Artikel über Datenanalyse und Statistik in MQL5
Artikel über mathematische Modelle und die Gesetze der Wahrscheinlichkeit können für viele Börsenhändler interessant sein. Denn Mathematik liegt technischer Indikatoren zugrunde, und Kenntnisse in Statistik braucht man, um die Ergebnisse des Handels zu analysieren und Strategien zu entwickeln.
Lesen Sie über die Fuzzylogik, digitale Filter, Marktprofil, Kohonenkarten, neuronales Gas und andere Werkzeuge, die man für den Handel verwenden kann.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Monte Carlo Permutationstests im MetaTrader 5
In diesem Artikel sehen wir uns an, wie wir Permutationstests auf der Grundlage von vermischten Tick-Daten für jeden Expert Advisor durchführen können, der nur Metatrader 5 verwendet.

Zeitreihen in der Bibliothek DoEasy (Teil 36): Objekt der Zeitreihe für alle verwendeten Symbolperioden
In diesem Artikel werden wir uns überlegen, die Listen der Bar-Objekte für jede verwendete Symbolperiode zu einem einzigen Symbol-Zeitreihen-Objekt zusammenzufassen. Auf diese Weise wird jedes Symbol ein Objekt haben, das die Listen aller verwendeten Symbolzeitreihen-Perioden speichert.

Datenwissenschaft und maschinelles Lernen (Teil 06): Gradientenverfahren
Der Gradientenverfahren spielt eine wichtige Rolle beim Training neuronaler Netze und vieler Algorithmen des maschinellen Lernens. Es handelt sich um einen schnellen und intelligenten Algorithmus, der trotz seiner beeindruckenden Arbeit von vielen Datenwissenschaftlern immer noch missverstanden wird - sehen wir uns an, worum es geht.

Datenkennzeichnung für Zeitreihenanalyse (Teil 2): Datensätze mit Trendmarkern mit Python erstellen
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!
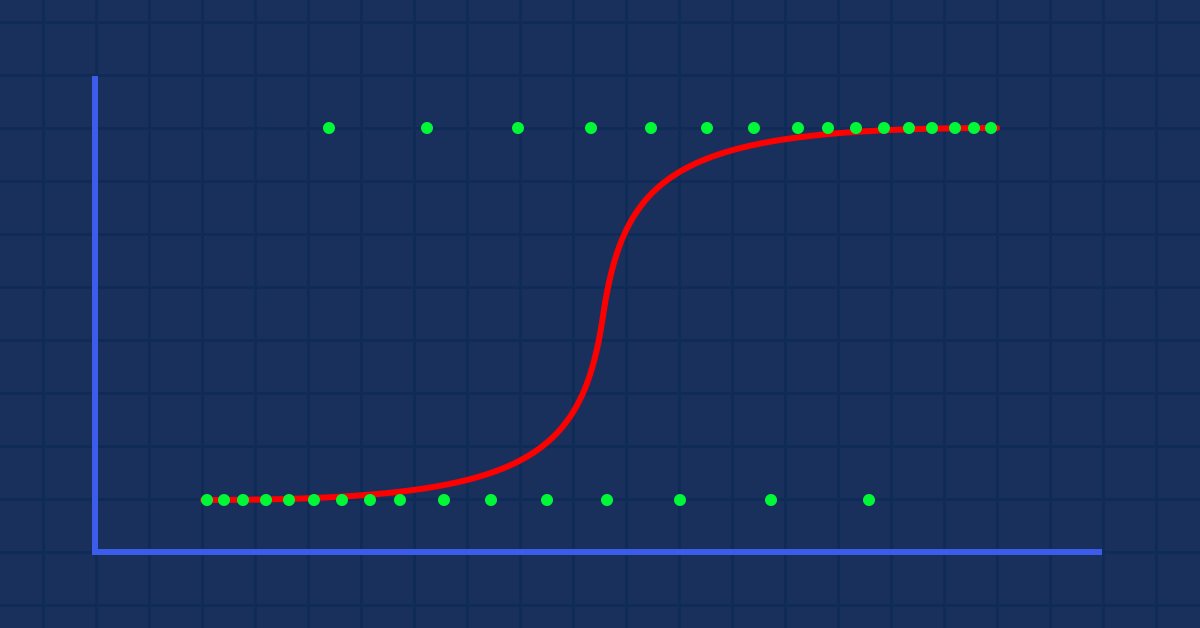
Datenwissenschaft und maschinelles Lernen (Teil 02): Logistische Regression
Die Klassifizierung von Daten ist für einen Algo-Händler und einen Programmierer von entscheidender Bedeutung. In diesem Artikel werden wir uns auf einen logistischen Klassifizierungsalgorithmus konzentrieren, der uns wahrscheinlich helfen kann, die Ja- oder Nein-Stimmen, die Höhen und Tiefen, Käufe und Verkäufe zu identifizieren.

