ニューラルネットワークが簡単に(第10回): Multi-Head Attention

目次
- はじめに
- 1. Multi-Head Attention
- 2. 数学について少し
- 3. 位置エンコーディング
- 4. 実装
- 4.1. Keysテンソルの排除
- 4.2. Multi-Head Attentionクラス
- 4.3. フィードフォワード(予測制御)
- 4.4. フィードバックワード
- 4.5. ニューラルネットワーク基本クラスの変更
- 5. テスト
- 終わりに
- 参照文献
- 記事で使用されたプログラム
はじめに
「ニューラルネットワークが簡単に(第8回): アテンションメカニズム」稿では、自己注意メカニズムとその実装の変形について検討しました。実際には、最新のニューラルネットワークアーキテクチャはMulti-Head Attentionを使用しています。このメカニズムは、異なる重みを持つ複数の並列自己注意スレッドの起動を意味します。このようなソリューションでは、シーケンスのさまざまな要素間の接続がより明らかになるはずです。同様のアーキテクチャを実装して、これら2つの方法の結果を比較してみましょう。
1. Multi-Head Attention
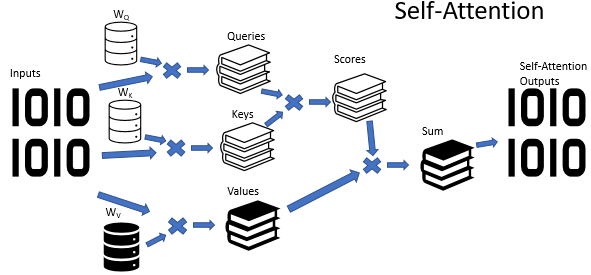
Self-Attentionアルゴリズムでは、3つの訓練済み重み行列(Wq、Wk、Wv)を使用します。行列データはQuery、Key、Valueの3つのエンティティを取得するために使用されます。最初の2つのエンティティはシーケンスの要素間を組とした関係を定義し、最後のエンティティは分析された要素のコンテキストを定義します。
状況が必ずしも明確であるとは限らないことは周知の事実です。それどころか、ほとんどの場合、状況はさまざまな観点から解釈できるようです。したがって、選択した視点によっては、結論が完全に反対になる可能性があります。このような状況で考えられるすべてのバリエーションを検討し、慎重に分析した後でのみ決定を下すことが重要です。Multi-Head Attentionメカニズムはこのような問題を解決するために提案されています。それぞれの「頭」には独自の意見がありますが、決定はバランスの取れた投票によって行われます。
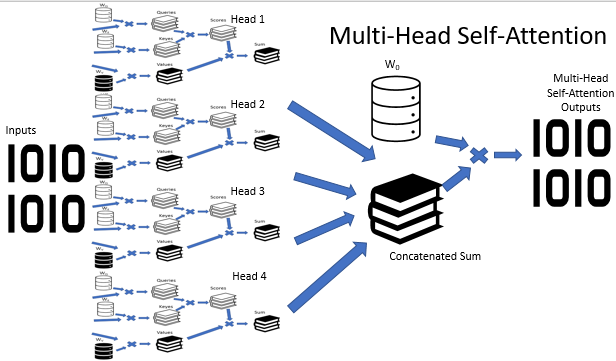
Multi-Head Attentionアーキテクチャは、異なる重みを持つ複数のSelf-Attentionスレッドを並行して使用することを意味し、状況の多様な分析を模倣します。自己注意スレッドの操作の結果は、単一のテンソルに連結されます。アルゴリズムの最終結果は、テンソルにW0行列を乗算することによって求められます。この行列のパラメータは、ニューラルネットワークの訓練プロセス中に選択されます。アーキテクチャ全体が、TransformerアーキテクチャのエンコーダおよびデコーダのSelf-Attentionブロックに置き換わります。
2. 数学について少し
次の式はSelf-Attentionアルゴリズムの数学的記述を提供できます。
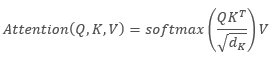 ,
,
ここで、「Q」はQueryテンソル、「K」はKeyテンソル、「V」はValuesテンソル、「d」は1つのkeyベクトルの次元です。
次に
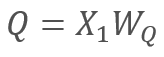 また
また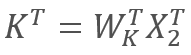 、
、
ここで、X1とX2はシーケンスの要素です。 WqとWkは、それぞれQueriesとKeysの重みの行列です。したがって、次のようになります。
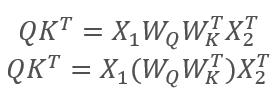
行列の結合法則により、最初に重み行列WqとWkを乗算できます。ご覧のとおり、重み行列の積は入力シーケンスに依存せず、特定のSelf-Attentionブロックのすべての反復で同じです(もちろん、これは行列パラメータが次に更新されるまで当てはまります)。したがって、計算操作を減らすために、特定のアプローチに対して中間行列を1回計算して他の計算に使用できます。
さらに、2つではなく1つの行列を訓練することもできます。ただし、不思議なことに、1つの行列だけを訓練するだけで操作の数を減らすことが常に可能であるとは限りません。たとえば、入力シーケンスベクトルの次元が大きい場合、次元は行列WqおよびWkによって縮小できます。この場合、入力ベクトルX1とX2の長さが100要素の場合、単一の行列には10K要素(100*100)が含まれます。次元が行列WqとWkによって10分の1に縮小されると、それぞれが1K要素(100*10)を持つ2つの行列になります。したがって、ネットワークのパフォーマンスとその操作結果の品質を考慮して、ソリューションを慎重に選択する必要があります。
3. 位置エンコーディング
また、時系列を使用するときは、シーケンス内の要素間の距離に注意してください。アテンションアルゴリズムは、シーケンスのすべての要素に同じ行列を使用して、シーケンスの要素間の依存関係のペアワイズ検証を実行します。同時に、時系列要素の相互影響は、それらの間の時間間隔に強く依存します。したがって、もう1つの重要な問題は、位置コーディングアルゴリズムの追加です。
理想的な位置コーディングアルゴリズムは、いくつかの基準を満たす必要があります。
- シーケンスの各要素は一意のコードを受け取る必要がある
- 2つの連続する要素間のステップは一定でなければなりない
- 任意の長さのシーケンスに対してモデルを簡単に調整および一般化できる必要がある
- モデルは決定論的でなければならない
Transformerアーキテクチャの作成者は、シーケンスをエンコードするために個別の要素ではなく、入力シーケンス要素の次元と等しい次元を持つベクトル全体を使用することを提案しました。ここでは、正弦はベクトルの偶数要素を表すために使用され、余弦は奇数要素を表すために使用されます。シーケンス要素は特定の配列要素ではなく、別の位置の状態を表すベクトルであることに注意してください。ここでの場合、それは1つのローソク足を表すベクトルです。
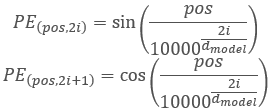 ,
,
ここで、「pos」はシーケンス要素の位置、「i」は1つの位置要素のベクトル内の要素の位置、「d」は 1つのシーケンス要素のベクトルの次元です。
このソリューションでは、シーケンスの各要素の位置を設定したり、要素間の距離を決定したりできます。
Transformerアーキテクチャでは直接的には、位置コーディングはその範囲外です。これは、最初のエンコーダにデータを入力する前に、入力シーケンステンソルに位置コーディングテンソルを追加することによって実行されます。2つの疑問が発生します。
- ベクトル連結の代わりに加算する理由
- テンソルを追加すると元のデータがどの程度歪むが
連結すると、データディメンションが増加するため、反復回数が増加します。これにより、システムの全体的なパフォーマンスが低下します。このようなソリューションの第2の側面は、ベクトルを追加することで、個々のシーケンス要素のベクトルだけでなく、ベクトルの各要素も配置できることです。仮定的に、これによって、シーケンスの要素間だけでなくそれらの個々のコンポーネント間の依存関係の分析が可能になります。
データの歪みに関しては、ニューラルネットワークは各要素の意味について何も知らず、エンコードが追加されたデータで訓練されます。つまり、各要素とその位置を個別に分析することはありません。たとえば、2番目と20番目の位置に同じ同事線が表示されている場合、私たちはおそらく最も近い同事線を優先しますが、位置コーディングを使用するニューラルネットワークの場合、これらは完全に異なる信号であり、取引中に蓄積されたデータに従って処理されます。
4. 実装
上記のソリューションの実装について考えてみましょう。Self-Attentionアルゴリズムの以前の実装では、QueriesとKeysのベクトルに使用される次元は入力シーケンスと同様でした。したがって、まず、1つの行列を訓練するためのアルゴリズムを再構築しました。
4.1. Keysテンソルの排除
実用的な解決策は非常に簡単です。CNeuronAttentionOCL::feedForwardメソッドで、Key畳み込み層の同様のメソッドの呼び出しをコメントアウトしました 。また、Score計算カーネル呼び出しで、Key畳み込み層を前のニューラル層に置き換えました。メソッドコードの変更は、以下で強調表示されています。
bool CNeuronAttentionOCL::feedForward(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=1; OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,prevLayer.getOutputIndex()); OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,prevLayer.Neurons()); if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Normalize: %d",GetLastError()); return false; } if(!prevLayer.Output.BufferRead()) return false; } //--- if(CheckPointer(Querys)==POINTER_INVALID || !Querys.FeedForward(prevLayer)) return false; //if(CheckPointer(Keys)==POINTER_INVALID || !Keys.FeedForward(prevLayer)) // return false; if(CheckPointer(Values)==POINTER_INVALID || !Values.FeedForward(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_score,Scores.GetIndex()); OpenCL.SetArgument(def_k_AttentionScore,def_k_as_dimension,iWindow); if(!OpenCL.Execute(def_k_AttentionScore,1,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionScore: %d",GetLastError()); return false; } if(!Scores.BufferRead()) return false; } //--- Further code has no changes
