controlará y detendrá el resultado del entrenamiento
- exam.csv — muestra para valorar el resultado del entrenamiento
- Test_CB_Setup_0_000000000//Archivo con información sobre las columnas de la muestra utilizadas para el entrenamiento
Iniciamos el archivo "_01_Train_All.bat" y observamos el proceso de entrenamiento iniciado.
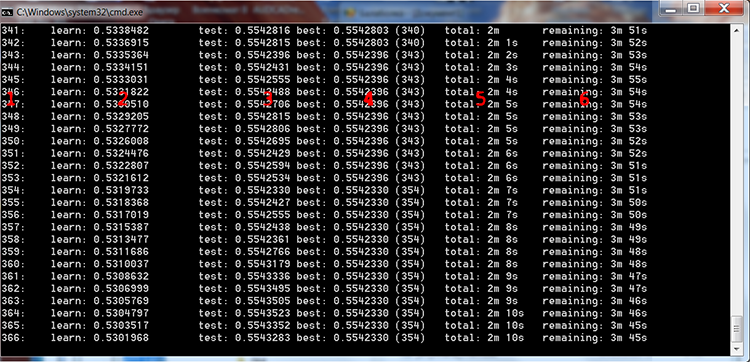
Fig. 4 "Proceso de entrenamiento de CatBoost"
En la imagen de arriba, hemos numerado las columnas en rojo para describir los valores en ellas:
- El número de árboles construidos es igual al número de iteraciones;
- El resultado del cálculo de la función de pérdida seleccionada en la muestra para el entrenamiento;
- El resultado del cálculo de la función de pérdida seleccionada en la muestra para el control;
- El mejor resultado del cálculo de la función de pérdida seleccionada en la muestra para el control, entre paréntesis, se indica el número de iteración;
- El tiempo real que ha pasado desde el inicio del entrenamiento del modelo;
- El tiempo restante estimado hasta el final del entrenamiento, si se entrenan todos los árboles indicados en la configuración.
Si hemos seleccionado el intervalo de búsqueda en la configuración del script, los modelos en el ciclo se entrenarán tantas veces como sea necesario, según el contenido del archivo:
FOR %%a IN (*.) DO ( catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 16 --feature-border-type MinEntropy --output-borders-file quant_4_00016.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type MinEntropy --output-borders-file quant_4_00032.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 48 --feature-border-type MinEntropy --output-borders-file quant_4_00048.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 64 --feature-border-type MinEntropy --output-borders-file quant_4_00064.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 80 --feature-border-type MinEntropy --output-borders-file quant_4_00080.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_96\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 96 --feature-border-type MinEntropy --output-borders-file quant_4_00096.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_112\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 112 --feature-border-type MinEntropy --output-borders-file quant_4_00112.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_128\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 128 --feature-border-type MinEntropy --output-borders-file quant_4_00128.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_144\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 144 --feature-border-type MinEntropy --output-borders-file quant_4_00144.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_160\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 160 --feature-border-type MinEntropy --output-borders-file quant_4_00160.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
Cuando se haya completado el entrenamiento, iniciamos a la vez los 6 archivos bat restantes para obtener los resultados del entrenamiento como etiquetas e indicadores estadísticos.
Valoración exprés de los resultados del entrenamiento
Para obtener las lecturas métricas de los modelos y sus resultados financieros, usamos el script "CB_Calc_Svod.mq5".
Este script tiene un filtro para seleccionar modelos según el balance final en la muestra de examen. Si el balance es superior a un valor dado, podemos construir un gráfico de balance a partir de la muestra, convertirlo en mqh y ubicarlo en un directorio separado del modelo CatBoost del proyecto.
Después de iniciar el script, esperamos a que termine su trabajo, y creamos el directorio "Analiz", en el cual estará el archivo "CB_Svod.csv" y los gráficos de balance según el nombre del modelo, si su construcción ha sido seleccionada en los ajustes, así como el directorio "Models_mqh" donde se encuentran los propios modelos convertidos a formato mqh.
Tras abrir el archivo "CB_Svod.csv", veremos las lecturas métricas de cada modelo para cada muestra aparte, incluyendo el resultado financiero.