Neuronale Netze leicht gemacht (Teil 21): Variierter Autoencoder (VAE)
Im letzten Artikel haben wir uns mit dem Algorithmus des Autoencoders vertraut gemacht. Wie jeder andere Algorithmus hat auch dieser seine Vor- und Nachteile. In seiner ursprünglichen Implementierung wird der Autoencoder verwendet, um die Objekte so weit wie möglich von der Trainingsstichprobe zu trennen. Dieses Mal werden wir darüber sprechen, wie man mit einigen ihrer Nachteile umgehen kann.
Zeitreihen in der Bibliothek DoEasy (Teil 48): Mehrperioden-Multisymbol-Indikatoren mit einem Puffer in einem Unterfenster
Der Artikel betrachtet ein Beispiel für die Erstellung von Mehrsymbol- und Mehrperioden-Standardindikatoren unter Verwendung eines einzigen Indikator-Puffers für die Konstruktion und die Darstellung im Indikator-Unterfenster. Ich werde die Bibliotheksklassen auf die Arbeit mit Standardindikatoren vorbereiten, die im Hauptfenster des Programms arbeiten und mehr als einen Puffer für die Anzeige ihrer Daten haben.
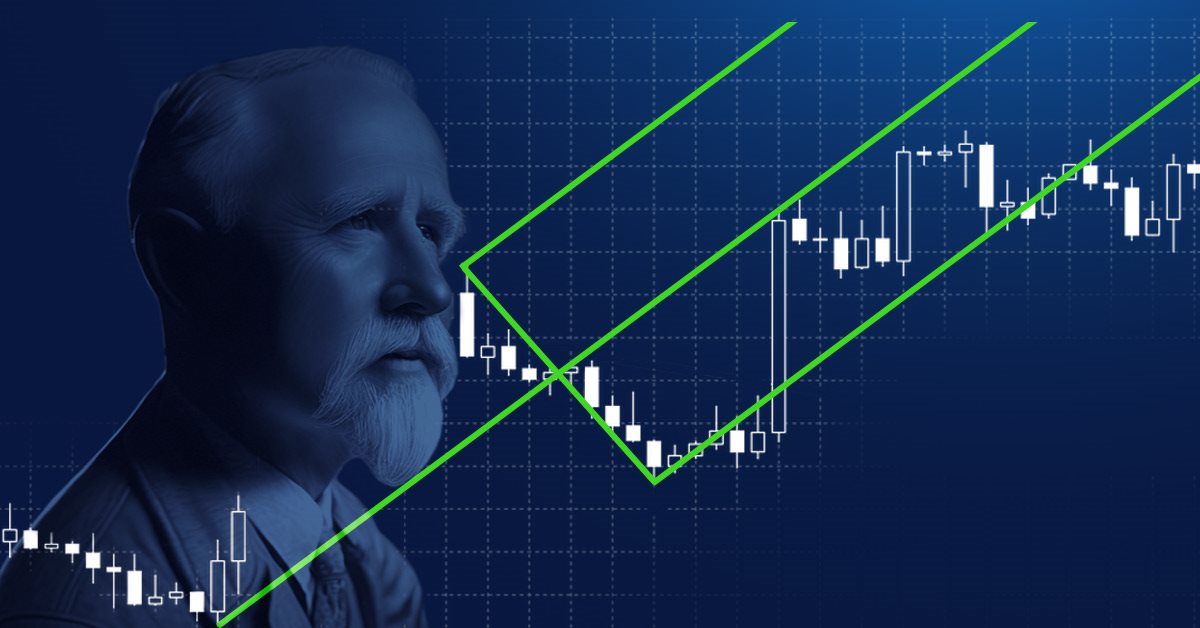
Alan Andrews und seine Methoden der Zeitreihenanalyse
Alan Andrews ist einer der berühmtesten „Ausbilder“ der modernen Welt auf dem Gebiet des Handels. Seine „pitchfork“ (Heugabel) ist in fast allen modernen Kursanalyseprogrammen enthalten. Doch die meisten Händler nutzen nicht einmal einen Bruchteil der Möglichkeiten, die dieses Instrument bietet. Im Übrigen enthält der ursprüngliche Lehrgang von Andrews nicht nur eine Beschreibung der Heugabel (obwohl sie das Hauptwerkzeug bleibt), sondern auch einiger anderer nützlicher Konstruktionen. Der Artikel gibt einen Einblick in die wunderbaren Methoden der Chartanalyse, die Andrews in seinem ursprünglichen Kurs lehrte. Achtung, es wird viele Bilder geben.

