MQL5における統計とデータの分析に関する記事
数学的なモデルと確率の法則は多くのトレーダーにとって興味深いでしょう。数学はテクニカル指標の基本であり、トレーディングの結果を分析しストラテジーを開発するためには統計が必要です。
あいまいなロジック、デジタルフィルタ、マーケットプロファイル、コホーネンマップ、ニューラルガス、その他のトレーディングに使用できる多くのツールについてご覧ください。
新しい記事を追加

取引の機会を逃しています。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索

インディケーター情報の測定
機械学習は、ストラテジー開発の手法として注目されています。これまで、収益性と予測精度の最大化が重視される一方で、予測モデル構築のためのデータ処理の重要性はあまり注目されてきませんでした。この記事では、Timothy Masters著の書籍「Testing and Tuning Market Trading Systems」に記載されているように、予測モデル構築に使用するインディケーターの適切性を評価するために、エントロピーの概念を使用することについて考察しています。


2013 年第二四半期 MQL5マーケット 実績
1年半成功裏に実績を積み、MQL5 「マーケット」はトレーダーにとってトレーディング戦略およびテクニカルインディケータの最大のストアとなりました。そこでは世界中の開発者 350 名から提供される約 800 件のトレーディングアプリケーションが提供されています。100,000 件以上のトレーディングプログラムがすでにトレーダーにより購入され、MetaTrader 5 ターミナルにダウンロードされています。
DoEasyライブラリの時系列(第48部): 複数銘柄・複数期間指標バッファ
本稿では、指標バッファオブジェクトのクラスを改善して、複数銘柄モードで動作するようにします。これにより、カスタムプログラムで複数銘柄・複数期間指標を作成するための道が開かれます。複数銘柄・複数期間指標標準指標を作成するために、不足している機能を計算バッファオブジェクトに追加します。

データサイエンスと機械学習(第18回):市場複雑性を極める戦い - 打ち切りSVD v.s. NMF
打ち切り特異値分解(Truncated SVD)と非負行列因子分解(NMF)は次元削減技法です。両者とも、データ主導の取引戦略を形成する上で重要な役割を果たしています。次元削減、洞察の解明、定量分析の最適化など、複雑な金融市場をナビゲートするための情報満載のアプローチをご覧ください。

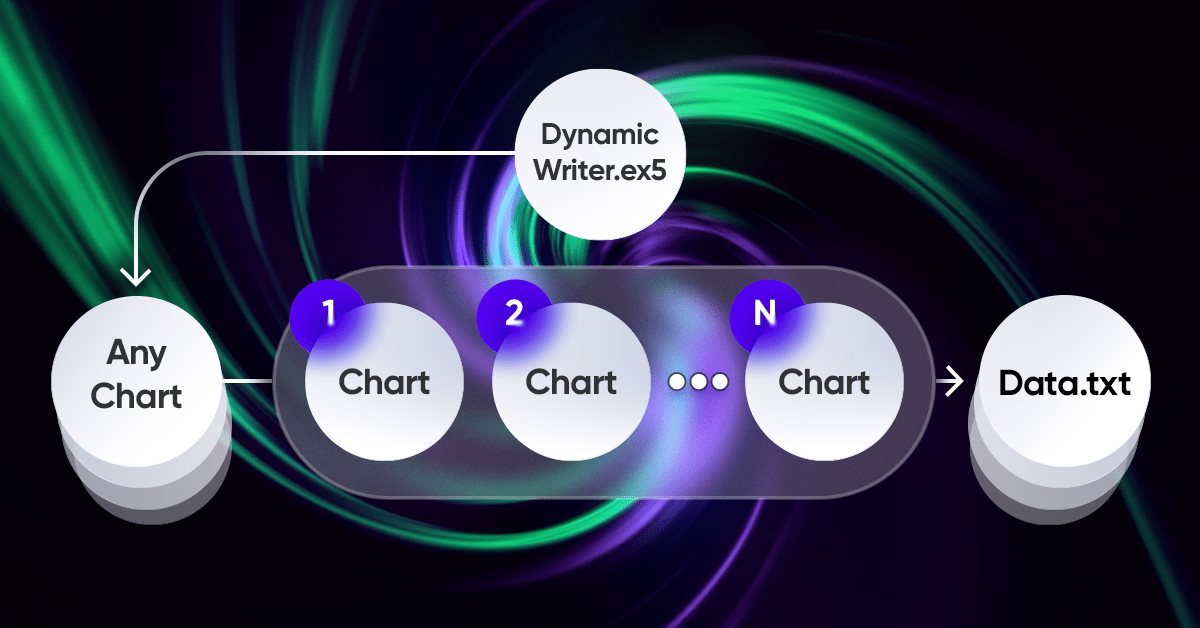
チャート上で取引を視覚化する(第2回):データのグラフ表示
ここでは、取引エントリを分析するために取引の印刷画面のアンロードを簡素化するスクリプトをゼロから開発します。単一の取引に関するすべての必要な情報は、異なる時間枠を描画する機能を備えた1つのチャートに便利に表示されます。
DoEasyライブラリでのその他のクラス(第70部): チャットオブジェクトコレクショの機能拡張と自動更新
本稿では、チャートオブジェクトの機能を拡張し、チャートのナビゲーション、スクリーンショットの作成、チャートの保存と適用を行います。また、チャートオブジェクトのコレクション、それらのウィンドウ、およびその中の指標の自動更新を実装します。

