
経済予測:Pythonの可能性を探る

はじめに
経済予測は、非常に複雑で手間のかかる作業です。過去のデータをもとに、将来起こりうる動きを分析できます。歴史的なデータと現在の経済指標を組み合わせて分析することで、経済がどこに向かおうとしているのかを推測できるのです。これは非常に有用なスキルであり、ビジネスや投資、経済政策において、より情報に基づいた判断を下すための助けになります。
私たちは、情報収集から予測モデルの作成まで、Pythonと経済データを用いてこのツールを開発していきます。このツールは、過去と現在のデータを分析し、将来の動向を予測する役割を果たします。
金融市場は経済の動きを示す良い指標であり、わずかな変化にも敏感に反応します。結果が予測可能な場合もあれば、予期しない反応が生じることもあります。指標の変化によって、市場というバロメーターがどのように振れるのか、いくつかの例を見てみましょう。
GDPが成長すれば、市場は通常ポジティブに反応します。インフレが上昇すれば、一般的に不安感が広がります。失業率が下がると、それはたいてい良いニュースと見なされます。ただし、例外も存在します。貿易収支や金利など、それぞれの指標が市場心理に影響を与えます。
実際のところ、市場はしばしば実際の結果そのものではなく、多数の市場参加者が抱いていた「期待」に反応します。「噂で買い、事実で売る」という古い株式市場の格言がありますが、これはその本質を的確に表しています。また、大きな変化がないことが、予想外のニュースよりも市場に大きな変動を引き起こす場合もあります。
経済は複雑なシステムです。すべてが相互に関連しており、ひとつの要因が他の要因に影響を及ぼします。あるパラメータの変化が連鎖反応を引き起こすこともあります。私たちの課題は、これらの関係を理解し、それを分析できるようになることです。Pythonというツールを使って、解決策を探っていきます。
環境の設定:必要なライブラリのインポート
では、何が必要でしょうか。まずはPythonです。まだインストールされていない場合は、python.orgにアクセスしてください。また、インストールプロセス中に、[PythonをPATHに追加]ボックスをチェックすることを忘れないでください。
次に必要なのはライブラリです。ライブラリを使うことで、ツールの基本的な機能を大幅に拡張することができます。今回使用するライブラリは以下のとおりです。
- pandas:データの操作に使用します。
- wbdata:世界銀行とやり取りするためのライブラリ。これを使って最新の経済データを取得します。
- MetaTrader5:実際の市場との直接的な連携に必要です。
- catboostのCatBoostRegressor:小規模な手作りAIモデルとして利用します。
- sklearnのtrain_test_splitとmean_squared_error:モデルの性能評価に使用します。
すべてのライブラリをインストールするには、コマンドプロンプトを開いて以下のコマンドを入力します。
pip install pandas wbdata MetaTrader5 catboost scikit-learn
準備が整ったら、次に、最初のコード文字列を書いてみましょう。
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
必要なツールはすべて準備しました。次へ移りましょう。
世界銀行APIの使用:経済指標の読み込み
それでは、世界銀行から経済データをどのように取得するかを見ていきましょう。
まず、指標コードを含む辞書を作成します。
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
}
これらの各コードは、特定の種類のデータへのアクセスを提供します。
続けましょう。コード全体を実行するループを開始します。
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
ここでは、各指標に対してデータの取得を試みます。うまく取得できた場合はリストに追加し、失敗した場合はエラーを表示して次に進みます。
その後、すべてのデータをひとつの大きなDataFrameにまとめます。
data = pd.concat(data_frames, axis=1) この段階で、必要なすべての経済データが取得できているはずです。
次のステップは、取得したデータをファイルに保存することです。これにより、後で必要な分析などに再利用できるようになります。
data.to_csv('economic_data.csv', index=True) これで、世界銀行から大量のデータをダウンロードすることができました。とても簡単です。
分析のための主要経済指標の概要
初心者の方にとっては、大量のデータや数値を理解するのが少し難しく感じられるかもしれません。そこで、分析を進めやすくするために、まずは主要な指標を確認しておきましょう。