Kometenschweif-Algorithmus (CTA)
In diesem Artikel befassen wir uns mit der Optimierungsalgorithmus nach dem Kometenschweif (Comet Tail Optimization Algorithm, CTA), der sich von einzigartigen Weltraumobjekten inspirieren lässt - von Kometen und ihren beeindruckenden Schweifen, die sich bei der Annäherung an die Sonne bilden. Der Algorithmus basiert auf dem Konzept der Bewegung von Kometen und ihren Schweifen und ist darauf ausgelegt, optimale Lösungen für Optimierungsprobleme zu finden.

Techniken des MQL5-Assistenten, die Sie kennen sollten (Teil 01): Regressionsanalyse
Der Händler von heute ist ein Philomath, der fast immer (entweder bewusst oder unbewusst...) nach neuen Ideen sucht, sie ausprobiert, sich entscheidet, sie zu modifizieren oder zu verwerfen; ein explorativer Prozess, der einiges an Sorgfalt kosten sollte. Dies legt eindeutig einen hohen Stellenwert auf die Zeit des Händlers und die Notwendigkeit, Fehler zu vermeiden. Diese Artikelserie wird vorschlagen, dass der MQL5-Assistent eine Hauptstütze für Händler sein sollte. Warum? Denn der Händler spart nicht nur Zeit, indem er seine neuen Ideen mit dem MQL5-Assistenten zusammenstellt, und reduziert Fehler durch doppelte Codierung erheblich. Er ist letztendlich so eingestellt, dass er seine Energie auf die wenigen kritischen Bereiche seiner Handelsphilosophie konzentriert.
Andere Klassen in der Bibliothek DoEasy (Teil 70): Erweiterte Funktionalität und automatisches Aktualisieren der Kollektion der Chartobjekte
In diesem Artikel werde ich die Funktionalität von Chartobjekten erweitern und die Navigation durch Charts, die Erstellung von Screenshots sowie das Speichern und Anwenden von Vorlagen auf Charts einrichten. Außerdem werde ich die automatische Aktualisierung der Kollektion von Chartobjekten, ihrer Fenster und der Indikatoren darin implementieren.

MQL5 Market - Ergebnisse für Q2/2013
MQL5 Market, bereits seit 18 Monaten erfolgreich, ist zum größten Platz für Handelsstrategien und technische Indikatoren für Händler geworden. Dort findet man ca. 800 Handels-Anwendungen von 350 Entwicklern aus der ganzen Welt. Viele Händler haben bereits mehr als 100.000 Handelsprogramme gekauft und auf ihre MetaTrader 5 Terminals heruntergeladen.
Andere Klassen in der Bibliothek DoEasy (Teil 69): Kollektionsklasse der Chart-Objekte
Mit diesem Artikel beginne ich die Entwicklung der Kollektionsklasse der Chart-Objekt. Die Klasse wird die Kollektionsliste der Chart-Objekte mit ihren Unterfenstern und Indikatoren speichern und die Möglichkeit bieten, mit beliebigen ausgewählten Charts und ihren Unterfenstern oder mit einer Liste von mehreren Charts gleichzeitig zu arbeiten.

Zeitreihen in der Bibliothek DoEasy (Teil 55): Die Kollektionsklasse der Indikatoren
Der Artikel setzt die Entwicklung von Objektklassen für die Indikatoren und deren Kollektionen fort. Für jedes Indikatorobjekt erstellen wir seine Beschreibung und die richtige Kollektionsklasse für die fehlerfreie Speicherung und das Abrufen von Indikatorobjekten aus der Kollektionsliste.

Das Preisbewegungsmodell und seine wichtigsten Bestimmungen (Teil 2): Probabilistische Preisfeldentwicklungsgleichung und das Auftreten des beobachteten Random Walk
Der Artikel befasst sich mit der probabilistischen Preisfeldentwicklungsgleichung und dem Kriterium der bevorstehenden Preisspitzen. Sie zeigt auch das Wesen der Preiswerte auf den Charts und den Mechanismus für das Auftreten eines Random Walk dieser Werte.