バックプロパゲーションメソッドCNeuronAttentionOCL::calcInputGradientsには同様の変更が実装されています。エラー勾配(error gradient)の最初の部分は前の層のバッファに先に書き込まれるため、勾配の蓄積プロセスが先に開始されることに注意してください。以下のコードでは、変更が強調表示されています。
bool CNeuronAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- if(!FF2.calcInputGradients(FF1)) return false; if(!FF1.calcInputGradients(AttentionOut)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,Gradient.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } //--- { uint global_work_offset[2]={0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iWindow; OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_gradient,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys_g,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys_g,Querys.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values,Values.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values_g,Values.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_scores,Scores.GetIndex()); if(!OpenCL.Execute(def_k_AttentionGradients,2,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionGradients: %d",GetLastError()); return false; } double temp[]; if(Querys.getGradient(temp)<=0) return false; } //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } //--- if(!Querys.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } ////--- // if(!Keys.calcInputGradients(prevLayer)) // return false; ////--- // { // uint global_work_offset[1]={0}; // uint global_work_size[1]; // global_work_size[0]=iUnits; // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); // OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); // OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); // if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) // { // printf("Error of execution kernel MatrixSum: %d",GetLastError()); // return false; // } // double temp[]; // if(AttentionOut.getGradient(temp)<=0) // return false; // } //--- Further code has no changes
また、CNeuronAttentionOCL::updateInputWeightsメソッドのKey畳み込み層の重みの更新と、このオブジェクトの一般的な宣言についてもコメントしました。
すべてのメソッドと関数の完全なコードは、添付ファイルにあります。
4.2. Multi-Head Attentionクラス
Multi-Head Attentionの構築は、CNeuronAttentionOCL親クラスに基づいて、別のCNeuronMHAttentionOCLクラスで実装されます。protectedブロックで、アテンションヘッドの数に応じて、畳み込み層のQuerysとValuesの追加インスタンスを宣言します。 この例では、4つのヘッドが使用されています。また、各アテンションヘッドにScoresバッファと完全に接続された AttentionOut層を追加します。さらに、アテンションヘッドからのデータを連結するための全結合層(AttentionConcatenate)と、模倣を可能にする畳み込み層Weights0が必要です。これにより、加重投票を模倣し、結果テンソルの次元を減らすことができます。
class CNeuronMHAttentionOCL : public CNeuronAttentionOCL { protected: CNeuronConvOCL *Querys2; ///< Convolution layer for Querys Head 2 CNeuronConvOCL *Querys3; ///< Convolution layer for Querys Head 3 CNeuronConvOCL *Querys4; ///< Convolution layer for Querys Head 4 CNeuronConvOCL *Values2; ///< Convolution layer for Values Head 2 CNeuronConvOCL *Values3; ///< Convolution layer for Values Head 3 CNeuronConvOCL *Values4; ///< Convolution layer for Values Head 4 CBufferDouble *Scores2; ///< Buffer for Scores matrix Head 2 CBufferDouble *Scores3; ///< Buffer for Scores matrix Head 3 CBufferDouble *Scores4; ///< Buffer for Scores matrix Head 4 CNeuronBaseOCL *AttentionOut2; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionOut3; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionOut4; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionConcatenate;///< Layer of Concatenate Self-Attention Out CNeuronConvOCL *Weights0; ///< Convolution layer for Weights0 //--- virtual bool feedForward(CNeuronBaseOCL *prevLayer); ///< Feed Forward method.@param prevLayer Pointer to previous layer. virtual bool updateInputWeights(CNeuronBaseOCL *prevLayer); ///< Method for updating weights.@param prevLayer Pointer to previous layer. /// Method to transfer gradients inside Head Self-Attention virtual bool calcHeadGradient(CNeuronConvOCL *query, CNeuronConvOCL *value, CBufferDouble *score, CNeuronBaseOCL *attention, CNeuronBaseOCL *prevLayer); public: /** Constructor */CNeuronMHAttentionOCL(void){}; /** Destructor */~CNeuronMHAttentionOCL(void); virtual bool Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl, uint window, uint units_count, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object.@param[in] window Size of in/out window and step.@param[in] units_countNumber of neurons.@param[in] optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolean result of operations. virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); ///< Method to transfer gradients to previous layer @param[in] prevLayer Pointer to previous layer. //--- virtual int Type(void) const { return defNeuronMHAttentionOCL; }///< Identificator of class.@return Type of class //--- methods for working with files virtual bool Save(int const file_handle); ///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle); ///< Load method @param[in] file_handle handle of file @return logical result of operation };
