データサイエンスと機械学習(第13回):主成分分析(PCA)で金融市場分析を改善する

「PCAは、データ分析と機械学習の基本的な手法であり、画像と信号の処理から金融と社会科学に至るまでのアプリケーションで広く使用されています。」
デビッド・J・シェスキン
はじめに
主成分分析(PCA)は、大きなデータセットの次元を削減するためによく使用される次元削減手法です。これは、変数の大きなセットを、大きなセット内のほとんどの情報をまだ含む小さな変数に変換することによっておこなわれます。
データセット内の変数の数を減らすと、通常は精度が犠牲になりますが、次元削減の秘訣は、単純化のために精度をほとんど犠牲にすることです。あなたも私も、データセット内のいくつかの変数を使用すると、探索、視覚化が容易になり、機械学習アルゴリズムのデータ分析がはるかに簡単かつ高速になることを知っています。私は個人的に、正確さのためにシンプルさを犠牲にすることは悪いことではないと思います。正確さは必ずしも利益を意味するわけではありません。

PCAの主なアイデアは、核となる非常に単純なものです。できるだけ多くの情報を保持しながら、データセット内の変数の数を減らします。主成分分析アルゴリズムに含まれる手順を見てみましょう。
主成分分析アルゴリズムに含まれる手順
- データを標準化する
- 行列の共分散を見つける
- 固有ベクトルと固有値を見つける
- PCAスコアを見つけて標準化する
- コンポーネントを取得する
それでは早速、データの標準化から始めましょう。
01:データを標準化する
データを標準化する目的は、すべての変数のスケールを揃えて、対等な立場で比較および分析できるようにすることです。データを分析する場合、変数の測定単位やスケールが異なることが多く、これが偏った結果や誤った結論につながる可能性があります。たとえば、移動平均指標の価格帯は市場価格と同じですが、RSI指標の値は通常0~100です。これら2つの変数は、任意のモデルで一緒に使用すると、比類のないものになります。それらを意味のある方法で一緒に使用することはできません。
データの標準化では、平均が0になり、標準偏差が1になるように各変数を変換します。 これにより、各変数のスケールと分布が同じになり、直接比較できるようになります。データの標準化は、特に変数の大きさや分散が異なる場合に、機械学習モデルの精度と安定性を向上させるのにも役立ちます。
ポイントを示すために、血圧データを使用します。私は通常、物事を構築するためだけにさまざまな種類の無関係なデータを使用します。この種のデータは人間に関連しているため、物事の理解とデバッグが容易になるからです。
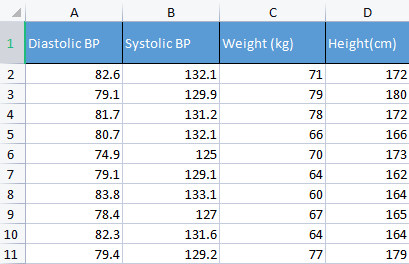
matrix Matrix = matrix_utiils.ReadCsv("bp data.csv"); pre_processing = new CPreprocessing(Matrix, NORM_STANDARDIZATION);
前後の比較:
CS 0 10:17:31.956 PCA Test (NAS100,H1) Non-Standardized data CS 0 10:17:31.956 PCA Test (NAS100,H1) [[82.59999999999999,132.1,71,172] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.09999999999999,129.9,79,180] CS 0 10:17:31.956 PCA Test (NAS100,H1) [81.7,131.2,78,172] CS 0 10:17:31.956 PCA Test (NAS100,H1) [80.7,132.1,66,166] CS 0 10:17:31.956 PCA Test (NAS100,H1) [74.90000000000001,125,70,173] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.09999999999999,129.1,64,162] CS 0 10:17:31.956 PCA Test (NAS100,H1) [83.8,133.1,60,164] CS 0 10:17:31.956 PCA Test (NAS100,H1) [78.40000000000001,127,67,165] CS 0 10:17:31.956 PCA Test (NAS100,H1) [82.3,131.6,64,164] CS 0 10:17:31.956 PCA Test (NAS100,H1) [79.40000000000001,129.2,77,179]] CS 0 10:17:31.956 PCA Test (NAS100,H1) Standardized data CS 0 10:17:31.956 PCA Test (NAS100,H1) [[0.979632638610581,0.8604038253411385,0.2240645398825688,0.3760399462363875] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4489982926965129,-0.0540350228475094,1.504433339211528,1.684004976623816] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.6122703991316175,0.4863152056275964,1.344387239295408,0.3760399462363875] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2040901330438764,0.8604038253411385,-0.5761659596980309,-0.6049338265541837] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-2.163355410265021,-2.090739730176784,0.06401843996644889,0.539535575034816] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