母集団最適化アルゴリズム:粒子群(PSO)
この記事では、一般的な粒子群最適化(PSO)アルゴリズムについて検討します。以前は、収束、収束率、安定性、スケーラビリティなどの最適化アルゴリズムの重要な特性について説明し、テストスタンドを開発し、最も単純なRNGアルゴリズムを検討しました。

行列ユーティリティ - 行列とベクトルの標準ライブラリの機能を拡張する
行列は大規模な数学的演算を効率的に処理できるため、機械学習アルゴリズムや一般的なコンピュータの基盤となっています。標準ライブラリは必要なものをすべて備えていますが、ユーティリティファイルでライブラリにはまだないいくつかの関数を導入して、拡張する方法を見てみましょう。

MQL5とデータ処理パッケージの統合(第1回):高度なデータ分析と統計処理
統合により、MQL5から生の財務データをJupyter Labのようなデータ処理パッケージにインポートし、統計テストを含む高度な分析をおこなうシームレスなワークフローが実現します。

ペア取引における平均回帰による統計的裁定取引:数学で市場を攻略する
本記事では、ポートフォリオレベルの統計的アービトラージの基本的な概念を紹介します。数学の深い知識がない読者にも理解しやすく説明し、実際の運用を始めるためのコンセプトフレームワークを提案することを目的としています。記事には、動作するエキスパートアドバイザー(EA)と、1年間のバックテストに関する注記、再現用の設定ファイル(.iniファイル)も含まれています。

データサイエンスと機械学習(第29回):AI訓練に最適なFXデータを選ぶための重要なヒント
この記事では、AIモデルのパフォーマンスを向上させるために、最も適切で高品質なFXデータを選択するための重要な側面について深く掘り下げます。
データサイエンスと機械学習(第09回):K近傍法(KNN)
これは、訓練データセットから学習しない遅延アルゴリズムです。代わりにデータセットを保存し、新しいサンプルが与えられるとすぐに動作します。シンプルでありながら、実世界でさまざまなケースに応用されています。
データサイエンスと機械学習(第07回)::多項式回帰
線形回帰とは異なり、多項式回帰は、線形回帰モデルでは処理できないタスクをより適切に実行することを目的とした柔軟なモデルです。MQL5で多項式モデルを作成し、そこから何か良いものを作る方法を見つけてみましょう。

MQL5における修正グリッドヘッジEA(第1部):シンプルなヘッジEAを作る
古典的なグリッド戦略と古典的なヘッジ戦略を混合した、より高度なグリッドヘッジEAのベースとして、シンプルなヘッジEAを作成する予定です。この記事が終わるころには、簡単なヘッジ戦略の作り方がわかり、この戦略が本当に100%儲かるかどうかについての人々の意見も知ることができるでしょう。

MQL5で取引管理者パネルを作成する(第1回):メッセージングインターフェイスの構築
この記事では、システム管理者を対象に、プラットフォーム内で他のトレーダーと直接コミュニケーションを図るための、MetaTrader 5用メッセージングインターフェイスの作成について説明します。ソーシャルプラットフォームとMQL5との最近の統合により、さまざまなチャンネルに素早くシグナルをブロードキャストことができるようになりました。YESかNOのどちらかをクリックするだけで、送られてきたシグナルを検証できることをご想像ください。詳しくは本稿をご覧ください。