クラスメソッドのセットは、親クラスの仮想メソッドを書き換え、おそらく、すでに標準と呼ぶことができます。唯一の例外は、各ヘッドに対して繰り返されるエラー勾配伝播の反復を記述するcalcHeadGradientメソッドです。
クラスコンストラクタを空のままにして、新しいオブジェクトの初期化をInit初期化メソッドに移動します。クラスデストラクタで、このクラスによって作成され、protectedブロックで宣言されたオブジェクトインスタンスの削除を実装します。
CNeuronMHAttentionOCL::~CNeuronMHAttentionOCL(void) { if(CheckPointer(Querys2)!=POINTER_INVALID) delete Querys2; if(CheckPointer(Querys3)!=POINTER_INVALID) delete Querys3; if(CheckPointer(Querys4)!=POINTER_INVALID) delete Querys4; if(CheckPointer(Values2)!=POINTER_INVALID) delete Values2; if(CheckPointer(Values3)!=POINTER_INVALID) delete Values3; if(CheckPointer(Values4)!=POINTER_INVALID) delete Values4; if(CheckPointer(Scores2)!=POINTER_INVALID) delete Scores2; if(CheckPointer(Scores3)!=POINTER_INVALID) delete Scores3; if(CheckPointer(Scores4)!=POINTER_INVALID) delete Scores4; if(CheckPointer(Weights0)!=POINTER_INVALID) delete Weights0; if(CheckPointer(AttentionOut2)!=POINTER_INVALID) delete AttentionOut2; if(CheckPointer(AttentionOut3)!=POINTER_INVALID) delete AttentionOut3; if(CheckPointer(AttentionOut4)!=POINTER_INVALID) delete AttentionOut4; if(CheckPointer(AttentionConcatenate)!=POINTER_INVALID) delete AttentionConcatenate; }
Initメソッドは、親クラスのメソッドとの類似性によって構築されています。メソッドの先頭で、親クラスの関連するメソッドを呼び出します。
bool CNeuronMHAttentionOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint window,uint units_count,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronAttentionOCL::Init(numOutputs,myIndex,open_cl,window,units_count,optimization_type)) return false;
次に、Querys畳み込み層のインスタンスを初期化します。最初のヘッドのすべてのオブジェクトのインスタンスは親クラスで初期化されるため、2番目のヘッドからオブジェクトを初期化することに注意してください。
if(CheckPointer(Querys2)==POINTER_INVALID) { Querys2=new CNeuronConvOCL(); if(CheckPointer(Querys2)==POINTER_INVALID) return false; if(!Querys2.Init(0,6,open_cl,window,window,window,units_count,optimization_type)) return false; Querys2.SetActivationFunction(None); } //--- if(CheckPointer(Querys3)==POINTER_INVALID) { Querys3=new CNeuronConvOCL(); if(CheckPointer(Querys3)==POINTER_INVALID) return false; if(!Querys3.Init(0,7,open_cl,window,window,window,units_count,optimization_type)) return false; Querys3.SetActivationFunction(None); } //--- if(CheckPointer(Querys4)==POINTER_INVALID) { Querys4=new CNeuronConvOCL(); if(CheckPointer(Querys4)==POINTER_INVALID) return false; if(!Querys4.Init(0,8,open_cl,window,window,window,units_count,optimization_type)) return false; Querys4.SetActivationFunction(None); }
同様に、Valuesのクラスインスタンス、AttentionOutのScoresを初期化します。
if(CheckPointer(Values2)==POINTER_INVALID) { Values2=new CNeuronConvOCL(); if(CheckPointer(Values2)==POINTER_INVALID) return false; if(!Values2.Init(0,9,open_cl,window,window,window,units_count,optimization_type)) return false; Values2.SetActivationFunction(None); } //--- if(CheckPointer(Values3)==POINTER_INVALID) { Values3=new CNeuronConvOCL(); if(CheckPointer(Values3)==POINTER_INVALID) return false; if(!Values3.Init(0,10,open_cl,window,window,window,units_count,optimization_type)) return false; Values3.SetActivationFunction(None); } //--- if(CheckPointer(Values4)==POINTER_INVALID) { Values4=new CNeuronConvOCL(); if(CheckPointer(Values4)==POINTER_INVALID) return false; if(!Values4.Init(0,11,open_cl,window,window,window,units_count,optimization_type)) return false; Values4.SetActivationFunction(None); } //--- if(CheckPointer(Scores2)==POINTER_INVALID) { Scores2=new CBufferDouble(); if(CheckPointer(Scores2)==POINTER_INVALID) return false; } if(!Scores2.BufferInit(units_count*units_count,0.0)) return false; if(!Scores2.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(Scores3)==POINTER_INVALID) { Scores3=new CBufferDouble(); if(CheckPointer(Scores3)==POINTER_INVALID) return false; } if(!Scores3.BufferInit(units_count*units_count,0.0)) return false; if(!Scores3.