- GDP成長率:国の「収入」のようなものです。成長していればポジティブなサイン、減少していれば国にとってマイナスの影響を与えます。
- インフレ:商品やサービスの価格が上昇することです。物価が上がれば、人々の購買力は低下します。
- 実質金利:上昇すると、ローンなどの借り入れのコストが高くなります。
- 輸出と輸入:国が何を売り、何を買っているかを示します。輸出が増えることは、通常ポジティブな兆候とされます。
- 経常収支:外国とのお金のやり取りの収支を表します。数値が大きいほど、国の対外的な財務状況が良好であることを意味します。
- 政府債務:国の借金の総額です。少ないほど望ましいとされます。
- 失業率:職に就いていない人の割合です。数値が低いほど良いと考えられます。
- 一人当たりGDPの成長率:平均的な人が豊かになっているかどうかを示す指標です。
これらの指標は、コード上では次のように表現されます。
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
}
それぞれの指標には固有の重要性があります。単体ではそれほど多くを語りませんが、組み合わせることで、より包括的な経済の全体像が見えてきます。また、これらの指標は互いに影響を及ぼし合っている点にも注意が必要です。たとえば、失業率が低いのは一般的に良いニュースとされますが、それがインフレ率の上昇を招くこともあります。あるいは、GDPが大きく成長していても、それが巨額の借金によって達成されたものであれば、必ずしも歓迎できるとは限りません。
こうした複雑な関係性を考慮するために、私たちは機械学習を活用します。機械学習は情報処理を高速化し、膨大なデータを整理しながら、指標同士の複雑な相互作用も取り込むことができます。ただし、このプロセスを理解し活用するには、ある程度の努力や学習も必要です。
世界銀行のデータの整理と構造化
もちろん、最初は世界銀行の膨大なデータ量に圧倒されるかもしれません。しかし、作業や分析をよりスムーズに行うために、これらのデータを表形式で整理していきます。
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
次に、各指標ごとにデータの取得を試みます。一部の指標については問題が発生する可能性がありますが、その場合はエラーとして記録し、処理を続けます。その後、個別に取得したデータを一つの大きなDataFrameにまとめます。
しかし、ここで終わりではありません。ここからが一番面白いところです。
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe())
何ができたのかを見てみましょう。どのような指標が含まれているか、データの最初の数行はどのような内容になっているか。それはまるで、完成したパズルを初めて眺める瞬間のようです。すべてのピースが正しく収まっているかを確認します。そして、このデータ全体をCSVファイルとして保存します。
最後に、いくつかの統計を確認します。平均値や最高値、最低値といった基本的な指標です。これは、データに異常がないかをざっと確認する作業のようなものです。このようにして、ばらばらだった数値の集まりが、一貫性のあるデータシステムへと姿を変えました。これで、本格的な経済分析に必要な準備がすべて整いました。
MetaTrader 5の導入:接続を確立してデータを受信する
ここからは、MetaTrader 5について見ていきましょう。最初のステップは、MetaTrader 5との接続を確立することです。実際のコードは以下のようになります。
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
次の重要なステップは、データの取得です。まずは、どの通貨ペアが利用可能かを確認する必要があります。
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols]
上記のコードを実行すると、利用可能なすべての通貨ペアのリストが取得されます。次に、利用可能な各ペアの過去の相場データをダウンロードする必要があります。
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df
入力したこのコードでは何が行われているのでしょうか。MetaTraderに対して、各取引銘柄について過去1000日分のデータを取得するよう指示しています。その後、取得したデータは表形式で読み込まれます。
このデータには、過去3年間に通貨市場で起きた出来事が詳細に記録されています。これにより、取得した価格データを分析し、一定のパターンを見つけ出すことが可能になります。ここから先に広がる分析の可能性は、まさに無限です。
データの準備:経済指標と市場データを組み合わせる
この段階では、実際にデータを扱っていきます。私たちの手元には、「経済指標」と「為替レート」という2つの異なる分野のデータがあります。ここでの目的は、それらを一つに統合し、分析可能な形にまとめることです。
