
CatBoostモデルにおける交差検証と因果推論の基本、ONNX形式への書き出し
はじめに
これまでの記事で、機械学習アルゴリズムを使用して取引システムを作成する様々な方法を紹介してきました。かなりの成功を収めた物もあれば、(主に初期の出版物から)大幅に過学習だった物もあります。このように、私の記事の順序は、機械学習が実際に何ができるのかという理解の進化を反映しています。もちろん、これは時系列の分類の話です。
例えば、前回の「機械学習におけるメタモデル」稿では、2つの分類器の相互作用を通してパターンを見つけるアルゴリズムについて考えました。この非自明な方法が選ばれたのは、MLアルゴリズムは一般化と予測はよくできるが、因果関係の探索に関しては「怠け者 」だからです。つまり、因果関係がすでに確立されていて、それが新しいデータでも持続するような訓練例を一般化するのです。しかし、この接続は連想的、つまり通過的で信頼性の低いものになる可能性もあります。
このモデルは、どのような接続を扱っているのか理解していません。訓練データはすべて、訓練データとして認識されます。これは、初心者が新しいデータを使用して利益を上げる取引方法を教えようとする際に大きな問題となります。そこで前回の記事では、統計的に有意な予測を無作為な予測から切り離すために、アルゴリズムに自身の誤差を分析するよう教え込む試みをおこないました。
今回の記事は、前回のトピックを発展させたものであり、過剰適合を最小限に抑えながらデータのパターンを探すことができる自己訓練アルゴリズムの作成に向けた次のステップです。結局のところ、私たちは機械訓練の利用から真の効果を得たいのであり、機械訓練が訓練例を一般化するだけでなく、その中に因果関係があるかどうかを判断したいのです。
イン(理論)
このセクションでは、FXで「人工知能」を作り出そうとした結果得られた、ちょっとした経験に基づく主観的な推論がある程度含まれます。それはまだ愛ではなく、経験だからです。
結論が間違っていることが多く、検証する必要があるように、機械学習モデルによる予測結果も再確認する必要があります。再確認のプロセスを自分に向ければ、自制心が生まれます。機械学習モデルの自己制御は、異なるが似たような状況で何度も予測に誤りがないか確認することに尽きます。モデルのミスが平均的に少なければ過学習ではないことを意味しますが、頻繁にミスをする場合は、そのモデルに何か問題があることを意味します。
選択したデータでモデルを一度訓練すると、自己制御ができなくなります。無作為なサブサンプルでモデルを何度も訓練し、それぞれの予測の質を確認し、すべての誤差を合計すれば、実際に間違っているケースと、よく当たっているケースについて、比較的信頼性の高い図を得ることができます。これらのケースは、2つのグループに分けられ、互いに分離することができます。これは、ウォークフォワード検証や交差検証の実施に似ているが、追加要素があります。これが自制心を獲得し、よりロバストなモデルを得る唯一の方法です。
したがって、訓練データセットで交差検証をおこない、モデルの予測値と訓練ラベルを比較し、すべてのフォールドで結果を平均化する必要があります。平均的に誤って予測された例は、最終的な訓練セットから誤りとして削除されるべきです。また、予測可能なケースと予測不可能なケースを区別し、すべての可能な結果をより完全にカバーできるようにするために、すべてのデータに対して2つ目のモデルを訓練する必要があります。
悪い訓練例が取り除かれた場合、メインモデルの分類誤差は小さくなりますが、取り除かれたケースの予測性能は低くなります。精度は高いですが、再現性は低いです。ここで2つ目の分類器を追加し、1つ目のモデルがうまく分類できるように学習したケースでのみ、1つ目のモデルに取引をさせるように教えれば、TS全体の結果が改善されるはずです。
最初のモデルのエラーは2番目の分類器に転送されるが、どこにも消えないことがわかりました。しかし、取引の方向性を直接予測するわけではなく、データの網羅性が高いため、このような予測は依然として価値があります。
ここでは、2つのモデルで十分であり、その肯定的な結果で訓練エラーを補うことができると仮定します。
そこで、悪い訓練例を排除することで、平均的に利益をもたらす状況を探し、平均的に損失を出すような場所では取引しないようにします。
アルゴリズムの核心
meta_learner関数はアルゴリズムの中核であり、上記のすべてをおこなうので、より詳細に分析する必要があります。残りの関数は補助的なものです。
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=folds_number) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 return data[data.columns[1:]]
以下が受け入れられます。
- 交差検証のフォールド数
- ベース訓練器の訓練反復回数
- ベース学習ツリーの深さ
- 勾配ステップ
これらのパラメータは最終的な結果に影響するので、経験的に選択するか、グリッドを使用して選択する必要があります。