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(Scores4)==POINTER_INVALID) { Scores4=new CBufferDouble(); if(CheckPointer(Scores4)==POINTER_INVALID) return false; } if(!Scores4.BufferInit(units_count*units_count,0.0)) return false; if(!Scores4.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(AttentionOut2)==POINTER_INVALID) { AttentionOut2=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut2)==POINTER_INVALID) return false; if(!AttentionOut2.Init(0,12,open_cl,window*units_count,optimization_type)) return false; AttentionOut2.SetActivationFunction(None); } //--- if(CheckPointer(AttentionOut3)==POINTER_INVALID) { AttentionOut3=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut3)==POINTER_INVALID) return false; if(!AttentionOut3.Init(0,13,open_cl,window*units_count,optimization_type)) return false; AttentionOut3.SetActivationFunction(None); } //--- if(CheckPointer(AttentionOut4)==POINTER_INVALID) { AttentionOut4=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut4)==POINTER_INVALID) return false; if(!AttentionOut4.Init(0,14,open_cl,window*units_count,optimization_type)) return false; AttentionOut4.SetActivationFunction(None); }
AttentionConcatenateデータ連結の層を初期化します。これは全結合層であり、データ送信にのみ使用されます。したがって、発信する接続の数は「0」に等しくなります。層のサイズは、4つのアテンションヘッドすべての出力データを格納するのに十分でなければなりません。シーケンス内の要素の数によって、1つのヘッドの出力層の4つのウィンドウの積に等しい層内のニューロンの数を示します。
if(CheckPointer(AttentionConcatenate)==POINTER_INVALID) { AttentionConcatenate=new CNeuronBaseOCL(); if(CheckPointer(AttentionConcatenate)==POINTER_INVALID) return false; if(!AttentionConcatenate.Init(0,15,open_cl,4*window*units_count,optimization_type)) return false; AttentionConcatenate.SetActivationFunction(None); }
メソッドの最後に、Weights0畳み込み層を初期化します。この層の目的は、すべてのアテンションヘッドから受け取ったデータに基づいて最適な戦略を選択することです。出力データの次元は、Multi-HeadAttentionブロックに入力された元のデータの次元に縮小されます。層を初期化するときは、入力ウィンドウとステップのサイズが前の層の4つのデータウィンドウに等しく、出力ウィンドウのサイズが前の層のデータウィンドウに等しいことを示します。
if(CheckPointer(Weights0)==POINTER_INVALID) { Weights0=new CNeuronConvOCL(); if(CheckPointer(Weights0)==POINTER_INVALID) return false; if(!Weights0.Init(0,16,open_cl,4*window,4*window,window,units_count,optimization_type)) return false; Weights0.SetActivationFunction(None); } //--- return true; }
すべてのメソッドと関数の完全なコードは、添付ファイルにあります。
4.3. フィードフォワード(予測制御)
フィードフォワードアルゴリズムは、主に以前に作成されたOpenCLプログラムを使用して構築されています。唯一の例外は、各アテンションヘッドからの4つのテンソルのデータを単一のテンソルに連結するカーネルの作成です。カーネルは、データバッファと各バッファウィンドウサイズへのポインタ、結果テンソルへのポインタをパラメータで受け取ります。入力データバッファによる詳細なウィンドウサイズが追加され、さまざまなサイズのテンソルをさまざまなウィンドウサイズで連結できるようになりました。
__kernel void ConcatenateBuffers(__global double *input1, int window1, __global double *input2, int window2, __global double *input3, int window3, __global double *input4, int window4, __global double *output)
カーネル本体では、データは入力配列から出力配列に要素ごとにコピーされます。アルゴリズムはとてもシンプルなので、添付のコードはわかりやすいと思います。
CNeuronMHAttentionOCLクラスでは、フィードフォワードはfeedForwardメソッドで実装されます。メソッドの開始時に、前の層への受信リンクの有効性を確認し、入力データを正規化します。
bool CNeuronMHAttentionOCL::feedForward(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=1; OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,prevLayer.getOutputIndex()); OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,prevLayer.Neurons()); if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Normalize: %d",GetLastError()); return false; } if(!prevLayer.Output.BufferRead()) return false; }
次に、適切な畳み込み層メソッドを呼び出し、すべてのアテンションヘッドのクエリと値のテンソルの値を再計算します。
if(CheckPointer(Querys)==POINTER_INVALID || !Querys.FeedForward(prevLayer)) return false; if(CheckPointer(Querys2)==POINTER_INVALID || !Querys2.FeedForward(prevLayer)) return false; if(CheckPointer(Querys3)==POINTER_INVALID || !Querys3.FeedForward(prevLayer)) return false; if(CheckPointer(Querys4)==POINTER_INVALID || !Querys4.FeedForward(prevLayer)) return false; if(CheckPointer(Values)==POINTER_INVALID || !Values.FeedForward(prevLayer)) return false; if(CheckPointer(Values2)==POINTER_INVALID || !Values2.FeedForward(prevLayer)) return false; if(CheckPointer(Values3)==POINTER_INVALID || !Values3.FeedForward(prevLayer)) return false; if(CheckPointer(Values4)==POINTER_INVALID || !Values4.FeedForward(prevLayer)) return false;
次に、各ヘッドの注意を再計算します。アルゴリズムは、記事8で説明されている親クラスに似ています。以下は、1つのアテンションヘッドのコードです。他のヘッドのコードも同様であり、適切なアテンションヘッドのオブジェクトへのポインタのみが類似しています。