4489982926965129,-0.3865582403706605,-0.8962581595302708,-1.258916341747898] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.469448957915872,1.276057847245071,-1.536442559194751,-0.9319250841510407] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.7347244789579271,-1.259431686368917,-0.416119859781911,-0.7684294553526122] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.8571785587842599,0.6525768143891719,-0.8962581595302708,-0.9319250841510407] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.326544212870186,-0.3449928381802696,1.184341139379288,1.520509347825387]]
主成分分析(PCA)のコンテキストでは、データの標準化は重要な手順です。これは、PCAが変数間のスケールと分散の違いに敏感な共分散行列に基づいているためです。PCAを実行する前にデータを標準化することで、結果の主成分が、分析を歪め、誤った結論につながる可能性がある、より大きなサイズまたは分散を持つ変数によって支配されないようにすることができます。
02:行列の共分散を求める
共分散行列は、確率変数が変化にどの程度影響するかの測定値を含む行列で、データ行列のすべての列間の共分散を計算するために使用されます。有限の二次モーメントを持つ2つの共同分布の実数値確率変数XとYの間の共分散は、次のように定義されます。
![]()
しかし、標準ライブラリにはこの関数があるので、この式を理解することについて心配する必要はありません。
matrix Cova = Matrix.Cov(false); Print("Covariances\n", Cova);
出力:
CS 0 10:17:31.957 PCA Test (NAS100,H1) Covariances CS 0 10:17:31.957 PCA Test (NAS100,H1) [[1.111111111111111,1.05661579634328,-0.2881675653452953,-0.3314539233600543] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.05661579634328,1.111111111111111,-0.2164241126576326,-0.2333966556085017] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.2881675653452953,-0.2164241126576326,1.111111111111111,1.002480628180182] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.3314539233600543,-0.2333966556085017,1.002480628180182,1.111111111111111]]
共分散では対角の値が1の正方行列であることに注意してください。この共分散行列メソッドを呼び出すときは、rowval入力をfalseに設定する必要があります。
matrix matrix::Cov( const bool rowvar=true // rows or cols vectors of observations );
4つの列があるため、この関数に与える列に基づいて正方行列を恒等行列にしたいためです。出力は4x4行列になります。それ以外の場合は、8x8行列になります。
03:固有ベクトルと固有値を見つける
固有ベクトル(Eigenvector)は、正方行列に関連付けられた特別なベクトルです。行列の固有ベクトルは、行列で乗算すると、固有値と呼ばれるそれ自体のスカラー倍になる、非零ベクトルです。
より公式には、Aが正方行列の場合、固有値と呼ばれる、Av=λvとなるようなスカラーλが存在する場合に、非零ベクトルvはAの固有ベクトルです。詳細については、こちらをご覧ください。
これも式を理解することを心配する必要はありません。標準ライブラリにもあります。
if (!Cova.Eig(component_matrix, eigen_vectors)) Print("Failed to get the Component matrix matrix & Eigen vectors");
このEigメソッドを詳しく見てみます。
bool matrix::Eig( matrix& eigen_vectors, // matrix of eigenvectors vector& eigen_values // vector of eigenvalues );
最初の入力行列eigen_vectorsは名前通り固有ベクトルを返します。ただし、この固有ベクトルは成分行列と呼ばれることもあります。したがって、MQL5言語標準に従って、実際には行列である場合に固有「ベクトル」と呼ぶと分かりにくいため、この固有ベクトルをコンポーネント行列に格納しています。
Print("\nComponent matrix\n",component_matrix,"\nEigen Vectors\n",eigen_vectors);
出力:
CS 0 10:17:31.957 PCA Test (NAS100,H1) Component matrix CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.5276049902734494,0.459884739531444,0.6993704635263588,-0.1449826035480651] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4959779194731578,0.5155907011803843,-0.679399121133044,0.1630612352922813] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4815459137666799,0.520677926282417,-0.1230090303369406,-0.6941734714553853] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4937128827246101,0.5015643052337933,0.184842006606018,0.6859404272536788]] CS 0 10:17:31.957 PCA Test (NAS100,H1) Eigen Vectors CS 0 10:17:31.957 PCA Test (NAS100,H1) [2.677561590453738,1.607960239905343,0.04775016337426833,0.1111724507110918]
05:PCAスコアを検索する
主成分分析スコアの検索は非常に簡単で、1行のコードで済みます。
pca_scores = Matrix.MatMul(component_matrix);
PCAスコアは、正規化された行列に成分行列を乗算することで求めることができます。
出力:
CS 0 10:17:31.957 PCA Test (NAS100,H1) PCA SCORES CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537,0.1425145462368588,0.1006701620494091] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321,-0.1510888243020112,0.1670753033981925] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756,0.001937917070391801,-0.6847663538666366] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518,-0.4827665581567511,0.09571954869438426] CS 0 10:17:31.957 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386,-0.0006861487484489809,0.2983796568520111] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733,-0.1738415909335406,-0.2393186981373224] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769,0.1774740257067155,0.4223436077935874] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977,0.2509606394263523,-0.337079680008286] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656,0.09411419638842802,-0.03495245015036286] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609,0.1413817973120564,0.2119289033750197]]
PCAスコアを取得したら、それらを標準化する必要があります。
pre_processing = new CPreprocessing(pca_scores_standardized, NORM_STANDARDIZATION); 出力:
CS 0 10:17:31.957 PCA Test (NAS100,H1) PCA SCORES | STANDARDIZED CS 0 10:17:31.957 PCA Test (NAS100,H1) [[-0.4187491401035159,0.9970295470975233,0.68746486754918,0.3182591681100855] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.172130620033975,1.15846730049564,-0.7288256625700642,0.528192723531639] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.1731572094549987,1.181160740523977,0.009348167869829477,-2.164823873278453] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.715386880184365,-0.05481045923432144,-2.328780161211247,0.3026082735855334] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.594713612332284,-1.470442808583469,-0.003309859736641006,0.9432989819176616] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-0.4023014443028848,-1.250129598312728,-0.8385809690405054,-0.7565833632510734] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.68012890598631,0.05510361946569121,0.8561031894464458,1.335199254045385] CS 0 10:17:31.957 PCA Test (NAS100,H1) [0.2786284867625921,-1.321151824538665,1.210589566461227,-1.06564543418136] CS 0 10:17:31.957 PCA Test (NAS100,H1) [-1.074244269325531,-0.1690934905926844,0.4539901733759543,-0.1104988556867913] CS 0 10:17:31.957 PCA Test (NAS100,H1) [1.072180711318756,0.8738669736790375,0.6820006878558206,0.6699931252073736]]