scikit learnパッケージのcross_val_predict関数は、各訓練例の交差検証スコアを返し、次にこれらのスコアを元のラベルと比較します。予測が正しくない場合、その予測は悪い例の帳簿に登録され、それに基づいて2番目の分類器のための「メタラベル」が生成されます。
この関数は、渡されたデータフレームに「メタラベル」を追加して返します。このデータフレームは、コードで示されるように、最終モデルの訓練に使用されます。
# features for model\meta models. We learn main model only on filtered labels X, X_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[:-2]] X = X[X.columns[:-2]] # labels for model\meta models y, y_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[-1]] y = y[y.columns[-2]]
上のコードでは、最初のモデルは、メタラベルが1に対応する行、つまり良い訓練例としてマークされた行に対してのみ訓練されることが示されています。2つ目の分類器は、データセット全体に対して訓練されます。
その後、2つの分類器が単純に訓練されます。1つは売買の確率を予測するもので、もう1つは売買する価値があるかどうかを判断するものです。
ここで、各モデルは、ハイパーパラメータには含まれない独自の訓練パラメータも持っています。これらは個別に設定できますが、この最終段階でモデルが過学習にならないように、意図的に100に等しい少ない反復回数を選びました。訓練サンプルとテストサンプルの相対的なサイズを変更することができ、これも最終結果に若干の影響を与えます。一般に、最初のモデルは、よく分類された例に対してのみ訓練されるので、訓練は非常に簡単です。モデルが複雑である必要はありません。2つ目のモデルはより複雑なタスクがあるため、モデルの複雑さを増すことができます。
# train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False)
アルゴリズムのハイパーパラメータ
訓練を開始する前に、最終結果にも影響するすべての入力パラメーターを正しく設定する必要があります。
export_path = '/Users/dmitrievsky/Library/Application Support/MetaTrader 5/\ Bottles/metatrader5/drive_c/Program Files/MetaTrader 5/MQL5/Include/'
# GLOBALS SYMBOL = 'EURUSD' MARKUP = 0.00015 PERIODS = [i for i in range(10, 50, 10)] BACKWARD = datetime(2015, 1, 1) FORWARD = datetime(2022, 1, 1)
- 訓練済みモデルを保存するためのインクルード端末フォルダへのパス
- 銘柄のティッカー
- スプレッド、手数料、スリッページを含む平均マークアップ(ポイント単位)
- 価格増分の計算に使用される移動平均期間。これらはモデルを訓練するための属性です。
- 訓練の日付範囲:この範囲の左側と右側は、新しいデータに対するテストの訓練なし(OOS)の履歴です。
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame:
この関数は引数minとmaxを持ち、無作為に取引をサンプリングします。各新規取引は小節単位で無作為な期間が設定されます。同じ値を設定すれば、すべての取引は固定期間となります。
補助関数とライブラリ
作業を始める前に、必要なパッケージがすべてインストールされ、インポートされていることを確認してください。
import numpy as np import pandas as pd import random import math from datetime import datetime import matplotlib.pyplot as put from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.model_selection import cross_val_predict
次に、MetaTrader 5端末から相場を書き出します。必要な銘柄、時間枠、履歴の深さを選択し、Pythonプロジェクトの/filesサブディレクトリに保存します。
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/EURUSD_H1.csv', delim_whitespace=True) pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<CLOSE>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') pFixed = pFixed.dropna() pFixedC = pFixed.copy() count = 0 for i in PERIODS: pFixed[str(count)] = pFixedC.rolling(i).mean() - pFixedC count += 1 return pFixed.dropna()