Algorithmen zur Optimierung mit Populationen: Der Algorithmus intelligenter Wassertropfen (IWD)
Der Artikel befasst sich mit einem interessanten, von der unbelebten Natur abgeleiteten Algorithmus - intelligente Wassertropfen (IWD), die den Prozess der Flussbettbildung simulieren. Die Ideen dieses Algorithmus ermöglichten es, den bisherigen Spitzenreiter der Bewertung - SDS - deutlich zu verbessern. Der neue Führende (modifizierter SDSm) befindet sich wie üblich im Anhang.

Modifizierter Grid-Hedge EA in MQL5 (Teil II): Erstellung eines einfachen Grid EA
In diesem Artikel wird die klassische Rasterstrategie untersucht, ihre Automatisierung mit einem Expert Advisor in MQL5 detailliert beschrieben und die ersten Backtest-Ergebnisse analysiert. Wir haben die Notwendigkeit einer hohen Haltekapazität für die Strategie hervorgehoben und Pläne für die Optimierung von Schlüsselparametern wie Abstand, TakeProfit und Losgrößen in zukünftigen Ausgaben skizziert. Die Reihe zielt darauf ab, die Effizienz der Handelsstrategien und die Anpassungsfähigkeit an unterschiedliche Marktbedingungen zu verbessern.

Datenkennzeichnung für Zeitreihenanalyse (Teil 1):Erstellen eines Datensatzes mit Trendmarkierungen durch den EA auf einem Chart
In dieser Artikelserie werden verschiedene Methoden zur Kennzeichnung von Zeitreihen vorgestellt, mit denen Daten erstellt werden können, die den meisten Modellen der künstlichen Intelligenz entsprechen. Eine gezielte und bedarfsgerechte Kennzeichnung von Daten kann dazu führen, dass das trainierte Modell der künstlichen Intelligenz besser mit dem erwarteten Design übereinstimmt, die Genauigkeit unseres Modells verbessert wird und das Modell sogar einen qualitativen Sprung machen kann!
Preise in der DoEasy-Bibliothek (Teil 63): Markttiefe und deren abstrakte Anforderungsklasse
In diesem Artikel werde ich mit der Entwicklung der Funktionalität für die Arbeit mit der Markttiefe (Depth of Market, DOM) beginnen. Ich werde auch die Klasse des abstrakten Objekts der Markttiefe und seine Nachkommen erstellen.

Neuronale Netze leicht gemacht (Teil 26): Reinforcement-Learning
Wir untersuchen weiterhin Methoden des Reinforcement-Learnings. Mit diesem Artikel beginnen wir ein weiteres großes Thema, das Reinforcement-Learning. Dieser Ansatz ermöglicht es den Modellen, bestimmte Strategien zur Lösung der Probleme zu entwickeln. Es ist zu erwarten, dass diese Eigenschaft des Reinforcement-Learnings (Lernen durch Verstärkung) neue Horizonte für die Entwicklung von Handelsstrategien eröffnen wird.
Preise in der DoEasy-Bibliothek (Teil 60): Listen von Serien mit Symbol-Tickdaten
In diesem Artikel werde ich eine Liste zur Speicherung von Tickdaten eines einzelnen Symbols erstellen und deren Erstellung und Abruf der benötigten Daten in einem EA überprüfen. Tickdatenlisten, die für jedes verwendete Symbol individuell sind, werden weiterhin eine Kollektion von Tickdaten darstellen.

Anwendung von OLAP im Handel (Teil 4): Quantitative und visuelle Analyse der Testberichte
Der Artikel bietet grundlegende Werkzeuge für die OLAP-Analyse von Testberichten in Bezug auf einzelne Durchläufe und Optimierungsergebnisse. Das Werkzeug kann mit Dateien im Standardformat (tst und opt) arbeiten und bietet auch eine grafische Schnittstelle. MQL-Quellcodes sind unten angefügt.

Datenwissenschaft und maschinelles Lernen (Teil 04): Vorhersage des aktuellen Börsenkrachs
In diesem Artikel werde ich versuchen, unser logistisches Modell zu verwenden, um den Börsencrash auf der Grundlage der Fundamentaldaten der US-Wirtschaft vorherzusagen. NETFLIX und APPLE sind die Aktien, auf die wir uns konzentrieren werden, wobei wir die früheren Börsencrashs von 2019 und 2020 nutzen werden, um zu sehen, wie unser Modell in der aktuellen Krise abschneiden wird.