まずは、データを準備するための関数から始めましょう。今回の全体的な作業の中では、以下のようなコードになります。
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
では、一つずつ見ていきましょう。まずは通貨ペアのデータをコピーします。なぜかというと、元のデータではなくコピーを使って作業したほうが安全だからです。万が一エラーが起きても、元のデータを再作成する手間を省けます。
ここからが最も興味深い部分です。新たに「close_diff」と「close_corr」という2つの列を追加します。「close_diff」は終値が前日比でどれだけ変化したかを示します。これにより価格が上昇傾向にあるのか下降傾向にあるのかがわかります。「close_corr」は終値の自己相関(1日分のずれを持つもの)を表します。これは、今日の価格が昨日の価格とどれくらい似ているかを示す指標として使います。
ここからが難しいところです。通貨データに経済指標を組み込もうとします。つまり、異なるデータを一つのまとまったデータセットにしていく作業です。すべての経済指標について世界銀行のデータから該当するものを探し、見つかれば通貨データに追加します。見つからないこともありますが、そのときは、その旨を警告として表示し、処理を続けます。
こうした処理の後に欠損値が含まれる行が残る場合がありますが、その行は削除します。
では、この関数をどのように使うかを見てみましょう。
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data)
各通貨ペアに対して、先ほど作成した関数を適用します。そうすることで、ペアごとに完成したデータセットが得られます。ペアごとに別々のセットになりますが、すべて同じルールで構築されています。
このプロセスで最も重要なことが何か、お分かりでしょうか。私たちはまったく新しいものを作り出しているのです。様々な経済指標データとリアルタイムの為替レートデータを組み合わせ、一貫性のある情報へと昇華させています。個別ではばらばらに見えるデータも、組み合わせることでパターンが見えてくるのです。
これで分析に使用できるデータセットが完成しました。このデータからシーケンスを探し、未来を予測し、示唆を得ることができます。ただし、本当に注目すべきサインを見極める必要があります。データの世界においては、無意味な細部など存在しません。データ準備のすべての段階が、最終的な成果に大きな影響を与えます。
私たちのモデルにおける機械学習
機械学習は非常に複雑で手間のかかるプロセスです。CatBoost Regressor関数は、その中で重要な役割を果たします。使い方は以下の通りです。
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
ここではすべてのパラメータが重要です。1000回の反復は、モデルがデータを何度繰り返して学習するかを示します。学習率0.1は、すぐに高い速度で学習を進めるのではなく、徐々に学習するための設定です。深さ8は、複雑なパターンや関係性を捉えるための深さを意味します。RMSEは、モデルの誤差を評価する指標です。モデルの学習には一定の時間がかかり、学習の過程で例を示し、正確さを評価していきます。CatBoostは多様な種類のデータに対して特に効果的に動作し、機能が限られた狭い範囲にとどまりません。
通貨を予測するには、次を実行します。
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}")
データの一部は学習用、他の部分はテスト用です。それは学校に行くようなものです。まず学習して、それから試験を受けます。
データを2つの部分に分けます。なぜそうするのかというと、1つは学習用、もう1つはテスト用だからです。結局のところ、まだ使ったことのないデータでモデルを評価する必要があります。
学習後、モデルは予測を試みます。二乗平均平方根誤差は、どれだけうまく機能したかを示します。誤差が小さいほど予測精度は高いです。CatBoostは間違いから学び、継続的に改善される点が特徴です。
もちろん、CatBoostは自動で万能ではありません。良質なデータが必要です。そうでなければ、入力データも出力データも効果が薄くなってしまいます。しかし、適切なデータがあれば良い結果が得られます。それでは、データの分割について説明しましょう。検証に使うクオートが必要だと話しましたが、コードではこのようになります。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) データの50%はテスト用に割り当てます。これらを混同してはいけません。金融データでは時系列の順序を保つことが非常に重要です。
モデルの作成と学習が最も興味深い部分です。ここでCatBoostはその実力を最大限に発揮します。
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