//--- Scores Head 1 { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_score,Scores.GetIndex()); OpenCL.SetArgument(def_k_AttentionScore,def_k_as_dimension,iWindow); if(!OpenCL.Execute(def_k_AttentionScore,1,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionScore: %d",GetLastError()); return false; } if(!Scores.BufferRead()) return false; } //--- { uint global_work_offset[2]={0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iWindow; OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_scores,Scores.GetIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_inputs,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_values,Values.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_out,AttentionOut.getOutputIndex()); if(!OpenCL.Execute(def_k_AttentionOut,2,global_work_offset,global_work_size)) { printf("Error of execution kernel Attention Out: %d",GetLastError()); return false; } double temp[]; if(!AttentionOut.getOutputVal(temp)) return false; }
各ヘッドの注意を計算した後、以前に記述されたカーネルを使用して、結果を単一のテンソルに連結します。
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input1,AttentionOut.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window1,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input2,AttentionOut2.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window2,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input3,AttentionOut3.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window3,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input4,AttentionOut4.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window4,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_out,AttentionConcatenate.getOutputIndex());
if(!OpenCL.Execute(def_k_ConcatenateMatrix,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Concatenate Matrix: %d",GetLastError());
return false;
}
double temp[];
if(!AttentionConcatenate.getOutputVal(temp))
return false;
}
テンソル連結結果をWeights0畳み込み層に渡して、Multi-Head Attention作業結果のサイズを縮小します。
if(CheckPointer(Weights0)==POINTER_INVALID || !Weights0.FeedForward(AttentionConcatenate)) return false;
次に、得られた結果を前の層のデータと平均し、結果を正規化します。
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Weights0.getOutputIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
if(!Output.BufferRead())
return false;
}
//---
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=1;
OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,Weights0.getOutputIndex());
OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,Weights0.Neurons());
if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Normalize: %d",GetLastError());
return false;
}
double temp[];
if(!Weights0.getOutputVal(temp))
return false;
}
次に、親クラスと同様に、結果をFeedForwardブロックに渡します。
if(!FF1.FeedForward(Weights0)) return false; if(!FF2.FeedForward(FF1)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,FF2.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Output.GetIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } if(!Output.BufferRead()) return false; } //--- return true; }
すべてのメソッドと関数の完全なコードは、添付ファイルにあります。
4.4. フィードバックワード
フィードバックワードプロセスには、エラー勾配を1レベル下げることと、重み行列を更新することの2つのサブプロセスが含まれます。重みは、以前に作成されたOpenCLカーネルを使用して更新されますが、エラーバックプロパゲーションプロセスでは、いくつかの変更を加える必要があります。
まず、アテンションヘッドによるエラー勾配を伝播する必要があります。この関数を実行するには、DeconcatenateBuffersカーネルを作成します。勾配伝播用のバッファへのカーネルポインタ、各バッファのウィンドウサイズ、および前の反復から受信した勾配のバッファへのポインタへを入力します。
__kernel void DeconcatenateBuffers(__global double *output1, int window1, __global double *output2, int window2, __global double *output3, int window3, __global double *output4, int window4, __global double *inputs)
カーネルの開始時に、シーケンス要素の序数と、元のテンソルと最初のアテンションヘッドテンソルの最初の位置シフトを定義します。
{
int n=get_global_id(0);
int shift=n*(window1+window2+window3+window4);
int shift_out=n*window1;
次に、ループ内で、最初の注意の頭のエラー勾配のベクトルを移動します。
for(int i=0;i<window1;i++) output1[shift_out+i]=inputs[shift+i];
サイクルが終了したら、元のテンソルでポインタの位置を調整し、2番目の注意ヘッドのバッファで最初の位置シフトを決定します。次に、2番目のアテンションヘッドのデータコピーサイクルを実行します。この操作は、アテンションヘッドごとに繰り返されます。
//--- Head 2 shift+=window1; shift_out=n*window2; for(int i=0;i<window2;i++) output2[shift_out+i]=inputs[shift+i]; //--- Head 3 shift+=window2; shift_out=n*window3; for(int i=0;i<window3;i++) output3[shift_out+i]=inputs[shift+i]; //--- Head 4 shift+=window3; shift_out=n*window4; for(int i=0;i<window4;i++) output4[shift_out+i]=inputs[shift+i]; }
各アテンションヘッドのエラー勾配を計算した後で、ニューラルネットワークの前の層で勾配を1つのデータバッファに結合する必要があります。技術的には、すべてのアテンションヘッドの勾配をペアで追加することにより、SumMatrixカーネルを使用できます。ただし、このソリューションはパフォーマンスの点で最適ではありません。それでは、別のカーネルであるSum5Matrixを作成しましょう。カーネルパラメータで、データバッファ(5つの入力と1つの出力)、データウィンドウのサイズ、および乗数(合計補正係数)へのポインタを渡します。おそらく、4つのアテンションヘッドを持つ5つの着信バッファがある理由を説明する必要があります。5番目のバッファは、エラー勾配をパススルーして、勾配フェードのリスクを最小限に抑えるために使用されます。
__kernel void Sum5Matrix(__global double *matrix1, ///<[in] First matrix __global double *matrix2, ///<[in] Second matrix __global double *matrix3, ///<[in] Third matrix __global double *matrix4, ///<[in] Fourth matrix __global double *matrix5, ///<[in] Fifth matrix __global double *matrix_out, ///<[out] Output matrix int dimension, ///< Dimension of matrix double multiplyer ///< Multiplyer for output )
カーネル本体で、シーケンス内の処理されたベクトルの最初の要素のシフトを定義し、勾配を合計するためのサイクルを開始します。エラー勾配の合計に0.2を掛けると、送信されたエラーの値をニューラルネットワークの前の層で平均化できます。次に、乗数は意図的にパラメータに実装され、アルゴリズムの調整中にその値を選択できるようにします。