強調表示されたコードは、ボットがどこから相場を取得し、PERIODSリストでハイパーパラメーターとして指定された移動平均から終値を引くことによって属性をどのように作成するかを示しています。
その後、生成されたデータセットは、ラベル(または目標)をマーキングするための次の関数に渡されます。
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame: labels = [] meta_labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if future_pr < curr_pr: labels.append(1.0) if future_pr + MARKUP < curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) elif future_pr > curr_pr: labels.append(0.0) if future_pr - MARKUP > curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) else: labels.append(2.0) meta_labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset['meta_labels'] = meta_labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
この関数は、同じデータフレームを返しますが、labelsとmeta labels列が追加されます。
テスター関数は大幅に高速化されました。これで大きなデータセットを読み込んでも、テスターの動作が遅くなる心配はなくなりました。
def tester(dataset: pd.DataFrame, plot= False): last_deal = int(2) last_price = 0.0 report = [0.0] chart = [0.0] line = 0 line2 = 0 indexes = pd.DatetimeIndex(dataset.index) labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() close = dataset['close'].to_numpy() for i in range(dataset.shape[0]): if indexes[i] <= FORWARD: line = len(report) if indexes[i] <= BACKWARD: line2 = len(report) pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta==1: last_price = pr last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 report.append(report[-1] - MARKUP + (pr - last_price)) chart.append(chart[-1] + (pr - last_price)) continue if last_deal == 1 and pred < 0.5 and pred_meta==1: last_deal = 2 report.append(report[-1] - MARKUP + (last_price - pr)) chart.append(chart[-1] + (pr - last_price)) y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(chart) plt.axvline(x = line, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x = line2, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
すでに訓練済みのモデルをテストするための補助関数の外観が、より簡潔になりました。モデルのリストを入力として受け取り、クラス確率を計算し、テスト用の特徴とラベルを持つ既製のデータフレームと同じようにテスターに渡します。したがって、テスター自身は、元の訓練データフレームと、すでに訓練されたモデルからの予測を受け取った結果として生成されたデータフレームの両方で動作します。
def test_model(result: list, plt= False): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
ヤン(練習)