モデルは貪欲にデータを吸収し、パターンを探します。各反復は、市場の理解を深める一歩です。
そして、いよいよ真価を問う時です。精度の評価です。
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
二乗平均平方根誤差は、モデルの誤差を評価する上で非常に重要な指標です。この値は小さいほど良いです。これにより、プログラムの品質を判断できます。ただし、取引においては絶対的な保証があるわけではありません。しかし、CatBoostを使うことで分析の効率が格段に向上し、私たちが見落としがちなものも捉えることができます。予測を重ねるたびに、結果は改善されていきます。
通貨ペアの将来予測
通貨ペアの予測は確率を扱う作業です。うまくいくこともあれば、損失を被ることもあります。大切なのは、最終的な結果が自分たちの期待に沿っているかどうかです。
コード内のforecast関数は確率を用いて動作します。計算の仕組みは次のようになっています。
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
まず、すでにあるデータと予測対象のデータを分けます。次に、データを学習用とテスト用の2つに分割します。モデルは学習用のデータで学習し、テスト用のデータで性能を確認します。学習が終わると、モデルは予測をおこない、二乗平均平方根誤差でどれくらい誤差があったかを評価します。数値が低いほど、予測精度は高くなります。
しかし、最も興味深いのは、過去30日分のデータを使って将来の価格変動を予測し、その結果を分析することです。まるで経験豊富なアナリストの予測を頼るような状況です。可視化については、残念ながら現状のコードには明示的な表示機能はありません。しかし、これを追加してみて、どのように見えるか確かめてみましょう。
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
このコードは、各通貨ペアのチャートを作成します。グラフは線で結ばれており、各点は特定の日の予測価格を示しています。これらのチャートは将来のトレンドの可能性を表すよう設計されており、膨大で複雑なデータをもとに作成されています。多くの場合、一般の人には理解が難しいかもしれません。線が上向きなら通貨の価値は上昇することを意味し、下向きなら価格の下落に備える必要があります。
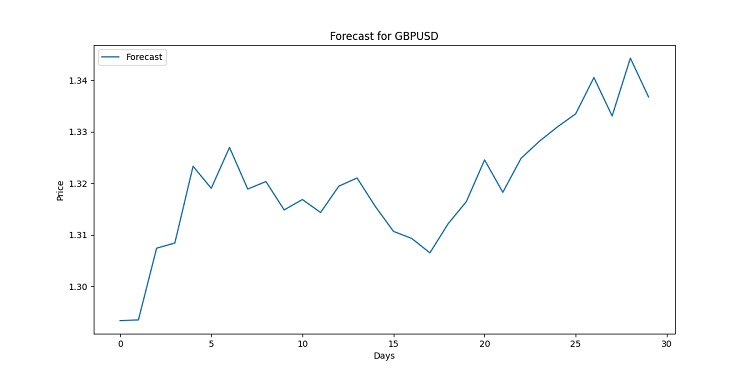
予測はあくまで保証ではないことを忘れないでください。市場は予想外の動きをすることもあります。しかし、適切な可視化があれば、少なくとも何を期待すべきかを把握できます。こうした状況では、高質な分析をすぐに活用できるのです。
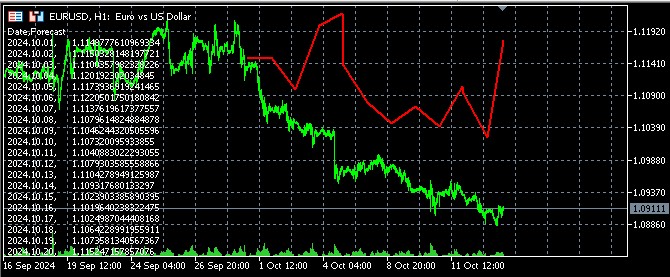
また、ファイルを開いて予測結果をコメントに出力することで、MQL5上で予測を可視化するコードも作成しました。
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/ja/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/ja/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
端末では予測が以下のように表示されます。
結果の解釈:経済要因が為替レートに与える影響の分析
それでは、コードをもとに結果の解釈を詳しく見ていきましょう。私たちは何千もの異なる事実を整理されたデータとして集めましたが、それらをさらに分析する必要があります。
まず、GDP成長率から失業率まで、さまざまな経済指標が存在します。それぞれの要因は市場背景に独自の影響を与えています。個別の指標がそれぞれ影響力を持つ一方で、これらが組み合わさることで最終的な為替レートに作用しているのです。
GDPを例に挙げましょう。コード上では、いくつかの指標で表現されています。
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
GDPの成長は通常、通貨を強くします。なぜなら、好調な経済ニュースは、さらなる成長を見越して資本を投資しようとする投資家を引きつけるからです。投資家は成長する経済に魅力を感じ、その国の通貨の需要が高まります。
一方で、インフレ(「FP.CPI.TOTL.ZG」:インフレ率)はトレーダーにとって警戒すべきシグナルです。インフレが高くなるほどお金の価値は速く目減りします。一般的にインフレ率が高いと、その国のサービスや商品の価格が上昇し、通貨は弱くなりやすいです。
次に、貿易収支を見てみましょう。興味深い指標です。
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
これらの指標は、まるで天秤のようなものです。輸出が輸入を上回れば、その国はより多くの外貨を手に入れ、それが通常は自国通貨の強化につながります。
