
統計の基礎

はじめに
統計とは?ここに、Wikipediaで見られる定義があります:「統計は、収集、構成、分析、実行、データの表現に関する研究です」 (統計学). この定義は、統計の3つの主要な要素を提示しています。: データ収集、測定、そして、分析です。データ分析 は、取得した情報がブローカーや、トレーディングターミナルによって提供され、すでに測定されている祭、特に役に立ちます。
現代のトレーダー(大半)は、テクニカル分析を使用し、買いか売りかを決定します。特定のインジケーターを使用するか、最近の期間における価格レベルを予想しようとする際に、なすことすべてにおいて統計を扱っています。実際、価格の変動チャートは、特定の時間における株や通貨の統計を表示しています。そのため、トレーダーにとって意思決定を促進する仕組みの多くの根底にある統計の基礎法則を理解することがとても重要です。
確率理論と統計
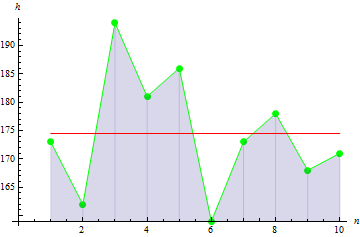
いかなる統計も、オブジェクトの変化の結果です。1時間のタイムフレームでのEURUSD価格チャートを考えてみましょう:

この場合、そのオブジェクトは、統計がその価格である一方、二つの通貨の相関です。二つの通貨の相関関係が価格にどのように影響するのでしょうか?なぜこの価格チャートを持ち、特定の時間間隔での異なる価格チャートを持たないのでしょうか?なぜその価格は、現在下降し、上昇しないのでしょうか?これらの質問に対する答えは、'確率'という単語です。確率に応じて、すべてのものは様々な値を持ちます。
簡単な実験をしてみましょう:コインを取り、特定の回数指で弾き、毎度トスの結果を記録します。フェアなコインを持っていると想定します。その時、それに対する図表は以下のようになります:
| 結果 | 確率 |
|---|---|
| 頭 | 0.5 |
| 尾 | 0.5 |
その図表は、そのコインは、等しく頭と尾になると示しています。すべての起こりうるイベントの確率の合計は1に等しく、その他の結果は、不可能です(コインの淵でたったものは排除しています)
10回コインを弾いてください。トス結果をみてみましょう:
| 結果 | 数 |
|---|---|
| 頭 | 8 |
| 尾 | 2 |
もしコインがどちらか片側で等しく着地するなら、どうしてこのような結果が出たのでしょうか?片側で着地するコインの確率は、実際等しいですが、数回のトスの後、コインが片側の回数と同じ回数を別側で着地するというわけではありません。この特定の試みにおいては、そのコインは頭をあげるか、尾をあげるか、両方のイベントが同じ確率を持ちます。
100回コインを弾いてみましょう。新しい結果の図表を得ました:
| 結果 | 数 |
|---|---|
| 頭 | 53 |
| 尾 | 47 |
ご覧の通り、また結果の数は等しくはありません。しかしながら、53と47は、最初の確率の想定を証明する結果です。そのコインは、尾で着時するのと同じ数を頭で着地しました。
逆の順序で同じことをやってみましょう。コインはありますが、片側への着地の確率はわからないと想定します。もしフェアなコインであれば、それは、等しく両面で着地するか判断します。
最初の実験からデータを取得しましょう。合計の結果の数によって片側の結果の回数を割り算します。以下の確率を得ることができます:
| 結果 | 確率 |
|---|---|
| 頭 | 0.8 |
| 尾 | 0.2 |
コインがフェアなものか最初の実験からは結論付けることは難しいです。二番目の実験を同じように行います。
| 結果 | 数 |
|---|---|
| 頭 | 0.53 |
| 尾 | 0.47 |
これらの結果により、これはフェアなコインであると高い正確さを持っていうことができます。
このシンプルな例により、重要な結論を導くことができます: 実験の回数が多ければ、オブジェクトの性質は、生成される統計により正確さを増して反映されます。.
従って、統計や確率は、密接に関連しています。統計は、オブジェクトにおける実験結果を示し、そのオブジェクトの確率に直接依存します 。逆に、オブジェクトの確率は、統計により推定できます。. ここに、トレーダーの主要なチャレンジ があります。: 特定の期間におけるトレードのデータを所有し、以下の期間における価格の 予想を行うことや、この情報に基づき買い売り決定を行うこと.などです。
イントロダクションにて指摘されたポイントに立ち返ると、 統計と確率の関係性を知り、理解すること、また、リスク評価やリスクの状況における知識を持つことは、重要です。後者は、この記事の範囲外です。
基礎的な統計パラメーター
基礎の統計パラメーターを見てみましょう。グループ10人に関してcmにて身長のデータを取得します。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 身長 | 173 | 162 | 194 | 181 | 186 | 159 | 173 | 178 | 168 | 171 |
図表にセットされたデータは、サンプルと呼ばれ、一方データ量は、 サンプルサイズです。そのサンプルのいくつかのパラメーターを見ていきます。すべてのパラメーターは、サンプルパラメーターであり、ランダム変数データではなく、サンプルデータに由来します。
1. サンプル平均値
サンプル平均値は、サンプルの平均の値です。この場合、グループの中の人々の平均身長になります。
平均値を計算するために, 以下を行う必要があります:
- すべてのサンプル値を合計する.
- サンプルサイズにより合計値を割る。
公式:
![]()
Where:
- M はサンプル平均値です。
- a[i]は、サンプル要素です。
- nは、サンプルサイズです。
計算の後、174.5 cmという平均値を取得します。
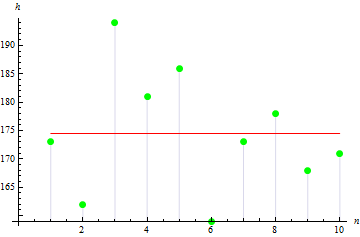
2. サンプル分散
サンプル分散は、サンプル値がサンプル平均値から離れているかを示します。その値が大きければ、データがより広く分散しています。
その分散を計算するために、以下を行う必要があります;
- サンプル平均値を計算する。
- それぞれのサンプル要素から平均値を引き、差異を二乗します。
- 上記で得た値を合計します。
- サンプルサイズー1で、合計を割り算します。
公式:
![]()
- Dは、サンプル分散です。
- M はサンプル平均値です。
- a[i]は、サンプル要素です。
- nは、サンプルサイズです。
この場合のサンプル分散は、113.611.
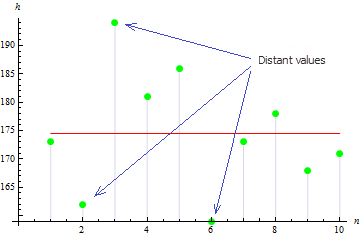