MQL5.community 人名鑑
MQL5.com ウェブサイトはみなさんのことをとてもよく覚えています!何本のスレッドがすばらしい出来か、記事がどれほど人気か、「コードベース」のプログラムがどのくらいの頻度でダウンロードされるか。これは MQL5.comで記憶されていることのほんの小さな一部にしかすぎません。みなさんの実績はプロフィールで確認可能ですが、全体像はどうでしょうか?本稿では全 MQL5.community メンバーの実績概要を示します。

リプレイシステムの開発 — 市場シミュレーション(第4回):設定の調整(II)
システムとコントロールを作り続けましょう。サービスをコントロールする能力がなければ、システムを前進させ、改善することは難しくなります。

外国為替市場の季節性から利益を得る
例えば、冬になると新鮮な野菜の値段が上がったり、霜が降りると燃料の値段が上がったりすることはよく知られていますが、同じようなパターンが外国為替市場にもあることを知っている人は少ないです。

独自のLLMをEAに統合する(第3部):CPUを使った独自のLLMの訓練
今日の人工知能の急速な発展に伴い、言語モデル(LLM)は人工知能の重要な部分となっています。私たちは、強力なLLMをアルゴリズム取引に統合する方法を考える必要があります。ほとんどの人にとって、これらの強力なモデルをニーズに応じて微調整し、ローカルに展開して、アルゴリズム取引に適用することは困難です。本連載では、この目標を達成するために段階的なアプローチをとっていきます。

ニュース取引が簡単に(第3回):取引の実施
この記事では、ニュース取引エキスパートアドバイザー(EA)で、データベースに保存されている経済指標カレンダーに基づいて取引を開始します。さらに、EAのグラフィックを改善し、今後の経済指標カレンダーイベントに関するより適切な情報を表示する予定です。


MQL5とPythonを使用したブローカーAPIとエキスパートアドバイザーの統合
この記事では、Pythonと連携したMQL5の実装について解説し、ブローカー関連の操作を自動化する方法を紹介します。VPS上にホストされて継続的に稼働するエキスパートアドバイザー(EA)が、あなたに代わって取引を実行すると想像してください。ある時点で、EAによる資金管理機能が非常に重要になります。具体的には、取引口座への残高補充や出金などの操作を含みます。本稿では、これらの機能の利点と実際の実装例を紹介し、資金管理を取引戦略にシームレスに統合する方法をお伝えします。どうぞご期待ください。
パターン検索への総当たり攻撃アプローチ(第VI部):循環最適化
この記事では、MetaTrader 4および5の取引の自動化チェーン全体を完成するだけでなく、より興味深いことができるようになった改善の最初の部分を示します。今後、このソリューションにより、EAの作成と最適化の両方を完全に自動化し、効果的な取引構成を見つけるための人件費を最小限に抑えることができます。

時系列マイニングのためのデータラベル(第5回):ソケットを使用したEAへの応用とテスト
この連載では、ほとんどの人工知能モデルに適合するデータを作成できる、時系列のラベル付け方法をいくつかご紹介します。ニーズに応じて的を絞ったデータのラベル付けをおこなうことで、訓練済みの人工知能モデルをより期待通りの設計に近づけ、モデルの精度を向上させ、さらにはモデルの質的飛躍を助けることができます。

データサイエンスとML(第32回):AIモデルを最新の状態に保つ、オンライン学習
常に変化する取引の世界では、市場の変動に適応することは選択肢ではなく、必要不可欠です。新たなパターンやトレンドが日々生まれる中で、最先端の機械学習モデルでさえ、進化する環境に対応し続けることが困難になっています。本記事では、モデルを自動的に再訓練することで、その有効性を維持し、新しい市場データに柔軟に適応させる方法を解説します。


PythonとMQL5でロボットを開発する(第3回):モデルベース取引アルゴリズムの実装
PythonとMQL5で自動売買ロボットを開発する連載を続けます。この記事では、Pythonで取引アルゴリズムを作成します。