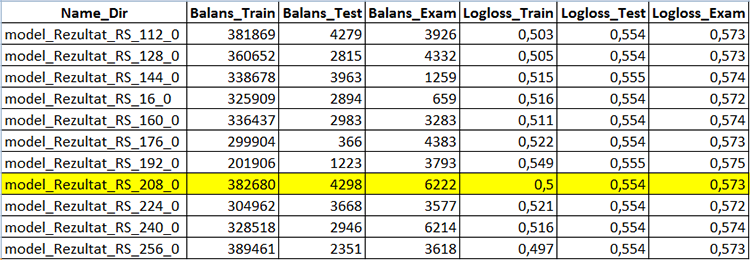
Fig. 5 "Fragmento del recuadro con los resultados de los modelos de construcción - archivo "CB_Svod.csv""
Seleccionamos el modelo necesario del subdirectorio "Models_mqh" del directorio en el que se han entrenado nuestros modelos y lo colocamos en el directorio con el asesor. Ponemos el signo de comentario "//" delante de la línea con los búferes vacíos al principio del código del asesor, igual que en el código de abajo, y luego incluimos el archivo en el modelo en nuestro asesor:
//If the CatBoost model is in an mqh file, comment the below line //uint TreeDepth[];uint TreeSplits[];uint BorderCounts[];float Borders[];double LeafValues[];double Scale[];double Bias[]; #include "model_RS_208_0.mqh"; // Model file
Después de realizar la compilación del asesor, pasamos el ajuste "Aplicar a los datos el modelo CatBoost" a "true", desactivamos el guardado de la muestra e iniciamos el simulador de estrategias con los siguientes parámetros.
1. Ajuste de las acciones con los predictores:
- "Calcular predictores" — establecemos "true";
- "Guardar predictores" — establecemos "false";
- "Tipo de volumen en los indicadores" — establecemos el tipo de volumen que había durante el entrenamiento;
- "Representar en el gráfico los indicadores de los predictores" — establecemos "false";
- "Comisión y spread en puntos para el registro en la función objetivo" — dejamos el valor que hay, este no influirá en el modelo preparado.
2. Parámetros del indicador MA para la señal de la estrategia básica:
- "Periodo": 8;
- "Marco temporal": 2 Minutes;
- "Métodos de medias móviles": Linear weighted;
- "Base de precio del cálculo": High price.
3. Parámetros de aplicación del modelo CatBoost:
- "Aplicar a los datos el modelo CatBoost" — dejamos "true";
- "Umbral de clasificación de la unidad por el modelo" — dejamos 0,5;
- "Límite de clasificación de la unidad por el modelo" — dejamos 1;
- "Guardar en un archivo el indicador del modelo" — dejamos "false".
Obtenemos el siguiente resultado en todo el periodo de muestra.
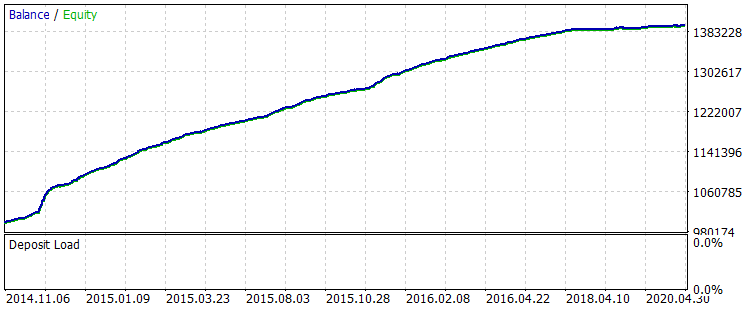
Fig. 6 "Balance después del entrenamiento en el periodo del 01.06.2014 al 31.10.2020
Comparamos los dos gráficos de balance en el intervalo (del 01.08.2019 al 31.10.2020) fuera del entrenamiento, lo cual se corresponde con la muestra "exam.csv" antes del entrenamiento y después del mismo.
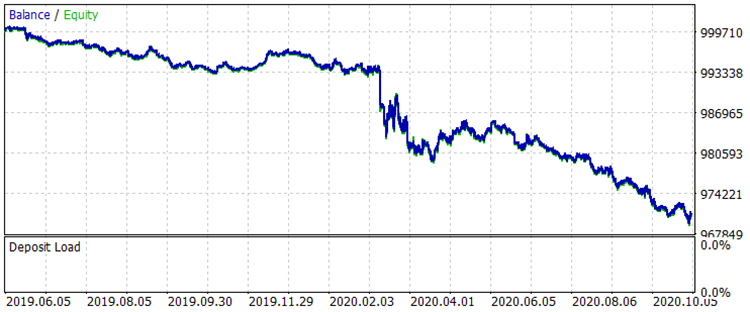
Fig. 7 "Balance antes del entrenamiento en el periodo del 01.08.2019 al 31.10.2020"
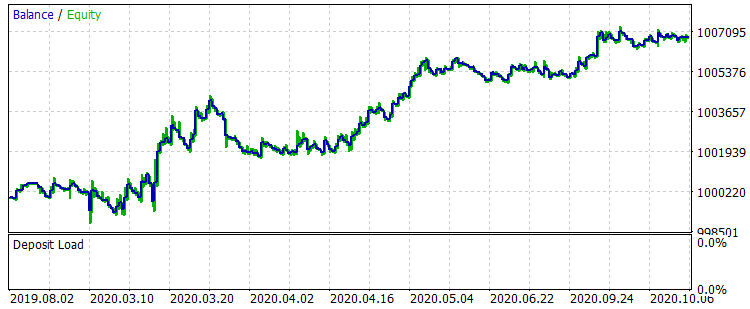
Fig. 8 "Balance después del entrenamiento en el periodo del 01.08.2019 al 31.10.2020"
Los resultados no son sobresalientes, pero podemos notar que se cumple la regla principal en el trading: "no perder dinero". Incluso si la selección no fuera responsabilidad de este modelo, sino del otro modelo del archivo "CB_Svod.csv", el efecto seguiría siendo positivo, porque el resultado financiero del peor modelo que obtuvimos es de -25 puntos, y el resultado financiero promedio de todos los modelos es de 3889,9 puntos.