その数字によれば、3つの値は、平均値から広く分散され、大きい分散値となっています。
3. サンプル歪度
サンプル歪度は、平均値におけるサンプル値の対称性の度合いを示すために使用されます。歪度値が0に近ければ、サンプル値は、より対称性を持ちます。
歪度を計算するために;
- サンプル平均値を計算する。
- サンプル分散を計算する。
- 各サンプル要素と、平均値の差異の3乗を合計します。
- 2/3の乗数まで上げられた分散値により答えを割り算します。
- サンプルサイズ−1とサンプルサイズー2により割られたサンプルサイズの値に等しい係数と答えを掛けます。
公式:
![]()
- Aは、サンプル歪度です。
- Dは、サンプル分散です。
- M はサンプル平均値です。
- a[i]は、サンプル要素です。
- nは、サンプルサイズです。
このサンプルにおいてかなり小さい歪度を得ました。: 0.372981. これは、分散値がそれぞれ埋め合わせているためです。
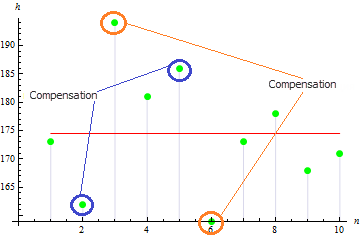
その値は、非対称サンプルにおいて大きくなります。例えば、以下のデータの値は、1.384651になります。
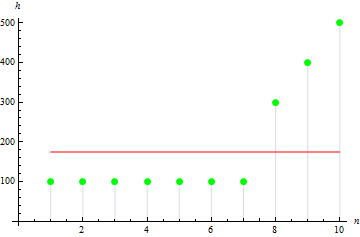
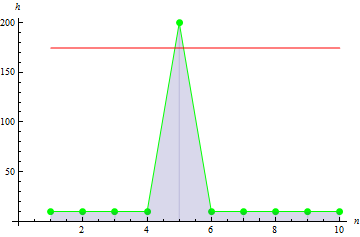
4. サンプル尖度
サンプル尖度は、サンプルの尖りを示します。
尖度を計算するためには:
- サンプル平均値を計算する。
- サンプル分散を計算する。
- それぞれのサンプル要素と平均値の差異の4乗を合計する。
- 二乗された分散値により割る。
- サンプルサイズー1、サンプルサイズー2、サンプルサイズー3により割られたサンプルサイズ+1とサンプルサイズに等しい、係数により結果の値を掛けます。
- サンプルサイズー1、サンプルサイズー2により割られたサンプルサイズと1の差異のの二乗と3を結果の値から引きます。
公式:
![]()
- Eは、サンプル尖度です。
- Dは、サンプル分散です。
- M はサンプル平均値です。
- a[i]は、サンプル要素です。
- nは、サンプルサイズです。
その身長データにおいては、0.1442285の値を取得できます。
より鋭いデータにおいては、より大きい値;10を得ます。
5. サンプル共分散
サンプル共分散は、二つのデータサンプル間の線形従属の度合いを示します。線形独立データ間の共分散は、0になります。
このパラメーターを紹介するために、それぞれの10人に体重データを追加します。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 体重 | 65 | 70 | 83 | 60 | 105 | 58 | 69 | 90 | 78 | 65 |
二つのサンプルの共分散を計算するために:
- 最初のサンプルの中間値を計算する。
- 二番目のサンプルの中間値を計算する。
- 二つの差異を合計します:最初の差異 - 最初のサンプル要素ー最初のサンプルの中間値;二番目の差異 - 二番目のサンプル要素(最初のサンプル要素と一致します)ー二番目のサンプル中間値
- サンプルサイズ−1によりその答えを割ります。
公式:
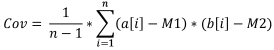
- Covは、サンプル共分散です。
- a[i]は、最初のサンプル要素です。
- b[i]は、二番目のサンプル要素です。
- M1は、最初のサンプル中間値です。
- M2は、二番目のサンプル中間値です。
- nは、サンプルサイズです。
二つのサンプル値の共分散を計算しましょう: 91.2778. 既存の従属は、組み合わされたチャートにて示されています。
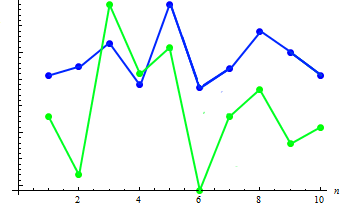
ご覧の通り、身長の上昇は体重の減少に一致します、逆もしかりです。
6. サンプル相関
サンプル相関は、二つのデータサンプル間の線形従属の度合いを示すために使用されますが、その値は、-1から1の間にあります。
二つのサンプルを計算するためには;
- 最初のサンプルの分散を計算する・
- 二番目のサンプルの分散を計算する。
- これらのサンプルの共分散を計算する。
- 分散値の平方根により共分散を割る。
公式:
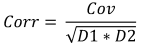
- Corrは、サンプル相関です。
- Covは、サンプル共分散です。
- D1は、最初のサンプルの分散です。
- D2は、二番目のサンプルの分散です。
特定の身長と体重データにおいて、相関は0.579098に等しいです。
トレーディングにおいて統計を使用する方法
トレーディングにおいての統計パラメーターの使用を示すシンプルな例は、MovingAverageインジケーターです。その計算は、特定の期間内のデータを必要とし、価格の中間値を出します。
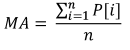
Where:
- MAは、インジケーター値です。
- P[i]は価格です。
- nは、MAの測定期間です。
インジケーターがサンプル中間値の類似物であるとわかります。その単純さにも関わらず、このインジケーターは、トレンド強度や方向を判断する古典的ツールのMACDインジケーターにおいて必要な要素である指数移動平均、EMAを計算する際に使用されます。