Das Preisbewegungsmodell und seine wichtigsten Aspekte. (Teil 3): Berechnung der optimalen Parameter des Börsenhandels
Im Rahmen des vom Autor entwickelten technischen Ansatzes, der auf der Wahrscheinlichkeitstheorie basiert, werden die Bedingungen für die Eröffnung einer profitablen Position gefunden und die optimalen (gewinnmaximierenden) Take-Profit- und Stop-Loss-Werte berechnet.

Entwicklung eines Replay-Systems — Marktsimulation (Teil 05): Hinzufügen einer Vorschau
Es ist uns gelungen, einen Weg zu finden, das Replay-System (Marktwiederholungssystem) auf realistische und zugängliche Weise umzusetzen. Lassen Sie uns nun unser Projekt fortsetzen und Daten hinzufügen, um das Wiedergabeverhalten zu verbessern.

Wer ist wer in der MQL5.community?
Die Webseite MQL5.com vergisst nichts und niemanden! Wie viele Abschlüsse legendär geworden sind, welcher Beliebtheit sich die einzelnen Artikel erfreuen, und wie oft die in der Codedatenbank gespeicherten Programme heruntergeladen wurden, all das ist nur ein kleiner Teil dessen, was MQL5.com nicht vergisst. In den Profilen werden die Errungenschaften jedes Einzelnen aufbewahrt, aber wie sieht das Gesamtbild aus? Dieser Beitrag soll eine Gesamtübersicht über die Leistungen aller Mitglieder der MQL5.community zeigen.
Zeitreihen in der Bibliothek DoEasy (Teil 44): Kollektionsklasse der Objekte von Indikatorpuffern
Der Artikel befasst sich mit der Erstellung einer Kollektionsklasse der Objekte von Indikatorpuffern. Ich werde die Fähigkeit testen, eine beliebige Anzahl von Puffern für Indikatoren zu erstellen und mit ihnen zu arbeiten (die maximale Anzahl von Indikatorpuffern, die in MQL erstellt werden können, beträgt 512).
Zeitreihen in der Bibliothek DoEasy (Teil 59): Objekt zum Speichern der Daten eines Ticks
Ab diesem Artikel beginnen wir mit der Erstellung von Bibliotheksfunktionen für die Arbeit mit Preisdaten. Heute erstellen wir eine Objektklasse, die alle Preisdaten speichert, die mit einem weiteren Tick angekommen sind.

Neuronale Netze leicht gemacht (Teil 17): Reduzierung der Dimensionalität
In diesem Teil setzen wir die Diskussion über die Modelle der Künstlichen Intelligenz fort. Wir untersuchen vor allem Algorithmen für unüberwachtes Lernen. Wir haben bereits einen der Clustering-Algorithmen besprochen. In diesem Artikel stelle ich eine Variante zur Lösung von Problemen im Zusammenhang mit der Dimensionsreduktion vor.

Datenwissenschaft und maschinelles Lernen (Teil 25): Forex-Zeitreihenvorhersage mit einem rekurrenten neuronalen Netzwerk (RNN)
Rekurrente neuronale Netze (RNNs) zeichnen sich dadurch aus, dass sie Informationen aus der Vergangenheit nutzen, um zukünftige Ereignisse vorherzusagen. Ihre bemerkenswerten Vorhersagefähigkeiten wurden in verschiedenen Bereichen mit großem Erfolg eingesetzt. In diesem Artikel werden wir RNN-Modelle zur Vorhersage von Trends auf dem Devisenmarkt einsetzen und ihr Potenzial zur Verbesserung der Vorhersagegenauigkeit beim Devisenhandel aufzeigen.

Hilfen zur Auswahl und Navigation in MQL5 und MQL4: Tabs für "Hausaufgaben" und das Sichern grafischer Objekte
In diesem Artikel werden wir die Fähigkeiten des zuvor erstellten Hilfsprogramms erweitern, indem wir Tabs (Registerkarten) zur Auswahl der benötigten Symbole hinzufügen. Wir werden auch lernen, wie man grafische Objekte, die wir erstellt haben, auf dem spezifischen Symboldiagramm speichert, damit wir sie nicht ständig neu erstellen müssen. Außerdem erfahren wir, wie man nur mit Symbolen arbeitet, die zuvor über eine bestimmte Website ausgewählt wurden.