06:PCAコンポーネントを取得する
最後になりましたが、これまでおこなってきたすべての手順の目的である主成分を取得する必要があります。
コンポーネントを取得するには、標準化されていないPCAスコアの係数を見つける必要があります。覚えておいてください。これで、標準化されたものと標準化されていないものの2つのPCAスコアが得られました。
各PCAスコアの係数は、PCAスコア列の各列の分散です。
pca_scores_coefficients.Resize(cols); vector v_row; for (ulong i=0; i<cols; i++) { v_row = pca_scores.Col(i); pca_scores_coefficients[i] = v_row.Var(); //variance of the pca scores }
出力:
2023.02.25 10:17:31.957 PCA Test (NAS100,H1) SCORES COEFF [2.409805431408367,1.447164215914809,0.04297514703684173,0.1000552056399828]
主成分を抽出するには、多くの基準の中から考慮する必要がある基準があります。
- 固有値基準:この基準では、固有値が最大の主成分を選択します。最大の固有値は、データの最大の分散を捉える主成分に対応するという考え方です。
- 分散比率基準:この基準には、データの合計分散の特定の割合を説明する主成分の選択が含まれます。このライブラリでは、90%以上に設定します。
- スクリープロット基準:この基準では、各主成分の固有値を降順に示すスクリープロットを調べます。曲線が横ばいになり始めるポイントは、保持する主成分を選択するためのしきい値として使用されます。
- カイザー基準:この基準では、固有値が係数の平均より大きい主成分のみを保持します。つまり、係数が1より大きい主成分です。
- 交差検証基準:この基準には、検証セットでのPCAモデルのパフォーマンスの評価と、最良の予測精度をもたらす主成分の選択が含まれます。
このライブラリでは、計算効率が高く優れていると思われる、分散比率、カイザー、スクリープロットの3つの基準をコードにしました。以下の列挙型を使用して、それぞれを選択できます。
enum criterion
{
CRITERION_VARIANCE,
CRITERION_KAISER,
CRITERION_SCREE_PLOT
};
以下は、主成分を抽出するための完全な関数です。
matrix Cpca::ExtractComponents(criterion CRITERION_) { vector vars = pca_scores_coefficients; vector vars_percents = (vars/(double)vars.Sum())*100.0; //--- for Kaiser double vars_mean = pca_scores_coefficients.Mean(); //--- for scree double x[], y[]; //--- matrix PCAS = {}; double sum=0; ulong max; vector v_cols = {}; switch(CRITERION_) { case CRITERION_VARIANCE: #ifdef DEBUG_MODE Print("vars percentages ",vars_percents); #endif for (int i=0, count=0; i<(int)cols; i++) { count++; max = vars_percents.ArgMax(); sum += vars_percents[max]; vars_percents[max] = 0; v_cols.Resize(count); v_cols[count-1] = (int)max; if (sum >= 90.0) break; } PCAS.Resize(rows, v_cols.Size()); for (ulong i=0; i<v_cols.Size(); i++) PCAS.Col(pca_scores.Col((ulong)v_cols[i]), i); break; case CRITERION_KAISER: #ifdef DEBUG_MODE Print("var ",vars," scores mean ",vars_mean); #endif vars = pca_scores_coefficients; for (ulong i=0, count=0; i<cols; i++) if (vars[i] > vars_mean) { count++; PCAS.Resize(rows, count); PCAS.Col(pca_scores.Col(i), count-1); } break; case CRITERION_SCREE_PLOT: v_cols.Resize(cols); for (ulong i=0; i<v_cols.Size(); i++) v_cols[i] = (int)i+1; vars = pca_scores_coefficients; SortAscending(vars); //Make sure they are in ascending first order ReverseOrder(vars); //Set them to descending order VectorToArray(v_cols, x); VectorToArray(vars, y); plt.ScatterCurvePlots("Scree plot",x,y,"variance","PCA","Variance"); //--- vars = pca_scores_coefficients; for (ulong i=0, count=0; i<cols; i++) if (vars[i] > vars_mean) { count++; PCAS.Resize(rows, count); PCAS.Col(pca_scores.Col(i), count-1); } break; } return (PCAS); }