MQL5での統計
上記の基礎的な統計パラメーターのMQL5の実装を見ていきます。上記の統計メソッドは、統計関数ライブラリ statistics.mqhにて実装されています。コードを見てみましょう。
1. サンプル平均値
サンプル平均値を計算するライブラリ関数は、Averageと呼ばれています;

入力データ;データサンプル出力データ:平均値
2. サンプル分散
サンプル分散を計算するライブラリ関数は、Varianceと呼ばれています。

入力データ:データサンプルと平均値出力データ:分散
3. サンプル歪度
歪度を計算するライブラリ関数は、Asymmetryと呼ばれます。

入力データ;データサンプル、平均値、分散。出力データ:歪度
4. サンプル尖度
サンプル尖度を計算するライブラリ関数は、Excessと呼ばれます(Excess2)

入力データ;データサンプル、平均値、分散。出力データ:尖度
5. サンプル共分散
サンプル共分散を計算するライブラリ関数はCovと呼ばれます。

入力データ;二つのデータサンプル、それぞれの平均値 出力データ:共分散
6.サンプル相関
サンプル相関値を計算するライブラリ関数はCorrと呼ばれます。

入力データ;二つのサンプルの共分散、最初のサンプルの分散、二番目のサンプルの分散出力データ;相関
身長と体重のサンプルデータ入力し、ライブラリを使用して処理します。#include <Statistics.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- specify two data samples. double arrX[10]={173,162,194,181,186,159,173,178,168,171}; double arrY[10]={65,70,83,60,105,58,69,90,78,65}; //--- calculate the mean double mx=Average(arrX); double my=Average(arrY); //--- to calculate the variance, use the mean value double dx=Variance(arrX,mx); double dy=Variance(arrY,my); //--- skewness and kurtosis values double as=Asymmetry(arrX,mx,dx); double exc=Excess(arrX,mx,dx); //--- covariance and correlation values double cov=Cov(arrX,arrY,mx,my); double corr=Corr(cov,dx,dy); //--- print results in the log file PrintFormat("mx=%.6e",mx); PrintFormat("dx=%.6e",dx); PrintFormat("as=%.6e",as); PrintFormat("exc=%.6e",exc); PrintFormat("cov=%.6e",cov); PrintFormat("corr=%.6e",corr); }
そのスクリプットを実行後、そのターミナルは、以下のような結果を生み出します:
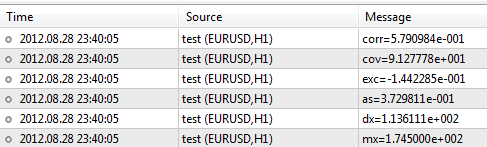
そのライブラリは、より多くの関数を含み、その記述は、CodeBase - https://www.mql5.com/ja/code/866にてご覧になれます。
結論
いくつかの結論がすでに「確率理論と統計」セクションの最後に導かれていました。上記に加えて、その他の科学と同様、統計はABCにから研究されます。基礎的な要素でさえ、日の終わりにはトレーダーの仕事においてとても必要な複雑な仕組みやパターンの多くの理解を促進させてくれます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/387
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 未知の確率密度関数のカーネル密度推定
未知の確率密度関数のカーネル密度推定
 自作 DLL の排除
自作 DLL の排除
 アルゴリズム取引に関する記事を投稿して200ドルを獲得できます
アルゴリズム取引に関する記事を投稿して200ドルを獲得できます
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
改造を決定するアルゴリズムはいくらでもあるはずだから、万能の自転車はここでは役に立たない。
むしろ、何を手に入れたいのか、何を手に入れたくないのか、例を見るべきだ。
私はこの記事が気に入った。
とても分かりやすく、十分な情報が含まれている。
そして、タイトルから判断するに、それ以上を装っていない。
この記事には何の役にも立たない。テレビの決まり文句の数々。そして、この記事が半ばトレーダーのような専門サイトに掲載されなければ、黙っていることも可能だろう。しかし、このサイトのことを考えると、以下のことを記しておきたい。
経済データを測定、分析、予測する科学がある。それは計量経済学と 呼ばれる。統計学とは血のつながった近い親戚だが、大きな違いがある。
1.トレーダーにとって、分析から予測が導かれなければ、分析そのものに価値はない。この記事では予測についてまったく触れていない。
2.計量経済学は当初、経済系列の非定常性から出発する。非定常系列に対しては、moや分散などの基本的な概念は、多くの留保付きで適用することができる。いずれにせよ、常に疑ってかかるべきである。例えば、非定常系列では、平均は必ずしもmoに収束しない。相関の話ではない。
3. 計量経済学は非常に短いサンプル、つまり数十の観測に基づいている。そのような平均は数年間ポーズをとっていることを意味するからである。危機においては、計算結果の推定が 重要になる。テレビと統計学、特に計量経済学を根本的に区別するのは、この推定値である。
学校の記事。特別な学校のレベル、研究所のジュニアコースでもない。
"この単純な例から、我々は重要な結論を導き出すことができる:試行回数が増えれば増えるほど、統計はそれらを生成 する オブジェクトの特性を より正確に反映する。"
定常過程(真空中の球形の馬)の場合 - はい。
実データの時系列の場合、この声明はナンセンスに近い。
もしFXが定常時系列であれば、それを推定するためにMQL5は必要ないだろう。食料品店で売っているシンプルな木のブラシで十分だ。
、全期間の統計は、RosStatのレポート、あるいは狂人の戯言のようなものになるだろう。
「ある期間の取引データ(統計)を知り、 次の期間の価格(レート)の動きを予測 し(確率を得る)、それに基づいて売買の判断を 下す。
という発言は、意味としてはナンセンスと言えなくもない。何かを予測するためには、まずその系列がランダムではなく、予測可能であることを自分で証明しなければならない。確率の非対称性と正負の期待値。
。