初心者のためのMetaTrader 5とRによるアルゴリズム取引
RとMetaTrader 5をシームレスに統合する技術を解き明かしながら、金融分析とアルゴリズム取引が出会う魅力的な探求に乗り出しましょう。この記事は、MetaTrader 5の強力な取引機能とRの精巧な分析の領域を橋渡しするためのガイドです。

母集団最適化アルゴリズム:ハーモニーサーチ(HS)
今回は、完璧な音のハーモニーを見つける過程に着想を得た、最も強力な最適化アルゴリズムであるハーモニーサーチ(HS)を研究し、検証してみます。私たちの評価でトップになるのはどのアルゴリズムでしょうか。

MQL5の圏論(第2回)
圏論は数学の一分野であり、多様な広がりを見せていますが、MQL5コミュニティではまだ比較的知られていません。この連載では、その概念のいくつかを紹介し、考察することで、コメントや議論を呼び起こし、トレーダーの戦略開発におけるこの注目すべき分野の利用を促進することを目的としたオープンなライブラリを確立することを目指しています。

ニューラルネットワークが簡単に(第16部):クラスタリングの実用化
前回は、データのクラスタリングをおこなうためのクラスを作成しました。今回は、得られた結果を実際の取引に応用するためのバリエーションを紹介したいと思います。

DoEasyライブラリの時系列(第55部): 指標コレクションクラス
本稿では、指標オブジェクトクラスとそのコレクションの開発を続けます。指標オブジェクトごとに、その説明と正しいコレクションクラスを作成して、エラーなしのストレージを作成し、コレクションリストから指標オブジェクトを取得します。

ニューラルネットワークが簡単に(第15部):MQL5によるデータクラスタリング
クラスタリング法について引き続き検討します。今回は、最も一般的なk-meansクラスタリング手法の1つを実装するために、新しいCKmeansクラスを作成します。テスト中には約500のパターンを識別することができました。

EAを用いたリスクとキャピタルの管理
この記事では、バックテストレポートでは見えないこと、自動売買ソフトを使用する際の注意点、エキスパートアドバイザー(EA)を使用している場合の資金管理、自動売買をおこなっている場合に取引活動を続けるために大きな損失をカバーする方法について説明します。

市場シミュレーション(第1回):両建て注文(I)
本日から第2段階に入り、市場リプレイ/シミュレーションシステムについて見ていきます。まず、両建て注文の可能な解決策を示します。これは最終版ではありませんが、近い将来に解決しなければならない問題に対するひとつの可能なアプローチとなります。
DoEasyライブラリでの価格(第64部): 板情報、DOMスナップショットのクラスおよびスナップショットシリーズオブジェクト
本稿では、2つのクラス(DOMスナップショットオブジェクトのクラスとDOMスナップショットシリーズオブジェクトのクラス)を作成し、DOMデータシリーズの作成をテストします。

プライスアクション分析ツールキットの開発(第21回):Market Structure Flip Detector Tool
The Market Structure Flip Detectorエキスパートアドバイザー(EA)は、市場センチメントの変化を常に監視する頼れるパートナーとして機能します。ATR (Average True Range)に基づく閾値を活用することで、構造の反転を的確に検出し、各高値切り下げおよび安値切り上げを明確なインジケーターで表示します。MQL5の高速な実行性能と柔軟なAPIにより、このツールはリアルタイム分析を可能にし、最適な視認性を保つよう表示を調整しながら、反転の回数やタイミングをモニターできるライブダッシュボードも提供します。さらに、カスタマイズ可能なサウンド通知やプッシュ通知により、重要なシグナルを確実に受け取ることができ、シンプルな入力と補助ルーチンがどのように価格変動を実用的な戦略へと変換するかを実感できます。
確率最適化と最適制御の例
SMOC(Stochastic Model Optimal Controlの略と思われる)と名付けられたこのエキスパートアドバイザー(EA)は、MetaTrader 5用の高度なアルゴリズム取引システムのシンプルな例です。テクニカル指標、モデル予測制御、動的リスク管理を組み合わせて取引判断をおこないます。このEAには、適応パラメーター、ボラティリティに基づくポジションサイジング、トレンド分析が組み込まれており、さまざまな市場環境においてパフォーマンスを最適化します。