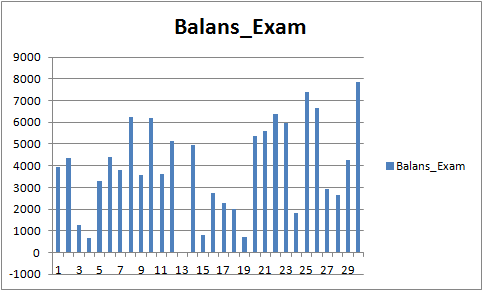
Fig. 9 "Resultado financiero de los modelos entrenados en el periodo del 01.08.2019 al 31.10.2020"
Análisis de predictores
En cada directorio del modelo (en el caso del autor, MQL5\Files\CB_Stat_03p50Q\Rezultat\RS_208\result_4_Test_CB_Setup_0_000000000) hay 3 archivos:
- Analiz_Train: análisis de la importancia de los predictores en la muestra de entrenamiento
- Analiz_Test: análisis de la importancia de los predictores en la muestra de prueba (validación)
- Analiz_Exam: análisis de la importancia de los predictores en la muestra de examen (fuera del entrenamiento)
Dependiendo de los ajustes seleccionados para el "Método de análisis del modelo" al generar los archivos para el entrenamiento, el contenido será distinto; tenga en cuenta el contenido al realizar la configuración de "PredictionValuesChange".
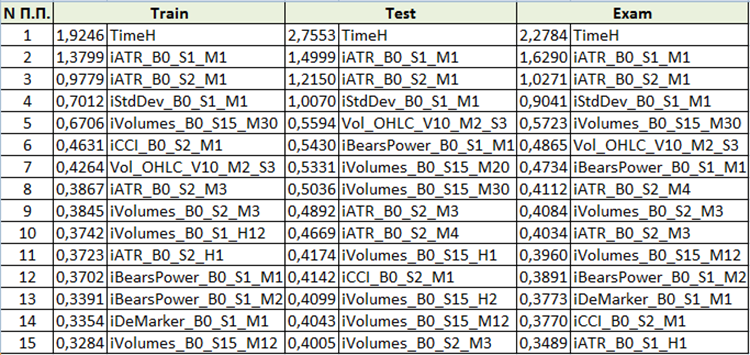
Fig. 10 "Recuadro resumido del análisis de significación de los predictores"
Partiendo de la evaluación de la importancia de los predictores, podemos deducir que los primeros 4 predictores son consistentemente importantes para el modelo resultante. Debemos notar que la importancia de los predictores depende no solo del propio modelo, sino también de la muestra a la que se aplica. Al fin y al cabo, si un predictor no ha tenido suficientes valores en la muestra que permitan surgir una bifuración al construir el árbol, no se podrá valorar objetivamente. Este método resulta adecuado para comprender aproximadamente la importancia de los predictores, pero debemos tener cuidado con él al trabajar con selecciones basadas en instrumentos comerciales.
Resumiendo
- Los métodos de aprendizaje de máquinas como la potenciación del gradiente, no pueden ser menos efectivos que la iteración interminable de parámetros y la creación manual de condiciones comerciales adicionales para mejorar el rendimiento de una estrategia.
- Los indicadores ofrecidos por MetaTrader 5 pueden resultar útiles para el aprendizaje de máquinas.
- CatBoost es una biblioteca de calidad que posee un envoltorio propio que permite utilizar de manera efectiva la potenciación del gradiente sin estudiar Python y R.
Epílogo
En este artículo, hemos intentado atraer el interés del lector hacia el aprendizaje de máquinas. Esperamos que después de describir detalladamente la metodología y ofrecer herramientas para su reproducción, surjan nuevos entusiastas del aprendizaje de máquinas. Proponemos al lector que se una a nosotros para buscar nuevas ideas en esta dirección, incluyendo la búsqueda de predictores, pues no tenemos que olvidar que la calidad de un modelo depende de los datos de entrada y de la función objetivo, y sumar esfuerzos en su búsqueda le permitirá alcanzar rápidamente el resultado deseado.