カイザー基準は、すべての分散の90%以上を説明する係数を持つ主成分を選択するように設定されているため、分散をパーセンテージに変換する必要がありました。
vector vars = pca_scores_coefficients; vector vars_percents = (vars/(double)vars.Sum())*100.0;
以下は、各手法を使用した場合の出力です。
カイザー基準:
CS 0 12:03:49.579 PCA Test (NAS100,H1) PCA'S CS 0 12:03:49.579 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518] CS 0 12:03:49.579 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609]]
差異基準:
CS 0 12:03:49.579 PCA Test (NAS100,H1) PCA'S CS 0 12:03:49.579 PCA Test (NAS100,H1) [[-0.6500472384886967,1.199407986803537] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.819562596624738,1.393614599196321] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.2688014256048517,1.420914385142756] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.110534258768705,-0.06593596223641518] CS 0 12:03:49.579 PCA Test (NAS100,H1) [2.475561333978323,-1.768915328424386] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-0.6245145789301378,-1.503882637300733] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-2.608156175249579,0.0662886285379769] CS 0 12:03:49.579 PCA Test (NAS100,H1) [0.4325302694103054,-1.589321053467977] CS 0 12:03:49.579 PCA Test (NAS100,H1) [-1.667608250048573,-0.2034163217366656] CS 0 12:03:49.579 PCA Test (NAS100,H1) [1.664404875867474,1.051245703485609]]
スクリープロット基準:

これで主成分が2つになります。簡単に言えば、データセットは4つの変数から2つの変数だけに削減されます。これらの変数は、作業中のどのプロジェクトでも使用できます。
MetaTraderでの主成分分析
ここで、主成分分析を使用して、見たい取引環境を調べます。
そのために、10個のオシレーターを選びました。それらはすべてオシレーターなので、ポイントを証明しようとするときに試してみることにしました。同じタイプの指標が10個ある場合、PCAを実行してそれらを減らすことができるため、簡単に実行できる変数がいくつか得られます。
1つのチャートに、ATR、ベアーズパワー、MACD、チャイキンオシレーター、コモディティチャネルインデックス、デマーカー、フォースインデックス、モメンタム、RSI、ウィリアムズパーセントレンジの10個の指標を追加しました。
handles[0] = iATR(Symbol(),PERIOD_CURRENT, period); handles[1] = iBearsPower(Symbol(), PERIOD_CURRENT, period); handles[2] = iMACD(Symbol(),PERIOD_CURRENT,12, 26,9,PRICE_CLOSE); handles[3] = iChaikin(Symbol(), PERIOD_CURRENT,12,26,MODE_SMMA,VOLUME_TICK); handles[4] = iCCI(Symbol(),PERIOD_CURRENT,period, PRICE_CLOSE); handles[5] = iDeMarker(Symbol(),PERIOD_CURRENT,period); handles[6] = iForce(Symbol(),PERIOD_CURRENT,period,MODE_EMA,VOLUME_TICK); handles[7] = iMomentum(Symbol(),PERIOD_CURRENT,period, PRICE_CLOSE); handles[8] = iRSI(Symbol(),PERIOD_CURRENT,period,PRICE_CLOSE); handles[9] = iWPR(Symbol(),PERIOD_CURRENT,period); for (int i=0; i<10; i++) { matrix_utiils.CopyBufferVector(handles[i],0,0,bars,buff_v); ind_Matrix.Col(buff_v, i); //store each indicator in ind_matrix columns }
これらすべての指標を同じチャートで視覚化することにしました。以下のようになります。