ハイパーパラメータを設定した後、モデルの訓練に直接進み、これはループで実行されます。
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learner(folds_number= 5, iter= 150, depth= 5, l_rate= 0.01)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
ここでは、25のモデルを訓練し、その後テストして MetaTrader 5端末に書き出しします。
訓練結果は、選択したパラメータ、訓練とテストの日付の範囲、および取引の期間に最も強く影響されます。これらの設定を試してみるべきです。
新しいデータを考慮したR^2によるベストモデルのトップ5を見てみましょう。グラフの横線は左右のOOSを示しています。
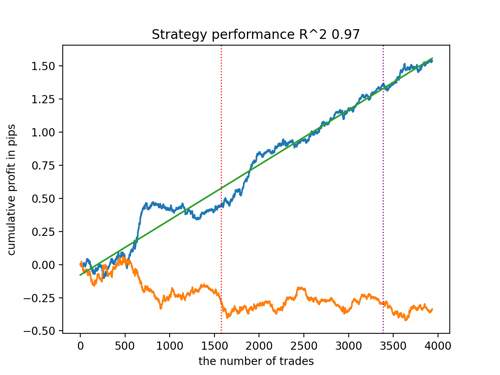
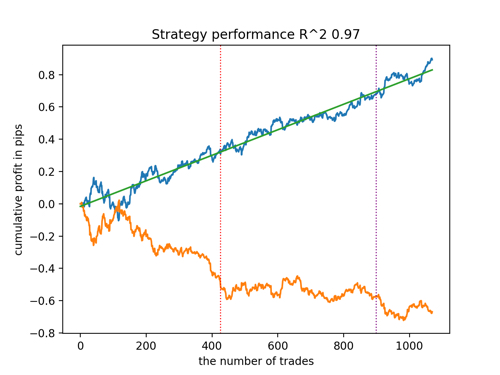
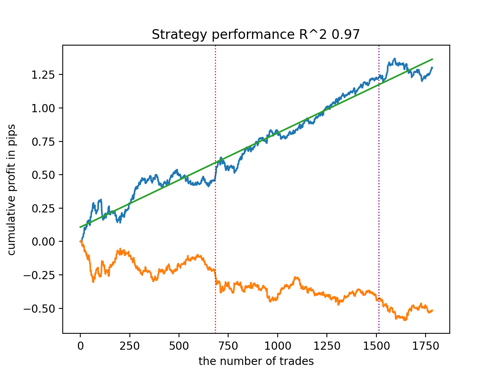
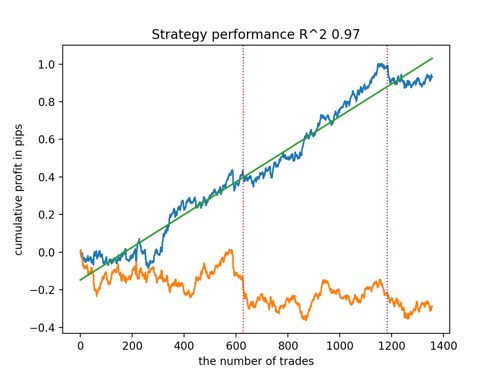
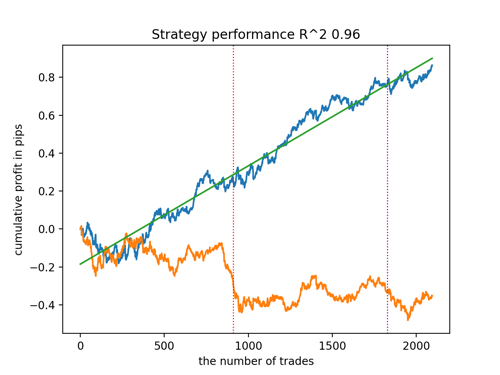
残高グラフは青で、相場グラフは橙色で示されています。すべてのモデルが互いに異なることがわかります。これは、取引の無作為サンプリングと、各モデルに組み込まれた無作為化によるものです。しかし、これらのモデルはもはやテスト用の宝石のようには見えず、OOSでもかなり自信を持って機能します。さらに、取引回数、ポイント利益、曲線の一般的な外観を比較することもできます。もちろん、1つ目と2つ目のモデルは良い比較をしているので、端末に書き出しします。
訓練パラメーターを変更し、何度か再開させることで、ユニークな挙動が得られることを念頭に置くべきです。グラフが同じになることはほとんどありませんが、そのうちのかなりの部分(これは重要)はOOSでうまく表示されます。
モデルをONNX形式に書き出す
以前の記事で、cppからMQLへの解析モデルを使用しました。現在、MetaTrader 5端末は、ONNX形式へのモデルの読み込みをサポートしています。これは、Pythonで訓練されたほぼすべてのモデルを、より少ないコードで転送することができるため、非常に便利です。
CatBoostアルゴリズムは、ONNX形式でモデルを書き出す独自のメソッドtitlehttps://catboost.ai/ja/docs/concepts/apply-onnx-mlmethodtitleを持ちます。書き出しのプロセスを詳しく見てみましょう。
出力には、2つのCatBoostモデルと、インクリメントの形で特徴を生成する関数があります。この関数は非常に単純なので、ボットコードに移すだけで、モデルはONNXファイルに書き出されます。
def export_model_to_ONNX(model, model_number): model[1].save_model( export_path +'catmodel' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) model[2].save_model( export_path + 'catmodel_m' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) code = '#include <Math\Stat\Math.mqh>' code += '\n' code += '#resource "catmodel'+str(model_number)+'.onnx" as uchar ExtModel[]' code += '\n' code += '#resource "catmodel_m'+str(model_number)+'.onnx" as uchar ExtModel2[]' code += '\n' code += 'int Periods' + '[' + str(len(PERIODS)) + \ '] = {' + ','.join(map(str, PERIODS)) + '};' code += '\n\n' # get features code += 'void fill_arays' + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods''[i],pr);\n' code += ' ret[0] = MathMean(pr) - pr[Periods[i]-1];\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(SYMBOL) + ' ONNX include' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
書き出し関数は、モデルのリストを受け取ります。それぞれ、オプションの書き出しパラメータとともにONNXに保存されます。このコードはすべて、モデルを端末のインクルードフォルダに保存し、次のような.mqhファイルも生成します。