{
const int i=get_global_id(0)*dimension;
for(int k=0;k<dimension;k++)
matrix_out[i+k]=(matrix1[i+k]+matrix2[i+k]+matrix3[i+k]+matrix4[i+k]+matrix5[i+k])*multiplyer;
}
CNeuronMHAttentionOCLクラスでは、各サブプロセスがそのメソッドを受け取ります。エラー勾配の伝播はcalcInputGradientsメソッドによって実行されます。このメソッドは、前のニューラルネットワーク層のオブジェクトへのポインタをパラメータで受け取ります。メソッドの開始時にポインタの有効性を確認してください。
bool CNeuronMHAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
次に、畳み込み層FF1とFF2の適切な方法を使用して、FeedForwardブロックを介してエラー勾配を計算します。
if(!FF2.calcInputGradients(FF1)) return false; if(!FF1.calcInputGradients(Weights0)) return false;
FeedForwardブロックの周りにエラー勾配を渡します。平均誤差値をWeights0層の勾配バッファに保存します。
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,Gradient.GetIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Weights0.getGradientIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
double temp[];
if(Weights0.getGradient(temp)<=0)
return false;
}
次に、アテンションヘッドによるエラー伝播の時です。勾配テンソルのサイズを連結されたアテンションバッファのサイズに増やす必要があります。これを行うには、畳み込み層の適切なメソッドを呼び出して、エラー勾配をWeights0畳み込み層に渡します。
if(!Weights0.calcInputGradients(AttentionConcatenate)) return false;
エラー勾配の十分な大きさのテンソルを受け取った後は、アテンションヘッドのバッファによってエラーを分散できます。上で作成した連結解除カーネルを使用します。
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output1,AttentionOut.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window1,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output2,AttentionOut2.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window2,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output3,AttentionOut3.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window3,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output4,AttentionOut4.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window4,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_inputs,AttentionConcatenate.getGradientIndex());
if(!OpenCL.Execute(def_k_DeconcatenateMatrix,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Deconcatenate Matrix: %d",GetLastError());
return false;
}
double temp[];
if(AttentionConcatenate.getGradient(temp)<=0)
return false;
}
アテンションヘッド内のエラー勾配の計算は、別のメソッドcalcHeadGradientで実装されます。ここでは、アテンションスレッドごとにこのメソッドを呼び出します。
if(!calcHeadGradient(Querys,Values,Scores,AttentionOut,prevLayer)) return false; if(!calcHeadGradient(Querys2,Values2,Scores2,AttentionOut2,prevLayer)) return false; if(!calcHeadGradient(Querys3,Values3,Scores3,AttentionOut3,prevLayer)) return false; if(!calcHeadGradient(Querys4,Values4,Scores4,AttentionOut4,prevLayer)) return false;
メソッドの最後に、すべてのアテンションヘッドからのエラー勾配を合計し、その結果をニューラルネットワークの前の層に渡します。
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix1,AttentionOut.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix2,AttentionOut2.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix3,AttentionOut3.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix4,AttentionOut4.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix5,Weights0.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix_out,prevLayer.getGradientIndex());
OpenCL.SetArgument(def_k_Matrix5Sum,def_k_sum5_dimension,iWindow);
OpenCL.SetArgument(def_k_Matrix5Sum,def_k_sum5_multiplyer,0.2);
if(!OpenCL.Execute(def_k_Matrix5Sum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Matrix5Sum: %d",GetLastError());
return false;
}
double temp[];
if(prevLayer.getGradient(temp)<=0)
return false;
}
//---
return true;
}
calcHeadGradientメソッドを見てみましょう。このメソッドは、検討中のアテンションヘッドに関連する内部ニューラル層「query」、 「value」、「score」 「attention」へのポインタ、および前のニューラル層へのポインタをパラメータで受け取ります。
bool CNeuronMHAttentionOCL::calcHeadGradient(CNeuronConvOCL *query,CNeuronConvOCL *value,CBufferDouble *score,CNeuronBaseOCL *attention,CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
メソッド本体は、前のニューラル層へのポインタの有効性を確認することから始まります。エラー勾配を内部層に分散するには、記事8で説明したAttentionInsideGradientsカーネルを呼び出します。
{
uint global_work_offset[2]={0,0};
uint global_work_size[2];
global_work_size[0]=iUnits;
global_work_size[1]=iWindow;
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_gradient,attention.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys,prevLayer.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys_g,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys,query.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys_g,query.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values,value.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values_g,value.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_scores,score.GetIndex());