すべてほぼ同じに見えるのは何故でしょうか。それらの相関行列を見てみましょう。
Print("Oscillators Correlation Matrix\n",ind_Matrix.CorrCoef(false));
出力:
CS 0 18:03:44.405 PCA Test (NAS100,H1) Oscillators Correlation Matrix CS 0 18:03:44.405 PCA Test (NAS100,H1) [[1,0.01772984879133655,-0.01650305145071043,0.03046861668248528,0.2933315924162302,0.09724971519249033,-0.054459564042778,-0.0441397473782667,0.2171969726706487,0.3071254662907512] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.01772984879133655,1,0.6291675928958272,0.2432064602541826,0.7433991440764224,0.7857575973967624,0.8482060554701495,0.8438879842180333,0.8287766948950483,0.7510097635884428] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.01650305145071043,0.6291675928958272,1,0.80889919514547,0.3583185473647767,0.79950773673123,0.4295059398014639,0.7482107564439531,0.8205910850439753,0.5941794310595322] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.03046861668248528,0.2432064602541826,0.80889919514547,1,0.03576792595345671,0.436675349452699,0.08175026884450357,0.3082792264724234,0.5314362133025707,0.2271361556104472] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.2933315924162302,0.7433991440764224,0.3583185473647767,0.03576792595345671,1,0.6368513319457978,0.701918992559641,0.6677393692960837,0.7952832674277922,0.8844891719743937] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.09724971519249033,0.7857575973967624,0.79950773673123,0.436675349452699,0.6368513319457978,1,0.6425071357003039,0.9239712092224102,0.8809179254503203,0.7999862160768584] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.054459564042778,0.8482060554701495,0.4295059398014639,0.08175026884450357,0.701918992559641,0.6425071357003039,1,0.7573281438252102,0.7142333470379938,0.6534102287503526] CS 0 18:03:44.405 PCA Test (NAS100,H1) [-0.0441397473782667,0.8438879842180333,0.7482107564439531,0.3082792264724234,0.6677393692960837,0.9239712092224102,0.7573281438252102,1,0.8565660350098397,0.8221821793990941] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.2171969726706487,0.8287766948950483,0.8205910850439753,0.5314362133025707,0.7952832674277922,0.8809179254503203,0.7142333470379938,0.8565660350098397,1,0.8866871375902136] CS 0 18:03:44.405 PCA Test (NAS100,H1) [0.3071254662907512,0.7510097635884428,0.5941794310595322,0.2271361556104472,0.8844891719743937,0.7999862160768584,0.6534102287503526,0.8221821793990941,0.8866871375902136,1]]
相関行列を見ると、他のいくつかの指標と相関するのはごく少数の指標であり、それらは少数派であるため、結局同じようには見えないことに気付くかもしれません。この行列にPCAを適用して、このアルゴリズムが得た結果を見てみましょう。
pca = new Cpca(ind_Matrix); matrix pca_matrix = pca.ExtractComponents(ENUM_CRITERION);以下のスクリープロット基準を選択したプロットは次のとおりです。

スクリープロットを見ると、3つのPCAのみが選択されていることは否定できません。以下はその外観です。