では、これをコード上でどのように分析するかを見てみましょう。CatBoost Regressorは私たちの主要なツールで、まるで熟練の指揮者のように、すべての楽器の音を一度に聴きながら、それぞれが互いにどのように影響し合っているかを把握します。
要因の影響をより深く理解するために、予測関数に以下のような処理を追加できます。
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions
これにより、各通貨ペアの予測においてどの要因が最も重要であったかを把握できます。たとえば、EURではECBの政策金利が主要因となり、JPYでは日本の貿易収支が大きな影響を与えているかもしれません。以下はデータ出力の例です。
EURUSDの解釈
1.価格動向:予測では今後30日間、上昇傾向が示されています。
2.ボラティリティ:予測される価格変動は比較的低いことを示しています。
3.主な影響要因:この予測で最も重要な特徴は「low(安値)」です。
4.経済的な意味合い
- GDP成長が主要な要因ならば、強い経済成長が通貨に良い影響を与えていることを示します。
- インフレ率の重要度が高い場合は、金融政策の変更が通貨に影響を及ぼしている可能性があります。
- 貿易収支が重要ならば、国際貿易の動向が通貨の動きを左右していることが考えられます。
5.取引への示唆:
- 上昇傾向はロングポジションを検討するサインかもしれません。
- 低ボラティリティは、ストップロスの幅を広げやすい状況を示します。
6.リスク評価:
- モデルの限界や予測外の市場変動には常に注意が必要です。
- 過去の実績は将来の結果を保証するものではありません。
ただし、経済に「これが正解」だといった単純な答えはありません。時には、予想に反して通貨が強くなることもあれば、理由もなく下がることもあります。市場はしばしば、現実よりも期待によって動きます。
もう一つ重要なのは「タイムラグ」です。経済の変化は為替レートにすぐには反映されません。これは巨大な船を操縦するようなもので、舵を切ってもすぐに進路が変わらないのです。コードでは日次データを使っていますが、一部の経済指標は更新頻度が低いため、予測に多少の誤差が生じることもあります。結局のところ、結果の解釈は科学であると同時に芸術でもあります。モデルは強力なツールですが、最終的な判断は人間がおこないます。このデータを賢く活用し、あなたの予測が的確でありますように。
経済データに潜む非明白なパターンを探る
外国為替市場は非常に巨大な取引プラットフォームです。価格の動きは必ずしも予測可能ではなく、それに加えて一時的にボラティリティや流動性を高める特別な出来事も存在します。これらは世界的な影響を及ぼす出来事です。
私たちのコードでは、経済指標に基づいて分析をおこなっています。
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
}
しかし、パンデミックや政治危機など、予期せぬことが起こったらどうすればいいのでしょうか。
そんなときに役立つのが、いわば「サプライズ指数」のようなものです。これをコードに組み込むと想像してみましょう。
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
これにより、突発的な世界的な出来事とその影響の徐々に薄れていく様子を考慮に入れることができます。
しかし、最も興味深いのは、こうした出来事が予測にどのような影響を与えるかという点です。時には、世界的な事件が私たちの予想を完全に覆すこともあります。たとえば、危機の際には、米ドルやスイスフランなどの「安全通貨」が経済の理屈に反して強くなることがあります。
そういった局面では、モデルの予測精度が落ちることがあります。だからこそ、慌てずに柔軟に対応することが大切です。たとえば、予測期間を一時的に短くしたり、最新のデータにより大きな重みを与えたりすることを検討してみるのもよいでしょう。
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
覚えておいてください。通貨の世界もダンスのようなものです。大事なのは、そのリズムに合わせて柔軟に対応することです。たとえそのリズムが時には思いもよらない形で変わることがあってもです。
異常値の発見:経済データの中に潜む非明白なパターンを探す方法
さて、ここからが最も面白い部分です。データの中に隠された宝物を見つけるようなものです。証拠を探す探偵のような感覚ですが、ここでは証拠の代わりに数字やチャートを手がかりにします。
私たちのコードではすでに多くの経済指標を使っていますが、それらの間に非明白な繋がりがあるかもしれません。見つけてみましょう。
まずは異なる指標同士の相関関係を調べるところから始められます。
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