Algorithmen zur Optimierung mit Populationen Künstliches Bienenvolk (Artificial Bee Colony, ABC)
In diesem Artikel werden wir den Algorithmus eines künstlichen Bienenvolkes untersuchen und unser Wissen durch neue Prinzipien zur Untersuchung funktionaler Räume ergänzen. In diesem Artikel werde ich meine Interpretation der klassischen Version des Algorithmus vorstellen.

Python, ONNX und MetaTrader 5: Erstellen eines RandomForest-Modells mit RobustScaler und PolynomialFeatures zur Datenvorverarbeitung
In diesem Artikel werden wir ein Random-Forest-Modell in Python erstellen, das Modell trainieren und es als ONNX-Pipeline mit Datenvorverarbeitung speichern. Danach werden wir das Modell im MetaTrader 5 Terminal verwenden.
Berg- oder Eisbergdiagramme
Was halten Sie von der Idee, der MetaTrader 5-Plattform einen neuen Chart-Typ hinzuzufügen? Einige Leute sagen, dass es an einigen Dingen mangelt, die andere Plattformen bieten. Aber die Wahrheit ist, dass MetaTrader 5 eine sehr praktische Plattform ist, da sie Ihnen Dinge ermöglicht, die auf vielen anderen Plattformen nicht (oder zumindest nicht ohne weiteres) möglich sind.

Wie man ein zyklusbasiertes Handelssystem aufbaut und optimiert (Detrended Price Oscillator – DPO)
Dieser Artikel erklärt, wie man ein Handelssystem mit dem Detrended Price Oscillator (DPO) in MQL5 entwickelt und optimiert. Er umreißt die Kernlogik des Indikators und zeigt, wie er kurzfristige Zyklen erkennt, indem er langfristige Trends herausfiltert. Anhand einer Reihe von Schritt-für-Schritt-Beispielen und einfachen Strategien lernen die Leser, wie man den Code erstellt, Ein- und Ausstiegssignale definiert und Backtests durchführt. Schließlich werden praktische Optimierungsmethoden vorgestellt, um die Leistung zu verbessern und das System an die sich ändernden Marktbedingungen anzupassen.

Neuronale Netze leicht gemacht (Teil 19): Assoziationsregeln mit MQL5
Wir fahren mit der Besprechung von Assoziationsregeln fort. Im vorigen Artikel haben wir den theoretischen Aspekt dieser Art von Problemen erörtert. In diesem Artikel werde ich die Implementierung der FP Growth-Methode mit MQL5 zeigen. Außerdem werden wir die implementierte Lösung anhand realer Daten testen.

Von der Saisonalität des Devisenmarktes profitieren
Wir sind alle mit dem Konzept der Saisonalität vertraut, z. B. sind wir alle an steigende Preise für frisches Gemüse im Winter oder an steigende Kraftstoffpreise bei strengem Frost gewöhnt, aber nur wenige Menschen wissen, dass es auf dem Devisenmarkt ähnliche Muster gibt.

Die diskrete Hartley-Transformation
In diesem Artikel werden wir eine der Methoden der Spektralanalyse und Signalverarbeitung betrachten - die diskrete Hartley-Transformation. Es ermöglicht die Filterung von Signalen, die Analyse ihres Spektrums und vieles mehr. Die Möglichkeiten der DHT stehen denen der diskreten Fourier-Transformation in nichts nach. Im Gegensatz zur DFT werden bei der DHT jedoch nur reelle Zahlen verwendet, was die Umsetzung in der Praxis erleichtert, und die Ergebnisse der Anwendung sind anschaulicher.
Zeitreihen in der Bibliothek DoEasy (Teil 53): Abstrakte Basisklasse der Indikatoren
Der Artikel beschäftigt sich mit dem Erstellen eines abstrakten Indikators, der im Weiteren als Basisklasse für die Erstellung von Objekten der Standard- und nutzerdefinierten Indikatoren der Bibliothek verwendet wird.
Preise in der DoEasy-Bibliothek (Teil 61): Kollektion der Tickserien eines Symbols
Da ein Programm bei seiner Arbeit verschiedene Symbole verwenden kann, sollte für jedes dieser Symbole eine eigene Liste erstellt werden. In diesem Artikel werde ich solche Listen zu einer Tickdatenkollektion zusammenfassen. In der Tat wird dies eine reguläre Liste sein, die auf der Klasse des dynamischen Arrays von Zeigern auf Instanzen der Klasse CObject und ihrer Nachkommen der Standardbibliothek basiert.