CS 0 15:03:30.992 PCA Test (NAS100,H1) PCA'S CS 0 15:03:30.992 PCA Test (NAS100,H1) [[-2.297373513063062,0.8489493134565058,0.02832445955171548] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-2.370488225540198,0.9122356709081817,-0.1170316144060158] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-2.728297784013197,1.066014896296926,-0.2859442064697605] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-1.818906988827231,1.177846546204641,-0.748128826146959] ... ... CS 0 15:03:30.992 PCA Test (NAS100,H1) [-3.26602969252589,0.4816995789189212,-0.7408982990360158] CS 0 15:03:30.992 PCA Test (NAS100,H1) [-3.810781495417407,0.4426824869307094,-0.5737277071364888…]
10変数からたったの3変数です。
これが、データアナリストかつトレーダーであることが非常に重要である理由です。なぜなら、私はトレーダーがチャート上に、時にはエキスパートアドバイザー(EA)に多くの指標を持っているのを見てきました。この方法を使用して変数を減らすことは、計算を減らすという点で価値があると思います。ところで、これは取引のアドバイスではありません。おこなってきたことがうまくいき、満足しているのであれば、心配する必要はありません。
これらの主成分を視覚化して、それらが同じ軸上でどのように見えるかを見てみましょう。
plt.ScatterCurvePlotsMatrix("pca's ",pca_matrix,"var","PCA");
出力:

主成分分析の長所
- 次元削減:PCAは、最も重要な情報を保持しながら、データセット内の変数の数を効果的に減らすことができます。データの分析と視覚化が簡素化され、計算の複雑さが軽減され、モデルのパフォーマンスが向上します。
- データ圧縮:PCAを使用すると、大規模なデータセットをより少数の主成分に効果的に圧縮できます。ストレージスペースを節約し、データ転送時間を短縮できます。
- ノイズ減少:PCAは、最も重要なパターンや傾向に注目することで、データのノイズやランダムな変動を取り除くことができます。先ほど見たように、10個のオシレーターには多くのノイズがありました。
- 解釈可能な結果:PCAは、簡単に解釈して視覚化できる主成分を生成し、データの構造を理解するのに役立ちます。
- データの正規化:PCAは、データを単位分散にスケーリングすることでデータを標準化します。これにより、変数スケールの違いの影響を減らし、統計モデルの精度を向上させることができます。
主成分分析の短所
- 情報の損失:あまりにも多くの主成分が破棄された場合、または保持された成分がデータ内のすべての関連する変化を捉えていない場合、PCAは情報の損失につながる可能性があります。
- 結果の解釈は煩わしい場合がある:特に元の変数が高度に相関している場合や主成分の数が多い場合は、主成分の解釈が困難になる可能性があります。
- 外れ値に敏感:多くのML手法と同様に、外れ値はこのアルゴリズムを歪め、偏った結果につながる可能性があります。
- 計算集約型:大規模なデータセットでは、PCAアルゴリズムが解決しようとしているのと同じ問題を引き起こす可能性があります。
- モデルの仮定:このアルゴリズムは、データが線形に関連し、主成分が無相関であることを前提としていますが、これは実際には常に正しいとは限りません。これらの仮定に違反すると、悪い結果が生じる可能性があります。
結びの言葉
結論として、主成分分析(PCA)は、最も重要な情報を保持しながらデータの次元を削減するために使用できる強力な手法です。データセットの主成分を特定することで、市場の根底にある構造についての洞察を得ることができます。PCAは、工学や生物学などの取引分野以外にも幅広い用途があります。数学的に集約的な手法ですが、その利点は試してみる価値があります。適切なアプローチとデータがあれば、PCAは新しい洞察を解き放ち、データに基づいて情報に基づいた取引決定を下すのに役立ちます。
このアルゴリズムの最新の開発と変更は、私のGitHubレポジトリ(https://github.com/MegaJoctan/MALE5)でご覧ください。
| ファイル | 説明 |
|---|---|
| matrix_utils.mqh | 追加の行列操作関数が含まれています |
| pca.mqh | メインの主成分分析ライブラリ |
| plots.mqh | ベクトルの描画を支援するクラスが含まれています |
| preprocessing.mqh | MLアルゴリズム用のデータを準備およびスケーリングするためのライブラリ |
| PCA Test.mqh | アルゴリズムとこの記事で説明したすべてをテストするためのEA |
参考記事:
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/12229
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
質問:逆相関を持つ指標は?この指標は資産やパラメータによって変化しますか?このプログラムでは、他の指標をハンドラーに挿入して、一緒に評価することができますか?あなたの記事は素晴らしいです!ありがとうございました!
疑問1 - 3つの指標とは?互いに逆相関している。正しいか?2 - あなたはより多くの指標を挿入するためにプログラムを変更することはできますか?プログラム内の移動平均や ボリュームインジケータのようなトレンド指標?3 - 3つのインジケータの結果は、各資産、タイムフレーム、各パラメータによって変化しますか?
私の記事を読んでいただきありがとうございます。このプログラムで遊べるアイデアや指標はたくさんあります。このプログラムで遊べるアイデアやインジケータはたくさんあります。誰もあなたのために、特にあなたのために、特に無料で仕事をすることはできません。