El autor admitirá gustoso cualquier observación sobre posibles errores, tanto en el artículo como en el código.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/8657
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 ¿Qué son las tendencias y cómo es la estructura de los mercados: de tendencia o plana?
¿Qué son las tendencias y cómo es la estructura de los mercados: de tendencia o plana?
 Gradient boosting (CatBoost) en las tareas de construcción de sistemas comerciales. Un enfoque ingenuo
Gradient boosting (CatBoost) en las tareas de construcción de sistemas comerciales. Un enfoque ingenuo
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Si tuviera que aplicar esto a un EA diferente, entonces ¿simplemente aplica el modelo catboost antes de que se coloque la orden y deja todo lo demás igual, o necesita modificar el model_CB() , o copy_arhiv()? No parece estar abriendo órdenes cuando se aplica el modelo CB.
Puedes añadir o cambiar la señal de entrada en la función Signal().
¿Ha entrenado el modelo CatBoost?
Si lo has hecho todo bien, debería funcionar.
Sí, he entrenado el modelo. ¿Qué pasa si el EA cierra, reduce o invierte posiciones en la señal opuesta, quieres filtrarlas usando el modelo o simplemente filtrar las nuevas órdenes de apertura?
Sí, he entrenado el modelo. ¿Qué pasa si el EA cierra, reduce o invierte posiciones en la señal opuesta, quieres filtrarlas usando el modelo o simplemente filtrar las nuevas órdenes de apertura?
No entendí el pensamiento: " ¿quieres filtrar las que utilizan el modelo ".
Con la ayuda del modelo se filtran las señales para abrir una posición en el artículo.
No entendí el pensamiento: " ¿quieres filtrar los que utilizan el modelo ".
Con la ayuda del modelo se filtran las señales para abrir una posición en el artículo.
Tu si tu EA tiene una señal contraria puede cerrar órdenes. Si en boost teóricamente puede reducir las señales falsas. Ellos si la señal contraria cierra órdenes, entonces catboost reduciría las órdenes falsas de cerrar y el resultado sería que dejas las órdenes abiertas más tiempo y se consiguen mayores beneficios. Por ejemplo. Usted coloca una orden cuando su MA cruza. su stoploss es de 50 pips y el TP es de 50. Sin embargo, la MA vuelve a cruzar antes de que usted llegue a su SL o TP, y su EA está programado para cerrar la orden si esto ocurre: esto se conoce como cerrar (o reducir, o invertir) en la señal opuesta. Ahora bien, si esa señal era una falsa alarma, entonces usted cierra su beneficio demasiado pronto, cuando podría haber subido a su TP en su lugar. Entonces, ¿Catboost podría haber filtrado un cierto porcentaje de esas señales falsas? Esta es mi pregunta. No todos los EA cierran posiciones en la señal contraria. Muchos sólo tienen un Sl y TP fijos. Por eso hice esta pregunta, porque algunos EA tienen esta funcionalidad.
Su si su EA tiene una señal opuesta puede cerrar órdenes. Si en boost teóricamente puede reducir las señales falsas. Ellos si la señal opuesta cierra órdenes, entonces catboost reduciría las órdenes falsas de cierre y el resultado sería que usted deja órdenes abiertas más tiempo y se logra un mayor beneficio. Por ejemplo. Usted coloca una orden cuando su MA cruza. su stoploss es de 50 pips y el TP es de 50. Sin embargo, la MA vuelve a cruzar antes de que usted llegue a su SL o TP, y su EA está programado para cerrar la orden si esto ocurre: esto se conoce como cerrar (o reducir, o invertir) en la señal opuesta. Ahora bien, si esa señal era una falsa alarma, entonces usted cierra su beneficio demasiado pronto, cuando podría haber subido a su TP en su lugar. Entonces, ¿Catboost podría haber filtrado un cierto porcentaje de esas señales falsas? Esta es mi pregunta. No todos los EA cierran posiciones en la señal contraria. Muchos sólo tienen un Sl y TP fijos. Por eso hice esta pregunta, porque algunos EA tienen esta funcionalidad.
Entendí de que se trataba la conversación.
Programáticamente, es fácil de implementar, pero será un juego con la aleatoriedad. El hecho es que el índice Recall en los modelos es bastante bajo, es decir, el modelo no reconoce más del 10% de todos los eventos, lo que significa que la posición contraria a menudo no se abre debido a un patrón no identificado. Esto está relacionado, entre otras cosas, con los predictores. El artículo muestra el algoritmo de aplicación de los modelos CatBoost. Es necesario reforzar el modelo con predictores, entonces su enfoque propuesto estará más justificado.