しかし、これはあくまで始まりにすぎません。本当の面白さは、非線形な関係を探し始めたときに始まります。たとえば、GDPの変化が為替レートに直ちに影響を与えるのではなく、数か月の遅れを伴って反映されることがあるかもしれません。
こうした遅延効果を捉えるために、データ準備の段階で「シフトした指標」を追加してみましょう。
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
これで、モデルは3か月および6か月の遅れを伴う依存関係も捉えることができるようになります。
しかし、最も興味深いのは、まったく予想外のパターンを探すことです。たとえば、EURの為替レートがアメリカのアイスクリームの売上と奇妙に相関しているなどということがあるかもしれません(もちろん冗談ですが、言いたいことは伝わると思います)。
こうした隠れた関係を見つけるためには、主成分分析(PCA: Principal Component Analysis)のような特徴量抽出手法を使うことができます。
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1]
これらの「隠れたパターン」は、より正確な予測の鍵になるかもしれません。
季節性も忘れないでください。通貨によっては、時期によって異なる動きをすることがあります。月や曜日の情報をデータに加えてみると、何か面白い発見があるかもしれません。
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
データの世界では、常に発見の余地があります。好奇心を持って実験を続けてください。もしかすると、取引の世界を変えるそのパターンを見つけるかもしれません。
結論:アルゴリズム取引における経済予測の展望
「経済データを使って為替レートの動きを予測できるか」というシンプルな問いから始めました。わかったことは、この考え方には一定の価値があるということです。しかし、一見したほど単純ではありません。
私たちのコードは経済データの分析を大きく簡素化しました。世界中から情報を集め、処理し、さらにはコンピューターに予測までさせることができるようになりました。しかし、最先端の機械学習モデルであっても単なるツールであることを忘れてはいけません。強力なツールではありますが、あくまでツールなのです。
CatBoostRegressorが経済指標と為替レートの複雑な関係性を見つけ出す様子を見てきました。これにより、人間の能力を超えてデータ処理と分析にかかる時間を大幅に短縮できます。しかし、どんなに優秀なツールでも未来を100%正確に予測することはできません。
なぜなら、経済は多くの要因に左右されるプロセスだからです。今日、誰もが石油価格を注視していても、明日には予想もしない出来事が世界を一変させるかもしれません。この点は「サプライズ指数」の話で触れた通りです。だからこそ重要なのです。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15998
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ここから持って いけこのテーマに関する古い記事。
今のところ、フライから取り出せるのは、今日現在のデータだけだ(((
私が理解できないのは、MQが何をするのかということだ。
それは上記の著者のシグナルだ。
このシグナルは純粋にSberのあるモデルをテストするために作られた。しかし、私はそれをテストしたことはなく、すでにマネー・マーケット・ファンドの通貨だけです。基本的に、私は自分のモデルで自分自身を取引していない、私は改善や開発のアイデアから離れることはできません))) 改善のための新しいアイデアが常にあります) そして、証券取引所では、私は主に株式に投資し、長期的には、私は非レズとしてMOEXで株式を購入し、Kazbirjiインデックス企業のKASEで。
今のところ、フライから得られるのは今日のデータが精一杯だ(((
私が理解する限り、データはモニタリングに接続されたアカウントで収集されるのですか?全てが正直であったとしても、大海の一滴である。
CFTCのデータの方が、スポットでなくオプション付き先物であっても信頼できる。2005年からの履歴が あり、あまり便利な形ではないが、Python用のAPIもあるだろう。
もちろん、それはあなた次第です。
このシグナルは、純粋にSberのあるモデルをテストするために作られた。しかし、私はそれをテストしたことはありません、それはすでにマネー・マーケット・ファンドのただの通貨です。基本的に、私は私のモデルで自分自身を取引していない、私は改善や開発のアイデアから離れることはできません))) 改善のための新しいアイデアが常にあります) そして、証券取引所では、私は主に株式に投資し、長期的には、私は非レズとしてMOEXで株式を購入し、Kazbirjiインデックス企業のKASEで。
そこに情報の矛盾がある、あなたにクレームはありません