if(!OpenCL.Execute(def_k_AttentionGradients,2,global_work_offset,global_work_size))
{
printf("Error of execution kernel AttentionGradients: %d",GetLastError());
return false;
}
double temp[];
if(query.getGradient(temp)<=0)
return false;
}
この例は、「query」と「key」に分割せずに、1つの行列の訓練を示しています。したがって、key層のバッファの代わりに前の層のバッファが指定されます。前の層で取得したエラー勾配を上書きしないように、他の内部層で計算する場合は、現在のアテンションヘッドのAttentionOutテンソルにデータを転送します。バッファ間でデータをコピーするための個別のテンソルは提供していません。この操作は、2つの行列加算カーネルSumMatrixを使用して実行されました。行列が1つしかないため、両方のテンソルのポインタで前の層を示します。値の重複を避けるために、0.5の乗数を使用します。
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
double temp[];
if(attention.getGradient(temp)<=0)
return false;
}
次に、対応する「query」層メソッドを呼び出して、query層を通過するエラー勾配を計算します。結果は、前の反復で得られた勾配と合計されます。この手順では、1に等しい乗数が使用されます。増加した勾配は、次の手順で平均化されます。
if(!query.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,attention.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(attention.getGradient(temp)<=0) return false; }
繰り返しになりますが、メソッドの最後に、「value」層を介して勾配を計算し、以前に取得した勾配と合計します。アテンションヘッド全体の勾配は、0.33の乗数を使用して平均化できます。
if(!value.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,attention.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow+1); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.33); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(prevLayer.getGradient(temp)<=0) return false; } //--- return true; }
エラー勾配を再計算した後、すべての内部層の重みを更新します。updateInputWeightsメソッドで、すべての内部ニューラル層の関連するメソッドの順次呼び出しを記述します。
bool CNeuronMHAttentionOCL::updateInputWeights(CNeuronBaseOCL *prevLayer) { if(!Querys.UpdateInputWeights(prevLayer) || !Querys2.UpdateInputWeights(prevLayer) || !Querys3.UpdateInputWeights(prevLayer) || !Querys4.UpdateInputWeights(prevLayer)) return false; //--- if(!Values.UpdateInputWeights(prevLayer) || !Values2.UpdateInputWeights(prevLayer) || !Values3.UpdateInputWeights(prevLayer) || !Values4.UpdateInputWeights(prevLayer)) return false; if(!Weights0.UpdateInputWeights(AttentionConcatenate)) return false; if(!FF1.UpdateInputWeights(Weights0)) return false; if(!FF2.UpdateInputWeights(FF1)) return false; //--- return true; }
すべてのメソッドと関数の完全なコードは、添付ファイルにあります。
4.5. ニューラルネットワーク基本クラスの変更
Multi-Head Attentionアルゴリズムを実装した後、Positional Encoderを実装する必要があります。このプロセスは、ニューラルネットワーククラスのCNet::feedForwardメソッドに含まれています。実装のために、windowとtemの2つのパラメータがメソッドに追加されました。1つ目はデータウィンドウのサイズを指定し、2つ目は機能を有効/無効にする必要性を担当します。
bool CNet::feedForward(CArrayDouble *inputVals,int window=1,bool tem=true)
プロセス自体は、入力データをネットワークに供給するためのブロックに実装されています。まず、2つの内部変数pos(シーケンス内の位置)とdim (データウィンドウ内の要素の序数)を宣言します。データウィンドウ内の要素の序数を決定します。これを行うには、ソースデータテンソルの要素の序数をウィンドウサイズで除算した余りを使用します。シーケンス内の位置は、ソースデータテンソルの要素の序数をウィンドウサイズで除算した整数の結果によって決定されます。次に、完了したニューラルネットワーク入力のテンソルに初期データを保存するときに、この記事のセクション3に示されている式を使用して計算結果を追加します。
CNeuronBaseOCL *neuron_ocl=current.At(0); double array[]; int total_data=inputVals.Total(); if(ArrayResize(array,total_data)<0) return false; for(int d=0;d<total_data;d++) { int pos=d; int dim=0; if(window>1) { dim=d%window; pos=(d-dim)/window; } array[d]=inputVals.At(d)+(tem ? (dim%2==0 ? sin(pos/pow(10000,(2*dim+1)/(window+1))) : cos(pos/pow(10000,(2*dim+1)/(window+1)))) : 0); } if(!opencl.BufferWrite(neuron_ocl.getOutputIndex(),array,0,0,total_data)) return false;
ここで、ニューラルネットワークの正常な機能のためにいくつかの追加の変更を加える必要があります。新しいカーネルを使用するための定数をdefineブロックに追加します。
#define def_k_ConcatenateMatrix 17 ///< Index of the Multi Head Attention Neuron Concatenate Output kernel (#ConcatenateBuffers) #define def_k_conc_input1 0 ///< Matrix of Buffer 1 #define def_k_conc_window1 1 ///< Window of Buffer 1 #define def_k_conc_input2 2 ///< Matrix of Buffer 2 #define def_k_conc_window2 3 ///< Window of Buffer 2 #define def_k_conc_input3 4 ///< Matrix of Buffer 3 #define def_k_conc_window3 5 ///< Window of Buffer 3 #define def_k_conc_input4 6 ///< Matrix of Buffer 4 #define def_k_conc_window4 7 ///< Window of Buffer 4 #define def_k_conc_out 8 ///< Output tensor //--- #define def_k_DeconcatenateMatrix 18 ///< Index of the Multi Head Attention Neuron Deconcatenate Output kernel (#DeconcatenateBuffers) #define def_k_dconc_output1 0 ///< Matrix of Buffer 1 #define def_k_dconc_window1 1 ///< Window of Buffer 1 #define def_k_dconc_output2 2 ///< Matrix of Buffer 2 #define def_k_dconc_window2 3 ///< Window of Buffer 2 #define def_k_dconc_output3 4 ///< Matrix of Buffer 3 #define def_k_dconc_window3 5 ///< Window of Buffer 3 #define def_k_dconc_output4 6 ///< Matrix of Buffer 4 #define def_k_dconc_window4 7 ///< Window of Buffer 4 #define def_k_dconc_inputs 8 ///< Input tensor //--- #define def_k_Matrix5Sum 19 ///< Index of the kernel for calculation Sum of 2 matrix with multiplyer (#SumMatrix) #define def_k_sum5_matrix1 0 ///< First matrix #define def_k_sum5_matrix2 1 ///< Second matrix #define def_k_sum5_matrix3 2 ///< Third matrix #define def_k_sum5_matrix4 3 ///< Fourth matrix #define def_k_sum5_matrix5 4 ///< Fifth matrix #define def_k_sum5_matrix_out 5 ///< Output matrix #define def_k_sum5_dimension 6 ///< Dimension of matrix #define def_k_sum5_multiplyer 7 ///< Multiplyer for output