#resource "catmodel.onnx" as uchar ExtModel[] #resource "catmodel_m.onnx" as uchar ExtModel2[] #include <Math\Stat\Math.mqh> int Periods[4] = {10,20,30,40}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods[i],pr); ret[0] = MathMean(pr) - pr[Periods[i]-1]; ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
次に、これをボットに接続する必要があります。各ファイルは、銘柄のティッカーと末尾のモデルシリアル番号で指定された固有の名前を持っています。したがって、このような訓練済みモデルのコレクションをディスクに保存したり、複数のモデルを一度にボットに接続したりすることができます。デモンストレーションのため、1つのファイルに限定します。
#include <EURUSD ONNX include1.mqh> この関数では、以下のようにモデルを正しく初期化する必要があります。 最も重要なことは、入力データと出力データの寸法を正しく設定することです。ここでのモデルは、PERIODSリストまたは書き出しされた配列に指定された特徴数に応じて可変長の特徴ベクトルを持つので、入力ベクトルの次元を以下のように定義します。どちらのモデルも同じ数の特徴を入力として受け取ります。
出力ベクトルの次元が混乱を招くかもしれません。
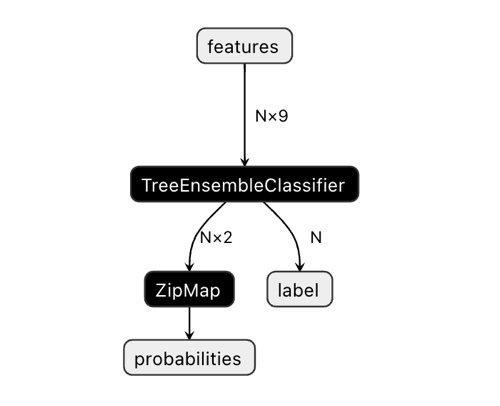

Netronアプリケーションでは、モデルには2つの出力があることがわかります。最初のものは単位テンソルであり、クラスラベルはゼロ出力またはゼロインデックス出力としてコードの後半で定義されます。しかし、CatBoostのドキュメントに記載されている既知の問題があるため、予測には使用できません。
「二値分類の場合、ラベルの推測が間違っています。これはonnxruntimeの実装における既知のバグです。バイナリ分類の場合、このパラメータの値は無視します。」
従って、2番目の「確率」出力を使うべきなのですが、MQLのコードでそれを正しく設定することができなかったので、単純に定義しませんでした。しかし、それ自体で定義され、すべてが機能しています。その理由は分かりません。
したがって、2番目の出力は、ボットのクラス確率を求めるために使用されます。
const long ExtInputShape [] = {1, ArraySize(Periods)};
int OnInit() { ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); ExtHandle2 = OnnxCreateFromBuffer(ExtModel2, ONNX_DEFAULT); if(ExtHandle == INVALID_HANDLE || ExtHandle2 == INVALID_HANDLE) { Print("OnnxCreateFromBuffer error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetInputShape(ExtHandle, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle); return(-1); } if(!OnnxSetInputShape(ExtHandle2, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle2); return(-1); } const long output_shape[] = {1}; if(!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetOutputShape(ExtHandle2, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); }
モデル信号の受信は、このように実装されています。ここでは、特徴の配列を宣言し、書き出された.mqhファイルにあるfill_arrays()関数を使用してそれを埋めます。
次に、特徴配列の値の順序を反転させるために別の配列fを宣言し、Onnx Runtimeに送信して実行させました。ベクトルとしての最初の出力は渡すだけでよいですが、今回は使用しません。構造体の配列は2番目の出力として渡されます。
モデル(メインとメタ)が実行され、予測値をテンソル配列に返します。私はそこから二流の確率を取ります。
void OnTick() { if(!isNewBar()) return; double features[]; fill_arays(features); double f[ArraySize(Periods)]; int k = ArraySize(Periods) - 1; for(int i = 0; i < ArraySize(Periods); i++) { f[i] = features[i]; k--; } static vector out(1), out_meta(1); struct output { long label[]; float tensor[]; }; output out2[], out2_meta[]; OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, out, out2); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f, out_meta, out2_meta); double sig = out2[0].tensor[1]; double meta_sig = out2_meta[0].tensor[1];
残りのボットコードは、前回の記事でお馴染みのはずです。meta_sigの有効化信号を確認します。それが0.5より大きい場合、最初のモデルのsig信号によって指定された方向に応じて、取引の開始と終了が許可されます。
if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } } if(meta_sig > 0.5) if(countOrders() < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(meta_sig), ORDER_TYPE_BUY)) { double l = LotsOptimized(meta_sig); if(sig < 0.5) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = OrderSend(Symbol(), OP_BUY, l, Ask, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } else { if(sig > 0.5) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = OrderSend(Symbol(), OP_SELL, l, Bid, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } } }
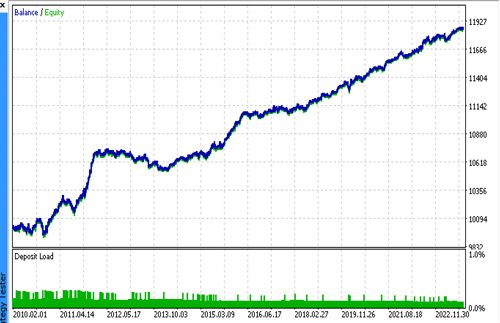
最終テスト
気に入ったモデルを持つ2つのファイルを順次接続し、カスタムテスターの結果がMetaTrader 5テスターの結果と完全に一致することを確認してみましょう。
さらに、実際のティックでボットをテストし、損切りと利食いを最適化し、ロットサイズを選択し、MetaTrader 5のオプティマイザーでさらに取引を追加することができます。
最後の言葉
取引のタスクのために時系列を分類するこのアプローチに科学的根拠があるかどうかはわかりません。試行錯誤の末に発明されたもので、私には非常に興味深く、有望に思えました。
この小さな研究で、私は、機械訓練モデルは時として、自明と思われるものとは異なる方法で訓練されるべきであることを強調したかったのです。特定のアーキテクチャに加え、これらのモデルの適用方法も非常に重要です。同時に、この記事で紹介した完全自動の「トレーダー兼研究者」的アプローチであれ、「教師」EAの介入を必要とする、より単純なアルゴリズムであれ、訓練結果を分析するための統計的アプローチが前面に出てきています。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/11147
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
奇妙だ...まるで1対1のコピーのようだ。
その通りだが、モデルの反応が違う
k...アーティファクト、はい、取り除けます。
その通り、モデルの反応は異なる
k...アーティファクト。
シリアライズがfeaturesに設定されているのを見た。だから結果が違うのだろう。
奇妙だ...。1対1でコピーされているようです。
UPD: OnnxRunのヘルプにある例では、チップはマトリックスで渡されているのに対して、あなたのは配列で渡されている。ヘルプに書いてあるとおりにならないのは不思議です。
ONNXモデルの入出力値として渡せるのは、配列、ベクトル、行列 ( 以下Data)のみです 。
ベクトルでも間違った反応が返ってきたようだ。再確認が必要だが、今のところ動作している。
https://www.mql5.com/ja/docs/onnx/onnx_types_autoconversion
ありがとう。私のデータセットで単純なMLP、RNN、LSTMとboustingの結果を比較しました。大差はなく、boustingの方が優れていることもありました。boustingの方が学習速度が速く、アーキテクチャをあまり気にする必要がありません。というのも、NSは拡張性があり、NSの様々なバリエーションを構築することができるからだ。この点ではNSの方が優れている。