新しいクラスを識別するための定数を追加します。
#define defNeuronMHAttentionOCL 0x7888 ///<Multi-Head Attention neuron OpenCL \details Identified class #CNeuronAttentionOCL
ニューラルネットワーククラスコンストラクタで、OpenCLクラス初期化ブロックに新しいクラスを追加します。
next=Description.At(1); if(next.type==defNeuron || next.type==defNeuronBaseOCL || next.type==defNeuronConvOCL || next.type==defNeuronAttentionOCL || next.type==defNeuronMHAttentionOCL) { opencl=new COpenCLMy(); if(CheckPointer(opencl)!=POINTER_INVALID && !opencl.Initialize(cl_program,true)) delete opencl; }
ネットワーク内のニューロンを初期化するブロックに新しいタイプのニューロンを追加します。
case defNeuronMHAttentionOCL: neuron_attention_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break;
新しいカーネルの宣言を追加します。
if(CheckPointer(opencl)==POINTER_INVALID) return; //--- create kernels opencl.SetKernelsCount(20); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers");
CNeuronBaseOCLクラスのディスパッチャメソッドに新しいクラスを追加します。以下のコードでは、変更が強調表示されています。
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; } bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronConvOCL *conv=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; } //--- return false; } bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
すべてのメソッドと関数の完全なコードは、添付ファイルにあります。
5. テスト
新しいアーキテクチャをテストするためにFractal_OCL_AttentionMHTEエキスパートアドバイザーが作成されました。このエキスパートアドバイザーは、記事8のFractal_OCL_Attentionエキスパートアドバイザーに基づいて作成されています。親EAとは、アテンションニューロンのクラスタイプと、入力データ要素の位置をエンコードするメカニズムの使用のみが異なります。
CArrayObj *Topology=new CArrayObj(); if(CheckPointer(Topology)==POINTER_INVALID) return INIT_FAILED; //--- CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=36; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- bool result=true; for(int i=0; (i<2 && result); i++) { desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMHAttentionOCL; desc.window=36; desc.optimization=ADAM; desc.activation=None; result=Topology.Add(desc); } if(!result) { delete Topology; return INIT_FAILED; } //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; delete Net; Net=new CNet(Topology); delete Topology;
実験の純粋さのために、Self-AttentionとMulti-Head Attentionの2つのエキスパートアドバイザーを並行してテストしました。テストは同じ条件で実行されました。EURUSD、H1時間枠、20本の連続したローソク足のデータがネットワークに供給され、訓練は過去2年間の履歴を使用して実行され、パラメータはAdamメソッドによって更新されました。
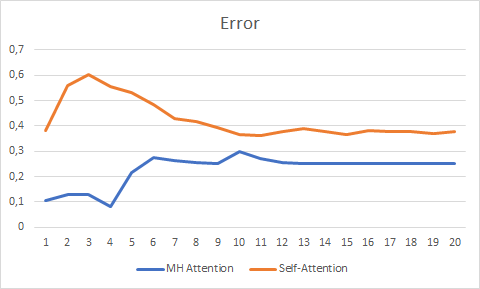
20エポック以上のテストでは、エラー変化グラフがより滑らかで、Self-Attentionの0.37に対して0.25のエラーで安定したMulti-Head Attentionの利点が示されました。
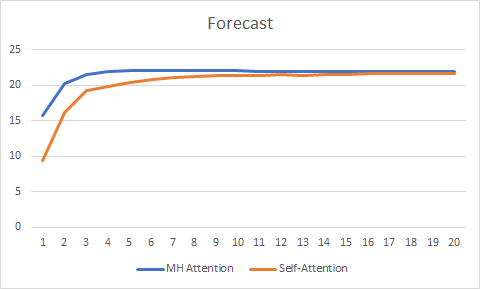
予測グラフはそれほど重要ではありませんが、Multi-Head Attentionテクノロジのパフォーマンスの向上も示しています。
すべてのクラスとエキスパートアドバイザーの完全なコードは、添付ファイルにあります。
終わりに
この記事では、Multi-Head Attentionアルゴリズムの実装を検討し、Single-Head Self-Attentionアーキテクチャとの比較テストを実施しました。同等のテスト条件で、Multi-Head Attentionはより良い結果を生み出しました。ただし、ネットワーク品質の向上には追加の計算コストが必要になることに留意するべきです。
参照文献
- ニューラルネットワークが簡単に
- ニューラルネットワークが簡単に(第2回): ネットワークのトレーニングとテスト
- ニューラルネットワークが簡単に(第3回): コンボリューションネットワーク
- ニューラルネットワークが簡単に(第4回): リカレントネットワーク
- ニューラルネットワークが簡単に(第5回): OPENCLでのマルチスレッド計算
- ニューラルネットワークが簡単に(第6回): ニューラルネットワークの学習率を実験する
- ニューラルネットワークが簡単に(第7回): 適応的最適化法
- ニューラルネットワークが簡単に(第8回): アテンションメカニズム
- ニューラルネットワークが簡単に(第9部): 作業の文書化
- Attention Is All You Need
- Multi-Head Attention: Collaborate Instead of Concatenate
記事で使用されたプログラム
| # | 名称 | 種類 | 説明 |
|---|---|---|---|
| 1 | Fractal_OCL_Attention.mq5 | エキスパートアドバイザー | 自己注意メカニズムを使用した分類ニューラルネットワーク(出力層に3つのニューロン)を持つエキスパートアドバイザー |
| 2 | Fractal_OCL_AttentionMHTE.mq5 | エキスパートアドバイザー | Multi-Head Attentionメカニズムを使用した分類ニューラルネットワーク(出力層に3つのニューロン)を備えたエキスパートアドバイザー |
| 3 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 4 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 5 | NN.chm | HTMLヘルプ | 変換済みHTMLヘルプファイル |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/8909
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 自己適応アルゴリズム(第IV部):その他の機能とテスト
自己適応アルゴリズム(第IV部):その他の機能とテスト
 自己適応アルゴリズム(第III部):最適化の放棄
自己適応アルゴリズム(第III部):最適化の放棄
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
最先端のGPUベースのNSアーキテクチャの委員会、Pythonはこれを持っているのだろうか?)
記事8からの通常のトランスフォーマーがまだ完全に理解できていないのが残念です ))